
NVIDIA VSS 3.2.0 GA を DGX Spark で動かしてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
NVIDIA の VSS(Video Search and Summarization)が、6 月 16 日に 3.2.0 として GA リリースされました。3.X 系としては最初の General Availability です。
VSS はざっくり言うと、映像を VLM(Vision Language Model)で要約・検索・アラート判定するためのリファレンス実装一式で、複数のマイクロサービスとエージェントワークフローを Docker Compose や Helm で立ち上げる構成になっています。これまでは EA(Early Access)でしたが、GA リリースということで、手元の DGX Spark 上に 3.2.0 をフル構成で立ち上げて、起動の手触りから新機能の現在地までを実機で確かめてみました。
DGX Spark は GB10(ARM64)を 1 基積んだコンパクトな AI ワークステーションで、CPU と GPU が Unified Memory を 128 GiB 共有する独特なアーキテクチャです。x86 + H100 / RTX PRO 6000 構成とは挙動が違う箇所も出てくるので、その点は適宜補足していきます。
VSS の以前のバージョンに触れた記事も書いているので、移行を考えている方は併せてどうぞ。
3.2.0 GA の概要
まずは 3.2.0 GA のリリースで何が変わったのか、release notes の NEW / CHANGED / FIXED / BREAKING を表にまとめてみました。
| 区分 | 主なトピック |
|---|---|
| NEW | 全マイクロサービスとエージェントワークフローの GitHub ソース公開(Apache-2.0 + MIT)、Agent Skills (EA)、NemoClaw + VSS (EA)、RT-CV-3D(Sparse4D v2.2)+ Auto Calibration、音声付き動画理解(Nemotron 3 Nano Omni) |
| CHANGED | /v1/generate_captions_alerts → /v1/generate_captions リネーム、base profile から Envoy/SDR routing 撤去、デプロイ構造を developer-profiles/ + services/ の include モデルへ |
| FIXED | 重複 stream/camera ID で HTTP 409 を返すように(旧挙動:silent overwrite)、Riva ASR NIM の compose 同梱を停止 |
| BREAKING | 上記 CHANGED + FIXED のうち、過去バージョンの client コード・compose をそのまま使うと動かなくなる項目 |
特に大きいのは「全ソース公開」と「デプロイ構造の刷新」だと感じました。本記事では、この 2 つの変化に乗っかる形で実機検証を進めていきます。
なお RT-CV-3D / Auto Calibration はマルチカメラ環境が必要で、本記事では深掘りしません。音声付き動画理解(Nemotron 3 Nano Omni)も、Riva ASR NIM が入れ替わる大きな変化なので、別記事で実機検証しようと思います。
デプロイ構造の刷新
3.2 のデプロイ構造は deploy/docker/{developer-profiles, industry-profiles, services}/ を include で繋いだモジュラー構成になっています。dev-profile.sh という起動スクリプトが GPU を自動検出して HARDWARE_PROFILE を決定し、プロファイル別の compose を組み立てる仕組みです。
点線は base profile で実際に拾われるサービス群(agent / Cosmos-Reason2-8B / Nemotron-Nano-9B-v2 FP8 / ui・vios・infra)を示しています。alerts や lvs の点線を引いていけば、別プロファイルが何を呼び込むかも同じ図で読めるはずです。
GPU 検出ロジックは dev-profile.sh:91 あたりにあって、
case "${gpu_name}" in
*gb10*) echo "DGX-SPARK" ;;
...
esac
nvidia-smi の GPU 名から DGX-SPARK を自動判定して HARDWARE_PROFILE=DGX-SPARK を generated.env に書き込みます。GB10 を積んだ DGX Spark なら、明示指定なしでも自動で正しいプロファイルに乗ってくれる、ということですね。
ちなみに HAProxy が API Gateway として 7777 番ポートで動く設計になっていて、独立した vss-api-gateway イメージは見当たりません。3.X 系では HAProxy がそのまま ingress + API Gateway 役を担う形に落ち着いた印象です。
DGX Spark で動かすときの実機ポイント
ここからは DGX Spark で base profile を立ち上げたときに見えてくる現在地を、LLM / Alert / 起動時間の三本立てで整理します。
Local LLM は vLLM コンテナで動く
base profile を起動した状態で LLM コンテナの中身を docker inspect で覗いてみると、走っているのは NIM ではなく素の vLLM コンテナでした。
$ docker inspect nvidia-nemotron-nano-9b-v2-fp8 --format '{{.Config.Image}}'
nvcr.io/nvidia/vllm:25.12.post1-py3
実際の起動コマンドはこんな形で、
python3 -m vllm.entrypoints.openai.api_server \
--model nvidia/NVIDIA-Nemotron-Nano-9B-v2-FP8 \
--trust-remote-code \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.40 \
--port 8000 \
--mamba_ssm_cache_dtype float32 \
--enable-auto-tool-choice \
--tool-parser-plugin /opt/toolcall_parser/nemotron_toolcall_parser_no_streaming.py \
--tool-call-parser nemotron_json
公式 compose(deploy/docker/services/nim/nvidia-nemotron-nano-9b-v2-fp8/compose.yml)にもこんなコメントがついていて、
# Nemotron-Nano-V2 and tool-parser (nemotron_toolcall_parser_no_streaming.py) require vLLM 25.12+; 25.10 does not support Nemotron.
