
AIにSlackへ投稿された問い合わせへ回答対応させることにした
問い合わせへのリードタイムや調査コストを減らすため、各種仕様書等をGemini for workspaceのGemに搭載しての問い合わせ自動対応も行っていましたが、案外使われないことも多いと理解しました。
そこで、AIに問い合わせ対応まで任せようと思い立ちました。
構成
Gemに搭載したデータはNotion FAQ、Zendesk、Google Docsの3種類でした。Notion FAQはSlack Logを元に人力でNotionに書き起こし、GAS経由でSpreadsheetに入力したものです。今後、書き起こしをBedrockにフォーマットを含めて推論させてMarkdown化する想定で、Slack Logとして追加しています。
費用面は問い合わせの頻度にもよりますが、月あたり$3程度を見込んでいます。
AIに要件だけ伝えたところ、当初OpenSearch Serverlessが提案されました。実際の問い合わせ頻度も伝えるとPineconeで再提案され、確認の上で採用しました。
プロセスは以下の通り。
- スタッフがSlackの問い合わせフォームから投稿
- EventBridge Schedulerが5分毎にLambdaを起動
- Lambdaが未着手の問い合わせを検出
- Bedrock RAGで回答生成
- Slackスレッドに自動返信
実装
YAMLファイル一つに収まっているのは、Claude Codeに小規模出力から始めて次第に拡張していったためです。
AWSTemplateFormatVersion: '2010-09-09'
Description: |
Slack自動返信システム(ステートレス版)
- DynamoDB不要、Slackのスレッド状態のみを参照
- EventBridge Scheduler + Lambda + Bedrock RAG
Parameters:
Environment:
Type: String
Default: dev
AllowedValues:
- dev
- prod
Description: 環境名(dev/prod)
SlackBotTokenSecretArn:
Type: String
Description: Slack Bot TokenのSecrets Manager ARN(事前に作成が必要)
SlackChannelId:
Type: String
Description: 監視対象のSlackチャンネルID
SlackUsergroupHandle:
Type: String
Default: g-cm-team-aws-serviceg
Description: サービス開発室のユーザーグループハンドル(@なし)
BedrockKnowledgeBaseId:
Type: String
Description: Bedrock Knowledge Base ID
BedrockModelArn:
Type: String
Default: arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-haiku-20240307-v1:0
Description: Bedrock基盤モデルのARN(デフォルト:Haiku、高品質が必要な場合はSonnetに変更)
ScheduleRate:
Type: String
Default: rate(5 minutes)
Description: 実行間隔(例:rate(5 minutes))
MinAgeMinutes:
Type: Number
Default: 5
MinValue: 1
MaxValue: 60
Description: 回答対象とする最小経過時間(分)- 人間対応中を除外
MaxAgeMinutes:
Type: Number
Default: 60
MinValue: 10
MaxValue: 1440
Description: 回答対象とする最大経過時間(分)- 古い質問を除外
Resources:
# =============================================================================
# Lambda実行ロール
# =============================================================================
LambdaExecutionRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub slack-auto-reply-lambda-role-${Environment}
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Policies:
- PolicyName: BedrockAccess
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- bedrock:RetrieveAndGenerate
- bedrock:Retrieve
- bedrock:InvokeModel
Resource: '*'
- PolicyName: SecretsManagerAccess
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- secretsmanager:GetSecretValue
Resource: !Ref SlackBotTokenSecretArn
# =============================================================================
# Lambda関数
# =============================================================================
SlackAutoReplyFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: !Sub slack-auto-reply-${Environment}
Description: Slackの未着手問い合わせを検出し、Bedrock RAGで自動返信
Runtime: python3.12
Handler: index.lambda_handler
Role: !GetAtt LambdaExecutionRole.Arn
Timeout: 300
MemorySize: 256
Environment:
Variables:
SLACK_BOT_TOKEN_SECRET_ARN: !Ref SlackBotTokenSecretArn
SLACK_CHANNEL_ID: !Ref SlackChannelId
SLACK_USERGROUP_HANDLE: !Ref SlackUsergroupHandle
BEDROCK_KNOWLEDGE_BASE_ID: !Ref BedrockKnowledgeBaseId
BEDROCK_MODEL_ARN: !Ref BedrockModelArn
MIN_AGE_MINUTES: !Ref MinAgeMinutes
MAX_AGE_MINUTES: !Ref MaxAgeMinutes
Code:
ZipFile: |
"""
Slack自動返信Lambda(ステートレス版)
servicedev-manage-gas/reception-snapshot の判定ロジックを移植
- 問い合わせフォームBot投稿を検出
