
LiteLLM Proxyで生成AIによる動的コンテンツフィルターを実装してみた
はじめに
こんにちは、スーパーマーケットが大好きなコンサル部の神野(じんの)です。
前回の記事では、LiteLLM OSS のカスタムガードレール機能を使って、チームごとに異なる Bedrock Guardrails を適用する仕組みを紹介しました。
Bedrock Guardrails は有害コンテンツの検出や PII フィルタリングなど、あらかじめ定義されたカテゴリに対して高速かつ非常に有効です。ただ、実際に運用しているともう少し柔軟にフィルタリングしたいと感じる場面が出てきます。
たとえば、「来期のA社向けプロジェクトの予算は5000万で、4月キックオフ予定」というメッセージを考えてみます。これは自社にとっては明らかに社外秘ですが、Bedrock Guardrails のキーワードフィルタやトピック検出では引っかけるのが難しいです。理由として何が「自社にとっての機密情報」かは、会社ごと・チームごとに異なるからです。でもここで生成AIの判断能力を活用できればいい感じに動的にフィルターできるのでは・・・?と考えました。
そこで今回は、LLM 自体を判定エンジンとして使うコンテンツフィルターを LiteLLM のカスタムガードレールとして実装してみました。LLM の文脈理解力を活かした意味ベースのフィルタリング(セマンティックフィルタリング)を行います。
前提
- LiteLLM OSS(Enterprise ライセンス不要)
- Amazon Bedrock(Claude Haiku 4.5 / Claude Sonnet 4.5 が有効化済み)
- Docker / Docker Compose
- AWS CLI が設定済み(Bedrock へのアクセス権限あり)
前回の記事のリポジトリをベースに、LLM ベースのコンテンツフィルターを追加実装したリポジトリは下記です。
Bedrock Guardrails と LLM ベースのフィルターの違い
まず、両者の違いを整理しておきます。
| 観点 | Bedrock Guardrails | LLM ベースの動的フィルター |
|---|---|---|
| 検出方式 | キーワード / パターンマッチ / 定義済みカテゴリ | LLM による文脈理解 |
| ポリシー定義 | AWS コンソール/IaCで設定 | 自然言語で記述(JSON ファイル) |
| ポリシー変更 | バージョン更新 | JSON を差し替えるだけの作りにした |
| カスタマイズ性 | 定義済みカテゴリ + カスタムワード | 自由に定義可能 |
| コスト | Bedrock Guardrails の料金 | LLM 呼び出しコスト(Haiku は低コスト) |
| レイテンシ | 低い(〜数十ms) | LLM 呼び出し分の追加(環境によって数百ms〜数秒) |
Bedrock Guardrails は AWS 側で最適化されたルールエンジンなので、速くて安定しています。一方で自社の業務コンテキストに合わせた柔軟なフィルタリングとなると、事細かに全てのルールやシチュエーションを指定するのは現実的ではないので生成AIの力を借りてフィルタリングを行ってみます。
また、両者は排他ではなく、重ねがけも可能です。Bedrock Guardrails でベースラインを押さえつつ、LLM ベースのフィルターで自社固有のポリシーを動的に適用する、という構成も実現できます。
アーキテクチャ
全体の流れはこうなります。
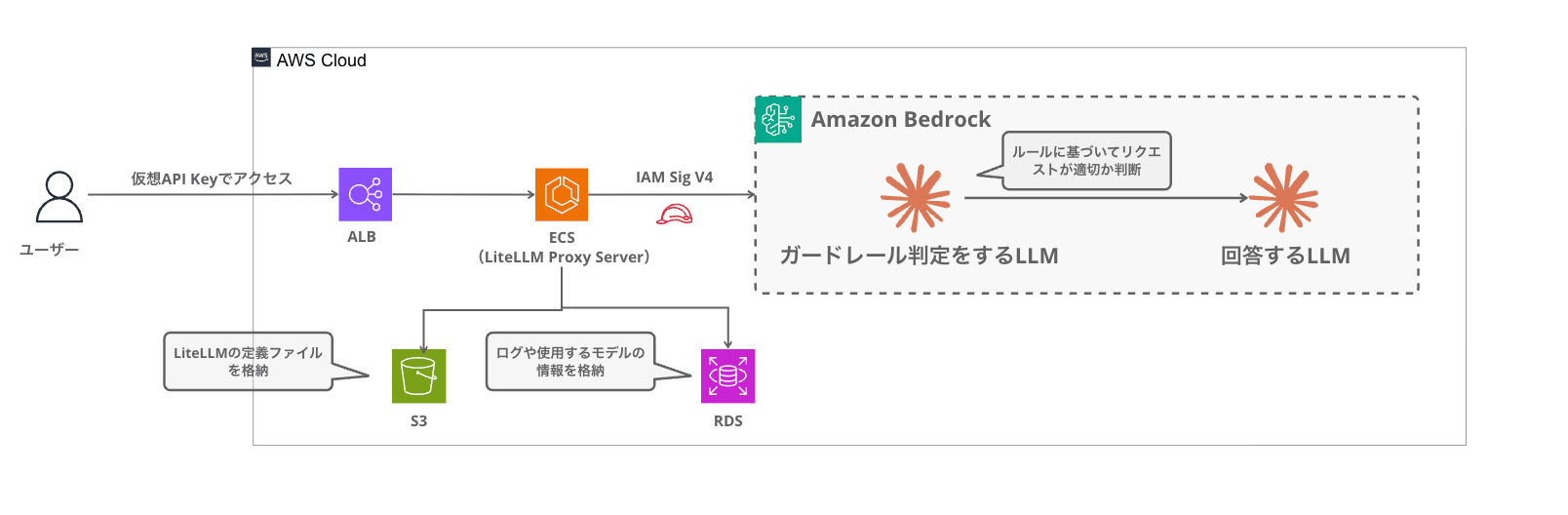
リクエストが LiteLLM Proxy に到着すると、pre_call hook(LLM へリクエストを送る前に実行される処理)でコンテンツフィルターが起動します。ユーザーメッセージと判断させたいポリシーを一緒に Haiku へ送信し、構造化した判定結果に基づいて、ブロックか通過かを決定します。通過した場合のみ本体の LLM(Claude Sonnet / Haiku)に転送され、レスポンスがユーザーに返却されます。
このフィルターは LiteLLM の CustomGuardrail を継承した Python クラスで、async_pre_call_hook でリクエストをインターセプトする仕組みです。
実装
Structured Output の判定モデル
フィルターの判定結果を確実にパースするために、Bedrock の Structured Output 機能を活用します。
Bedrock では Converse API の outputConfig.textFormat パラメータで JSON Schema を指定すると、モデルの出力をそのスキーマに準拠した形式で得られます。Claude Haiku 4.5 もこの機能に対応しています。
Bedrock の Structured Output については下記記事でも詳しく紹介しているので必要に応じてご参照ください。
今回は litellm 経由で呼び出すので、Pydantic モデルを response_format パラメータに渡す形で Structured Output を利用します。litellm が内部的に Pydantic のスキーマを Bedrock Converse API の outputConfig.textFormat に変換してくれます。
from pydantic import BaseModel, Field
class FilterJudgment(BaseModel):
is_blocked: bool = Field(description="Whether the message violates any policy")
reason: str = Field(description="Brief explanation of the judgment")
