
Amazon Timestream for LiveAnalytics で 必要なクエリのニーズに応じてコンピューティングリソースが提供される Timestream Compute Unit がリリースされたので詳しく検証してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
先日、Amazon Timestream にて「タイムストリーム コンピューティング ユニット (TCU)」と呼ばれるデータクエリの新しい実行方式がリリースされました。
これに伴い課金体系も変わり、従来の「スキャンしたデータサイズによる課金」モードは BYTES_SCANNED と呼ばれ、新しい TCU ベースの課金モードは COMPUTE_UNITS と呼ばれます。
タイムストリーム コンピューティング ユニット (TCU) とは
これまでは、クエリを実行する際のコンピューティングリソースはユーザーが管理できるものではなく、クエリ実行時のデータスキャン量に応じた課金となっていました。
今回の「タイムストリーム コンピューティング ユニット (TCU)」では、ユーザーが利用するコンピューティングリソースのスペックをあらかじめ指定して、そのリソース内でクエリを実行する形に変わります。
課金体系も変わり、スキャンサイズに関係なく、利用したコンピューティングユニットの時間に応じて課金が発生します。
| 利用種別 | コンピューティングリソースの管理 | クエリ課金の対象 |
|---|---|---|
BYTES_SCANNED モード |
AWS が管理 | スキャンしたデータサイズ |
COMPUTE_UNITS モード |
ユーザーが TCU の最大値を指定 | ・利用したコンピューティングユニットのリソース単位 ・コンピューティングユニットを利用した時間単位(TCU 時間) |
何がうれしいのか?
従来は、クエリ時にスキャンしたデータサイズに応じた課金となっていたため、クライアントからのデータ利用方法によっては思わぬ高額料金が発生することがありました。
今回のアップデートによって、スキャンサイズを意識する必要がなくなったことになります。
しかし、ユースケースの内容次第で COMPUTE_UNITS モードの方が安くなる場合と高くなる場合がありそうなので、以降の内容にて検証した結果を紹介していきたいと思います。
COMPUTE_UNITS モードを試してみる
COMPUTE_UNITS モードを有効にする際の注意点
COMPUTE_UNITS モードを使う場合、カジュアルに有効化するのは危険です。まずは下記のポイントをよく理解しておいてください。
試す場合は使ってないリージョンか、新規に検証用の AWS アカウントを用意することをお勧めします。
- 新規の AWS アカウントや Timestream を新たに使うリージョンでは
COMPUTE_UNITSモデルが有効になっている - 既存の
BYTES_SCANNEDモデルで利用している場合、COMPUTE_UNITSモデルにオプトイン可能だが元に戻せない COMPUTE_UNITSモデルはリージョン単位で有効になる