- サービス開発室メンバーの対応状況で未着手を判定
- Bedrock RAGで回答を生成してスレッドに返信
"""
import json
import os
import time
import urllib.request
import urllib.parse
import boto3
from datetime import datetime
# =============================================================================
# 環境変数
# =============================================================================
SLACK_BOT_TOKEN_SECRET_ARN = os.environ['SLACK_BOT_TOKEN_SECRET_ARN']
SLACK_CHANNEL_ID = os.environ['SLACK_CHANNEL_ID']
SLACK_USERGROUP_HANDLE = os.environ['SLACK_USERGROUP_HANDLE']
BEDROCK_KNOWLEDGE_BASE_ID = os.environ['BEDROCK_KNOWLEDGE_BASE_ID']
BEDROCK_MODEL_ARN = os.environ['BEDROCK_MODEL_ARN']
MIN_AGE_MINUTES = int(os.environ.get('MIN_AGE_MINUTES', '5'))
MAX_AGE_MINUTES = int(os.environ.get('MAX_AGE_MINUTES', '60'))
# 問い合わせフォームの判定用定数
INQUIRY_FORM_HEADER = "問い合わせフォーム"
INQUIRY_USERNAME = "問い合わせ"
# 完了リアクション
FINISH_REACTIONS = ["sumi", "zumi"]
# Botのリアクション(対応中判定から除外)
BOT_REACTIONS = ["miru-nya", "megane-nya", "help-nya"]
# AWSクライアント
secrets_client = boto3.client('secretsmanager')
bedrock_agent_runtime = boto3.client('bedrock-agent-runtime')
# キャッシュ(Lambda実行中のみ有効)
_slack_token_cache = None
_service_dev_member_ids_cache = None
# =============================================================================
# Slack API ヘルパー関数
# =============================================================================
def get_slack_token():
"""Secrets ManagerからSlack Bot Tokenを取得(キャッシュ付き)"""
global _slack_token_cache
if _slack_token_cache:
return _slack_token_cache
response = secrets_client.get_secret_value(SecretId=SLACK_BOT_TOKEN_SECRET_ARN)
_slack_token_cache = response['SecretString']
return _slack_token_cache
def slack_api_call(method, endpoint, token, params=None, body=None):
"""Slack API呼び出し"""
url = f"https://slack.com/api/{endpoint}"
headers = {
'Authorization': f'Bearer {token}',
'Content-Type': 'application/json; charset=utf-8'
}
if method == 'GET' and params:
url += '?' + urllib.parse.urlencode(params)
data = None
else:
data = json.dumps(body).encode('utf-8') if body else None
req = urllib.request.Request(url, data=data, headers=headers, method=method)
with urllib.request.urlopen(req) as response:
return json.loads(response.read().decode('utf-8'))
# =============================================================================
# サービス開発室メンバーID取得
# =============================================================================
def get_usergroup_id_by_handle(token, handle):
"""ユーザーグループハンドルからIDを取得"""
response = slack_api_call('GET', 'usergroups.list', token, params={'include_users': 'false'})
if not response.get('ok'):
print(f"usergroups.list エラー: {response}")
return None
for group in response.get('usergroups', []):
if group.get('handle') == handle:
return group.get('id')
return None
def get_usergroup_members(token, usergroup_id):
"""ユーザーグループのメンバーID一覧を取得"""
response = slack_api_call('GET', 'usergroups.users.list', token,
params={'usergroup': usergroup_id})
if not response.get('ok'):
print(f"usergroups.users.list エラー: {response}")
return []
return response.get('users', [])
def get_service_dev_member_ids(token):
"""サービス開発室メンバーのUser ID一覧を取得(キャッシュ付き)"""
global _service_dev_member_ids_cache
if _service_dev_member_ids_cache is not None:
return _service_dev_member_ids_cache
usergroup_id = get_usergroup_id_by_handle(token, SLACK_USERGROUP_HANDLE)
