![[AIM380][Code Talk] ツール呼び出しを強化するために Amazon Nova モデルをカスタマイズする #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[AIM380][Code Talk] ツール呼び出しを強化するために Amazon Nova モデルをカスタマイズする #AWSreInvent
製造ビジネステクノロジー部スマートファクトリーチームの田中孝明です。
ツール呼び出しを強化するために Amazon Nova モデルをカスタマイズする
Amazon SageMaker のトレーニングジョブとレシピを活用し、直接選好最適化 (DPO) と教師あり微調整 (SFT) 技術を用いて Nova モデルを微調整し、Amazon Bedrock にシームレスにデプロイする方法を学びます。このセッションでは、高度なツール呼び出し機能向けに Nova モデルを微調整する方法を紹介します。これにより、複数の AWS サービス、カスタム API、内部ツールと連携することで、ワークフローを自律的に実行できるインテリジェントエージェントを実現できます。信頼性と制御性を維持しながら、複数ステップのビジネスプロセスを処理できる、本番環境対応のエージェントシステム向けに Nova モデルをカスタマイズ、評価、デプロイする方法を学びます。
モデルカスタマイズの位置づけ

LLM のカスタマイズ手法を重みを変えるかどうかで整理する
- 重みを変えない軽量な手法
- プロンプトエンジニアリング
- RAG( Retrieval Augmented Generation )
- 重みを変える本格的な手法
- 事前学習の追加( Pre-training )
- 事後学習 / 微調整( Fine-Tuning、SFT、DPO、RFT など)
今回のセッションでは以下を採用
- Supervised Fine-Tuning(SFT)
- 正解となるツール呼び出し JSON を教師データとして学習
- 主にフォーマットやスタイル、こう答えてほしいなどの振る舞いを覚えさせる
- Reinforcement Fine-Tuning(RFT)
- AWS Lambda で実装した「報酬関数」が、出力されたツール呼び出しの良し悪しをスコアリング
- モデルはこの報酬を最大化するように学習
Amazon Nova / Forge の最近のアップデート
- Nova 1.x から 2.x への進化
- Nova Lite / Pro などの第 2 世代モデル
- 多言語対応、エージェント用途、コード生成などに強化
- Nova Pro の特徴
- 中間チェックポイント(mid-train checkpoint)へのアクセス
- Amazon がキュレーションした学習データ(Nova Data)と自社データをブレンド可能
- 強化学習(RFT)用の環境とつなげられる仕組み
- 責任ある AI(コンテンツモデレーション等)向けツールキット
ツール呼び出しエージェントのユースケース
