![[小ネタ] AgentCore Runtimeの会話履歴とスコープ](https://images.ctfassets.net/ct0aopd36mqt/7qr9SuOUauNHt4mdfTe2zu/8f7d8575eed91c386015d09e022e604a/AgentCore.png?w=3840&fm=webp)
[小ネタ] AgentCore Runtimeの会話履歴とスコープ
はじめに
こんにちは、スーパーマーケットが好きなコンサル部の神野です。
皆さんはStrands AgentsとAgentCoreでAIエージェントを作っていますか?私も毎日少しずつ触っています。
今回、話題にしたいのは会話履歴についてです。
例えば、会話履歴を永続化したい場合はAgentCore Memoryの短期記憶などを使うイメージですが、
実は同一セッションかつ、セッションが生きている状態であればMemoryを使わずとも会話を引き継ぐことができます。
ただ処理の書き方で変数のスコープなども変わってくるので、維持されないケースもあります。
今回はこの辺りを深掘りしていければと思い記事を書いてみました。
Strands Agentの会話履歴の仕組み
Strands Agentはmessages属性に会話履歴を保持します。
同じAgentインスタンスを使い続ける限り、このmessagesに会話が蓄積されていきます。
from strands import Agent
agent = Agent()
# 1回目の呼び出し
agent("こんにちは、私の名前は神野です")
# 2回目の呼び出し - 同じインスタンスなので会話履歴が残っている
agent("私の名前は何ですか?")
# 会話履歴を確認
print(agent.messages)
agent2 = Agent()
agent2("私の名前は何ですか?")
print(agent2.messages)
実行してみると下記のようにレスポンスが返却されて、今までのメッセージが蓄積されていることがわかります。
一方で新しく生成したインスタンスはメッセージが記憶されていません。イメージ通りの挙動です。
# 一回目の実行
はじめまして、神野さん。こんにちは!私はClaudeです。お会いできて嬉しいです。何かお手伝いできることがあればお気軽にお声かけください。いかがお過ごしですか?あなたのお名前は神野さんですね。先ほど自己紹介していただきました。[{'role': 'user', 'content': [{'text': 'こんにちは、私の名前は神野です'}]}, {'role': 'assistant', 'content': [{'text': 'はじめまして、神野さん。こんにちは!私はClaudeです。お会いできて嬉しいです。何かお手伝いできることがあればお気軽にお声かけください。いかがお過ごしですか?'}]}, {'role': 'user', 'content': [{'text': '私の名前は何ですか?'}]}, {'role': 'assistant', 'content': [{'text': 'あなたのお名前は神野さんですね。先ほど自己紹介していただきました。'}]}]
# 二回目の実行
申し訳ありませんが、あなたのお名前をお教えいただいていないので、わかりません。よろしければ、お名前を教えていただけますでしょうか?[{'role': 'user', 'content': [{'text': '私の名前は何ですか?'}]}, {'role': 'assistant', 'content': [{'text': '申し訳ありませんが、あなたのお名前をお教えいただいていないので、わかりません。よろしければ、お名前を教えていただけますでしょうか?'}]}]
公式ドキュメントにも下記のように記載があります。
Conversation history is automatically:
- Maintained between calls to the agent
- Passed to the model during each inference
書いてある内容は確認した結果と同じで、Agentインスタンスのmessagesに会話履歴が自動的に蓄積され、
同じインスタンスを使い続けると、前の会話を覚えている状態で推論が行われます。
一方で新しいインスタンスを生成すると、会話履歴は空からスタートするといった感じです。
ならこれがAgentCoreでも同じですが、agentの初期化位置で挙動が変わるので確認してみます。
セットアップ
それでは実装パターンを確認するための環境セットアップをしていきます。
前提
今回は下記バージョンを使用しました。
- Python 3.12
- strands-agents >= 1.22.0
- bedrock-agentcore >= 1.2.0
- bedrock-agentcore-starter-toolkit >= 0.2.6
- uv 0.6.12
依存関係の初期化
uv を使用してプロジェクトを初期化します。
uv init
下記のコマンドで依存関係を追加します。
uv add strands-agents bedrock-agentcore bedrock-agentcore-starter-toolkit
AgentCore へのデプロイ
実装したAgentをAgentCore Runtimeにデプロイします。デプロイ前に、まずデプロイの設定を行う必要があります。
デプロイ設定
agentcore configure コマンドでデプロイ設定を行います。
IAM認証を使用するため、認証設定はデフォルトのままで問題ありません。
uv run agentcore configure -e agent.py
実行するとインタラクティブなプロンプトが表示されます。基本的には推奨設定で進めればOKです!