violated_policy: str = Field(
description="The policy that was violated, or empty string if none"
)
is_blocked / reason / violated_policy の3フィールドで、ブロック判定・理由・違反ポリシーをすべて構造化して返してもらいます。Bedrock の Structured Output により JSON Schema 準拠の出力が得られるため、自由形式のテキスト出力をパースする場合と比べて、フォーマット不一致によるパース失敗を大きく減らせます。
判定プロンプト
Haiku に渡すシステムプロンプトはこんな感じです。
JUDGE_SYSTEM_PROMPT = """\
あなたはコンテンツフィルターの判定エンジンです。
ユーザーのメッセージが以下のポリシーに違反しているかどうかを判定してください。
## ポリシー
{policies}
## 判定基準
- メッセージの意図と文脈を考慮し、ポリシーに明確に違反している場合のみ is_blocked を true にしてください
- 曖昧なケースやポリシーに関係ないメッセージは is_blocked を false にしてください
- violated_policy には違反したポリシーの内容を記載してください(違反なしの場合は空文字列)
- reason には判定理由を日本語で簡潔に記載してください
"""
ポリシーは {policies} に動的に挿入されます。「明確に違反している場合のみブロック」という基準と過検知は避けるように安全に振っています。この辺りは実際に運用しながら適宜プロンプトの見直しは必要になりそうです。
フィルタールールの定義
フィルタールールは JSON で定義します。レベル名をキー、ポリシー文字列のリストを値とするシンプルな構造です。
{
"standard": [
"個人情報(氏名と紐づいた電話番号・住所・メールアドレス・マイナンバー等)を含むメッセージを禁止する",
"社外秘の情報(未公開の製品情報・社内プロジェクトの予算・売上データ・顧客との契約条件等)を外部LLMに送信することを禁止する"
],
"strict": [
"個人情報(氏名と紐づいた電話番号・住所・メールアドレス・マイナンバー等)を含むメッセージを禁止する",
"社外秘の情報(未公開の製品情報・社内プロジェクトの予算・売上データ・顧客との契約条件等)を外部LLMに送信することを禁止する",
"競合他社の製品やサービスとの比較分析を依頼するメッセージを禁止する",
"法的判断を求めるメッセージを禁止する"
]
}
ポリシーを自然言語で書けるのが LLM ベースのフィルターならではのメリットです。エンジニアでなくても「何をブロックすべきか」を読み書きできます。standard レベルでは情報漏洩の防止に絞り、strict レベルではさらに用途の制限を加えるという構成にしています。
SemanticFilter クラス
ここからは本体の実装です。
コード全体(semantic_filter.py)
import json
import os
import traceback
from pathlib import Path
from typing import Any
import litellm
from litellm._logging import verbose_proxy_logger
from litellm.integrations.custom_guardrail import CustomGuardrail
from litellm.proxy._types import UserAPIKeyAuth
from pydantic import BaseModel, Field
class FilterJudgment(BaseModel):
is_blocked: bool = Field(description="Whether the message violates any policy")
reason: str = Field(description="Brief explanation of the judgment")
violated_policy: str = Field(
description="The policy that was violated, or empty string if none"
)
JUDGE_SYSTEM_PROMPT = """\
あなたはコンテンツフィルターの判定エンジンです。
ユーザーのメッセージが以下のポリシーに違反しているかどうかを判定してください。
## ポリシー
{policies}
## 判定基準
- メッセージの意図と文脈を考慮し、ポリシーに明確に違反している場合のみ is_blocked を true にしてください
- 曖昧なケースやポリシーに関係ないメッセージは is_blocked を false にしてください
- violated_policy には違反したポリシーの内容を記載してください(違反なしの場合は空文字列)
- reason には判定理由を日本語で簡潔に記載してください
"""
class SemanticFilter(CustomGuardrail):
def __init__(self, **kwargs):
super().__init__(**kwargs)
rules_raw = os.environ.get("SEMANTIC_FILTER_RULES", "{}")
if os.path.isfile(rules_raw):
rules_raw = Path(rules_raw).read_text()
self.filter_rules: dict[str, list[str]] = json.loads(rules_raw)
self.base_level = os.environ.get("BASE_SEMANTIC_FILTER_LEVEL", "")
