
I tried to understand NIST AI RMF (AI Risk Management Framework)
This page has been translated by machine translation. View original
Hello, I'm Arahira (@eiraces) from the Consulting Division of the Cloud Business Unit.
In discussions about generative AI governance and risk, I've started to occasionally see the term "AI RMF." I understood it to be a framework for using AI safely, but I wondered what exactly it contained — so I decided to write this up to organize my own understanding.
Let's take a look at NIST AI RMF. I hope you'll also read the original text and the Japanese translation (below).
What is NIST AI RMF?
NIST AI RMF (AI Risk Management Framework) is, in a single phrase, guidance for risk management aimed at building "trustworthiness" into AI systems. NIST published "AI RMF 1.0" on January 26, 2023, as a document called NIST AI 100-1.
The key point is that this is voluntary, not mandatory, guidance. It is not something that laws require you to follow; rather, it is positioned as a set of tools for organizations to voluntarily confront AI risks.
What can be confusing here is that in the security world, there is a separately existing NIST SP 800-37 (Risk Management Framework for information systems) that shares the same abbreviation "RMF."
The names look very similar, but the contents are different — this AI RMF is specifically focused on AI. The author initially mistook them for the same thing just by looking at the names.
Another characteristic feature is that the risks it targets span a broad range covering "individuals, organizations, and society," with AI's potential impact on people also within scope.
Incidentally, translations into Japanese and other languages exist, so if the English original is difficult, please refer to a translated version. Having Claude or similar tools read it for comprehension purposes is also a good idea.
The 7 Characteristics of "Trustworthy AI"
The foundation of AI RMF is the definition of what trustworthy AI looks like. In AI RMF 1.0, this is organized into 7 characteristics.
| Characteristic | In plain terms |
|---|---|
| Valid & Reliable | Does it work as intended? |
| Safe | Does it avoid harming people or the environment? |
| Secure & Resilient | Can it withstand attacks and recover? |
| Accountable & Transparent | Who is responsible and is the process visible? |
| Explainable & Interpretable | Can the reason behind its output be explained? |
| Privacy-Enhanced | Does it protect personal information? |
| Fair with harmful bias managed | Does it avoid treating anyone unfairly due to bias? |
It feels distinctly AI-specific that not only accuracy (Valid & Reliable) but also fairness, privacy, and explainability are treated side by side as "components of trust."
NIST notes that these characteristics can trade off against each other, and rather than maximizing all of them simultaneously, the intent is to balance them according to context. (Addressing AI trustworthiness characteristics individually will not ensure AI system trustworthiness; tradeoffs are usually involved, rarely do all characteristics apply in every setting, and some will be more or less important in any given situation.)
The 4 Core Functions (Govern / Map / Measure / Manage)
On top of that, the mechanism for actually running risk management consists of 4 core functions. Whereas SP 800-37 Rev.2 uses 7 steps (Prepare, Categorize, Select, Implement, Assess, Authorize, Monitor), AI RMF expresses this through these 4 functions.
