
NVIDIA の新しい LLM ルーティング基盤 NeMo Switchyard を試してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
DGX Spark で NVIDIA LLM Router を動かす記事を 2 本公開したばかりなのですが、その直後に「LLM Router のアルゴリズムも取り込んでいく、新しいルーティング基盤が出た」と教えてもらいました。NeMo Switchyard、v0.1.0 のリリースは日本時間の 2026 年 7 月 1 日です。
記事の続きを準備していた身としては少し複雑な気持ちですが、実際に触ってみると「LLM Router で苦労して自作した機能が最初から入っている」ことが次々に分かってきました。この記事では、手元の Mac と DGX Spark で Switchyard を動かし、LLM Router 検証で踏んだ罠が本当に解消されているのかを確かめていきます。
NeMo Switchyard とは何者か
GitHub の NVIDIA-NeMo organization で公開された、LLM トラフィックを振り分ける routing proxy です。pip install nemo-switchyard で入る Python パッケージで、中身は maturin でビルドされた Rust コアに Python がかぶさる二層構成。ライセンスは Apache 2.0、バージョンは 0.1.0 で、開発ステータスには Alpha と明示されています。
ドキュメントサイトも公開されています。
LLM Router との関係については NVIDIA に確認する機会があり、単純な後継ではなく「さまざまなルーティング技術と、それらをホスト・改善するためのインフラを包括する、より正式な製品」という位置づけとの回答をもらいました。LLM Router の Blueprint にあるアルゴリズムも、現在 Switchyard へ移植が進められている最中とのことです。
LLM Router を触ったことがある方向けに、性格の違いを表にしてみます。
| 観点 | LLM Router | NeMo Switchyard |
|---|---|---|
| 配布形態 | Docker Compose(Blueprint、fork 前提) | pip install |
| ルーティング判定 | 訓練済み分類器(要 GPU、要訓練データ) | LLM classifier または tool 実行履歴のヒューリスティクス |
| 対応 API | OpenAI Chat Completions のみ | OpenAI Chat / Anthropic Messages / OpenAI Responses を変換 |
| Claude Code 接続 | CCR などの変換プロキシを別途用意 | switchyard launch claude の 1 コマンド |
| GPU | router の推論に必要 | 不要 |
大きな違いは「訓練済み router がいない」ことと「プロトコル変換を内蔵した」ことの 2 点かなと思います。LLM Router は Qwen の embedding を PCA と MLP に通す独自分類器を訓練する設計でした。Switchyard はそこを LLM への問い合わせや、エージェントの tool 実行履歴から取れるシグナルに置き換えています。GPU が要らなくなったので、Mac でもそのまま動きます。
routing は 4 方式から選ぶ
ドキュメントに載っている routing は 4 方式です。
| 方式 | tier の決め方 | 向いている場面 |
|---|---|---|
| passthrough | 固定 1 モデル | 別名を安定させたいだけのとき |
| random-routing | 指定確率で strong / weak を振り分け | A/B テスト、コスト実験 |
| llm-routing | classifier 用の LLM がリクエスト内容を分類 | 内容に応じた振り分け |
| cascade | tool 実行結果のシグナルで判定し、迷ったときだけ classifier に相談 | コーディングエージェントの長い作業 |
llm-routing は、直近 4 ターンの会話を要約して classifier モデルに渡し、simple / medium / complex / reasoning の 4 カテゴリに分類させてから weak / strong の tier にマップします。判定には tool calling を使い、確信度が閾値を下回ったり分類に失敗したりしたときはデフォルト tier に落ちる fail-open 設計です。分類ポリシーは general、coding_agent、openclaw の 3 種類が組み込まれていて、コーディング向けと常駐アシスタント向けがあらかじめ用意されているのが面白いところですね。
