![[Amazon Bedrock AgentCore] Gateway経由でLambda関数をAIエージェントのツールにしてみた](https://images.ctfassets.net/ct0aopd36mqt/7qr9SuOUauNHt4mdfTe2zu/8f7d8575eed91c386015d09e022e604a/AgentCore.png?w=3840&fm=webp)
[Amazon Bedrock AgentCore] Gateway経由でLambda関数をAIエージェントのツールにしてみた
はじめに
こんにちは、コンサルティング部の神野です。
皆さんはAmazon Bedrock AgentCore(以下AgentCore)のGateway機能を使っていますか?
Gatewayを試そうと公式ハンズオンを確認していると、「LambdaサーバーをMCPサーバ化できる!」と記載があってどういうこと・・・?とわからなかったので、実際に手を動かして理解を深めてみることにしました!
公式が提供しているハンズオン
Gatewayとは
Gatewayは既存のAPI、Lambda関数、各種サービスをMCP(Model Context Protocol)互換のツールに変換して、AIエージェントから簡単に呼び出せるようにしてくれるサービスです。
公式ハンズオンに記載があった図としては下記になります。
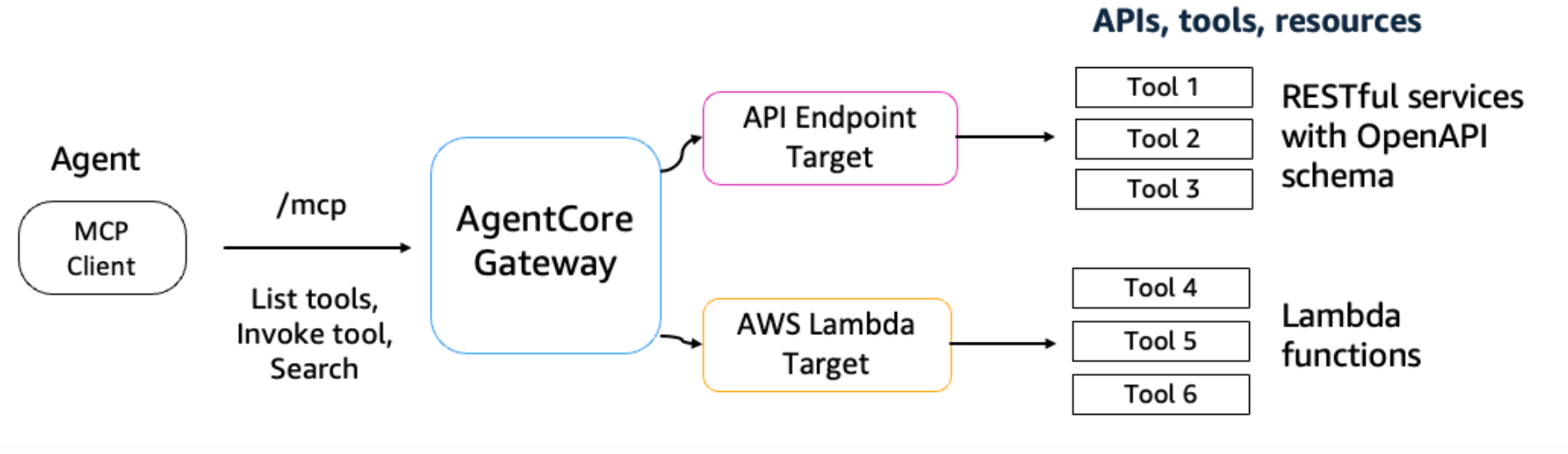
なるほど・・・?図を見るとGatewayが仲介になって、AIエージェントとLambda関数の架け橋になって、エージェントがLambda関数をtoolとして呼び出したり、その実行結果を踏まえて判断できるみたいな機能なんですかね。より深掘りします。
Gatewayが行っていることを順序立てて説明すると、以下のようになります。
- ツールの統合: 既存のLambda関数やAPIをMCPツールとして登録
- プロトコル変換: AIエージェントからのMCPリクエストを、実際のLambda関数呼び出しに変換
- 認証・認可: Inbound認証(エージェント側)とOutbound認証(リソース側)を管理
- AWSリソースの場合はGatewayのIAMロールにLambda関数を実行できる権限を付与すれば実行可能となります。
- 結果の変換: Lambda関数の実行結果をMCPレスポンス形式に変換してエージェントに返却