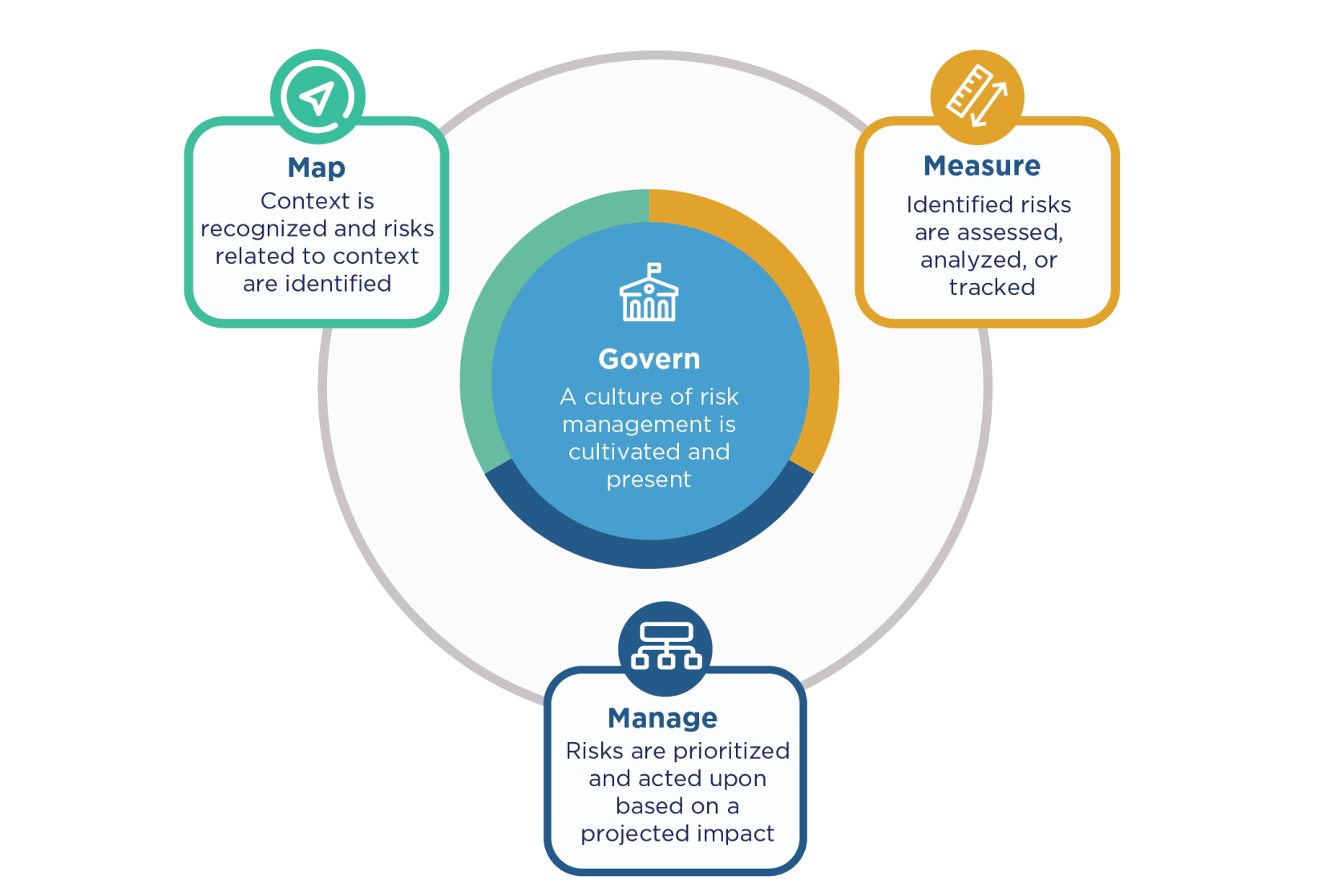
Source: AI RMF 1.0 Fig.5 (https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf)
For reference, let's think about each of the 4 functions by applying them to the example of "building and releasing an AI chatbot for internal inquiry handling." The system itself can be anything — just picture an AI application developed in-house.
Govern
This is a cross-cutting function spanning the entire organization, serving as the foundation on which the other three (Map / Measure / Manage) rest. It is essentially the command center that establishes the culture, policies, role assignments, and accountability for AI risk management across the organization.
While the other 3 functions primarily address individual AI systems, Govern alone covers the entire organization.
