Sumo Logic – FER(Field Extraction Rules)の作成方法と注意点について
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
記事の内容が古い場合は、公式サイトもご確認ください。
Sumo Logic については以下をご参照ください。
最初に
Sumo Logic では、メッセージデータ(ログ・メトリクス)を受信したときに以下の順でデータを評価します。

※ 今回はフィールド抽出ルール(Field Extraction Rules)をご紹介します!
FER(Field Extraction Rules)について
Sumo Logic に配信されてくるログメッセージは、JSON、XML、CSV などのデータ構造体です。
フィールド抽出ルール (FER) は、こういった生データの必要な部分だけをパースして「フィールド:値」として抽出してくれます。

FER で抽出したデータは、後の工程でインデックスが作成されます。
FER は、作成時点以降のメッセージデータに適用されます。 そのため、早い段階で設定することが推奨されています。 また、FER を作成・変更した場合、ルールは即時適用されます。
FER 作成時の注意点
FER の作成には、以下の制限や、作成のベストプラクティスがあります。
FER 作成に必要なロール
- Manage field extraction rules
「フィールドの管理」、「フィールドの表示」、「フィールド抽出ルールの表示」に関する権限です。
FER の制限
- FER の数は、最大 50 件まで
- FER に指定可能なフィールド数は、最大 200 個まで
- 式は、最大 16k (16,384) 文字まで
FER 管理画面の下部に上限・使用数・使用率が表示されます。
![]()
また、フィールドの制限は、アカウント単位です。
Field 管理画面の下部に上限・使用数・使用率が表示されます。
![]()
FER のベストプラクティス
- 正確なキーワードを含める
- 用途に応じて複数のルールを作成 & 適用する
- 不要なフィールドを抽出させない
- ルールを作成する前にスコープをテストする
- 定義した FER で必要なフィールドが存在しているか確認する
- 複数の FER で、同じスコープ + 同じメッセージデータの同じフィールド名をターゲットにしない
- parse nodrop ステートメントを使用する
データのサブセットを識別するためにメッセージデータ自体のスコープを出来る限り絞って作成してください。 広いスコープを定義すると、解析するフィールドが増えてしまい、不要なフィールドが抽出されてしまう可能性が高まります。
1つの FER で複雑なルールを定義するより、ルールの粒度を細かく区分した複数のルール作りをおすすめします。 明確な用途に応じて作成されたルールは管理しやすくなります。例えば改修した時の影響範囲を最小限に抑えられます。
スコープを絞ったうえで、さらに抽出するフィールドも絞ってください。 必要最低限のデータを選定したフィールドの抽出が推奨されています。
Log Search でフィールドに該当する予定のデータが正常に取得できるか確認してください。
フィールド抽出ルールを作成しても、フィールドが存在していなければデータを取得できません。 抽出したメッセージデータのフィールドが削除・無効化されてないか、確認してください。
この場合、対象のフィールド名に対する FER は、ランダムに 1 つしか適用されないためです。
※ スコープが分離している別々のメッセージデータに対して、複数の FER で同じフィールド名を指定することは可能です。
指定した条件に一致、もしくは一致しないデータの選別が可能になります。 parse operator のオプションとして、ルール式の中で使用可能です。
FER の作成方法
以下のステップで、FER の作成ページに移動します。
① Manage Data > ② Logs > ③ Field Extraction Rules > ④ + Add Rule