self.judge_model = os.environ.get(
"SEMANTIC_FILTER_MODEL",
"bedrock/us.anthropic.claude-haiku-4-5-20251001-v1:0",
)
verbose_proxy_logger.info(
f"SemanticFilter initialized — "
f"levels: {list(self.filter_rules.keys())}, "
f"base: {self.base_level or '(none)'}, "
f"model: {self.judge_model}"
)
def _resolve_rules(self, metadata: dict[str, Any] | None) -> list[str]:
rules: list[str] = []
meta = metadata if isinstance(metadata, dict) else {}
if self.base_level and self.base_level in self.filter_rules:
rules.extend(self.filter_rules[self.base_level])
team_level = meta.get("semantic_filter_level")
if team_level and team_level in self.filter_rules:
for rule in self.filter_rules[team_level]:
if rule not in rules:
rules.append(rule)
return rules
def _extract_last_user_message(self, messages: list[dict]) -> str:
for msg in reversed(messages):
if msg.get("role") != "user":
continue
content = msg.get("content", "")
if isinstance(content, str):
return content.strip()
if isinstance(content, list):
texts = [
p["text"]
for p in content
if isinstance(p, dict) and isinstance(p.get("text"), str)
]
return "\n".join(texts).strip()
return ""
async def _judge(self, message: str, rules: list[str]) -> FilterJudgment:
policies = "\n".join(f"- {r}" for r in rules)
response = await litellm.acompletion(
model=self.judge_model,
messages=[
{
"role": "system",
"content": JUDGE_SYSTEM_PROMPT.format(policies=policies),
},
{"role": "user", "content": message},
],
response_format=FilterJudgment,
)
return FilterJudgment.model_validate_json(
response.choices[0].message.content
)
async def async_pre_call_hook(
self,
user_api_key_dict: UserAPIKeyAuth,
cache: Any,
data: dict,
call_type: str,
) -> None:
team_id = getattr(user_api_key_dict, "team_id", None)
metadata = getattr(user_api_key_dict, "metadata", None)
rules = self._resolve_rules(metadata)
if not rules:
return
messages = data.get("messages", [])
user_message = self._extract_last_user_message(messages)
if not user_message:
return
verbose_proxy_logger.info(
f"SemanticFilter: checking team={team_id}, rules={len(rules)}"
)
try:
judgment = await self._judge(user_message, rules)
except Exception:
verbose_proxy_logger.error(
f"SemanticFilter: judge failed — {traceback.format_exc()}"
)
return
verbose_proxy_logger.info(
f"SemanticFilter: team={team_id} — "
f"blocked={judgment.is_blocked}, reason={judgment.reason}"
)
if judgment.is_blocked:
raise Exception(
f"[Semantic Filter] {judgment.reason} "
f"(violated: {judgment.violated_policy})"
)
ポイントをピックアップして説明します。
ルールの解決
