
I tried implementing a dynamic content filter using generative AI with LiteLLM Proxy
This page has been translated by machine translation. View original
Introduction
Hello, I'm Jinno from the Consulting Division, a huge fan of supermarkets.
In my previous article, I introduced a mechanism for applying different Bedrock Guardrails per team using the LiteLLM OSS custom guardrail feature.
Bedrock Guardrails is fast and highly effective for predefined categories such as harmful content detection and PII filtering. However, when actually operating it, situations arise where you want more flexible filtering.
For example, consider a message like "The budget for next term's Project A is 50 million yen, with a kickoff planned for April." This is clearly confidential information for the company, but it's difficult to catch with Bedrock Guardrails' keyword filters or topic detection. The reason is that what constitutes "confidential information for our company" differs from company to company and team to team. But I thought that if we could leverage generative AI's judgment capabilities here, we might be able to dynamically filter in a smart way...
So this time, I implemented a content filter that uses an LLM itself as the judgment engine, as a LiteLLM custom guardrail. It performs meaning-based filtering (semantic filtering) that leverages the LLM's contextual understanding.
Prerequisites
- LiteLLM OSS (no Enterprise license required)
- Amazon Bedrock (Claude Haiku 4.5 / Claude Sonnet 4.5 enabled)
- Docker / Docker Compose
- AWS CLI configured (with Bedrock access permissions)
The repository based on the previous article's repository, with the LLM-based content filter added, is below.
Differences Between Bedrock Guardrails and LLM-Based Filters
First, let me organize the differences between the two.
| Aspect | Bedrock Guardrails | LLM-Based Dynamic Filter |
|---|---|---|
| Detection method | Keyword / pattern matching / predefined categories | LLM-based contextual understanding |
| Policy definition | Configured via AWS console/IaC | Written in natural language (JSON file) |
| Policy changes | Version update | Built so you just swap the JSON |
| Customizability | Predefined categories + custom words | Freely definable |
| Cost | Bedrock Guardrails pricing | LLM invocation cost (Haiku is low-cost) |
| Latency | Low (~tens of ms) | Additional LLM invocation (hundreds of ms to seconds depending on environment) |
Bedrock Guardrails is a rules engine optimized on the AWS side, so it's fast and stable. On the other hand, for flexible filtering tailored to your company's business context, it's not realistic to specify every single rule and situation in detail, so let's try filtering with the help of generative AI.
Also, the two are not mutually exclusive — they can be stacked. A configuration where Bedrock Guardrails covers the baseline while the LLM-based filter dynamically applies company-specific policies is also achievable.
Architecture
The overall flow is as follows.