cascade はさらに凝っていて、エラーの深刻度やテストの合否、ファイル編集の回数といった tool 実行結果のシグナルを 3 層で判定します。まず明確な状況(クリティカルなエラーは strong、テスト全通過の仕上げ作業は weak)を即決し、次に重み付きスコアで判断、確信が持てないときだけ LLM classifier に相談する、という段階構成です。ユーザーが触るダイヤルは confidence_threshold の 1 つだけで、推奨値 0.5 は SWE-Bench Pro で較正したと書かれています。
インストールから serve まで
Python 3.12 以降が条件です。今回は uv で環境を作りました。
uv init switchyard-handson && cd switchyard-handson
uv add "nemo-switchyard[server,cli]"
wheel は Linux の x86_64 / aarch64 に加えて macOS の arm64 も用意されているので、Apple Silicon の Mac にそのまま入ります。
設定は endpoints(プロバイダ接続)、targets(upstream のモデル)、profiles(クライアントに見せる routing ポリシー)の 3 層構造です。tier は strong に GLM-5.2、weak に DeepSeek V4 Flash を割り当てました。routing 判定を担う classifier には、weak と同じ target をそのまま参照させています。実はこの classifier のモデル選定で一度手痛い失敗をしていて、いま見えている構成はその反省を織り込んだ 2 代目なのですが、顛末は後半でまとめて紹介します。
endpoints:
openrouter:
base_url: https://openrouter.ai/api/v1
api_key: ${OPENROUTER_API_KEY}
targets:
strong:
endpoint: openrouter
model: z-ai/glm-5.2
format: openai
weak:
endpoint: openrouter
model: deepseek/deepseek-v4-flash
format: openai
profiles:
fast:
type: passthrough
target: weak
smart:
type: llm-routing
profile_name: coding_agent
strong: strong
weak: weak
classifier: weak
つまずいたのは 2 点だけでした。profile の type 名はハイフン区切りの random-routing で、クイックスタートの例に出てくる random_routing(アンダースコア)は旧形式の route bundle 用の別体系です。また llm-routing の classifier には target の ID を文字列で渡します。どちらもエラーメッセージが「expected one of strong, weak, ...」「expected a string」と期待する形を具体的に教えてくれるので、すぐに直せました。なお classifier に weak と同じ ID を渡しているのは手抜きではなく、同じモデルで target を 2 つ定義すると重複登録のエラーになるためです。1 つの target を判定役と応答役の両方から参照する形にします。
この 2 形式の命名差はクイックスタートに注記がなかったので、ドキュメントへの追記を upstream に PR として送っています。
起動は 1 コマンドです。
uv run switchyard serve --config profiles.yaml --port 4000
これで OpenAI Chat Completions、Anthropic Messages、OpenAI Responses の 3 つの API が同じポートに生えます。クライアント側の形式と upstream 側の形式が違っても、内部の中間表現を介して相互変換してくれます。
/v1/models が 3 種類の ID を返す
serve を立てて最初に GET /v1/models を見ると、Switchyard の設計思想が一番よく分かります。返ってくるモデル一覧に、種類の違う ID が同居しています。
{"id": "smart", "display_name": "llm-routing", ...}
{"id": "strong", "display_name": "z-ai/glm-5.2", ...}