VSS 側で「vLLM 25.12+ を選んだ意図」までソースで読めるようになっています。Nemotron のツールコール用パーサも、nvidia-nemotron-nano-9b-v2-fp8-toolcall-init という init コンテナが HuggingFace から fetch してボリュームに置く仕掛けまで含まれていて、自前で tool parser を mount する手間はかかりません。
公式の prerequisites では「Fully local deployment for all agent workflows ... is planned for a future release」と将来計画として残しているのですが、
hw-DGX-SPARK.envの存在と上記 compose の作りを見るかぎり、base profile に限れば実機としては Local LLM が普通に動く状態になっています。建前としての「Remote LLM 限定」と、実装としての「Local LLM 動くようにできてる」が同居しているところは、頭の片隅に置いておくと良さそうですね。
Alert は単一の vss-alert-verification に集約
Alert ワークフローのコンテナ構成は、3.2 では deploy/docker/services/alert/compose.yml の中に単一サービスとしてまとまっています。
services:
alert-bridge:
image: nvcr.io/nvidia/vss-core/vss-alert-verification:3.2.0
container_name: vss-alert-bridge
image 名は vss-alert-verification ですが、コンテナ名は vss-alert-bridge のまま残されているところがちょっと面白いポイントで、過去バージョンから移行してきた compose 参照や監視スクリプトを壊さない配慮になっています。
サービス自体は単一ですが、機能としては次の 4 系統を環境変数で出し分ける作りでした。
| 環境変数 | 担当する機能 |
|---|---|
ALWAYS_ON_RULES_CONFIG |
Always-on alerts のルール設定 |
VLM_AS_VERIFIER_CONFIG_FILE |
VLM-as-Verifier の挙動設定 |
VLM_AS_VERIFIER_ALERT_TYPE_CONFIG_FILE |
VLM-as-Verifier の alert type 定義 |
RTVI_VLM_BASE_URL / RTVI_VLM_MODEL_TO_USE |
Real-Time VLM のエンドポイントとモデル |
VLM-as-Verifier の設定ファイル(vlm-as-verifier/configs/config.yml)のパスはそのまま残っているので、過去バージョンからの設定移行も比較的素直に通せそうな印象です。
Base profile のデプロイ時間
dev-profile.sh up -p base -H DGX-SPARK ... を実行してから、HAProxy 経由でヘルスチェックが通るまでの所要時間を time 込みで実測してみました。
| 区間 | 所要 |
|---|---|
down 既存クリーンアップ |
約 2 秒 |
| Image pull(vLLM + NIM 一式) | 約 55 秒 |
| Container 起動カスケード | 約 13 分(うち VLM NIM コンパイル待ちが支配的) |
| 合計(実測) | 14 分 0 秒 |
実測値には自分の環境固有の事情で起動中に 5 分ほどポート衝突のリカバリ作業が挟まっているので、これを差し引いた純粋な起動カスケードは約 9 分、合計でも 10 分前後というのが代表的な値です。Langfuse などを並走させていない素の DGX Spark なら、おおむねこちらの値に近いはずです。
ボトルネックは VLM(Cosmos-Reason2-8B、FP8 dynamic + KV8)の NIM 内部での TRT-LLM コンパイル時間で、コールドスタートで 8〜9 分を占めます。hw-DGX-SPARK.env で NIM_DISABLE_CUDA_GRAPH=1 がセットされているのは、おそらくこの cold start を少しでも短くするための工夫ですね。
なお Image pull が 55 秒で済んだのは過去の検証で別バージョンの vLLM や NIM image を pull した際の layer cache が効いたためで、まっさらな環境からだと数分〜10 分くらいは追加で見ておくほうが安全です。
API 周りで知っておきたい挙動
過去バージョンからの移行を考えている方や、既存のクライアントコードを流用したい方向けに、API 周りで挙動が違う箇所を整理しておきます。ソースはすべて v3.2.0 タグの GitHub リポジトリで grep できます。
