
DGX Spark で NVIDIA Cosmos 3 を動かしてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
NVIDIA が Physical AI(身体性を持った AI、フィジカル AI)の最前線を走っているのを最近強く感じます。ロボット制御や工場のシミュレーションを支える土台として、世界基盤モデル(World Foundation Model)の重要度がぐっと上がってきました。
その NVIDIA Cosmos シリーズの次世代版「Cosmos 3」を DGX Spark™ で動かす機会をいただいたので、どのようなモデルなのかをお伝えしていきます。Cosmos 3 は 1 つのモデルでロボットの観察・予測動画生成・制御指令生成までを一気通貫で扱う構造になっていて、これまでパイプラインを 2 〜 3 段つなぐ必要があった部分が、まとめて世界基盤モデル側に飲み込まれつつあります。
Cosmos 3 のアーキテクチャ — MoT 2 タワー
これまでの Cosmos シリーズでは、動画生成を担う Cosmos Predict 2.5 や、映像理解を担う VLM の Cosmos Reason 2 といったモデルが、用途ごとに個別に提供されていました。Cosmos 3 ではこの構成が大きく変わりました。Cosmos 3 の中核は Omni モデルで、Reasoner Tower と Generator Tower という 2 つのタワーが、同じ MoT(混合 Transformer、Mixture-of-Transformers)アーキテクチャの中で並走する構造です。
Reasoner Tower は映像やテキストを「読む・判断する」理解担当の VLM、Generator Tower は画像・動画・音声・action を「作る・動かす」生成担当の diffusion expert です。この 2 つを別モデルとして並べるのではなく、shared latent representations(共有の中間表現)で接続しているのがポイントで、理解側のタワーが導き出した中間表現を生成側がそのまま条件として受け取れます。テキストは次トークンを順番に予測する autoregressive なデコーディングで、画像・動画・音声・action は反復的なデノイジングで生成する、という具合に、モダリティごとに相性のよい生成方式を 1 つの枠組みの中で使い分けられる設計です。
Cosmos 3 には、この MoT 構成の omnimodel が Nano(15.17B)と Super(63.99B)の 2 サイズで提供されています。推論時には Reasoner Tower だけを切り出して VLM として動かすこともできるので、理解寄りの用途なら Reasoner として、生成まで必要なら omnimodel 全体として、と同じモデルを使い分けられます。本稿では Nano を中心に検証していきます。
DGX Spark での検証環境
検証は NVIDIA DGX Spark(GB10 / ARM64 / 128 GB ユニファイドメモリ、CUDA 13.0、Ubuntu 24.04)で行いました。モデルは Cosmos3-Nano(フル Omni 構成、BF16 約 30 GB)です。
公式の推論コードは uv sync 一発で環境が揃う作りで、torch 2.10.0+cu130 や natten(Blackwell 用 wheel)、lerobot などが一通り入ります。Cosmos 3 の visual tokenizer には Alibaba の Wan 2.2 VAE が採用されていて、初回推論時に Hugging Face から自動取得されます。
4 つのユースケースを動かす
ここからが本題です。Cosmos 3 の Omni モデルで、text-to-image / text-to-video / image-to-video / Policy Model の 4 つのモードを DGX Spark で動かしてみます。実行はいずれも公式サンプルの JSON を指定するだけのシンプルな作りです。
