
JMeterの実行結果CSVデータをローカルMacにたてたElasticsearchとKibanaで可視化する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
「JMeterの結果CSV、216万行か〜。これくらいだったらJMeterの「グラフ表示」で読み込んで見られるかな〜」
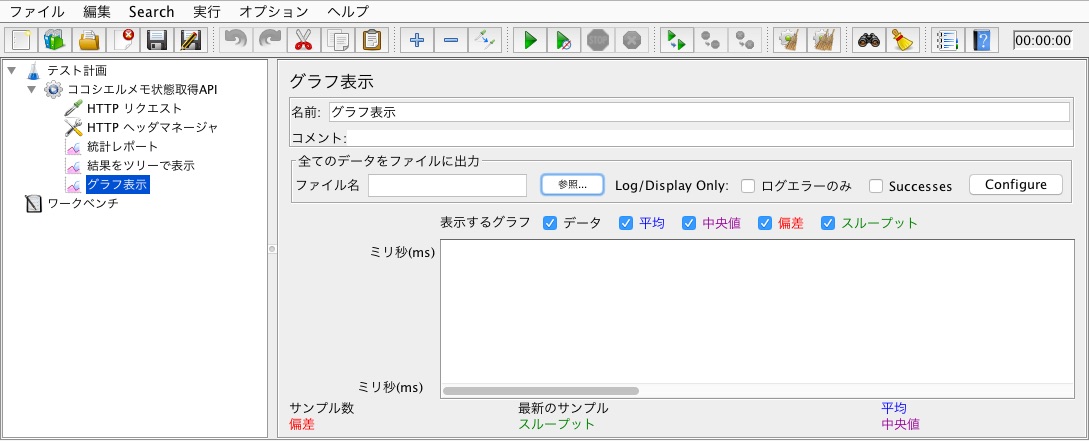
CPU「ブオオオオオオオオン!」
はじめに
システムの負荷試験において、Apache JMeterのようなツールを使って試験を実施・結果を出力するケースもあると思います。結果ファイルのサイズがそれほど大きくない場合は、全データを計算する(JMeterでいう「統計レポート」)で問題ありませんが、例えば、長時間負荷をかけたので時系列でデータをグラフ化したい、といったことになると事情が変わってきます。JMeterの結果CSVは手元にあるので、なんとかこれを活用したいところではありますが、数百万行レベルのデータになると、とたんにExcelなどでは辛くなります(というか最大行数的に無理な気がします)。
そこで、ちょうど、弊社木戸がElasticsearchシリーズを連載しているところですし、ElasticsearchとKibanaを使って可視化してみることにします。Elasticsearch本来の使い方としては、分析用のクラスタが構築されていて、すべてのデータをそこへ投入することが望ましいです。が、パッと使いたいところ、必要なデータが投入されていなかったり、新しくデータを投入するには社内フローを通す必要があったりと、前提条件を満たすのに時間を要する場合もあると思います。手元にちょっとしたデータの分析ができる環境を用意しておくと先々心強いです。そんなもくろみも含めて、今回はJMeterの結果を可視化してみることにします。本記事の目的はあくまでJMeter結果CSVの可視化です。手元での実行可能性を重視しており、Elasticsearchとその周辺技術の掘り下げは行いませんのでご注意ください。
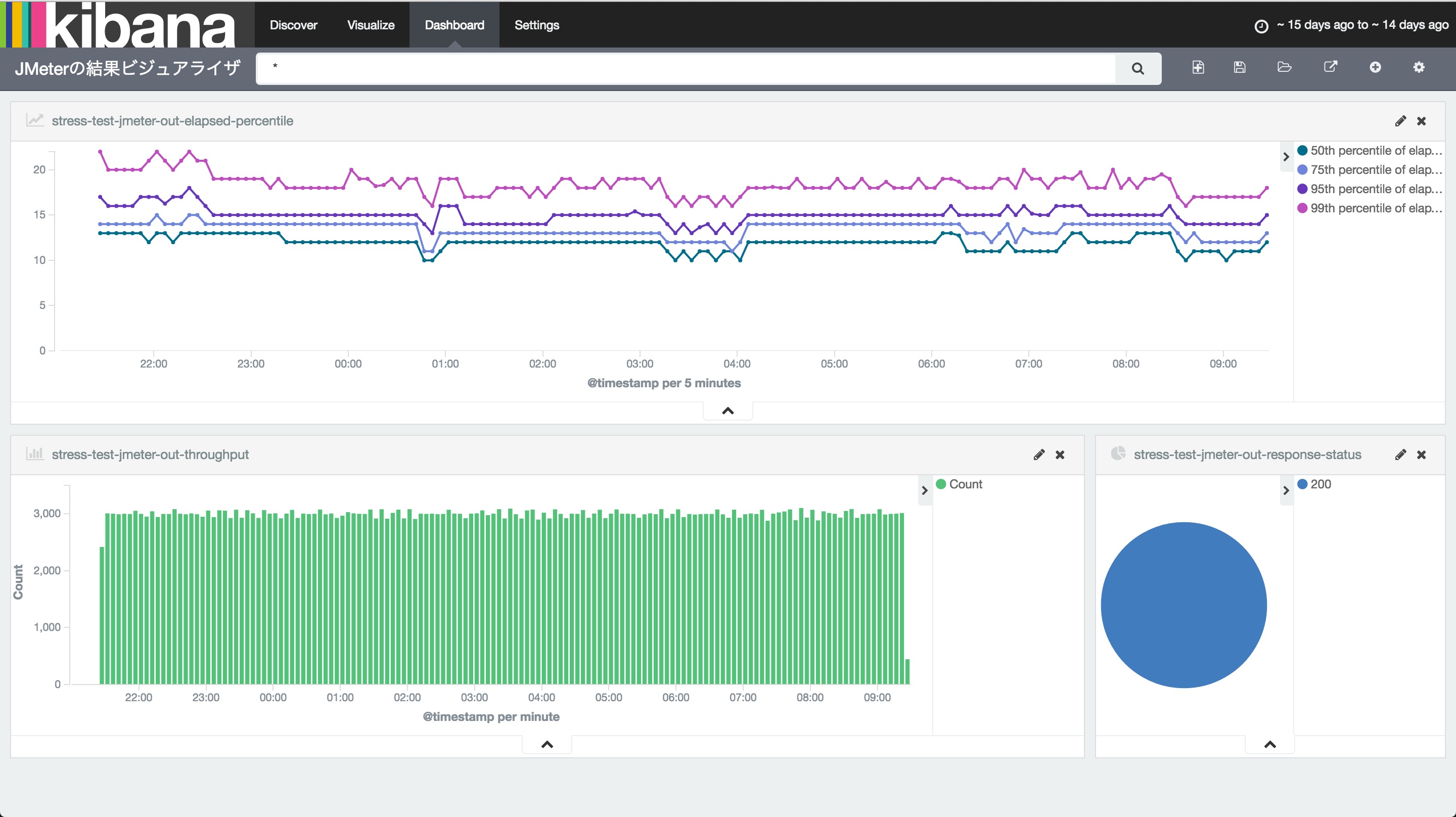
最終的に以下のようなダッシュボードを作ります。
やること
実現するためのステップはそれほど多くありません。順番に見ていきましょう。
- JMeterの結果CSVファイルを用意する
- Logstash, Elasticsearch, Kibanaをダウンロードする
- Logstashの設定ファイルを作成してデータを投入する
- Kibanaで処理時間、スループット、レスポンスステータスをビジュアライズする
- Kibanaでダッシュボードを作る
ローカルに構築する分析基盤は下図のような構成になります。使う道具について簡単に説明します。
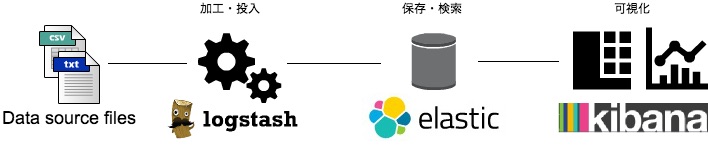
Logstash
ログ収集、Elasticsearchのフィールドへのマッピング、Elasticsearchへのデータ投入を担います。
Elasticsearch
スケーラブルな検索サーバです。DB、といってしまうと乱暴ですが、役割は検索対象のデータを保存し、クエリを発行して検索できるようにすることです。すべての操作がRESTで可能という特徴があります。このため、LogstashやKibanaをはじめとして周辺ツールが非常に充実しています。
Kibana
Elasticsearchでの検索結果を対象として、データをグラフや表で可視化できるツールです。
これら3つは今回のようにセットで利用されることが多いため、まとめてELKとよびます。
JMeterの結果CSVファイルを用意する
JMeterを利用した負荷試験を実施します。コマンドラインで実行する際に、-lオプションを付与することで結果をファイルへ出力することができ、かつ、バージョン2.9からは結果ファイル形式のデフォルトがXMLからCSVへ変更になったので、出力されたファイルがそのまま利用できます。今回は216万行のデータがあるCSVファイルを出力し、これを使うこととします。
jmeter3/bin/jmeter -n -t test.jmx -l jmeter-out.csv
-nコマンドラインで実行する-tテスト実行のための設定ファイルを指定する-lテスト実行の結果ファイルを指定する
Logstash, Elasticsearch, Kibanaをダウンロードする
ダウンロードさえすればすぐに利用可能な状態になるので、非常に簡単です。それぞれのサイトへ行きダウンロード&解凍します。
私は適当に~/optディレクトリをつくり、そこへすべて解凍しました。
$ tree ~/opt/ -d -L 1 ~/opt/ ├── elasticsearch-2.3.3 ├── kibana-4.5.1-darwin-x64 └── logstash-2.3.2
