
I tried NeMo Switchyard, the successor to NVIDIA LLM Router
This page has been translated by machine translation. View original
Introduction
Hello, I'm Morishige from Classmethod's Manufacturing Business Technology Department.
I had just published two articles about running NVIDIA LLM Router on DGX Spark, when someone told me right after that "a Python library that serves as the successor to LLM Router has been released." NeMo Switchyard, v0.1.0 was released on July 1, 2026 Japan time.
It's a bit of a mixed feeling as someone who was preparing a continuation of those articles, but as I actually started using it, I kept discovering that "features I struggled to build myself in LLM Router are already included from the start." In this article, I'll run Switchyard on my Mac and DGX Spark to verify whether the pitfalls I encountered during LLM Router testing have truly been resolved.
What Is NeMo Switchyard
It's a routing proxy that distributes LLM traffic, published under the NVIDIA-NeMo organization on GitHub. It's a Python package you can install with pip install nemo-switchyard, and internally it has a two-layer structure where Python wraps a Rust core built with maturin. The license is Apache 2.0, the version is 0.1.0, and the development status is explicitly listed as Alpha.
A documentation site has also been published.
For those who have used LLM Router, here's a table comparing the differences in character.
| Aspect | LLM Router | NeMo Switchyard |
|---|---|---|
| Distribution | Docker Compose (Blueprint, fork required) | pip install |
| Routing decision | Trained classifier (GPU required, training data required) | LLM classifier or tool execution history heuristics |
| Supported APIs | OpenAI Chat Completions only | Converts OpenAI Chat / Anthropic Messages / OpenAI Responses |
| Claude Code connection | Requires separate conversion proxy like CCR | Single command: switchyard launch claude |
| GPU | Required for router inference | Not required |
I think the two major differences are "no trained router" and "built-in protocol conversion." LLM Router was designed to train a custom classifier that passes Qwen embeddings through PCA and MLP. Switchyard replaces that with signals obtained from LLM queries and agent tool execution histories. Since GPU is no longer required, it runs as-is on a Mac.
Choose From 4 Routing Methods
The documentation covers 4 routing methods.
| Method | How tiers are determined | Best suited for |
|---|---|---|
| passthrough | Fixed single model | When you just want to stabilize an alias |
| random-routing | Distributes strong / weak by specified probability | A/B testing, cost experiments |
| llm-routing | A classifier LLM categorizes request content | Distribution based on content |
| cascade | Determines based on tool execution result signals, consults classifier only when uncertain | Long coding agent tasks |
llm-routing summarizes the last 4 turns of conversation, passes it to a classifier model, classifies it into 4 categories (simple / medium / complex / reasoning), then maps it to weak / strong tiers. It uses tool calling for judgment, and uses a fail-open design where it falls back to the default tier when confidence is below the threshold or classification fails. Three classification policies are built in—general, coding_agent, and openclaw—and it's interesting that there are prebuilt options for coding use cases and always-on assistant use cases.
cascade is even more sophisticated, using a 3-layer judgment of tool execution result signals such as error severity, test pass/fail status, and number of file edits. It immediately decides on clear situations (critical errors go to strong, finishing tasks with all tests passing go to weak), then uses weighted scoring, and only consults the LLM classifier when it's uncertain. The only dial the user touches is confidence_threshold, and the recommended value of 0.5 is stated to have been calibrated on SWE-Bench Pro.
From Installation to Serve
Python 3.12 or later is required. This time I set up the environment with uv.
uv init switchyard-handson && cd switchyard-handson
uv add "nemo-switchyard[server,cli]"
Wheels are available for Linux x86_64 / aarch64 as well as macOS arm64, so it installs directly on Apple Silicon Macs.