◆ GOVERN Functions
| Category | Overview |
|---|---|
| GOVERN 1 | Organization-wide policies, processes, procedures, and practices for mapping, measuring, and managing AI risks are in place, transparent, and effectively implemented. |
| GOVERN 2 | An accountability structure is in place to empower appropriate teams and individuals, clarify responsibilities, and provide training for identifying, measuring, and managing AI risks. |
| GOVERN 3 | Processes related to workforce diversity, equity, inclusion, and accessibility (DEIA) are prioritized when identifying, measuring, and managing risks throughout the AI lifecycle. |
| GOVERN 4 | Organizational teams are working to cultivate a culture that considers and shares AI risks. |
| GOVERN 5 | Structures are in place for robust engagement with relevant AI stakeholders. |
| GOVERN 6 | Policies and procedures are in place to address AI risks and benefits arising from third-party software, data, and other supply chain factors. |
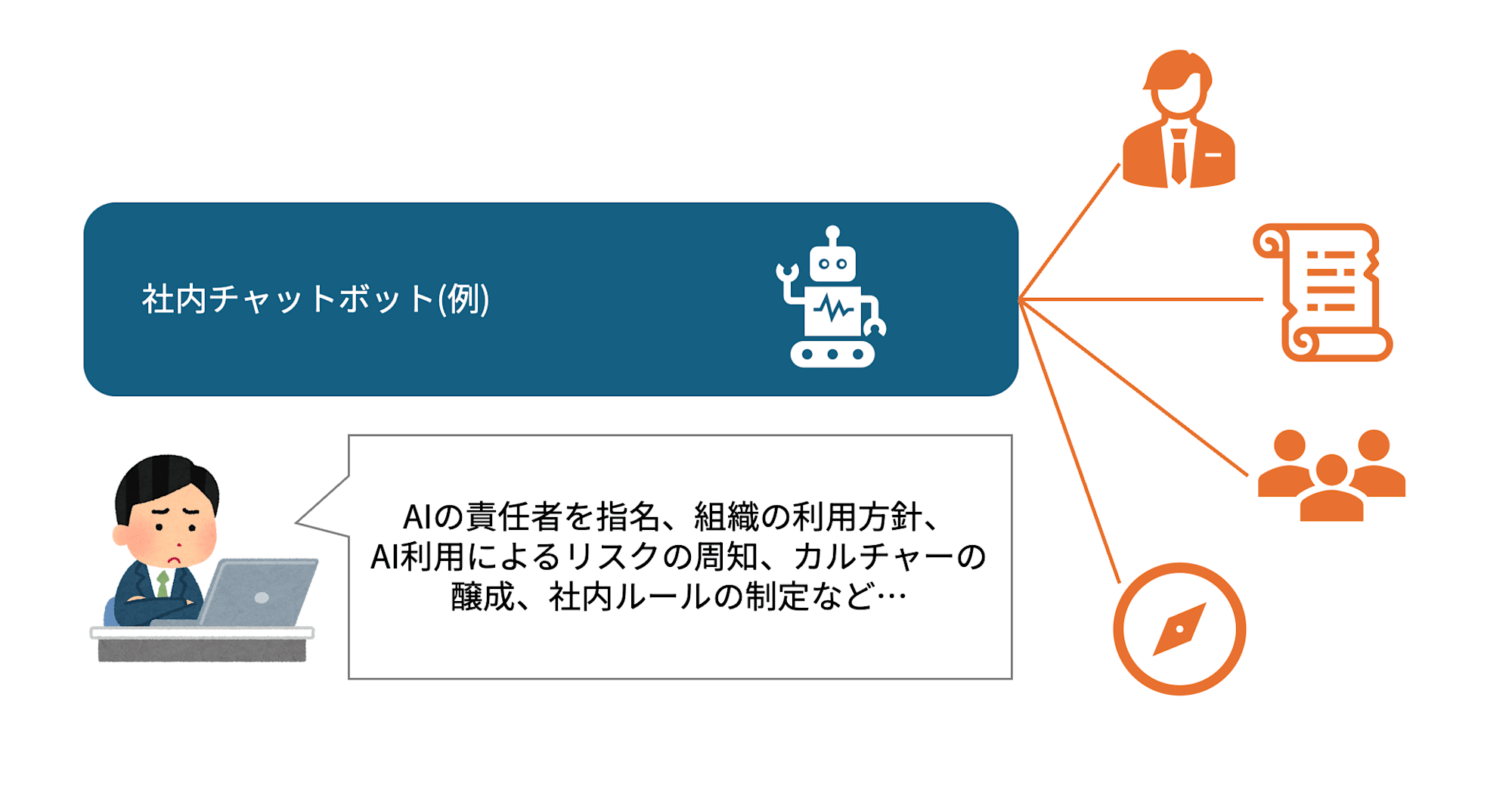
◆ Applying to the Internal AI Chatbot Example
This is where the rules for "how our company handles AI" are created. For example, defining internal policies such as "don't include customer personal information in prompts" or "always have a human reviewer for AI responses," and appointing someone responsible for AI risk. Rather than being a discussion of specific technology, this is the layer that determines the company's stance on how it engages with AI.
