
I tried running NVIDIA Cosmos 3 on DGX Spark
This page has been translated by machine translation. View original
Introduction
Hello, I'm Morishige from Classmethod's Manufacturing Business Technology Department.
I've been strongly sensing lately that NVIDIA is at the forefront of Physical AI (embodied AI). As the foundation supporting robot control and factory simulation, the importance of World Foundation Models has risen significantly.
I was given the opportunity to run the next-generation "Cosmos 3" from the NVIDIA Cosmos series on DGX Spark™, so I'd like to share what kind of model it is. Cosmos 3 has a structure that handles everything from robot observation, predictive video generation, to control command generation in a single model, and what previously required connecting 2 to 3 pipeline stages is now being absorbed into the world foundation model all at once.
Cosmos 3 Architecture — MoT 2-Tower
In previous Cosmos series, models were provided individually for each purpose, such as Cosmos Predict 2.5 for video generation and Cosmos Reason 2 as a VLM for video understanding. Cosmos 3 significantly changes this configuration. The core of Cosmos 3 is the Omni model, where two towers called Reasoner Tower and Generator Tower run in parallel within the same MoT (Mixture-of-Transformers) architecture.
The Reasoner Tower is a VLM responsible for understanding — "reading and judging" video and text — while the Generator Tower is a diffusion expert responsible for generation — "creating and moving" images, video, audio, and actions. The key point is that rather than placing these two as separate models side by side, they are connected through shared latent representations, so the generator tower can directly receive the intermediate representations derived by the understanding tower as conditions. Text uses autoregressive decoding that predicts the next token sequentially, while images, video, audio, and actions are generated through iterative denoising — a design that allows the most suitable generation method for each modality to be used within a single framework.
Cosmos 3 provides this MoT-based omnimodel in two sizes: Nano (15.17B) and Super (63.99B). During inference, you can also extract only the Reasoner Tower and run it as a VLM, so the same model can be used either as a Reasoner for understanding-oriented tasks, or as the full omnimodel when generation is needed. In this article, we'll focus our verification on Nano.
Verification Environment on DGX Spark
Verification was conducted on NVIDIA DGX Spark (GB10 / ARM64 / 128 GB unified memory, CUDA 13.0, Ubuntu 24.04). The model is Cosmos3-Nano (full Omni configuration, BF16 approximately 30 GB).
The official inference code is set up so the environment can be prepared with a single uv sync, installing torch 2.10.0+cu130, natten (Blackwell wheel), lerobot, and more. Alibaba's Wan 2.2 VAE has been adopted as the visual tokenizer for Cosmos 3, and it is automatically retrieved from Hugging Face on first inference.
Running 4 Use Cases
Now for the main topic. Let's run 4 modes — text-to-image, text-to-video, image-to-video, and Policy Model — with the Cosmos 3 Omni model on DGX Spark. All executions simply involve specifying the official sample JSON, making for a straightforward setup.
Generating Commercial-Quality Robotics Scenes from Text
Text-to-image generates images of robotics scenes from long prompts. When given content such as "a modern laboratory with white walls and gray floor, a metal-finished robot arm mounted on a white workbench," DGX Spark produced an image containing most of the elements described in the prompt, with actual measurements of 960×960 / 35 steps / 22 seconds after model loading / approximately 30 GB GPU memory. It's quite moving to think that 22 seconds per image means an open-source world foundation model runs on a single DGX Spark. Since it's built on training data from the Physical AI domain, it seems well-suited for VSS, synthetic scene materials for manufacturing, and data augmentation for PPE training.
Generating Videos of Grasping Actions from Text
For text-to-video, we verified operation with the prompt "a gripper grasps a red cube and slowly lifts it." With a light setting of 256p / 24 frames / 12 fps, the inference time was 22 seconds. In the generated video, the robot arm structure remained consistent over time, and the action sequence of "descend → contact → grasp → lift" was arranged in a physically plausible order. The fact that the structure doesn't break down even at low resolution settings is behavior befitting a model trained in the Physical AI domain.
Generating Physically Conservative Videos from Existing Images
Image-to-video generates video starting from a conditioning image. When given the prompt "the right arm slowly reaches out over the board in the center and returns to its original position" with the official sample conditioning image (robot arms on left and right with a wooden board), the result cleanly showed only the right arm moving while both arms were maintained — exactly as instructed. The inference time was 17 seconds, shorter than text-to-video, suggesting that image conditioning stabilizes diffusion convergence.
What I personally found interesting was how strongly it respects the physical state of the conditioning image. Its stance of "preserve what's in the image, don't introduce what isn't" is clear, so for applications like surveillance video that predict "what would happen if this state were left unattended," the faithfulness of not spontaneously introducing nonexistent objects seems very reliable.
Simultaneously Generating Video and Control Commands with Policy Model
The centerpiece of this article is the Policy Model. This is the flagship mode of Cosmos 3, simultaneously outputting predicted video and robot action sequences from observation video and natural language task instructions. What previously required connecting separate pipelines for "observation," "planning," "generation," and "control" is completed in a single inference.
For verification, we used the official sample as-is. The observation video is from the Bridge dataset in LeRobot v3 format (WidowX kitchen robot), and the prompt in English is "Put the pot to the left of the purple item." Running on DGX Spark, it output 640×480 × 17 frames of predicted video and 16 steps × 10-dimensional actions in 21 seconds after model loading.

The prompt instructions are properly reproduced in the video — "pot" is interpreted as the stainless steel bowl in the scene that corresponds to "a portable container," and the flow of grasping it and moving to the left is realized.