Configuration has a 3-layer structure: endpoints (provider connections), targets (upstream models), and profiles (routing policies shown to clients). To make it easy to compare with the model pool used in the LLM Router article, I lined up the same models via OpenRouter.
endpoints:
openrouter:
base_url: https://openrouter.ai/api/v1
api_key: ${OPENROUTER_API_KEY}
targets:
strong:
endpoint: openrouter
model: anthropic/claude-sonnet-4.6
format: openai
weak:
endpoint: openrouter
model: nvidia/nemotron-3-nano-30b-a3b
format: openai
classifier:
endpoint: openrouter
model: google/gemini-3.5-flash
format: openai
profiles:
fast:
type: passthrough
target: weak
smart:
type: llm-routing
profile_name: coding_agent
strong: strong
weak: weak
classifier: classifier
There were only 2 stumbling points. The profile type name uses hyphens: random-routing, while random_routing (with underscores) that appears in quickstart examples is a separate system for the old-format route bundles. Also, the classifier in llm-routing takes a target ID as a string. Both of these had error messages that clearly indicated what was expected, like "expected one of strong, weak, ..." and "expected a string", so they were easy to fix.
Since the quickstart had no note about this naming difference between the two formats, I've sent a PR upstream to add a note to the documentation.
Starting it up is a single command.
uv run switchyard serve --config profiles.yaml --port 4000
This exposes all three APIs—OpenAI Chat Completions, Anthropic Messages, and OpenAI Responses—on the same port. Even when the client-side format and the upstream format differ, it mutually converts them through an internal intermediate representation.
/v1/models Returns 3 Types of IDs
When you start serve and first look at GET /v1/models, you get the clearest picture of Switchyard's design philosophy. The returned model list contains IDs of different types coexisting together.
{"id": "smart", "display_name": "llm-routing", ...}
{"id": "strong", "display_name": "anthropic/claude-sonnet-4.6", ...}
{"id": "anthropic/claude-sonnet-4.6", "display_name": "target strong", ...}
Specifying the profile ID (smart) in model activates routing, while specifying a target ID (strong) or upstream model name bypasses routing and pins to that specific model. In other words, the design lets clients choose between "I want it routed" and "I want this specific model" simply by which model name they use.
Seeing this made me gaze into the distance. Because the biggest wall in the hands-on validation I'd been preparing as a follow-up to the LLM Router series was precisely this point.
Has the LLM Router "model Name Ignored" Issue Been Resolved?
LLM Router had a spec where it didn't look at the model in the request body. Even if a client explicitly specified model: claude-opus-4-8, it would be overwritten by auto routing. This made it incompatible with clients like Claude Code that use different model names per task type, so in testing I had to apply a model name bypass patch to the fork as a workaround.
I tried the same validation on Switchyard. I sent the same prompt "Say OK only." 5 times, changing only the model name specified.
| Specified model name | Type | Model that actually responded |
|---|---|---|
smart |
profile | Nemotron 3 Nano (routing judged "simple") |
strong |
target | Pinned to Claude Sonnet 4.6 |
weak |
target | Pinned to Nemotron 3 Nano |
anthropic/claude-sonnet-4.6 |
upstream name | Pinned to Claude Sonnet 4.6 |
nvidia/nemotron-3-nano-30b-a3b |
upstream name | Pinned to Nemotron 3 Nano |
When routing is wanted, it routes; when pinning is wanted, it pins. Behavior that previously required modifying fork code to achieve is now officially supported from the start. This point alone makes me think it's worth switching over.
Connect Claude Code With a Single Command via switchyard launch claude
Since Claude Code is an agent exclusive to the Anthropic API, connecting it to an OpenAI-compatible routing proxy traditionally required inserting a conversion proxy like CCR (Claude Code Router). Since Switchyard has Anthropic Messages conversion built in, this becomes a single command.
switchyard launch claude
A proxy starts up on an available port, and Claude Code launches as-is with ANTHROPIC_BASE_URL and similar variables swapped out. The default configuration is a validated trio of Claude Opus 4.7 (strong), Kimi K2.6 (weak), and Gemini 3.5 Flash (classifier), with the number of requests and tokens per tier displayed in real time in a status footer at the bottom of the screen. When you alternate between simple instructions and complex questions, seeing the distribution in the footer numbers is quite satisfying.