The discussion here is about the foundation and organizational approach, not the inner workings of the chatbot.
Map
This function identifies the context and risks surrounding a target AI system. It organizes what the system is used for (intended use), who is involved (stakeholders), what stage of the lifecycle it is at, and which trustworthiness characteristics are relevant.
Without drawing this overall picture first, the subsequent measurement and response (risk management) can become difficult.
◆ MAP Functions
| Category | Overview |
|---|---|
| MAP 1 | Context is established and understood. |
| MAP 2 | Classification of the AI system has been performed. |
| MAP 3 | The AI's capabilities, targeted use cases, goals, and expected benefits and costs compared to appropriate benchmarks are understood. |
| MAP 4 | Risks and benefits for all components of the AI system, including third-party software and data, are organized and identified. |
| MAP 5 | Impacts on individuals, groups, communities, organizations, and society as a whole are characterized. |
◆ Applying to the Internal AI Chatbot Example
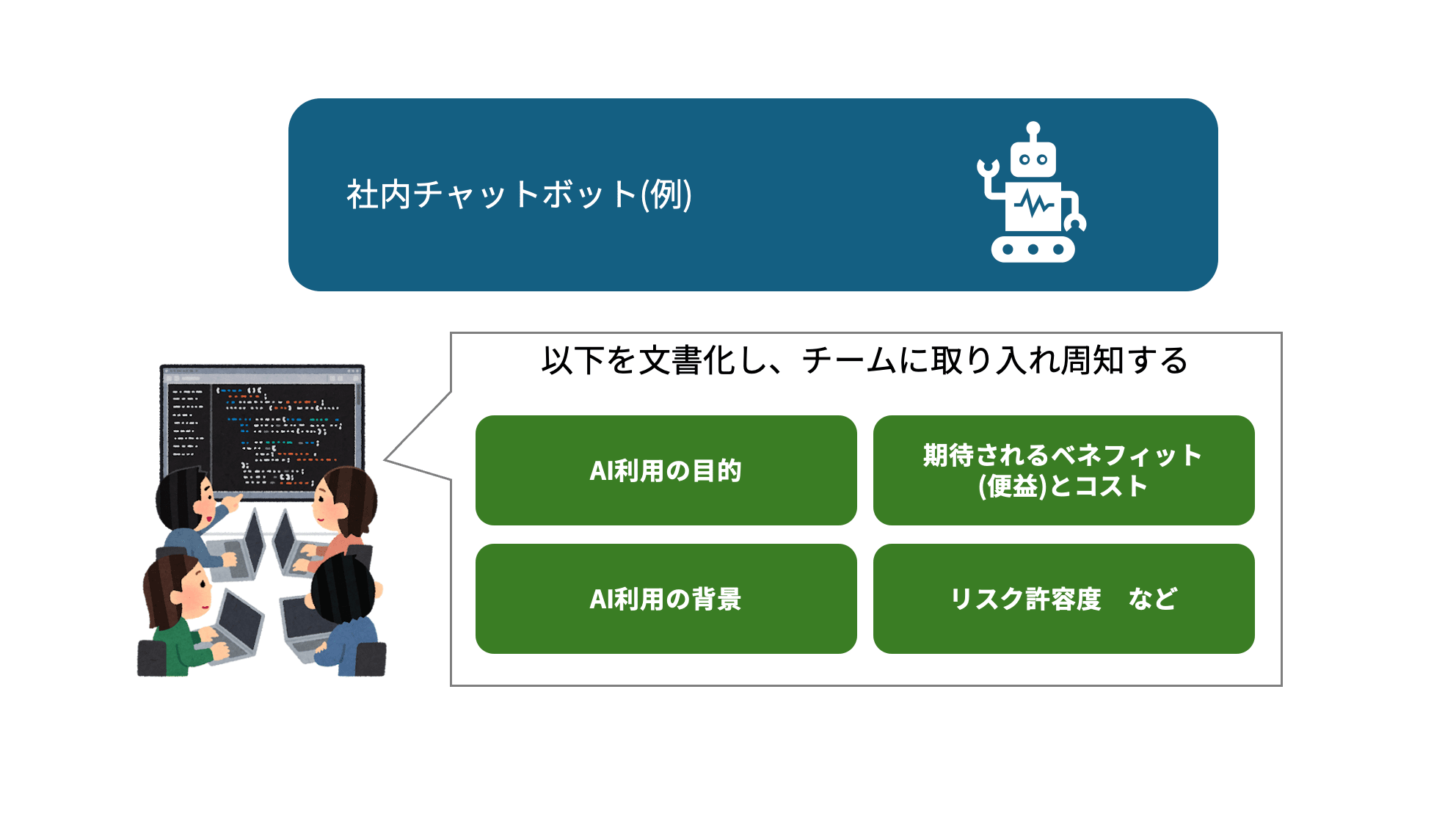
This is the process of specifically writing out "what risks does this bot carry?" For example — users suffering losses due to incorrect answers (Valid & Reliable), being manipulated into revealing confidential information (Secure), providing biased answers based on certain attributes (Fair), and so on.