Here's where it gets interesting. The Policy Model outputs numerical values for "how to move the robot arm" together with the video. The arm movements for 16 steps (a numerical sequence summarizing hand position, orientation, gripper opening/closing, etc.) come out at a level of precision that could be passed directly to an arm for execution. The sample includes "reference movements" for comparison against your output. The official pass/fail threshold (0.05) is also defined, making the evaluation clear.
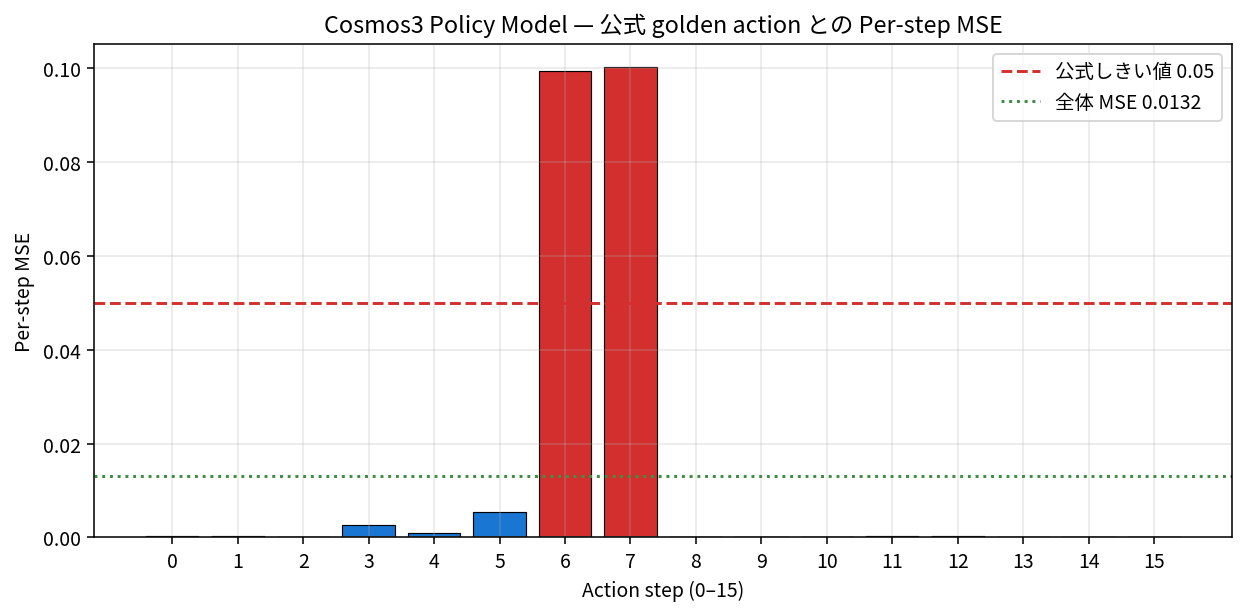
The overall error was 0.013194, less than one-quarter of the passing threshold of 0.05. 14 out of 16 steps matched the reference almost exactly, with slight deviation only at the moment the gripper opens and closes. Being able to simultaneously produce predicted video and passing-level movement from just observation video and natural language instructions in 21 seconds gives a real sense of practical readiness as a foundation for "instructing an arm with words" for small robots like Reachy Mini or SO-ARM101.
Differences from Before and Summary
Finally, let me organize what has changed compared to the previous Cosmos series.
Previously, when building Physical AI applications, it was necessary to construct the observation part and the generation part with separate models — connecting two pipelines, such as Cosmos Reason 2 as a VLM for observation and Cosmos Predict 2.5 as diffusion for generation. Each consumed around 17–40 GB in BF16, so having two models coexist required careful resource management. With Cosmos 3, this observation and generation are completed in a single inference. The Policy Model in this verification output predicted video and 16 steps × 10-dimensional action sequence together in 21 seconds.
The range of on-site applications also looks promising. For small robots like Reachy Mini or SO-ARM101, since the Policy Model generates "language → video + action" end-to-end, there's a sense that what previously required separate training of GR00T or ACT can now be handled by a single model. For factory footage, use cases are also emerging, such as starting from anomaly events extracted with VSS to visualize "what would happen if this state were left unattended" as video.
To summarize the flow:
- Roles that were previously separate, such as video generation and video understanding, are consolidated into the Reasoner + Generator 2-tower MoT in Cosmos 3
- Text-to-image / text-to-video / image-to-video delivered practical-quality output in around 35 steps and 22 seconds
- Image-to-video behaves conservatively by prioritizing the physical state of the conditioning image, making it reliable for safety-critical applications
- Policy Model simultaneously generates predicted video and action sequence from observation video and task instructions, clearing the official golden standard with MSE 0.013
The biggest change I felt this time is that the concept of completing "observation → planning → generation → control" in a single world foundation model can now run in a size that fits on a single DGX Spark.
Cosmos 3 was officially released (GA) at Computex. I hope to continue with separate articles going deeper into Physical AI reasoning with Cosmos 3 Reasoner, environment setup details, and more in-depth verification of the Policy Model.
Reference Links
- NVIDIA Cosmos Platform Overview
- Wan 2.2 VAE (Wan-AI/Wan2.2-TI2V-5B)
- Qwen3-VL technical report (arXiv:2511.21631)
- LeRobot v3 dataset format
- Related Cosmos series articles by the author
- Related VSS series