_resolve_rules メソッドで、ベースレベル + チーム固有レベルのポリシーをマージしています。前回の Bedrock Guardrails 版と同じ「重ねがけ」の考え方です。ベースレベルで全社共通のポリシーを適用し、チーム metadata の semantic_filter_level でチーム固有のポリシーを追加できます。今回の動作確認ではベースレベル(standard)を使用しています。
def _resolve_rules(self, metadata: dict[str, Any] | None) -> list[str]:
rules: list[str] = []
meta = metadata if isinstance(metadata, dict) else {}
if self.base_level and self.base_level in self.filter_rules:
rules.extend(self.filter_rules[self.base_level])
team_level = meta.get("semantic_filter_level")
if team_level and team_level in self.filter_rules:
for rule in self.filter_rules[team_level]:
if rule not in rules:
rules.append(rule)
return rules
Haiku への判定リクエスト
_judge メソッドが判定のコアです。litellm の acompletion に response_format=FilterJudgment を渡すだけで、Bedrock の Structured Output が適用されます。
async def _judge(self, message: str, rules: list[str]) -> FilterJudgment:
policies = "\n".join(f"- {r}" for r in rules)
response = await litellm.acompletion(
model=self.judge_model,
messages=[
{
"role": "system",
"content": JUDGE_SYSTEM_PROMPT.format(policies=policies),
},
{"role": "user", "content": message},
],
response_format=FilterJudgment,
)
return FilterJudgment.model_validate_json(
response.choices[0].message.content
)
litellm は内部で Pydantic モデルの JSON Schema を取り出し、Bedrock Converse API の outputConfig.textFormat に変換してリクエストを送ります。レスポンスは message.content に JSON 文字列として格納されるので、model_validate_json で型安全にパースできます。
LiteLLM の設定
config.yaml にガードレールを登録します。
model_list:
- model_name: claude-sonnet
litellm_params:
model: bedrock/us.anthropic.claude-sonnet-4-5-20250929-v1:0
aws_region_name: us-east-1
- model_name: claude-haiku
litellm_params:
model: bedrock/us.anthropic.claude-haiku-4-5-20251001-v1:0
aws_region_name: us-east-1
litellm_settings:
drop_params: true
guardrails:
- guardrail_name: "semantic-filter"
litellm_params:
guardrail: semantic_filter.SemanticFilter
mode: "pre_call"
default_on: true
mode: "pre_call" でリクエスト送信前に実行され、default_on: true で全リクエストに自動適用されます。
デプロイ
今回は Terraform で ECS Fargate + ALB の構成にデプロイしました。前回の記事と同じリポジトリに enable_semantic_filter フラグを追加して、フィルターの有効/無効を切り替えられるようにしています。
aws_region = "us-east-1"
name_prefix = "litellm-sf"
litellm_master_key = "sk-your-secret-key"
ecs_cpu = 512
ecs_memory = 1024
desired_count = 1
enable_rds = false
enable_redis = false
enable_guardrail = false
enable_semantic_filter = true
enable_semantic_filter = true にすると、Terraform が以下を自動で行います。
- semantic_filter.py と semantic_filter_rules.json を S3 にアップロード
- ECS タスク定義にフィルター用の環境変数を追加
- コンテナ起動時に S3 からプラグインファイルをダウンロード
cd terraform
terraform init
terraform apply
Apply complete! Resources: 39 added, 0 changed, 0 destroyed.
