
NIST AI RMF(AIリスク管理フレームワーク)について理解しようとしてみた
こんにちは、クラウド事業本部 コンサルティング部の荒平(@eiraces)です。
生成AIのガバナンスやリスクの話題で、たまに「AI RMF」という言葉を見かけるようになりました。AIを安全に使うためのフレームワーク、ということは分かりますが、どういった内容なんだっけ?となったので、自分の理解を整理するためにまとめてみることにしました。
さっそく『NIST AI RMF』について見ていきましょう。是非、原文や日本語訳(下記)もお読み頂けますと幸いです。
NIST AI RMFとは
NIST AI RMF(AI Risk Management Framework)は、一言で表すとAIシステムに「信頼性(trustworthiness)」を組み込むための、リスク管理のガイダンスです。NISTが NIST AI 100-1 という文書として、2023年1月26日に「AI RMF 1.0」を公開しました。
ポイントは、これが強制ではなく任意(voluntary)のガイダンスだということです。法律で「従いなさい」というものではなく、組織が自主的にAIのリスクと向き合うための道具立て、という位置づけですね。
ここで紛らわしいのが、セキュリティの世界には同じ「RMF」という略語の NIST SP 800-37(情報システム向けのRisk Management Framework) が別に存在することです。
名前はそっくりですが中身は別物で、こちらの AI RMF はAIに特化したものになります。筆者も最初、名前だけ見て同じものかと勘違いしていました。
対象とするリスクも「個人・組織・社会」と幅広く取っているのが特徴で、AIが誰かに与えうる影響まで視野に入れているんですね。
ちなみに日本語版などの各国語訳も存在するので、英語の原文がつらい場合は翻訳版を参照してください。理解のためにClaudeなどに読ませるのもいいと思います。
「信頼できるAI」の7つの特性
AI RMFの土台になっているのが、信頼できるAIとは何かという定義です。AI RMF 1.0では、これを7つの特性で整理しています。
| 特性 | ざっくり言うと |
|---|---|
| Valid & Reliable(妥当・信頼できる) | ちゃんと意図通りに動くか |