すでに Timestream を利用している場合、そのリージョンは従来の BYTES_SCANNED モードになっています。
現在のリージョンでどのモードが有効になっているか AWS CLI 出確認する場合は、次の内容で確認できます。下記は従来の BYTES_SCANNED モードだった場合のレスポンスです。
aws timestream-query describe-account-settings
{
"QueryPricingModel": "BYTES_SCANNED"
}
COMPUTE_UNITS が有効になっている場合は、MaxQueryTCU も一緒に返されます。
初めて使う場合はデフォルトで 200 にセットされています。
aws timestream-query describe-account-settings
{
"MaxQueryTCU": 200,
"QueryPricingModel": "COMPUTE_UNITS"
}
COMPUTE_UNITS モードを有効化する
COMPUTE_UNITS モード有効化の注意点が把握できたら、モードを切り替えます。
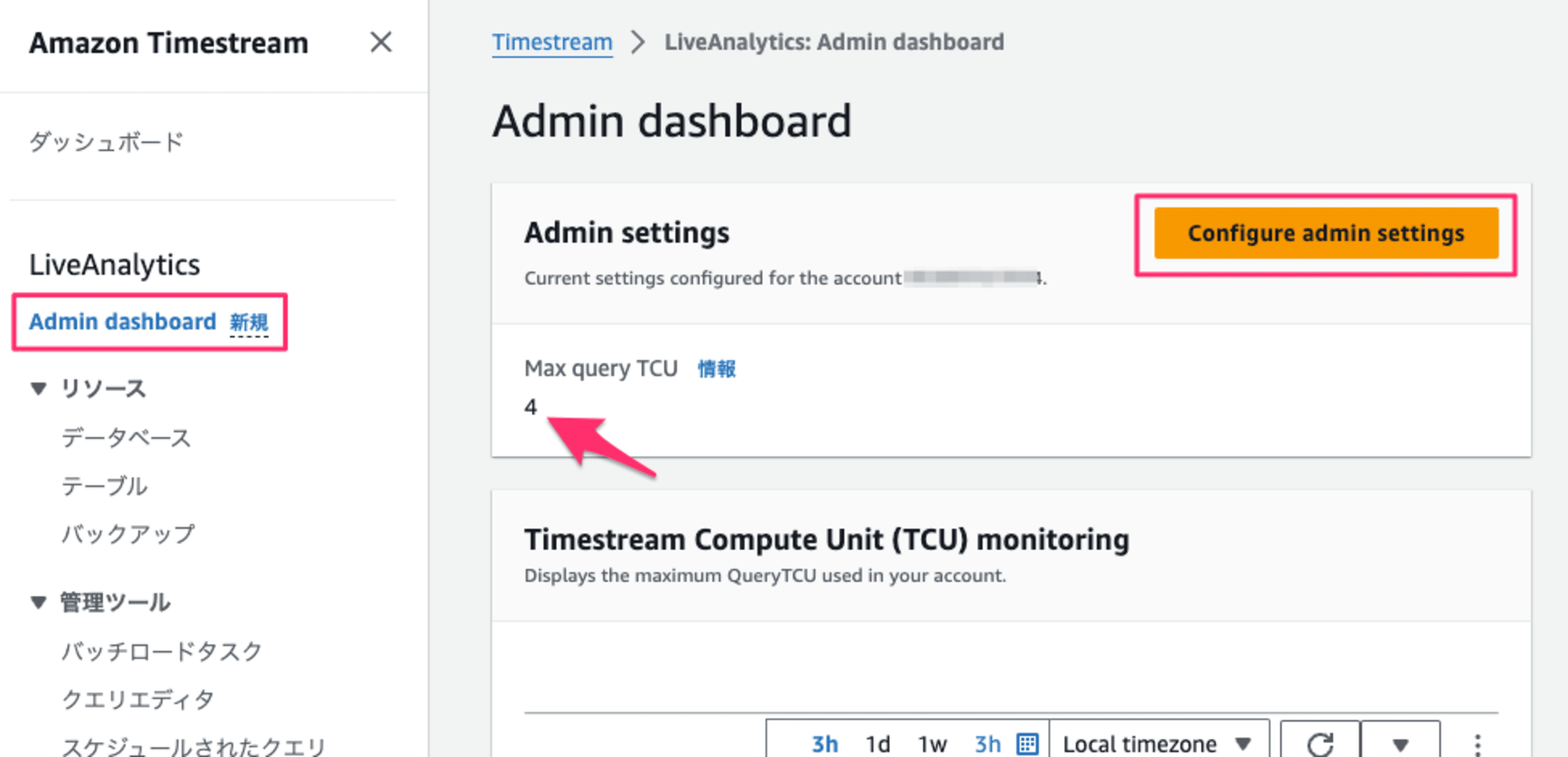
既存環境を切り替える場合は、マネジメントコンソールから Admin dashboard > Configure admin settings とクリックして、 Max query TCU に値をセットすることで有効化されます。
既存の環境がない場合は、すでに COMPUTE_UNITS モードが有効になっています。
検証の準備:データベースの作成
まず最初に、COMPUTE_UNITS が有効なリージョンで適当なデータベースとテーブルを作成します。
検証用データの書き込みは下記のコードで行いました。
このコードでは、5 個のセンサーデータ( item_0 〜 item_4)のデータをマルチメジャーレコードで 10レコード 書き込みます。
ここで書き込んだデータはフルスキャンしても「744 Byte」程度の非常に小さなサイズのものになります。
import boto3
from botocore.config import Config
import time
import random
session = boto3.Session()
write_client = session.client('timestream-write', region_name='eu-west-1',
config=Config(read_timeout=20, # リクエストタイムアウト(秒)
max_pool_connections=5000, # 最大接続数
retries={'max_attempts': 10})) # 最大試行回数
# Amazon Timestream データベースとテーブル
DatabaseName='[YOUR_DATABASE_NAME]'
