
S3 Tables 向けの Iceberg REST Catalog API が追加されたので、PyIcebergからアクセスしてみた。
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部の笠原です。
S3 Tables向けのIceberg REST Catalog APIが追加されました。
以前こちらの記事ではGlueのIceberg REST endpoint経由でS3 TablesのIcebergテーブルにアクセスしていました。
今回は、その記事をベースに新たなIceberg REST Catalog APIのendpointにアクセスしたいと思います。
概要
今回追加されたエンドポイントは以下になります。
https://s3tables.<AWS_REGION>.amazonaws.com/iceberg
S3 Tablesの準備
まずはS3 Tablesのテーブルバケット・ネームスペース・テーブルを作成します。
今回も、東京リージョンでテーブルバケットを作成します。
「AWS 分析サービスとの統合」を有効化していない場合は、マネジメントコンソールから「統合を有効にする」をクリックして有効化しておきましょう。
テーブルバケットはマネジメントコンソール上で作っても構いませんが、今回はAWS CLIで作成します。
aws s3tables create-table-bucket \
--name pyiceberg-sample-bucket
ネームスペースとテーブルについては、以前はAWS CLIで作成しました。
今回はAthena経由でS3 Tablesのマネジメントコンソールから作成できるようになったので、せっかくなのでこれを試しましょう。
テーブルバケット作成後、テーブルバケット名をクリックするとテーブル一覧が表示されます。まだ何も作ってないので一覧内は空です。「Athenaでテーブルを作成」をクリックしましょう。
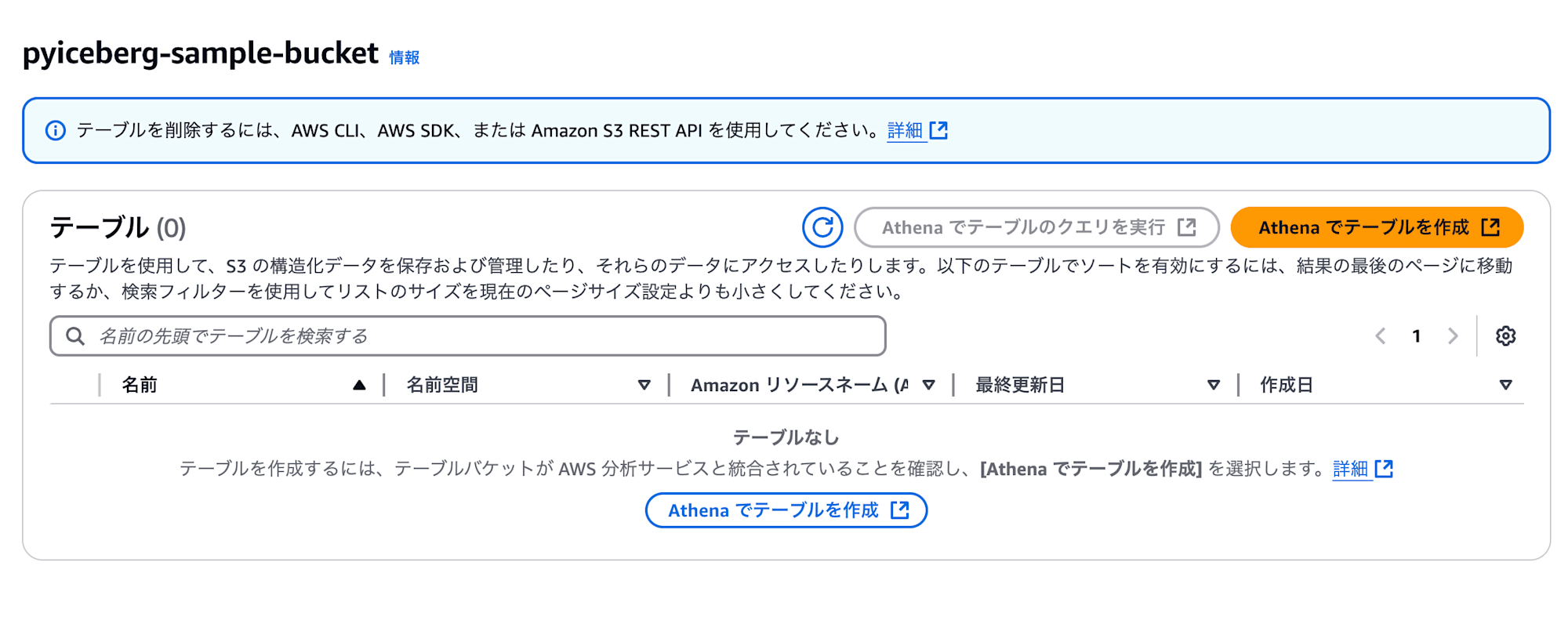