想定シナリオ
- 想定ユーザー: 弁護士、パラリーガルなど
- タスク: 証券取引に関する契約書をレビューし、関連する規制・判例と照らし合わせて助言する
利用するデータソース
- SEC に提出された実際の証券関連契約書(EDGAR Filings)
- SEC の正式な規制文書(どのような条項が求められるか)
- 連邦裁判所などによる判例・解釈文書
これらをもとに、モデルが以下のような Python ツールを組み合わせて呼び出せるようにします。
- 特定条項の検索ツール
- 規制要件チェックツール
- 判例検索ツール
ツールは Python 関数として定義し、「どのツールを」「どの順序で」「どんなパラメータで」呼ぶべきかをモデルに学習させます。
合成データによるトレーニングデータ生成
多くの顧客が「そもそも学習用データが足りない」という課題を持っていることから、今回のデモでは合成データ(synthetic data)生成を採用していました。
合成データ生成の流れ
- 生データ収集
- Web などから規制文書・契約書・判例を取得
- チャンク分割
- モデルのコンテキスト長を超えないように、文字数ベースでチャンク分割
n文字のオーバーラップを設定して文脈を維持
- プロンプト指定
- ツール仕様、期待する JSON スキーマ、カテゴリなどを明示
- 例:
- 利用可能なツール一覧
- 各ツールのパラメータ仕様
- 質問をカテゴリ分類し、それに対応するツールを選択するルール
- 基盤モデルへの呼び出し
- 各チャンクごとに 1 回ずつ LLM を呼び出し、
「ユーザー質問」「ツール呼び出し JSON」「モデル回答」などを含む JSON Lines 形式で生成
- 各チャンクごとに 1 回ずつ LLM を呼び出し、
- 構文バリデーション
- 生成された JSON が期待するスキーマどおりかどうかを検証し、不正なものを除外/修正
ここでのポイントは、「本番で使用するプロンプトに近い形で」データ生成プロンプトを組むことです。
トレーニング時と推論時のプロンプト分布を近づけることで、推論時の再現性が高まります。
Supervised Fine-Tuning(SFT)によるカスタマイズ
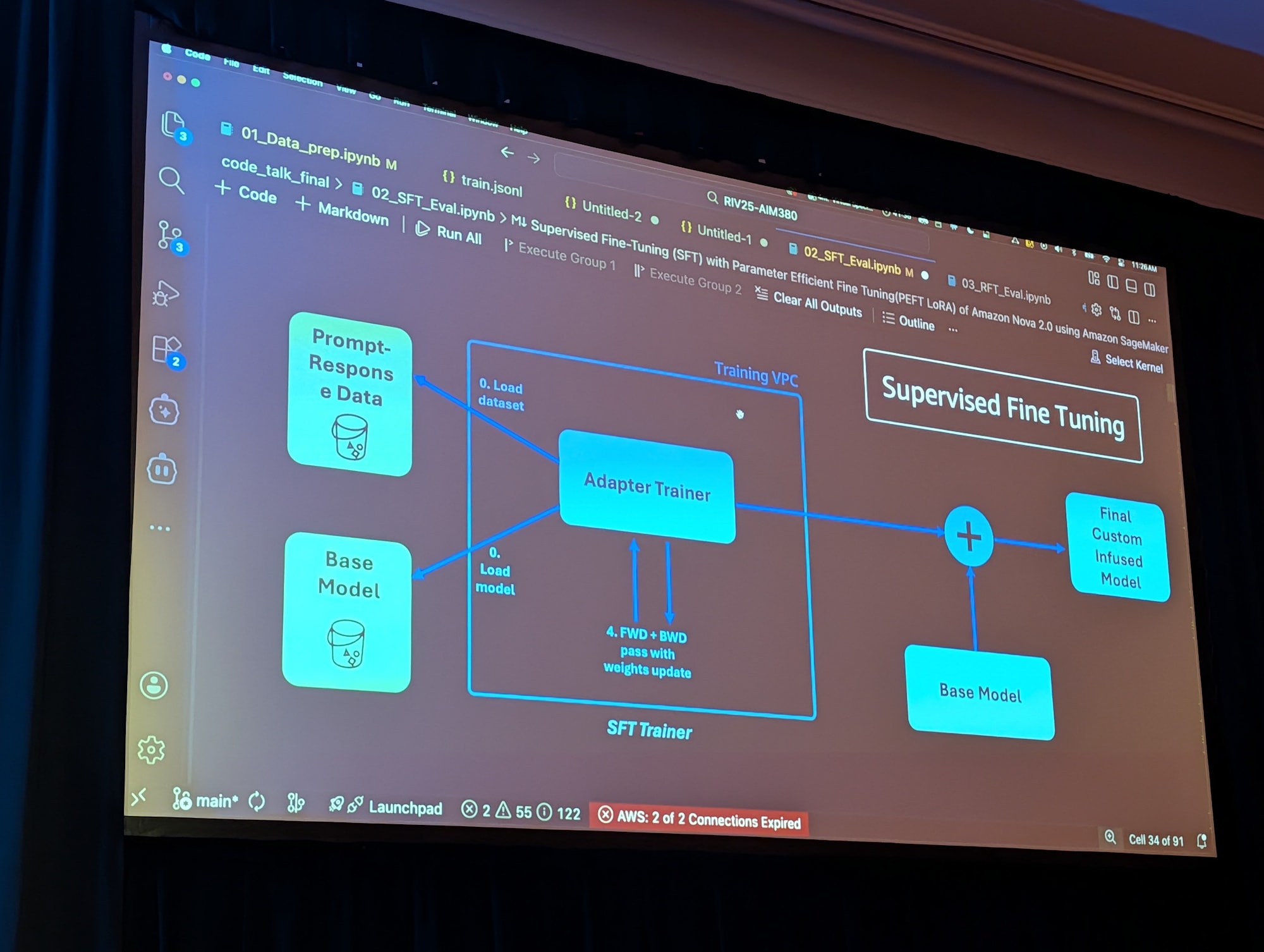
パラメータ効率の高い学習(Parameter-Efficient Fine-Tuning)
セッションでは、 LoRA ベースのパラメータ効率の高い学習を利用
- モデル全体の 1~2 % 程度の重みだけを更新
- フルファインチューニングと比べてコスト・時間・リスクを大幅削減
- ベースモデルと「アダプター」を後から融合することで、カスタムモデルを得る
ワークフロー概要
- SageMaker セッションとトレーニングインスタンスの選定
- Amazon 提供のコンテナイメージ(PyTorch / Pyro ベース)とレシピ(ハイパーパラメータのプリセット)を指定
- Estimator を作成し、トレーニングジョブを実行