Outputs:
alb_dns_name = "litellm-sf-alb-xxxxxxxxxx.us-east-1.elb.amazonaws.com"
service_url = "http://litellm-sf-alb-xxxxxxxxxx.us-east-1.elb.amazonaws.com"
ECS タスクが起動してヘルスチェックが通るまで 1〜2 分ほどかかります。
curl -s http://<ALB_DNS>/health/liveliness
"I'm alive!"
起動できましたね!
動作確認
実際にリクエストを送って、フィルターの動作を確認していきます。
ケース 1: 通常の質問(通過)
curl -s http://<ALB_DNS>/v1/chat/completions \
-H "Authorization: Bearer $MASTER_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-haiku",
"messages": [{"role": "user", "content": "Pythonのリスト内包表記の書き方を教えてください"}]
}' | jq .
{
"choices": [
{
"message": {
"content": "# Pythonのリスト内包表記\n\nリスト内包表記は、リストを簡潔に生成する方法です。..."
}
}
]
}
一般的な技術質問なのでポリシーに違反せず、通常通りレスポンスが返ってきました。
ケース 2: 個人情報を含むメッセージ(ブロック)
curl -s http://<ALB_DNS>/v1/chat/completions \
-H "Authorization: Bearer $MASTER_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-haiku",
"messages": [{"role": "user", "content": "田中太郎さんの連絡先は090-1234-5678、住所は東京都千代田区1-1-1です。この情報を整理してください"}]
}' | jq .
{
"error": {
"message": "[Semantic Filter] メッセージに氏名(田中太郎)と紐づいた電話番号及び住所が含まれており、個人情報保護ポリシーに違反しています (violated: 個人情報(氏名と紐づいた電話番号・住所・メールアドレス・マイナンバー等)を含むメッセージを禁止する)"
}
}
ブロックされましたね! ブロック時は本体の LLM 呼び出しが発生しないため、フィルター判定の時間のみで返却されます。エラーメッセージにどのポリシーに違反したかが含まれているので、ユーザーにも管理者にも原因がわかりやすく返信が返ってきましたね。
ケース 3: 社内機密情報(ブロック)
curl -s http://<ALB_DNS>/v1/chat/completions \
-H "Authorization: Bearer $MASTER_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-haiku",
"messages": [{"role": "user", "content": "来期のA社向けプロジェクトの予算は5000万円で、4月からキックオフ予定です。提案書のドラフトを作ってください"}]
}' | jq .
{
"error": {
"message": "[Semantic Filter] メッセージに社外秘情報(未公開プロジェクトの予算額)が含まれており、外部LLMへの送信がポリシーで禁止されています。 (violated: 社外秘の情報(未公開の製品情報・社内プロジェクトの予算・売上データ・顧客との契約条件等)を外部LLMに送信することを禁止する)"
}
}
これが LLM ベースのフィルターが効果を発揮するケースです。「A社」「5000万」「4月キックオフ」といった断片的な情報は、それぞれキーワードとしては普通の単語です。Bedrock Guardrails のキーワードフィルタやトピック検出で引っかけるのは難しいところを、Haiku は文脈から「社内プロジェクトの予算情報を外部に送信しようとしている」ことを理解して、適切にブロックしています。
ケース 4: 紛らわしいが問題ないメッセージ(通過)
curl -s http://<ALB_DNS>/v1/chat/completions \
-H "Authorization: Bearer $MASTER_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-haiku",
"messages": [{"role": "user", "content": "一般的なIT企業のプロジェクト予算の相場感を教えてください。中規模のWebアプリケーション開発の場合、どのくらいが目安でしょうか"}]
}' | jq .
{
"choices": [
{
"message": {
"content": "# IT企業のプロジェクト予算相場\n\n## 中規模Webアプリケーション開発の目安\n\n**一般的な予算幅:500万~3,000万円程度**\n..."