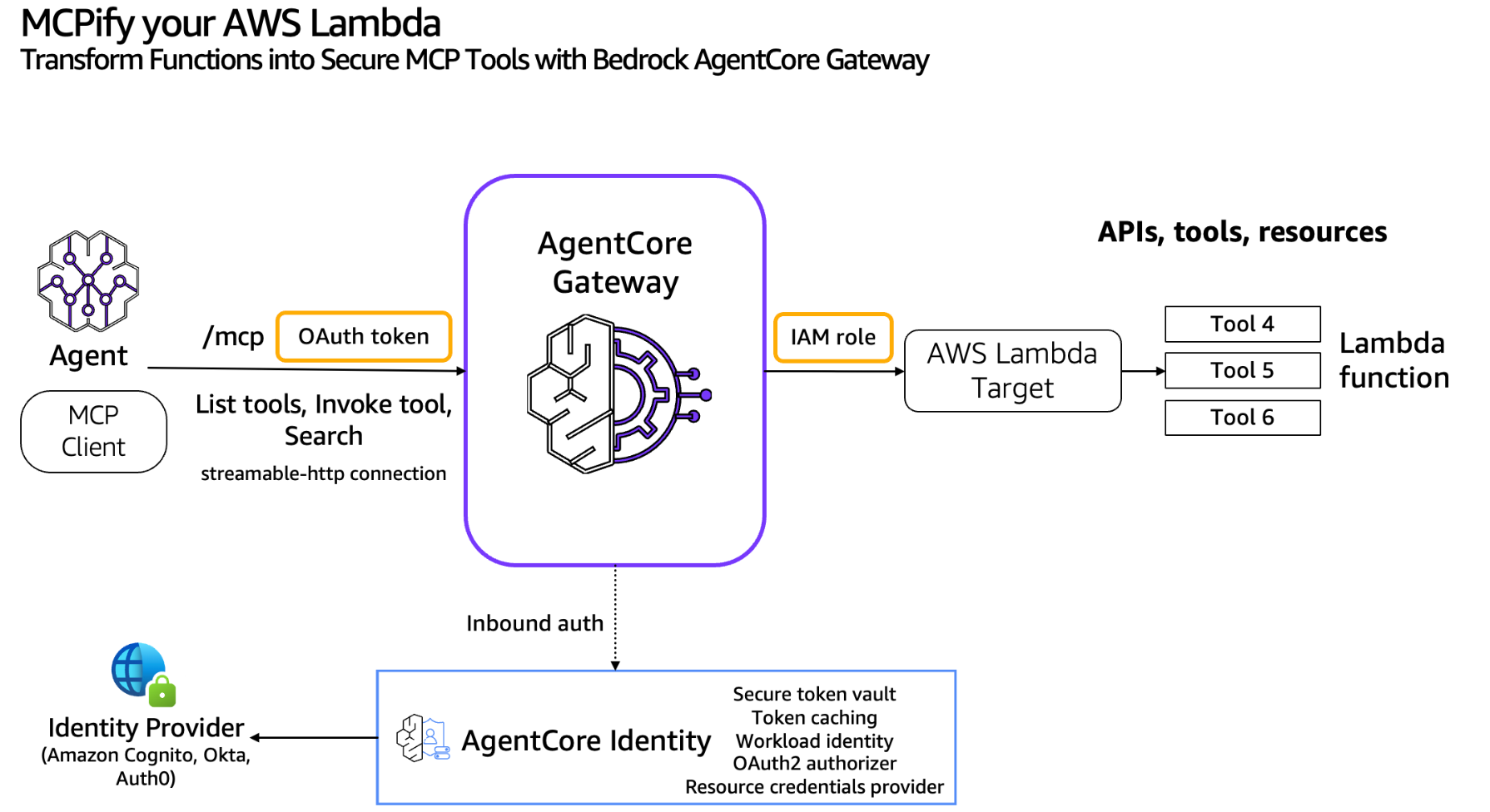
上の流れを今回のLambda関数との連携をイメージしてざっくりとした絵で描いてみました。
まさにGatewayはLambda関数とAIエージェントの架け橋としてMCPツール呼び出しを可能にしているんですね。
今回はLambda関数を対象にしていますが、OpenAPI仕様のAPIを使った場合なども試してみたいですね。
ツール統合
既存のエンタープライズリソースを、エージェントが使えるツールに簡単に変換できます。例えば、今回のように既存のLambda関数があれば、それをそのままMCPツール化可能です!具体的には下記対応しております。
- OpenAPI形式のAPI
- Lambda関数
- Smithy モデル
さらに、Salesforce、Slack、Jira、Asana、Zendesk などのメジャーなSaaSツールとの統合も提供されているため、企業で使用している既存システムとの連携が非常にスムーズに行えると思います。
認証機能