| Safe(安全) | 人や環境に危害を加えないか |
| Secure & Resilient(セキュア・回復力がある) | 攻撃に耐え、立ち直れるか |
| Accountable & Transparent(説明責任・透明) | 誰が責任を持ち、過程が見えるか |
| Explainable & Interpretable(説明可能・解釈可能) | なぜその出力なのか説明できるか |
| Privacy-Enhanced(プライバシー強化) | 個人情報を守れるか |
| Fair with harmful bias managed(公平・有害バイアス管理) | 偏りで誰かを不当に扱わないか |
精度(Valid & Reliable)だけでなく、公平性やプライバシー、説明可能性まで横並びで「信頼の構成要素」として扱っているのが、AIならではと感じます。
なおNISTは、これらの特性は互いにトレードオフしうるとしており、全部を同時に最大化するというより、文脈に応じてバランスを取るものとされています。(Addressing AI trustworthiness characteristics individually will not ensure AI system trustworthiness; tradeoffs are usually involved, rarely do all characteristics apply in every setting, and some will be more or less important in any given situation. )
4つのコア機能(Govern / Map / Measure / Manage)
そのうえで、リスク管理を実際に回していくための仕組みが、4つのコア機能です。SP 800-37 Rev.2 の方が7ステップ(準備・分類・選択・実装・アセスメント・認可・監視)だったのに対して、AI RMFはこの4つで表現されます。
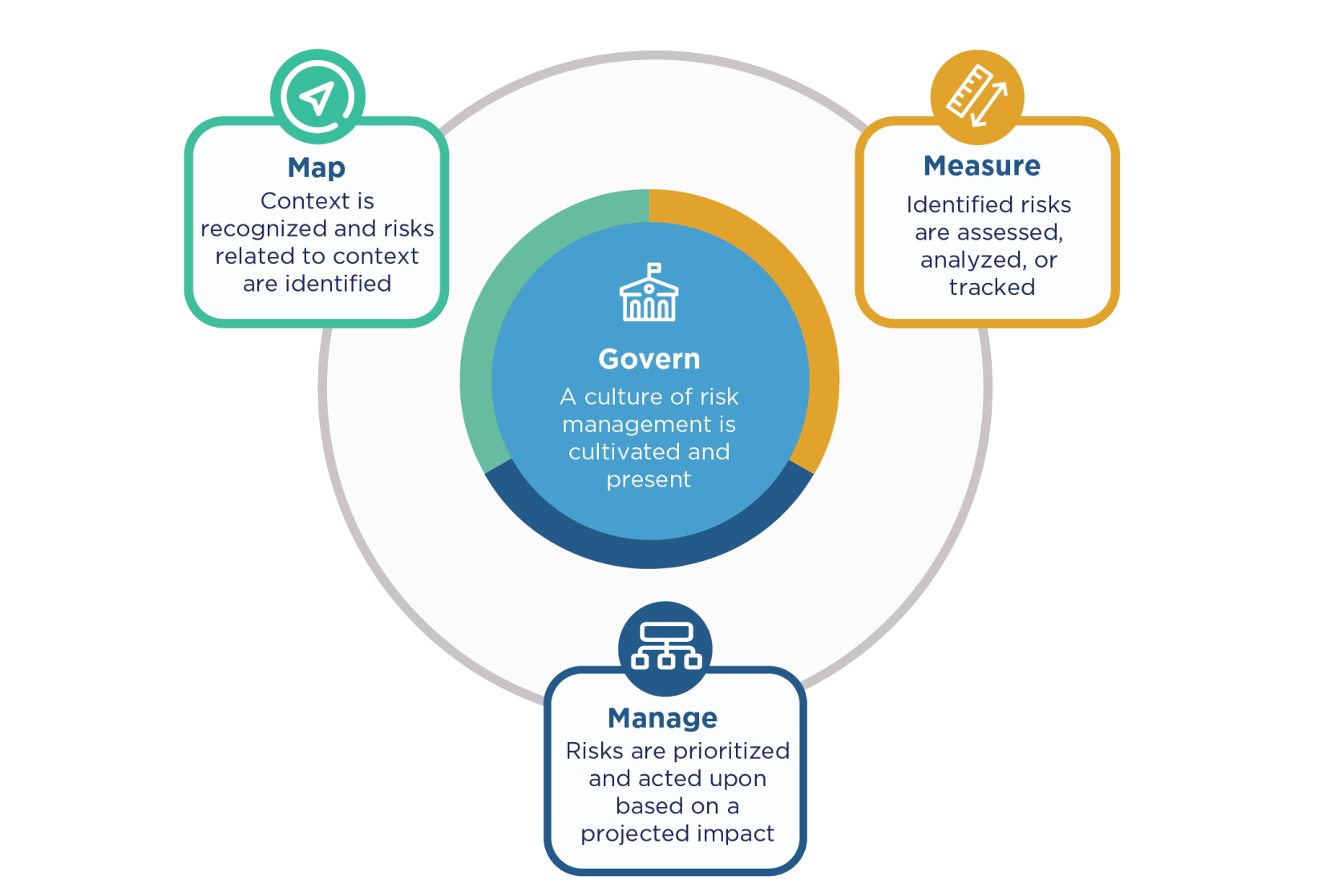
引用元:AI RMF 1.0 Fig.5 (https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf)