TableName='[YOUR_TABLE_NAME]'
# タイムスタンプの付与
def current_milli_time():
return round(time.time() * 1000)
# ディメンションの作成
def gen_dimensions():
municipalities = random.choice(['Shinjuku', 'Toshima', 'Nakano', 'Ota', 'Chiyoda'])
gateway_id = random.choice(['gateway_1', 'gateway_2', 'gateway_3'])
device_name = str(municipalities) + '_' + str(gateway_id)
dimensions = [
{'Name': 'Location', 'Value': 'Tokyo'},
{'Name': 'Municipalities', 'Value': municipalities},
{'Name': 'DeviceName', 'Value': device_name}
]
return dimensions
# 何件のメジャー値(アイテム、RDBのカラムに相当するもの)を作成するか
# 1レコードあたりに入れるアイテムを複数作成する
def gen_item():
records = []
MultiMeasureValue = []
start_item_num = 0 # 任意のアイテム番号からMeasureValueを作成
end_item_num = 5 # start_item_numから 256を超えない範囲で指定
for multi_measure_num in range(start_item_num,end_item_num):
#ランダムな数値データをメジャー値として作成
MeasureValue = str(random.uniform(1, 90))
dummy_multi_measure = 'item_' + str(multi_measure_num)
myitem = {
'Name': dummy_multi_measure,
'Value': MeasureValue,
'Type': 'DOUBLE'
},
records.append(myitem)
t = records[multi_measure_num - start_item_num]
MultiMeasureValue.append(t[0]) # 要素だけ抽出して、それを連結して変数に入れる
return MultiMeasureValue
# レコードの生成
def gen_dummy_record():
records_X = []
# 何件のレコードを作成するか ; 100件:(0,100) 最大100
for record_num in range(0,10):
dummy_measure = {
'Dimensions': gen_dimensions(),
