
DSQLでもカラムテトリスによってストレージサイズが最適化されるか確認してみた
リテールアプリ共創部@大阪の岩田です。
PostgreSQLには俗にいう「カラムテトリス」によってストレージサイズを最適化するテクニックが存在します。詳細については割愛しますが、以下の記事などが参考になります。
このカラムテトリスがPostgreSQL互換を謳うDSQLにおいても有効なテクニックなのか気になったので検証してみました。DSQLはPostgreSQLのワイヤプロトコルに互換性があるものの、内部実装は通常のPostgreSQLと全くの別物です。果たしてカラムテトリスの効果はいかに?
やってみる
それでは実際に検証していきましょう。
検証用テーブルの作成
まず検証用に2つのクラスタを作成し、それぞれテーブル定義が最適化されたテーブルと非効率なテーブルを作成します。
最適化したテーブル定義は以下の通りです。
CREATE TABLE efficient(
pkey uuid PRIMARY KEY,
int4_col1 int4,
int4_col2 int4,
int4_col3 int4,
int4_col4 int4,
int4_col5 int4,
int4_col6 int4,
int4_col7 int4,
int4_col8 int4,
int4_col9 int4,
int4_col10 int4,
int2_col1 int2,
int2_col2 int2,
int2_col3 int2,
int2_col4 int2,
int2_col5 int2,
int2_col6 int2,
int2_col7 int2,
int2_col8 int2,
int2_col9 int2,
int2_col10 int2
);
主キーに続けてint4のカラムを10個、int2のカラムを10個並べています。
続いて非効率なテーブル定義です。
CREATE TABLE inefficient(
pkey uuid PRIMARY KEY,
int4_col1 int4,
int2_col1 int2,
int4_col2 int4,
int2_col2 int2,
int4_col3 int4,
int2_col3 int2,
int4_col4 int4,
int2_col4 int2,
int4_col5 int4,
int2_col5 int2,
int4_col6 int4,
int2_col6 int2,
int4_col7 int4,
int2_col7 int2,
int4_col8 int4,
int2_col8 int2,
int4_col9 int4,
int2_col9 int2,
int4_col10 int4,
int2_col10 int2
);
int4のカラムとint2のカラムを交互に配置することで意図的に無駄なパディングを発生させています。
データの投入
続いてそれぞれのテーブルに対して3千万件のデータを投入します。
今回はNode.jsで以下のような簡単なプログラムを書きました。
import { Client } from 'pg'
