
AIが開発/運用しやすいクラウド サーバーレスの視点から考える設計原則(CNS449)
はじめに
クラスメソッド コンサルティング部の浅野です。
AWS Summit Japan 2026で聴講したセッション「CNS449: AIが開発/運用しやすいクラウド サーバーレスの視点から考える設計原則」のレポートを記載します。

非常にボリュームのあるセッション(スライド114ページ)で、コンテキストエンジニアリングからサーバーレス設計、運用エージェントまで広範な内容をカバーしていました。本記事ではポイントを絞って、個人的に印象に残った部分を中心にレポートします。
セッション資料はこちらから参照できます。
セッションの概要
- タイトル: AIが開発/運用しやすいクラウド サーバーレスの視点から考える設計原則
- セッション番号: CNS449
- 登壇者: 淡路 大輔氏 / アマゾン ウェブサービス ジャパン合同会社
このセッションの問いは「AIエージェントにとって開発・運用しやすくするには、クラウドの構成やソフトウェアをどう設計すべきか?」です。コンテキストエンジニアリング、ソフトウェア設計原則、サーバーレスアーキテクチャ、クラウド運用の4つの観点から設計原則が提示されていました。

何トークンから精度の壁を感じるか
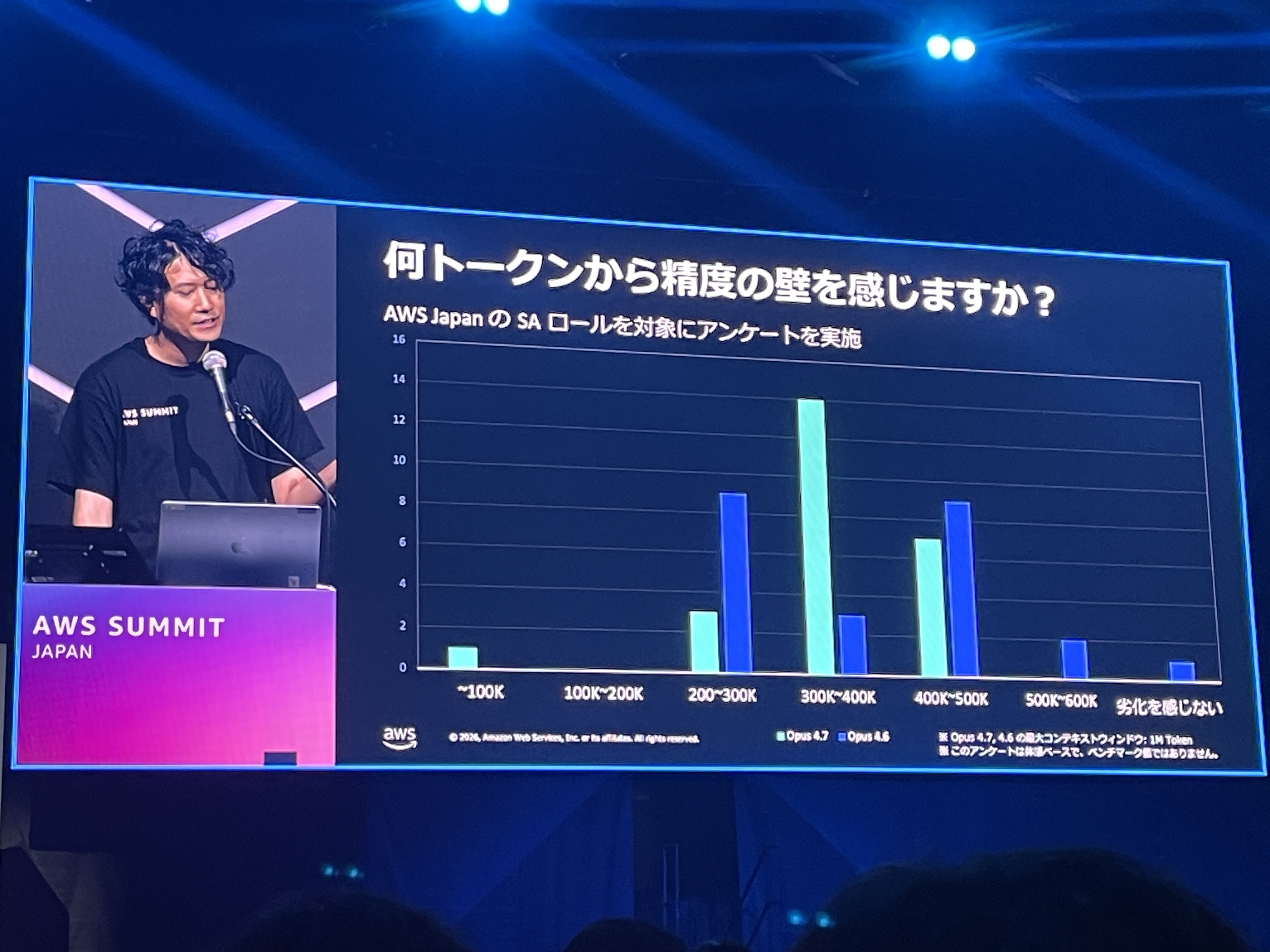
AWS JapanのSAロールを対象にしたアンケート結果が紹介されました。Opus 4.7では300K〜400Kトークンあたりで精度の壁を感じる人が最も多く、Opus 4.6では400K〜500Kトークンにピークがあるというデータでした。
コンテキストウィンドウの「Smart Zone」と「Dumb Zone」
