
【レポート】効果的なデータ・AI戦略についての手法を学べる「Preparing for the new frontier: Accelerating AI with great data」に参加してきました #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、引き続きre:Inventに参加中のこーへいです。
Preparing for the new frontier: Accelerating AI with great data(新たなフロンティアへの準備: 優れたデータでAIを加速する※機械翻訳)に参加してきましたのでレポートしていきます。
本セッションについて
タイトル:Preparing for the new frontier: Accelerating AI with great data
Level: 200 – Intermediate
Speaker:Marty Andolino,Kajal Wood
概要:※下記は機械翻訳
AI革命は、企業がクラウド上でデータをどのように管理し、利用するかということの重要性を高めている。 優れたAIには優れたデータが必要であり、豊富で適切に管理されたデータを持つ組織は、AIを活用する上で大きなアドバンテージを持つ。 本セッションでは、Capital Oneが、顧客の困難な問題を解決し、真のビジネス価値を促進するAIのユースケースを加速させるために、適切に管理され、見つけやすく、理解しやすく、利用しやすい高品質なデータの作成について、企業がどのように考えるべきかを紹介します。 本プレゼンテーションは、AWSパートナーであるCapital Oneがお届けします。
アジェンダ
- Capital One Tech Journey(Capital Oneのテクノロジーの歩み)
- Data Principles for AI(AIにおけるデータの重要性)
- Data Producer Experience(データ作成者の体験)
- Data Consumer Experience(データ消費者の体験)
- Kye Takeaways(結論)
Capital Oneのテクノロジーの歩み
初めに、Capital Oneの10年以上にわたる技術革新の歩みについての説明がありました。
Capital Oneは「オープンソースベースの独自技術構築」「APIとマイクロサービスの早期採用」「クラウド(AWS)への完全移行」「サーバーレスコンピューティングの重視」に関して早期に注力してきました。

また「AWS認定エンジニアが1000人以上の確保」「14,000人規模の技術者組織の構築」「DevOps文化の導入」により組織を強化し、AIとMLの大規模活用する環境を整えることで、1億人の顧客へのサービス提供を可能としてきました。またカスタマーや従業員エクスペリエンスの向上や、詐欺対策の強化に繋げることができました。

AIにおけるデータの重要性
データには3つの複雑性が存在します。
- Volume(量):世界のデータ量は5年で2倍に(147ゼタバイト)
- Variety(多様性):80-90%が非構造化データ
- Velocity(速度):リアルタイムデータの重要性(10ミリ秒単位)

データ品質にも以下の課題が存在します。
- 64%のデータ分析専門家がデータ品質を最重要課題と指摘
- 52%のIT専門家が機械学習での構造化データ処理に苦心
- 62%がAIのためのリアルタイムデータアクセスを重視
- 組織内の68%のデータが未活用

良質なデータ生産・消費のために以下の3原則が必要となります。
- セルフサービス:ツール、アクセス、発見可能性の提供
- 自動化:データプロセスの自動化
- スケール:AI対応の大規模データ処理

AIの成功にはデータの質と管理が不可欠で、最適な管理を実現するためのアプローチを次の章で解説しています。
データ作成者の体験
本章ではデータ作成者の体験を向上させるために重要なポイントが紹介されました。
基本原則が以下の4つとなります。こちらを守った上でデータセットオンボーディング(新しいデータセットをシステムに導入・統合するプロセス全体)を整えていきます。
- シンプルさ:直感的で使いやすい
- インテリジェンス:データから自動的に情報を推測
- 透明性:プロセスとSLAの明確化
- 効率性:高いガバナンス基準を維持しながら簡単に使える

データオンボーディングの手順は以下となります。
- メタデータの登録(プライバシー、セキュリティ設定含む)
- スキーマの設計と承認
- 承認プロセス
- データのプロビジョニング