Logstashの設定ファイルを作成してデータを投入する
CSVファイルは、そのままではElasticsearchで利用できません。Elasticsearchでデータ解析をできるようにするにはフィールドを定義する必要があり、CSVのカンマで句切られた個々のデータを、フィールドの概念に対応付ける必要があります。そこで、Logstashが登場します。Logstashの仕事は大きく3つです。
- ① 入力元となるファイルの情報を指定する
- ② 入力元ファイルのデータを、Elasticsearchのデータにマッピングする
- ③ データを転送(ここではローカルのElasticsearch)する
設定ファイルを作成する
①②③の仕事を行うための設定ファイルを用意します。
input { # -- (1)
file {
path => "~/opt/jmeter-out.csv" # -- (1-1)
start_position => "beginning" # -- (1-2)
sincedb_path => "/dev/null" # -- (1-3)
}
}
filter { # -- (2)
csv {
columns => ["timeStamp","elapsed","label","responseCode","responseMessage","threadName","dataType","success","failureMessage","bytes","grpThreads","allThreads","Latency","IdleTime"] # -- (2-1)
separator => "," # -- (2-2)
}
date { # -- (2-3)
match => [ "timeStamp", "UNIX_MS" ]
}
mutate { # -- (2-4)
convert => {
"elapsed" => "integer"
"Latency" => "integer"
"IdleTime" => "integer"
}
}
}
output { # -- (3)
elasticsearch {
hosts => ["localhost:9200"]
index => "jmeter-out"
}
}
- (1) input: 入力情報です。今回はファイルを指定します。Logstashの仕事①に相当します。
- (1-1) path: ここでファイル名を指定します。
- (1-2) start_position: ファイルの読み込みを開始するポジションを指定します。
beginningかendを指定でき、今回のように初回読み込みを一度行うような場合はbeginningを指定します。逆に、継続的に更新されていくログファイルなどを読みこませる場合はendを指定します。デフォルトはendです。 - (1-3) sincedb_path: Logstashは継続的にデータを投入する機能をサポートしており、「入力ファイルの何行目までを処理したか」という情報を持ちます。その情報を記載するためのファイルパスをここで指定するのですが、今回は一度最初から最後まで読みきってしまえばそこでLogstashの仕事は終わりです。セーブポイントを設ける必要はありませんので、
/dev/nullを指定します。 -
(2) filter: Elasticsearchへ投入するためのデータ変換の定義をここに書きます。Logstashの仕事②に相当します。
- (2-1) columns: CSVファイルのカンマ区切り項目それぞれを、何というフィールド名にマッピングさせるか書きます。JMeterの出力CSVファイルを見てください。1行目に項目名が記載されているはずです。それをそのまま使えばOKです。
- (2-2) separator: 項目のセパレータです。CSVなのでノータイムでカンマです。
- (2-3) date: タイムスタンプとしてどのフィールドを使うか指定します。
-
(2-4) mutate: 重要です。ここにデータの変換ルールを記載します。今回の場合、この設定なしだとすべてのフィールドを文字列として解釈してしまいます。これでは、平均値や95%点など、数値計算を利用した集計を行うことができなくなります。Kibanaで可視化する際、集計したいデータはここで数値に変換します。
-
(3) output: データ出力先の情報です。今回はElasticsearchです。URLとインデックス名を指定します。仕事③に相当します。
データを投入する
設定ファイルができれば、あとはデータを投入するのみです。早速投入します…といきたいところですが、まずはElasticsearchとKibanaを起動しておきます。
$ elasticsearch-2.3.3/bin/elasticsearch
[2016-06-07 12:45:31,270][INFO ][node ] [Amalgam] starting ...