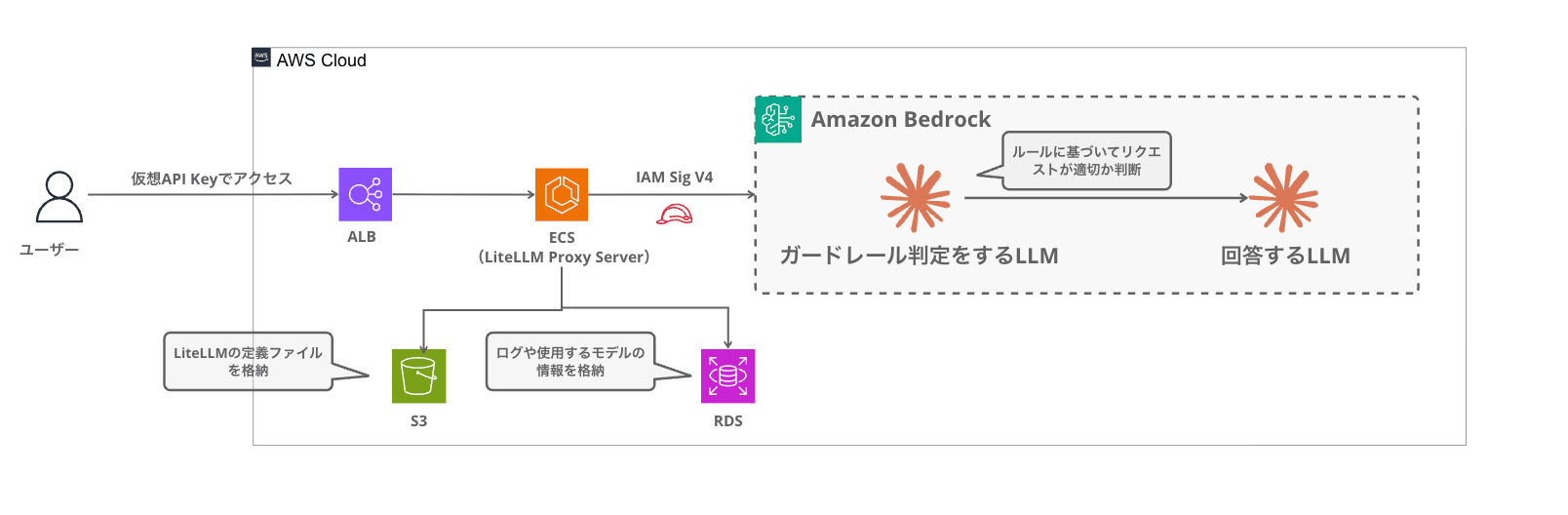
When a request arrives at the LiteLLM Proxy, the content filter is triggered in the pre_call hook (processing executed before sending a request to the LLM). The user message and the policies to be judged are sent together to Haiku, and based on the structured judgment result, a decision is made whether to block or pass. Only if it passes is it forwarded to the main LLM (Claude Sonnet / Haiku), and the response is returned to the user.
This filter is a Python class inheriting from LiteLLM's CustomGuardrail, with a mechanism that intercepts requests in async_pre_call_hook.
Implementation
Judgment Model with Structured Output
To reliably parse the filter's judgment results, we leverage Bedrock's Structured Output feature.
In Bedrock, by specifying a JSON Schema with the outputConfig.textFormat parameter of the Converse API, you can get the model's output in a format conforming to that schema. Claude Haiku 4.5 also supports this feature.
For more details on Bedrock's Structured Output, please refer to the article below as needed.
This time, since we're calling through litellm, we use Structured Output by passing a Pydantic model to the response_format parameter. litellm internally converts the Pydantic schema to the outputConfig.textFormat of the Bedrock Converse API.
from pydantic import BaseModel, Field
class FilterJudgment(BaseModel):
is_blocked: bool = Field(description="Whether the message violates any policy")
reason: str = Field(description="Brief explanation of the judgment")
violated_policy: str = Field(
description="The policy that was violated, or empty string if none"
)
With the three fields is_blocked / reason / violated_policy, we have all of the block judgment, reason, and violated policy returned in a structured format. With Bedrock's Structured Output providing JSON Schema-compliant output, we can greatly reduce parse failures due to format mismatches compared to parsing free-form text output.
Judgment Prompt
The system prompt passed to Haiku looks like this.
JUDGE_SYSTEM_PROMPT = """\
You are a content filter judgment engine.
Please determine whether the user's message violates any of the following policies.
## Policies
{policies}
## Judgment Criteria
- Consider the intent and context of the message, and set is_blocked to true only when it clearly violates a policy
- For ambiguous cases or messages unrelated to the policies, set is_blocked to false
- In violated_policy, describe the content of the violated policy (empty string if no violation)
- In reason, briefly describe the judgment reason in Japanese
"""
The policies are dynamically inserted into {policies}. The criteria of "block only when clearly in violation" is set conservatively to avoid over-detection. This area will likely need prompt revisions as actual operation progresses.
Defining Filter Rules
Filter rules are defined in JSON. It's a simple structure with level names as keys and lists of policy strings as values.