At the same time, intended use cases and stakeholders are organized, such as "is it only for internal employees, or will external customers also use it?" This is the mapmaking work of identifying where risks lurk, and sharing that awareness among stakeholders reduces overall risk.
After completing the MAP function, an initial go/no-go decision is made on whether to design, develop, or deploy the AI system. Even when proceeding, the MAP function needs to be applied continuously, as the AI system's context, capabilities, risks, benefits, and potential impacts change over time.
Measure
This function analyzes and tracks the risks identified through MAP using both quantitative and qualitative approaches. It evaluates the AI's performance and impact, and assesses how well the trustworthiness characteristics are being met.
In addition to evaluating the AI model itself, it is necessary to be able to monitor various metrics, including organizational usage patterns, error rates, and security and resilience assessments.
◆ MEASURE Functions
| Category | Overview |
|---|---|
| MEASURE 1 | Appropriate methods and metrics are identified and applied. |
| MEASURE 2 | AI systems are evaluated for whether they possess trustworthy characteristics. |
| MEASURE 3 | Mechanisms are in place to track identified AI risks over time. |
| MEASURE 4 | Feedback on the effectiveness of measurements is collected and evaluated. |
◆ Applying to the Internal AI Chatbot Example
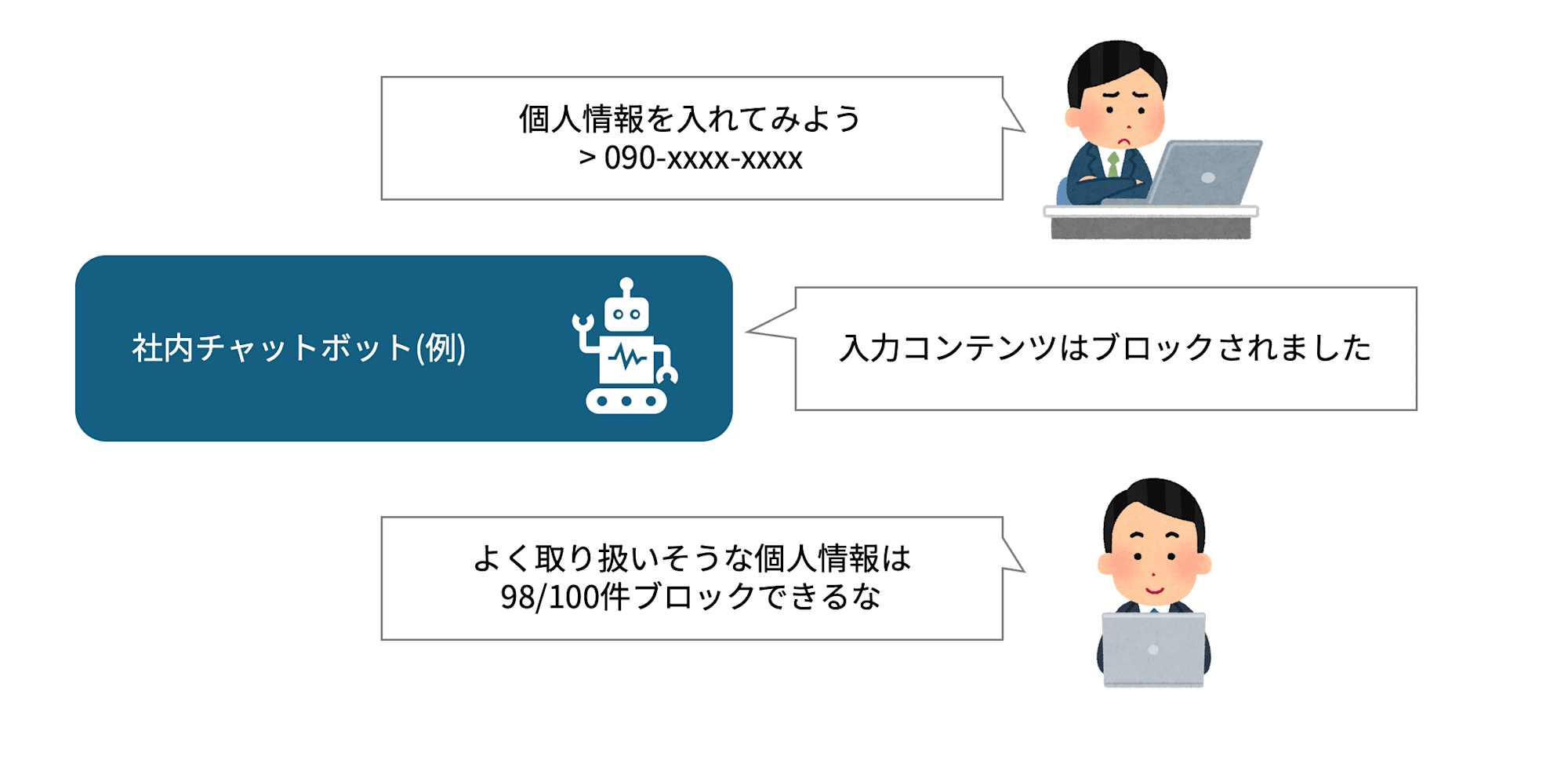