[2016-06-07 12:45:31,363][INFO ][transport ] [Amalgam] publish_address {127.0.0.1:9300}, bound_addresses {[fe80::1]:9300}, {[::1]:9300}, {127.0.0.1:9300}
[2016-06-07 12:45:31,370][INFO ][discovery ] [Amalgam] elasticsearch/vF8fNm4pRLeU23dpWk2Q0g
[2016-06-07 12:45:34,416][INFO ][cluster.service ] [Amalgam] new_master {Amalgam}{vF8fNm4pRLeU23dpWk2Q0g}{127.0.0.1}{127.0.0.1:9300}, reason: zen-disco-join(elected_as_master, [0] joins received)
[2016-06-07 12:45:34,428][INFO ][http ] [Amalgam] publish_address {127.0.0.1:9200}, bound_addresses {[fe80::1]:9200}, {[::1]:9200}, {127.0.0.1:9200}
[2016-06-07 12:45:34,428][INFO ][node ] [Amalgam] started
$ kibana-4.5.1-darwin-x64/bin/kibana log [14:36:35.091] [info][status][plugin:kibana] Status changed from uninitialized to green - Ready log [14:36:35.117] [info][status][plugin:elasticsearch] Status changed from uninitialized to yellow - Waiting for Elasticsearch log [14:36:36.519] [info][status][plugin:timelion] Status changed from uninitialized to green - Ready log [14:36:36.523] [info][status][plugin:kbn_vislib_vis_types] Status changed from uninitialized to green - Ready log [14:36:36.529] [info][status][plugin:markdown_vis] Status changed from uninitialized to green - Ready
次に、投入対象ファイルの1行目はヘッダ情報ですので、削除します。
$ sed -i -e '1d' ~/opt/jmeter-out.csv
準備完了です。投入します。
$ logstash-2.3.2/bin/logstash -f ~/opt/csv.conf Settings: Default pipeline workers: 4 Pipeline main started
データの投入が始まります。かなりCPUを使いますが10分かからずに完了するはずです。途中、インデックスが作成されているかElasticsearchにリクエストを投げて確認してみましょう。