Configuring Bedrock AgentCore...
✓ Using file: agent.py
🏷️ Inferred agent name: agent
Press Enter to use this name, or type a different one (alphanumeric without '-')
Agent name [agent]: agent_sample_test_0123
✓ Using agent name: agent_sample_test_0123
🔍 Detected dependency file: pyproject.toml
Press Enter to use this file, or type a different path (use Tab for autocomplete):
Path or Press Enter to use detected dependency file: pyproject.toml
✓ Using requirements file: pyproject.toml
🚀 Deployment Configuration
Select deployment type:
1. Direct Code Deploy (recommended) - Python only, no Docker required
2. Container - For custom runtimes or complex dependencies
Choice [1]: 1
Select Python runtime version:
1. PYTHON_3_10
2. PYTHON_3_11
3. PYTHON_3_12
4. PYTHON_3_13
Choice [3]: 3
✓ Deployment type: Direct Code Deploy (python.3.12)
🔐 Execution Role
Press Enter to auto-create execution role, or provide execution role ARN/name to use existing
Execution role ARN/name (or press Enter to auto-create):
✓ Will auto-create execution role
🏗️ S3 Bucket
Press Enter to auto-create S3 bucket, or provide S3 URI/path to use existing
S3 URI/path (or press Enter to auto-create):
✓ Will auto-create S3 bucket
🔐 Authorization Configuration
By default, Bedrock AgentCore uses IAM authorization.
Configure OAuth authorizer instead? (yes/no) [no]: no
✓ Using IAM authorization (default)
IAM認証がデフォルトで設定されるため、特に変更の必要はありません!
デプロイの実行
設定が完了したら、下記のコマンドでデプロイを実行します。
uv run agentcore deploy
デプロイが完了すると、エージェントのARNが表示されます。このARNが後ほどのテストで使用されます。
デプロイ後、起動したエージェントをテストするには下記のコマンドを実行します。
uv run agentcore invoke '{"prompt": "こんにちは"}'
2パターンそれぞれデプロイしても構わないですし、1パターンを上書き実装してデプロイでも構いません。
今からそれぞれの実行パターンをデプロイして挙動を確認していきます。
私は2パターンそれぞれデプロイしました。同ディレクトリで2つのエージェントをデプロイした場合は、呼び出す際に--agent引数を渡せば明示的に呼び出したいエージェントを指定できます。
uv run agentcore invoke '{"prompt": "私の名前は神野です。覚えておいてください。"}' --agent agent_global --session-id a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p67
実装パターンの比較
パターン1: エントリーポイント内で初期化
まずはエントリーポイント内でAgentを初期化します。
from strands import Agent
from strands.models import BedrockModel
from bedrock_agentcore.runtime import BedrockAgentCoreApp
app = BedrockAgentCoreApp()
@app.entrypoint
async def entrypoint(payload):
message = payload.get("prompt", "")
# エントリーポイント内でAgentを初期化
model = BedrockModel(
model_id="us.anthropic.claude-haiku-4-5-20251001-v1:0",
params={"max_tokens": 4096, "temperature": 0.7},
region_name="us-west-2"
)
agent = Agent(model=model)
# 毎回新しいインスタンスなので会話履歴は空
result = agent(message)
return {"result": str(result)}
if __name__ == "__main__":
app.run()
この実装では、リクエストのたびにAgentが新しく生成されます。