テーブル作成の前にネームスペースを先に作成します。「名前空間を作成」が選択されていることを確認して、ネームスペース名を入力します。ここでは main としています。その後、「名前空間を作成」をクリックします。
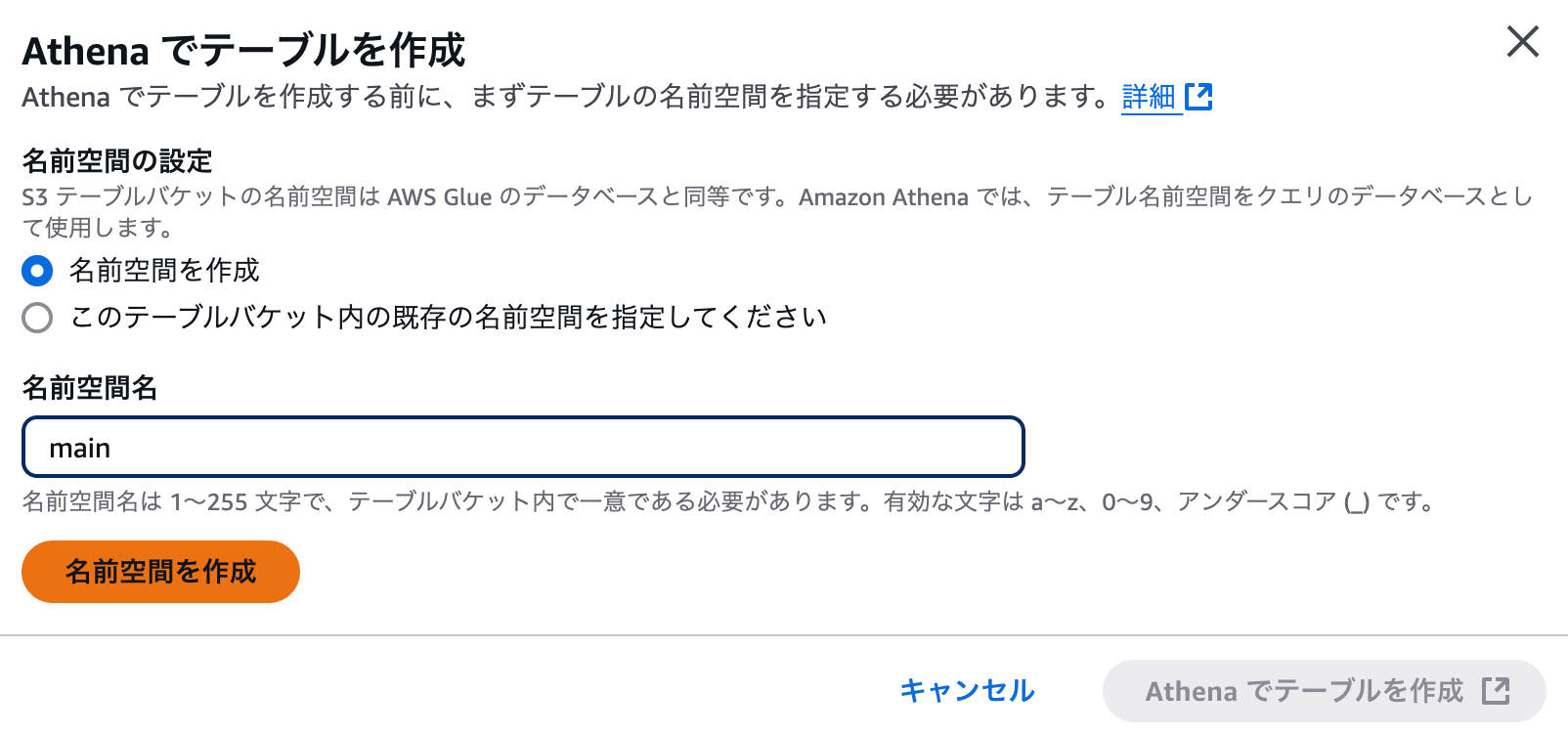
実際にネームスペースが正常に作成できたら、「Athenaでテーブルを作成」をクリックします。

Athenaの画面が表示されます。 CREATE TABLE クエリのサンプルも表示されています。
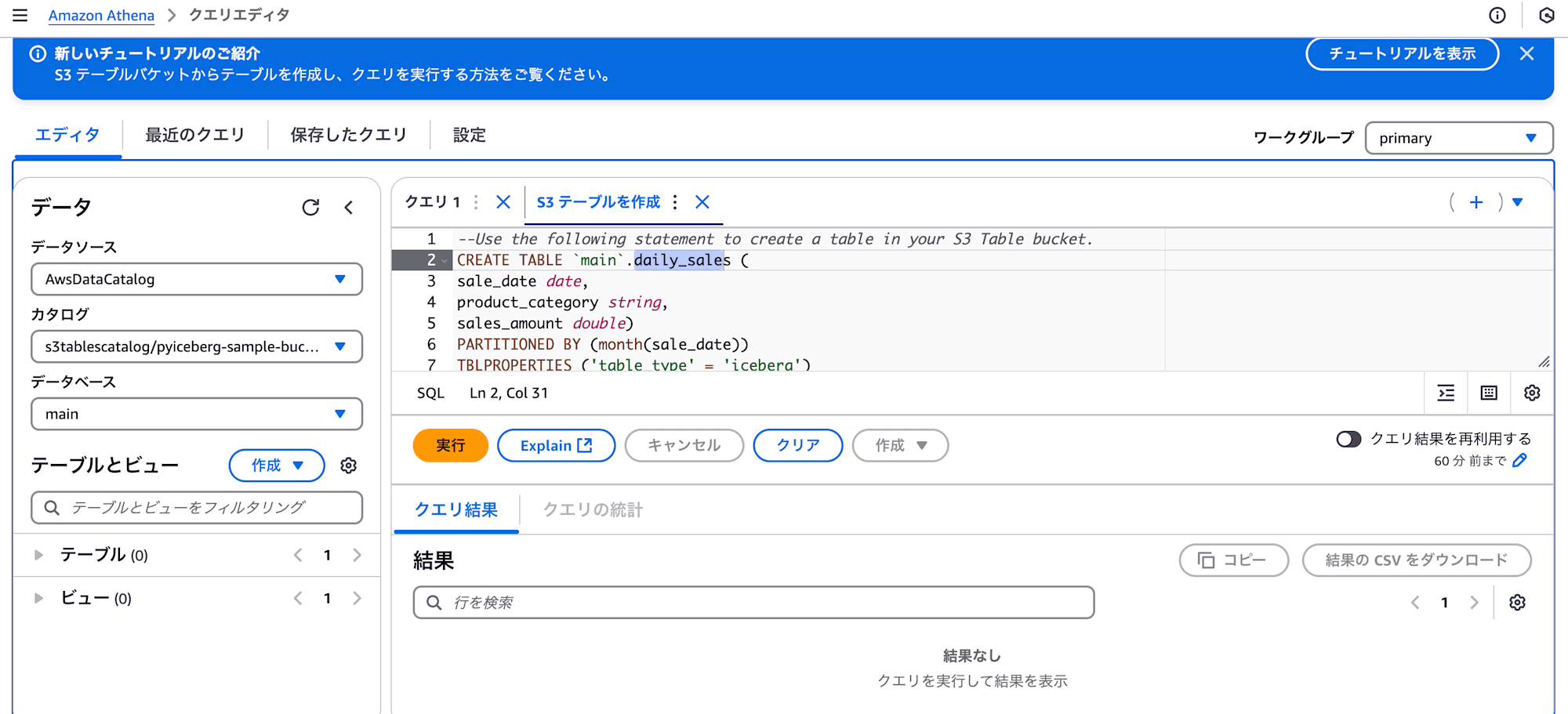
CREATE TABLE クエリは以下のように変更して、実行しましょう。
パーティション設定もおまけでやってみます。
CREATE TABLE main.temperature_humidity_histories (
sensor_id int,
created_at timestamp,
temperature double,
humidity double)
PARTITIONED BY (month(created_at))
TBLPROPERTIES ('table_type' = 'iceberg')
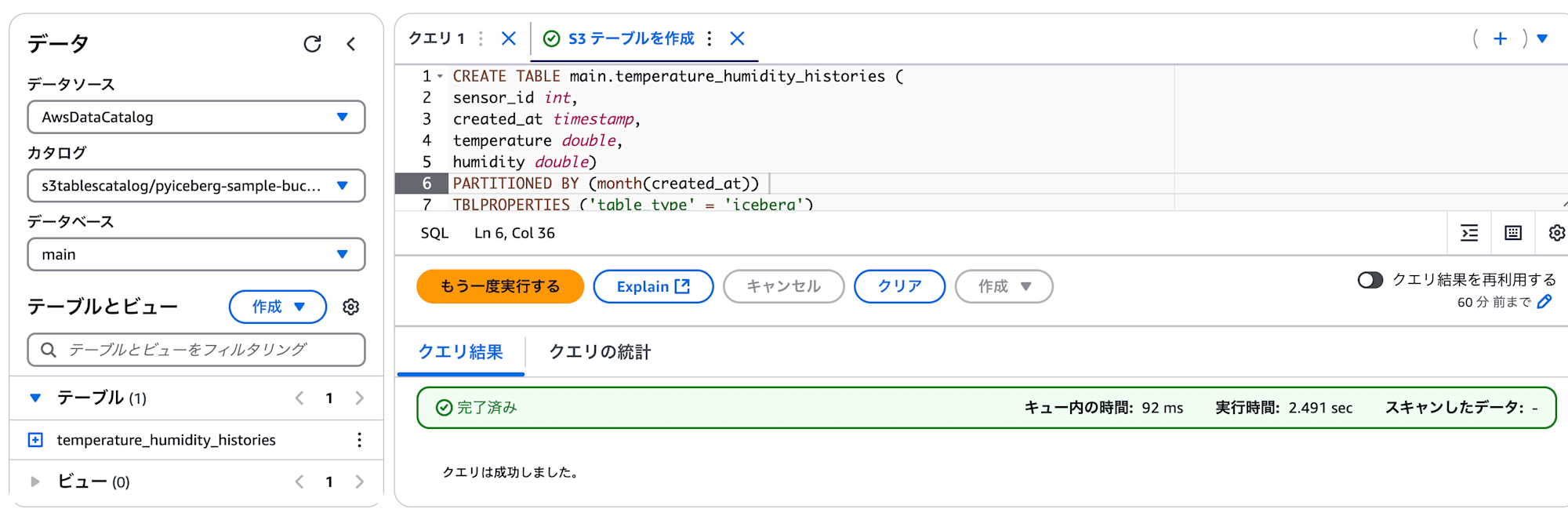
これで、S3 Tablesのテーブルバケットにネームスペースとテーブルが作成されました。
権限設定
IAMロールやLake Formationで権限設定を行います。
IAMロール
Lambda関数にアタッチするロールのポリシーは、 AWSLambdaBasicExecutionRole に加えて、以下のポリシーを設定します。今回は s3tables のアクションと該当テーブルバケットリソースへの権限が必要です。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3tables:GetTableBucket",
"s3tables:ListTableBuckets",
"s3tables:GetNamespace",
"s3tables:ListNamespaces",