- トレーニング後、 S3 上にチェックポイントが出力される
評価
- トレーニングループ内の評価は「教師データとテキスト一致しているか」が中心
- ツール呼び出し品質の評価では別途カスタム指標を定義
主な指標例:
- 正しいツールが選ばれているか
- 複数ツールが必要な場合、順序は正しいか
- ツール引数が正しく埋められているか
- JSON スキーマに準拠しているか
セッションの例では、 SFT によって「全体スコア」がおおよそ 44 % → 75 % 程度まで改善。
Reinforcement Fine-Tuning(RFT)による報酬最適化
SFT だけでは取りきれない「ツール選択の細かいニュアンス」や「パラメータ設定の最適化」を行うために、 RFT を追加で適用する。
全体アーキテクチャ
- Train VPC 内に配置された 2 つのモジュール:
- Rollout
- 1 つの入力に対して n 個の回答候補を生成
- Trainer
- Lambda から返ってくる報酬を受け取り、モデル重みを更新
- Rollout
- Customer VPC 内の Lambda
- 報酬関数(reward function)を実装
- 各回答候補に対してスコアを計算し返却
このサイクルを指定したステップ数だけ繰り返し、報酬が最大化されるようにモデルを更新する。
報酬関数設計のポイント
セッション中で強調されていたのが「報酬関数が最重要」という点。
- 指標例
- 正しいツールが選択されているか
- ツールパラメータは正しいか
- ツールの順序は適切か
- JSON 構造は正しいか
- 集約方法
- 各指標に重みをつけた加重平均で最終スコアを計算( 0~1 の連続値)
- ベストプラクティス
- バイナリ(0 / 1)ではなく、段階的なスコアをつける
- 例: 1 ~ 5 のスケールで 悪い / 普通 / 良い / かなり良い / ベスト など
- 連続的な勾配を与えることで、モデルがより良くなる方向を学習しやすくなる
- 報酬ハッキングに注意
- 報酬関数の穴を突いて高得点を出すだけの出力をモデルが学習しないように設計
- バイナリ(0 / 1)ではなく、段階的なスコアをつける
RFT の効果
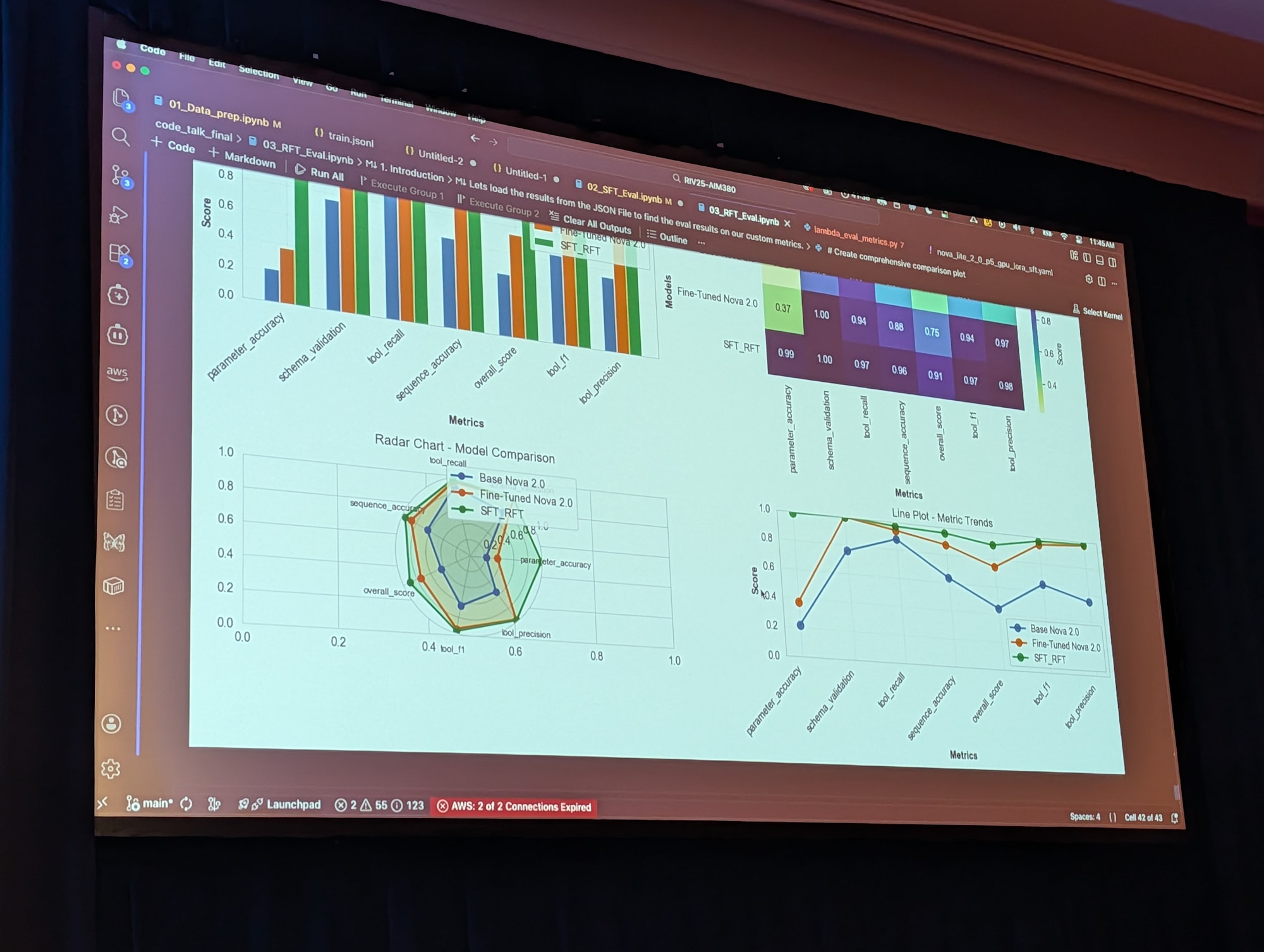
- トレーニングステップに応じて報酬が徐々に上昇するグラフを確認
- 例では、 SFT 後のスコア 75 % 前後 → RFT 適用後 90 % 前後までさらに改善
- 特にツール選択・パラメータ妥当性などの指標で明確な向上
ベースモデルに直接 RFT をかける実験も行っており、それよりも「SFT → RFT」の 2 段階構成の方が結果がよかったとのこと。
モデルのデプロイ(Bedrock へのデプロイ)
学習後のチェックポイントは S3 のサービスバケット上に保存される。
ユーザーは直接バケットにはアクセスでないが、 API 経由で Bedrock カスタムモデルとしてエクスポート・デプロイ可能。
デプロイ手順
