![[セッションレポート] 実践的なマルチクラウドネットワーキングの戦略 #GoogleCloudNext](https://images.ctfassets.net/ct0aopd36mqt/4VZteia2tZFWoXPzZmZcuT/32265bac33524fc15a9254504b80ef85/260401_eyechatch_googlecloudnext26_w1200h630.png?w=3840&fm=webp)
[セッションレポート] 実践的なマルチクラウドネットワーキングの戦略 #GoogleCloudNext
はじめに
こんにちは、すらぼです。Google Cloud Next' 26 Las Vegas のセッション "Build a cross-cloud network to connect apps securely across clouds"(マルチクラウドをプライベートに接続する Cross-Cloud Network まわりの総括セッション)のセッションレポートです。
ここよりセッション紹介
セッションの内容
本セッションでは、大きく次の4つの柱が語られました。
- AI ワークロード向けの Cross-Cloud ネットワーク
- マネージドサービス向けのセキュアな接続
- Google Cloudへの移行
- 金融取引所向けの超低遅延(ULL)
背景:なぜ今、マルチクラウドのネットワークか

マルチクラウド・ネットワークの需要を押し上げるトレンドとして、セッションでは主に次が挙げられています。
-
自律型AIの加速
AI技術の進化により、自律的にタスクをこなす「Agentic AI」が急速に普及しています。AIが参照するデータソースは一箇所に集中しておらず、さまざまな場所に分散しています。これを効率的に活用するために、マルチクラウドが求められています。 -
ワークロードのモダナイゼーション
システムを最新の技術に合わせてモダナイズしていく動きです。単一のベンダーに縛られず、各クラウドの「一番良いサービス」を組み合わせて使うアプローチが主流になっています。
Kubernetes に代表されるような、コンテナ技術やマイクロサービスをベースとしたアーキテクチャへアプリケーションを作り変える動きが、複数環境への分散を容易にし、複数クラウドの活用も後押ししています。 -
信頼性・主権・パフォーマンス要件
システムの安定稼働と、データの法的な取り扱い(データレジデンシー)は、企業にとって妥協できない大前提となっています。
複数のクラウドのワークロードを分散させることで、安定稼働をより向上させることができます。また、データレジデンシーを満たすために、要件に合わせて適切なクラウドの保存場所を選択する必要もあります。
1. AI ワークロード向けの Cross-Cloud ネットワーク
このセッションでは、AI 時代に向けた基盤として、計算チップだけでなくネットワークも重要なインフラの1つであると紹介されました。
その大きな要因として、AIの進化によって消費電力やデータ量が爆発的に増加しています。計算の処理を行うロケーションが物理的に分散し、従来のネットワーク網では対応できなくなりつつあります。
そして、AIの開発では「大量のデータを、他クラウドなど外部から持ってくること(外部との通信)」と「内部で高速に計算させること(内部での通信)」の2つの基盤が重要となります。そして、このそれぞれについての Google Cloud の解決策が紹介されました。
1つめの「外部との通信」では、Cross-Cloud Interconnect / Dedicated Interconnect を使って、他クラウドからデータを取得する機能を提供します。 400Gbps の回線を、LAG によって最大 8つ束ねることができ、最大 3.2 Tbps という超高速な通信を実現します。
この高速な回線によって、GPU / TPU といった高価なチップが「データが届くのを待つ」というアイドル時間が発生することを最小限にし、AIワークロードに対する投資効率を最大化することができます。

2つ目の「内部での通信」では、RDMA VPC・Managed Lustre・GKEを使った実装方法が紹介されました。
ワークロードが大きくなると通信が増加し、遅延が発生しやすくなります。結果として GPU / TPU のアイドル時間増加につながります。クラスタ内では、ノード同士が CPU を介さずメモリへ直接送受信する RDMA VPC でノード間をつなぎ、損失の少ない低遅延と高い帯域を確保できます。
ストレージには Managed Lustre を組み合わせることで、10TB/s 級の入出力を扱えるようになり、こちらもアイドル時間の削減につながります。
また、実行環境に GKE を選択することで、ノードは最大 125,000 まで広げることができ、大規模なワークロードであっても十分なスケーリングが可能になっています。