This is the process of actually measuring the risks identified in Map. For example, submitting 100 test questions and calculating the incorrect response rate, attempting adversarial inputs (prompt injection) to see how many get through, and checking for response bias by attribute category. The idea is to express a vague concern like "I'm worried about hallucinations" in concrete numbers like "incorrect information appeared in 7 out of 100 test cases."
Manage
Based on the measurement results, this function allocates resources for responding to risks. It prioritizes and addresses risks, records remaining risks (residual risks), and responds when incidents occur.
Because it is impossible to achieve zero risk, the key point is to leave the decision-making of "how much to accept and how to prepare for it" on record.
◆ MANAGE Functions
| Category | Overview |
|---|---|
| MANAGE 1 | AI risks are prioritized, addressed, and managed based on assessments and other analysis results obtained from the MAP and MEASURE functions. |
| MANAGE 2 | Strategies to maximize AI benefits and minimize negative impacts are planned, prepared, implemented, and documented, with input from relevant AI actors (people, organizations, systems) reflected in them. |
| MANAGE 3 | AI risks and benefits from third-party organizations are managed. |
| MANAGE 4 | Risk countermeasures and communication plans, including response and recovery for identified and measured AI risks, are documented and regularly monitored. |
◆ Applying to the Internal AI Chatbot Example
This is the process of responding to the risks exposed by MAP and MEASURE.