キャプション生成のエンドポイント
ストリームのキャプション生成は /v1/generate_captions で呼びます。
curl -X POST http://localhost:7777/v1/generate_captions -d '{...}'
ルートの実体は services/video-summarization/src/via_server.py:1013 付近にあります。旧名 /v1/generate_captions_alerts を使っていたコードがあれば、移行が要ります。リポジトリ内を grep してもほぼ消えていて、
$ grep -rn "generate_captions_alerts" services/ | wc -l
1
唯一残っている 1 件も services/alert/alert-agent-web/app/api/realtime_schemas.py:218 のドキュメント文字列で「Same as RTVI VLM generate_captions_alerts: ...」と過去名を引用しているだけでした。API レベルでは綺麗にリネーム済みです。
重複 stream / camera ID は 409 で拒否
同じ stream ID / camera ID を投げ直すと、HTTP 409 + DuplicateStreamId / DuplicateCameraId で拒否されます。コードで見るとこうなっていて、
# services/rtvi/rt-vlm/src/utils/asset_manager.py:1265 付近
if camera_id:
existing_asset_id = self._camera_id_map.get(camera_id)
if existing_asset_id and existing_asset_id in self._asset_map:
raise ServiceException(
f"Live stream with camera_id '{camera_id}' already exists",
"DuplicateCameraId",
409,
)
if stream_id:
asset_id = str(stream_id)
if asset_id in self._asset_map:
raise ServiceException(
f"Live stream with stream_id '{asset_id}' already exists",
"DuplicateStreamId",
409,
)
rt-vlm 側と rt-embed 側の両方に同じガードが入っています。同じ ID を投げると上書きされる、と思っていると驚かれるので、409 ハンドリングを足しておくと安全ですね。
同一 RTSP は独立ジョブ扱い
/v1/generate_captions を同じ RTSP URL に対して複数回呼ぶと、毎回独立した request ID(UUID v4)で別ジョブとして扱われます。asset_manager.py の該当ロジックで stream_id を指定しなければ str(uuid.uuid4()) で新規 UUID を発行する作りなので、同じ RTSP に対して同時並行で別々の処理を走らせたい場合は便利です。
Base profile の routing は Envoy/SDR なし
base profile では Envoy + SDR routing を経由せず Stream Processing に直接接続する構成になっています。dev-profile-base/.env に明示的なコメントがついていて、
# Direct streamprocessing (no SDR/Envoy/SDRC router on :10000)
alerts / lvs / search プロファイルには sdrc/<mode>/configs/*.yml.tmpl が残っているので、base profile だけ意図的に routing 層を外している格好です。Envoy にカスタム filter / route を差し込んでいた構成、Istio や Linkerd 経由を前提にしていた構成、ENVOY_* 系の環境変数を使っていた構成は、base profile では効かなくなる点に注意ですね。
DGX Spark の公式ポジション
公式の prerequisites では DGX Spark の位置付けが次のように書かれています。
"AGX/IGX Thor and DGX Spark platforms currently support the listed remote-LLM configurations. Fully local deployment for all agent workflows (base, summarization, alerts, and search) is planned for a future release."