'MeasureName': 'dummy_metrics',
'MeasureValueType': 'MULTI',
'MeasureValues': gen_item(),
'Time': str(current_milli_time()),
'TimeUnit': 'MILLISECONDS'
}
records_X.append(dummy_measure)
time.sleep(1/1000)
return records_X
for write_num in range(0,1): # 生成したレコードを何回書き込むか
print ("start write_records...: " + str(write_num))
result = write_client.write_records(DatabaseName=DatabaseName,
TableName=TableName,
Records=gen_dummy_record(), CommonAttributes={})
TCU の利用状況を確認してみる
サンプルデータができたので、具体的にクエリを発行して TCU の利用状況を確認してみます。
Max query TCU を適宜変更しながらクエリを実行してみます。
マネジメントコンソールで変更する場合は Admin dashboard > Configure admin settings から編集できます。
なお、場合によっては Max query TCU を変更したのに指定した値に変わっていないことがあります。その場合は、反映されるまで何回か繰り返してみてください。
Max query TCU の変更が反映されるには最大で 24 時間かかる場合があるとのことですが、私の場合は多くても 2 回くらいで反映できました。
検証に使うクエリは下記のコードで行います。マネジメントコンソールのクエリエディタを使う場合はクエリにかかった時間が表示されるのですが、CLI など API 経由ではクエリ時間は取れないようなので、クエリの実行前後で時間を計測するようにします。
import json
import boto3
from botocore.config import Config
#import json
from datetime import datetime
config = Config(region_name = 'eu-west-1')
config.endpoint_discovery_enabled = True
timestream_query_client = boto3.client('timestream-query', config=config)
#def lambda_handler(event, context):
start_time = datetime.utcnow() # クエリ開始時間を記録
result = timestream_query_client.query(