{
"standard": [
"Prohibit messages containing personal information (phone numbers, addresses, email addresses, My Number, etc. linked to a person's name)",
"Prohibit sending confidential information (unpublished product information, internal project budgets, sales data, customer contract terms, etc.) to external LLMs"
],
"strict": [
"Prohibit messages containing personal information (phone numbers, addresses, email addresses, My Number, etc. linked to a person's name)",
"Prohibit sending confidential information (unpublished product information, internal project budgets, sales data, customer contract terms, etc.) to external LLMs",
"Prohibit messages requesting comparative analysis of competitor products or services",
"Prohibit messages seeking legal judgments"
]
}
Being able to write policies in natural language is a unique advantage of LLM-based filters. Even non-engineers can read and write "what should be blocked." The standard level focuses on preventing information leakage, while the strict level adds further restrictions on usage.
The SemanticFilter Class
From here is the main implementation.
Full code (semantic_filter.py)
import json
import os
import traceback
from pathlib import Path
from typing import Any
import litellm
from litellm._logging import verbose_proxy_logger
from litellm.integrations.custom_guardrail import CustomGuardrail
from litellm.proxy._types import UserAPIKeyAuth
from pydantic import BaseModel, Field
class FilterJudgment(BaseModel):
is_blocked: bool = Field(description="Whether the message violates any policy")
reason: str = Field(description="Brief explanation of the judgment")
violated_policy: str = Field(
description="The policy that was violated, or empty string if none"
)
JUDGE_SYSTEM_PROMPT = """\
You are a content filter judgment engine.
Please determine whether the user's message violates any of the following policies.
## Policies
{policies}
## Judgment Criteria
- Consider the intent and context of the message, and set is_blocked to true only when it clearly violates a policy
- For ambiguous cases or messages unrelated to the policies, set is_blocked to false
- In violated_policy, describe the content of the violated policy (empty string if no violation)
- In reason, briefly describe the judgment reason in Japanese
"""
class SemanticFilter(CustomGuardrail):
def __init__(self, **kwargs):
super().__init__(**kwargs)
rules_raw = os.environ.get("SEMANTIC_FILTER_RULES", "{}")
if os.path.isfile(rules_raw):
rules_raw = Path(rules_raw).read_text()
self.filter_rules: dict[str, list[str]] = json.loads(rules_raw)
self.base_level = os.environ.get("BASE_SEMANTIC_FILTER_LEVEL", "")
self.judge_model = os.environ.get(
"SEMANTIC_FILTER_MODEL",
"bedrock/us.anthropic.claude-haiku-4-5-20251001-v1:0",
)
verbose_proxy_logger.info(
f"SemanticFilter initialized — "
f"levels: {list(self.filter_rules.keys())}, "
f"base: {self.base_level or '(none)'}, "
f"model: {self.judge_model}"
)
def _resolve_rules(self, metadata: dict[str, Any] | None) -> list[str]:
rules: list[str] = []
meta = metadata if isinstance(metadata, dict) else {}
if self.base_level and self.base_level in self.filter_rules:
rules.extend(self.filter_rules[self.base_level])
team_level = meta.get("semantic_filter_level")
if team_level and team_level in self.filter_rules:
for rule in self.filter_rules[team_level]:
if rule not in rules:
rules.append(rule)
return rules
def _extract_last_user_message(self, messages: list[dict]) -> str:
for msg in reversed(messages):
if msg.get("role") != "user":
continue
content = msg.get("content", "")
if isinstance(content, str):
return content.strip()
if isinstance(content, list):
texts = [
p["text"]
for p in content
if isinstance(p, dict) and isinstance(p.get("text"), str)
]
return "\n".join(texts).strip()
