
定期的にDynamoDBのデータをS3バケットにCSV形式で保存するLambdaを作成してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
Amazon DynamoDBのデータを毎日Amazon S3バケットへCSV形式で保存するAWS Lambdaを作成する機会がありましたので、紹介します。
構成としては以下のとおりです。

- Amazon EventBridge Schedulerで毎日01:00にLambdaを呼出します
- Lambdaは、DynamoDBから前日に保存されたデータを取得します。
- LambdaでCSV形式に変換し、S3バケットに保存します。
DynamoDBのテーブルは、属性としてデータを保存した日付が入っていれば、テーブルは何でもよいですが、今回は以下の記事で作成したテーブルを利用します。
本記事で使用するDynamoDBのテーブルには、start_date(保存した日付)の属性が必要です。存在しない場合は、新たに追加してください。
- 保存した日付:
start_date(必須)- 例:2024-04-26
- 保存した日時:
start_time- 例:2024-04-26T09:40:18+0900
本記事では1日ごとにCSV形式で保存していますが、その場合、GSIのソートキー(保存した日時start_time)は不要です。
ただし、1時間など時間単位でCSV形式で保存する場合、ソートキー(時間が記載された属性)も必要になりますので、今回は使わないですがソートキーを設定しています。
DynamoDB グローバルセカンダリインデックス作成
以下のようにグローバルセカンダリインデックス(GSI)を作成します。
- パーティションキー:
start_date - ソートキー:
start_time - インデックス名:start_date-start_time-index

Lambda作成
作成するLambdaの設定は以下の通りです。
- ランタイム:Python3.12
- タイムアウト:10秒
- 追加するIAMポリシー
- AmazonDynamoDBReadOnlyAccess
- AmazonS3FullAccess
- 環境変数
DYNAMODB_TABLE_NAME(DynamoDBテーブル名)S3_BUCKET_NAME(S3バケット名)DYNAMODB_GSI_NAME(DynamoDBテーブルのGSI名)
import boto3
import csv
import json
import os
from datetime import datetime, timedelta, timezone
from io import StringIO
from boto3.dynamodb.conditions import Key
TABLE_NAME = os.environ['DYNAMODB_TABLE_NAME']
BUCKET_NAME = os.environ['S3_BUCKET_NAME']
GSI_NAME = os.environ['DYNAMODB_GSI_NAME']
START_DATE = 'start_date'
START_TIME = 'start_time'
def get_dynamodb_data(yesterday_date):
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(TABLE_NAME)
start_date = yesterday_date.strftime('%Y-%m-%dT00:00:00+0900')
end_date = (yesterday_date + timedelta(days=1)).strftime('%Y-%m-%dT00:00:00+0900')
formatted_date_key = yesterday_date.strftime('%Y-%m-%d')
response = table.query(
IndexName=GSI_NAME,
KeyConditionExpression=Key(START_DATE).eq(formatted_date_key) & Key(START_TIME).between(start_date, end_date)
)
return response['Items']
def create_csv(dynamo_records):
csv_data = StringIO()
fieldnames = [key for key in dynamo_records[0].keys() if key != START_DATE]
writer = csv.DictWriter(csv_data, fieldnames=fieldnames)
writer.writeheader()
for record in dynamo_records:
filtered_record = {key: record[key] for key in fieldnames}
writer.writerow(filtered_record)
return csv_data.getvalue()
def upload_to_s3(csv_data, yesterday_date):
s3 = boto3.client('s3')
year = yesterday_date.strftime("%Y")
month = yesterday_date.strftime("%m")
s3_key = f'{year}/{month}/{TABLE_NAME}-{yesterday_date.strftime("%Y-%m-%d")}.csv'
s3.put_object(
Body=csv_data,
Bucket=BUCKET_NAME,
Key=s3_key
)
return s3_key
def get_yesterday_date():
jst = timezone(timedelta(hours=9))
today = datetime.now(jst).date()
return today - timedelta(days=1)
def lambda_handler(event, context):
print('event:' + json.dumps(event, ensure_ascii=False))
yesterday_date = get_yesterday_date()
dynamo_records = get_dynamodb_data(yesterday_date)
if not dynamo_records:
print("No data found for the given date.")
return
csv_data = create_csv(dynamo_records)
s3_key = upload_to_s3(csv_data, yesterday_date)
print(f'Successfully uploaded CSV to S3: s3://{BUCKET_NAME}/{s3_key}')- 関数名
get_dynamodb_dataでは、GSIを使用して前日保存されたデータを検索します。DynamoDBに前日保存されたデータが無い場合、空の配列が返ります。 - 関数名
create_csvでは、取得したDynamoDBのデータをCSV形式に変換します。必要な属性値のみをCSV形式に出力し、start_dateは不要だったため、除外しています。
EventBridge Scheduler
Lambdaを毎日呼び出すため、EventBridge Schedulerを作成します。
毎日午前1時に実行させます。
cron式は以下の通りです
0 1 * * ? *