{"id": "z-ai/glm-5.2", "display_name": "target strong", ...}
profile の ID(smart)を model に指定すると routing が働き、target の ID(strong)や upstream のモデル名を指定すると routing をスキップしてそのモデルに固定されます。つまり「振り分けてほしいとき」と「このモデルと決め打ちしたいとき」を、クライアントは model 名の使い分けだけで選べる設計です。
これを見て、思わず遠い目になりました。LLM Router 連載の実践編として準備していた検証で、一番の壁がまさにここだったからです。
LLM Router の「model 名無視」は解消されたのか
LLM Router には、リクエスト body の model を見ないという仕様がありました。クライアントが model: claude-opus-4-8 と明示しても auto routing に上書きされてしまうため、Claude Code のようにタスク種別ごとにモデル名を出し分けるクライアントとは相性が悪く、検証では fork にモデル名バイパスのパッチを当てて回避していました。
Switchyard に同じ検証を投げてみます。同一プロンプト「Say OK only.」を、指定する model 名だけ変えて 5 通り送りました。
| 指定した model 名 | 種別 | 実際に応答したモデル |
|---|---|---|
smart |
profile | DeepSeek V4 Flash(routing が「簡単」と判定) |
strong |
target | GLM-5.2 に固定 |
weak |
target | DeepSeek V4 Flash に固定 |
z-ai/glm-5.2 |
upstream 名 | GLM-5.2 に固定 |
deepseek/deepseek-v4-flash |
upstream 名 | DeepSeek V4 Flash に固定 |
routing してほしいときは routing され、固定したいときは固定される。LLM Router では fork のコードに手を入れてようやく実現した挙動が、最初から公式にサポートされています。この一点だけでも、乗り換える価値はあるかなと思っています。
switchyard launch claude で Claude Code を 1 コマンド接続
Claude Code は Anthropic API 専用のエージェントなので、OpenAI 互換の routing proxy と繋ぐには従来 CCR(Claude Code Router)のような変換プロキシを挟む必要がありました。Switchyard は Anthropic Messages の変換を内蔵しているため、これが 1 コマンドになります。
switchyard launch claude
空きポートに proxy が立ち、ANTHROPIC_BASE_URL などを差し替えた Claude Code がそのまま起動します。デフォルトの構成は Claude Opus 4.7(strong)、Kimi K2.6(weak)、Gemini 3.5 Flash(classifier)という検証済みトリオで、画面下部のステータスフッターに tier ごとのリクエスト数とトークン数がリアルタイム表示されます。簡単な指示と重い相談を投げ分けると、フッターの数字で振り分けが見えるのはなかなか爽快ですよ。
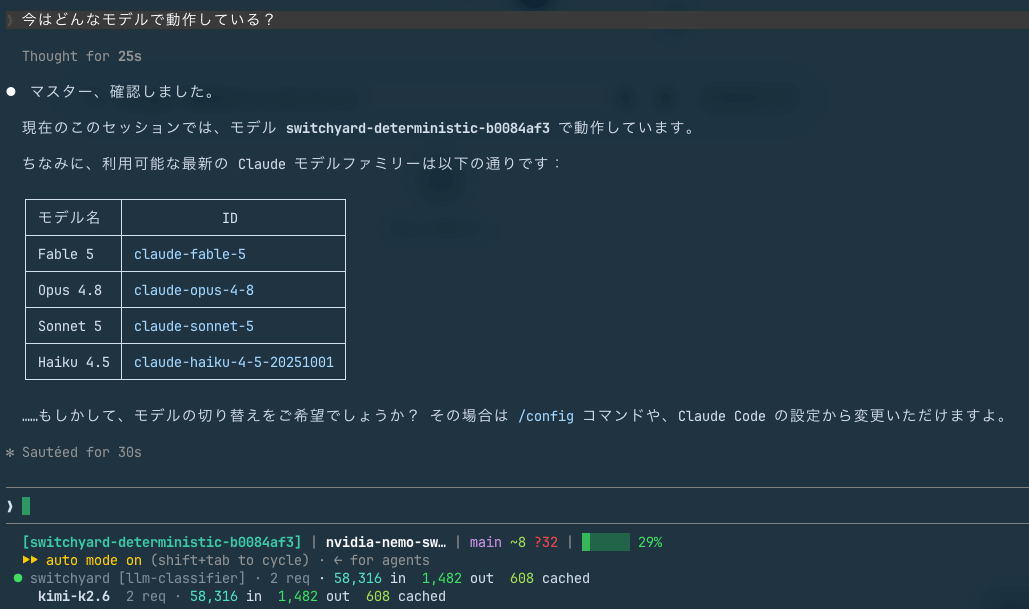
セッション内で「今はどんなモデルで動作している?」と尋ねると、route の ID である switchyard-deterministic-... が返ってきました。Claude Code 本体は自分が proxy 越しの routing 構成で動いていることを知らないまま、裏では Kimi K2.6 が応答している。この透過っぷりが launcher の肝です。
疎通の確認には smoke テストが用意されています。credential の解決から proxy 起動、Claude Code の実応答までを 8 段階で自動チェックしてくれました。
[1/8] Resolving credentials... OK
[2/8] Reaching backend... OK (GET /models 200, 289ms)
[3/8] Probing /v1/messages support... OK (native passthrough)
[4/8] Starting proxy... OK (127.0.0.1:51068)
[5/8] Locating claude binary... OK
[6/8] Round-tripping chat completion... OK (reply='ok')