return ""
async def _judge(self, message: str, rules: list[str]) -> FilterJudgment:
policies = "\n".join(f"- {r}" for r in rules)
response = await litellm.acompletion(
model=self.judge_model,
messages=[
{
"role": "system",
"content": JUDGE_SYSTEM_PROMPT.format(policies=policies),
},
{"role": "user", "content": message},
],
response_format=FilterJudgment,
)
return FilterJudgment.model_validate_json(
response.choices[0].message.content
)
async def async_pre_call_hook(
self,
user_api_key_dict: UserAPIKeyAuth,
cache: Any,
data: dict,
call_type: str,
) -> None:
team_id = getattr(user_api_key_dict, "team_id", None)
metadata = getattr(user_api_key_dict, "metadata", None)
rules = self._resolve_rules(metadata)
if not rules:
return
messages = data.get("messages", [])
user_message = self._extract_last_user_message(messages)
if not user_message:
return
verbose_proxy_logger.info(
f"SemanticFilter: checking team={team_id}, rules={len(rules)}"
)
try:
judgment = await self._judge(user_message, rules)
except Exception:
verbose_proxy_logger.error(
f"SemanticFilter: judge failed — {traceback.format_exc()}"
)
return
verbose_proxy_logger.info(
f"SemanticFilter: team={team_id} — "
f"blocked={judgment.is_blocked}, reason={judgment.reason}"
)
if judgment.is_blocked:
raise Exception(
f"[Semantic Filter] {judgment.reason} "
f"(violated: {judgment.violated_policy})"
)
Let me highlight the key points.
Rule Resolution
The _resolve_rules method merges base level + team-specific level policies. It follows the same "stacking" concept as the Bedrock Guardrails version from the previous article. The base level applies company-wide policies, and team-specific policies can be added via semantic_filter_level in the team metadata. For this verification, we're using the base level (standard).
def _resolve_rules(self, metadata: dict[str, Any] | None) -> list[str]:
rules: list[str] = []
meta = metadata if isinstance(metadata, dict) else {}
if self.base_level and self.base_level in self.filter_rules:
rules.extend(self.filter_rules[self.base_level])
team_level = meta.get("semantic_filter_level")
if team_level and team_level in self.filter_rules:
for rule in self.filter_rules[team_level]:
if rule not in rules:
rules.append(rule)
return rules
Judgment Request to Haiku
The _judge method is the core of the judgment. Simply passing response_format=FilterJudgment to litellm's acompletion applies Bedrock's Structured Output.
async def _judge(self, message: str, rules: list[str]) -> FilterJudgment:
policies = "\n".join(f"- {r}" for r in rules)
response = await litellm.acompletion(
model=self.judge_model,
messages=[
{
"role": "system",
"content": JUDGE_SYSTEM_PROMPT.format(policies=policies),
},
{"role": "user", "content": message},
],
response_format=FilterJudgment,
)
return FilterJudgment.model_validate_json(
response.choices[0].message.content
)
litellm internally extracts the JSON Schema from the Pydantic model and converts it to outputConfig.textFormat in the Bedrock Converse API request. The response is stored as a JSON string in message.content, so it can be type-safely parsed with model_validate_json.
LiteLLM Configuration
Register the guardrail in config.yaml.
model_list:
- model_name: claude-sonnet
litellm_params:
model: bedrock/us.anthropic.claude-sonnet-4-5-20250929-v1:0
aws_region_name: us-east-1
- model_name: claude-haiku
litellm_params:
model: bedrock/us.anthropic.claude-haiku-4-5-20251001-v1:0
aws_region_name: us-east-1
litellm_settings:
drop_params: true
guardrails:
- guardrail_name: "semantic-filter"
litellm_params:
guardrail: semantic_filter.SemanticFilter
mode: "pre_call"
default_on: true
With mode: "pre_call", it executes before sending the request, and default_on: true automatically applies it to all requests.
