![[資料公開] 試されDATA SAPPOROで「Data & AIの未来とLakeHouse」というタイトルで登壇しました](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1762613955/user-gen-eyecatch/mmzpr1izv4g99nyevscl.jpg)
[資料公開] 試されDATA SAPPOROで「Data & AIの未来とLakeHouse」というタイトルで登壇しました
クラウド事業本部の石川です。先日、2025年11月7日に開催されたイベント 試されDATA SAPPORO にて、 「Data & AIの未来とLakeHouse」 というタイトルで登壇しました。
本日は、当日の発表内容をダイジェストでご紹介します。
登壇資料
Dataware HouseとDataLakeでデータが分断されていませんか? そのサイロ化問題を解決するのが、DWHの「信頼性」とDataLakeの「柔軟性」を両立させる新標準「LakeHouse」です 。中核技術Apache Icebergがデータレイクの信頼性を高め 、BIからAIまで多様なワークロードを単一基盤で実現します 。特に生成AI(RAG)活用の鍵となる「信頼できる唯一の情報源」 として不可欠な、次世代データ基盤の全貌を解説します 。
LakeHouseとは?
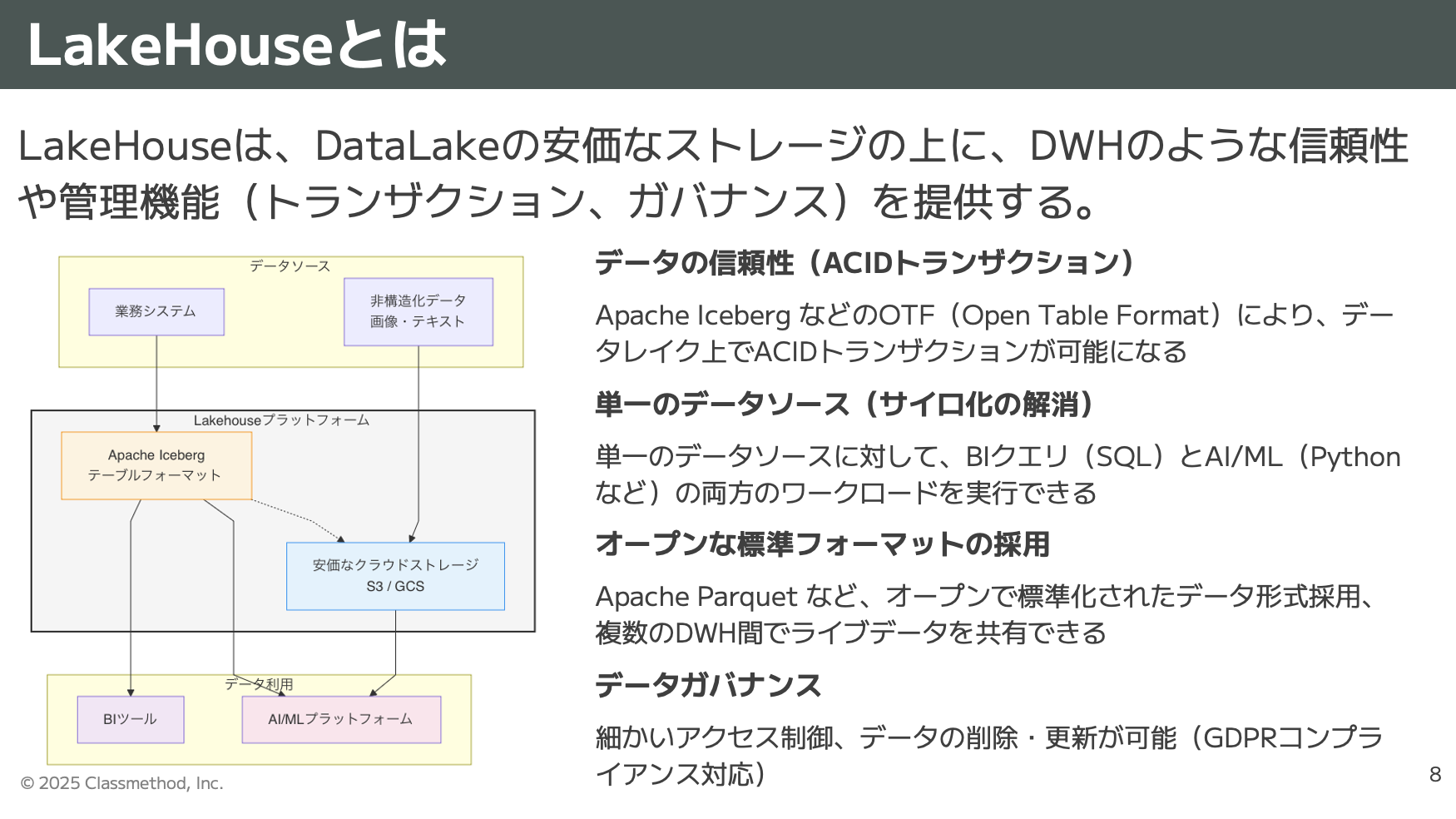
- これは、DataLakeの柔軟性とDWH(データウェアハウス)の信頼性を単一の基盤に統合するものです。
- BI、AI、ストリーミングなど多様なワークロードを統一的に扱えます。
- LakeHouseはAI時代のデータ戦略の中核であり、その技術的根幹にはApache Icebergなどのオープンフォーマットが存在します。
DWHとDataLakeの課題
従来のデータ分析基盤は、DWHとDataLakeという2つのアプローチに分かれていました。

この2つの基盤が併存することにより、以下の問題が発生していました。
- データのサイロ化: BI用とAI用のデータが分断される。
- 高コスト・複雑性: 2つの異なる基盤の維持管理が必要。