建前としては Remote LLM 限定なのですが、hw-DGX-SPARK.env と vLLM 公式 compose を組み合わせることで、base profile に関しては実機としては Local LLM がそのまま動きます。alerts / search プロファイルは Remote LLM 必須のままです。
VIOS 系の image は x86_64 / AGX Thor / DGX Spark を単一の OCI image index に統合している一方で、RTVI / RT-CV / RT-CV-3D 系は SBSA 専用 tag(*:3.2.0-sbsa)が別途必要、というアーキ依存も残っています。dev-profile.sh が DGX-SPARK を検出すると RTVI_VLM_IMAGE_TAG=3.2.0-sbsa を自動で書き込んでくれるので、こちらは特に意識せずに済みます。
おまけ: services/agent をローカルビルドして image 差し替えてみる
3.2 で「全マイクロサービスとエージェントワークフローの GitHub ソース公開」が来たので、せっかくならその恩恵を実機で味わってみたい、という話です。
リポジトリの services/agent/ 配下には VSS Agent のフルソースが入っていて、Dockerfile も同梱されています。ライセンスは Apache 2.0。
$ head -1 services/agent/LICENSE.md
Apache License
Version 2.0, January 2004
ちなみにリポジトリ全体としては Apache 2.0 + MIT のデュアル構成で、トップレベルの LICENSE に「Apache-2.0 applies to all code in the repository except the services/ui/ directory. MIT applies to the original code under the services/ui/ directory」と切り分けが明示されています。本記事の対象は services/agent なので Apache 2.0 で扱います。
公式 image を使わずに、自分でビルドしたものを差し替えてみます。
ビルドコマンド
Dockerfile は services/agent/docker/Dockerfile にあって、build context は services/ ディレクトリです。
docker build \
-f services/agent/docker/Dockerfile \
-t my-vss-agent:local \
services/
ビルドは multi-stage で、各ステージの役割はこんな感じです。
| ステージ | ベース | 役割 |
|---|---|---|
| builder | python:3.13-bookworm |
uv で依存解決、ARM64 用に pycairo をソースコンパイル |
| security-patches | debian:bookworm |
libssl3 を CVE 修正版にパッチ |
| runtime | nvcr.io/nvidia/distroless/python:3.13-v3.1.7 |
distroless で最小化 |
| agent-runtime | runtime から派生 | ENTRYPOINT /vss-agent/.venv/bin/nat serve |
production-grade な作りで、LGPL コンプライアンスのために FFmpeg ソースをイメージに同梱(services/agent/3rdparty/ffmpeg/FFmpeg-n8.0.1.tar.gz、ビルド時に verify_ffmpeg_tarball.py で存在と妥当性をチェック)するこだわりまで入っています。ビルドには 10〜20 分くらい見ておくと安全です。
落とし穴:security-patches ステージの URL が古びる
ここで「ソース公開時代のあるあるな落とし穴」に遭遇しました。Dockerfile の security-patches ステージで、libssl3 を Debian security repo から直接 wget する作りになっているのですが、
# v3.2.0 オリジナル(抜粋)
wget -O /patches/libssl3.deb http://security.debian.org/debian-security/pool/.../libssl3_3.0.19-1~deb12u2_arm64.deb
この 3.0.19-1~deb12u2 は本記事の検証時点では Debian security の current pool から外れていて、HTTP 404 で取れなくなっていました。CVE 修正の意図は保ちつつ、現行版を自動取得する形に書き換えるのが現実的です。
- RUN apt-get update && \