if not usergroup_id:
print(f"ユーザーグループ '{SLACK_USERGROUP_HANDLE}' が見つかりません")
_service_dev_member_ids_cache = []
return []
member_ids = get_usergroup_members(token, usergroup_id)
print(f"サービス開発室メンバー数: {len(member_ids)}")
_service_dev_member_ids_cache = member_ids
return member_ids
# =============================================================================
# 問い合わせメッセージ判定
# =============================================================================
def is_inquiry_message(message):
"""
問い合わせフォームからのBot投稿かどうかを判定
判定条件:
- message.type === "message"
- message.subtype === "bot_message"
- message.username === "問い合わせ"
- blocks内に「問い合わせフォーム」ヘッダーがある
"""
if not message:
return False
if message.get('type') != 'message':
return False
if message.get('subtype') != 'bot_message':
return False
if message.get('username') != INQUIRY_USERNAME:
return False
# blocksの構造チェック
blocks = message.get('blocks', [])
if not blocks:
return False
try:
# blocks[0].elements[0].elements[0].text に「問い合わせフォーム」が含まれるか
first_block = blocks[0]
elements = first_block.get('elements', [])
if not elements:
return False
first_element = elements[0]
inner_elements = first_element.get('elements', [])
if not inner_elements:
return False
header_text = inner_elements[0].get('text', '')
if INQUIRY_FORM_HEADER not in header_text:
return False
except (IndexError, KeyError, TypeError):
return False
return True
def extract_title_from_inquiry(message):
"""問い合わせメッセージから件名を抽出(ログ表示用)"""
text = message.get('text', '')
# 件名行を探す
lines = text.split('\n')
for i, line in enumerate(lines):
if '件名' in line and i + 1 < len(lines):
return lines[i + 1].strip()[:100]
return text[:50]
def get_thread_replies(token, channel_id, thread_ts):
"""スレッドの返信を取得"""
try:
response = slack_api_call('GET', 'conversations.replies', token, params={
'channel': channel_id,
'ts': thread_ts,
'limit': 10
})
if response.get('ok'):
# 最初のメッセージ(親)を除いた返信を返す
messages = response.get('messages', [])
return messages[1:] if len(messages) > 1 else []
return []
except Exception as e:
print(f"スレッド取得エラー: {e}")
return []
def extract_inquiry_for_bedrock(message, token):
"""
問い合わせから種類・件名・詳細を抽出してBedrock用の質問文を生成
"""
text = message.get('text', '')
message_ts = message.get('ts')
# 親メッセージから種類と件名を抽出
category = ""
title = ""
lines = text.split('\n')
current_field = None
for line in lines:
line = line.strip()
if '*種類*' in line:
current_field = 'category'
continue
if '件名' in line:
current_field = 'title'
continue
if '*問い合わせ元' in line or '詳細は以下' in line:
current_field = None
continue
if current_field == 'category' and line and not line.startswith('*'):
category = line.strip()
current_field = None
elif current_field == 'title' and line and not line.startswith('*'):
title = line.strip()
current_field = None
# スレッドから詳細を取得
detail = ""
replies = get_thread_replies(token, SLACK_CHANNEL_ID, message_ts)
if replies:
# 最初の返信(通常は詳細)を取得
first_reply = replies[0]
# Bot自身の返信でなければ詳細として使用
if first_reply.get('subtype') != 'bot_message' or '問い合わせフォーム' not in first_reply.get('text', ''):
detail = first_reply.get('text', '')
# Bedrock用の質問文を生成
question_parts = []
if category:
question_parts.append(f"種類: {category}")
if title:
question_parts.append(f"件名: {title}")
if detail:
question_parts.append(f"詳細: {detail}")
question = '\n'.join(question_parts) if question_parts else text
print(f"Bedrock質問文: {question[:200]}...")