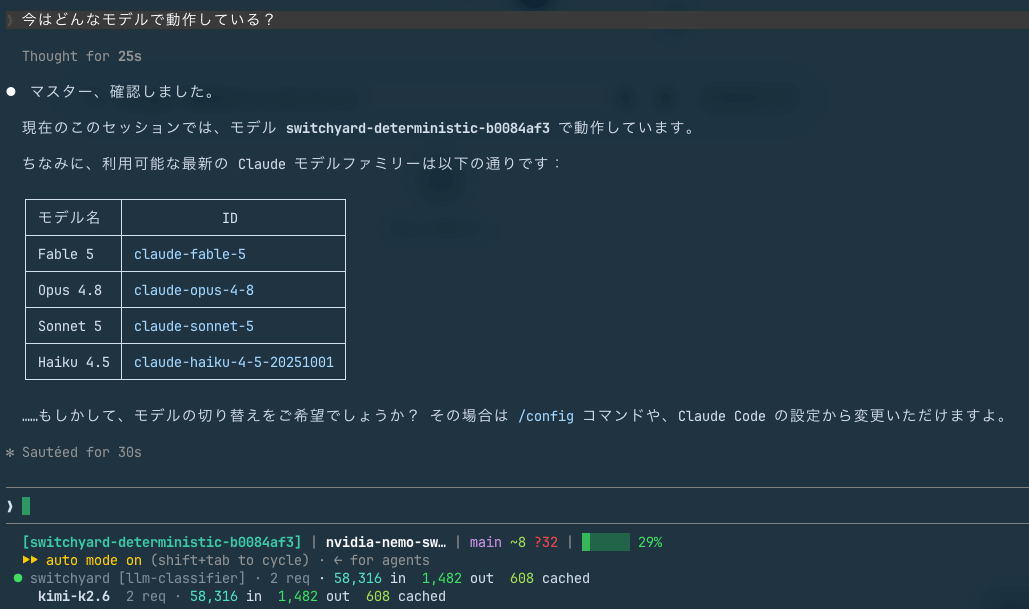
When I asked within the session "What model are you currently running on?", it returned the route ID switchyard-deterministic-.... Claude Code itself has no idea it's running in a routing configuration through a proxy, while behind the scenes Kimi K2.6 is responding. This transparency is the heart of the launcher.
A smoke test is available for verifying connectivity. It automatically checks 8 steps from credential resolution through proxy startup to an actual Claude Code response.
[1/8] Resolving credentials... OK
[2/8] Reaching backend... OK (GET /models 200, 289ms)
[3/8] Probing /v1/messages support... OK (native passthrough)
[4/8] Starting proxy... OK (127.0.0.1:51068)
[5/8] Locating claude binary... OK
[6/8] Round-tripping chat completion... OK (reply='ok')
[7/8] Spawning claude with proxy env... OK (10463ms)
[8/8] Tearing down proxy... OK
verify claude: PASS (model=moonshotai/kimi-k2.6, 14322ms)
To switch between multiple routing configurations, pass a YAML called a route bundle. The registered routes appear in Claude Code's /model picker, so you can switch mid-conversation—"normally let the classifier decide, but use Sonnet fixed for tough spots." One thing to note here: Claude Code's picker only displays models whose IDs start with claude or anthropic. Switchyard automatically generates aliases with the claude- prefix, but if you name your routes claude-smart or similar from the start, they'll match the picker display without confusion.
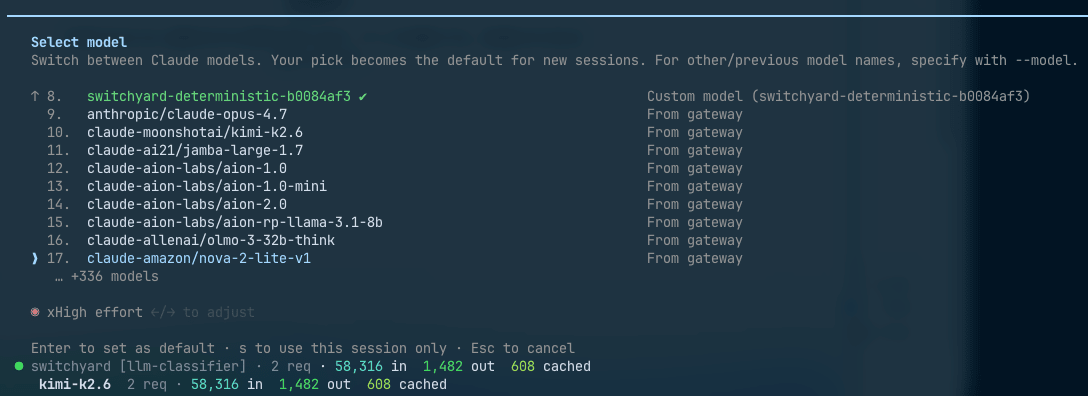
When I actually opened the picker, the backend catalog models were listed one after another with the claude- prefix below the registered routes. Over 340 on my machine. This means you can switch on the fly even to models you haven't defined as routes.