また、参考までに、「社内問い合わせ対応にAIチャットボットを作って公開する」という例えを、4機能それぞれに当てはめながら考えてみます。システム自体は何でもいいので、自社開発のAIアプリケーションを思い浮かべてください。
Govern(統治)
組織全体にまたがる横断的な機能で、ほかの3つ(Map / Measure / Manage)の上に乗っかる土台です。AIのリスク管理に関する文化・方針・役割分担・説明責任を組織として整える、いわば司令塔です。
ほかの3機能が主に個別のAIシステムに向き合うのに対して、Governだけは組織全体をカバーしているのが特徴です。
◆ GOVERN 機能
| カテゴリー | 概要 |
|---|---|
| GOVERN 1 | AIリスクのマッピング、測定、管理に関する組織横断的なポリシー、プロセス、手順、および慣行が整備されており、それらは透明性が確保され、かつ効果的に実施されています。 |
| GOVERN 2 | AIリスクの特定、測定、管理に向けた適切なチームや個人の権限付与、責任の明確化、および教育を行うためのアカウンタビリティ(説明責任)体制が整備されています。 |
| GOVERN 3 | AIのライフサイクル全体を通じてリスクを特定・測定・管理する際、労働力の多様性、公平性、包摂性、およびアクセシビリティ(DEIA)に関するプロセスを優先的に考慮します。 |
| GOVERN 4 | 組織のチームは、AIのリスクを考慮し、それを共有する文化の醸成に取り組んでいます。 |
| GOVERN 5 | 関連するAIステークホルダーと強固に関与するための体制が整っています。 |
| GOVERN 6 | サードパーティ製のソフトウェアやデータ、その他サプライチェーンに起因するAIのリスクやメリットに対処するためのポリシーと手順が整備されています。 |
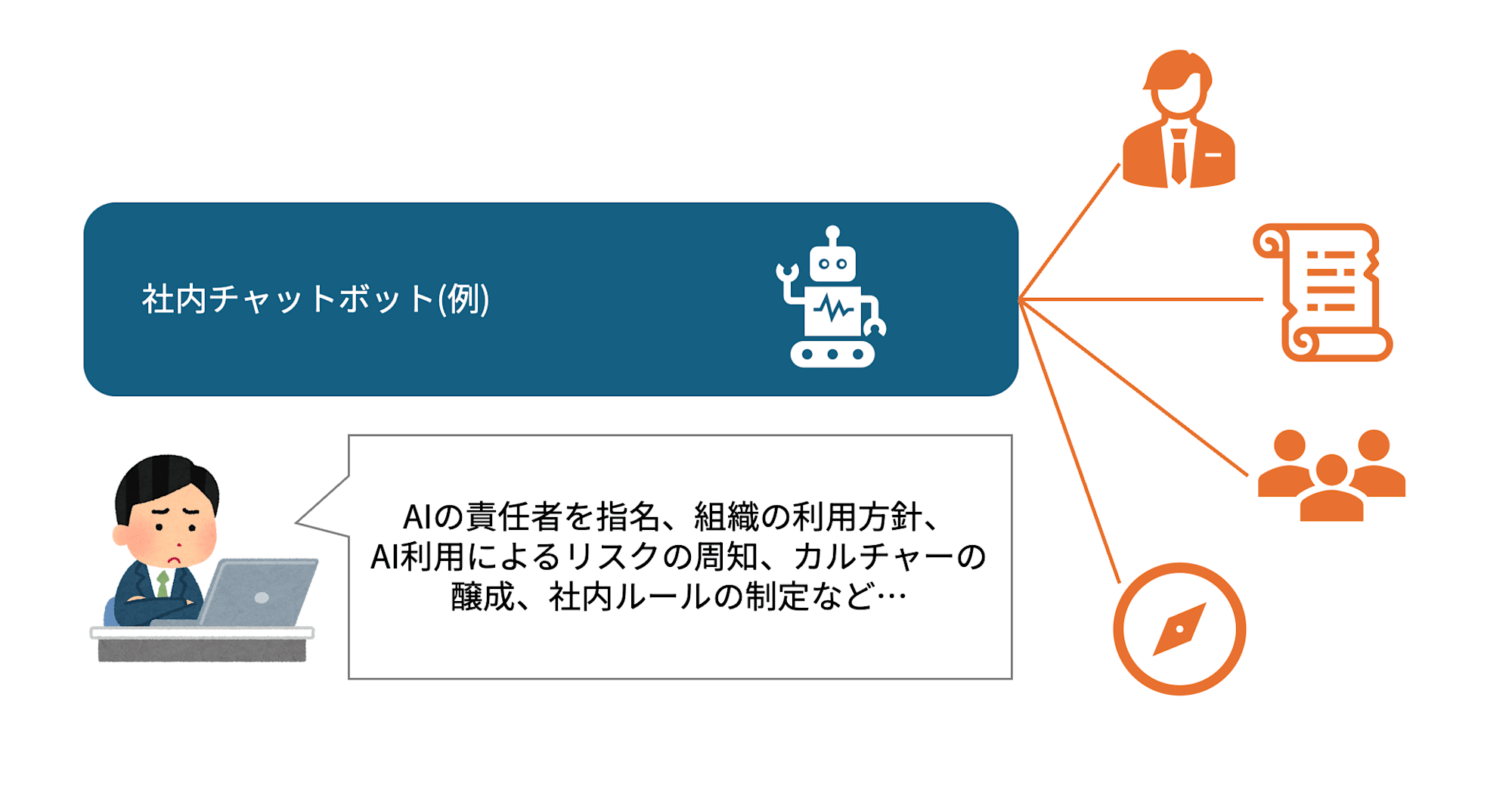
◆ 社内AIチャットボットの例え
「自社でAIをどう扱うか」のルール作りがここです。たとえば「顧客の個人情報はプロンプトに入れない」「AIの回答には必ず人間のレビュー担当を置く」といった社内ポリシーを定めたり、AIリスクの責任者を任命したり。個別の技術の話というより、会社としてAIとどう向き合うかの方針を決める層です。