return question
# =============================================================================
# ステータス判定
# =============================================================================
def determine_status(message, service_dev_member_ids):
"""
問い合わせのステータスを判定
判定ロジック(優先順):
1. sumi または zumi リアクション → 完了
2. megane-nya リアクション → 処理中(AI回答済み)
3. サービス開発室メンバーがリアクション → 処理中
4. サービス開発室メンバーがスレッド投稿 → 処理中
5. それ以外 → 未着手
Returns:
str: "完了", "処理中", "未着手" のいずれか
"""
if not message:
return "未着手"
reactions = message.get('reactions', [])
reply_users = message.get('reply_users', [])
# 1. sumi または zumi リアクションチェック(最優先)
for reaction in reactions:
if reaction.get('name') in FINISH_REACTIONS:
return "完了"
# 2. megane-nya リアクション(AI回答済み)チェック
for reaction in reactions:
if reaction.get('name') == 'megane-nya':
return "処理中"
# 3. サービス開発室メンバーがリアクションしているかチェック
# (Botのリアクションは除外)
for reaction in reactions:
if reaction.get('name') in BOT_REACTIONS:
continue
for user_id in reaction.get('users', []):
if user_id in service_dev_member_ids:
return "処理中"
# 4. サービス開発室メンバーがスレッド投稿しているかチェック
for user_id in reply_users:
if user_id in service_dev_member_ids:
return "処理中"
# 5. それ以外は未着手
return "未着手"
# =============================================================================
# チャンネルメッセージ取得
# =============================================================================
def get_channel_messages(token, oldest_ts, latest_ts=None):
"""チャンネルのメッセージ履歴を取得(ページネーション対応)"""
all_messages = []
cursor = None
page_count = 0
max_pages = 50
while True:
page_count += 1
params = {
'channel': SLACK_CHANNEL_ID,
'oldest': oldest_ts,
'limit': 200
}
if latest_ts:
params['latest'] = latest_ts
if cursor:
params['cursor'] = cursor
response = slack_api_call('GET', 'conversations.history', token, params=params)
if not response.get('ok'):
print(f"conversations.history エラー: {response}")
break
messages = response.get('messages', [])
all_messages.extend(messages)
print(f"ページ {page_count}: {len(messages)}件取得(累計: {len(all_messages)}件)")
# 次のカーソル
metadata = response.get('response_metadata', {})
cursor = metadata.get('next_cursor')
if not cursor or page_count >= max_pages:
break
time.sleep(0.1) # レート制限対策
return all_messages
# =============================================================================
# Bedrock RAG
# =============================================================================
# スコア閾値
SCORE_THRESHOLD_HIGH = 0.75 # 確信を持って回答
SCORE_THRESHOLD_LOW = 0.60 # 参考情報として回答
def check_relevance_score(question):
"""
Retrieve APIでスコアを事前チェック
Returns:
tuple: (max_score, confidence_level)
- confidence_level: "high" (>=0.75), "medium" (0.60-0.74), "low" (<0.60)
"""
try:
response = bedrock_agent_runtime.retrieve(