2. マネージドサービス接続と Cross-Cloud Interconnect
Google Cloud の自前で管理するコンピューティングリソースへのアクセス方法については1つの実現方法がわかりました。次に、BigQuery などマネージドサービスでのマルチクラウドの実現方法についてです。
これまで、AWS や Azure などの外部環境から Google Cloud のサービスを使おうとすると、ブループリント(正解となる構成)がなく、以下のような課題がありました。
- 通常のインターネット経由では、必要なパフォーマンスが得られない
- 冗長性・セキュリティ・信頼性を自身で確保する必要があり、運用が複雑。
- コストが予測できない
これらに対して、Google Cloud では以下のような3つの要素から成る「ブループリント」を用意し、課題に対する解決策を提供します。
- Cross-Cloud Interconnect: 堅牢なクラウド間通信を実現
- Private Service Connect(PSC): サービスベースでの接続経路を確保
- Network Connectivity Center(NCC): これらの構成を一元的に管理し、スケーラブルな運用を実現
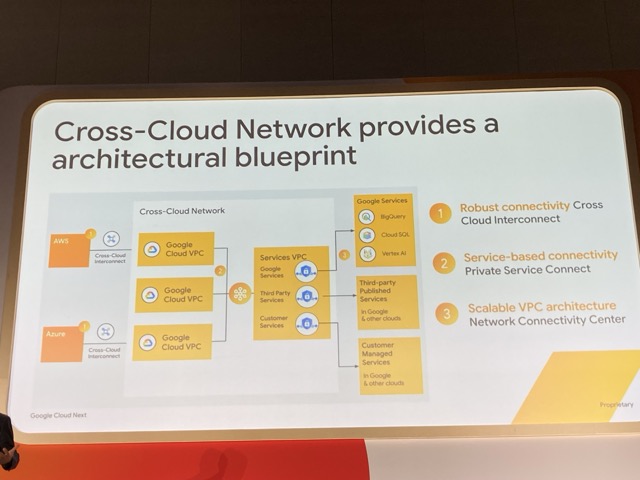
このうち、Cross-Cloud Interconnect に関しては今回の Next のタイミングで正式に GA が発表されました。
数分でデプロイできるシンプルな設定、デフォルトで回復力やセキュリティを持っているといった機能的なメリットがあります。
また、請求は通信量ベースではなく固定の請求であるため、費用の管理が行いやすいというメリットも紹介されています。

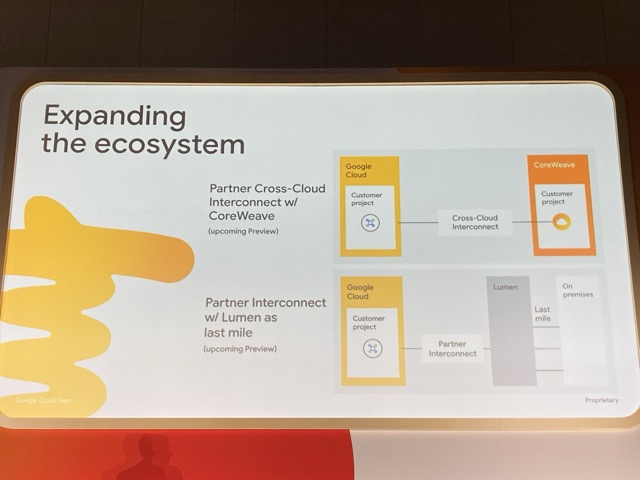
また、今後の更なる拡大として、AWS や Azure 意外にも、CoreWeave との連携や、 Lumen を通じたオンプレミスとの接続など連携を拡大していくことが予告されました。
3. Google Cloud へのマイグレーションを支えるネットワークサービス
次に、すでに大規模に構築されたオンプレミスネットワークを Google Cloud に移行するための方法について紹介されました。
そもそも、オンプレミスからの移行は以下のようなモチベーションで実施されます。
- VMやDBなどのアプリケーションを移行し、シンプルなインフラ運用にする
- クラウドのマネージドサービスを最大限活用する
そして、これを実現するためには、必ず「移行期間」が発生します。ただ、この移行期間が最もインフラが複雑化し、問題も起きやすくなります。
特に解決すべき課題と、それに対する Google Cloud の支援策は以下のようになっています。
解決すべき課題
- 将来を見据えたネットワーク構築: オンプレミスとクラウド双方を安全かつ拡張性の高い方法で実現する必要があります。
- IPアドレスの衝突回避: 誤って両者で同じIPを割り当てるなど、ミスによるシステムダウンを防ぐ中央集権的なIP管理が必要です。
- ダウンタイムなしの移行: 移行作業中も顧客へのサービス提供は停止しません。
- 環境を跨いだ可視性(オブザーバビリティ): オンプレミスとクラウドの両方で、「どこで何が起きているか」を見通せる監視方法を確立する必要があります。
Google Cloud が提供する支援策
- ネットワーク構築 → NCC と PCS の活用
- IPアドレス管理 → Cloud Number Registry(新サービス) によるIPアドレス管理
- 無停止での移行 → Hybrid Subnets(新サービス)でIPアドレスを変えずに移行
- 可視性(オブザーバビリティ)の確保 → Cloud Network Insights(新サービス)で、ネットワークのトラブルシュートを可視化