CreateCustomModelAPI- RFT / SFT で得たチェックポイント S3 URI を指定し、 Bedrock 上のカスタムモデルとして登録
- ステータス確認
- モデルが
ACTIVEになるまで待機
- モデルが
CreateCustomModelDeploymentAPI- On-demand inference エンドポイントとしてデプロイ
その後の利用は Bedrock Converse API などで、 modelId にカスタムモデル ID を指定するだけ。
- ベースモデル利用時:
- Fomat などを指示しても、ツール呼び出し JSON が崩れたりする
- カスタムモデル利用時:
- 想定した JSON スキーマに沿ったツール呼び出し、適切なツール・パラメータ選択が実現できている
といったビフォーアフターを紹介。
コストとセキュリティに関する補足
コスト
- 推論コスト
- Parameter-Efficient なアダプター方式( LoRA )であれば、ベースモデルと同じハードウェアで動作するため、推論単価はベースモデルと同等
- トレーニングコスト
- LoRA を利用した SFT / RFT により、フルファインチューニングより大幅に削減
- 例: 数百~千数百サンプル程度・ 20~40 分程度のトレーニングで有意な改善を確認
一方でモデル全体の重みを変更するフルファインチューニングを行う場合は、 専用ハードウェアを占有する必要がありコストが大きくなる点が注意事項として挙げられていた。
セキュリティ / データ保護
- トレーニングは顧客アカウント内(VPC)で行われる
- 自社の機密データを使ってカスタマイズしても、そのデータは他テナントと共有されない
- 入力データソースは現状 S3 が前提
- DynamoDB など別ソースから一度 S3 にエクスポートして前処理する構成は問題なし
リーガルやヘルスケアなどセンシティブな領域では、適切なレビューとガバナンスを前提に利用してほしいという注意点も明示。
実務での適用に向けたポイント
セッションの内容を実務に落とし込む際のポイントを以下に整理します。
- まずはベースモデルとプロンプト / RAG だけでどこまで行けるか確認
- 合成データを含め、最低数百〜千サンプル程度の SFT データを用意
- ツール呼び出し JSON のフォーマット・パラメータに強くフォーカスした SFT を実施
- その上で、 Lambda ベースの報酬関数を設計して RFT を適用
- 報酬関数は連続値かつ「ちょっと良い」「かなり良い」の差を表現できるようにする
- カスタムモデルを Bedrock にエクスポートしてエンドポイント化
- 本番トラフィックのログや失敗ケースから、再度合成データを生成して再学習サイクルを回す
特に「ツール呼び出しの品質を上げたい」というユースケースでは、
プロンプトや RAG だけでは限界があり、このような SFT + RFT のアプローチが非常に有効であることが示されていました。










