
ECS on EC2でGPUとCPUの簡易ベンチマークを測定してみた
はじめに
みなさんこんにちは、クラウド事業本部コンサルティング部の浅野です。
みなさんはGPUインスタンスを使用したことがありますか?私は使用したことがなく、なんとなく機械学習や画像処理向けに使用するものと思っており、実際の性能イメージを掴めていませんでした。
そこで今回は簡易的なECS on EC2構成にてPyTorch公式のベンチマーク手法を参考にしながらN×Nの行列積を計算し、GPU対応インスタンスと通常の汎用インスタンスで性能を比較してみました。
今回のベンチマーク測定にECSを使用する必要はないのですが、デプロイしやすいのと、あまり自分がECS on EC2を触ったことがなかったのもあり学習がてら使用しています。
以下、ECSに対応しているGPUインスタンスタイプ一覧です。
弊社ブログでもまとめてくれています。
構成
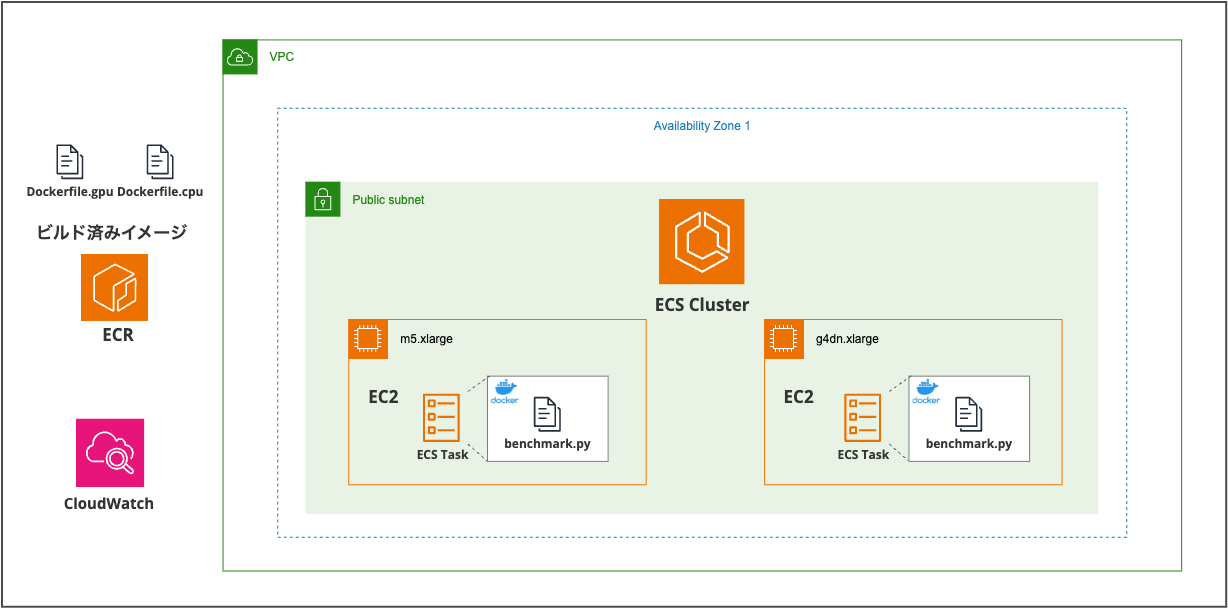
- GPUインスタンスに「g4dn.xlarge」を使用 ※NVIDIA T4 GPU搭載
- 汎用インスタンスに「m5.xlarge」を使用
- CPU用Dockerイメージ、GPU用Dockerイメージをそれぞれ用意しビルドしてECRにPush
- ASGなしの起動設定「EC2」にてECSタスクを起動させ「benchmark.py」を実行して終了
使用インスタンスのスペック(オンデマンド)
※料金は東京リージョンを想定
| インスタンスサイズ | GPU | vCPU | メモリ (GiB) | インスタンスストレージ (GB) | ネットワーク帯域幅 (Gbps) | EBS 帯域幅 (Gbps) | オンデマンド料金/時間* |
|---|---|---|---|---|---|---|---|
| g4dn.xlarge | 1 | 4 | 16 | 1 × 125 NVMe SSD | 最大 25 | 最大 3.5 | 0.71 USD |
| m5.xlarge | 0 | 4 | 16 | EBS-Optimized | 最大 10 | 最大 4.75 | 0.248 USD |
GPUインスタンスを使用するために
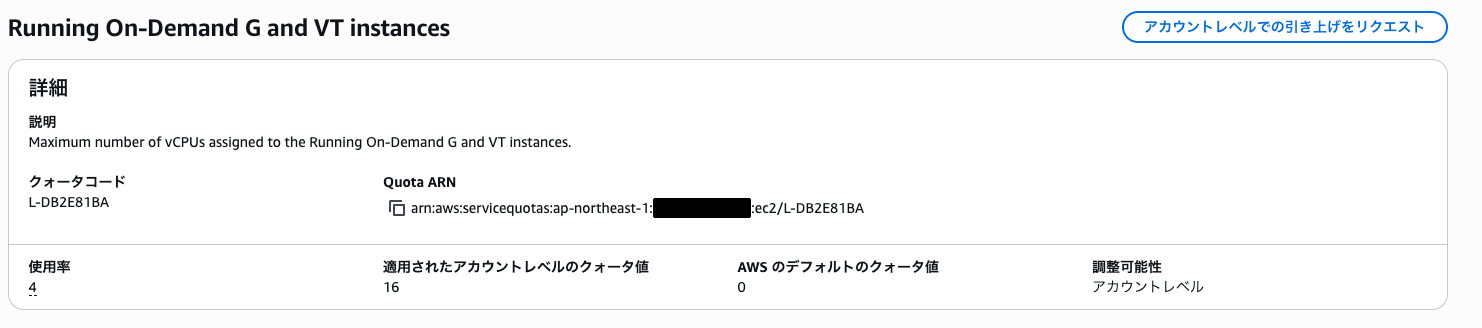
AWS初期アカウントの状態では「Service Quotas」にてG系インスタンスやP系インスタンスはデフォルトのクォータ値が「0」に設定されており、インスタンスを起動できません。
そこで使用したいインスタンスタイプを選択した上で「アカウントレベルでの引き上げをリクエスト」する必要があります。今回使用したいのは「g4dn.xlarge」です。