- apt-get install -y --no-install-recommends wget ca-certificates && \
- mkdir -p /patches && \
- if [ "$TARGETARCH" = "amd64" ]; then \
- wget -O /patches/libssl3.deb http://security.debian.org/debian-security/pool/.../libssl3_3.0.19-1~deb12u2_amd64.deb; \
- elif [ "$TARGETARCH" = "arm64" ]; then \
- wget -O /patches/libssl3.deb http://security.debian.org/debian-security/pool/.../libssl3_3.0.19-1~deb12u2_arm64.deb; \
- fi && \
- cd /patches && \
- dpkg-deb -x libssl3.deb /patches/libssl3-extracted && \
- rm -rf /var/lib/apt/lists/*
+ RUN apt-get update && \
+ apt-get install -y --no-install-recommends ca-certificates && \
+ mkdir -p /patches && \
+ cd /patches && \
+ apt-get download libssl3 && \
+ mv libssl3_*.deb libssl3.deb && \
+ dpkg-deb -x libssl3.deb /patches/libssl3-extracted && \
+ rm -rf /var/lib/apt/lists/*
apt-get download libssl3 にしておけば、bookworm-security に現時点で入っている最新の patched 版が自動で取れます。「ソース公開してくれてありがたい」と同時に、「外部依存の経年劣化と付き合う覚悟が要る」というのも合わせて学べる良い事例でした。
修正後のビルドは DGX Spark 上で約 8 分で完走し、最終 image サイズは 1.98 GB(distroless runtime 込み)でした。nvcr.io/nvidia/vss-core/vss-agent:3.2.0 の公式 image も docker images で同じく 1.98 GB。Dockerfile から組んだローカルビルド版が公式と寸分違わぬサイズに収まったのは、公式 image が Dockerfile から再現可能になっていることの分かりやすい証拠だと思います。
image 差し替え
deploy/docker/services/agent/compose.yml の該当行はこうなっていて、
vss-agent:
# for release, change this to the versioned image from the registry
image: nvcr.io/nvidia/vss-core/vss-agent:${VSS_AGENT_VERSION}
「change this to the versioned image from the registry」とコメントで明示されている通り、ユーザーが差し替えやすい作りになっています。my-vss-agent:local に差し替えて vss-agent だけ再起動するなら、
# compose.yml の image: を編集
sed -i 's|nvcr.io/nvidia/vss-core/vss-agent:.*|my-vss-agent:local|' \
deploy/docker/services/agent/compose.yml
# deploy/docker に移動して、vss-agent コンテナだけ再起動(依存サービスはそのまま)
cd deploy/docker
docker compose --env-file developer-profiles/dev-profile-base/generated.env \
up -d --no-deps --force-recreate vss-agent
--no-deps を付けないと vLLM / NIM / Phoenix 含む依存サービスも再起動されてしまい、また 10 分待つことになります。地味に重要なフラグですね。
起動後の動作確認は、まず docker inspect vss-agent で image が差し替わっているかをチェックし、
$ docker inspect vss-agent --format '{{.Config.Image}}'
my-vss-agent:local
/health 直叩きでアプリ層が応答していることを確認、
$ curl -s http://localhost:8000/health
{"value":{"isAlive":true}}
HAProxy 経由の Web UI も問題なし、