次はそれぞれのサービスについての解説です。
Networking Connectivity Center
NCC はすでにリリース済みのサービスであり、以下のような特徴があります。
- シンプルさ・拡張性: ハブ&スポーク構成により、従来のメッシュ型から構築・運用コストが大きく軽減。
- 高度なネットワーキング: マネージドサービスへの推移的アクセスなど、安全かつ高度な通信を提供。
- グローバルな活用: Site-to-site WAN / VPN や、他クラウドとの結合なども提供。
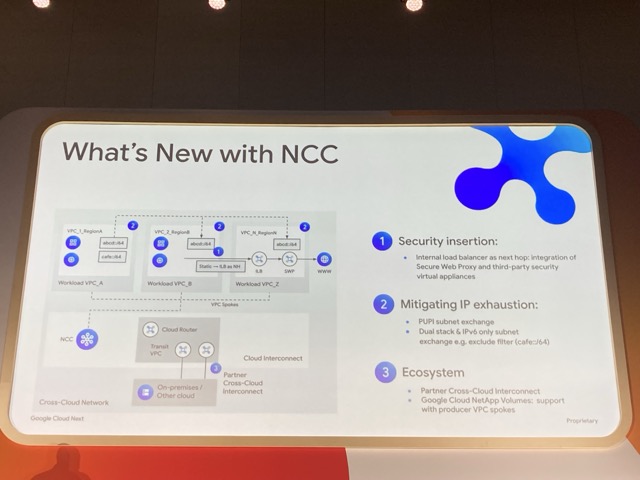
そして、今回のアップデートで以下のような新機能も提供されました。
- セキュリティの挿入: ネットワーク経路の途中に、セキュリティアプライアンスを簡単に挿入できるように。
- IPアドレス枯渇の緩和: PUPI サブネット交換のサポートや、IPv6 への本格対応により IP アドレス枯渇に対する緩和策を提供。
- エコシステムの拡大: Partner Cross-Cloud Interconnect の提供、Google Cloud NetApp Volumes に対する NCC スポークとしてサポートが提供開始。
これらの機能により、単なる VPC 同士のハブではなく、高機能な次世代のルーターに進化していることが紹介されました。
Cloud Number Registry
Cloud Number Registry(CNR)は、移行パートで挙げられた「IP アドレスの衝突を避ける、組織横断の IP 管理」に対応する新しい仕組みとして紹介されました。
CNR は、次のような特徴が挙げられます。
- 自動検出: Compute Engine まわりの IP リソースを検出し、プライベート/パブリックや IPv4/IPv6 など、目的ごとの領域に整理して一覧できる。
- 利用率の可視化: 組織全体の使用状況を把握し、枯渇を防ぐための判断材料にする。
- IP 検索: メタデータと IP 情報を組み合わせた柔軟な検索。
- IP 計画: 複数プロジェクトをまたいだ、将来の割り当ての設計。
- 外部連携: Infoblox などサードパーティとの連携で、オンプレやクロスクラウドの IP 管理ともつなげる。
またセッション中では、 Network Domain Agent が CNR や IPAM 系の API、メトリクス・ログと組み合わさり、自然言語で利用状況を問い合わせられる、という紹介もありました。

Hybrid Subnets
Hybrid Subnets は、先の一覧にあった「IP を変えずに移行する」支援に対応する新機能として、データセンター退出やクラウド移行を摩擦の少なく速く進める狙いで紹介されました。
IP アドレススキーマを保ちたい理由として、たとえば次のような点が挙げられていました。
- IP が設定・データベース・ソースコード・場合によってはバイナリまで埋め込まれている。
- IP を変えるとアプリの依存関係が壊れるおそれがある。
- 長年続いたシステムではドキュメントや暗黙知が追いにくい。

オンプレでは VMware の vMotion がこれらに対処できる一方、クラウド移行にはそれに相当する答えがありませんでした。
ネットワーク側は、Andromeda を中心とした SDN です。オンプレと GCP の VPC に同じサブネットレンジを載せ、Hybrid Subnet リソースとして両環境から広告します。
GCP からハイブリッドサブネット宛のトラフィックは、次の分岐になります。
- Andromeda が、GCP 上に応答できるエンドポイントがあるかを確認する。
- なければオンプレへ通常ルーティングで送る。
- 移行後の VM が GCP にあれば、VPC 内へローカルに届ける。
この方式のメリットとしては、標準プロトコルなのでネットワークエンジニア向けの新しい研修が不要であること、L2 カプセルを使わず MTU も変えず標準の L3 ルーティングであるのでパフォーマンス上のオーバーヘッドがないこと、IP を付け替えないので移行リスクが下がること、といった点が語られていました。