チャットボットの中身ではなく、土台や組織のあり方について議論します。
Map(マッピング)
対象のAIシステムについて、文脈とリスクを洗い出す機能です。何のために使うのか(想定用途)、誰が関わるのか(ステークホルダー)、ライフサイクルのどの段階か、そしてどの信頼特性が効いてくるのか、を整理します。
ここで全体像を描いておかないと、この後の測定や対応(リスクマネジメント)が困難になることがあります。
◆ MAP 機能
| カテゴリー | 概要 |
|---|---|
| MAP 1 | コンテキストは確立され、理解されています。 |
| MAP 2 | AIシステムの分類が行われています。 |
| MAP 3 | AIの能力、対象とする用途、目標、ならびに適切なベンチマークと比較した際の期待される利益とコストが把握されています。 |
| MAP 4 | サードパーティ製のソフトウェアやデータを含む、AIシステムのすべてのコンポーネントについて、リスクと利点を整理・特定しています。 |
| MAP 5 | 個人、グループ、地域社会、組織、そして社会全体に及ぶ影響が特徴付けられています。 |
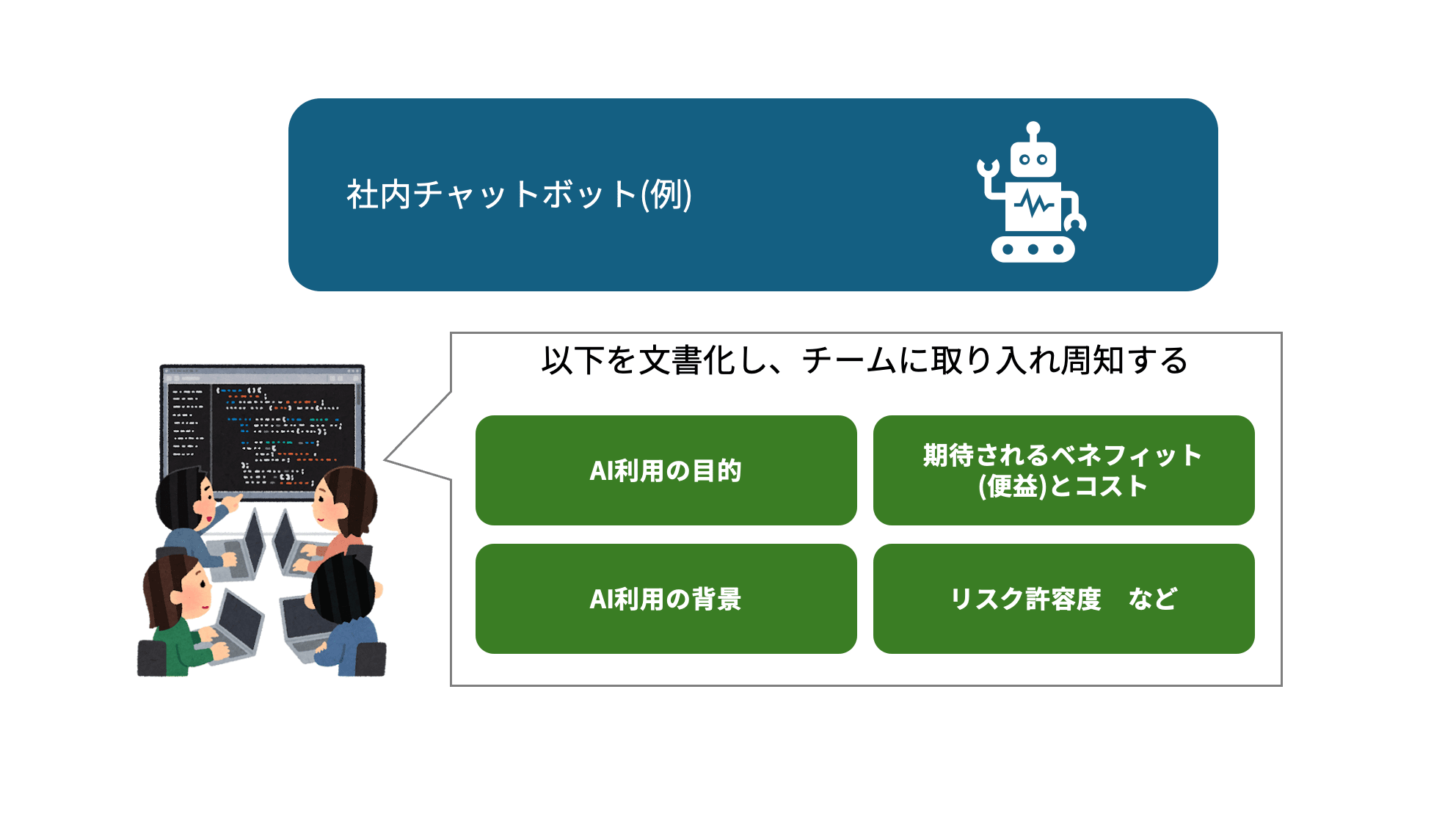
◆ 社内AIチャットボットの例え
「このボットには何のリスクがあるか」を具体的に書き出す工程です。たとえば — 誤った回答で利用者が損をする(Valid & Reliable)、誘導されて社外秘を喋ってしまう(Secure)、特定の属性に偏った回答をする(Fair)、といったリスクを洗い出します。
あわせて「使うのは社内の従業員だけか/社外の顧客も触るのか」といった想定用途とステークホルダーも整理します。どこにリスクが潜むかの地図づくりを実施し、それを関係者間で認識することで全体のリスクを低減します。
MAP 機能完了後に、そのAI システムを設計、開発、またはデプロイするかどうかに関する最初の実施/非実施の決定を下します。続行する場合でも、AI システムのコンテクスト、能力、リスク、ベネフィット、潜在的なインパクトが時間経過とともに変化するため、継続的にMAP 機能を適用する必要があります。
Measure(測定)