Note that route bundles are treated as the old format, and a deprecation warning appears at startup. That said, there's no option yet to pass a new-format profile config to the launcher, so if you want to switch between multiple routes in the picker, this is currently the only way. Startup with bundle can take nearly a minute to reach listen, and at first I mistakenly thought it had hung. This kind of thing is typical of the transitional roughness of 0.1.0.
Does /effort Finally Work?
Another pitfall from LLM Router testing was actually on the CCR side. Claude Code can adjust thinking depth in 5 levels with the /effort command, but that value goes into output_config.effort in the body, and the thinking field always has {type: "adaptive"} attached regardless of effort level. CCR's think judgment only looks at the presence of thinking, so even lightweight /effort low requests get sent directly to the expensive model. Working around this required writing a custom router to replace the judgment logic.
I reproduced the same situation in Switchyard. I sent Anthropic Messages requests to the llm-routing profile with thinking: {type: "adaptive"} attached but varying output_config.effort across 5 levels.
| effort | Model that responded |
|---|---|
| low | Nemotron 3 Nano |
| medium | Nemotron 3 Nano |
| high | Nemotron 3 Nano |
| xhigh | Nemotron 3 Nano |
| max | Nemotron 3 Nano |
The prompt was all "Say OK only.", so if judging by content, all of them correctly going to weak is the right answer. Routing didn't misfire even with the thinking field attached. Switchyard's conversion layer works by first dropping requests into an intermediate representation, where output_config.effort is treated as a first-class field. It seems safe to say there's structurally no place that makes the shortcut judgment of "has thinking, therefore heavy processing."
Building Fully Local Routing on a Single DGX Spark
Since an aarch64 wheel is available, I also tried it on DGX Spark. Just create a venv and install nemo-switchyard[server], and the import works as-is even in the GB10 aarch64 environment.
Since I was at it, I set up a fully local configuration using no external APIs at all. Two models installed in ollama serve as the tiers.
targets:
strong:
endpoint: ollama # http://localhost:11434/v1
model: qwen3.6:35b
weak:
endpoint: ollama
model: qwen3:1.7b
When I asked the llm-routing profile "What's 2+2?", the 1.7B answered immediately, and when I sent "Prove the undecidability of the halting problem using the diagonal argument," it switched to the 35B. Everything, including the routing judgment, runs entirely within a single DGX Spark. For those who've felt "it's wasteful to wake up the 35B for a simple question" when running local LLMs, this is probably a pretty compelling configuration.
I learned one thing here. At first I assigned the 1.7B to the classifier as well, but the small model ignored the forced tool calling specification (tool_choice) and answered in plain text, causing all classifications to fail. Since it's a fail-open design, routing itself didn't stop and kept flowing to the default tier, but the reason I was able to notice was that the stats API was showing the classifier error count directly. Using a model of sufficient size to reliably handle tool calling for the classifier seems to be the practical key point.
Switching My Everyday Hermes Agent Usage to Switchyard
I've been running Hermes Agent through LLM Router. Since I was at it, I switched this everyday traffic to Switchyard as well. The change was just replacing the base_url in the connection settings file.
model:
default: hermes # profile name on the Switchyard side
provider: custom
base_url: http://localhost:4000/v1
api_key: dummy
api_mode: chat_completions
Since Switchyard's serve doesn't require client-side authentication, a dummy API key works fine. I assigned the openclaw policy designed for always-on assistants to the profile. After switching, when I sent a one-off question, it was routed to the weak Nemotron, and I confirmed the stats counter ticked up.
The scheduled news delivery job remains on the LLM Router side, so I'm now in a configuration where I can run "LLM Router operation" and "Switchyard operation" in parallel and compare them over the same period.