Cloud Network Insights
最後に、オブザーバビリティについてです。
Cross-Cloud ネットワークは、日々複雑さとデータ量が増しています。エージェント型や AI を含むアプリは、複数クラウド・オンプレ・SaaS・インターネットのエンドポイントやトランジットにまたがります。この規模のネットワークに対し、クラウド単体内の可視性だけでは、横断的な観測が不足する課題がありました。
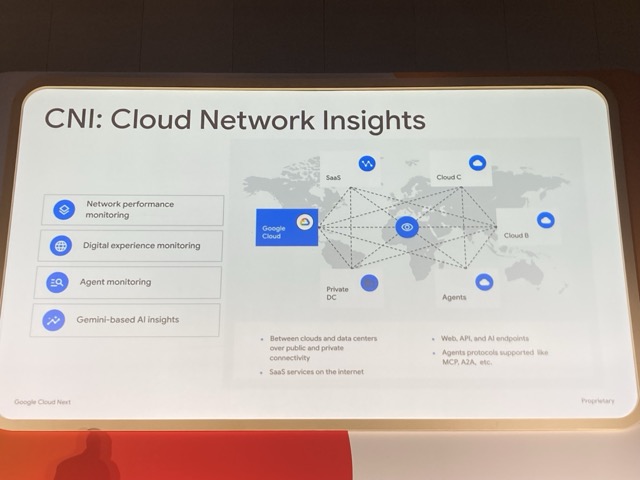
この課題に対し、Cloud Network Insights(CNI)が、ネットワークのオブザーバビリティを改善するサービスとして発表されました。ネットワーク障害の検知から緩和までの時間を短縮する狙いです。
CNI の主要な機能は次の四つです。
- ネットワーク性能の監視
- デジタルエクスペリエンスの監視
- エージェントの監視
- Gemini ベースの AI インサイト
監視対象は、パブリック/プライベート接続を経由したクラウド間およびデータセンター間、インターネット上の SaaS、Web・API・AI のエンドポイント、MCP や A2A などのエージェント向けプロトコルにも及びます。
Web アプリや API、エージェント向けのデジタルエクスペリエンス監視にも口頭で触れられ、パートナーである Broadcom の AppNeta テクノロジーを基盤にすること、Network Domain Agent と同様に自然言語で問い合わせられることも紹介されていました。
4. 金融取引所向けの超低遅延通信
金融の取引所のようなワークロードでは、規制への適合と、取引タイミングの決定性が両方とも欠かせません。Google Cloud は、この市場向けにフルマネージドの Ultra Low Latency (ULL)ソリューションを用意しており、要求の厳しい金融向け要件に合わせた用途特化インフラとして紹介されていました。

このインフラが押さえている軸は、おおまかに次の三つです。
- 市場との WAN アクセス: 高性能で、きめ細かな制御が可能。
- 決定性: 高精度のクロック同期で、取引のばらつきを抑える。
- 規制コンプライアンスと運用上の信頼性: ナノ秒単位の可観測性に加え、厳格な SLO や RTO を前提にした設計。
中央の ULL fabric が取引所オペレータと参加者を結びます。オペレータはデータを publish し、参加者は注文を execute する。オペレータ側では TPU(AI トレーディング)、HPC(分散計算)、BigQuery(大規模データ処理)なども組み合わせて使用します。
ULL に対して強調されていた技術要素は、おおまかに次のとおりです。
- サブ 10 ナノ秒級のクロック同期
- A/B フィードや順序どおりのパケット配送による冗長性と順序保証。
- 超低ジッタ・低分散で、性能の予測可能性を高める。
- ミッションクリティカル負荷向けに厳しい SLO を満たす高可用性。
これらの技術によって、超低遅延の通信を実現しています。
セッション紹介ここまで
終わりに
Cross-Cloud ネットワークに関する、最新技術のセッションを紹介しました。
最近注目され、クラウドベンダー自身も機能提供を開始しているということもあり、多くのサービスが新規にリリースされており注力を感じる領域でした。
個人的には AI による GPU / TPU の待ち時間を減らすためにハイパフォーマンスのネットワークを確保することが、結果的に計算リソースの最適化につながるという点は盲点でした。データの入出力の部分まで含めて AI の推論だと考えると、これらのネットワークの知識もより重要になっていきそうです。キャッチアップは大変ですが、AI 時代に向けてさらに知識を身につけていきたいと強く感じたセッションでした。
この記事が最新ネットワーク情報キャッチアップの助けになれば幸いです。以上、すらぼでした。