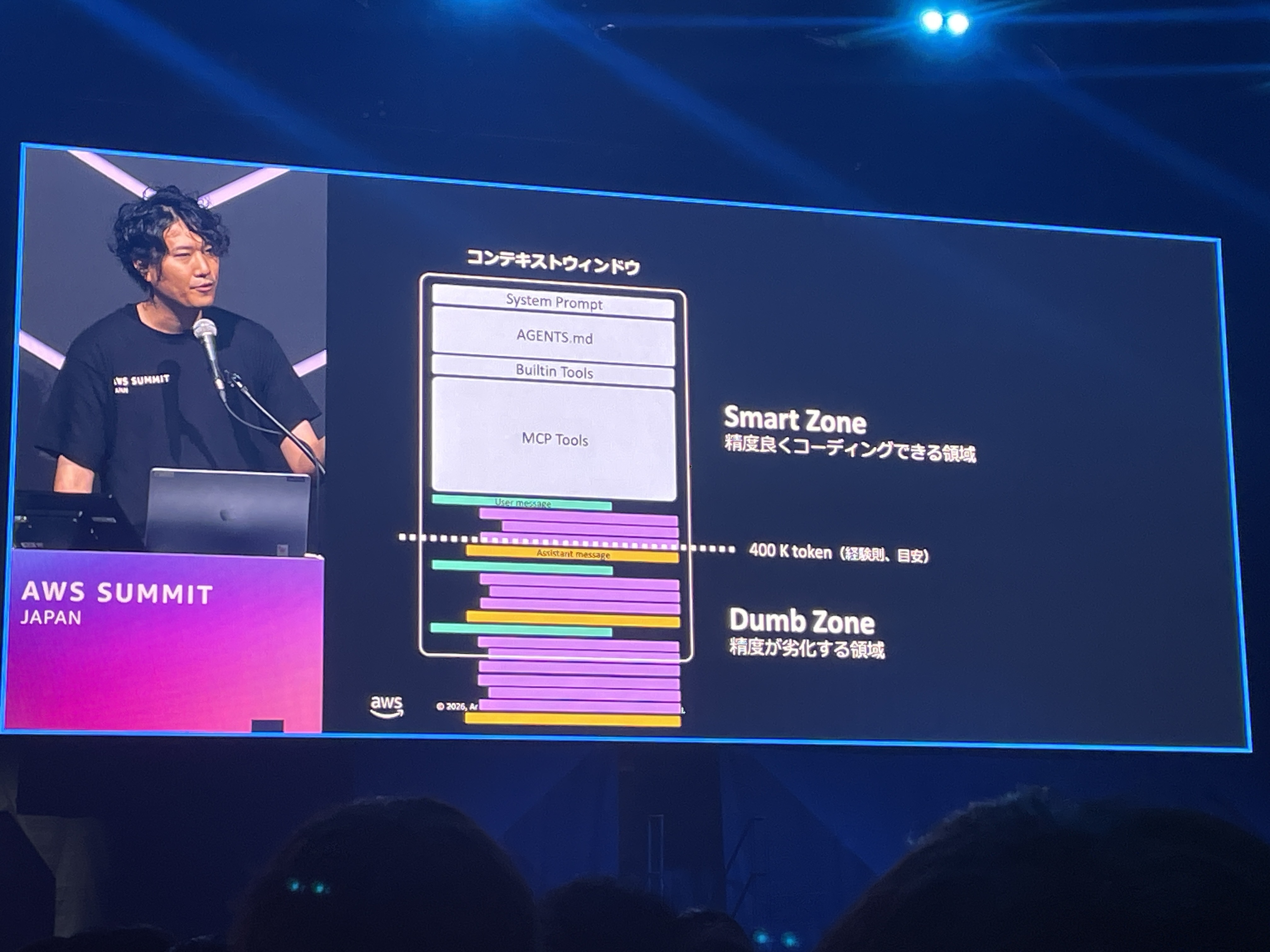
コンテキストウィンドウには「Smart Zone(精度良くコーディングできる領域)」と「Dumb Zone(精度が劣化する領域)」があるという概念が紹介されました。昨今扱える1Mコンテキストのモデルに対して約400Kトークンを経験則上の境界として、System Prompt、AGENTS.md、Builtin Tools、MCP Toolsなどが上部を占め、ユーザーとアシスタントのメッセージが積み重なるにつれてDumb Zoneに入っていくという図解です。
このDumb Zoneに入った状態がいわゆるコンテキストロットで、会話が長くなるほどノイズが蓄積し精度が劣化していきます。これは開発に限った話ではなく、資料作成や調査用途でも起こるというのが実感としてあります。長い会話の中でAIに資料を作らせていると、途中から品質が落ちたり、冒頭の指示を忘れたりする経験は多くの方にあるのではないでしょうか。
セッションを要約して切り替える
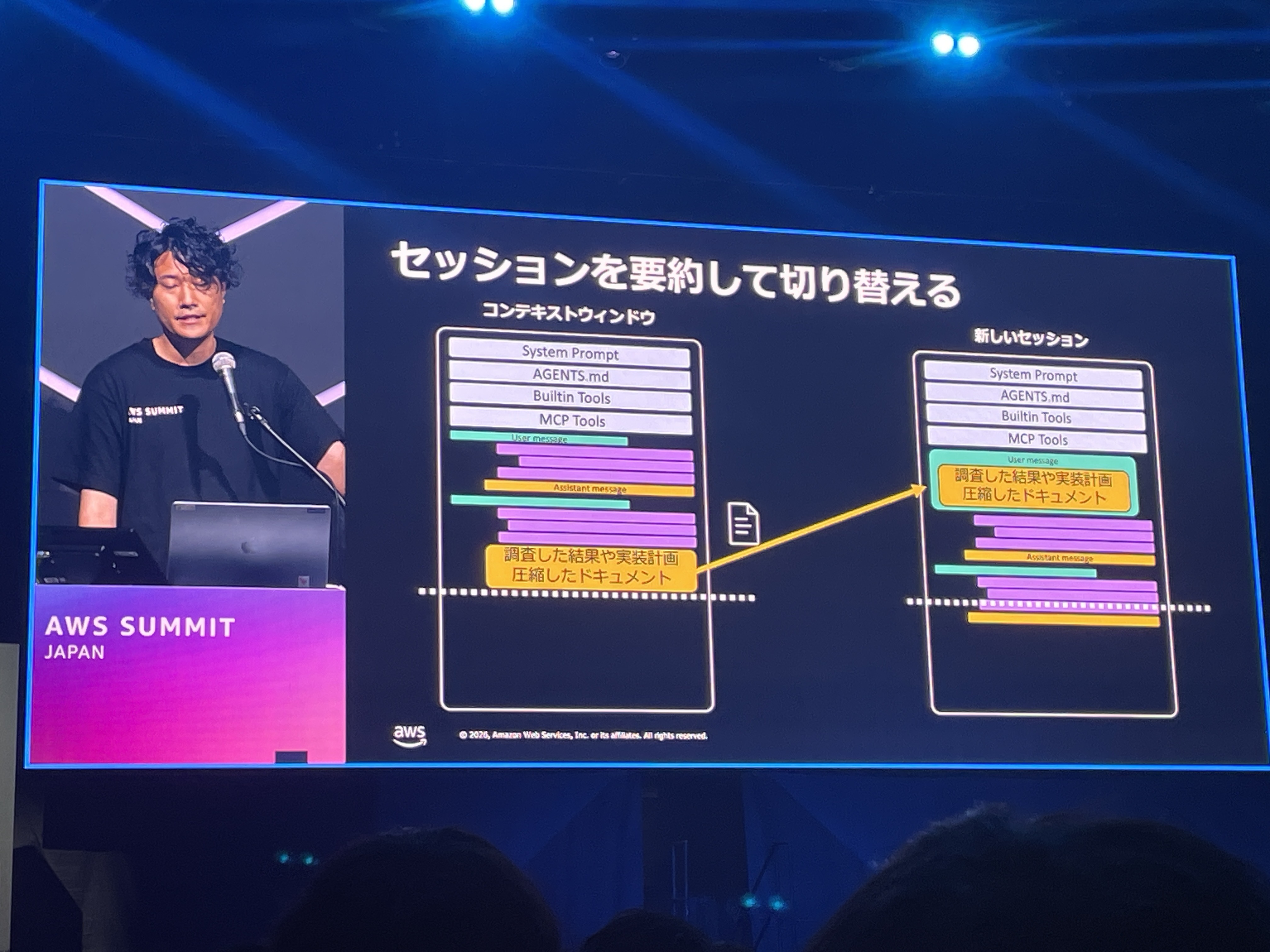
コンテキストロットへの対策として、作業の区切りで引き継ぎドキュメントを作成し、次のセッションでそれを引き継ぐというアプローチが紹介されました。調査結果や実装計画、現在の課題を圧縮したドキュメントにまとめ、新しいコンテキストウィンドウのSmart Zoneを有効に使い続けるという考え方です。
Claude Codeでは/compactコマンドで会話を圧縮する機能がありますが、これをより意図的に、必要なコンテキストだけを選別して引き継ぐ運用は実践的だと思いました。自分も実作業でよくやります。
主要なシステムのコード量