knowledgeBaseId=BEDROCK_KNOWLEDGE_BASE_ID,
retrievalQuery={'text': question},
retrievalConfiguration={
'vectorSearchConfiguration': {
'numberOfResults': 3
}
}
)
results = response.get('retrievalResults', [])
if not results:
print("検索結果なし")
return 0.0, "low"
max_score = max(r.get('score', 0) for r in results)
print(f"最高スコア: {max_score:.4f}")
if max_score >= SCORE_THRESHOLD_HIGH:
return max_score, "high"
elif max_score >= SCORE_THRESHOLD_LOW:
return max_score, "medium"
else:
return max_score, "low"
except Exception as e:
print(f"Retrieve APIエラー: {e}")
return 0.0, "low"
def generate_answer_with_bedrock(question):
"""
Bedrock Knowledge Baseを使って回答を生成
スコア閾値に基づいて回答:
- 0.75以上: 確信を持って回答
- 0.60-0.74: 参考情報として回答
- 0.60未満: 回答しない(Noneを返す)
Returns:
tuple: (answer_text, confidence_level) or (None, "low")
"""
# まずスコアをチェック
score, confidence = check_relevance_score(question)
if confidence == "low":
print(f"スコア {score:.4f} が閾値 {SCORE_THRESHOLD_LOW} 未満のため回答をスキップ")
return None, "low"
try:
response = bedrock_agent_runtime.retrieve_and_generate(
input={'text': question},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': BEDROCK_KNOWLEDGE_BASE_ID,
'modelArn': BEDROCK_MODEL_ARN,
'generationConfiguration': {
'promptTemplate': {
'textPromptTemplate': '''あなたはAWSの技術サポート担当です。
以下の検索結果を参考に、質問に対して丁寧かつ正確に回答してください。
検索結果:
$search_results$
質問: $query$
回答の際の注意点:
- 検索結果に情報がない場合は、正直に「この情報については確認が必要です」と伝えてください
- 専門用語は可能な限り平易な言葉で説明してください
- 回答の最後に、参考にした情報源があれば簡潔に示してください
- 回答は簡潔にまとめてください(500文字以内目安)'''
}
}
}
}
)
# 関連情報(citations)が見つかったかチェック
citations = response.get('citations', [])
has_relevant_info = False
for citation in citations:
retrieved_refs = citation.get('retrievedReferences', [])
if retrieved_refs:
has_relevant_info = True
break
if not has_relevant_info:
print("Knowledge Baseから関連情報が見つかりませんでした。リプライをスキップします。")
return None, "low"
print(f"関連情報が見つかりました({len(citations)}件の引用、信頼度: {confidence})")
return response['output']['text'], confidence
except Exception as e:
print(f"Bedrock呼び出しエラー: {e}")
return None, "low"
# =============================================================================
# Slack返信
# =============================================================================
def post_reply(token, thread_ts, text):
"""スレッドに返信を投稿"""
body = {
'channel': SLACK_CHANNEL_ID,
'thread_ts': thread_ts,
'text': text
}
return slack_api_call('POST', 'chat.postMessage', token, body=body)
def add_reaction(token, message_ts, reaction_name):
"""メッセージにリアクションを追加"""
body = {
'channel': SLACK_CHANNEL_ID,
'timestamp': message_ts,
'name': reaction_name
}
response = slack_api_call('POST', 'reactions.add', token, body=body)