[7/8] Spawning claude with proxy env... OK (10463ms)
[8/8] Tearing down proxy... OK
verify claude: PASS (model=moonshotai/kimi-k2.6, 14322ms)
複数の routing 構成を切り替えたい場合は、route bundle という YAML を渡します。登録した route は Claude Code の /model ピッカーに並ぶので、「普段は classifier 任せ、難所だけ Sonnet 固定」といった切り替えが会話の途中でできます。ここで 1 つ注意があって、Claude Code のピッカーは ID が claude か anthropic で始まるモデルしか表示しません。Switchyard 側が claude- prefix の別名を自動生成してくれますが、route 名を最初から claude-smart のように付けておくと picker の表示と一致して迷いません。
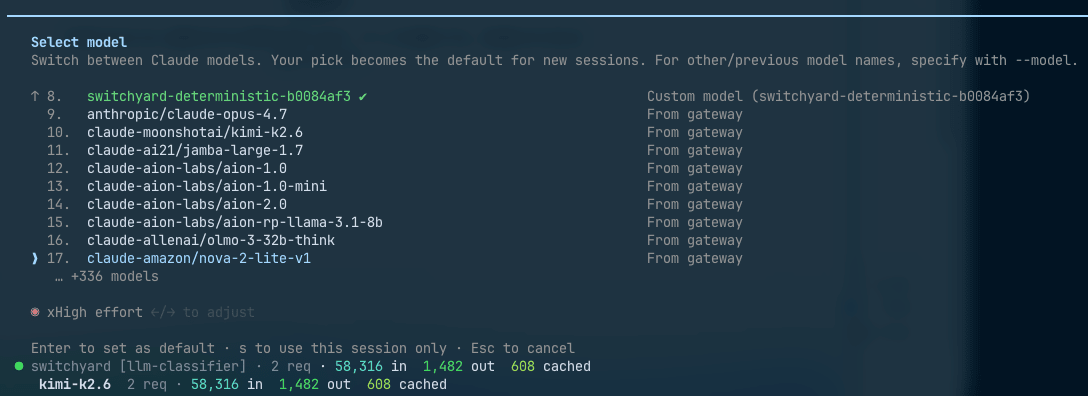
実際にピッカーを開いてみると、登録した route の下に backend カタログのモデルが claude- prefix 付きでずらりと並んでいました。手元では 340 個超え。route として定義していないモデルにも、その場の気分で直接切り替えられるということですね。
なお route bundle は旧形式扱いで、起動時に deprecated の警告が出ます。かといって新形式の profile config を launcher に渡すオプションはまだ無いので、ピッカーで複数 route を切り替えたい場合は現状これが唯一の手段です。bundle 経由の起動は listen まで 1 分近くかかることがあり、自分は最初ハングしたと勘違いしました。このあたりは 0.1.0 らしい過渡期の隙間ですね。
/effort は今度こそ効くのか
LLM Router 検証で踏んだもう 1 つの罠は、実は CCR 側にありました。Claude Code は /effort コマンドで思考の深さを 5 段階に調整できますが、その値は body の output_config.effort に入っていて、thinking フィールドは effort レベルに関係なく常に {type: "adaptive"} が付きます。CCR の think 判定は thinking の存在しか見ないため、/effort low の軽いリクエストまで高価なモデルに直送されてしまう。回避には判定ロジックを差し替えるカスタム router を書く必要がありました。
Switchyard で同じ状況を再現してみます。thinking: {type: "adaptive"} を付けたまま、output_config.effort を 5 段階に変えた Anthropic Messages リクエストを llm-routing の profile に投げました。
| effort | 応答したモデル |
|---|---|
| low | DeepSeek V4 Flash |
| medium | DeepSeek V4 Flash |
| high | DeepSeek V4 Flash |
| xhigh | DeepSeek V4 Flash |
| max | DeepSeek V4 Flash |
プロンプトは全部「Say OK only.」なので、内容で判定すればすべて weak 行きが正解です。thinking フィールドが付いていても routing は暴発しませんでした。Switchyard の変換層はリクエストを一度中間表現に落とす作りで、output_config.effort はそこで第一級のフィールドとして扱われています。「thinking があるから重い処理」という短絡的な判定をする場所が構造的に存在しない、と言えそうです。
DGX Spark 1 台で完全ローカル routing を組む
aarch64 の wheel が出ているので、DGX Spark でも試してみました。venv を作って nemo-switchyard[server] を入れるだけで、GB10 の aarch64 環境でもそのまま import が通ります。
せっかくなので、外部 API を一切使わない完全ローカル構成を組んでみました。ollama に入れた 2 つのモデルを tier に見立てます。
targets:
strong:
endpoint: ollama # http://localhost:11434/v1
model: qwen3.6:35b
weak:
endpoint: ollama
model: qwen3:1.7b