1行あたり約10トークン程度ですが、実際には1万行程度でもコンテキストに収まりづらいという話がありました。IPAの「ソフトウェア開発分析データ集」に基づく概算として、小規模(〜1万行:部門内の小さなWebシステムや単機能のWeb API)、中規模(1万〜10万行:一般的な部門業務系の1サブシステム)、大規模(10万行〜:典型的な業務システム本体)という分類が示されていました。
全てのコンテキストを凝集する — Monorepo

コーディングエージェントが効果的に計画・実装するには、全てのコンテキスト(ソースコード、IaC、設定ファイル、設計ドキュメント、エージェントのステアリングファイル)を1つのリポジトリに凝集することが理想的だという主張です。

Monorepoにおけるディレクトリ構成の例として、README.md、AGENTS.md、skills/、docs/、packages/(libs/、frontend/、backend/、Infra/)という構成が紹介されていました。
Monorepoでコンテキストを集約する方針は効果的だと思いますが、個人的には開発言語やフレームワーク、システムの特性によって最適なパッケージ境界は変わってくるので、「Monorepoにすればいい」で終わりではなく、その中のパッケージ分割をどう設計するかが本質的な課題だと思っています。
Monorepoの弱点と考慮するポイント

Monorepoの弱点として、1つのリポジトリで全てのファイルにアクセスできる一方でコードベースが肥大化し、何も工夫をしなければエージェントは大量のファイルを読み込んでコンテキストウィンドウを圧迫するという課題が挙げられていました。対策として「パッケージの依存関係を最小限にし、細部を見なくても理解できる構造を作る」という方針が示されています。
実装の細部を読まずとも理解できる状態を作る
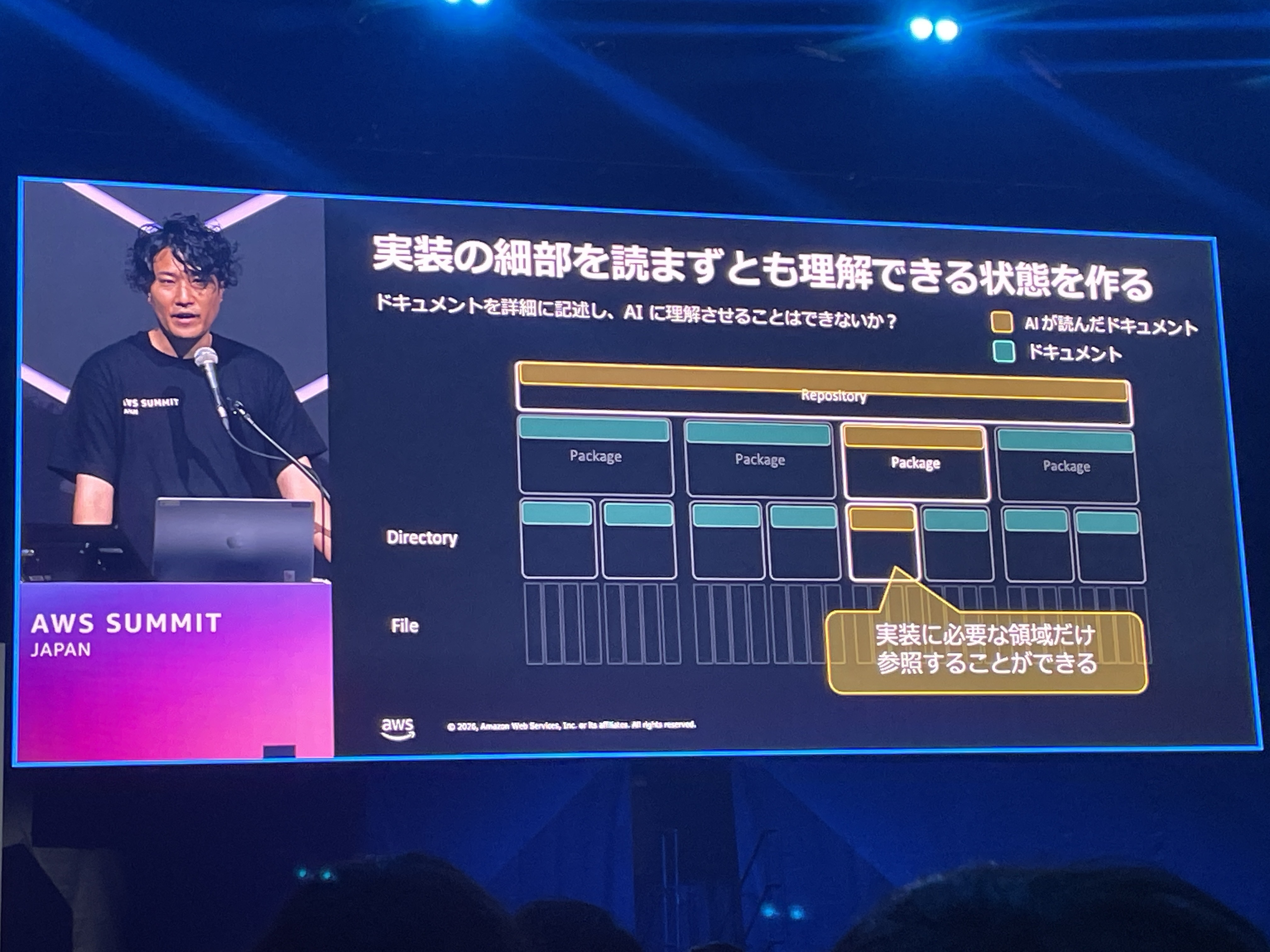
「ドキュメントを詳細に記述し、AIに理解させることはできないか?」という問いに対して、Repository > Package > Directory > Fileの階層構造で実装に必要な領域だけを参照できる設計が理想だとして図示されていました。しかし、この理想を追求した結果として次のスライドにつながります。
「ドキュメントは腐る」— 実装との乖離
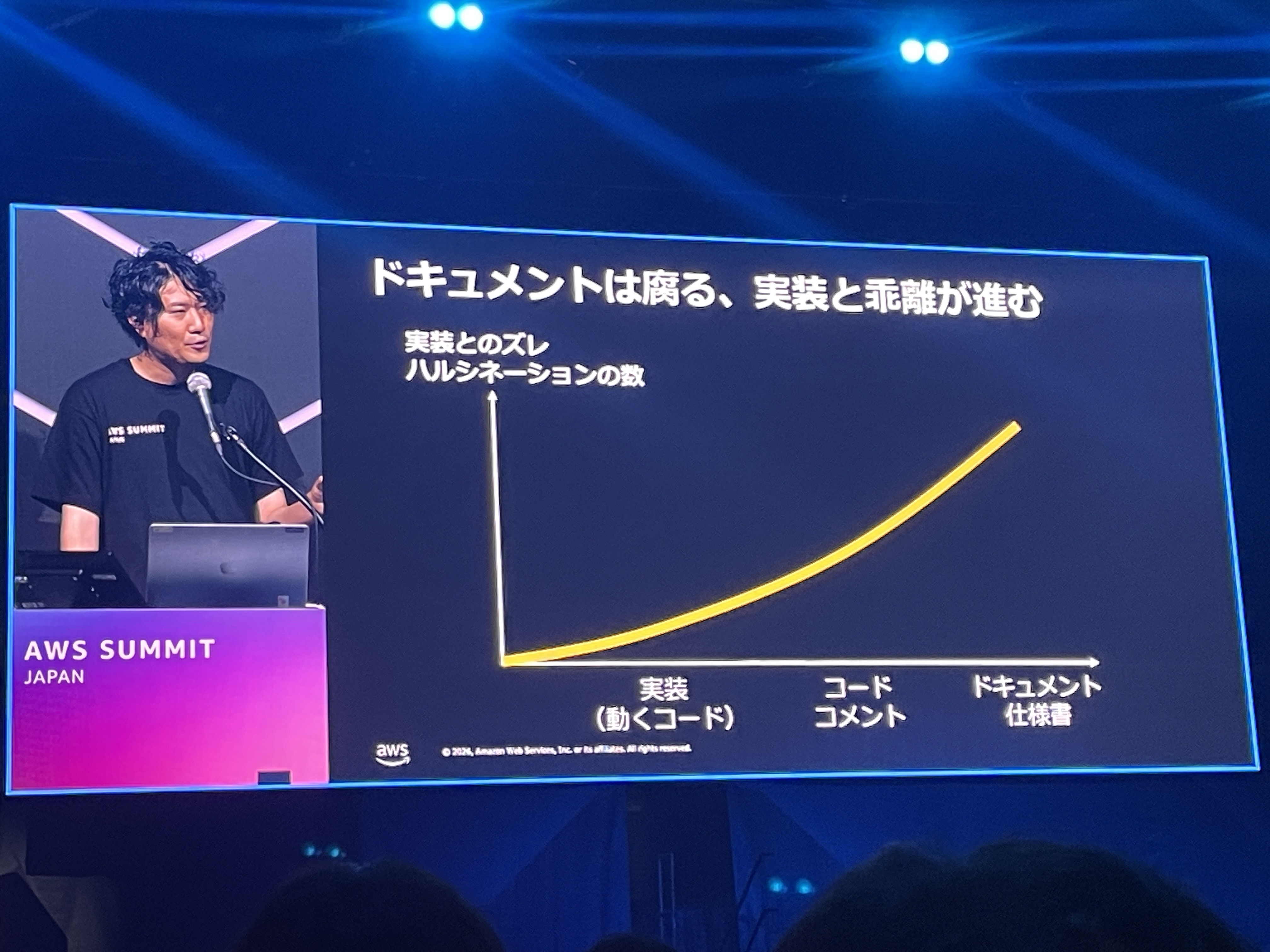
ドキュメントは実装から離れるほど、実装とのズレやハルシネーションが増えるというグラフが示されていました。実装(動くコード)が最も信頼でき、コードコメント、ドキュメント・仕様書の順に乖離が大きくなります。
自分もAI駆動開発で「まずドキュメントをしっかり整備してAIに読ませよう」というアプローチを試したことがあり、開発スピードに追従し続ける難しさを感じていました。ドキュメントの維持に注力するよりも、アーキテクチャそのもので情報を表現するという考え方は、より持続可能なアプローチだと思います。
AIが開発しやすいソフトウェアの構造を考える