ここが今回の実装で最も重要なポイントになるのですが、GatewayはInbound認証(エージェントの身元確認)とOutbound認証(外部ツールへの接続)の両方をマネージドサービスIdentityで管理できます。
Runtimeの認証を実装する際もIdentityでもInbound/Outbound Auth出てきましたが、Gatewayでも必要になってくるんですね。
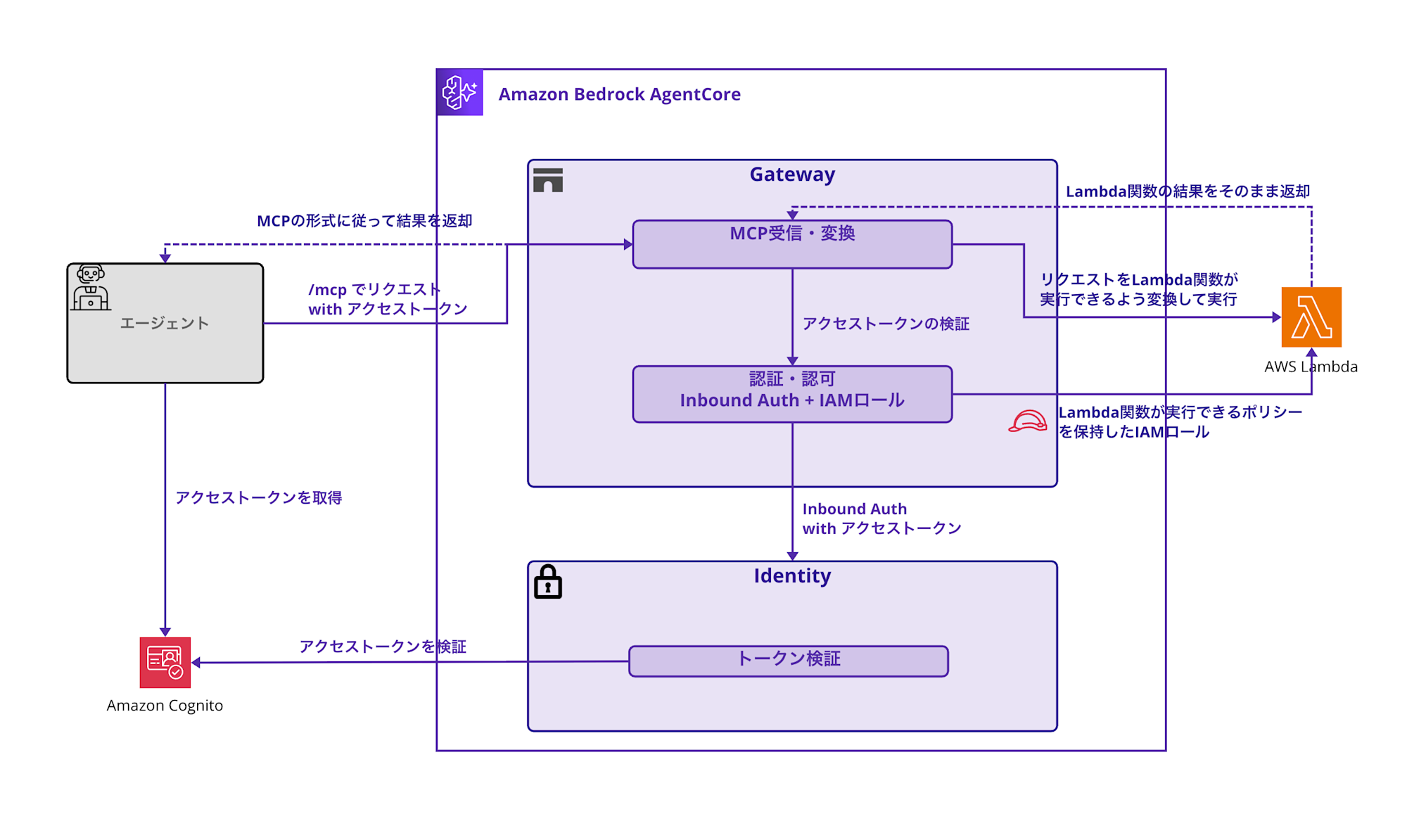
今回実装するLambda関数との統合についても公式ハンズオンで図があるので確認してみましょう。
この図から、以下の認証フローが読み取れます。
今回はLambda関数をターゲットとする場合は、Outbound Authは使用せずGatewayのIAMロールがLambdaの実行権限さえあればOKといった形になります。
- エージェント→Gateway: OAuth tokenでの認証(Inbound Auth)
- Gateway→Identity: トークン検証(今回はCognitoを使用)
- Gateway→Lambda: IAMロールでの実行権限
M2M(Machine-to-Machine)認証とは?
今回設定するパラメータにM2Mとあったので先に言及します。
