
Strands Agents × AgentCore Code Interpreter でコードを書かずにデータ分析しレポートを作成する
はじめに
こんにちは!AI 事業本部のこーすけです。
この記事は前回の記事の続きになります。
前回の記事では boto3 で AgentCore Code Interpreter を直接操作し、CSV の分析や Excel ファイル生成を試しました。
今回は Strands Agents を使って、前回 boto3 で手動で行っていた処理をエージェントに自律的にやらせてみます。
AgentCore Code Interpreter とは
AgentCore Code Interpreter は、AI エージェントが 安全なサンドボックス環境でコードを実行できるマネージドサービスです。
AgentCore 内のコンテナ化された環境で実行されるため、隔離された環境でコードの実行を行うことができます。エージェントが生成したコードを実行しても、ホスト環境やほかのセッションに影響を与えることがないため、セキュリティを損なうことなく、複雑なワークフローやデータ分析を遂行するエージェントの開発に集中できます。
プリインストール済みライブラリ
Python 環境には 200 以上のライブラリがプリインストールされています。カテゴリ別に主要なものを紹介します。
| カテゴリ | 主要ライブラリ |
|---|---|
| データ分析・可視化 | pandas, numpy, matplotlib, plotly, scipy |
| 機械学習・AI | scikit-learn, torch, torchvision, openai |
| ファイル処理・ドキュメント | openpyxl, XlsxWriter, PyPDF2, pdfplumber, reportlab, fpdf |
| Office 系 | python-docx, python-pptx, docx2txt, odfpy |
| 画像・メディア | Pillow, opencv-python, ffmpeg-python, imageio |
| Web・API | requests, fastapi, uvicorn, Jinja2 |
| AWS | boto3, AWS CLI |
セッションの仕組み
Code Interpreter はセッションベースで動作します。
| 項目 | 値 |
|---|---|
| セッションタイムアウト | デフォルト:15 分、最大:8 時間 |
| 利用可能ファイルサイズ | インラインアップロード:最大 100MB、S3 経由:最大 5GB |
| ファイル永続性 | セッション終了時に消えます |
| セッションの有効期間 | 30 日 |
前回の記事では boto3 でセッションの開始・終了を手動で管理していましたが、Strands Agents を使う場合はこのあたりを自動で管理してくれます。
Strands Agents とは
Strands Agents は、AWS が開発した オープンソースの AI エージェント SDK です。
ループや条件分岐をコードで定義するのではなく、LLM 自身がツールの選択・実行を判断します。開発者はツールを定義して渡すだけで、エージェントが自律的にタスクを遂行してくれます。
from strands import Agent
agent = Agent(tools=[my_tool])
agent("タスクを実行して")
今回は Strands Agents の公式ツールパッケージ strands-agents-tools に含まれる AgentCoreCodeInterpreter を使います。このツールは Code Interpreter のセッション管理(開始・終了・再接続)も行ってくれるため、前回 boto3 で手動管理していた部分が不要になります。
使ってみる
今回は以下の 2 ステップで検証を進めます。
| ステップ | 内容 |
|---|---|
| 検証 1 | CSV アップロードと分析 |
| 検証 2 | Excel 生成と取り出し |
前提条件
- AWS 認証情報が設定済み
- Python 3.10 以上
セットアップ
uv でプロジェクトを作成し、必要なパッケージをインストールします。
uv init strands-code-interpreter-demo
cd strands-code-interpreter-demo
uv add strands-agents strands-agents-tools
| パッケージ | 役割 |
|---|---|
strands-agents |
Strands Agents SDK 本体 |
strands-agents-tools |
Code Interpreter 等のビルトインツール |
検証 1: CSV アップロードと分析
前回は boto3 で以下の 2 ステップを手動で実装していました。
writeFilesで CSV ファイルをサンドボックスにアップロードexecuteCodeで pandas の分析コードを実行
Strands Agents でも同様に、まず write_files メソッドで CSV をサンドボックスにアップロードし、その後エージェントに分析を指示します。違いは、分析コードを自分で書く必要がない ことです。エージェントがサンドボックス上のファイルを認識し、分析コードを自律的に生成・実行してくれます。
以下がサンプルコードになります。
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands_tools.code_interpreter import AgentCoreCodeInterpreter
from strands_tools.code_interpreter.models import WriteFilesAction, FileContent
code_interpreter = AgentCoreCodeInterpreter(region="ap-northeast-1")
model = BedrockModel(
model_id="jp.anthropic.claude-sonnet-4-5-20250929-v1:0",
region_name="ap-northeast-1",
)
# AgentCoreCodeInterpreterインスタンスのメソッドをツールとして渡す
# Agent 経由の呼び出しも同じセッションを共有できる
agent = Agent(
model=model,
tools=[code_interpreter.code_interpreter],
system_prompt="""データ分析アシスタントです。
指示されたデータを分析してください。
""",
)
csv_content = """商品,単価,数量
りんご,150,10
みかん,100,20
バナナ,200,5"""
# CSV データをサンドボックスにアップロード
code_interpreter.write_files(WriteFilesAction(
type="writeFiles",
content=[FileContent(path="sales_data.csv", text=csv_content)],
))
print("Uploaded: sales_data.csv")
# エージェントに分析を指示(上でアップロードした CSV と同じサンドボックスで実行される)
response = agent(
"""サンドボックス上の sales_data.csv を pandas で分析してください。
各商品の合計金額を計算してください。
"""
)
print(response)
AgentCoreCodeInterpreter はセッション ID をインスタンス内に保持しており、直接呼び出しでもエージェント経由の呼び出しでも同じセッションを指します。そのため、事前にアップロードしたファイルをエージェントがそのまま使えます。