パッケージ内のファイル群が複雑に絡み合った依存関係を持っている状態が図示されていました。これでは、AIが1つの機能を修正しようとしても大量のファイルを読み込む必要があり、コンテキストウィンドウを圧迫してしまいます。
モジュール境界を意識して設計する

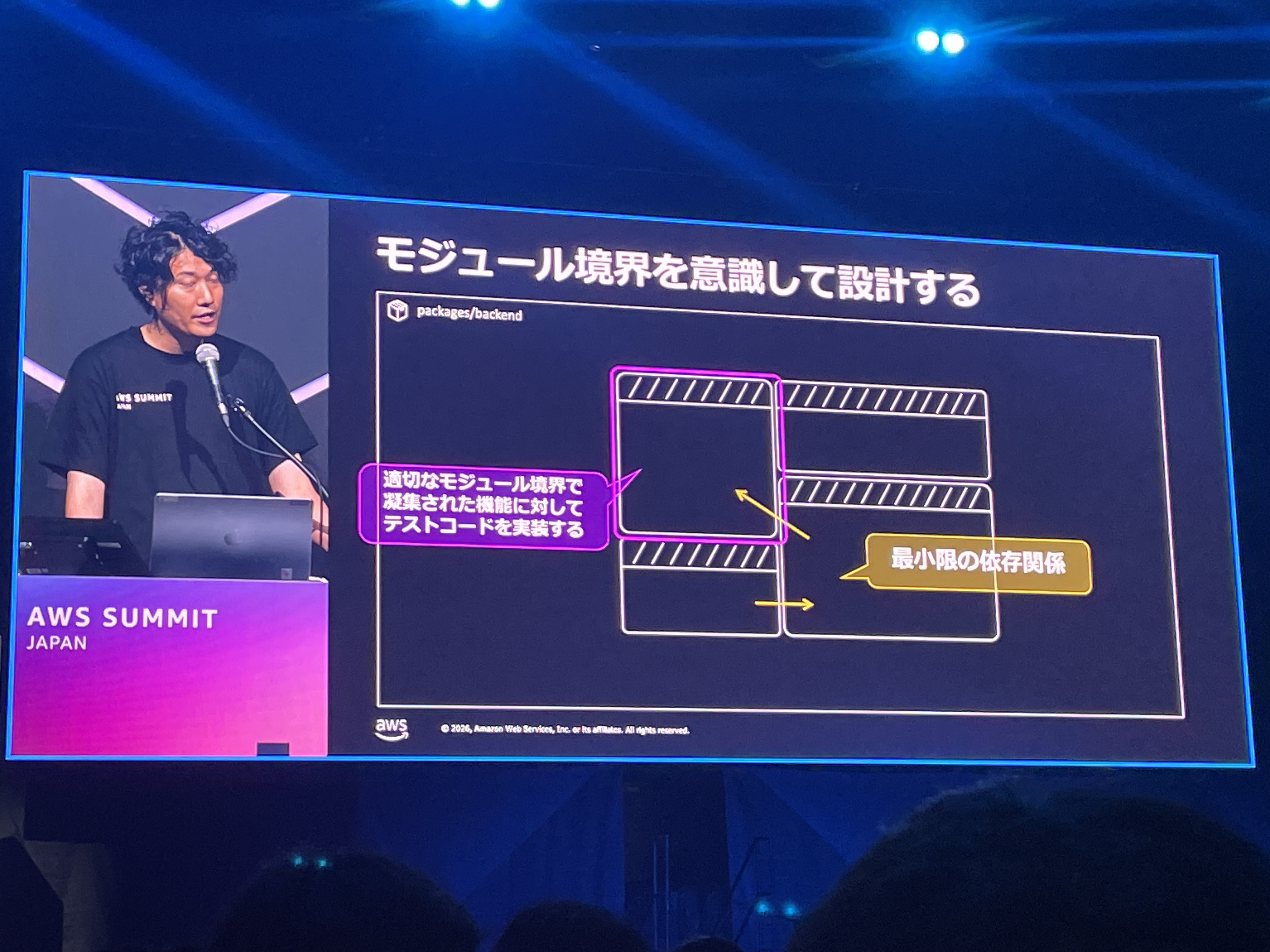
複雑に絡み合ったファイル群をモジュール境界で分割し、凝集された機能に対してテストコードを実装する、というBefore/Afterが示されていました。モジュール間の依存関係は最小限に保ち、インターフェースを通じてのみやり取りする設計です。
DDDの境界づけられたコンテキストやクリーンアーキテクチャの依存関係の方向制御など、従来のソフトウェアアーキテクチャの議論と重なる部分が多く、これらの知見をAIエージェント向けにどう適用するかを深掘りしていきたいテーマです。
Deep ModuleとShallow Module
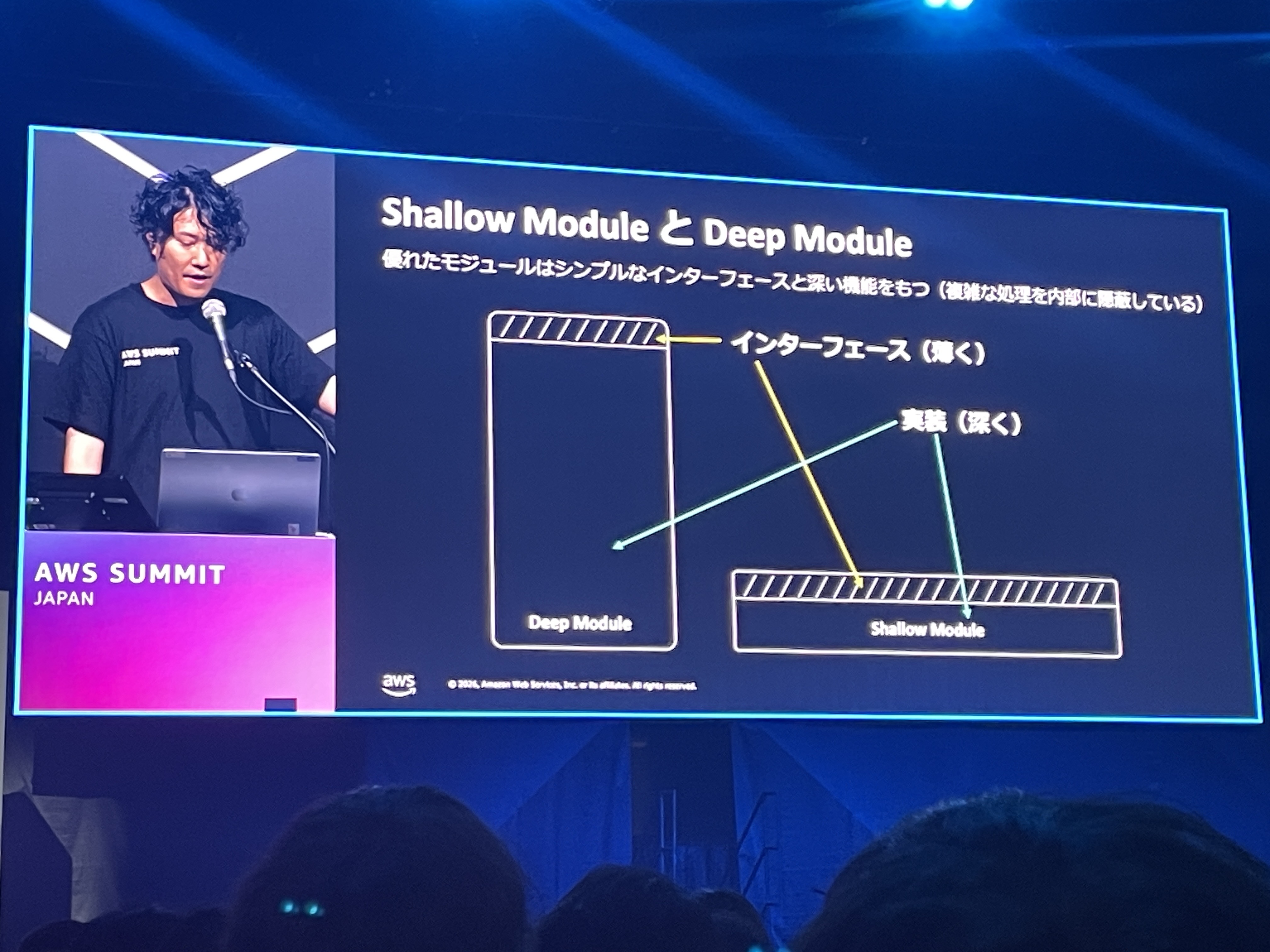
John Ousterhoutの「A Philosophy of Software Design」から引用された概念で、優れたモジュールはシンプルなインターフェースと深い機能を持つ(複雑な処理を内部に隠蔽している)というものです。
Deep Moduleとしてのあるべき姿は抽象度が高い概念なので、具体的にどう適用するかは自分の中でまだ整理しきれていません。AIエージェントがインターフェースだけを読んで判断できる設計が理想だという方向性は理解できるので、実際のプロジェクトで試しながら解像度を上げていきたいところです。
サービスクラスのインターフェースの例

TypeScriptのBefore/Afterで具体的なコード例が示されていました。Before側ではid: string、email: stringのように素の型を使っているのに対し、After側ではUserId、Email、UserName、ISODateStringといったBranded Types(型表現の強化)を使っています。