$ curl 'http://localhost:9200/_cat/indices' yellow open jmeter-out 5 1 2160000 0 391.3mb 391.3mb yellow open .kibana 1 1 7 0 38.4kb 38.4kb
無事、インデックスが作成されていますね。2160000がインデックス済みレコード数です。これが投入元データの行数と一致していれば読み込み完了です。
Kibanaでレスポンスタイム、スループット、レスポンスステータスをビジュアライズする
以下のような流れで進めます。
- ビジュアライズ対象のインデックスを指定する
- レスポンスタイムのグラフを作成
- スループットのグラフを作成
- レスポンスステータスの円グラフを作成
インデックスを指定する
データ投入が終わりました。投入されたデータを使って、ビジュアライズしてみます。ブラウザでhttp://localhost:5601/へアクセスしてください。以下のような画面が出ます。Index name or patternに完全一致で先ほど作成したインデックス名を入れると、下部のボタンがアクティブになりますのでクリックします。これでKibanaがインデックスを認識します。
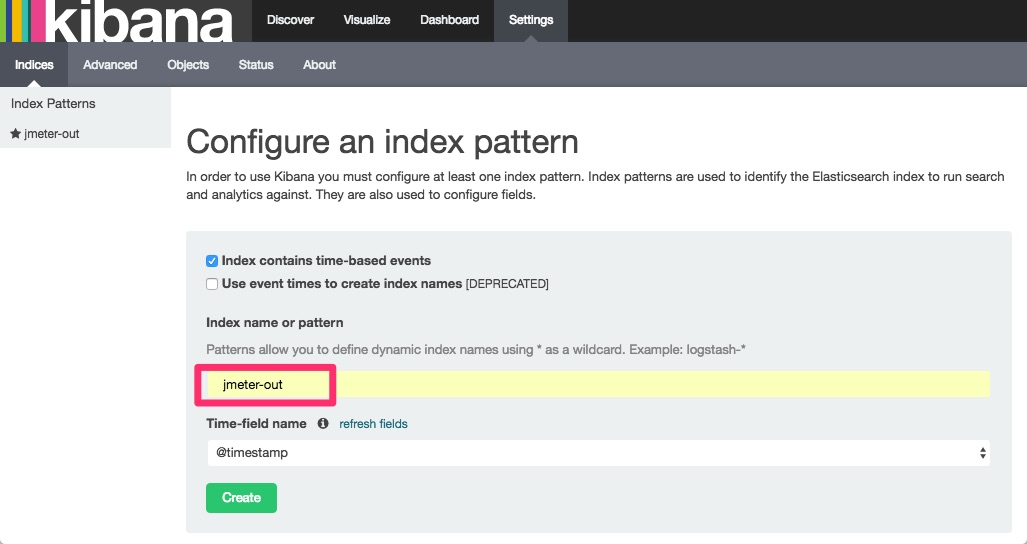
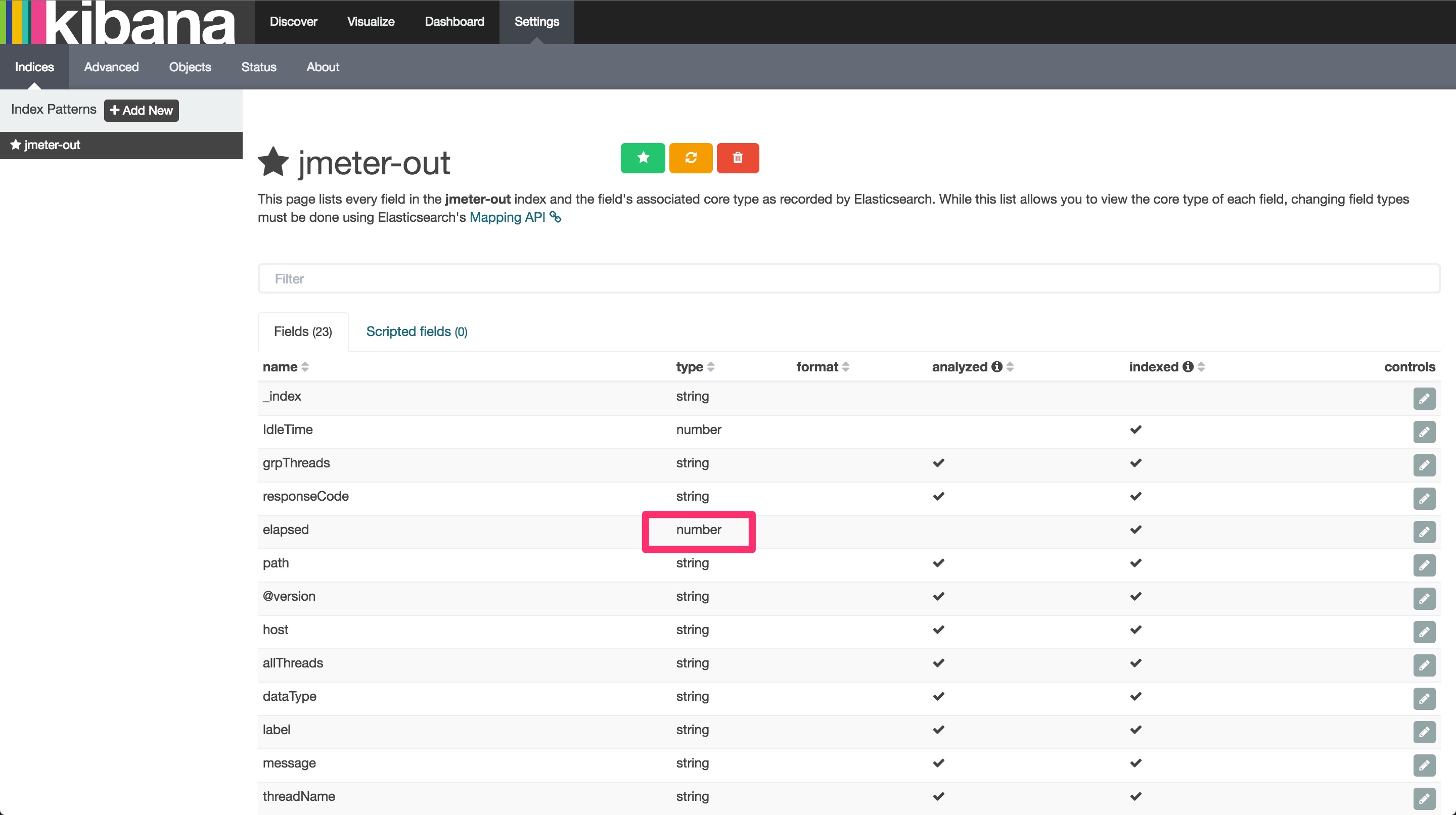
インデックスの情報を見ると、Elasticsearchが認識しているフィールドの一覧が出ます。解析したいデータのtypeがnumberとなっていることが確認できます。
レスポンスタイムのグラフを作成
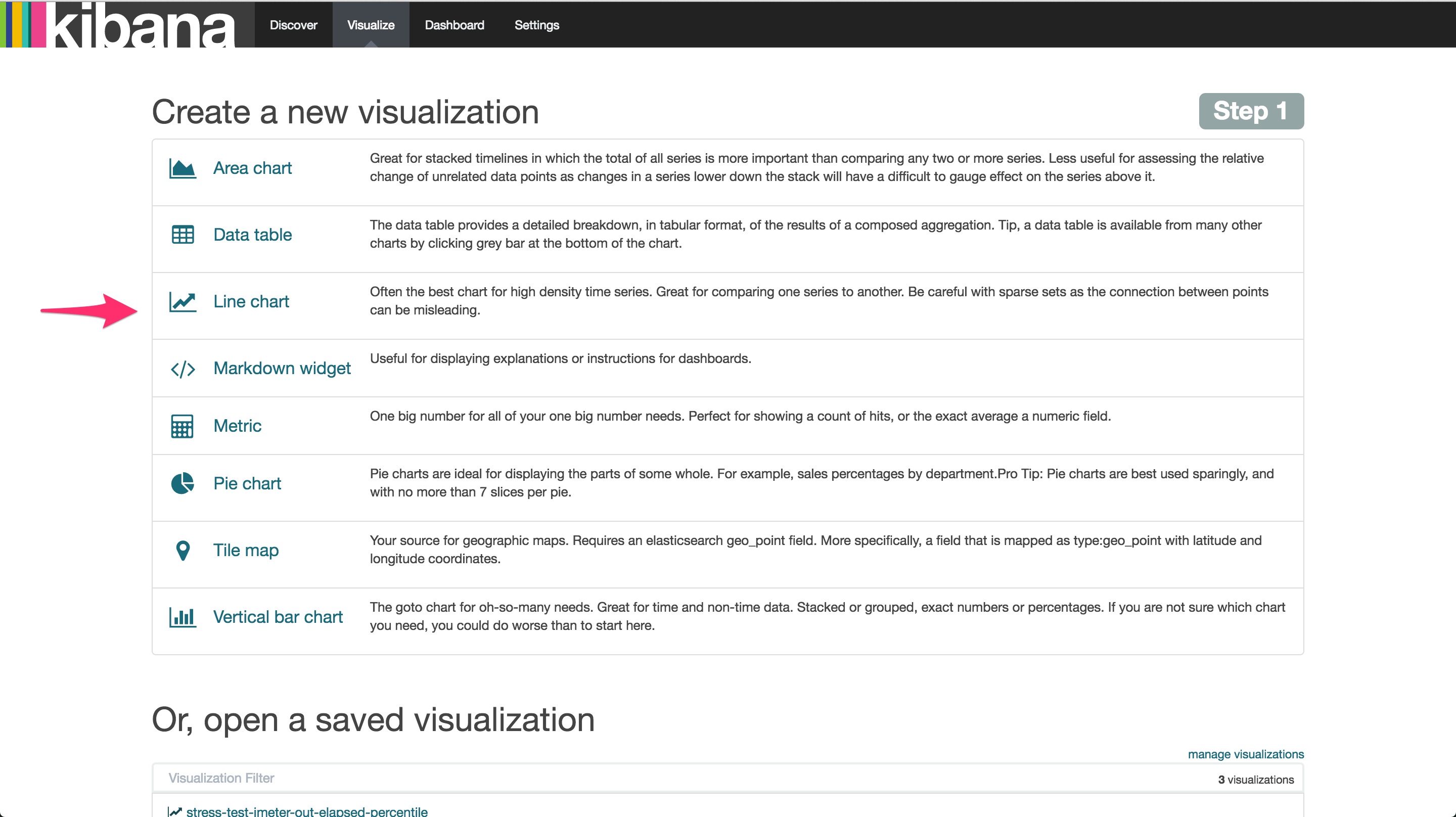