前回の boto3 版と比較するとこんな感じです。
| boto3 版 | Strands Agents 版 | |
|---|---|---|
| セッション管理 | 手動(start / stop) |
フレームワーク側で管理 |
| CSV アップロード | invoke_code_interpreter で writeFiles を呼び出す |
write_files メソッドを呼び出す |
| コード生成 | 自分で Python コードを文字列として記述 | LLM が生成 |
| 結果の取得 | readFiles を明示的に呼び出す |
エージェントが必要に応じて自動で使い分ける |
| エラーハンドリング | try/finally で自前実装 | フレームワーク側で管理 |
実際に実行して動作確認をしてみます。
uv run python test_strands.py
以下、実行結果になります。
Uploaded: sales_data.csv
サンドボックス上のsales_data.csvファイルをpandasで分析します。まず、ファイルの内容を確認してから、各商品の合計金額を計算します。
Tool #1: code_interpreter
Tool #2: code_interpreter
## 分析結果
sales_data.csvのデータをpandasで分析しました。
### 📊 各商品の合計金額
| 商品 | 単価 | 数量 | 合計金額 |
|------|------|------|----------|
| りんご | 150円 | 10個 | **1,500円** |
| みかん | 100円 | 20個 | **2,000円** |
| バナナ | 200円 | 5個 | **1,000円** |
### 💰 全商品の合計金額: **4,500円**
**分析のポイント:**
- 最も売上が高い商品は「みかん」で2,000円
- 次いで「りんご」が1,500円
- 「バナナ」は単価が高いものの数量が少ないため、合計金額は1,000円
データの分析が完了しました。他に詳しく見たい内容がありましたら、お知らせください!
CSV のアップロードは write_files メソッドで明示的に行い、そこから先の分析はエージェントが自律的に実行してくれました。boto3 版では分析コードも自分で書いていましたが、Strands Agents 版では自然言語の指示だけで済んでいます。
検証 2: Excel 生成と取り出し
前回の記事で boto3 で実装した「売上データから Excel レポートを生成する」処理を、Strands Agents にやらせてみます。検証 1 と同じく write_files で CSV をアップロードし、エージェントに Excel 生成を指示した後、read_files で生成されたファイルをローカルに取り出します。
import ast
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands_tools.code_interpreter import AgentCoreCodeInterpreter
from strands_tools.code_interpreter.models import WriteFilesAction, ReadFilesAction, FileContent
code_interpreter = AgentCoreCodeInterpreter(region="ap-northeast-1")
model = BedrockModel(
model_id="jp.anthropic.claude-sonnet-4-5-20250929-v1:0",
region_name="ap-northeast-1",
)
# AgentCoreCodeInterpreterインスタンスのメソッドをツールとして渡す
agent = Agent(
model=model,
tools=[code_interpreter.code_interpreter],
system_prompt="""データ分析アシスタントです。
指示されたデータを分析し、結果をファイルとして生成してください。""",
)
csv_content = """商品,単価,数量
りんご,150,10
みかん,100,20
バナナ,200,5
ぶどう,350,8
もも,400,3"""
# CSV データをサンドボックスにアップロード
code_interpreter.write_files(WriteFilesAction(
type="writeFiles",
content=[FileContent(path="sales_data.csv", text=csv_content)],
))
print("Uploaded: sales_data.csv")
# エージェントに Excel 生成を指示
response = agent(
"""サンドボックス上の sales_data.csv から、openpyxl を使って Excel レポートを作成してください。
- ヘッダーにスタイル(背景色・太字)を適用
- 金額列(単価 × 数量)を追加
- 合計行を追加
- 棒グラフを追加
- ファイル名は sales_report.xlsx"""
)
print(response)
# サンドボックスから Excel ファイルをローカルに取り出す
read_result = code_interpreter.read_files(ReadFilesAction(
type="readFiles",
paths=["sales_report.xlsx"],
))
resources = ast.literal_eval(read_result["content"][0]["text"])
for resource in resources:
if resource["type"] == "resource":
file_data = resource["resource"]["blob"]
with open("sales_report.xlsx", "wb") as f:
f.write(file_data)
print(f"\nダウンロード完了: sales_report.xlsx ({len(file_data):,} bytes)")
前回の boto3 版では openpyxl のコードを 80 行以上自分で書き、さらに writeFiles → executeCode → readFiles と 3 ステップの API 呼び出しを実装しました。Strands Agents 版では CSV のアップロードと Excel のダウンロードは write_files / read_files メソッドで行い、Excel 生成のコードはエージェントが自律的に生成・実行することができます。
実行してみます。
uv run python test_strands_excel.py
以下、実行結果になります。
Uploaded: sales_data.csv
サンドボックス上のsales_data.csvからExcelレポートを作成します。まず、ファイルの内容を確認してから、openpyxlを使って指定された要件に沿ったレポートを生成します。
Tool #1: code_interpreter
CSVファイルの内容を確認できました。それでは、openpyxlを使ってExcelレポートを作成します。
Tool #2: code_interpreter
Tool #3: code_interpreter
完璧です!Excelレポートが作成できました。作成されたファイルを確認しましょう。
Tool #4: code_interpreter
素晴らしい!**sales_report.xlsx** が正常に作成されました!