下部にはconst user = await userService.getUser(input.email);とするとコンパイルエラーになる例が示されており、Email型をUserId型に割り当てることはできないという型安全性がAIへのフィードバックにもなるという主張です。
DDDの値オブジェクトと重なる概念で、Branded Types自体は他の文脈でもよく紹介されています。ただ、型安全性を「AIへのフィードバック手段」として位置づけている点は、人間のための型安全性とは異なる切り口で、コンパイルエラーがAIの自己修正を促すという使い方は実用的だと思いました。
Git管理するドキュメントには何を書くべきか

| 情報の種類 | 内容 | Source of Truth |
|---|---|---|
| WHAT(現在の振る舞い) | 型・API・スキーマ・テーブル定義 | インターフェース、型、OpenAPI Spec、テストコード |
| HOW(どう動くか) | アルゴリズム・実装の詳細 | コード |
| WHEN, WHO(いつ誰が) | 変更の事実 | Gitのログ |
| WHY, WHY NOT(なぜそうなっているか) | 意思決定の文脈、棄却された選択肢 | コードコメント、ドキュメント(ADRなど) |
つまり、ドキュメントとして書くべきは「WHY / WHY NOT」— アーキテクチャの設計思想や意思決定の背景であり、日々更新されるWHATやHOWはコードやインターフェースに任せるべきということです。逆を言えば、開発者が意識すべきは変わらない概念設計の部分であるということ。
例えば、「このサービスはなぜDynamoDBを選定したのか(RDSではなく)」「なぜこのAPI設計でページネーションにカーソル方式を採用したのか」といった意思決定の背景や、棄却した選択肢の理由こそドキュメントに残すべきで、テーブルスキーマやAPIのリクエスト/レスポンス定義はコードやOpenAPI Specに任せる。こうした使い分けを普段の開発で意識していきたいです。
最適なサーバーレスアーキテクチャを考える