GPU系のインスタンスでは最も安価かつコスト効率が良いインスタンスタイプなので今回はこちらを選定しました。
リクエストを申請する際に使用したいインスタンス数ではなく選定したインスタンスタイプのvCPUのコア数を指定してあげる必要があります。
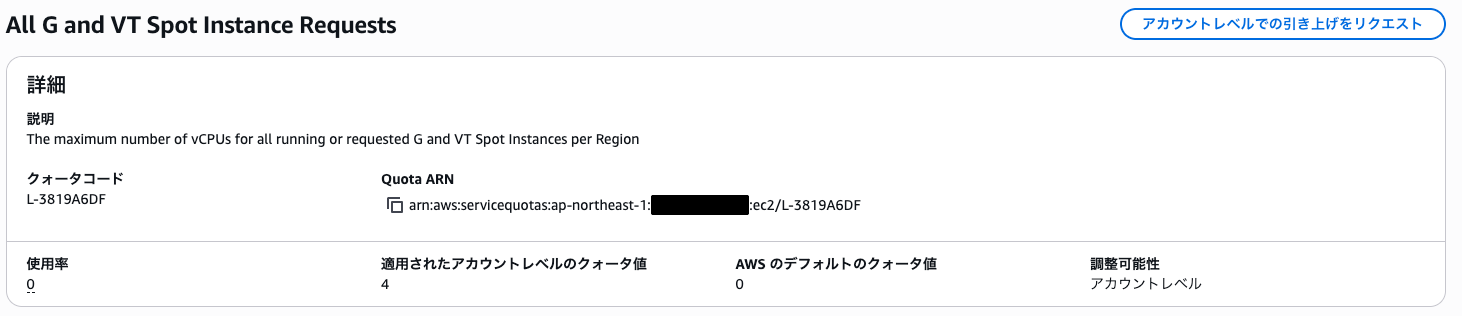
さらにオンデマンドのスポットインスタンスでリクエストする名称が異なりますので注意が必要です。
-
G系オンデマンドインスタンスを使用したい場合
-
G系スポットインスタンスを使用したい場合
その他P系インスタンスに関してもクォータリクエストが異なりますので使用前に確認する必要があります。
ベンチマークの目的と注意点
今回の検証はあくまでGPUの性能イメージを掴むための簡易的なベンチマークです。本格的な性能評価ではなく、CPUとGPUにてN×Nの行列積をそれぞれ計算させ、その性能差を体感することが目的です。
なぜ行列積を計算するのか
行列積(matrix multiplication)は、機械学習や画像処理において最も基本的な数値計算の一つです。2つの行列を掛け合わせる演算で、N×Nの行列積とは例えば以下のようなイメージです。
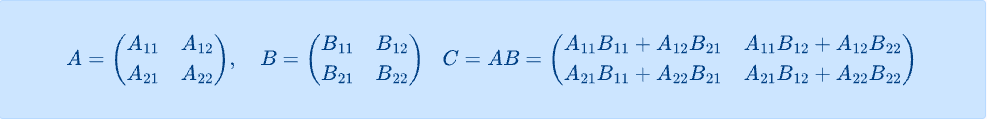
画像処理での行列積の重要性
行列積は実際の画像処理において中核的な役割を果たすらしいです。
- 畳み込み演算: フィルタリング、エッジ検出、ぼかし処理などに使用
- 機械学習: 画像分類、物体検出の推論処理に使用
なので今回の行列積のベンチマーク結果は、実際の画像処理におけるGPU vs CPUの性能差として参考になります。
この計算は掛け算と足し算の繰り返しなので単純化しやすく、CPUよりも遥かに大量のコア数で並列処理できるGPUに適した計算です。
今回は上記のようなN×Nの行列積の 実行速度 と FLOPS を測定します。
FLOPSとは
FLOPSは「Floating Point Operations Per Second」の略で、1秒間に実行できる浮動小数点演算の回数を表す性能指標です。ギガフロップス(GFLOPS)は10億回/秒、テラフロップス(TFLOPS)は1兆回/秒を意味します。
機械学習や画像処理、3Dグラフィックスなどでは大量の数値計算が必要になるため、FLOPSが高いほどコンピュータの計算性能が優秀ということになります。車の馬力のような性能指標と考えるとわかりやすいでしょう。
浮動小数点演算とは