QueryString='SELECT DeviceName,item_1,item_2 FROM "blogtest2"."table2" WHERE time > \'2024-05-20 00.000000000\''
)
end_time = datetime.strptime(result['ResponseMetadata']['HTTPHeaders']['date'], '%a, %d %b %Y %H:%M:%S %Z') # クエリ終了時間を取得
execution_time = end_time - start_time # 実行時間を計算
cumulative_bytes_scanned = result["QueryStatus"]["CumulativeBytesScanned"]
print(f"CumulativeBytesScanned: {cumulative_bytes_scanned}") # スキャンサイズを標準出力に表示
print(f"Query execution time: {execution_time}") # 実行時間を標準出力に表示
クエリの同時実行数と 利用 TCU の結果
上記で準備が整いました。ここからは各種パラメーターを変えながら TCU の仕様を探っていきたいと思います。
クエリの同時実行数・Max query TCU・消費 TCU ・クエリ時間の関係
クエリを同時実行する方法についてですが、今回は Mac の iTerm2 を使って複数のペインで同じコマンドを同時に実行するようにしました。以下のようなイメージで実行したい数に応じてペインを増やしてクエリを実行しました。
Timestream からのレスポンスに含まれる「クエリ ID」はすべてユニークなものだったので並列でクエリを実行できていることを確認済みです。
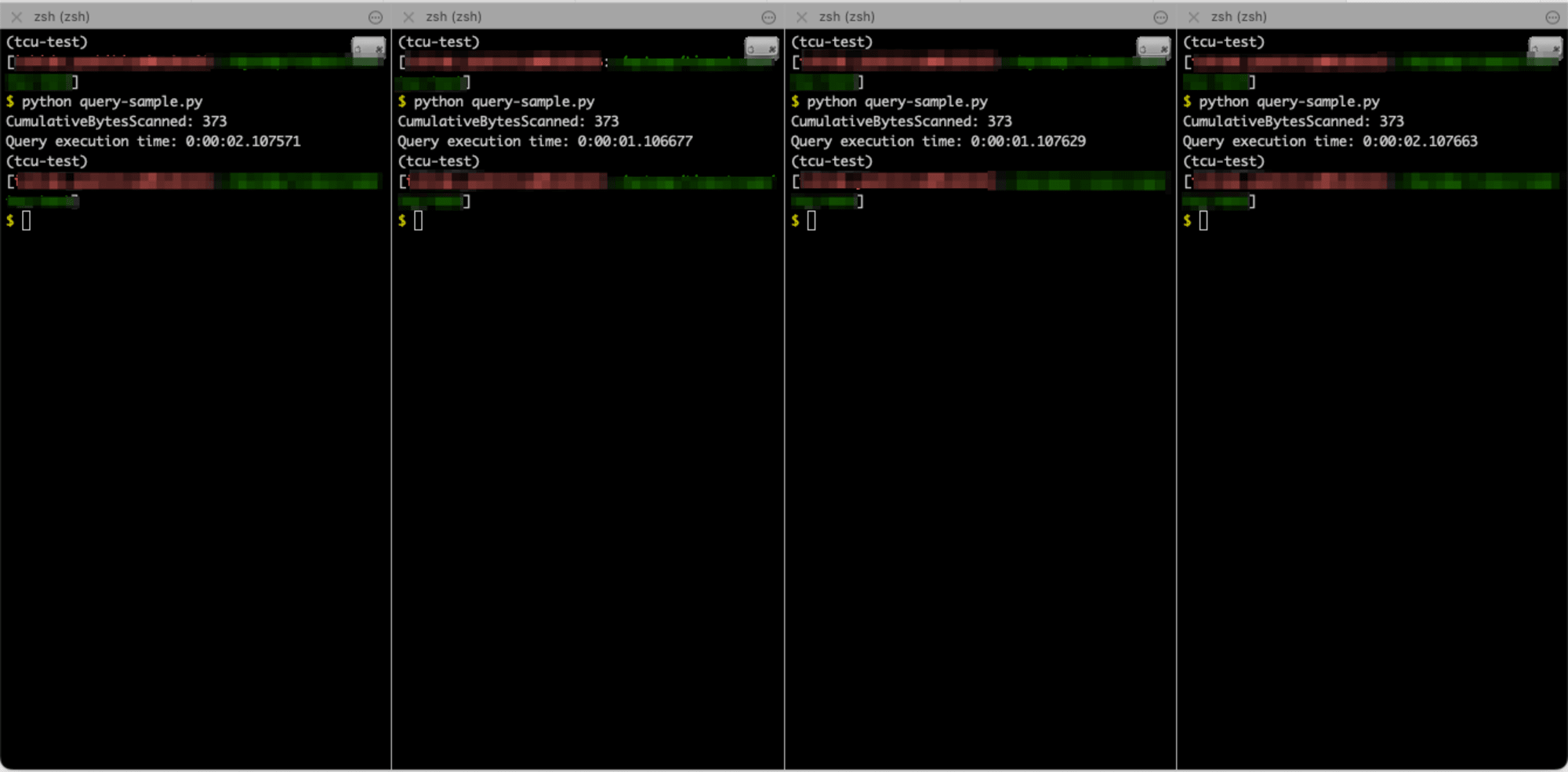
(上記の方法で実行した)クエリの同時実行数や Max query TCU を変えながら、消費した TCU やクエリ処理時間をまとめてみました。
| クエリの同時実行数 | Max query TCU | 利用した TCU | 各クエリ時間 | クエリ時間の平均 |
|---|---|---|---|---|
| 1 | 4 | 4 | 1.378647 |
1.378647 |
| 4 | 4 | 4 | 1.6440591.6427571.6437921.643267 |
1.64346875 |
| 4 | 24 | 12 | 1.2042221.2041761.2040731.204288 |
1.20418975 |
| 8 | 4 | 4 | 1.4044502.4033872.39291402.4042252.4030871.3966111.4051581.397370 |
1.90090025 |
| 8 | 24 | 24 | 1.5031661.5021121.5048321.4983091.4997881.4975151.5044211.496669 |
1.5008515 |