そのため、前回の会話を覚えていない状態で毎回推論が行われます。
パターン1の起動例
デプロイ後、Starter toolkit の agentcore invoke コマンドを使用してテストしてみます。
各リクエストには --session-id を指定します。
この --session-id はセッションを一意に識別するIDで、同じセッションでも毎回新しいAgentインスタンスが生成されるパターン1では、セッション内の会話履歴も保持されません。
まず、セッションID1で1回目のリクエストを送信します。
uv run agentcore invoke '{"prompt": "私の名前は神野です。覚えておいてください。"}' --agent agent_inside --session-id a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6
レスポンスは下記のように返却されました。
{"result": "わかりました。あなたの名前は**神野**さんですね。覚えておきます。\n\n何かお手伝いできることはありますか?\n"}
続けて同じセッションID1で2回目のリクエストを送信します。
uv run agentcore invoke '{"prompt": "私の名前は何ですか?"}' --agent agent_inside --session-id a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p67
パターン1では、毎回エントリーポイント内でAgentが新しく生成されるため、
同じセッションID1を使用していても、下記のように前の会話を覚えていません。
期待通りです。
{"result":
"申し訳ありませんが、あなたのお名前を知りません。\n\n私はこれまでのチャット履歴にアクセスすることができず、各会話は新しく始まるため、あなたについての情報を持っていません
。\n\nよろしければ、あなたのお名前を教えていただけますか?\n"}
異なるセッションID2でリクエストを送信しても、同様に会話履歴はリセットされます。
uv run agentcore invoke '{"prompt": "私の名前は何ですか?"}' --agent agent_inside --session-id b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6q78
{"result":
"申し訳ありませんが、あなたのお名前を知りません。\n\n私はこれまでのチャット履歴にアクセスすることができず、各会話は新しく始まるため、あなたについての情報を持っていません
。\n\nよろしければ、あなたのお名前を教えていただけますか?\n"}
このように、パターン1ではセッション内でも、
セッション間でも、常に会話履歴がリセットされることがわかりますね。
パターン2: グローバルスコープで初期化
こちらではグローバルスコープでAgentを初期化します。
from strands import Agent
from strands.models import BedrockModel
from bedrock_agentcore.runtime import BedrockAgentCoreApp
app = BedrockAgentCoreApp()
# グローバルスコープでモデルとエージェントを初期化
model = BedrockModel(
model_id="us.anthropic.claude-haiku-4-5-20251001-v1:0",
region_name="us-west-2"
)
agent = Agent(
model=model,
system_prompt="あなたは親切なアシスタントです。"
)
@app.entrypoint
def invoke(payload):
prompt = payload.get("prompt", "")
if not prompt:
return {"error": "promptが必要です"}
# グローバルのagentを使用 - 会話履歴が引き継がれる可能性あり
result = agent(prompt)
return {"result": str(result)}
if __name__ == "__main__":
app.run()
この実装では、Agentがグローバルスコープで初期化されています。実行環境が再利用される場合、同じAgentインスタンスが使われるため、前回の会話履歴が残っている状態で推論が行われます。
パターン2の起動例
デプロイ後、starter toolkit の agentcore invoke コマンドを使用してテストしてみます。
まず、セッションID1で1回目のリクエストを送信します。
uv run agentcore invoke '{"prompt": "私の名前は神野です。覚えておいてください。"}' --agent agent_global --session-id a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p67
レスポンスは下記のように返却されました。
{"result": "はい、神野さん。お名前を覚えました。これからどのようにお手伝いできるでしょうか。\n"}
続けて同じセッションID1で2回目のリクエストを送信します。
名前を覚えているか確認します。
uv run agentcore invoke '{"prompt": "私の名前はなんですか?"}' --agent agent_global --session-id a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p67
グローバルスコープで初期化されたAgentインスタンスが、
同一の実行環境に保持されているため、下記のように前の会話を覚えていました!!