浮動小数点演算は、小数点を含む計算のことです。機械学習や画像処理では、1.234 × 2.567や0.891 ÷ 4.123のような小数を扱う計算が大量に発生します。整数の計算(1 + 2 = 3など)と比べて、コンピュータにとっては複雑で負荷の高い処理になります。
今回の行列積測定も、実際の機械学習ワークロードと同様に小数を含む行列で計算を行います。これにより、実用的な浮動小数点演算の性能を測定できます。
どうやって算出するか
FLOPSの算出方法を理解するために、まず簡単な2×2行列で考えてみます:
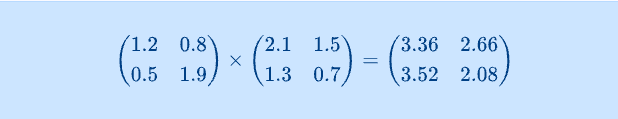
結果の各要素を計算するには
- 左上(1.2×2.1+0.8×1.3=3.36):2回の掛け算と1回の足し算
- 右上(1.2×1.5+0.8×0.7=2.66):2回の掛け算と1回の足し算
- 左下、右下も同様
2×2行列では合計8回の掛け算と4回の足し算が必要です。
N×N行列の場合
- 結果はN×N個の要素を持つ
- 各要素の計算にはN回の掛け算とN-1回の足し算が必要
- 合計でN² × N = N³回の掛け算と、約N³回の足し算
- 掛け算と足し算を合わせて約2×N³回の演算
例えば8192×8192の行列なら、約2 × 8192³ ≈ 1,100兆回の計算が必要になります。
以下の式でGFLOPSを算出しています:
GFLOPS = (2 × N³) ÷ (実行時間[秒] × 10^9)
この値が高いほど、同じ時間でより多くの計算を処理できる、つまり高性能ということになります。
測定パターン
ライブラリの扱い方やTimerを使用した実行時間測定方法などはPyTorch Benchmarkを参考にしています。
計算内容は独自のコードをAIに作成させ、サイズを3段階に分けて測定しました。
- 小規模: 256 × 256
- 中規模: 2048 × 2048
- 大規模: 8192 × 8192
import os
import torch
import torch.utils.benchmark as benchmark
def measure_matmul_performance(device, matrix_size):
# ランダムな値で行列生成
a = torch.randn(matrix_size, matrix_size, device=device)
b = torch.randn(matrix_size, matrix_size, device=device)
# ベンチマーク実行(自動的に複数回実行して統計的に処理)
timer = benchmark.Timer(
stmt='torch.matmul(a, b)',