セッション後半では、ここまでのソフトウェア設計原則をサーバーレスアーキテクチャに具体的に適用する話に移りました。
Lambda関数の粒度: Pragmatic Lambda
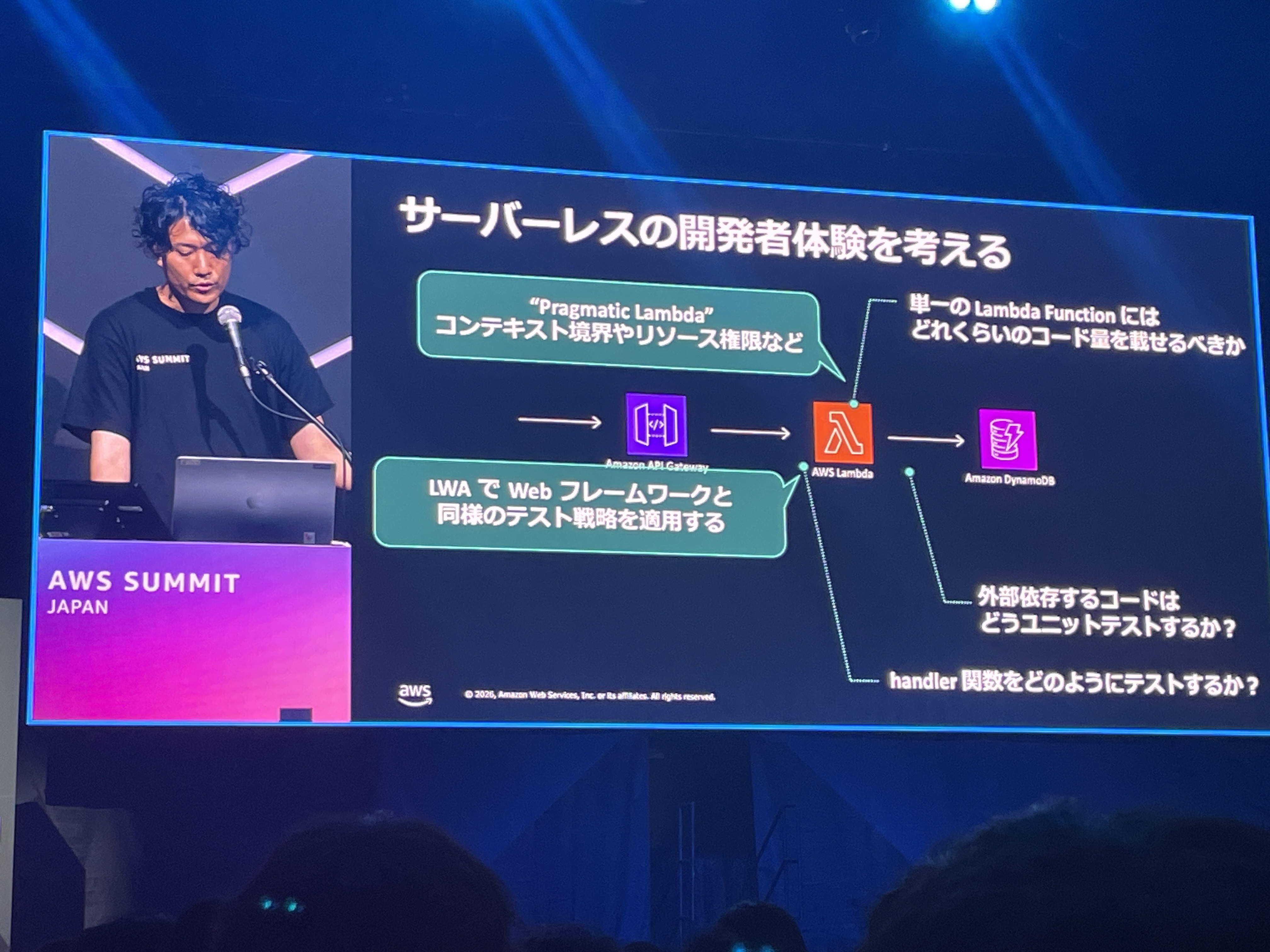
Lambda関数にはどの程度のコード量を凝集すべきかという問いに対して、3つのパターンが紹介されました。
- Lambda-lith: 1つのLambda関数に全エンドポイントを詰め込む。ルーティングロジックが関数内に存在する
- Micro Lambda: エンドポイントごとに1つのLambda関数。関数数が爆発的に増える
- Pragmatic Lambda: 境界づけられたコンテキスト(User, Productなど)で分割する
さまざまなプロジェクトを通して、Lambda関数の粒度は課題だと感じていました。Pragmatic Lambdaは大規模なシステムでは筋の良い分割方法だと思います。ただし、規模と管理工数によって正解は変わるので、銀の弾丸ではないことは意識しておきたいです。
Monorepoのpackage単位でデプロイする
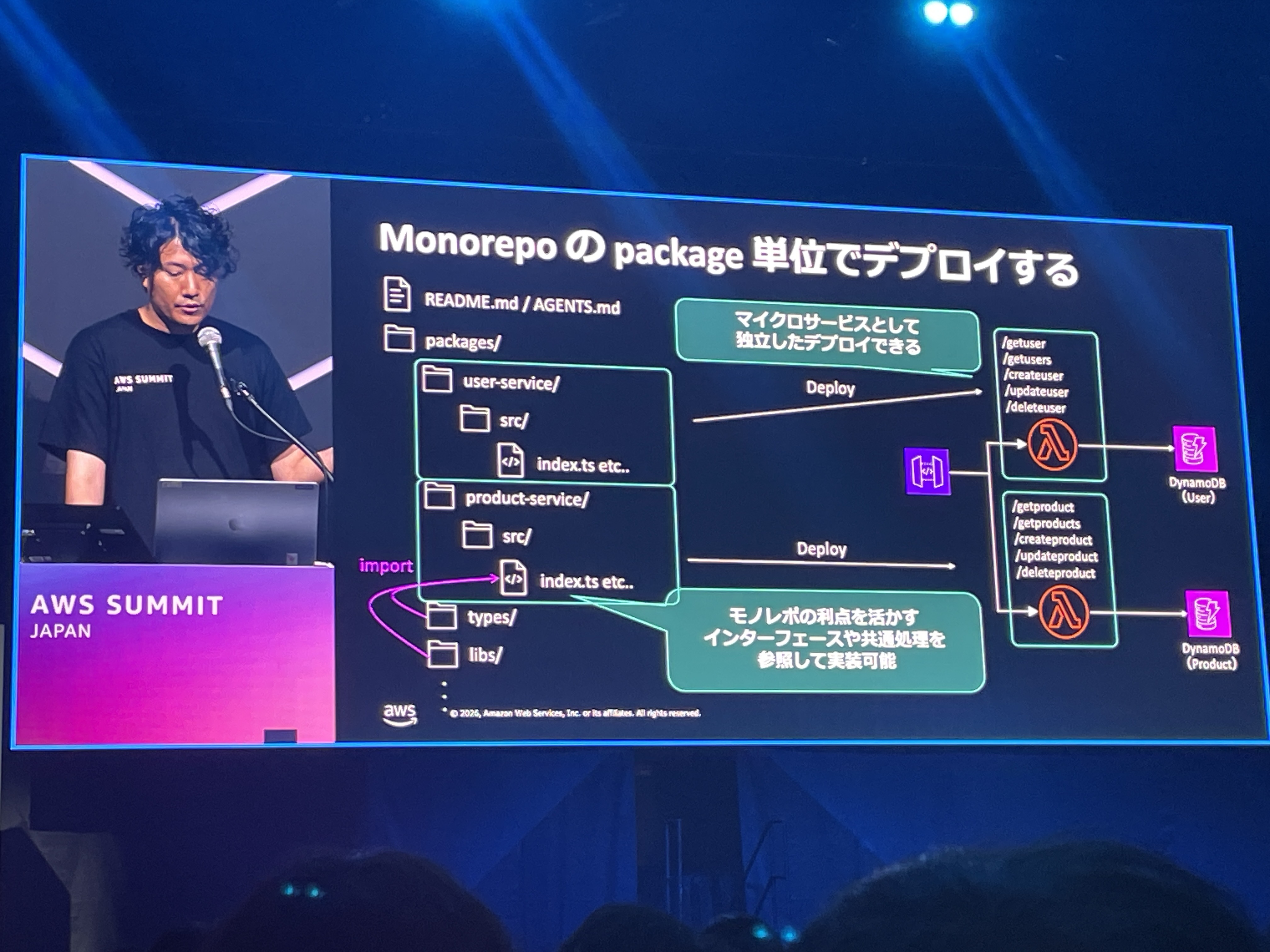
Monorepoのpackages/配下にuser-service/やproduct-service/を配置し、それぞれを独立したLambda関数としてデプロイする構成が紹介されました。各サービスはマイクロサービスとして独立したデプロイが可能でありながら、types/やlibs/といった共通のインターフェースや共通処理をimportして参照できるのがMonorepoの利点です。
Lambda固有コードが生むテストの課題