"s3Tables:GetTable",
"s3Tables:ListTables",
"s3Tables:GetTableData",
"s3Tables:PutTableData",
"s3Tables:GetTableMetadataLocation",
"s3Tables:UpdateTableMetadataLocation",
],
"Resource": [
"arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/pyiceberg-sample-bucket",
"arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/pyiceberg-sample-bucket/*",
],
"Effect": "Allow"
},
{
"Action": "lakeformation:GetDataAccess",
"Resource": "*",
"Effect": "Allow"
}
]
}
Lake Formation
上記のIAMロールのS3Tablesへのアクセス権限を付与します。
## データベースへの権限付与
## AWS_PRINCIPAL_ARN は、Lambda関数にアタッチするIAMロールのARN
aws lakeformation grant-permissions \
--catalog-id "${AWS_ACCOUNT_ID}" \
--principal "{\"DataLakePrincipalIdentifier\": \"${AWS_PRINCIPAL_ARN}\"}" \
--resource "{\"Database\": {\"CatalogId\": \"${AWS_ACCOUNT_ID}:s3tablescatalog/${TABLE_BUCKET_NAME}\", \"Name\": \"main\" }}" \
--permissions "ALL"
## テーブルへの権限付与
aws lakeformation grant-permissions \
--catalog-id "${AWS_ACCOUNT_ID}" \
--principal "{\"DataLakePrincipalIdentifier\": \"${AWS_PRINCIPAL_ARN}\"}" \
--resource "{\"Table\": {\"CatalogId\": \"${AWS_ACCOUNT_ID}:s3tablescatalog/${TABLE_BUCKET_NAME}\", \"DatabaseName\": \"main\", \"TableWildcard\": {} }}" \
--permissions "ALL"
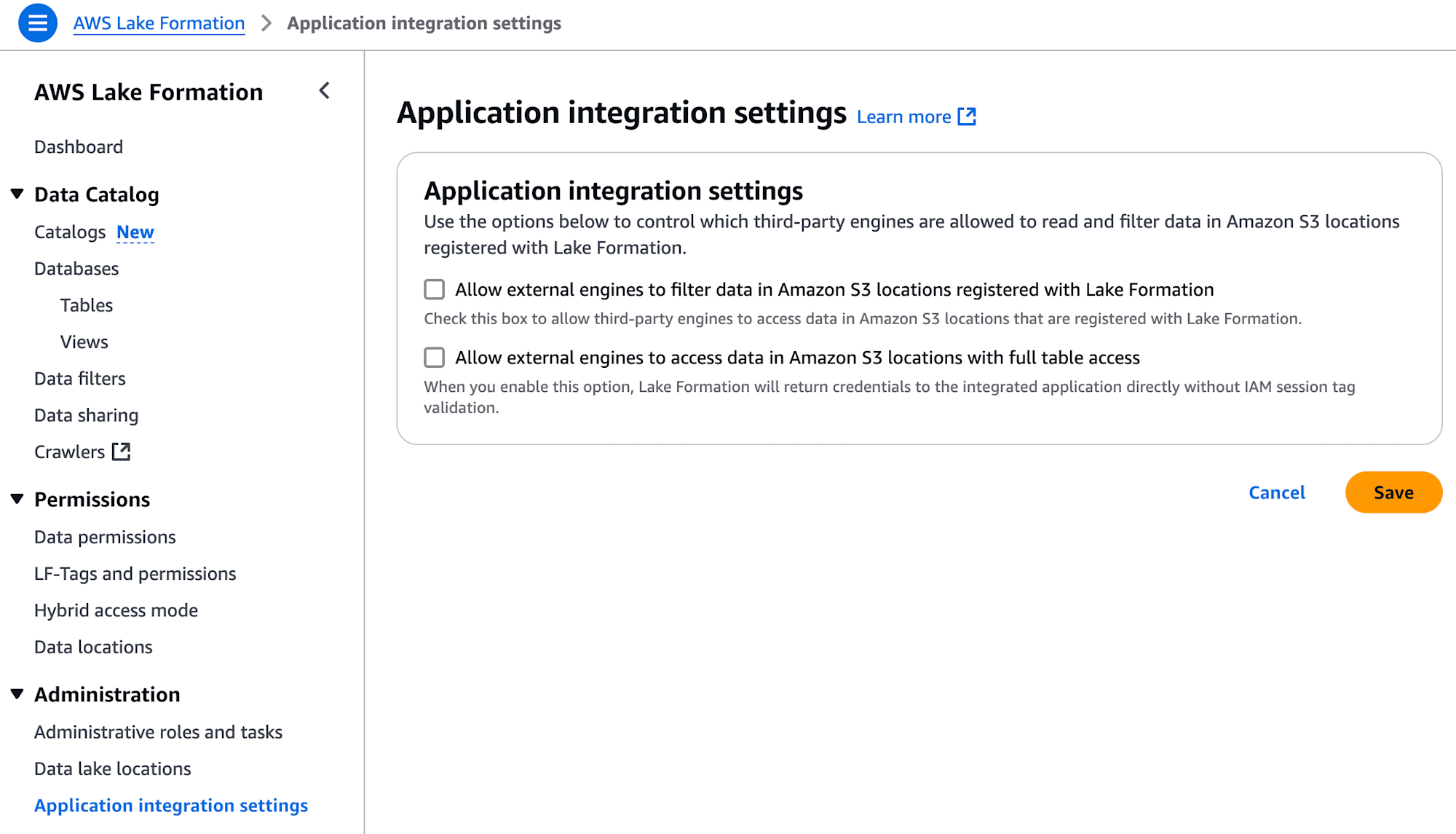
また、「Application integration settings」の「Allow external engines to access data in Amazon S3 Locations with full table access」については、今回チェック入れなくてもアクセスできることを確認しています。
Glue Iceberg REST endpointへのアクセスでは、チェックを入れないと、PyIcebergの load_table() 実行時に 403 AccessDenied でアクセス拒否されてしまいますが、S3 Tables Iceberg REST endpointへのアクセスでは、チェック入れなくてもアクセスには問題ないようです。
Lambda関数
pyicebergをLambda Layerに入れて、以下のようなLambda関数を用意します。
import os
import random
import datetime
import pyarrow as pa
from pyiceberg.catalog import load_catalog
def init_rest_catalog(s3table_bucket_name: str, account_id: str, region: str, catalog_name: str = "S3TablesCatalog"):