| 16 | 4 | 4 | 2.4025091.4134011.4377452.1444772.4049761.4462852.4531842.5047642.4244662.4516521.3843011.4352872.4230272.3962152.4119581.468029 |
2.03764225 |
| 16 | 200 | 44 | 0.9085831.7773901.8368401.7970711.8338451.7946851.1109211.8079121.2033400.9011211.8152961.7805531.7929720.7102761.7837940.976061 |
1.48941625 |
この表から次のことが分かります。
- クエリの同時実行数が同じでも、Max query TCU が高ければクエリ処理時間は短くなる
- Max query TCU が低くても、クエリは必ずしもエラーにはならない
- 消費した TCU を倍にしてもクエリ時間は半分にならない
- より大規模なデータに対してクエリを実行するような場合では、結果が変わるかも知れません。
- クエリがエラーになると予測したクエリでも正常終了したが、実行時間に時間がかかった
また、同じ条件で同じクエリを実行しても、消費する TCU はタイミングによって異なることもありました。
公式ドキュメントには、Max Query TCU を超える TCU の利用時は 4xx エラーとなることがある、と記載されていましたが、今回の検証内容ではエラーが発生することはありませんでした。
この結果から、エラーになる Max Query TCU の値は一律的に決めることができないことが分かります。どこまで Max Query TCU を下げると、どれくらいクエリ時間が変わるのか、どのタイミングでエラーになるのか、といった点は実際のワークロードに沿った検証が必要になります。
クエリの同時実行数・Max query TCU・消費 TCU ・クエリ時間・料金
それぞれの並列実行数におけるクエリ料金は次のとおりです。並列で実行したクエリ料金の合計金額を「各クエリの料金合計」に記載しています。
なお、課金対象となるクエリ時間は最小 30 秒なので、30 秒未満のクエリはすべて 30 秒のクエリ時間とみなされますが、今回は比較のため「時間単価」を秒に変換して計算しています。
| クエリの同時実行数 | Max query TCU | 利用した TCU | クエリ時間の平均 | 各クエリの料金合計 |
|---|---|---|---|---|
| 4 | 4 | 4 | 1.64346875 |
0.004280323056 |
| 4 | 24 | 12 | 1.20418975 |
0.009408735913 |
| 8 | 4 | 4 | 1.90090025 |
0.009901578191 |
| 8 | 24 | 24 | 1.5008515 |
0.04690661221 |
| 16 | 4 | 4 | 2.03764225 |
0.02122770415 |