MAPで見えてきたリスクを、定量・定性の両面で分析して追跡する機能です。AIの性能や影響を測り、信頼特性がどれくらい満たされているかを評価します。
また、AIモデルの評価だけでなく、組織の利用状況やエラーレート、セキュリティ・レジリエンスの評価など、様々な指標を確認できるようにしておく必要があります。
◆ MEASURE 機能
| カテゴリー | 概要 |
|---|---|
| MEASURE 1 | 適切な手法と指標を特定し、適用します。 |
| MEASURE 2 | AIシステムは、信頼できる特性を備えているかどうか評価されます。 |
| MEASURE 3 | 特定されたAIリスクを長期的に追跡する仕組みが整備されています。 |
| MEASURE 4 | 測定の有効性に関するフィードバックが収集され、評価されます。 |
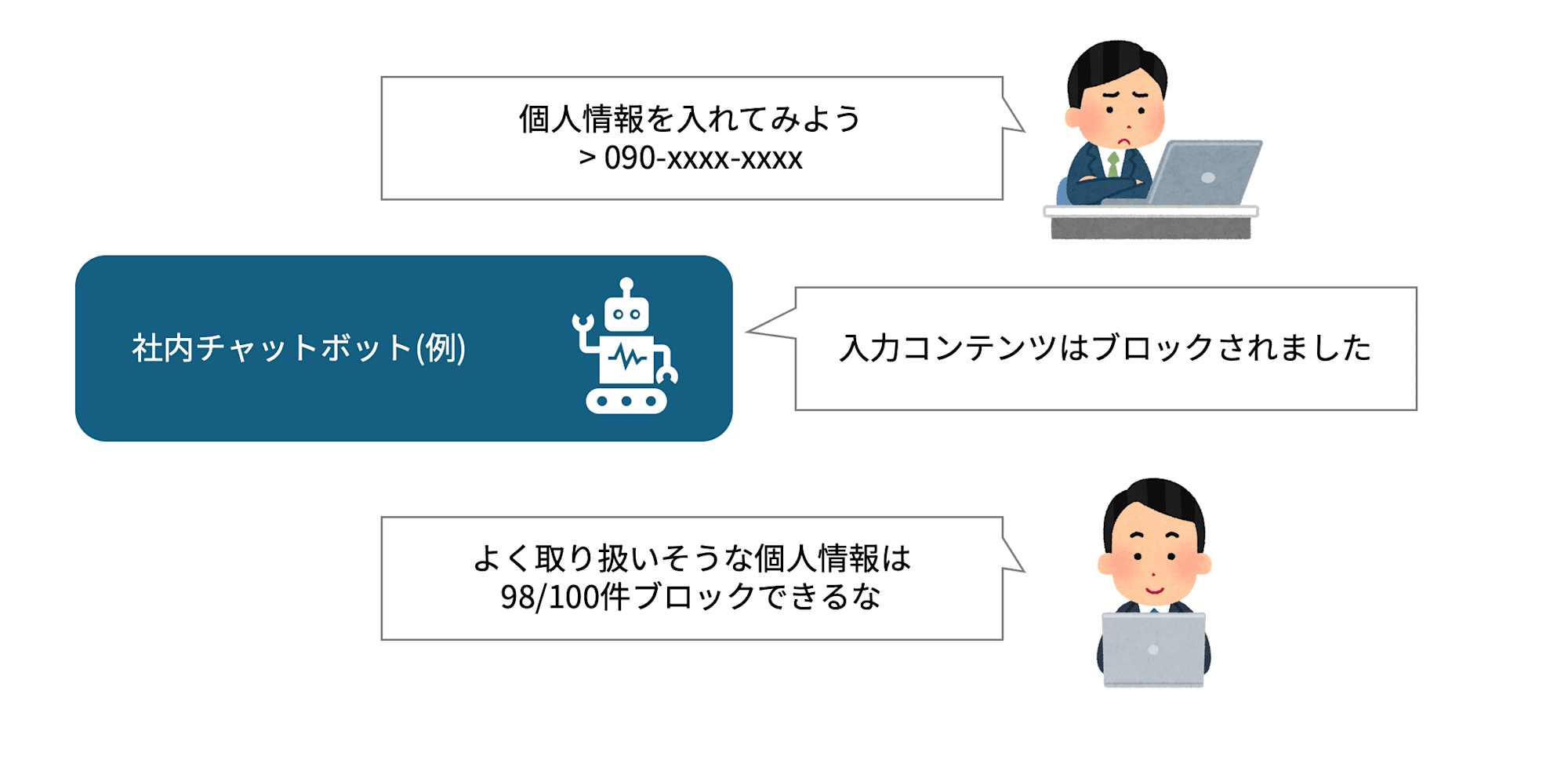
◆ 社内AIチャットボットの例え
Mapで挙げたリスクを実際に測る工程です。たとえば100件のテスト質問を投げて誤回答率を出す、わざと意地悪な質問(プロンプトインジェクション)を投げて何件すり抜けるか試す、回答に偏りが出ないか属性別にチェックする、など。「ハルシネーションが心配」を「テスト100件中7件で誤情報が出た」という数字で表記するイメージです。
Manage(マネジメント)
測定結果をもとに、リスクへの対応にリソースを割り当てる機能です。優先順位をつけて対処し、残ったリスク(残留リスク)を記録し、インシデントが起きたら対応します。
完全にゼロリスクにはできないからこそ、「どこまでを受け入れてどう備えるか」を意思決定として残すことがポイントです。
◆ MANAGE 機能
| カテゴリー | 概要 |
|---|---|
| MANAGE 1 | MAPおよびMEASURE機能から得られる評価やその他の分析結果に基づき、AIリスクの優先順位付け、対応、および管理が行われる。 |
| MANAGE 2 | AIのベネフィットを最大化し、ネガティブインパクトを最小限に抑えるための戦略が、計画・準備・実施・文書化されており、関連するAIアクター(人・組織・システム)からのインプットがそれらに反映されています。 |
| MANAGE 3 | サードパーティ組織によるAIのリスクとベネフィットが管理されています。 |