After implementing guardrails for responses with high incorrect answer rates, preventing confidential data from being referenced in the first place to avoid leakage of proprietary information, and so on — the remaining risk of "occasionally getting things wrong" is accepted and recorded in the form of "displaying a message on screen saying 'This is an AI response; please confirm with a person in charge for final decisions.'" Incident response for when problems arise after launch is also included here.
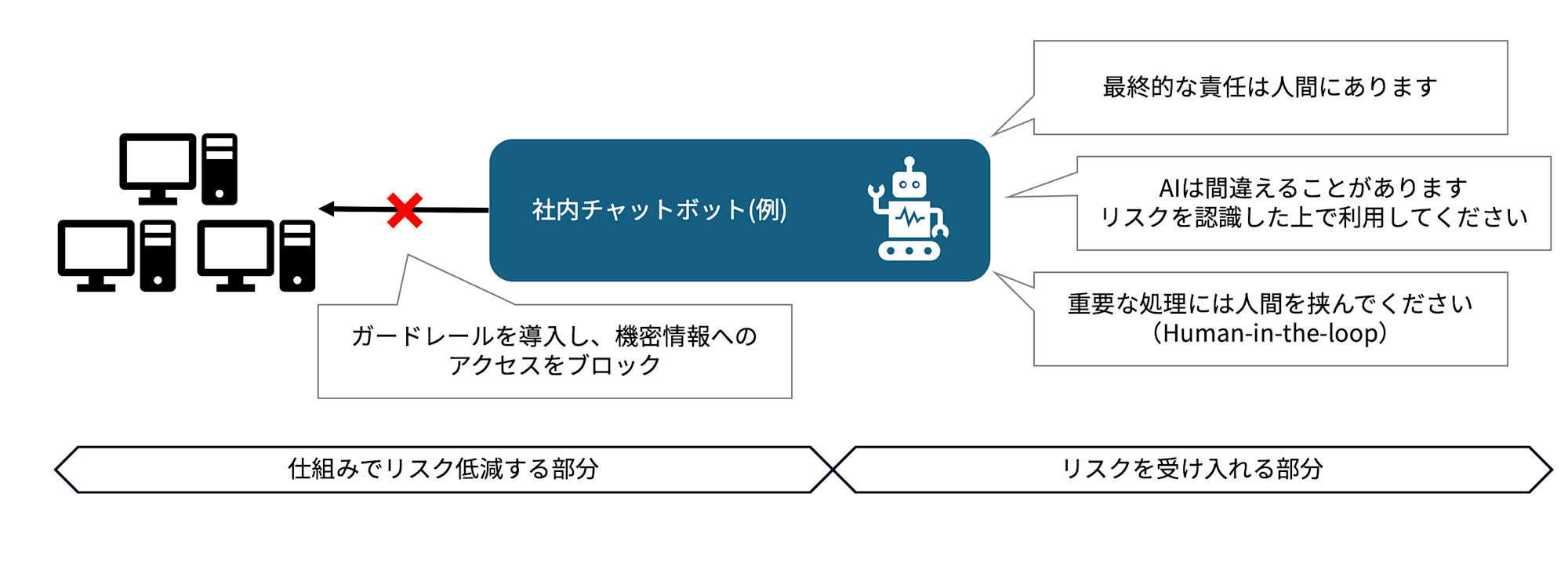
While the ideal is to systematize everything and manage risks, I feel strongly that educating AI users is also critically important.
The quantity, quality, and nature of risk vary depending on the relevant AI actors (people, organizations, systems), but I believe the ideal is to fundamentally aim for a state where those risks are recognized, addressed, and managed.
Note that these 4 functions are not something to be performed once and finished — they are meant to be continuously cycled through the entire AI lifecycle.