globals={'a': a, 'b': b, 'torch': torch})
# blocked_autorange()が自動的に最適な回数実行し中央値を取得
result = timer.blocked_autorange()
# 性能指標計算(2 × N³が行列積の演算回数)
flops = 2 * matrix_size**3
gflops = flops / (result.median * 1e9)
return result.median * 1000, gflops
def main():
compute_device = os.environ.get('COMPUTE_DEVICE', 'cpu')
# デバイス設定
if compute_device == 'gpu' and torch.cuda.is_available():
device = torch.device('cuda')
device_name = "GPU"
else:
device = torch.device('cpu')
device_name = "CPU"
print(f"実行環境: {device_name}")
# 3つの行列サイズでテスト
sizes = [256, 2048, 8192]
for matrix_size in sizes:
time_ms, gflops = measure_matmul_performance(device, matrix_size)
print(f"{matrix_size} x {matrix_size}: {time_ms:.2f}ms, {gflops:.2f}GFLOPS")
print(f"{device_name}ベンチマーク完了")
if __name__ == "__main__":
main()
torch.randn()でランダムな浮動小数点数の行列を生成(正規分布から-1.234、0.567、2.891のような値)benchmark.Timerのblocked_autorange()が自動的に適切な回数実行し、統計的に安定した結果を取得- 結果は中央値(median)を使用することで、外れ値の影響を排除
- GPUの場合はCUDAを利用
torch.randn()により小数を含む行列要素がランダムに生成されるため、先ほど説明した浮動小数点演算が実際に行われることになります。
Docker Image
PyTorchを扱え、CPU用にCUDAが入っていない軽量イメージがなかなか見つからず、PyTorch公式のものが見つからなかったため、非公式のイメージを使用しています。
CPU用 Dockerfile