M2M認証は、人間の介入なしにサービス同士が安全に通信するための認証方法です。
今回使用するOAuth2のclient_credentialsフローがその代表例です。
簡単に言うと、以下のような流れになります。
-
サービスA(今回はRuntime)が、自分のクライアントIDとシークレットを使って認証サーバー(Cognito)にアクセス
- Outbound Authに安全にシークレット情報は保管(Secrets Manager)されている
-
認証サーバーが一時的なアクセストークンを発行
-
サービスAは、このトークンを使ってサービスB(Gateway)にアクセス
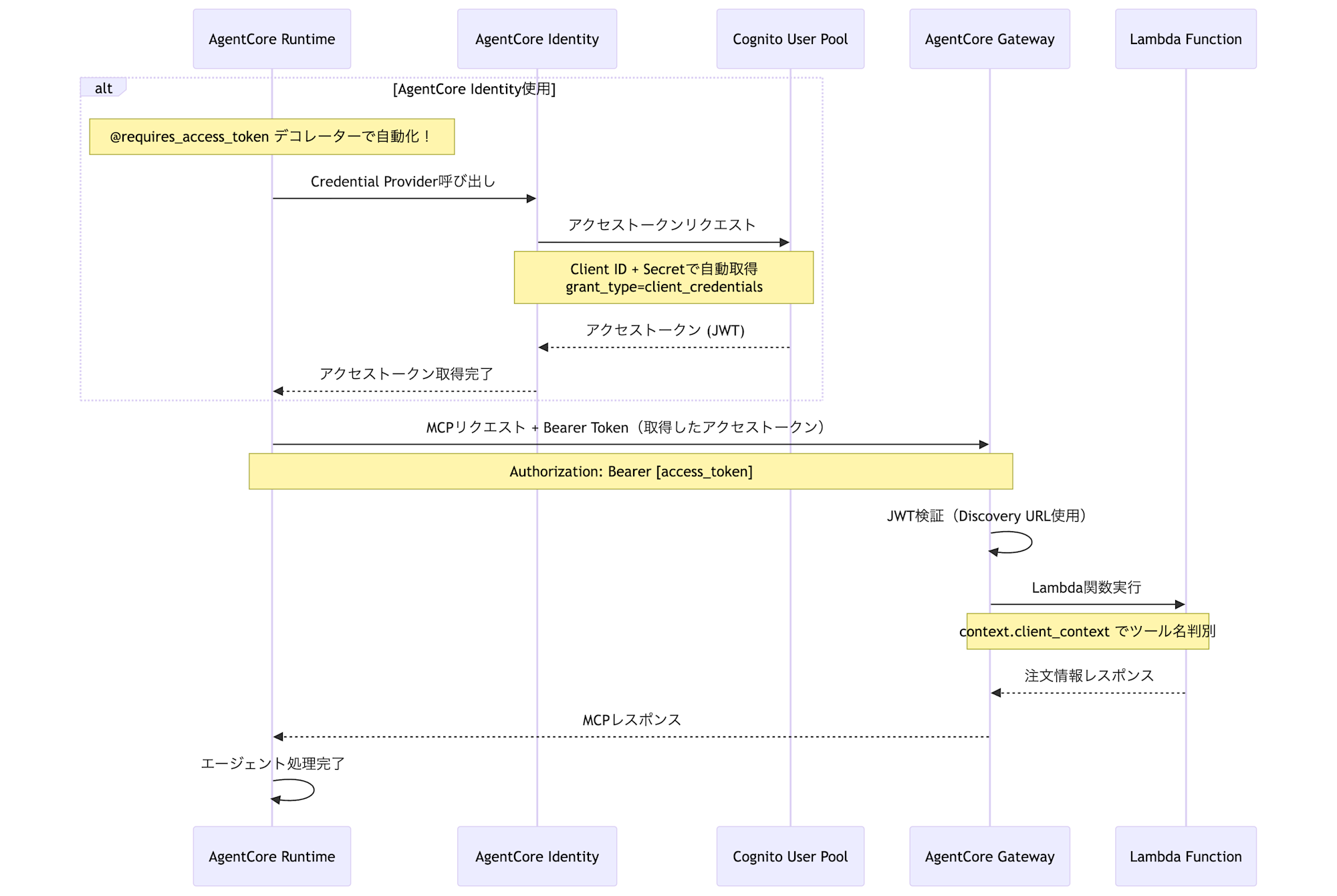
今回の実装全体をシーケンス図で記載するとこんなような感じです。
Identityの機能で、トークン取得が簡略化されるのは魅力の1つかと思います。
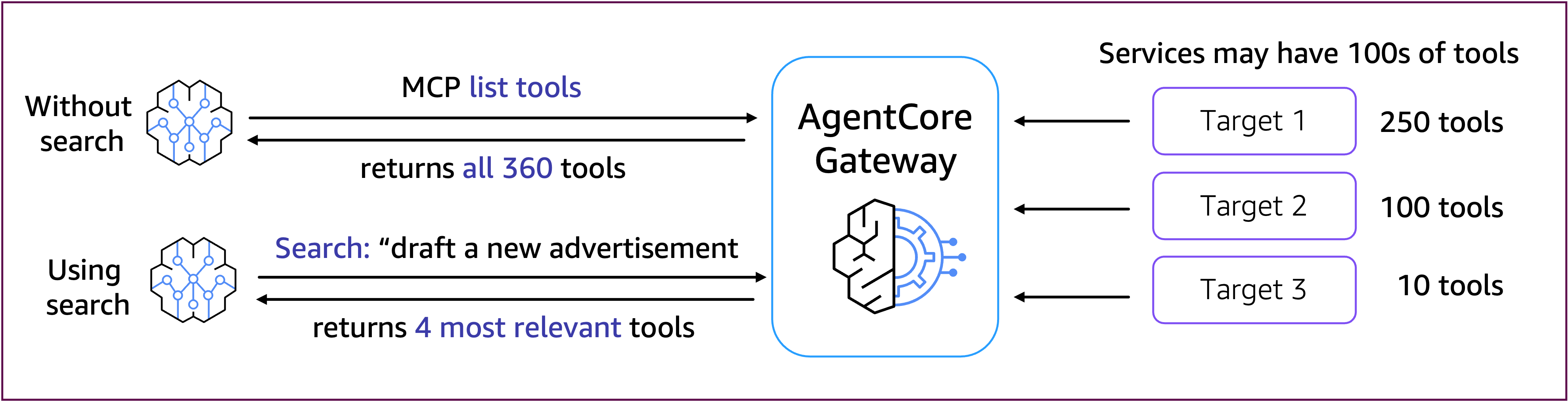
Semantic Search機能
実は今回のGateway作成時にenable_semantic_search=Trueという設定を有効にしています。これは何でしょうか?