import { DsqlSigner } from '@aws-sdk/dsql-signer';
const region = 'us-east-1';
const clusterIdentifier = '<DSQLのクラスターID>';
const tableName = '<対象テーブル名>';
const clusterEndpoint = `${clusterIdentifier}.dsql.${region}.on.aws`;
const signer = new DsqlSigner({
hostname: clusterEndpoint,
region,
});
const main = async () => {
const token = await signer.getDbConnectAdminAuthToken();
const client = new Client({
host: clusterEndpoint,
port: 5432,
database: 'postgres',
user: 'admin',
password: token,
ssl:true
});
await client.connect();
for(let i = 0; i < 10000; i++) {
console.log(`Inserting batch ${i + 1} of 10000`);
await client.query(`
INSERT INTO ${tableName}
SELECT
gen_random_uuid(),
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20
FROM
generate_series(1, 3000)
`);
}
}
console.log('start');
main().then(() => {
console.log('end');
process.exit(0);
});
DSQLの制約により単一トランザクション内で変更可能なレコード数が3,000に制限されるため、3,000レコードのINSERTを1万ループする実装としています。
このプログラムを実行したらデータが投入されるまでしばらく待ちましょう。
ページサイズを確認してみる
データが投入できたら各テーブルのページ数、ページサイズを確認してみましょう。
そもそもですが、ページサイズは8Kなのでしょうか?一応確認しておきます。
postgres=> SHOW block_size;
block_size
------------
8192
(1 row)
DSQLでもページサイズは8Kのようですね。
では最適化したテーブルのサイズを確認してみましょう。
SELECT
relpages as pages,
(relpages * 8192) / 1024 /1024 as page_size__mb
FROM
pg_class
WHERE
relname = 'efficient';
結果は以下の通りでした。
pages | page_size__mb
--------+---------------