{"result": "神野さんです。先ほど、神野さんからお名前を教えていただきました。\n"}
一方、異なるセッションID2でリクエストを送信すると、新しいセッション用の実行環境となり、Agentがリセットされるため、会話履歴も引き継がれません。
uv run agentcore invoke '{"prompt": "私の名前は何ですか?"}' --agent agent_global --session-id b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6q78
{"result": "申し訳ありませんが、あなたの名前は知りません。名前を教えていただけますか?\n"}
パターン2では同じセッションID内では会話履歴が保持されますが、異なるセッションIDでは会話履歴がリセットされます。
これがセッション別に実行環境が異なる仕組みですね。
Lambdaと同じスコープの考え方
AgentCore Runtimeのコンテナ再利用の仕組みは、
AWS Lambdaのコールドスタート・ウォームスタートの概念とほぼ同じです。
Lambdaのスコープの考え方
import boto3
# グローバルスコープ - コンテナ再利用時は保持される
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('MyTable')
def lambda_handler(event, context):
# ハンドラ内 - 毎回実行される
item = {"id": event["id"]}
table.put_item(Item=item)
return {"statusCode": 200}
Lambdaでは、グローバルスコープで初期化したオブジェクト(上記の例ではdynamodbやtable)は、
コンテナが再利用される際にそのまま保持されます。これにより、接続の再利用やキャッシュの活用ができます。
AgentCore Runtimeでも同様
AgentCore Runtimeでも同じ考え方が適用されます。
| スコープ | 初期化タイミング | 会話履歴 |
|---|---|---|
| グローバル | 起動時(コールドスタート時)のみ | 再利用時は保持される |
| エントリーポイント内 | リクエストごと | 毎回リセットされる |
使い分けのイメージ
| ユースケース | 推奨パターン | 理由 |
|---|---|---|
| ステートレスなQ&A | エントリーポイント内で初期化 | 毎回クリーンな状態で応答できる |
| 簡易的な会話継続(保証不要) | グローバルスコープで初期化 | 再利用時のみ会話継続 |
| 確実な会話履歴の永続化 | AgentCore Memory + Session Manager | セッション間で確実に状態を保持 |
確実にセッション間で会話履歴を保持したい場合は、AgentCore Memoryを使う方法が良いかと思います!
Strands Agentsなら下記方法が提供されているので活用しましょう!簡単にMemoryと連携できます!
ちょっと話題は変わりますが、使用する会話履歴(どれだけ履歴を保持するかなど)をコントロールしたい際はConversation Managementといった機能も提供されているので必要に応じて活用したいですね。
補足:セッションの維持期間