- データの二重管理と鮮度の低下: 同じデータを別々に管理する必要があり、鮮度が落ちる。
LakeHouseによる解決
LakeHouseは、DataLakeの安価なストレージ(S3やGCSなど)の上に、DWHのような信頼性や管理機能(トランザクション、ガバナンス)を提供します。
- 単一のデータソース(サイロ化の解消):
- 単一のデータソースに対して、BIクエリ(SQL)とAI/ML(Pythonなど)の両方のワークロードを実行できます。
- 高い信頼性(ACIDトランザクション):
- Apache Icebergなどのオープンテーブルフォーマット(OTF)により、データレイク上でACIDトランザクションが可能になります。
- オープンな標準フォーマット:
- Apache Parquetなどのオープンな形式を採用し、複数のDWH間でライブデータを共有できます。
LakeHouseを支える Apache Iceberg
LakeHouseアーキテクチャの中核をなすのが、Apache Icebergです。
- Apache Icebergとは?
- DataLake上にあるペタバイト規模の巨大な分析用データセットを管理するために設計された、オープンソースのテーブルフォーマット(OTF)です。
- 2017年にNetflixで誕生しました。
- DataLakeの課題を解決:
- Icebergは、従来のDataLakeが抱えていた技術的な課題を解決します。
- データ整合性の欠如 → 楽観的同時実行制御(ACIDトランザクション)で解決。
- 少量レコード更新の非効率性 → Row-levelの更新・削除(MERGE、UPDATE、DELETE)をサポート。
- パーティション管理の限界 → **Hidden Partitioning(隠しパーティション)**により、ユーザーはパーティションを意識不要。
- 過去状態の復元が困難 → タイムトラベル機能により、任意の時点のスナップショットにアクセス可能。
LakeHouseとAIの未来
AI、特に生成AIの時代において、LakeHouseは不可欠な存在となります。
- AI(RAG)の要件:
- 生成AI(LLM)がハルシネーションを避けるためには、**RAG(検索拡張生成)**によって信頼できる外部情報を参照する必要があります。
- LakeHouseの役割:
- LakeHouseは、**構造化データ(DB)と非構造化データ(文書、画像など)**の両方を、信頼できる品質で一元管理できます。
- これにより、LakeHouseはRAGにとって理想的な「信頼できる唯一の情報源(Single Source of Truth)」として機能します。
- 例えば、最新の売上データ(構造化)と顧客レビュー(非構造化テキスト)を同じ基盤上で簡単に組み合わせて(JOIN)、AIの学習用データとして利用できます。
AWSによるLakeHouse戦略
AWSも、Apache Icebergを中心としたオープンなLakeHouse戦略を強力に推進しています。
- アーキテクチャのコア: Apache Icebergをコア技術として採用。
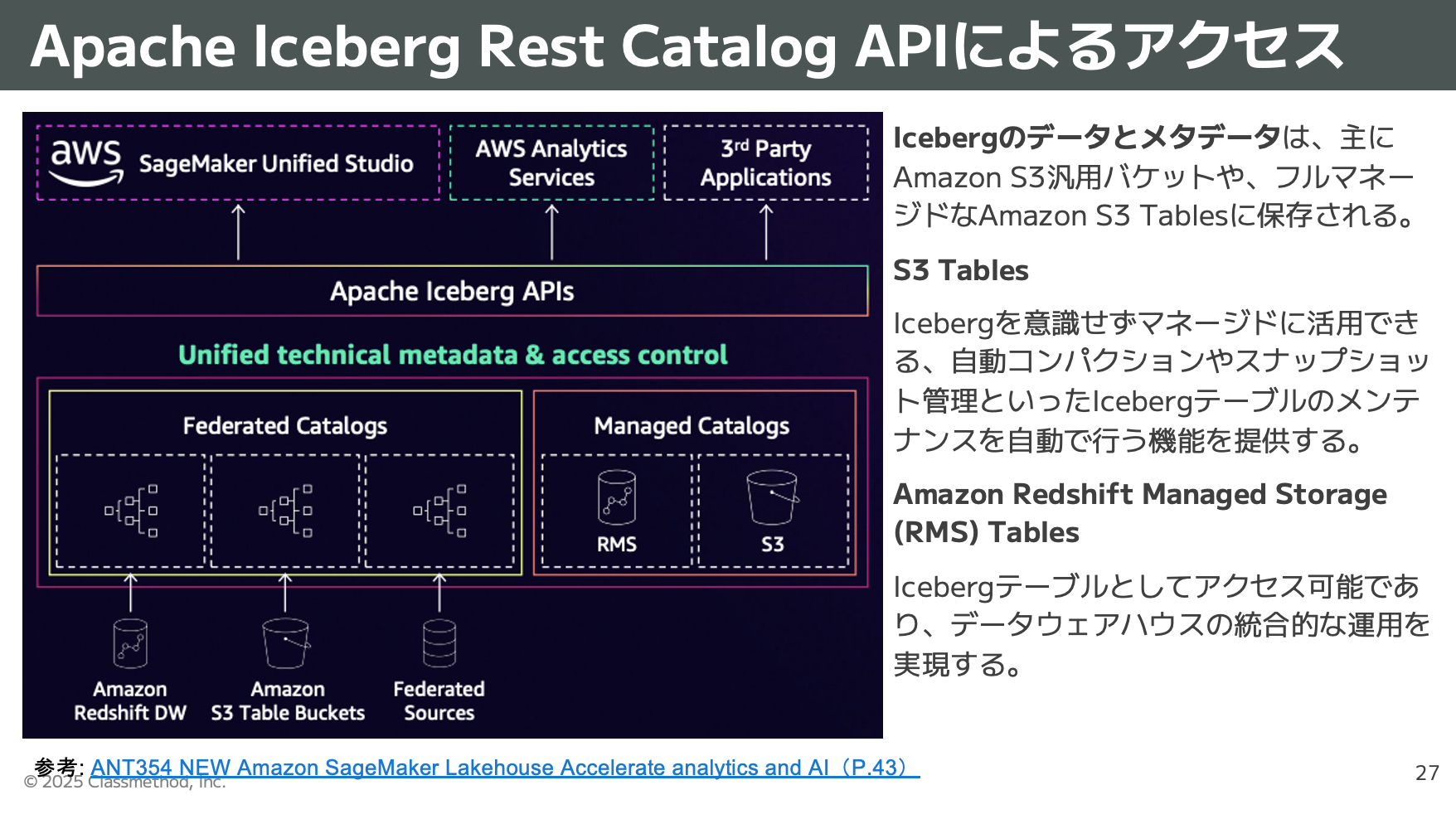
- 多様なクエリエンジン: Amazon Redshift, Amazon Athena, AWS Glue, Amazon EMRなどがIcebergをネイティブに利用できます。
- オープンな連携: AWS Glue Iceberg REST endpoint(re:Invent 2024で発表)などにより、SparkやTrinoなどAWS外のツールからもシームレスな利用が可能になります。
- マネージドサービス: Amazon S3 Tables(自動コンパクションやスナップショット管理を自動化するIceberg専用ストレージ)なども提供されています。
最後に
LakeHouseは、AI技術の発展とともにデータ活用の新たな柱となっています。AWSもApache Icebergを中心にオープンなLakeHouse戦略を推進し、Amazon AthenaやAWS Glueなど多様なサービスで対応を進めています。これにより、高い信頼性と柔軟性を兼ね備えた次世代データ基盤の実現が加速し、生成AIのRAG活用にも最適な「信頼できる唯一の情報源」としての役割を果たせるでしょう。今後の展開にもぜひご注目ください。