Semantic Search(セマンティック検索)は、Gatewayが提供するインテリジェントなツール検索機能です。
通常、エージェントが利用できるツールの数には制限があり(一般的に100個程度)、ツールが増えるとプロンプトサイズが大きくなり、適切なツールを見つけるのが困難になるという課題があります。
Semantic Searchを有効にすると、以下のようなメリットがあります。
- コンテキストに基づくツール発見: エージェントがタスクの文脈に基づいて、最も関連性の高いツールを自動的に発見
- トークン処理の削減: 必要なツールのみをフォーカスすることで、処理するトークン数を大幅に削減
- 推論パフォーマンスの向上: 関連性の高いツールに絞り込むことで、全体的な応答時間を短縮
- スケーラビリティ: 数千のツールがあっても効率的に管理・利用可能
公式が提供している絵としては下記のような感じです。
ベストなツールをいい感じに検索できるようなイメージですね。
Gateway作成時に以下のように設定します。
gateway_response = gateway_client.create_mcp_gateway(
name=gateway_name,
role_arn=gateway_role_arn,
authorizer_config=authorizer_config,
enable_semantic_search=True # セマンティック検索を有効化!
)
ただし、Semantic Searchは作成時のみ有効化可能で既存のGatewayに後から追加することはできません。
下記のようにツールを検索して使用可能になると公式ドキュメントに記載がありました!
async def search_tools(gateway_url, access_token, query):
headers = {"Authorization": f"Bearer {access_token}"}
async with streamablehttp_client(gateway_url, headers=headers) as (read, write, _):
async with ClientSession(read, write) as session:
await session.initialize()
# Use the built-in search tool
response = await session.call_tool(
"x_amz_bedrock_agentcore_search",
arguments={"query": query}
)
# Parse the search results
for content in response.content:
results = json.loads(content.text)
print(f"Found {len(results)} relevant tools for: {query}")
for tool in results:
print(f"- {tool['name']}: {tool['description']}")
# Example usage
await search_tools(
"https://gateway-id.gateway.bedrock-agentcore.us-west-2.amazonaws.com/mcp",
"your-access-token",
"How do I process images?"