A chatbot doesn't end at launch either; as usage patterns change, new risks emerge, so this framework needs to be used with the premise of continuously cycling through Map → Measure → Manage.
(Reference) Relationship with NIST RMF (SP 800-37)
I touched on this briefly at the beginning, but let me organize it again here. Even sharing the same abbreviation "RMF," NIST RMF for information systems (SP 800-37) and AI RMF (NIST AI 100-1) are separate documents. They are often confused because the names look so similar, but they differ in origin and structure.
| NIST RMF (SP 800-37) | NIST AI RMF (AI 100-1) | |
|---|---|---|
| Target | Security and privacy for information systems in general | Trustworthiness of AI systems |
| Structure | 7 steps (Prepare to Monitor) | 4 functions (Govern / Map / Measure / Manage) |
| Nature | Effectively mandatory for the federal government (based on FISMA/OMB A-130) | Voluntary guidance |
| Goal | Issue an Authorization to Operate (ATO) | Manage AI-specific risks and enhance trustworthiness |
| Main risk perspectives | Confidentiality, Integrity, Availability (CIA) | Also includes fairness, explainability, safety, etc. |
These 2 documents are apparently not "choose one or the other" but rather complementary. Since an AI system is also essentially one type of information system, the idea is to layer them: covering the underlying infrastructure and data protection with the traditional RMF (SP 800-37), while adding AI-specific risks (bias, hallucination, explainability, etc.) on top with AI RMF.
Note that while AI RMF 1.0 is the framework itself, supplementary materials are also available for actually using it. (I won't go into those here.)
· AI RMF Playbook: A collection of actions on how to practically implement each function
· Generative AI Profile (NIST AI 600-1): A profile focused on risks specific to generative AI
(Reference) Relationship with OWASP Top 10 for LLM Applications
AI RMF 1.0 presents risk classification and examples in Appendix B from the perspective of "harm to individuals, organizations, society, and ecosystems." However, this is closer to a "framework for understanding risk" and does not go into enough specificity to be directly applicable to LLM application implementation.
That's where OWASP Top 10 for LLM Applications 2025 comes in. It is a list of LLM application-specific risks identified by name, such as prompt injection and sensitive information disclosure, with the following lineup (as of the 2025 version at time of writing).
| ID | Risk |
|---|---|
| LLM01 | Prompt Injection |
| LLM02 | Sensitive Information Disclosure |
| LLM03 | Supply Chain |
| LLM04 | Data and Model Poisoning |
| LLM05 | Improper Output Handling |
| LLM06 | Excessive Agency |
| LLM07 | System Prompt Leakage |
| LLM08 | Vector and Embedding Weaknesses |
| LLM09 | Misinformation |
| LLM10 | Unbounded Consumption |
The countermeasures for each have been written up previously by Takakuni, as noted below.
The author had originally been using this OWASP Top 10 as a baseline for identifying risks, but when placed alongside AI RMF, the framing of "AI RMF as the 'mold' and OWASP as the 'content'" seems to work well.
※ Note that OWASP Top 10 for LLM is a "catalog of risks and vulnerabilities," so it does not cover everything.
In the chatbot example from earlier, during the Map stage,
"LLM01: Prompt Injection → risk of crafted inputs causing the bot to malfunction"
"LLM02: Sensitive Information Disclosure → risk of the bot revealing proprietary information"
"LLM09: Misinformation → risk of users suffering losses due to incorrect answers"
can be organized by linking vague concerns to OWASP item numbers.
This allows the conversation to move into specifics such as Measure test items, giving the framework a much more tangible feel.
Closing
This entry was intended to help me understand NIST AI RMF in my own way. I suspect there are many companies that have moved ahead with AI adoption but haven't yet addressed governance or fully sorted out their risks.
Organizing things according to frameworks like this may surface issues that need to be addressed, so I hope you'll read the original text and its translation. (If you notice anything, please feel free to leave a comment.)
I hope this entry is helpful to someone.
This has been Arahira from the Consulting Division of the Cloud Business Unit!
References