Deployment
This time, I deployed to an ECS Fargate + ALB configuration using Terraform. I added an enable_semantic_filter flag to the same repository as the previous article, allowing the filter to be enabled/disabled.
aws_region = "us-east-1"
name_prefix = "litellm-sf"
litellm_master_key = "sk-your-secret-key"
ecs_cpu = 512
ecs_memory = 1024
desired_count = 1
enable_rds = false
enable_redis = false
enable_guardrail = false
enable_semantic_filter = true
Setting enable_semantic_filter = true causes Terraform to automatically:
- Upload semantic_filter.py and semantic_filter_rules.json to S3
- Add filter-related environment variables to the ECS task definition
- Download plugin files from S3 at container startup
cd terraform
terraform init
terraform apply
Apply complete! Resources: 39 added, 0 changed, 0 destroyed.
Outputs:
alb_dns_name = "litellm-sf-alb-xxxxxxxxxx.us-east-1.elb.amazonaws.com"
service_url = "http://litellm-sf-alb-xxxxxxxxxx.us-east-1.elb.amazonaws.com"
It takes about 1-2 minutes for the ECS task to start and pass health checks.
curl -s http://<ALB_DNS>/health/liveliness
"I'm alive!"
It started successfully!
Verification
Let's send actual requests to verify the filter's behavior.
Case 1: Normal Question (Pass)
curl -s http://<ALB_DNS>/v1/chat/completions \
-H "Authorization: Bearer $MASTER_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-haiku",
"messages": [{"role": "user", "content": "Pythonのリスト内包表記の書き方を教えてください"}]
}' | jq .
{
"choices": [
{
"message": {
"content": "# Pythonのリスト内包表記\n\nリスト内包表記は、リストを簡潔に生成する方法です。..."
}
}
]
}
Since this is a general technical question that doesn't violate any policy, the response was returned normally.
Case 2: Message Containing Personal Information (Block)
curl -s http://<ALB_DNS>/v1/chat/completions \
-H "Authorization: Bearer $MASTER_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-haiku",
"messages": [{"role": "user", "content": "田中太郎さんの連絡先は090-1234-5678、住所は東京都千代田区1-1-1です。この情報を整理してください"}]
}' | jq .
{
"error": {
"message": "[Semantic Filter] The message contains a phone number and address linked to a name (Taro Tanaka), violating the personal information protection policy (violated: Prohibit messages containing personal information (phone numbers, addresses, email addresses, My Number, etc. linked to a person's name))"
}
}
It was blocked! When blocked, no main LLM call is made, so only the filter judgment time is needed for the response. The error message includes which policy was violated, making it easy for both users and administrators to understand the reason.
Case 3: Internal Confidential Information (Block)
curl -s http://<ALB_DNS>/v1/chat/completions \
-H "Authorization: Bearer $MASTER_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-haiku",
"messages": [{"role": "user", "content": "来期のA社向けプロジェクトの予算は5000万円で、4月からキックオフ予定です。提案書のドラフトを作ってください"}]
}' | jq .
{
"error": {
"message": "[Semantic Filter] The message contains confidential information (unpublished project budget), and sending it to an external LLM is prohibited by policy. (violated: Prohibit sending confidential information (unpublished product information, internal project budgets, sales data, customer contract terms, etc.) to external LLMs)"
}
}
This is the case where the LLM-based filter proves its worth. Fragmented pieces of information like "Company A," "50 million," and "April kickoff" are each ordinary words as keywords. While it's difficult to catch them with Bedrock Guardrails' keyword filters or topic detection, Haiku understands from the context that "someone is trying to send internal project budget information externally" and blocks it appropriately.
Case 4: Ambiguous but Safe Message (Pass)
curl -s http://<ALB_DNS>/v1/chat/completions \
-H "Authorization: Bearer $MASTER_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-haiku",
"messages": [{"role": "user", "content": "一般的なIT企業のプロジェクト予算の相場感を教えてください。中規模のWebアプリケーション開発の場合、どのくらいが目安でしょうか"}]
}' | jq .
{
"choices": [
{
"message": {
"content": "# IT企業のプロジェクト予算相場\n\n## 中規模Webアプリケーション開発の目安\n\n**一般的な予算幅:500万~3,000万円程度**\n..."