llm-routing の profile に「2+2 は?」と聞くと 1.7B が即答し、「停止性問題が決定不能であることを対角線論法で証明して」と投げると 35B に切り替わりました。routing の判定も含めて全部 DGX Spark 1 台の中で完結しています。ローカル LLM 運用で「軽い質問に 35B を起こすのはもったいない」と感じていた方には、かなり刺さる構成ではないでしょうか。
1 つ学びがありました。最初は classifier にも 1.7B を割り当てたのですが、小さいモデルは tool calling の強制指定(tool_choice)を無視して普通の文章で答えてしまい、分類がすべて失敗しました。fail-open 設計なので routing 自体は止まらずデフォルト tier に流れ続けるのですが、気づけたのは stats API に classifier のエラー数がそのまま出ていたからです。classifier には tool calling を確実にこなせる規模のモデルを充てる、というのが実践上のポイントになりそうです。
Hermes Agent の普段使いを Switchyard に切り替えてみた
手元では Hermes Agent を LLM Router 経由で運用してきました。せっかくなので、この普段使いのトラフィックも Switchyard に切り替えてみます。変更は接続先の設定ファイルで base_url を差し替えるだけでした。
model:
default: hermes # Switchyard 側の profile 名
provider: custom
base_url: http://localhost:4000/v1
api_key: dummy
api_mode: chat_completions
Switchyard の serve はクライアント向けの認証を要求しないので、API キーはダミーで通ります。profile には常駐アシスタント向けの openclaw ポリシーを割り当てました。運用側の profiles.yaml では、あとから見て分かりやすいよう tier 名にモデル名を織り込んでいます。
targets:
weak-ds:
endpoint: openrouter
model: deepseek/deepseek-v4-flash
format: openai
strong-glm:
endpoint: openrouter
model: z-ai/glm-5.2
format: openai
profiles:
hermes:
type: llm-routing
profile_name: openclaw
strong: strong-glm
weak: weak-ds
classifier: weak-ds
fallback_target_on_evict: strong-glm
ここで罠を 1 つ踏みました。llm-routing の fallback_target_on_evict は、省略すると strong という名前の target を探しにいきます。tier 名を strong-glm に変えた途端に起動エラーになったので、規定の strong / weak 以外の tier 名を使うときは明示指定が必要です。
この構成で一晩、約 15 時間ほど日常のトラフィックをそのまま流しました。stats では routing 判定が 56 回、weak 本体への振り分けが 39 回でエラーは 0。期間中の DeepSeek V4 Flash 全体は OpenRouter 実測で 95 リクエスト・約 253 万トークン・$0.25 で、Switchyard 側のカウント(判定 56 回 + weak 本体 39 回 = 95 回)と請求リクエスト数がぴったり一致したのは気持ちよかったですね。strong 側の GLM-5.2 も、tool calling と streaming 込みでエラー 0 で動いています。routing 判定の上乗せは中央値で約 7.2 秒ありますが、Hermes のトラフィックは cron と非同期のメッセージ応答が中心なので実害は出ていません。
あわせて、品質を落としたくない定時配信ジョブは routing を通さず、model 名に strong-glm などの target ID を直接指定する形に寄せました。「振り分けたいときは profile の ID、決め打ちしたいときは target の ID」という記事前半の使い分けが、そのまま運用の道具になってくれています。なお定時実行のニュース配信ジョブは LLM Router 側に残してあるので、同じ期間の「LLM Router 運用」と「Switchyard 運用」を並走させて見比べられる構成です。