| MANAGE 4 | 特定および測定されたAIリスクに対する、対応・復旧を含むリスク対策とコミュニケーション計画が文書化され、定期的に監視されている。 |
◆ 社内AIチャットボットの例え
MAP, MEASUREによって露呈したリスクに対応する工程です。
誤回答率が高い回答にガードレールを入れる、社外秘の漏えいを防ぐため機密データはそもそも参照させないなど対策したうえで、それでも残ってしまう「たまに間違える」リスクは「画面に『AIの回答です、最終確認は担当へ』と明記する」という形で受け入れて記録しておく。そして公開後に問題が起きたら対応する、というインシデント対応もここに含まれます。
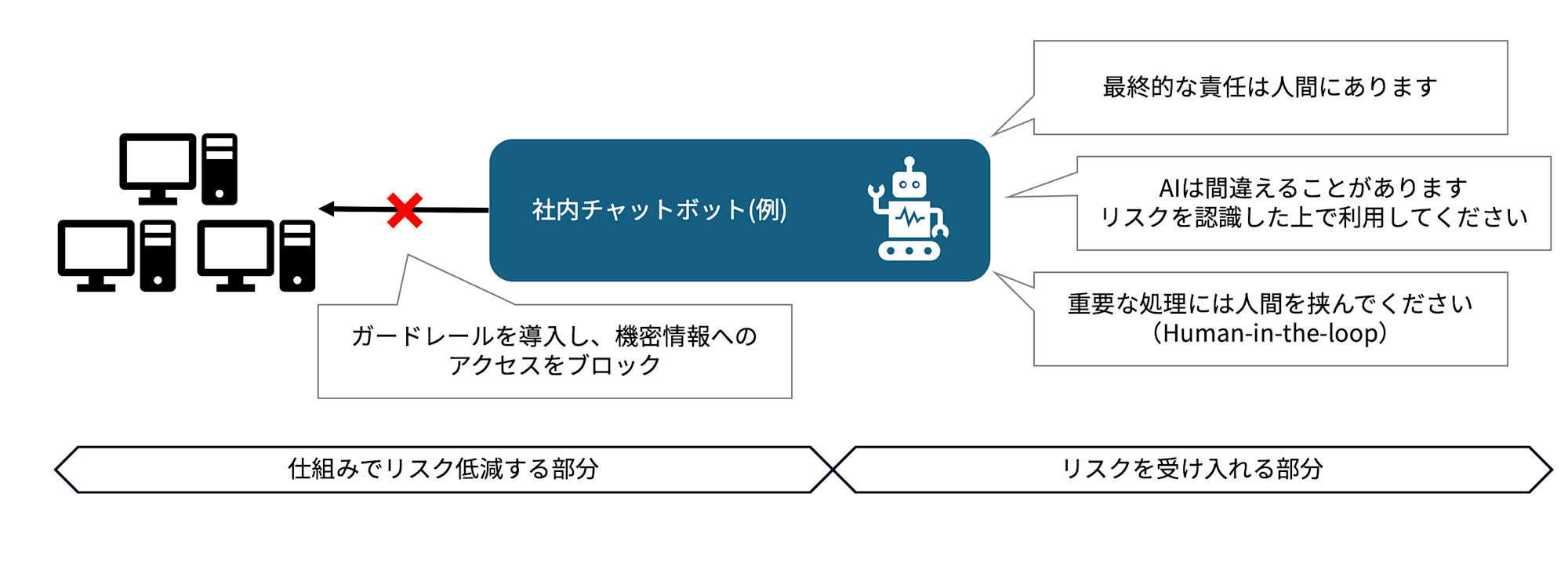
全て仕組み化してリスク管理できるのが理想ですが、AI利用者の教育も非常に重要だと感じています。
関連するAIアクター(人・組織・システム)によってリスクの量や質、内容が異なりますが、本質的にはそれらを認知、対応、管理できている状態を目指すのが理想ではないかと思います。
なお、この4機能は一回実施して終わりではなく、AIのライフサイクル全体を通じて継続的に回していくものとされています。
チャットボットも公開して終わりではなく、使われ方が変われば新しいリスクが出てくるので、Map→Measure→Manage を回し続ける前提でこのフレームワークを利用する必要があります。
(参考)NIST RMF(SP 800-37)との関係
冒頭でも少し触れましたが、改めて整理しておきます。同じ「RMF」でも、情報システム向けの NIST RMF(SP 800-37) と、今回の AI RMF(NIST AI 100-1) は別のドキュメントです。名前がそっくりなので混同されがちですが、生い立ちも構造も違います。
| NIST RMF (SP 800-37) | NIST AI RMF (AI 100-1) | |
|---|---|---|
| 対象 | 情報システム全般のセキュリティ・プライバシー | AIシステムの信頼性(trustworthiness) |
| 構造 | 7ステップ(Prepare〜Monitor) | 4機能(Govern / Map / Measure / Manage) |