レスポンスタイムのグラフを作りましょう。まず、上部メニュー「Visualize」をクリックします。すると、「どのタイプのビジュアライズを行うか」という選択画面が出ますので、「Line Chart」を選びます。次の画面は「From a new search」を選択します。
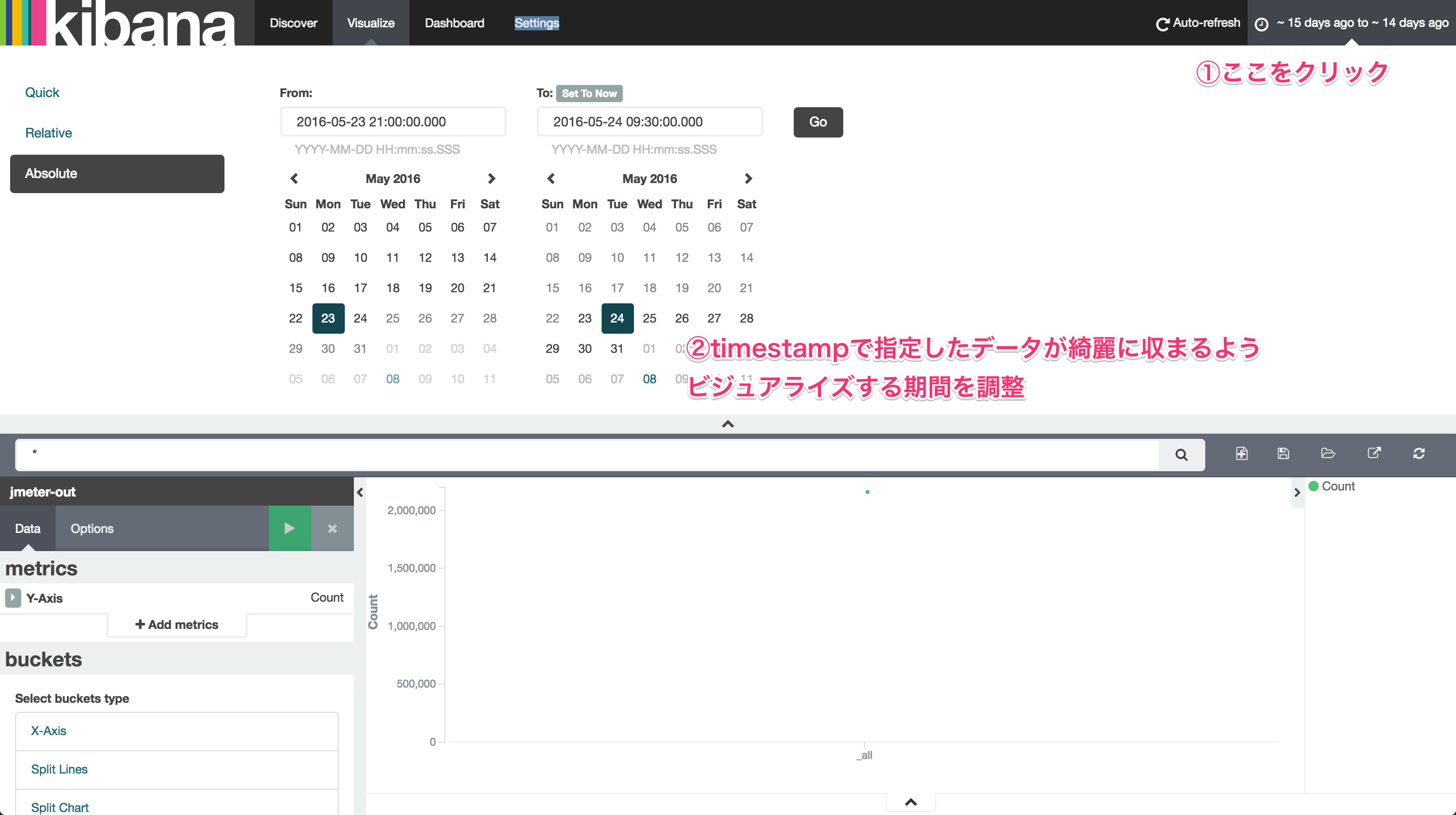
すると、ビジュアライズするための画面へ遷移します。ここでは最初に対象となる期間を指定します。右上部をクリックして、ビジュアライズしたいデータが綺麗に収まるよう、絶対時間範囲で指定しまうのがよさそうです。
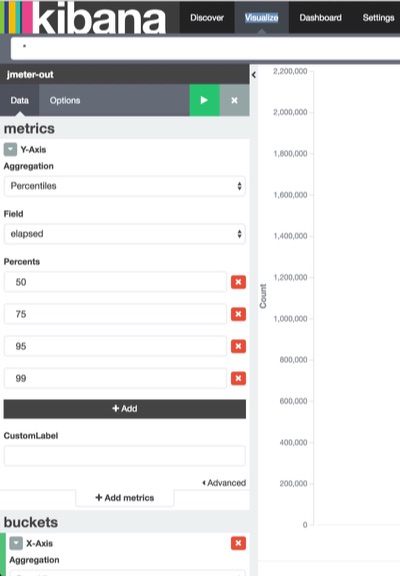
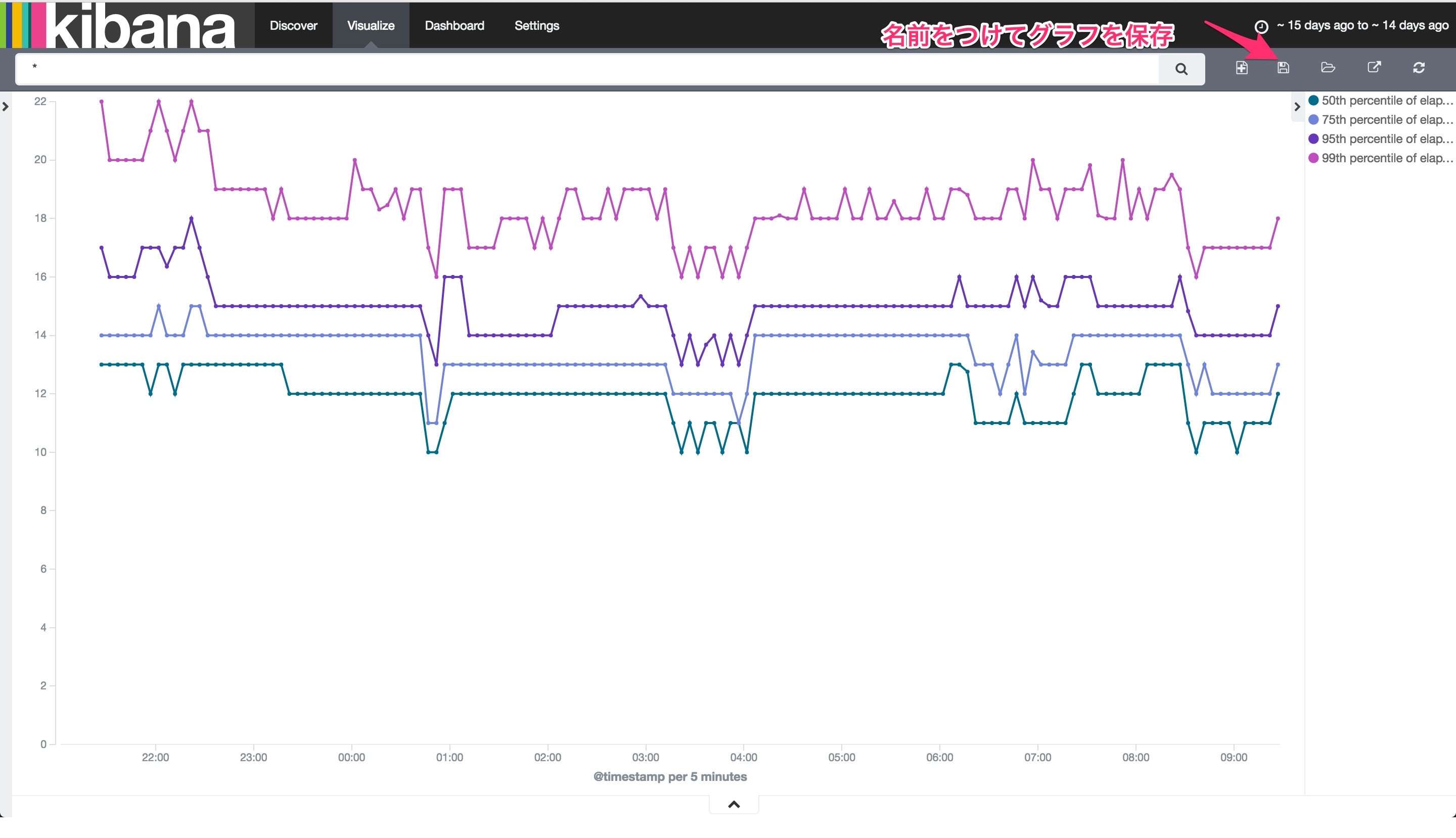
お膳立てが終わりました。X軸とY軸を調整します。まずはY軸です。実行時間のパーセンタイルの値が欲しいので、以下図のようにパーセンタイルの軸を定義します。利用する値はelapsedです。
次にX軸です。時系列でみたいのでAggregationをDate Histogram、分刻みのプロットを打ちたいためIntervalをMinuteとします。ここまでできたら、XY軸設定の上部にあるRunボタンを押しましょう。
パーセンタイルの折れ線グラフが表示されるはずです。どんなものでも目に見えるようになる瞬間というのは嬉しいものですね!作成したグラフは保存します。後でダッシュボードを表示するときに使います。
スループットのグラフを作成
次に、スループットのグラフを作成します。Visualizeをクリックして新しくグラフを作ります。今回はVertical bar chartにしてみましょう。時間範囲、そしてX軸にDate Histogramを指定する点は同じ。Y軸の指定だけが違います。ここは単位時間あたりにさばいたリクエストの数がわかれば良いので、Y軸にはcountを指定すればよさそうです。