AgentCore Runtimeでセッションを使い続ける際は、
セッションがどのくらい保持されるのかを理解しておくことも大事です。
Runtimeは、各セッションに対してライフサイクル設定を適用していて、2つの主要なタイムアウト設定があります。
| 設定項目 | デフォルト値 | 説明 |
|---|---|---|
| idleRuntimeSessionTimeout | 900秒(15分) | セッションがアイドル状態にある時間。 この期間何も処理がないと、セッションは終了します。 |
| maxLifetime | 28800秒(8時間) | セッションの最大ライフタイム。 この時間に達すると、セッションは強制的に終了します。 |
セッションは以下のいずれかの条件に達すると終了するということです。
- 15分間、何も処理がない状態が続いた場合
- セッション開始から8時間が経過した場合
絵にすると下記のようなイメージです。
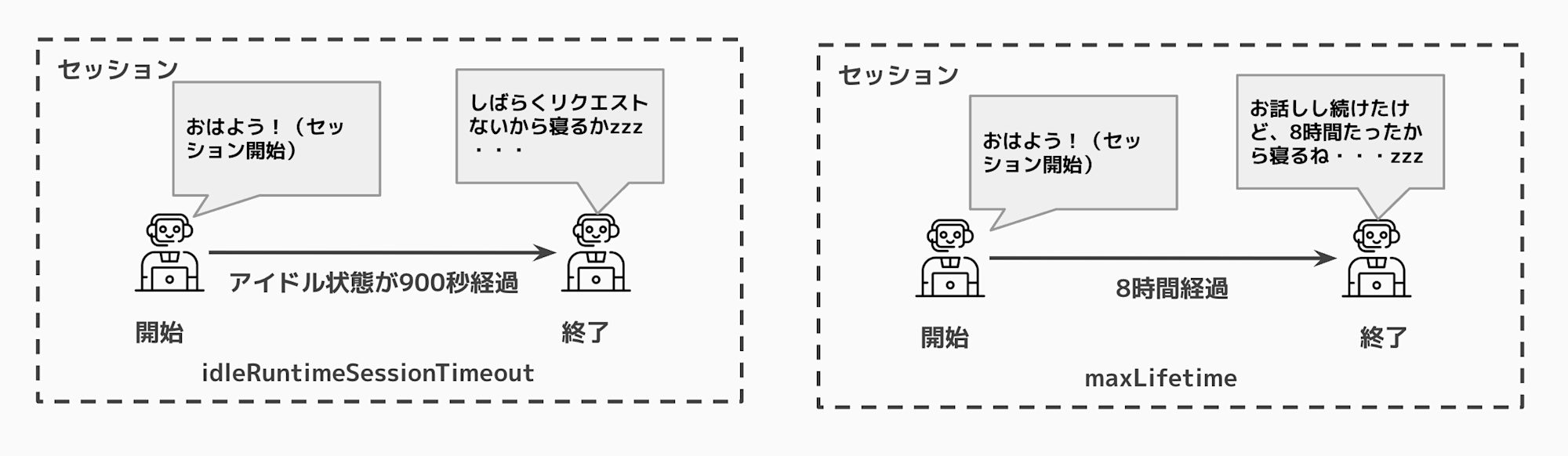
グローバルスコープで初期化したAgentインスタンスを使い続ける場合、同じ実行環境が再利用されている限り、このタイムアウト期間内であれば会話履歴は保持されます。
ただ、アイドルタイムアウトに達するか、最大ライフタイムに到達すると、
セッションが終了し、次回のリクエスト時に新しいセッションが作成されることになります。
その時点で会話履歴はリセットされるため、確実にセッション間で会話を引き継ぎたい場合は、AgentCore Memoryを使用して状態を永続化することが推奨されます。
Lifecycle configuration helps optimize resource utilization by automatically cleaning up idle sessions and preventing long-running instances from consuming resources indefinitely.
ちなみにユースケース別の設定時間例もあるので、参考になりますね。
開発時などは短めに設定するのが良さそうです。
ユースケース別の設定時間例
| ユースケース | アイドルタイムアウト | 最大存続時間 | 設定の根拠(理由) |
|---|---|---|---|
| インタラクティブなチャット | 10〜15分 | 2〜4時間 | 応答性とリソース使用率のバランスを維持するため |
| バッチ処理 | 30分 | 8時間 | 実行時間の長い処理を考慮するため |
| 開発環境 | 5分 | 30分 | コスト最適化のために素早くクリーンアップするため |
| 本番環境API | 15分 | 4時間 | 標準的な本番環境のワークロード |
| デモ・テスト用 | 2分 | 15分 | 一時的な利用のため、積極的にリソースを解放するため |
おわりに
Lambdaを使った方であれば、グローバルスコープとハンドラ内のスコープの違いは馴染みがあるかと思います。
グローバルスコープでの会話履歴保持はあくまで同一セッションIDでセッションが維持されている間に限るので、
一定期間永続的に会話履歴を保持したい場合はAgentCore Memoryを使いましょう!
本記事が少しでも参考になりましたら幸いです。
最後までご覧いただきありがとうございました!