もうひとつ、運用に乗せたからこそ見つかった問題があります。OpenRouter 側には 253 万トークンが記録されているのに、Switchyard の stats に載っている weak のトークン数はそのごく一部だけだったのです。切り分けていくと、streaming 応答の usage が stats に載らない(バッファされた応答しか集計されない)実装になっていて、upstream が usage フレームを送ってきていても落ちることまで確認できました。エージェント経由のトラフィックはほぼ streaming なので、実運用ではコスト集計が丸ごと見えなくなります。この件は再現手順と原因箇所を添えて issue として報告しています。
実は classifier の選定を一度間違えていた
白状すると、ここまで見せてきた tier 構成は 2 代目です。最初は LLM Router 記事のモデル pool と比較しやすいように strong を Claude Sonnet 4.6、weak を Nemotron 3 Nano とし、classifier には Gemini 3.5 Flash を立てていました。名前に Flash と付いているから判定役向きの安いモデルだろう、という選定です。
この初代構成で Hermes を半日運用したところ、125 リクエストでエラー 0、98.4% が weak に振られ、routing 判定の上乗せも中央値約 2.1 秒と、挙動は文句なしでした。ところが OpenRouter 側の集計を見ると、weak 本体が約 567 万トークンで $0.32 だったのに対して、classifier の Gemini 3.5 Flash は約 59 万トークンで $0.70。判定役が本体の 2 倍強のコストを使っていました。llm-routing は毎ターン直近 4 ターン分の会話を classifier に送るため、エージェントの長いコンテキストがそのまま載って 1 回あたり平均 4,000 トークン超になります。初回判定で tier を固定する sticky や、classifier を呼ばずに済ませる cascade が用意されている理由を、財布で理解した格好です。
ただ、トラフィック特性だけの問題ではありませんでした。単価表を並べ直すと、モデル選定そのものの誤りだったことが分かります。
| モデル | 入力(/M tokens) | 出力(/M tokens) | reasoning |
|---|---|---|---|
| Gemini 3.5 Flash | $1.50 | $9.00 | 必須(無効化不可)、$9.00 |
| DeepSeek V4 Flash | $0.09 | $0.18 | 任意 |
| GLM-5.2 | $0.93 | $3.00 | 任意 |
Gemini 3.5 Flash は、OpenRouter のモデル情報を見ると reasoning が mandatory、つまり思考を止める手段がないモデルです。当時の stats を確認すると、classifier の completion 32,360 トークンのうち 65% にあたる 21,184 トークンが reasoning でした。「4 カテゴリに分類して tool calling で返す」だけの仕事に、毎回 $9.00/M の思考料を払い続けていたことになります。名前の印象で選んで単価表の確認を省いたのが敗因でした。
悔しいのは、この情報が手元のナレッジベースに既にあったことです。2 週間前の LLM Router 検証では「reasoning モデルを judge にすると思考が止められず判定が重くなる」と記録し、数日前の OCR モデル選定でも「Gemini 3.5 Flash は mandatory reasoning で単純タスクには過剰」とまとめていました。記録していても、設定を書く瞬間に引き出せなければ意味がないですね。耳が痛い学びです。
そこで weak と classifier を DeepSeek V4 Flash の 1 モデル 2 役に統一し、strong を GLM-5.2 に選び直したのが、この記事で使ってきた現行構成です。GLM-5.2 は Artificial Analysis の指標で Sonnet 4.6 と同水準のスコアを出しつつ、単価は入力で約 1/3、出力で 1/5 という位置づけのモデルですね。切り替え前後の判定まわりを並べるとこうなりました。
| 観点 | Gemini 3.5 Flash(切替前) | DeepSeek V4 Flash(切替後) |
|---|---|---|
| 判定 1 回あたりのコスト | $0.0047(OpenRouter 実測) | 約 $0.0004(試算、約 1/12) |
| reasoning トークン | 21,184(completion の 65%) | 0 |
| 判定レイテンシ(p50) | 約 2.1 秒 | 約 7.2 秒 |
| 判定エラー | 0 | 0 |