テキストから商用品質のロボティクスシーンを生成する
text-to-image は、長文プロンプトからロボティクスシーンの画像を生成します。「白壁とグレー床のモダンな研究室、金属仕上げのロボットアームが白いワークベンチに取り付けられている」といった内容を与えると、DGX Spark では 960×960 / 35 ステップ・モデル常駐後 22 秒・GPU メモリ約 30 GB という実測で、プロンプトに書いた要素がだいたい揃った画像が出てきました。1 枚 22 秒で、オープンソースの世界基盤モデルが DGX Spark 1 台で動くと考えるとなかなか感慨深いですね。Physical AI ドメインの学習データで構築されているので、VSS や製造業の合成シーン素材、PPE 訓練用のデータ拡張あたりとの相性が良さそうです。
テキストから把持動作の動画を生成する
text-to-video は、「グリッパーが赤いキューブを掴んでゆっくり持ち上げる」というプロンプトで動作確認しました。256p / 24 フレーム / 12 fps の軽い設定で、推論時間は 22 秒です。生成された動画では、ロボットアームの構造が時間方向に一貫していて、グリッパーの「下降 → 接触 → 把持 → 持ち上げ」という動作シーケンスが物理的に妥当な順序で並んでいました。低解像度設定でも構造的に破綻しないあたりは、Physical AI ドメインで学習されたモデルらしい振る舞いですね。
既存画像から物理的に保守的な動画を生成する
image-to-video は、条件画像を起点に動画を生成します。公式サンプルの条件画像(左右に並んだロボットアームと木製ボード)に「右のアームが中央のボードの上にゆっくり手を伸ばして元の位置に戻る」というプロンプトを与えると、両アームを保ったまま右アームだけが動く、指示通りの動きが綺麗に出ました。推論時間は 17 秒と text-to-video より短く、image conditioning が diffusion の収束を安定させているようです。
個人的に面白いと感じたのは、条件画像の物理状態を強く尊重する点です。「画像にあるものは保つ、画像にないものは生やさない」というスタンスがはっきりしているので、監視映像のように「もしこの状態から放置したら何が起きるか」を予測する用途では、勝手に存在しない物体を出さない忠実さが頼りになりそうです。
Policy Model で動画と制御指令を同時生成する
本稿の中核となるのが Policy Model です。Cosmos 3 の看板機能にあたるモードで、観測動画と自然言語のタスク指示から、予測動画とロボットの action sequence を同時に出力します。これまで「観察」「計画」「生成」「制御」を別パイプラインで連結していた部分が、1 推論で完結します。
検証には公式サンプルをそのまま使いました。観測動画は LeRobot v3 形式の Bridge データセット(WidowX キッチンロボット)、プロンプトは英語で "Put the pot to the left of the purple item."(ポットを紫色の物体の左へ)です。DGX Spark での実行は、640×480 × 17 フレームの予測動画と 16 ステップ × 10 次元の action を、モデル常駐後 21 秒で出力しました。

プロンプトの指示が動画上できちんと再現されていて、pot はシーン中の「持ち運べる容器」にあたるステンレスボウルとして解釈され、把持して左方向に移動する流れになっています。
ここからが見どころです。Policy Model は動画と一緒に「ロボットアームをどう動かすか」の数値もまとめて出力します。16 ステップ分のアームの動き(手先の位置・向き・グリッパーの開閉などをまとめた数値列)が出てきて、そのままアームに渡せば動かせるレベルの精度です。サンプルには「お手本になる動かし方」が同梱されていて、自分の出力との近さを比較できます。公式が「これより誤差が小さければ合格」と決めているライン(0.05)も定義されているので、合否がはっきりわかります。