| 16 | 200 | 44 | 1.48941625 |
0.1706804826 |
上記の結果からは 「クエリ並列度が同じでも Max query TCU が潤沢な場合は、クエリ時間は短くなるが料金が高くなる」 ということが分かります。
検証時に実際に発生したクエリ料金
ここまでの検証で TCU の挙動と料金の関係の全体像が把握できました。
最後に COMPUTE_UNITS モードの課金について、数日クエリを実行して確認してみました。
実行したクエリの詳細は下記です。
- 対象のデータベースは上記検証と同じものを利用
- 10分に1回クエリを実行(数日の間ずっと実行)
- 1度のクエリ実行時間は2秒未満
- Max Query TCU は
4をセット
事前の計算
事前にどれくらいかかるか計算してみました。
1回のクエリで課金対象となる処理時間は、最小で 30 秒です。今回のクエリはすべて2秒未満で終わるので、「全クエリは30秒の実行時間」としてカウントされます。
これを前提とすると、1時間のクエリ時間は、6 回 * 30 秒 = 180 秒 となります。
24時間では、180 * 24 = 4320 秒 = 72 分 = 1.2 時間 となります。
消費した TCU はいずれも 4 なので、1日あたりの金額は下記になります。
4 TCU * 1.2 時間 * クエリ単価
今回の検証では、アイルランドリージョンを使っていたので、アイルランドの単価($0.586)を当てはめると、$2.8128 / 日 となります。
実際の料金
実際の料金を Cost Explorer で確認してみました。QueryUsage という API でフィルタリングしてみたところ、該当期間中は毎日 $2.93 の費用が発生していました。
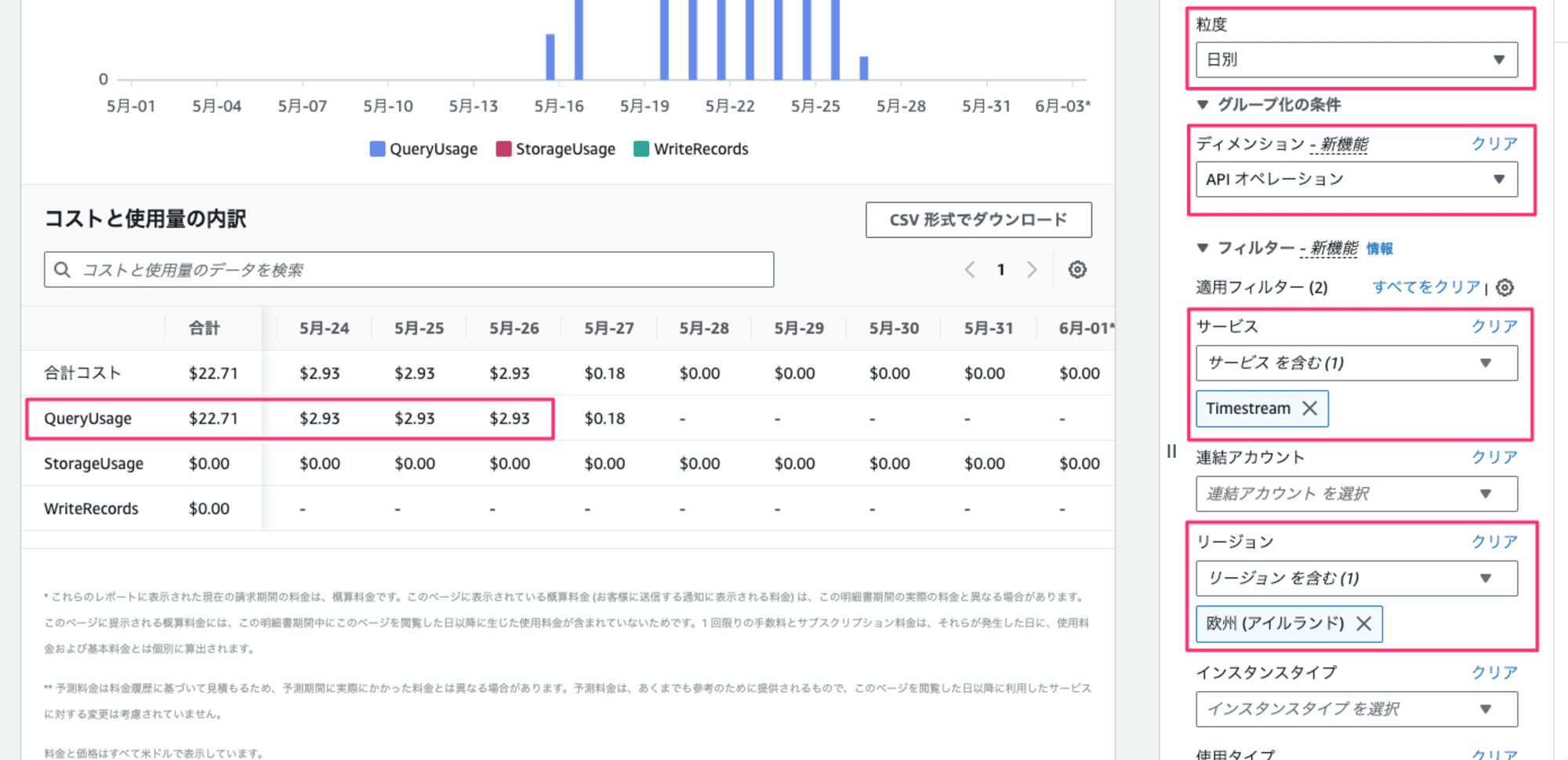
事前の見積もりよりも約 $0.1 違うのが気になりますが、おおよその金額感にズレが無いことが確認できました。これを元にすれば月額の費用感が把握しやすいかと思います。
TCU 前提で Timestream のコストを考慮した設計ポイント
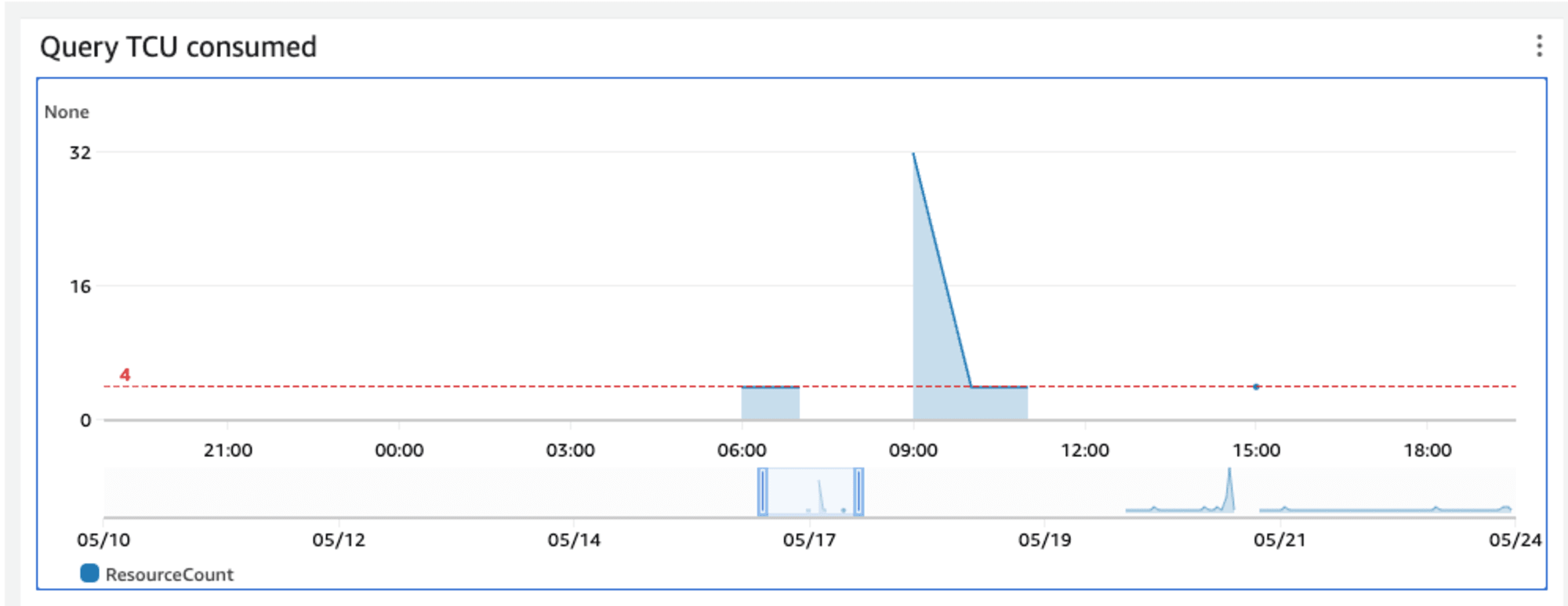
TCU 料金は面積
TCU 前提の料金は「利用した TCU の数」と「TCU を利用した時間」の掛け算です。下記は Timestream のコンソールに表示されるダッシュボードですが、この青色の部分の面積の大きさが TCU 料金となります。
ぽつんと 1点だけ TCU の利用がある場合(例えば下記では 15:00 の部分)でも、ダッシュボードに表示されない程度の短い処理時間が発生しているので、これも面積と考えることが出来ます。数学の積分をイメージしてもらうと分かりやすいと思います。
実際のワークロードを想定した事前検証が重要
さて、先ほどの料金表のように「利用したコンピューターリソースの従量課金」なのは直感的に分かりやすいと思います。しかし、同じクエリに対して利用した TCU が 3 倍になっても処理時間が 3 倍短くなるわけではありません。