判定 1 回あたりのコストはおよそ 12 分の 1 です。weak と同一モデルにしたため OpenRouter の請求では判定分を分離できなくなったので、切替後の値は stats のトークン数に公式単価を掛けた試算になります。一晩ぶんの判定 56 回の試算は $0.02 なので、「判定役が本体の 2 倍」だった逆転は「判定役は本体の 1 割」まで是正できました。
ただし、タダでは終わりませんでした。判定レイテンシの中央値が 2.1 秒から 7.2 秒へ、3 倍以上に伸びています。reasoning を捨てたのに遅くなるのは意外でしたが、平均 4,500 トークンのプロンプトを毎回処理する仕事自体は変わらないので、モデルと provider の素の応答速度がそのまま出る格好です。対話型エージェントの前段に置くなら、判定コストと判定レイテンシは別の軸として天秤にかける必要がありそうです。
tier の差し替え自体は YAML 数行の変更と serve の再起動だけで済みました。まず動く構成で運用に乗せて、stats と請求を見ながらモデルを入れ替えていく。この回し方が素直にできるのは、routing proxy が pip ライブラリになった恩恵かなと思います。
気になっているところ
良いところをたくさん書いてきたので、現時点の注意点も正直にまとめておきます。
まず開発ステータスが Alpha で、known issues も公開されています。0.1.0 時点では Codex 連携でトークン集計が 0 になるケースと、tool 付きリクエストが固定 tool スキーマの upstream に振られると失敗するケースの 2 件です。後者は tool を多用するエージェント運用では踏み得るので、routing 先の tier をすべて tool calling 対応モデルで揃えておくのが無難だと思います。
format: の指定漏れにも注意が必要です。省略すると OpenAI 形式として扱われ、Claude 系モデルに送るときに prompt caching 用の cache_control が剥がれるとドキュメントに明記されています。Claude を upstream にする target には format: anthropic を明示しておきましょう。
LLM Router の自分色バージョンは、9 モデルの pool から訓練済み分類器が 1 つを選ぶ多者択一でした。Switchyard の組み込み routing はどれも strong / weak の二者択一に classifier を添える設計なので、それ以上の使い分けをしたければ route を複数定義して、呼び出し側が model 名や /model ピッカーで明示的に選ぶことになります。自動判定は 2 択に絞り、多者択一は呼び出し側の明示指定に任せる、という役割分担です。これは以前紹介した Sakana Fugu で、fugu と fugu-ultra のどちらを呼ぶかはクライアント側の責任とし、呼んだ先の内部でオーケストレーションが動く、という構成と似た考え方ですね。
では多者択一の自動判定はもう戻ってこないのかというと、コードを読んでいて面白い発見がありました。ドキュメントに載っている routing は 4 方式ですが、ソースには LMSYS の RouteLLM(行列分解ベースの学習型 router)を profile として組み込む型がすでに実装されています。訓練済み router が消えたように見えて、学習型の受け皿はちゃんと用意されている。「LLM Router のアルゴリズムは Switchyard へ移植中」という NVIDIA の回答とも符合する動きですね。LLM Router の訓練資産を持っている身としては、ここは続編で掘りたいポイントです。
まとめ
NeMo Switchyard を Mac と DGX Spark で動かし、LLM Router 検証で踏んだ 2 つの罠を再検証しました。model 名が無視される問題は profile / target の ID 使い分けとして公式に解決され、/effort の暴発は変換層の設計レベルで発生しなくなっています。fork へのパッチや CCR のカスタム router として自作していたものが、どちらも不要になりました。
pip で入って GPU も不要、Claude Code とは 1 コマンドで繋がり、DGX Spark 上なら完全ローカルの routing も組める。Alpha 版らしい荒削りな部分はあるものの、LLM Router の「Blueprint を fork して育てる」重さから考えると、導入の敷居は劇的に下がった印象です。
classifier のコストは、モデルの選び直しで約 12 分の 1 になりました。次回は、判定の回数そのものを減らす sticky と cascade の実測比較、そしてコードに眠っていた RouteLLM 統合まわりを掘っていきたいところです。