}
}
]
}
Although the message contains the words "project budget," it's a general question rather than specific company information, so the filter allowed it through. A keyword-based filter might produce a false positive on "budget," but since this one understands context, over-detection is suppressed.
Response Time Summary
| Case | Result | Response Time | Breakdown |
|---|---|---|---|
| Normal question | Pass | ~7.1 seconds | Filter judgment + main response |
| Personal information | Block | ~1.7 seconds | Filter judgment only |
| Internal confidential information | Block | ~2.0 seconds | Filter judgment only |
| Ambiguous but safe | Pass | ~7.1 seconds | Filter judgment + main response |
When blocked, it was about 1.7-2.0 seconds; when passing, it was about 7 seconds including filter judgment + main LLM invocation. The filter judgment overhead is about 1.7-2.0 seconds, which stays within an acceptable range thanks to Haiku's low latency.
Per-Team Policy Switching
Just like in the previous article, different policy levels can be applied via team metadata.
curl -s http://<ALB_DNS>/team/new \
-H "Authorization: Bearer $MASTER_KEY" \
-H "Content-Type: application/json" \
-d '{
"team_alias": "legal-team",
"metadata": {"semantic_filter_level": "strict"}
}'
For strict-level teams, in addition to the standard policies, "comparative analysis with competitors" and "legal judgments" will also be blocked. Team management is handled entirely within LiteLLM's Admin UI, so no Terraform changes or deployments are required to switch policies.
Stacking with Bedrock Guardrails
You can also combine it with the Bedrock Guardrails plugin from the previous article. Simply list the guardrails in config.yaml.
guardrails:
- guardrail_name: "team-guardrail"
litellm_params:
guardrail: team_guardrail.TeamBedrockGuardrail
mode: "pre_call"
default_on: true
- guardrail_name: "semantic-filter"
litellm_params:
guardrail: semantic_filter.SemanticFilter
mode: "pre_call"
default_on: true
In Terraform, simply enable both enable_guardrail = true and enable_semantic_filter = true.
A combination where Bedrock Guardrails covers the baseline for harmful content and PII while the LLM-based filter dynamically applies company-specific policies is also possible. LiteLLM's guardrails execute in order from top to bottom, and if either one blocks the request, it is rejected.
Operational Considerations
There are several points to keep in mind for production use.
More various challenges may arise in actual operation. Please understand that this was an experimental implementation.
Fail-Open vs. Fail-Close
In the current implementation, if the Haiku call for judgment fails (timeout, API error, etc.), the request is allowed through rather than blocked (fail-open). The priority is availability, avoiding a situation where a filter failure stops the entire service.
On the other hand, if preventing information leakage is the top priority, fail-close — blocking the request when judgment fails — should also be considered. In this case, it can be switched simply by replacing return with raise Exception(...) in the exception handling of async_pre_call_hook. Which to adopt depends on whether you prioritize availability or governance.
Scope of Filter Targets
The current implementation uses _extract_last_user_message to target only the last user message for judgment. This means past conversation turns, system prompts, tool input/output, and attachment-equivalent content are outside the scope of judgment.
If you want to check the entire multi-turn conversation, or if confidential information could be included in tool payloads, the scope needs to be expanded. However, the more targets are added, the more input tokens are sent to Haiku, impacting cost and latency, so a balance needs to be struck.
Conclusion
I implemented a dynamic content filter using generative AI (Claude Haiku) as the judgment engine. After actually deploying and verifying the behavior, I experienced something interesting: it properly blocked cases like "internal confidential information that can't be judged by keywords alone," while allowing through ambiguous but safe messages.
Haiku's judgment latency is about 1.7-2.0 seconds — when blocked, it returns immediately; when passing, it's added on top of the main response. This may be a concern for use cases requiring real-time responsiveness, but it's also a trade-off, so it's an important point to clarify in advance: what do you want to prioritize most (latency or governance)?
I hope this article has been helpful in some way. Thank you for reading to the end!