}
}
]
}
「プロジェクト予算」という言葉は含まれていますが、自社の具体的な情報ではなく一般的な質問なので、フィルターは通過させました。キーワードベースのフィルタだと「予算」で誤検知してしまう可能性がありますが、文脈を理解しているので過検知を抑えられています。
レスポンス時間のまとめ
| ケース | 結果 | レスポンス時間 | 内訳 |
|---|---|---|---|
| 通常質問 | 通過 | 約 7.1 秒 | フィルター判定 + 本体応答 |
| 個人情報 | ブロック | 約 1.7 秒 | フィルター判定のみ |
| 社内機密情報 | ブロック | 約 2.0 秒 | フィルター判定のみ |
| 紛らわしいが安全 | 通過 | 約 7.1 秒 | フィルター判定 + 本体応答 |
ブロック時は約 1.7〜2.0 秒、通過時はフィルター判定 + 本体の LLM 呼び出しで約 7 秒でした。フィルター判定のオーバーヘッドは 1.7〜2.0 秒程度で、Haiku の低レイテンシのおかげで許容範囲に収まっています。
チーム単位のポリシー切り替え
前回の記事と同じように、チームの metadata で異なるポリシーレベルを適用できます。
curl -s http://<ALB_DNS>/team/new \
-H "Authorization: Bearer $MASTER_KEY" \
-H "Content-Type: application/json" \
-d '{
"team_alias": "legal-team",
"metadata": {"semantic_filter_level": "strict"}
}'
strict レベルのチームでは、standard のポリシーに加えて「競合他社との比較分析」「法的判断」もブロックされるようになります。チームの管理は LiteLLM の Admin UI で完結するため、ポリシーの切り替えに Terraform の変更やデプロイは必要ありません。
Bedrock Guardrails との重ねがけ
前回の Bedrock Guardrails プラグインと組み合わせることもできます。config.yaml にガードレールを並べるだけです。
guardrails:
- guardrail_name: "team-guardrail"
litellm_params:
guardrail: team_guardrail.TeamBedrockGuardrail
mode: "pre_call"
default_on: true
- guardrail_name: "semantic-filter"
litellm_params:
guardrail: semantic_filter.SemanticFilter
mode: "pre_call"
default_on: true
Terraform では enable_guardrail = true と enable_semantic_filter = true を両方有効にするだけです。
Bedrock Guardrails で有害コンテンツや PII のベースラインを押さえつつ、LLM ベースのフィルターで自社固有のポリシーを動的に適用する、という組み合わせも可能です。LiteLLM のガードレールは上から順に実行され、どちらか一方でもブロックすればリクエストは拒否されます。
運用上の注意点
実運用に向けていくつか意識しておきたいポイントがあります。
実際に運用していくともっと色々な課題は出てくるかもしれません。今回はあくまで試験的に実装したというところはご了承ください。
フェイルオープン と フェイルクローズ
今回の実装では、判定用の Haiku 呼び出しが失敗した場合(タイムアウト、API エラーなど)にリクエストをブロックせず通過させています(フェイルオープン)。可用性を優先し、フィルターの障害でサービス全体が止まることを避ける方針です。
一方、情報漏洩防止を最優先にする場合は、判定失敗時にリクエストをブロックするフェイルクローズも検討すべきです。この場合は async_pre_call_hook の例外ハンドリングで return の代わりに raise Exception(...) とするだけで切り替えられます。どちらを採用するかは、可用性とガバナンスのどちらを重視するかで決まります。
フィルター対象の範囲
現在の実装では _extract_last_user_message で最後の user メッセージのみを判定対象としています。つまり、過去ターンのメッセージ、system prompt、tool の入出力、添付ファイル相当のコンテンツは判定対象外です。
マルチターンの会話全体をチェックしたい場合や、tool payload にも機密情報が含まれうるケースでは、対象範囲を拡張する必要があります。ただし判定対象が増えるほど Haiku への入力トークン数が増え、コストとレイテンシに影響するので、バランスを見て決める形になります。
おわりに
生成 AI(Claude Haiku)を判定エンジンにした動的なコンテンツフィルターを実装してみました。実際にデプロイして動作確認したところ、社内機密情報のような「キーワードだけでは判定できないケース」をきちんとブロックしつつ、紛らわしいが問題ないメッセージは通過させるという面白いものを体験できました。
Haiku の判定レイテンシは約 1.7〜2.0 秒で、ブロック時はそのまま返却、通過時は本体の応答に加算される形になります。リアルタイム性が求められるユースケースでは気になるかもしれませんが、トレードオフでもあるので何を一番にとりたい(レイテンシなのかガバナンスなのか)かは事前に整理しておきたいポイントです。
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございました!