すると、以下の FER 作成メニューが右側に表示されます。

① Rule Name
分かりやすいルール名を指定します。
FER は用途に応じて複数作成することになるためです。
② Applied At
パース方式について以下、2タイプのいずれかを選択します。
- Ingest Time
- Run Time
任意の構造データ型をサポートします。パースするための式を記述する必要があります。
FER は最大 50 件、フィールドは最大 200 個までの制限があります。
FER 作成以降のメッセージデータに適用されます。
JSON データ型のみを自動的に解析します。
FER 数、フィールド 数ともに制限はありません。
自動解析モード(Auto Parse Mode)を使用したときに JSON データのみをパースします。
Sumo Logic では、ログ検索する際、JSON 型のみを動的にパースする機能が存在します。
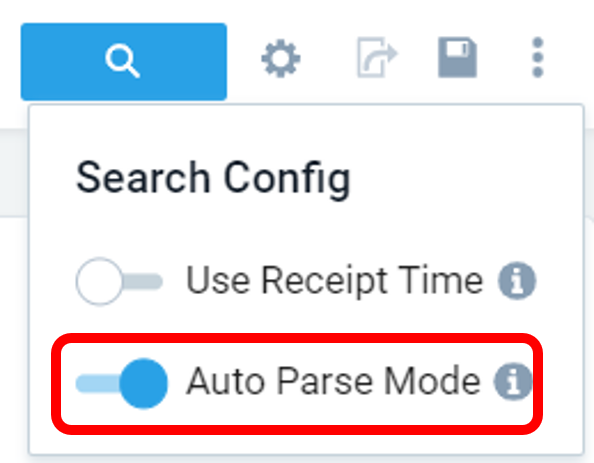
③ Scope
解析対象のログの範囲を決定できます。
設定するログの範囲内部に対して、後述の ④ Parsed template が適用されます。
- All Data
- Specific Data
- Parsed Template(Optional)
すべてのメッセージデータをスコープ範囲内とします。
- Metadata
以下に該当する組み込みメタデータをログの抽出範囲として指定します。

- Value
Metadata のフィールド値を指定します。
例)_sourcecategory=/Prod/NginxWebServer/Access
※ フィールドには、Bool 値、ワイルドカードなどの検索式を使用できます。
詳細は Keyword Search Expressions をご確認ください。
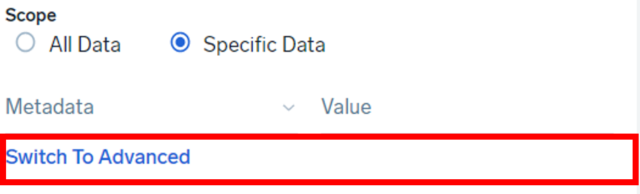
Switch To Advanced を選択すると、すべてを手入力するフォームになります。

② Applied At で、Ingest Time を指定した場合のみ表示されます。
後述の ④ Parse Expression に使用するテンプレート群です。
④ Parse Expression
② Applied At で、Ingest Time を指定した場合のみ表示されます。
サポートされている解析・検索オペレータを使用して、フィールドと値の抽出式を書きます。
例)

オペレータについては、各種以下をご確認ください。
・Search Operators
・Parse Operators
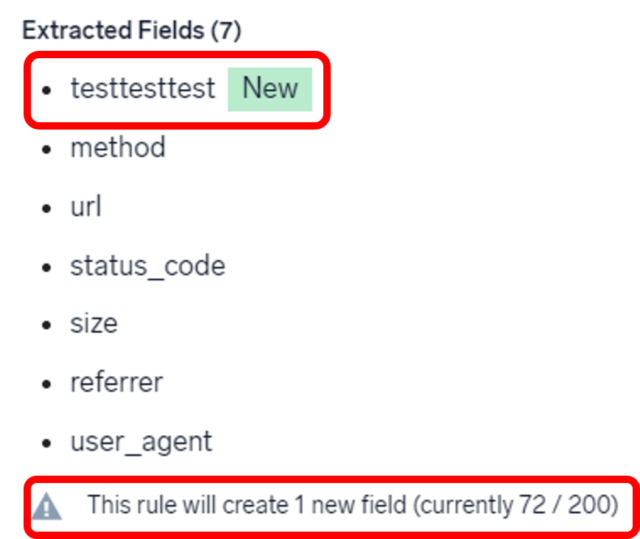
⑤ Extracted Fields
④ Parse Expression で指定したフィールド名が列挙されます。

フィールド抽出ルールで指定されたフィールドは、 フィールドテーブルスキーマに自動的に追加され、有効になります。
まとめ
FER を作成した後は、新たなログを配信するとき以外ほとんど触れない機能になります。 新たなログを配信するときや、そもそも取得する/しているログが多い場合は、複雑になりやすいです。 そのため、しっかりテストしながら細かく設定して、将来的な管理上のオーバーヘッドを減らしたいところです。