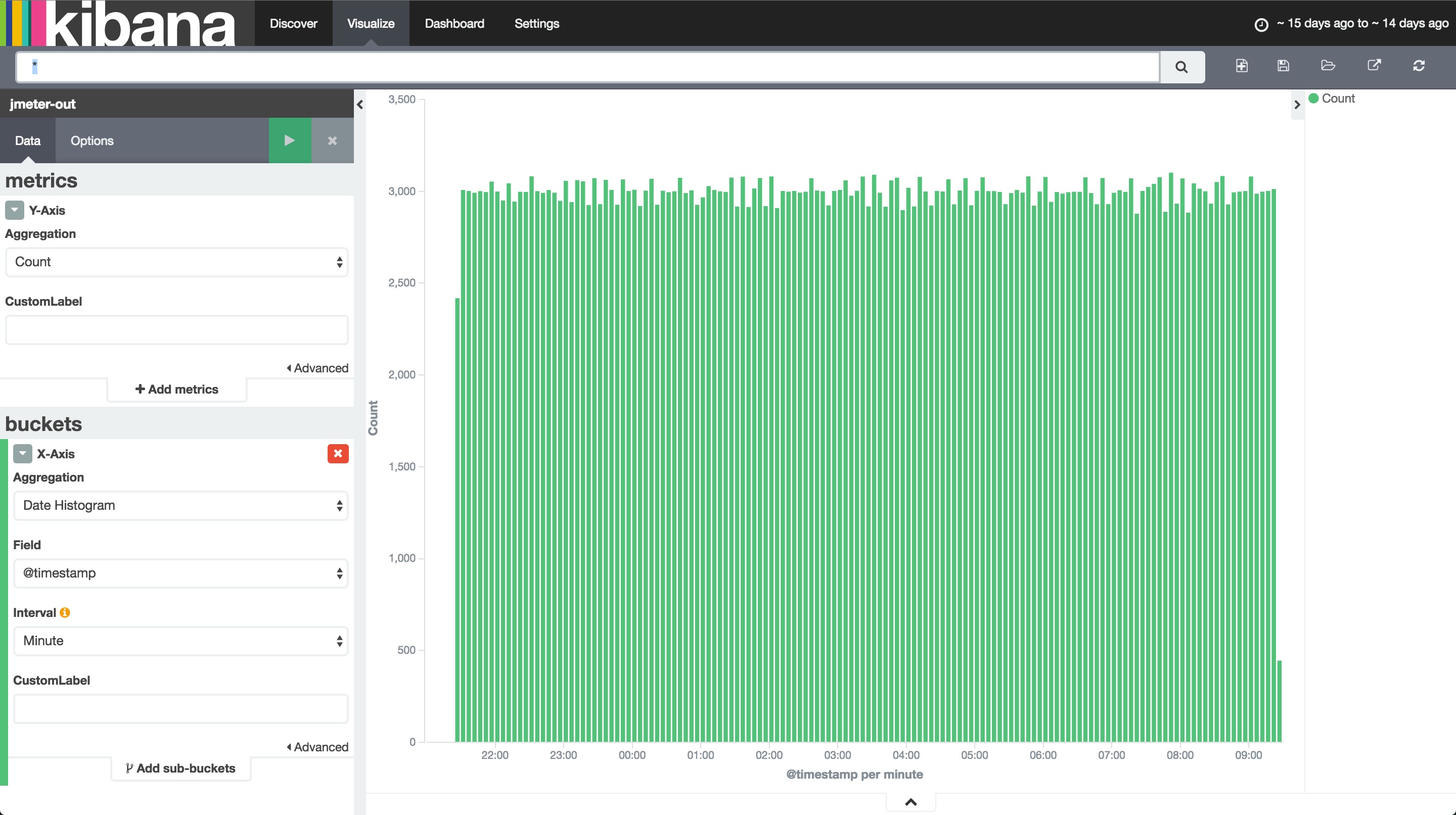
レスポンス時間と同じように名前をつけて保存しておきます。
レスポンスステータスの円グラフを作成
今回はすべて「200」になっていることを期待していますが、シナリオベースのテストをする場合など、400系、500系のエラーを期待するテストがあるかもしれません。レスポンスステータスごとの割合を示すための円グラフを作ってみましょう。
Visualize -> Pie chartとします。例によって作成したら名前をつけて保存しておきます。
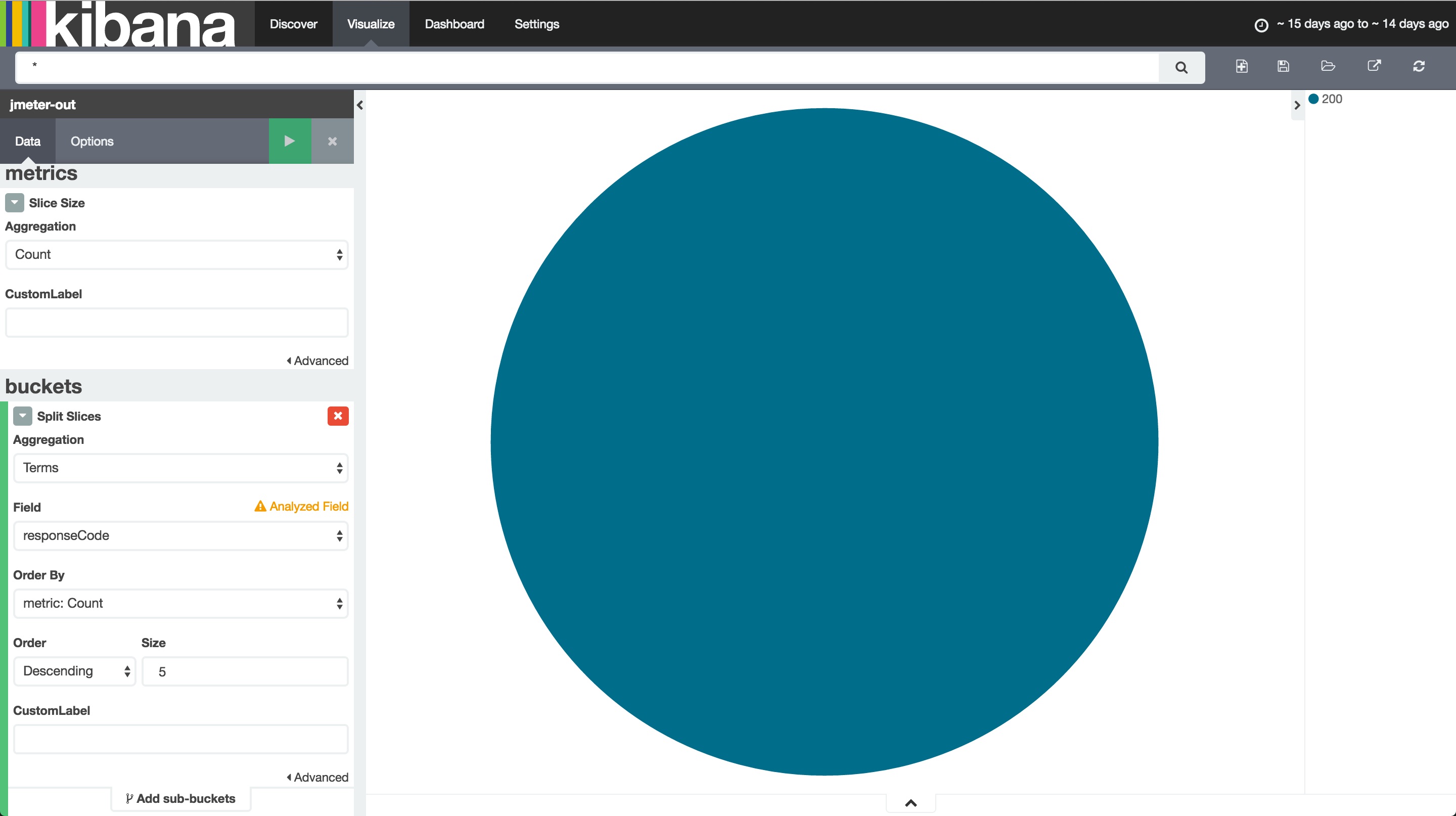
- metrics/Slice Size: 数でチャートを作りたいのでcountを指定します。
- buckets/Split Slices: 分割する方法を指定します。ユニークな値ごとに集計したいため、
Termsを選びます。FieldはresponseCodeに、Order By はCount、Order:Descending、Size:5とします。これで、「ユニークなresponseCodeの数を集計し、合計数が多い方から5つ、円グラフに表示する」という意味になります。
Kibanaでダッシュボードを作る
チャートさえ作ってしまえば、ダッシュボードはそれをはめこむだけで作れます。上部Dashboardをクリックし、クエリフォームの横にある+ボタンを押しましょう。
どのチャートを選択するか聞かれるので、作成したチャートをひとつずつすべて選択します。