Lambda固有のhandler関数でテストを書く場合の課題が具体的に示されていました。APIGatewayProxyEventを丸ごと手組みしなければならない、DynamoDBクライアントのモックが必要、レスポンスの文字列を再度パースしなければならないなど、テストコードが本質的なロジックの検証ではなくLambdaの作法に支配されてしまう問題です。LWA(Lambda Web Adapter)を使えば、これらの課題から解放されて普通のHTTPテストとして書けるようになります。
LWAにより、Lambda固有のevent/contextに縛られず、テストの本質的な部分に集中できるというのは有効な手段だと感じました。また、LWAはHTTP以外のトリガー(SQS、SNS、S3、DynamoDB、Kinesis、Kafka、EventBridge)にも対応しており、普段使っているWebフレームワークライクにイベントを扱える点も良いと思います。
DynamoDB Local

DynamoDB Localを使ってモックテストの乱立を防ぎ、ローカル/CI環境で高速にテストするアプローチが紹介されました。DockerやJVMで起動するDynamoDBのローカルエミュレータで、ロジックの検証はDynamoDB Localで高速にテストし、IAM認可など統合テストはクラウド環境のDynamoDBも併用するという使い分けです。
DynamoDBを使う場合には有効なアプローチだと思います。一方で、他のDBやマネージドサービスについても同様に事前準備の少ないテスト戦略があると理想的で、このあたりは引き続き模索していきたいところです。
サーバーレスの開発者体験
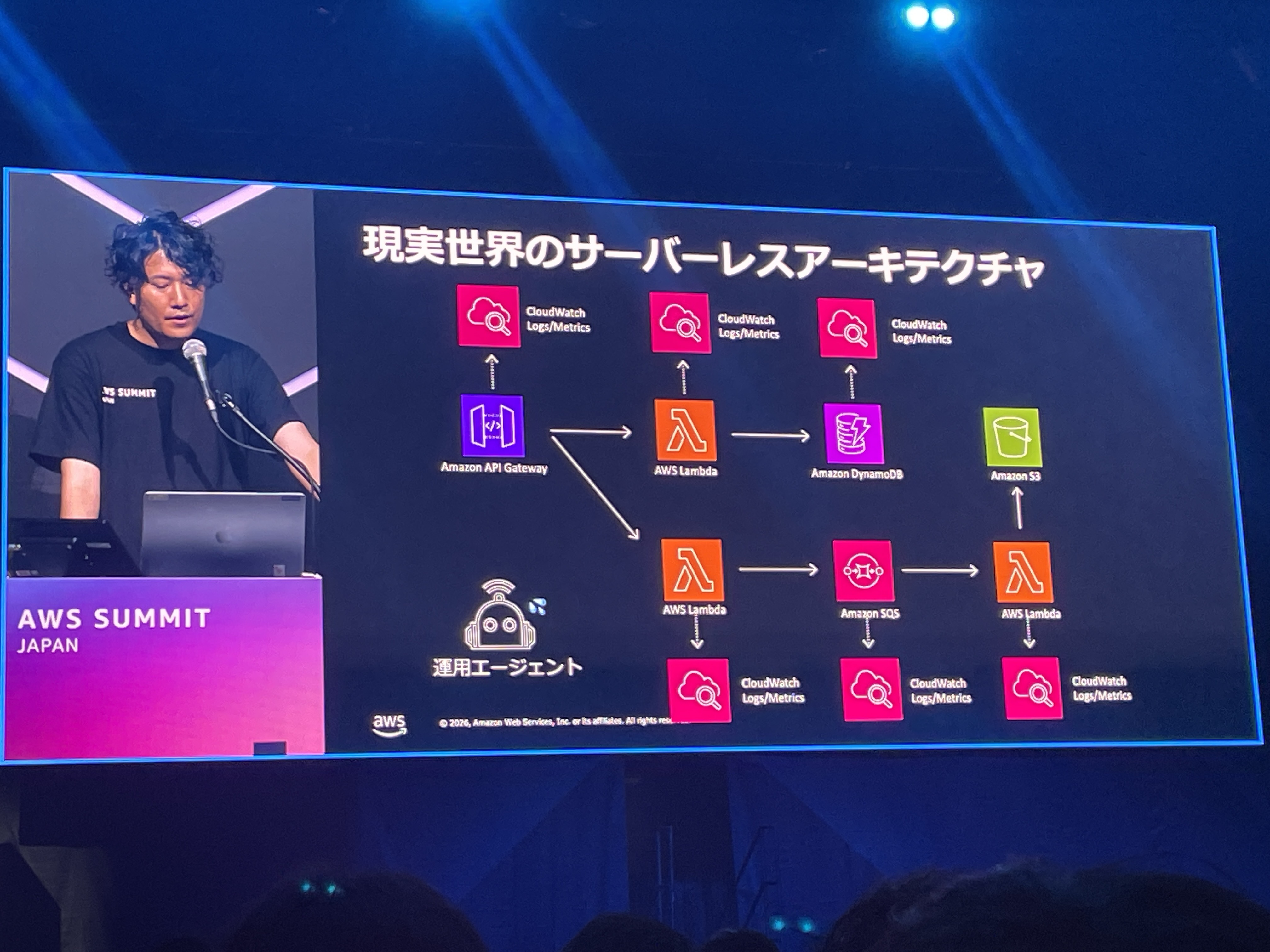
サーバーレスの開発者体験を整理したスライドです。Pragmatic Lambdaでコンテキスト境界を設計し、Lambda Web Adapter(LWA)でWebフレームワークと同様のテスト戦略を適用し、DynamoDB Localで外部依存のテストを行うという全体像が示されていました。
クラウドを運用するAIエージェントの視点