if not response.get('ok') and response.get('error') != 'already_reacted':
print(f"リアクション追加エラー: {response}")
return response
def remove_reaction(token, message_ts, reaction_name):
"""メッセージからリアクションを削除"""
print(f"リアクション削除開始: {reaction_name} from {message_ts}")
body = {
'channel': SLACK_CHANNEL_ID,
'timestamp': message_ts,
'name': reaction_name
}
response = slack_api_call('POST', 'reactions.remove', token, body=body)
if response.get('ok'):
print(f"リアクション削除成功: {reaction_name}")
elif response.get('error') == 'no_reaction':
print(f"リアクション削除スキップ(既になし): {reaction_name}")
else:
print(f"リアクション削除エラー: {response}")
return response
# =============================================================================
# 時間窓チェック
# =============================================================================
def is_within_time_window(message_ts):
"""
メッセージが処理対象の時間窓内かどうかを判定
- MIN_AGE_MINUTES以上経過(人間対応中を除外)
- MAX_AGE_MINUTES以内(古い質問を除外)
"""
current_time = time.time()
message_time = float(message_ts)
age_minutes = (current_time - message_time) / 60
return MIN_AGE_MINUTES <= age_minutes <= MAX_AGE_MINUTES
# =============================================================================
# メインハンドラー
# =============================================================================
def lambda_handler(event, context):
"""
メインハンドラー
1. サービス開発室メンバーIDを取得
2. Slackチャンネルのメッセージを取得
3. 問い合わせフォームBot投稿をフィルタリング
4. 未着手かつ時間窓内のメッセージを特定
5. Bedrock RAGで回答を生成
6. スレッドに返信
"""
print("=== Slack自動返信処理開始 ===")
# Slack Bot Token取得
token = get_slack_token()
# サービス開発室メンバーID取得
service_dev_member_ids = get_service_dev_member_ids(token)
if not service_dev_member_ids:
print("警告: サービス開発室メンバーIDが取得できませんでした")
# 時間窓の計算(MAX_AGE分前から現在まで)
oldest_ts = str(time.time() - (MAX_AGE_MINUTES * 60))
# チャンネルのメッセージを取得
messages = get_channel_messages(token, oldest_ts)
print(f"取得メッセージ数: {len(messages)}")
processed_count = 0
skipped_count = 0
for message in messages:
message_ts = message.get('ts')
# 問い合わせフォームBot投稿かチェック
if not is_inquiry_message(message):
continue
# 時間窓チェック
if not is_within_time_window(message_ts):
skipped_count += 1
continue
# miru-nyaが付いているかチェック(2段階処理の判定)
reactions = message.get('reactions', [])
reaction_names = [r.get('name') for r in reactions]
print(f"リアクション確認: {reaction_names}")
has_miru_nya = 'miru-nya' in reaction_names
# ステータス判定
status = determine_status(message, service_dev_member_ids)
# miru-nya付きで処理中/完了の場合はmiru-nyaを削除するだけ
if has_miru_nya and status != "未着手":
print(f"人間対応開始のためmiru-nya削除: ステータス={status}")
remove_reaction(token, message_ts, 'miru-nya')
skipped_count += 1
continue
if status != "未着手":
print(f"スキップ: ステータス={status}")
skipped_count += 1
continue
# 未着手の問い合わせを検出
title = extract_title_from_inquiry(message)