そのため、料金を見積もる際は単純な計算で試算することが難しいということになります。また、同じクエリに対しても処理時間は都度異なります。
一方で公式ドキュメントには、必要な TCU の見積もりの目安が記載されています。
| Concurrent queries | TCUs |
|---|---|
| 7 | 4 |
| 14 | 8 |
| 21 | 12 |
これを見ると、例えばクエリの同時実行数が 7 であれば 4 TCU が必要ということになります。しかし、今回の検証内容ではクエリの同時実行数が 16 でも 4 TCU だけでエラー無く処理できたケースがありました。
このような仕様を踏まえて料金を見積もるためには、ドキュメント記載の目安を参考にしつつ、実際のワークロードに沿ったテストを行うことが重要になります。
同じクエリに対してどの程度 TCU を消費するのか、Max query TCU を変えて処理時間を計測し、その時間が許容できる時間なのかどうか判断しながら、「TCU 料金の面積」が最小になるような Max query TCU を判断することになります。
COMPUTE_UNITS モデルでは料金が高くなる場合、S3 + Athena や RDS の小さなインスタンスタイプ の方が安くなる場合があります。ワークロードに応じて最適なサービスへの切り替えも視野に入れて検討していきましょう。
料金見積もりの注意点
COMPUTE_UNITS モデルで料金を見積もる際に事前に押さえておきたい注意事項があります。
- クエリ時に消費される TCU はクエリの内容にかかわらず 4 が最小値
- 課金対象となるクエリ時間は「秒単位」だが、30 秒未満のクエリは 30 秒としてカウントされる
COMPUTE_UNITS がリリースされてからしばらく検証していますが、実際に上記を前提とした内容で課金が発生しているようです。
そのため、ワークロードによって従来の BYTES_SCANNED よりも利用料金が高くなることがあります。特に、30 秒未満のクエリも課金最小時間の 30 秒としてカウントされることから、小規模なクエリを頻繁に実行するようなワークロードの場合、従来の BYTES_SCANNED モデルよりも料金が高くなることが多いのではないかと思います。
逆に、BI ツールなどで大規模なデータをバッチで分析したりアドホックにクエリするような場合、従来だと都度大量のデータスキャンが走りコスト高だった部分が、安くなる可能性が高くなります。
最後に
Timestream はスキーマレスで IoT データのデータストアとして使いやすい印象があるのですが、これまでスキャンサイズによる課金が青天井になることが採用上のリスクでした。
このリスクを回避するためにリリースされた Timestream Compute Unit ですが、検証した限りでは利用するワークロードの事前検証がとても重要なように思います。
まだリリースされたばかりなので、今後のアップデートが楽しみに待ちたいと思います。
以上です。