$ curl -s -o /dev/null -w "HTTP %{http_code}\n" http://localhost:7777/
HTTP 200
ここまで通れば、自分でビルドしたコードで Chat タブが動いている、という状態が手元にあるはずです。実際に Chat タブを開いて、サンプル動画(services/alert/warmup/test.mp4 の倉庫シーン)をアップロードしてから "Summarize this video in 2-3 lines." と投げてみたのが下の画面です。
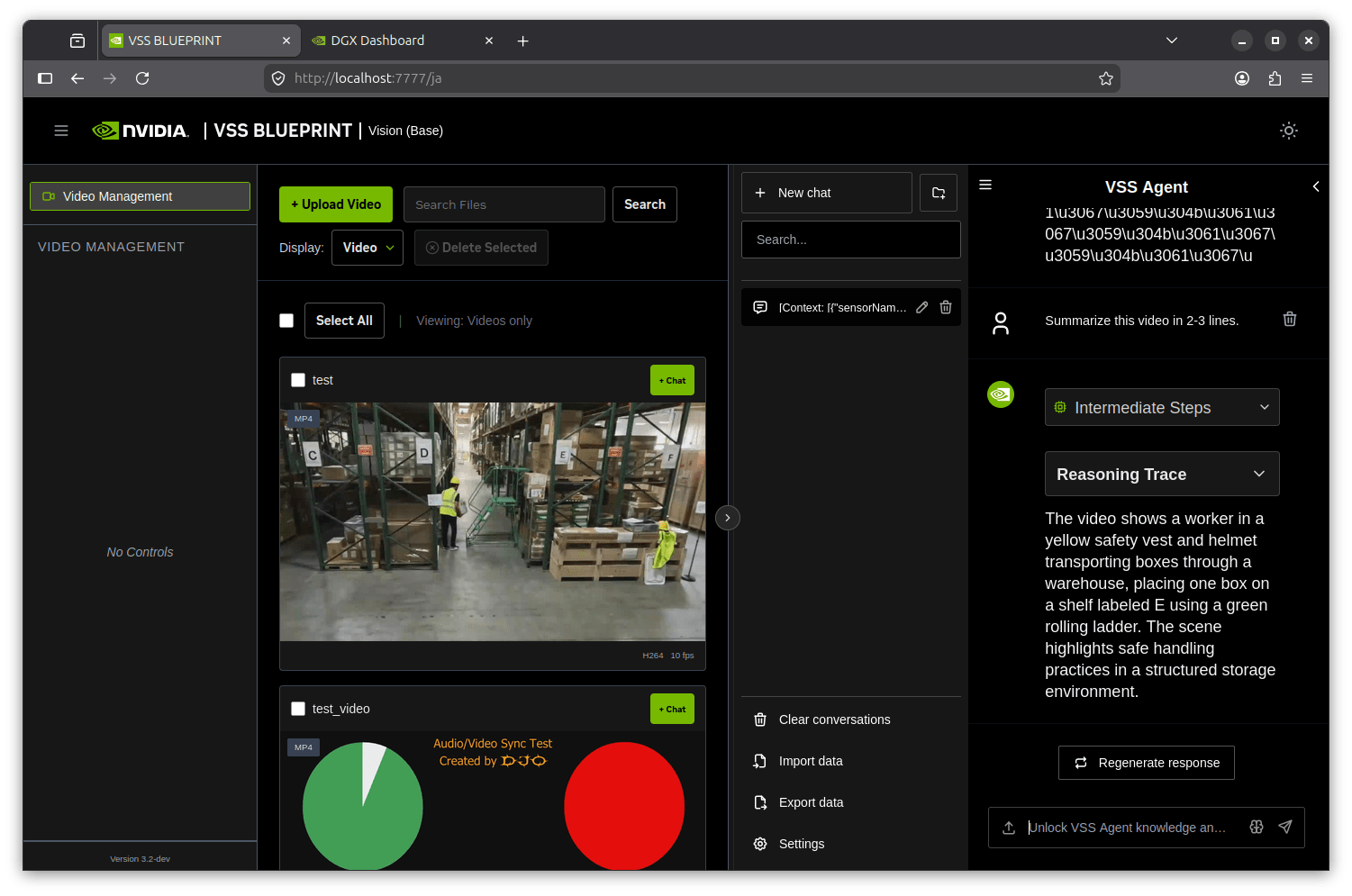
Reasoning Trace を開くと、エージェントが VLM の出力を踏まえて要約を組み立てている過程まで追えます。ローカルビルド版の vss-agent + 公式 NIM の VLM + Local vLLM の LLM、というハイブリッド構成でも、my-vss-agent:local が API Gateway 経由でちゃんと UI と話せている、ということが一枚で伝わるかなと思います。
次回は
最後に、3.2 でひっそりと退場したサービスについて触れておきます。
Riva ASR NIM が docker-compose から消えました。音声付き動画理解のために組み込まれていたのですが、3.2 では # RIVA ASR is not yet supported というコメントとともに退場し、代わりに Nemotron 3 Nano Omni VLM のネイティブ audio パスで音声理解を行う設計に切り替わっています。
# .env のサンプル(base profile + Omni)
VLM_NAME=Nemotron-Nano-V3-Omni-GA0420-FP8
RTVI_VLM_MODEL_TO_USE=vllm-compatible
VLM_MODEL_SUPPORTS_AUDIO=true
音声理解の設計変更はそこそこ大きな話なので、次回はそこを実機で追いかける予定です。
まとめ
VSS 3.2.0 GA を DGX Spark の base profile で立ち上げてみて見えてきたことをざっくり整理すると、こんなところでしょうか。
| 観点 | 3.2 GA + DGX Spark での実機の手触り |
|---|---|
| LLM | 公式 compose が vLLM コンテナで Nemotron-Nano-9B-v2 FP8 を起動。Tool-call パーサも init コンテナが自動で fetch |
| Alert | vss-alert-verification 単一 image で Always-on / VLM-as-Verifier / Real-Time を環境変数で出し分け |
| デプロイ時間 | base profile の素の起動カスケードで約 9 分、合計でも 10 分前後(VLM NIM コンパイル待ちが支配的) |
| API | キャプション系は /v1/generate_captions、重複 ID は 409、base profile は Envoy/SDR なし |
| ソース公開 | GitHub で全マイクロサービスと Agent ワークフローが Apache-2.0 + MIT で公開、Dockerfile も同梱 |
公式ドキュメントでは「DGX Spark は Remote LLM 限定」ですが、base profile の実装としては Local LLM がそのまま動く状態で、PoC や検証用途であればローカル完結で扱える仕上がりでした。Dockerfile が公開されたことで、自分でビルドしたコードを差し込んで挙動を確認する、という遊び方も普通にできる時代になっています。
参考リンク
- VSS docs(latest = 3.2.0)
- VSS 3.2.0 Release Notes
- VSS Prerequisites(ハードウェア / Profile / DGX Spark の Remote LLM 制約)
- VSS Helm chart デプロイガイド
- GitHub: video-search-and-summarization v3.2.0 リリース
- GitHub: LICENSE(Apache-2.0 + MIT デュアル)
- GitHub: services/agent ソース一式
- GitHub: deploy/docker(compose 配置)
- GitHub: services/agent/docker/Dockerfile(本記事でビルドした Dockerfile)
- HuggingFace: NVIDIA-Nemotron-Nano-9B-v2(tool parser のホスト元)
- build.nvidia.com: VSS Blueprint カード
- 前作: VSS 3.1.0 EA とハノーバーメッセで見えた製造業 VSS の今を調べてみた
- 初回: VSS 3.0.0 EA を DGX Spark で試してみた