| 性質 | 連邦政府では実質必須(FISMA/OMB A-130に基づく) | 任意(voluntary)のガイダンス |
| ゴール | 運用認可(ATO)を出す | AI特有のリスクを管理し信頼性を高める |
| 主なリスク観点 | 機密性・完全性・可用性(CIA) | 公平性・説明可能性・安全性なども含む |
この2文書は「どちらかを選ぶ」ものではなく、補完しあう関係ということのようです。AIシステムも実体としては1つの情報システムなので、土台のインフラやデータの守りは従来のRMF(SP 800-37)でカバーしつつ、AIならではのリスク(バイアス、ハルシネーション、説明可能性など)はAI RMFで上乗せして見る、という重ね方になります。
なお、AI RMF 1.0は枠組みそのものですが、それを実際に使うための周辺資料も用意されています。(ここでは一旦触れません)
・AI RMF Playbook:各機能を具体的にどう実践するかのアクション集
・生成AIプロファイル(NIST AI 600-1):生成AI特有のリスクに焦点を当てたプロファイル
(参考)OWASP Top 10 for LLM Applications との関係
AI RMF 1.0は Appendix B で「個人・組織・社会/エコシステムへの危害」という観点からリスクの分類や例を示しています。ただ、それは「リスクの捉え方の枠組み」に近く、LLMアプリの実装でそのまま使える具体性までは踏み込んでいません。
そこで用いるのが OWASP Top 10 for LLM Applications 2025 です。プロンプトインジェクションや機密情報漏えいといった、LLMアプリ特有のリスクを具体名で並べたリストで、以下のラインナップがあります(執筆時点の2025年版)。
| ID | リスク |
|---|---|
| LLM01 | Prompt Injection(プロンプトインジェクション) |
| LLM02 | Sensitive Information Disclosure(機密情報の漏えい) |
| LLM03 | Supply Chain(サプライチェーン) |
| LLM04 | Data and Model Poisoning(データ・モデルの汚染) |