FROM cnstark/pytorch:2.3.1-py3.10.15-ubuntu22.04
WORKDIR /app
COPY benchmark.py .
RUN chmod +x benchmark.py
CMD ["python", "benchmark.py"]
GPU用 Dockerfile
FROM cnstark/pytorch:2.3.1-py3.10.15-cuda12.1.0-ubuntu22.04
WORKDIR /app
COPY benchmark.py .
RUN chmod +x benchmark.py
CMD ["python", "benchmark.py"]
ECSタスク定義
今回のベンチマークでは、CPU用とGPU用でそれぞれ異なるタスク定義を作成しています。
CPU用タスク定義(benchmark-cpu-task)
- CPU: 4096 (4 vCPU相当)
- メモリ: 4096 MiB
- ネットワークモード: awsvpc
- 起動タイプ: EC2
GPU用タスク定義(benchmark-gpu-task)
- CPU: 4096 (4 vCPU相当)
- メモリ: 4096 MiB
- GPU: 1
- ネットワークモード: awsvpc
- 起動タイプ: EC2
両方のタスク定義で同じCPUとメモリ量を割り当てることで、公平な比較環境を作っています。今回はCPUとGPUの計算性能差を確認するのが目的なので、詳細なリソース最適化は行っていません。
検証結果
以下は実際に測定してみた結果です。
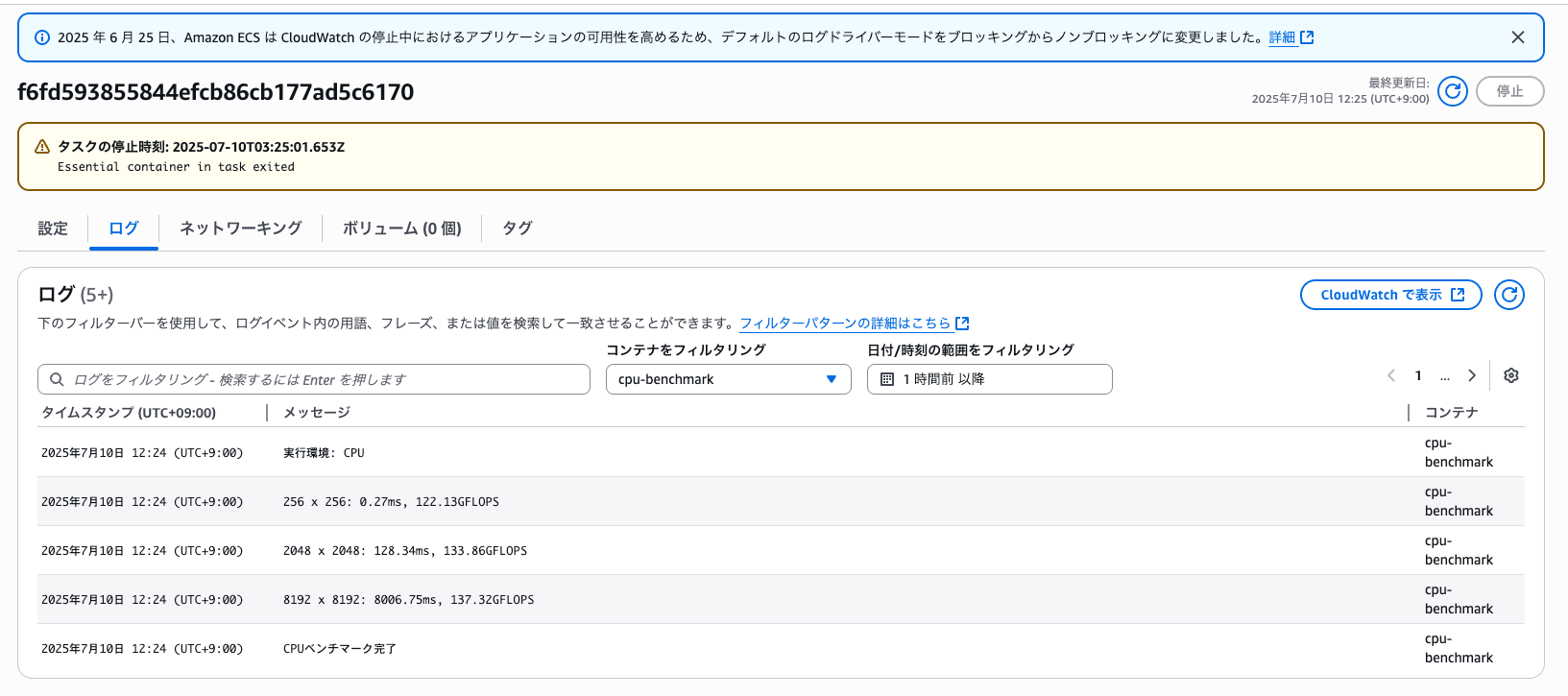
CPU(m5.xlarge)の結果
| 行列サイズ | 実行時間 | GFLOPS |
|---|---|---|
| 256×256 | 0.27ms | 122.13 |
| 2048×2048 | 128.34ms | 133.86 |
| 8192×8192 | 8006.75ms | 137.32 |
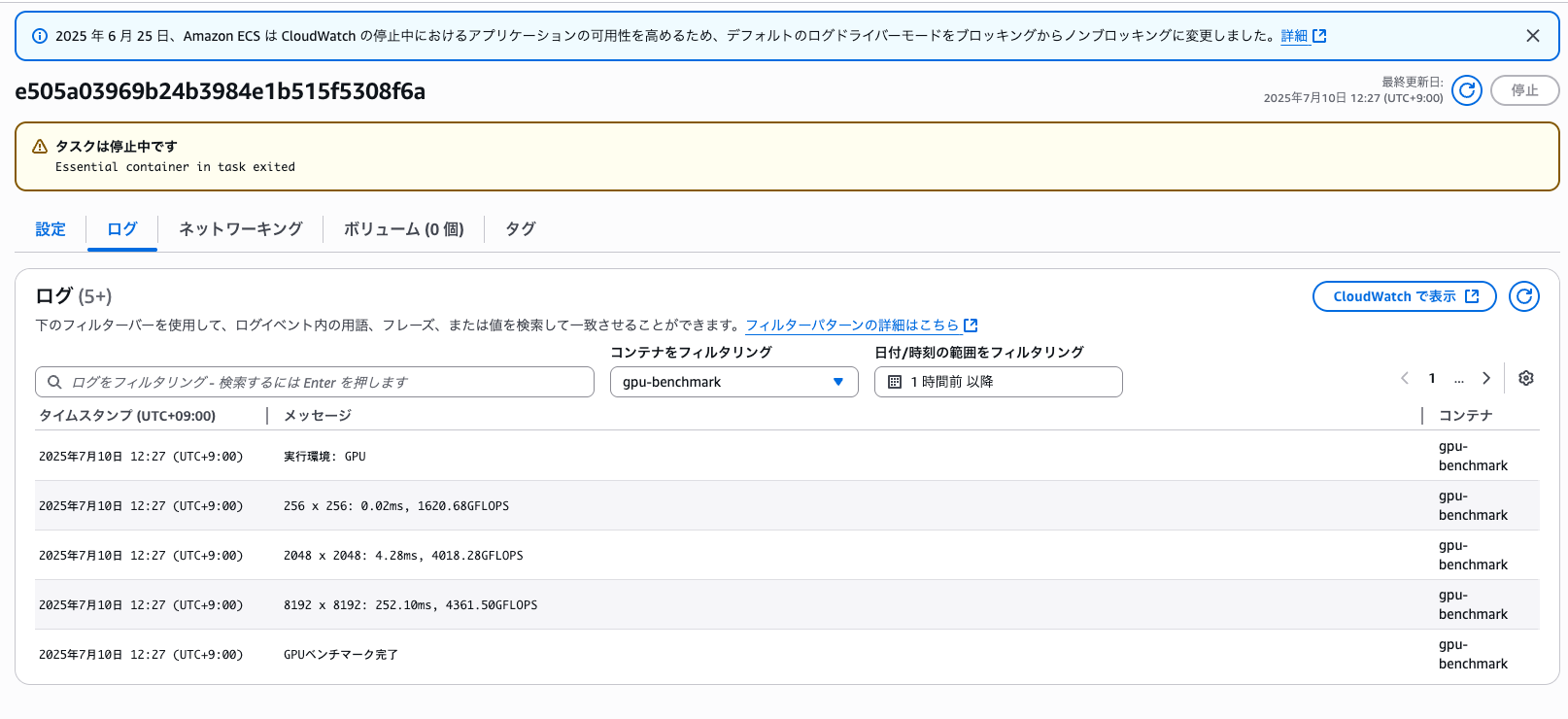
GPU(g4dn.xlarge)の結果
| 行列サイズ | 実行時間 | GFLOPS |
|---|---|---|
| 256×256 | 0.02ms | 1620.68 |
| 2048×2048 | 4.28ms | 4018.28 |
| 8192×8192 | 252.10ms | 4361.50 |
まとめ
| 行列サイズ | CPU実行時間 | GPU実行時間 | 時間差 | CPU GFLOPS | GPU GFLOPS |