作成したLambdaを選択します。

再試行数を調整し、他はデフォルトのまま次に進み作成します。

ちなみに、作成されたIAMロールのIAMポリシーは、作成したLambdaに対してlambda:InvokeFunction権限の許可が設定されています。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction"
],
"Resource": [
"arn:aws:lambda:ap-northeast-1:xxxxxxxx:function:Lambda名:*",
"arn:aws:lambda:ap-northeast-1:xxxxxxxxxxx:function:Lambda名"
]
}
]
}
確認してみる
翌日、S3バケットを確認したところ、CSV形式で正しく保存されていました。

中身も問題なくCSV形式であることが確認できました。
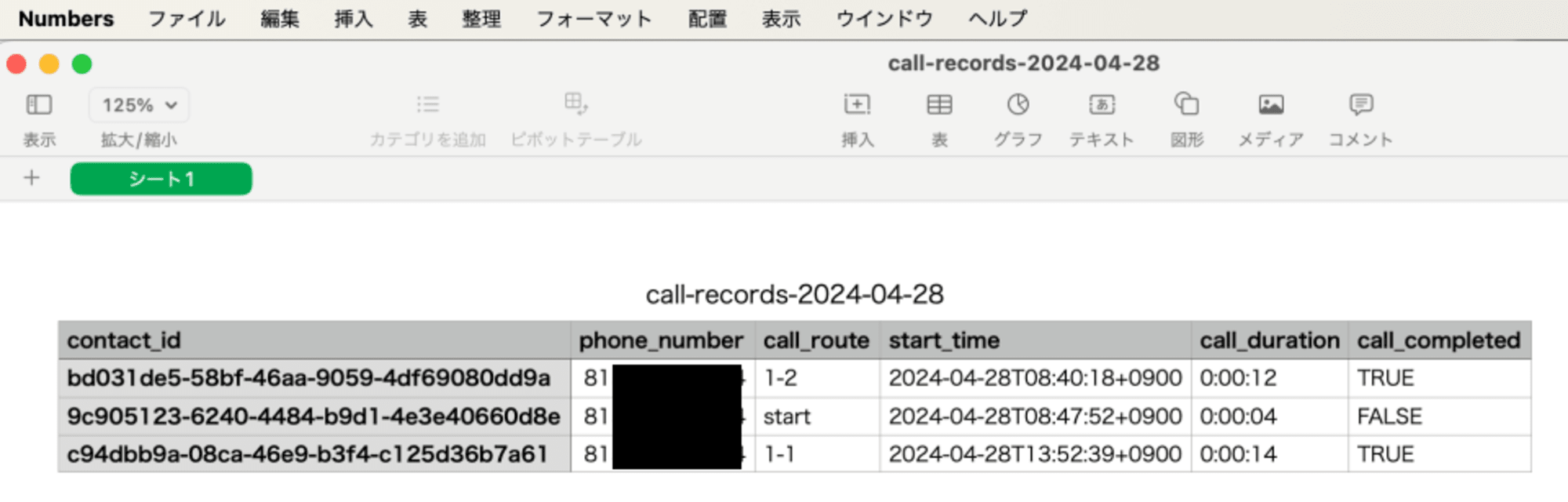)
Lambdaのログ(EventBridge Schedulerから受け取るイベント内容)は以下の通りです
{
"version": "0",
"id": "a0662d21-0082-48cf-8674-a39e2c497ffa",
"detail-type": "Scheduled Event",
"source": "aws.scheduler",
"account": "xxxxxxxxxxx",
"time": "2024-04-28T16:00:00Z",
"region": "ap-northeast-1",
"resources": [
"arn:aws:scheduler:ap-northeast-1:xxxxxxxxxxx:schedule/default/Lambda名"
],
"detail": "{}"
}
timeはUTCです。
最後に
DynamoDBのデータを毎日S3バケットにCSV形式で保存するための実現方法を紹介しました。
本記事では1日分のデータ処理を紹介しましたが、DynamoDBの属性やLambdaのコード、EventBridge Schedulerを修正することで1週間や1ヶ月分のデータ処理も可能です。
CSV形式で出力後は、DynamoDBのデータはTTL(Time to Live)機能で自動削除してもよいです。
参考になれば幸いです。