| LLM05 | Improper Output Handling(不適切な出力処理) |
| LLM06 | Excessive Agency(過剰な権限・自律性) |
| LLM07 | System Prompt Leakage(システムプロンプトの漏えい) |
| LLM08 | Vector and Embedding Weaknesses(ベクトル・埋め込みの弱点) |
| LLM09 | Misinformation(誤情報) |
| LLM10 | Unbounded Consumption(リソースの無制限消費) |
それぞれの対処については以前たかくにさんより書いていただいている通りです。
筆者はもともとこのOWASP Top 10を基準にリスクを洗い出していたのですが、AI RMFと並べてみると、 AI RMFが「型」、OWASPが「中身」 という整理が良さそうと思いました。
※ OWASP Top 10 for LLM は「リスク・脆弱性のカタログ」ですので、全て網羅されている訳ではないので注意が必要です。
先ほどのチャットボットの例えだと、Mapの段階で、
「LLM01: Prompt Injection → 細工した入力でボットを誤動作させられるリスク」
「LLM02: Sensitive Information Disclosure → 社外秘を喋ってしまうリスク」
「LLM09: Misinformation → 誤回答で利用者が損をするリスク」
のように、ふんわりした不安をOWASPの項番に紐づけて整理できます。
そうするとMeasureのテスト項目など話が具体に進められるので、フレームワークが一気に手触りのあるものになりそうです。
おわりに
本エントリはNIST AI RMFについて自分なりに理解してみるという趣旨でした。とりあえずAI導入を進めてみたけどガバナンスはまだ、リスクは整理しきれてない、という企業も多いのではないかと思います。
こういったフレームワークに沿って整理していくと対応すべき課題が出てくるかもしれないので、是非原文&訳文をお読みいただければと思います。(気付いたことがあれば、是非コメントください)
このエントリが誰かの助けになれば幸いです。
それでは、クラウド事業本部 コンサルティング部の荒平がお送りしました!
参考