return load_catalog(
catalog_name,
**{
"type": "rest",
"warehouse": f"arn:aws:s3tables:{region}:{account_id}:bucket/{s3table_bucket_name}",
"uri": f"https://s3tables.{region}.amazonaws.com/iceberg",
"rest.sigv4-enabled": "true",
"rest.signing-name": "s3tables",
"rest.signing-region": region,
},
)
def handler(event, context):
s3table_bucket_name = os.environ.get("S3TABLE_BUCKET_NAME")
account_id = os.environ.get("ACCOUNT_ID")
region = os.environ.get("REGION")
database_name = os.environ.get("DATABASE_NAME")
table_name = os.environ.get("TABLE_NAME")
JST = datetime.timezone(datetime.timedelta(hours=+9), 'JST')
## REST Catalog
rest_catalog = init_rest_catalog(s3table_bucket_name=s3table_bucket_name, account_id=account_id, region=region)
## Load Table
table = rest_catalog.load_table(f"{database_name}.{table_name}")
## Insert Data
schema = pa.schema([
pa.field('sensor_id', pa.int32(), nullable=False),
pa.field('created_at', pa.timestamp('us')),
pa.field('temperature', pa.float64()),
pa.field('humidity', pa.float64()),
])
sample_data = {
"sensor_id": random.choice(range(1, 11)),
"created_at": datetime.datetime.now(JST),
"temperature": random.normalvariate(20.0, 2),
"humidity": random.normalvariate(40.0, 10),
}
df = pa.Table.from_pylist([sample_data], schema=schema)
table.append(df)
return {
"status_code": 200,
}
「S3 Tables Iceberg REST Endpoint」を使ったカタログの読み込みを以下で行っています。
def init_rest_catalog(s3table_bucket_name: str, account_id: str, region: str, catalog_name: str = "S3TablesCatalog"):
return load_catalog(
catalog_name,
**{
"type": "rest",
"warehouse": f"arn:aws:s3tables:{region}:{account_id}:bucket/{s3table_bucket_name}",
"uri": f"https://s3tables.{region}.amazonaws.com/iceberg",
"rest.sigv4-enabled": "true",
"rest.signing-name": "s3tables",
"rest.signing-region": region,