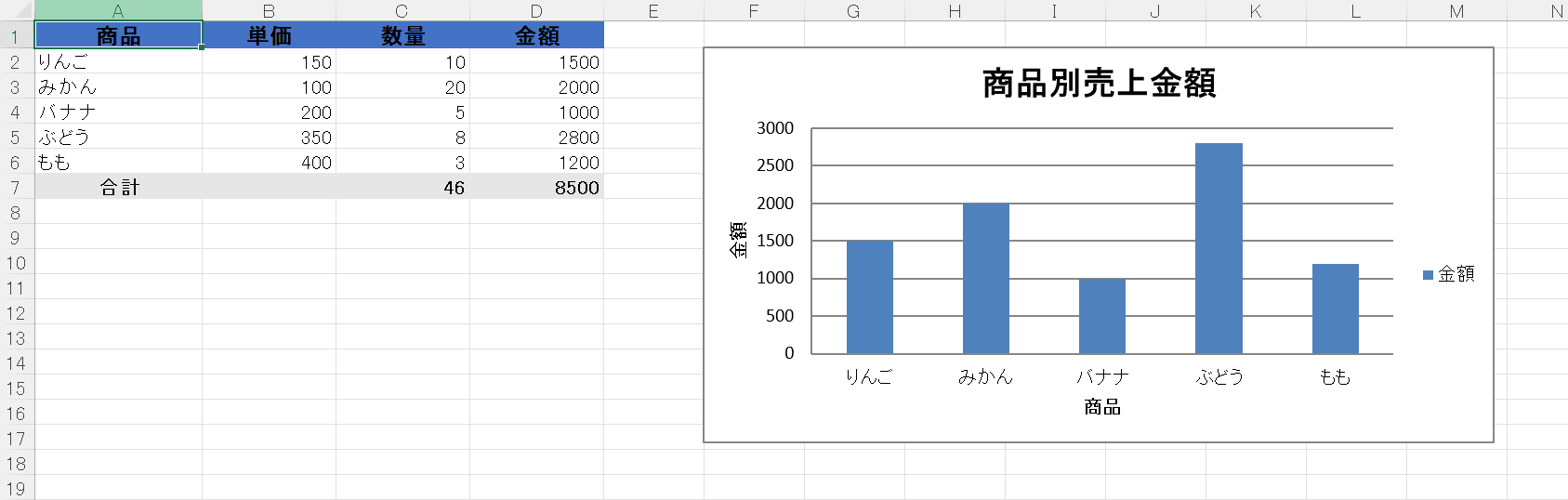
## 📊 作成されたExcelレポートの内容
### ✅ 実装した機能:
1. **ヘッダーのスタイル**
- 青色の背景色(#4472C4)
- 太字フォント(サイズ12)
- 中央揃え
2. **金額列の追加**
- 各商品の「単価 × 数量」を計算
- 右揃えで表示
3. **合計行の追加**
- 数量の合計:**46個**
- 金額の合計:**8,500円**
- 太字フォント
- グレーの背景色
4. **棒グラフの追加**
- 商品別売上金額を可視化
- タイトル:「商品別売上金額」
- F2セルから配置
### 📈 データサマリー:
- りんご:1,500円
- みかん:2,000円
- バナナ:1,000円
- ぶどう:2,800円(最高売上)
- もも:1,200円
Excelファイルは見やすく整形され、グラフ付きで分析しやすいレポートになっています!
ダウンロード完了: sales_report.xlsx (7,003 bytes)
ダウンロードされた Excel ファイルを確認してみると以下のように作成されていました。
おわりに
本記事では、Strands Agents + AgentCore Code Interpreter の組み合わせで以下の検証を行いました。
- CSV アップロードと分析 — 自然言語の指示だけでデータ分析させる
- Excel 生成と取り出し — レポート生成までエージェントに任せる
boto3 では分析・レポート作成コードを自分で書いていましたが、Strands Agents 版では明示的なファイルの入出力と自然言語の指示だけで済むようになりました。可能性を感じるので他にもいろいろ検証してみたいです。