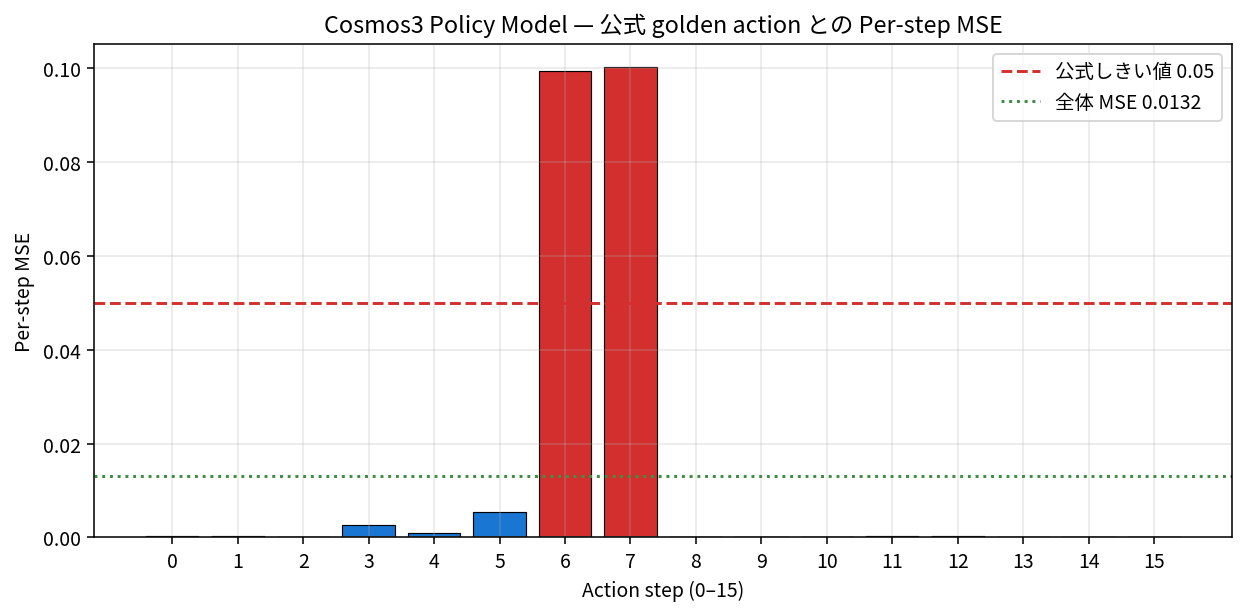
全体の誤差は 0.013194 で、合格ラインの 0.05 と比べて 4 分の 1 以下に収まりました。16 ステップ中 14 ステップはお手本とほぼぴたり一致、グリッパーが開閉する瞬間だけ少し偏差が出ています。観測動画と自然な言葉での指示だけで、予測動画と合格レベルの動かし方を 21 秒で同時に作れたのは、Reachy Mini や SO-ARM101 のような小型ロボットを「言葉でアームに指示する」土台として実用に届きそうな手応えがあります。
これまでとの違いとまとめ
最後に、これまでの Cosmos シリーズと比べて何が変わったのかを整理します。
これまでは、Physical AI のアプリケーションを組むときに、観察パートと生成パートを別のモデルで構築する必要がありました。観察は VLM の Cosmos Reason 2、生成は diffusion の Cosmos Predict 2.5、というようにパイプラインを 2 つ連結する形です。それぞれが BF16 で 17〜40 GB 程度を消費するので、2 モデルを同居させるならリソース管理に気を遣う場面もありました。Cosmos 3 では、この観察と生成が 1 つの推論で完結します。今回の Policy Model は、予測動画と 16 ステップ × 10 次元の action sequence をまとめて 21 秒で出力しました。
現場での使いどころも広がりそうです。Reachy Mini や SO-ARM101 のような小型ロボットには、Policy Model が「言語 → 動画 + action」を一気通貫で生成してくれるので、これまで GR00T や ACT を別途学習する必要があった部分を 1 モデルで担えそうな手応えがあります。工場映像については、VSS で抽出した異常イベントを起点に「もしこの状態から放置したら何が起きるか」を動画として可視化する、といった使い方も見えてきます。
改めて整理すると、こんな流れになります。
- これまで個別だった動画生成や映像理解などの役割が、Cosmos 3 では Reasoner + Generator の 2 タワー MoT に集約された
- text-to-image / text-to-video / image-to-video は、35 ステップ・22 秒前後で実用品質の出力が得られた
- image-to-video は条件画像の物理状態を優先する保守的な振る舞いで、安全クリティカル用途で頼りになりそう
- Policy Model は観測動画とタスク指示から予測動画と action sequence を同時生成し、公式 golden 基準を MSE 0.013 でクリアした
「観察 → 計画 → 生成 → 制御」を 1 つの世界基盤モデルで完結させる発想が、DGX Spark 1 台に乗るサイズで動かせるようになった、というのが今回いちばん感じた変化です。
Cosmos 3 は Computex で正式リリース(GA)されました。Cosmos 3 Reasoner の Physical AI 推論や、環境構築の詳細、Policy Model のさらに踏み込んだ検証なども、続けて別の記事で深掘りしていければと思います。
参考リンク
- NVIDIA Cosmos プラットフォーム概要
- Wan 2.2 VAE(Wan-AI/Wan2.2-TI2V-5B)
- Qwen3-VL technical report (arXiv:2511.21631)
- LeRobot v3 dataset format
- 関連する自身の Cosmos 連載
- VSS 連載との関連