運用エージェントが必要とするコンテキスト

運用エージェントが必要とするコンテキストとして、以下の3つが挙げられていました。
- ランタイムテレメトリ: ログ・メトリクス・トレース・アラート
- アーキテクチャ情報: サービス境界・依存関係・IaC(CDK)
- 設計意図: SLO・アラートの閾値・リトライ戦略
運用エージェントがこれらのコンテキストを読み取り、異常検知、原因特定、傾向分析を行うという構成が図示されていました。
現実世界のサーバーレスアーキテクチャの課題
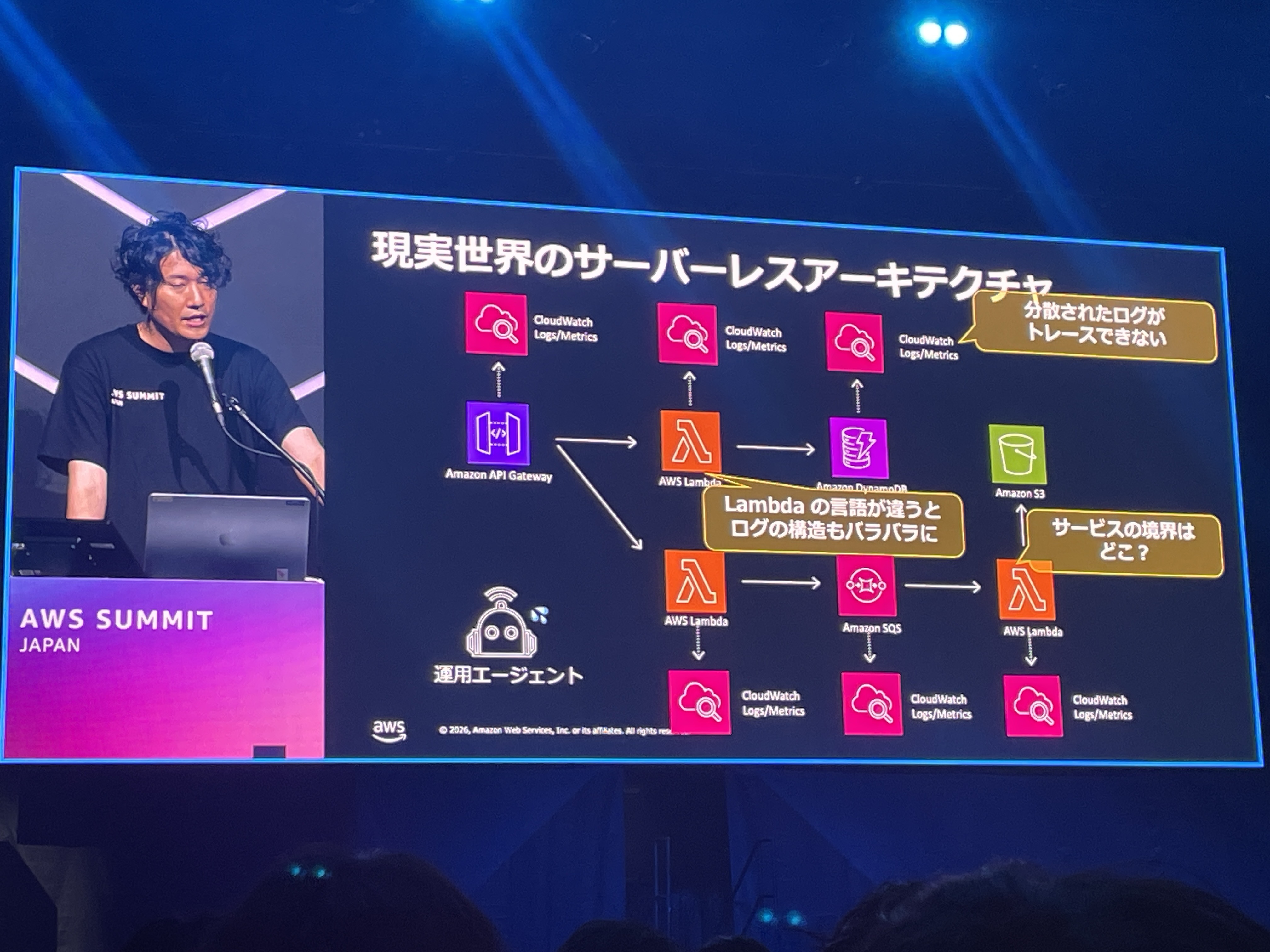
現実のサーバーレスアーキテクチャで運用エージェントが直面する課題が具体的に示されていました。
- 分散されたログがトレースできない: 各Lambda関数やサービスがそれぞれ独自にCloudWatch Logs/Metricsを出力し、横断的な追跡が困難
- Lambdaの言語が違うとログの構造もバラバラに: PythonとNode.jsでログのフォーマットが異なるなど
- サービスの境界はどこ?: API Gateway → Lambda → DynamoDB → S3、Lambda → SQS → Lambda といった処理フローにおいて、どこまでが1つのサービスなのかが不明確
共通インターフェースの重要性は開発だけでなく運用面でも重要だという理解になりました。ログ構造、API仕様、メトリクスの命名規則など、最初に決めておくべきインターフェースの具体項目を整理しておきたいと感じます。
エージェントから見た運用しやすい構造

運用エージェントの視点から見た、運用しやすいクラウド構造の3つの要件が示されました。
- 依存関係のある全てのログ、メトリクスが探索可能であること
- サービス間のアーキテクチャ境界が明確であること
- コンテキストロットしない領域(トークン数)で作業ができること
運用エージェントが調査しやすいログの例

構造化されたログの具体例が示されていました。サービス境界の明示("service": "order-service")、トレーサビリティ(function_name、xray_trace_id)、ビジネスロジックのコンテキスト(order_id、customer_id)、エラー情報、メタデータといった要素が含まれており、運用エージェントがログから原因特定や傾向分析を行うための情報が揃っている状態です。
Lambda Powertoolsによるメトリクス収集

Lambda Powertoolsを使った具体的なコード例が紹介されました。Logger、Tracer、MetricsをそれぞれserviceName: 'order-service'で初期化することで、JSON形式の構造化されたログ、AWS X-Ray統合による分散トレース、コンテキスト情報を持つカスタムメトリクスが実現できます。serviceNameでサービス境界を明示するのがポイントです。
まとめ

本セッションのポイントを整理します。
- コンテキストロット: AIのコンテキストウィンドウにはSmart ZoneとDumb Zoneがあり、ノイズの蓄積により精度が劣化する前提で設計する
- Monorepoとパッケージ境界: 全コンテキストを1リポジトリに集約しつつ、パッケージの依存関係を最小限にして細部を読まずとも理解できる構造を作る
- インターフェース・コンパクション: Deep Moduleの考え方で、インターフェースだけを読めばサービス間の境界がわかる状態を設計する
- ドキュメントの役割: WHATやHOWはコードやインターフェースに任せ、ドキュメントにはWHY/WHY NOT(意思決定の背景)を残す
- Pragmatic Lambda: Lambda関数を境界づけられたコンテキスト単位で分割し、LWAでフレームワークネイティブな開発・テスト体験を実現する
- エージェント・オブザーバビリティ: 運用エージェントの目線でログ・メトリクスのサービス境界を設計し、構造化ログとLambda Powertoolsで観測性を担保する
最後に
セッション全体を通して「コンテキストの圧縮を、ドキュメントだけでなくアーキテクチャで実現する」というメッセージが一貫していました。
自分が最も掘り下げていきたいと感じたのは、Deep / Shallow Moduleの考え方をどう実プロジェクトに落とし込むかという部分です。ここを言語化できれば、AI駆動開発でエージェントに任せられる範囲が広がると思っています。また、DDDやクリーンアーキテクチャなど既存のソフトウェアアーキテクチャ概念と重なる部分も多いので、それらとの関係性を整理しながら理解を深めていきたいです。
以上、AWS Summit Japan 2026のセッション「AIが開発/運用しやすいクラウド サーバーレスの視点から考える設計原則」のレポートでした。