セルフサービスポータルは、高品質なデータセットオンボーディングを実現する手段となります。
- 複雑な処理を裏側で自動化
- ストレージとアクセス権限の設定
- バージョン管理
- カタログ更新の自動化
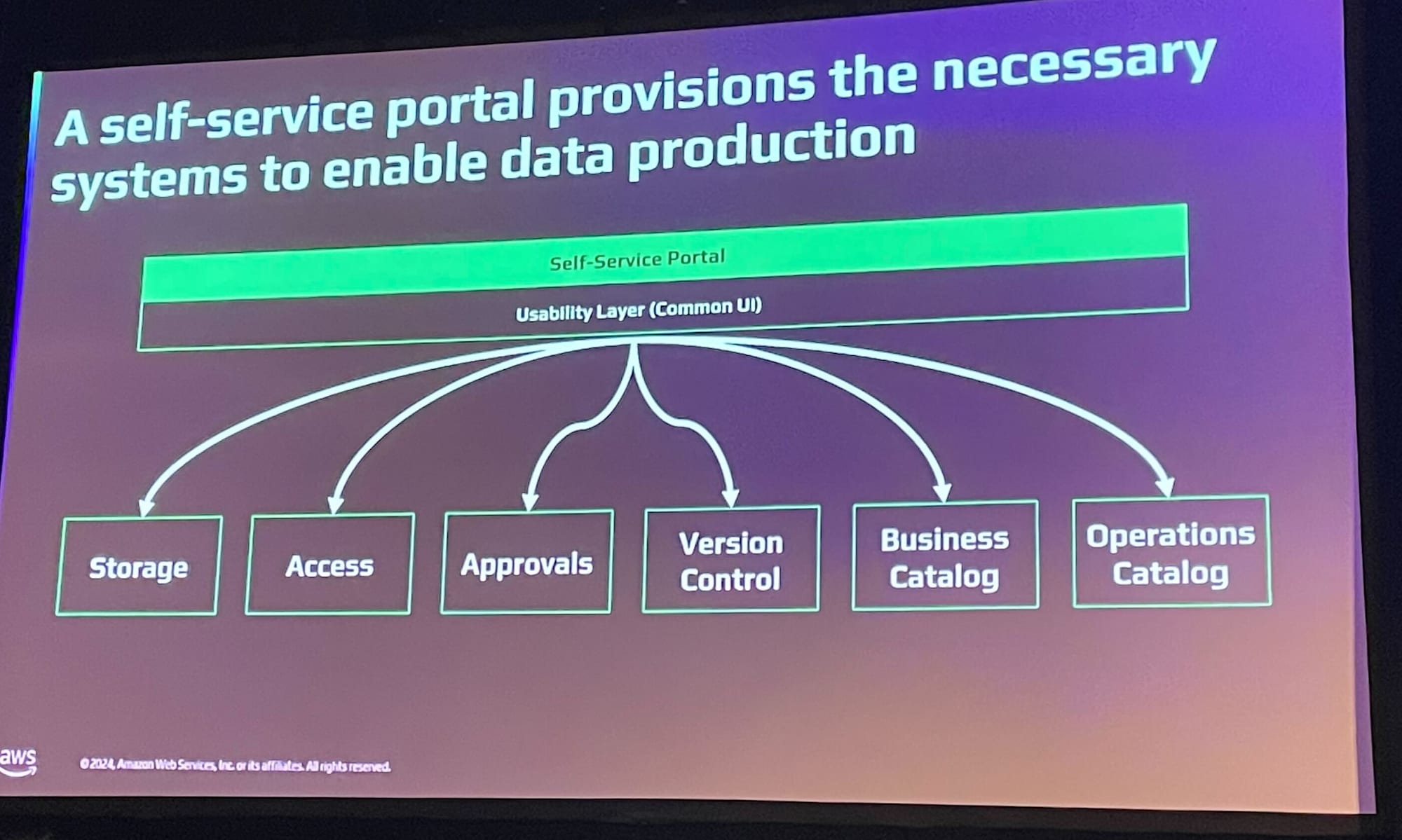
コントロールプレーンには、データを適切な場所に配置するための構成が保持されます
- 制御プレーンの主要機能
- メタデータとスキーマの検証
- データ品質ルールの設定と監視
- データの変換管理
- リアルタイムの監視と可観測性

これらの要素により、データ作成者は効率的かつ信頼性の高いデータ管理が可能になります。
データ消費者の体験
データを使用するユーザーが効率的かつ安全にデータにアクセスし、活用できるようにするための総合的な仕組みと体験向上のために以下のような機能が提供されています。
- セルフサービス機能
- 自動化されたアクセス管理
- データライフサイクル管理
- クロスリージョン可用性

結論
今回のセッションでは以下の4つが結論として出されました。
- 体験の革新(Invent experiences)
- 顧客体験と同様に、データ関連の体験を重視
- データ生産者と消費者のための合理化された体験の提供
- 適切なデータエコシステムの構築
- 実施メカニズム(Mechanisms of enforcement)
- 自動化を前提とした構築
- スケーラビリティの確保
- 中央集権型または連邦型データモデルの活用
- モデルライフサイクルポリシーの実装
- 迅速な実験(Rapid experimentation)
- データサイエンティストが素早くストレージをプロビジョニング
- モデルの構築とトレーニングの迅速化
- 実験のための柔軟な環境提供
- 揺るぎない信頼性(Unwavering trustworthiness)
- 適切なデータガバナンス
- 使いやすさの確保
- 簡単な検索と利用
- 容易な消費

これらが効果的なデータ・AI戦略の重要な構成要素であるでセッションが締め括られました。
感想
AI・データ周りの知見が薄く、セッション終了時点では理解度が浅く、何度もメモを読み返しながら本ブログを執筆しました。
もしかしたら頓珍漢な解釈をしている箇所があるかも知れませんので、その際はこそっと教えてください。