142410 | 1112
(1 row)
ページ数が約14万、サイズは1,112MBという結果でした。
続いて非効率なテーブルの方も確認してみましょう。
SELECT
relpages as pages,
(relpages * 8192) / 1024 /1024 as page_size__mb
FROM
pg_class
WHERE
relname = 'inefficient';
結果は以下の通りでした。
pages | page_size__mb
--------+---------------
158516 | 1238
(1 row)
ページ数が約16万、サイズは1,238MBという結果でした。
これを見る限りDSQLにおいてもカラムテトリスは有効であると言えそうですが、果たして…
DSQLのメトリクスを確認してみる
今回の検証で利用するテーブルはクラスターレベルで分離していたので、CloudWatchから各クラスタのメトリクスを比較してみました。すると結果は以下の通りでした。
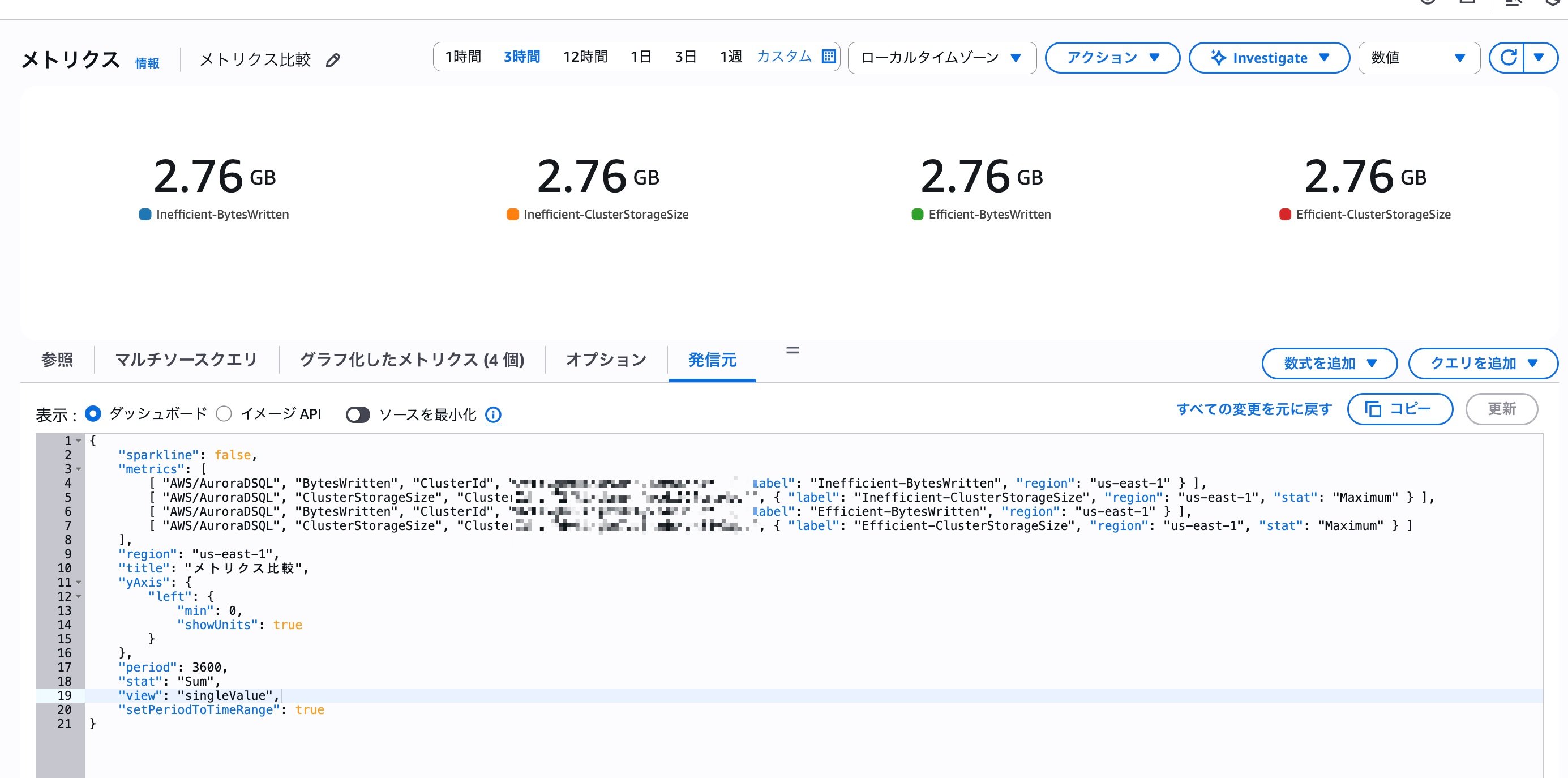
BytesWrittenの合計値、 ClusterStorageSize の最大値が全く同じになりました。この結果を見るとDSQLにおいてはカラムテトリスは無意味と言えそうです。
ちなみに各種DPUの比較は以下の通りでした。
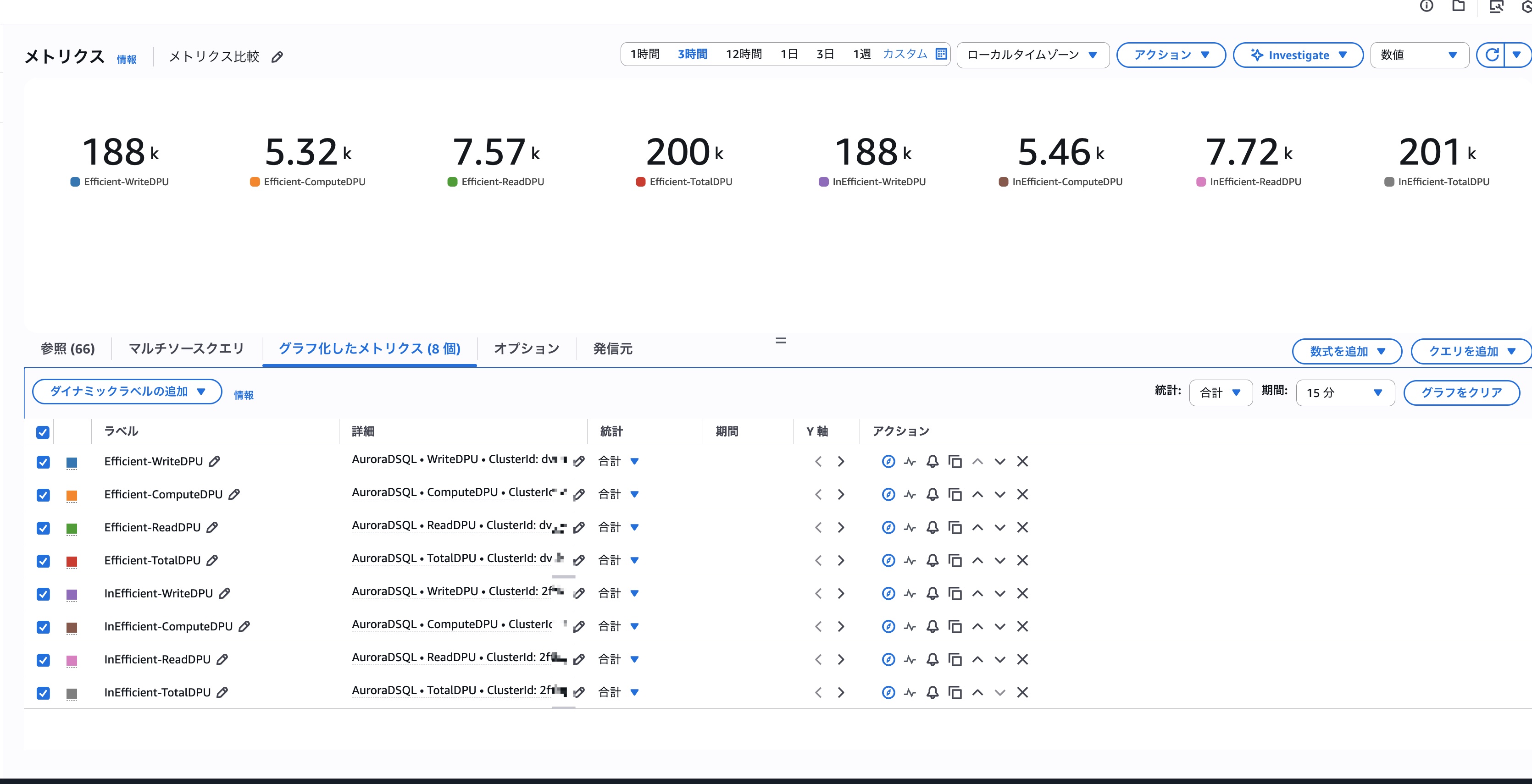
DPU関連の実績もほぼ同じ値となっています。
ANALYZEしてから再度ページサイズを確認してみる
よく考えたらpg_classは統計情報なので100%正確な情報が取得できるわけではなかったですね。かといってpg_total_relation_sizeのような関数はDSQLでサポートされていないので、とりあえずANALYZEしてから先程と同じSQLを再実行してみました。※ちなみにDSQLはVACUUMコマンドをサポートしていません。
最適化したテーブルでの実行結果は以下の通りでした。
pages | page_size__mb
--------+---------------
160331 | 1252
一方、最適化していないテーブルでの実行結果はこちらでした。
pages | page_size__mb
--------+---------------
160278 | 1252
まだ微妙に差異はありますが、最初に比べると大きく差が縮まりました。default_statistics_targetの設定なども試してみましたが、DSQLではサポートされていなかったので、pg_classの出力結果を完全に一致させることはできなさそうですね。
まとめ
pg_classから得られる情報はパターン間で多少の差異がありましたが、これはサンプリングされた統計情報という特性から発生する誤差だと考えられます。
メトリクスから確認できるBytesWrittenと ClusterStorageSize の合計値が一致していたので、「DSQLにおいてはカラムテトリスの効果は無い」と考えて良さそうです。