print(f"未着手問い合わせ検出: {title[:50]}...")
# help-nyaまたはmegane-nyaが付いている場合は処理済みとしてスキップ
has_help_nya = 'help-nya' in reaction_names
has_megane_nya = 'megane-nya' in reaction_names
if has_help_nya or has_megane_nya:
print(f"AI処理済みのためスキップ: help-nya={has_help_nya}, megane-nya={has_megane_nya}")
continue
if not has_miru_nya:
# 1回目: miru-nyaを追加するだけ(次回実行時に回答生成)
add_reaction(token, message_ts, 'miru-nya')
print(f"確認中マーク追加: {message_ts}")
skipped_count += 1
continue
# 2回目: miru-nyaが付いている → 回答生成して切り替え
# スレッドから種類・件名・詳細を抽出
question = extract_inquiry_for_bedrock(message, token)
print(f"回答生成開始: {message_ts}")
# Bedrockで回答生成(スコア閾値チェック付き)
answer, confidence = generate_answer_with_bedrock(question)
if answer:
# 信頼度に応じてヘッダーを変更
if confidence == "high":
# 0.75以上: 確信を持って回答
header = ":megane-nya: *AI自動返信*"
footer = "_この回答はAIによる自動生成です。正確性については担当者にご確認ください。_"
else:
# 0.60-0.74: 参考情報として回答
header = ":megane-nya: *AI自動返信(参考情報)*"
footer = "_この回答は関連度が中程度のため、参考情報としてご確認ください。詳細は担当者にお問い合わせください。_"
reply_text = f"{header}\n\n{answer}\n\n---\n{footer}"
# スレッドに返信
reply_response = post_reply(token, message_ts, reply_text)
if reply_response.get('ok'):
print(f"返信成功: {message_ts} (信頼度: {confidence})")
# 確認中リアクションを削除し、返信成功リアクションを追加
remove_reaction(token, message_ts, 'miru-nya')
add_reaction(token, message_ts, 'megane-nya')
processed_count += 1
else:
print(f"返信エラー: {reply_response}")
else:
# スコアが閾値未満、確認中リアクションを削除し、ヘルプ要請リアクションを追加
print(f"スコア閾値未満、スキップ: {message_ts}")
remove_reaction(token, message_ts, 'miru-nya')
add_reaction(token, message_ts, 'help-nya')
skipped_count += 1
print(f"=== 処理完了: 返信 {processed_count}件, スキップ {skipped_count}件 ===")
return {
'statusCode': 200,
'body': json.dumps({
'processed': processed_count,
'skipped': skipped_count
})
}
# =============================================================================
# EventBridge Scheduler
# =============================================================================
SchedulerExecutionRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub slack-auto-reply-scheduler-role-${Environment}
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: scheduler.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: InvokeLambda
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action: lambda:InvokeFunction
Resource: !GetAtt SlackAutoReplyFunction.Arn
SlackAutoReplySchedule:
Type: AWS::Scheduler::Schedule
Properties:
Name: !Sub slack-auto-reply-schedule-${Environment}
Description: Slack未着手問い合わせの定期チェック
ScheduleExpression: !Ref ScheduleRate
FlexibleTimeWindow:
Mode: 'OFF'
State: ENABLED
Target:
Arn: !GetAtt SlackAutoReplyFunction.Arn
RoleArn: !GetAtt SchedulerExecutionRole.Arn
