![[AWS Data Pipeline]S3上の任意のシェルを実行しジョブを連携させる](https://devio2023-media.developers.io/wp-content/uploads/2014/05/AWS_Data_Pipeline.png)
[AWS Data Pipeline]S3上の任意のシェルを実行しジョブを連携させる
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コンニチハ、千葉です。
AWS Data Pipelineを使って任意のシェルを実行してみましたのでご紹介します。
AWS Data Pipelineはジョブスケジューラとして利用でき、失敗した時に実行する処理、成功した時に実行する処理を定義することができます。 具体的にはバックアップ処理やETL処理をなどに利用されたりします。
今回は、Data Pipelineを使ってS3上に配置した任意のシェルを実行してみます。やりたいことは以下です。

やってみた
作業サマリです
- S3バケット作成と実行シェルの配置
- パイプラインの作成
- シェル1の定義
- シェルを実行するEC2の定義
- シェル2の定義
- EC2削除の定義
- 通知設定
S3バケットの作成と実行シェルの配置
実行するシェルを配置するS3バケットを用意し、シェルを配置します。

ダミーのシェルで以下を配しました。echoするだけです。
シェル1
#!/bin/bash echo "My name is shell 1"
シェル2
#!/bin/bash echo "My name is shell 2"
パイプラインの作成
パイプラインを作成します。マネージメントコンソールのData Pipelineの画面から「Create new pipline」をクリックします。

パイプライン名、ジョブ実行開始時刻、パイプラインのログ保存について適宜設定します。

ジョブの設定画面に移行するので、こちらから各ジョブを定義していきます。

シェル1の定義
シェル1を実行するジョブを追加します。任意のシェルを実行する場合は「ShellCommandActivity」を選択します。

「Add an optional field...」より、以下のオプションを追加します。※オプションの詳細はShellCommandActivityを参照
- Runs On
- Script Uri

シェルを実行するEC2の定義
シェルを実行するためのEC2を定義します。TypeをEC2にします。起動するAMIやリージョン、インスタンスタイプを適宜設定します。※オプションの詳細はEc2Resourceを参照

シェル2の定義
シェル1と同じく「Add」から「ShellCommandActivity」を追加します。シェル1との違いはオプションに「Depends On」を追加し、「シェル1」を指定する箇所です。これで、シェル1が実行されたあとにシェル2が実行される用意なります。

EC2削除の定義
シェル2が終了したタイミングでEC2の削除を行います。が、特に削除に関する定義しなくてもパイプライン終了後はEC2が自動で削除されました
逆に「actionOnTaskFailure」や「terminateAfter」を指定することで削除しないような設定ができそうでした。
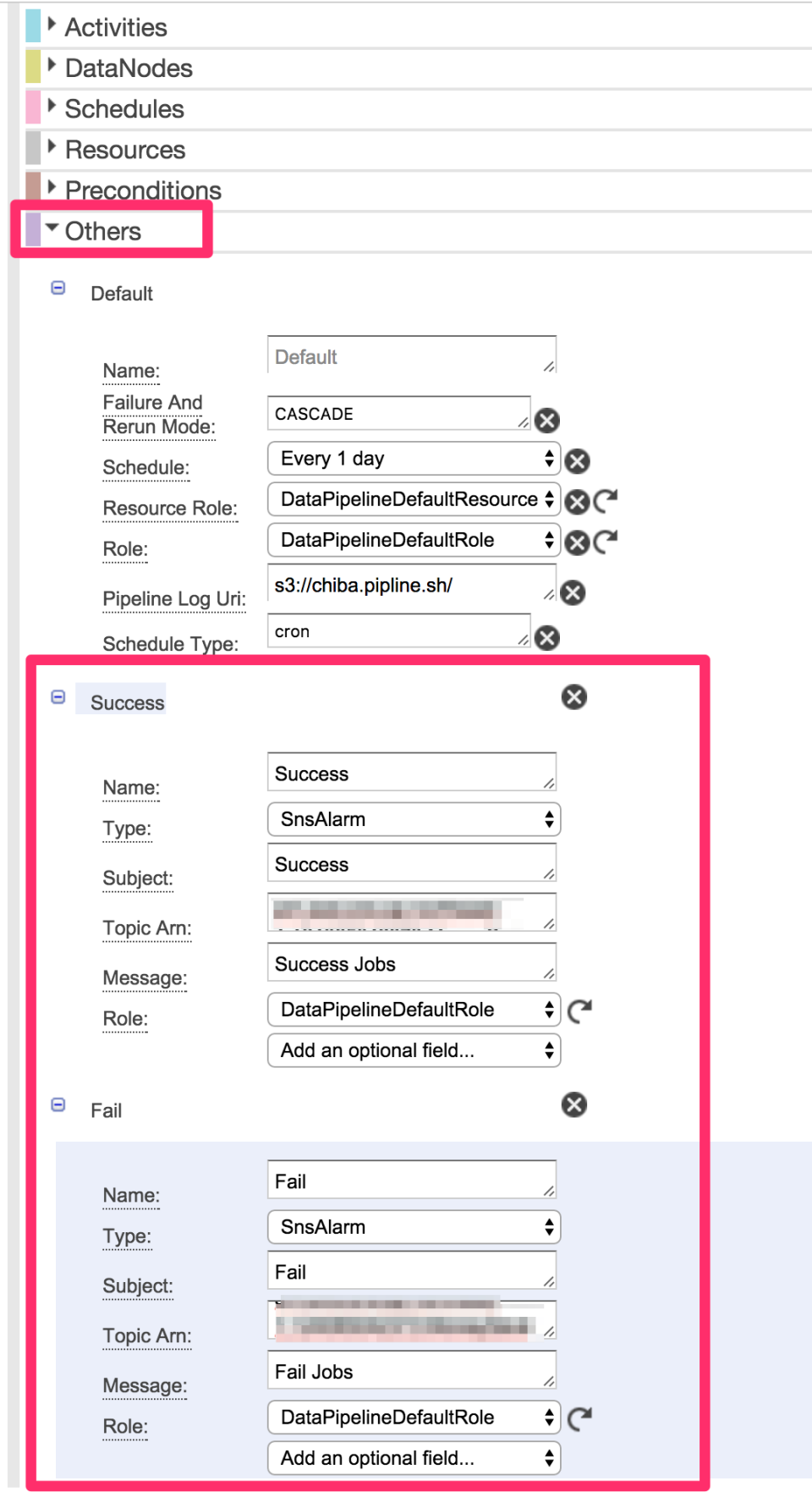
通知設定
通知は、シェル2が終了したタイミングで成功 or 失敗で通知を行います。以下のオプションを追加します。
- On Success
- ON Fail

次に「Others」を選択すると指定したアクションを設定できます。SNSでメール通知するように設定します。SNSトピックは別途作っておく必要があります。
最終的なフロー
最終的にはフローは以下のようになりました。

実行ログを見てみる
マネージメントコンソールでの表示
各ジョブのステータスや標準出力等のログを確認することができます

メール
設定した通りメールも受信しました

最後に
Data Pipelineを使ったジョブスケジューラを試してみました。S3上に配置した任意のシェルを実行できるので汎用性が高く、柔軟なジョブ作成ができるかなと思います。 定期実行するようなシンプルなジョブについてはこちらで対応できそうです。
参考
http://docs.aws.amazon.com/ja_jp/datapipeline/latest/DeveloperGuide/what-is-datapipeline.html