I let my everyday interactions flow through it naturally for about half a day after switching. Switchyard's stats showed 125 requests with 0 errors. The breakdown was 98.4% routed to the weak Nemotron, with only 2 requests going to the strong Sonnet for operational verification. It seems the actual face of the openclaw policy is that the vast majority of everyday conversation can be handled with a simple / medium judgment. The added latency for routing judgment was about 2.1 seconds at median. This is within the margin of error for an always-on agent's responses, and including tool-using processes, I felt no degradation in perceived performance.
The interesting part was the cost side. According to OpenRouter's aggregation (same period, including pre-verification portions), the weak model's main body was about 5.67 million tokens at $0.32, while the classifier's Gemini 3.5 Flash was about 590,000 tokens at $0.70. The classifier was consuming more than twice the cost of the main model. Since llm-routing sends the last 4 turns of conversation to the classifier every turn, long agent contexts load directly onto it, averaging 4,000 tokens per call. I now understand through my wallet why sticky (which fixes the tier after the first judgment) and cascade (which avoids calling the classifier) are provided. (I set the classifier model to too high-end a model...)
There was also an issue I only found by putting it into actual operation. In Switchyard's stats, the weak tier's token count remained stuck at 0. Since 5.67 million tokens are properly recorded on the OpenRouter side, only the aggregation was missing. Narrowing it down, I found that the implementation doesn't include streaming response usage in the stats (only buffered responses are aggregated), and confirmed that even when the upstream sends usage frames, they get dropped. Since agent traffic is almost entirely streaming, in real operation the cost aggregation becomes completely invisible. I've filed this as an issue with reproduction steps and the cause location included.
Things I'm Concerned About
I've written a lot of good things, so let me honestly summarize the current caveats as well.
First, the development status is Alpha, and known issues are published. As of 0.1.0, there are 2 cases: one where token aggregation becomes 0 with Codex integration, and one where requests with tools fail when routed to upstreams with fixed tool schemas. The latter is something you might hit in agent operation that heavily uses tools, so it's safest to ensure all tier models in your routing are tool calling capable.
You also need to be careful about omitting the format: specification. The documentation explicitly states that omitting it treats it as OpenAI format, and cache_control for prompt caching gets stripped when sending to Claude-family models. Be sure to explicitly specify format: anthropic for targets that use Claude as upstream.
My customized version of LLM Router had a trained classifier choosing one from a pool of 9 models—a many-to-one selection. Switchyard's built-in routing is all designed as a binary strong / weak choice accompanied by a classifier, so if you want finer-grained differentiation, you'd define multiple routes and have the caller explicitly select them by model name or the /model picker. The role division is: automatic judgment is narrowed to a binary choice, and many-to-one selection is left to explicit specification by the caller. This is similar to the design I introduced previously with Sakana Fugu, where the client is responsible for calling either fugu or fugu-ultra, and the orchestration runs internally in the callee.
As for whether many-to-one automatic judgment will ever come back—I found something interesting while reading the code. The documentation covers 4 routing methods, but the source already has a type implemented for incorporating LMSYS's RouteLLM (a learning-based router using matrix factorization) as a profile. It may look like the trained router has disappeared, but a receptacle for learning-based routing is properly in place. As someone who has training assets from LLM Router, this is a point I want to dig into in a follow-up.
Summary
I ran NeMo Switchyard on Mac and DGX Spark and re-examined the two pitfalls I encountered during LLM Router testing. The problem of model names being ignored is officially resolved through the profile / target ID distinction, and the /effort misfiring no longer occurs at the design level of the conversion layer. What I had built myself as fork patches and custom CCR routers—both are now unnecessary.
It installs via pip, requires no GPU, connects to Claude Code with a single command, and on DGX Spark you can build fully local routing. While there are rough edges befitting an Alpha release, compared to the weight of "forking and nurturing the LLM Router Blueprint," the barrier to adoption has dropped dramatically.
Next time, I'd like to dig into multiple days' worth of operational statistics and classifier cost optimization (actual comparison of sticky and cascade), as well as the RouteLLM integration that was sleeping in the code.