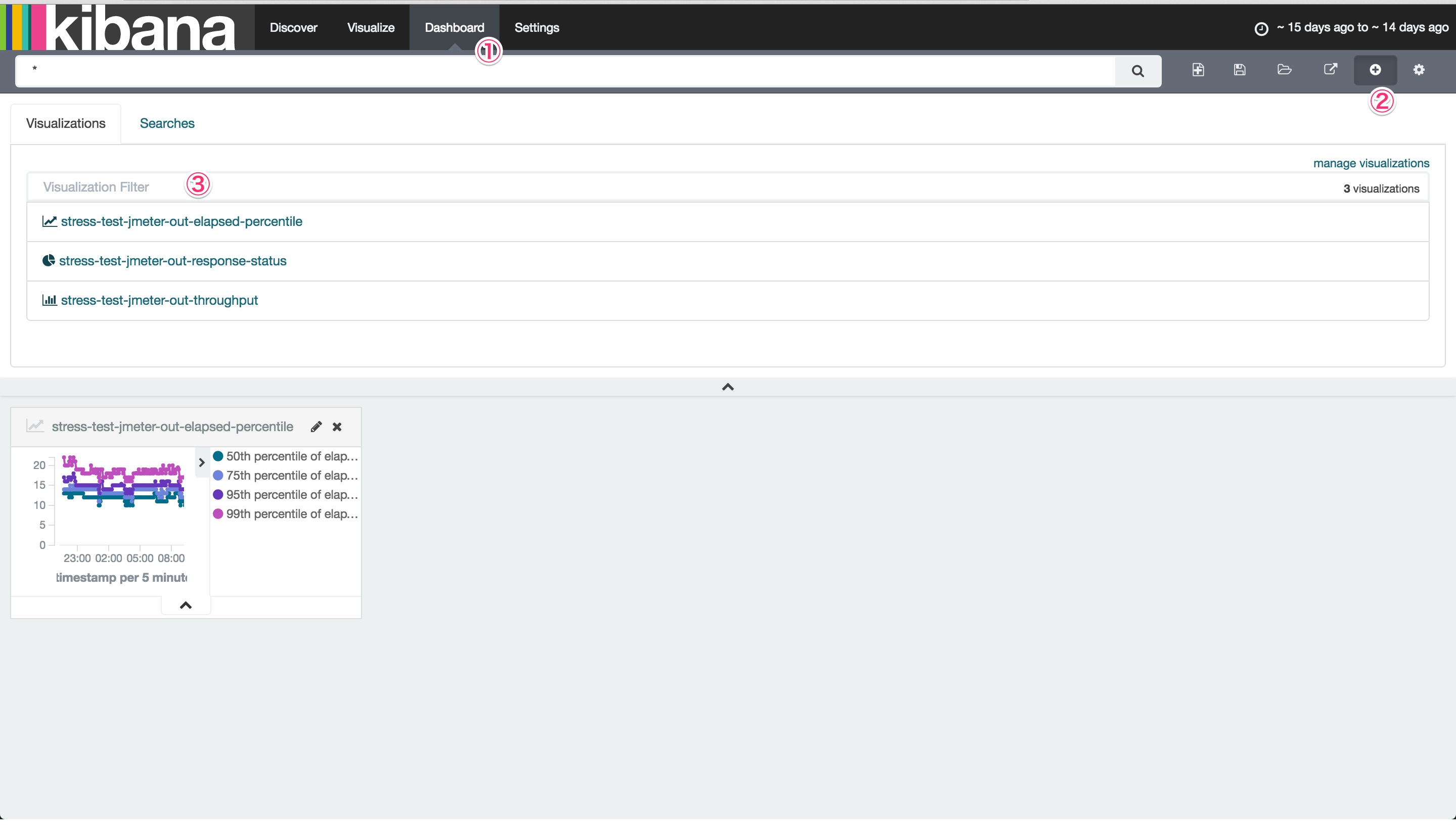
あとは、それぞれのチャートのサイズが自由に調整できるので、好みの大きさに変えてください。最後にダッシュボードに名前をつけて保存すれば完成です。このまま負荷試験のレポートとして提出してやりましょう。
おわりに
- JMeterの結果を可視化したい
- ElasticsearchとKibanaを使ってみたい。あわよくば手元で使える分析基盤としていつでも使えるようにしておきたい。
今回はこれらの要件がうまく噛み合い、Kibanaを使ってみることができました。JMeterでは結果のHTML出力機能などもあるようですが、自分の得意とする可視化ツールに落としこむ術を知っておくと、いろいろなデータソースに対して応用できるので、将来的なことも含めトータルで見るとElasticsearch+Kibanaでやるほうがお得かなと感じます。また、今回はElasticsearchの目玉機能のひとつであるクエリによる絞り込みを行っていません。可視化の対象がすべての試験結果データだったためです。例えば、失敗したテストだけ所要時間やレスポンスステータスを見たい、といった場合や、シナリオテストで特定のシナリオに絞って結果を見たい、といった要件が発生した場合にクエリが活躍することでしょう。さらに、Logstashは投入したきり終わりではなく継続的にファイルを監視、更新されたら都度投入といったことをやってくれるため、負荷テストの結果をひとつのファイルに集約、Elasticsearchに全投入といったケースにも応えられそうです。夢が広がりますね。
がっつり使おうとすると本当に奥が深いツールですが、「まずさわってみたい!」という方がとりかかるきっかけになれば幸いです。