|---|---|---|---|---|---|
| 256×256 | 0.27ms | 0.02ms | 13.5倍 | 122.13 | 1620.68 |
| 2048×2048 | 128.34ms | 4.28ms | 30.0倍 | 133.86 | 4018.28 |
| 8192×8192 | 8006.75ms | 252.10ms | 31.7倍 | 137.32 | 4361.50 |
結果を見てみると
- 小規模な行列(256×256) GPUが13.5倍高速
- 中規模な行列(2048×2048) GPUが30.0倍高速
- 大規模な行列(8192×8192) GPUが31.7倍高速
どのサイズでもGPUが圧倒的に速いですが、特に中規模以上では30倍以上の差が出てます。小さい行列でも13倍以上の差があるのはすごいですね。
費用対効果の考察
今回測定した具体的な数値を使用して、行列積計算のワークロードでの費用対効果を試算してみます。
今回の実測値
- 2048×2048行列積: CPU 128.34ms、GPU 4.28ms(30.0倍の差)
- インスタンス料金: m5.xlarge $0.248/時間、g4dn.xlarge $0.71/時間
今回の実測値を前提として、処理回数での比較をしてみます:
| ワークロード | CPU(m5.xlarge) | GPU(g4dn.xlarge) | 差 |
|---|---|---|---|
| 100万回バッチ処理 | 35.6時間 / $8.8 | 1.2時間 / $0.85 | GPU が30倍高速、10倍安い |
今回の実測結果から見える傾向(参考程度)
大量バッチ処理:GPUが圧倒的に有利
- 決まった処理量を短時間で済ませる場合、GPU の高い時間単価でも総コストが大幅削減
長時間稼働・軽い処理:CPUが有効
- 処理量が少なく長時間稼働が必要な場合は、CPUの安い時間単価が有利
結論:今回の行列積レベルの処理では、まとまった処理量をバッチで処理する場合はGPUを検討、処理量が少なく長時間稼働する場合はCPUが適している
最後に
今回初めてGPUインスタンスを触ってみましたが、想像以上の計算速度でした。特に大きい行列になると差は歴然でした。
今回の検証は冒頭でも述べた通り、あくまでGPUの性能イメージを掴むための簡易的なベンチマークです。すべての要素は考慮していませんが、それでもGPUの性能を十分体感できました。
今度は計算最適化に特化したc系インスタンス(c5.xlargeとか)とも比較してみたいですね。CPUでもアーキテクチャが違うとどれくらい差が出るのか気になります。今回は以上です。