# =============================================================================
# CloudWatch Logs(Lambda用、保持期間設定)
# =============================================================================
LambdaLogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub /aws/lambda/slack-auto-reply-${Environment}
RetentionInDays: 14
Outputs:
LambdaFunctionArn:
Description: Lambda関数のARN
Value: !GetAtt SlackAutoReplyFunction.Arn
LambdaFunctionName:
Description: Lambda関数名
Value: !Ref SlackAutoReplyFunction
ScheduleName:
Description: EventBridge Scheduler名
Value: !Ref SlackAutoReplySchedule
セットアップに必要なプロセスは以下の通り。
Step 1: Slack Bot作成
- https://api.slack.com/apps でApp作成
- Bot Token Scopesを設定:
- channels:history
- channels:read
- chat:write
- reactions:write
- reactions:read
- usergroups:read
- Botをチャンネルに招待
Step 2: Pinecone設定
- https://www.pinecone.io/ でアカウント作成(無料枠)
- Index作成:
- Dimensions: 1024
- Metric: cosine
Step 3: S3バケット作成
以下のコマンドで作成します。コンソール上から実施しても構いません。
aws s3 mb s3://your-faq-documents-bucket --region ap-northeast-1
Step 4: Bedrock Knowledge Base作成
以下の手順で実施します。
- AWSコンソール → Bedrock → Knowledge bases → Create
- Data source: S3バケットを指定
- Vector database: Pinecone を選択
- Embeddings: Titan Text Embeddings V2
- Knowledge Base ID をメモ
Step 5: Slack TokenをSecrets Managerに登録
aws secretsmanager create-secret \
--name slack-auto-reply/slack-bot-token-prod \
--secret-string "xoxb-your-token" \
--region ap-northeast-1
Step 6: CloudFormationデプロイ
SECRET_ARN=$(aws secretsmanager describe-secret \
--secret-id slack-auto-reply/slack-bot-token-prod \
--query 'ARN' --output text)
aws cloudformation deploy \
--template-file infra/slack-auto-reply.yaml \
--stack-name slack-auto-reply-prod \
--parameter-overrides \
Environment=prod \
SlackBotTokenSecretArn=$SECRET_ARN \
SlackChannelId=XXXXXXXX \
BedrockKnowledgeBaseId=YOUR_KB_ID \
--capabilities CAPABILITY_NAMED_IAM \
--region ap-northeast-1
実際の動作
Sandboxでの動作となります。
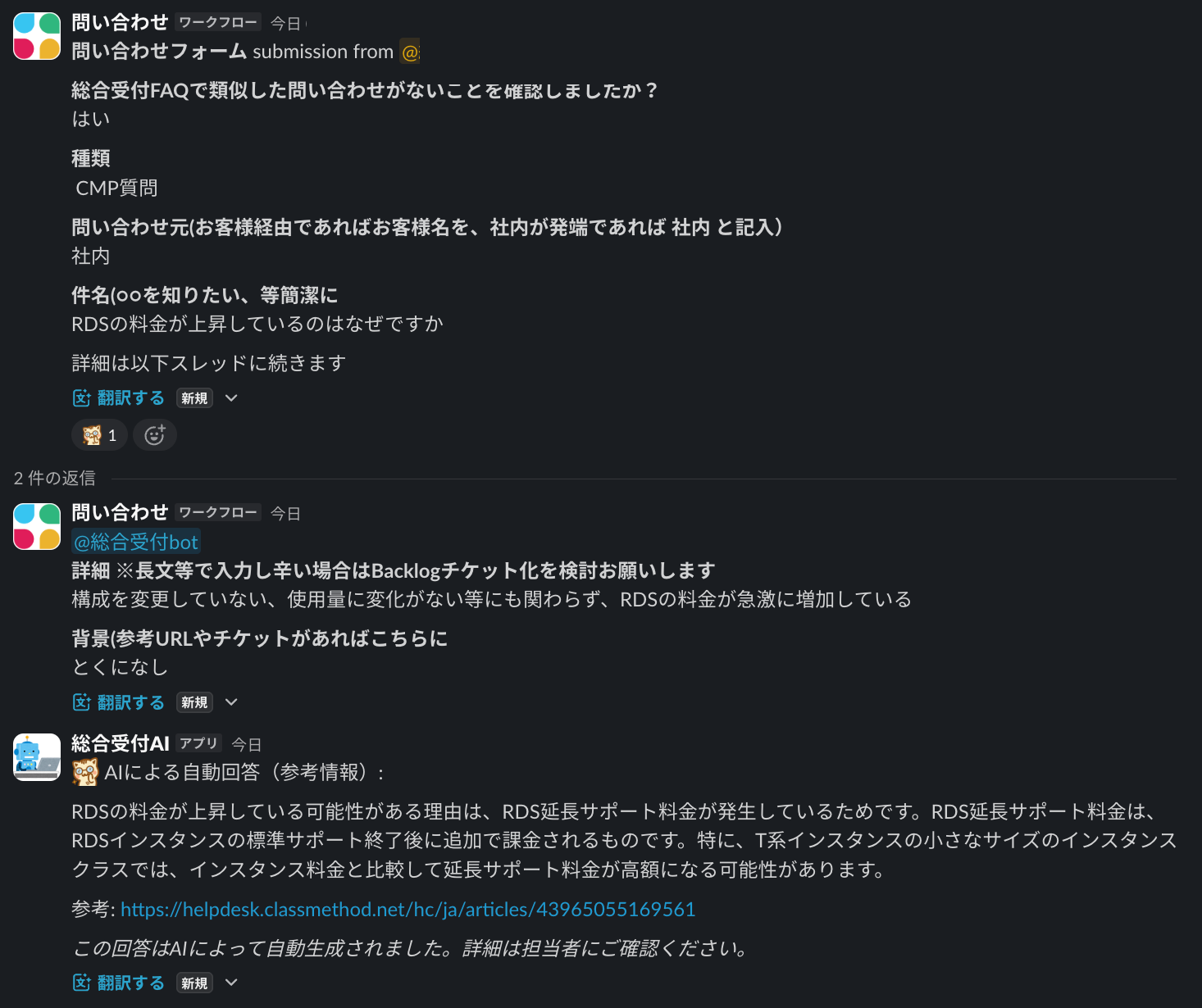
AIが着手したタイミングで人が調査をして、ほぼ同時にリプライが付いて、結果として問い合わせた人が悩むケースを回避するため、AIが着手したというサインを付けます。
既存データソースにマッチしない場合は専用の絵文字を付けて終了、マッチする場合は専用の絵文字を付けた上でレスポンスを入れます。
さらに効率のよい問い合わせ判定のため、Slackワークフローの指定フォーム経由のものだけが対象になるよう絞っています。
今後の課題
Gemに搭載したPDFデータソースをそのままBedrockに使うよりは、テキスト化したほうが精度が高くなります。
そこで、GitHub Actionsワークフローへ、PDFではなくMarkdownで出力するJobも追加しました。ただ、全てのワークフローで対応できているわけではないため、本番反映の前にこれから一通り対応させる必要があります。
あとがき
今回のプロセスについて作成は考えていましたが、問い合わせへの返答が完了するまでの時間と、プロセスを仕上げるまでの期間を比べてコストメリットが少なく、見送っていました。生成AIを利用開始したばかりの頃は出力が見合わないこともあって断念していました。
ですが、Claude Codeに対して、ローカル環境でのペルソナ設定やプロンプトが積み上げられていった結果、プロジェクトのコンテキストに沿った実装が素早くできるようになったため、今回試してみました。
要件が揃っていないがためにvibe-codingを利用した改修で思ったような成果が得られない、と悩む場合は、先ずはペルソナやプロンプトの積み重ねを実施することをおすすめします。