},
)
ちなみに、「Glue Iceberg REST Endpoint」を使った場合は以下の通りでした。
def init_rest_catalog(s3table_bucket_name: str, account_id: str, region: str, catalog_name: str = "S3TablesCatalog"):
return load_catalog(
catalog_name,
**{
"type": "rest",
"warehouse": f"{account_id}:s3tablescatalog/{s3table_bucket_name}",
"uri": f"https://glue.{region}.amazonaws.com/iceberg",
"rest.sigv4-enabled": "true",
"rest.signing-name": "glue",
"rest.signing-region": region,
},
)
warehouse 、 uri 、 rest.signing-name が異なっているだけで、他は変わりません。
warehouse は、Glueの場合はカタログIDを指定しますが、S3 Tablesの場合はテーブルバケットARNを指定します。
確認
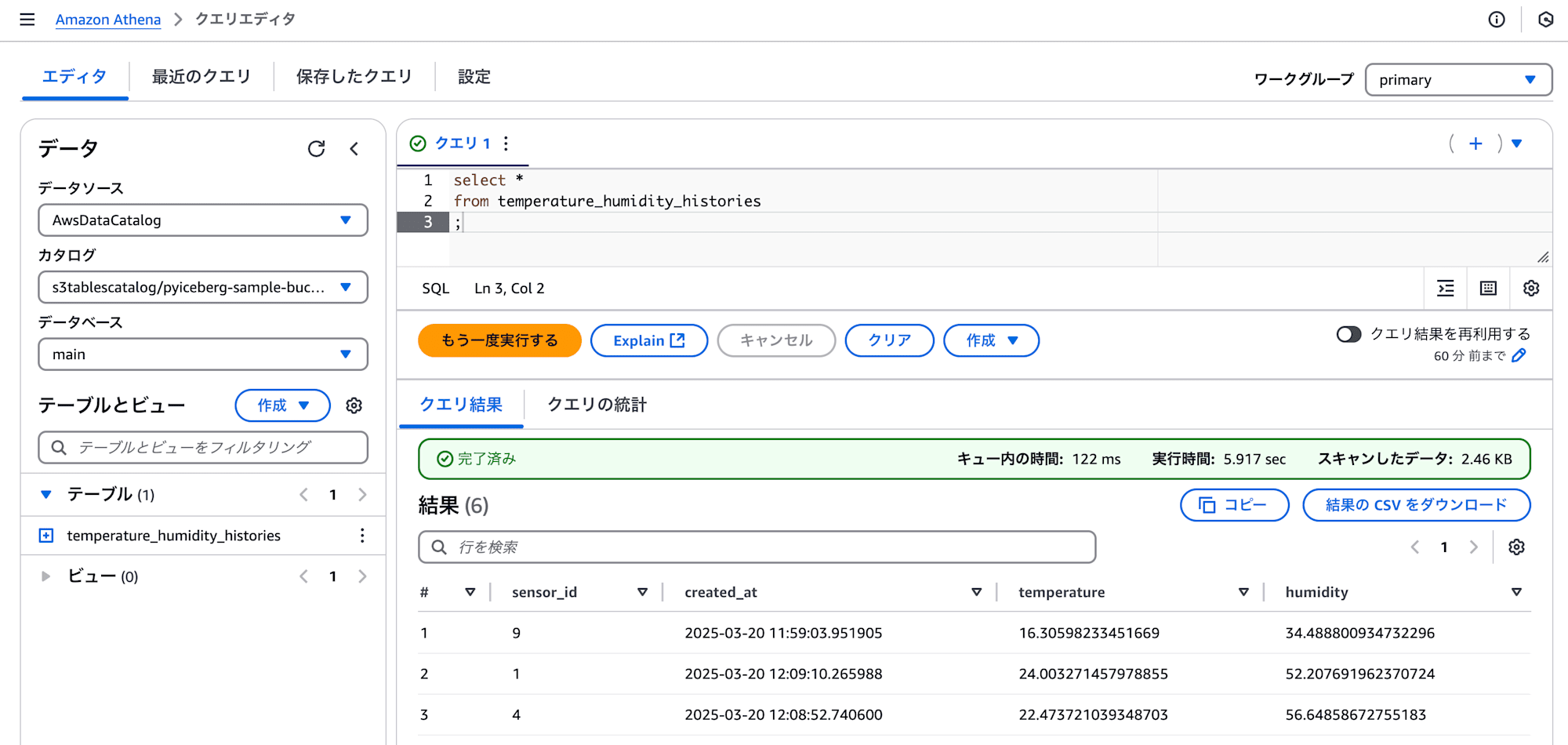
データが格納されたかどうかは、Athenaで確認してみます。
Lambda関数を実行した回数分、データが登録されていることが確認できました。
select *
from temperature_humidity_histories
;
まとめ
いかがでしたでしょうか。
S3 TablesのIceberg REST Catalog APIのendpointを経由してアクセスすることで、単一のS3テーブルバケットへのアクセスが必要な場合は、今後サードパーティからのアクセスが容易になることが予想されます。
ちょっとしたデータ加工を行う際の選択肢の一つとして検討してみてはいかがでしょうか。