)
シンプルに使えそうでいいですね!また精度など検証してみたいです。
今回実装する構成
今回実装するアーキテクチャは以下のようになります。(ちょっと見づらい絵ですみません・・・)
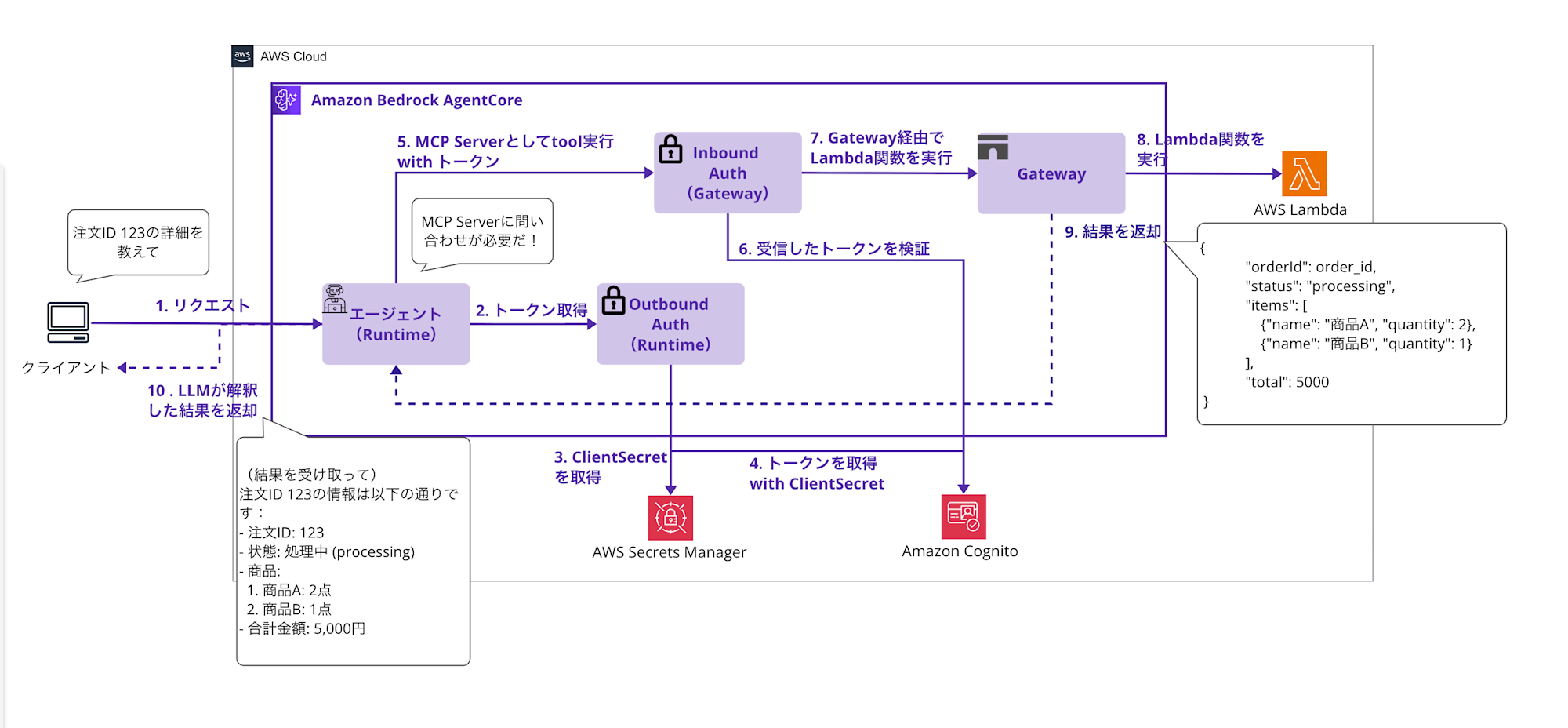
図の番号に沿って、それぞれのコンポーネントの役割を見ていきましょう。
1. AgentCore Runtime(認証なしで起動)
開発環境想定で簡略化のためにInbound認証なしでRuntimeを作成します。クライアントからのリクエストを直接受け付けて処理を開始します。
2-4. Outbound Auth でのトークン取得フロー
RuntimeのOutbound Auth機能が自動的に以下の処理を実行します。
-
- トークン取得: RuntimeがGatewayアクセス用のトークンを取得開始
-
- ClientSecret を取得: AWS Secrets ManagerからCognitoのクライアントシークレットを安全に取得
-
- トークンを取得 with ClientSecret: Amazon CognitoのOAuth2エンドポイントにM2M認証(client_credentials)でアクセストークンを取得
この部分がAgentCore Identityの魅力で、@requires_access_tokenデコレーターを使うだけで自動化可能です!
5. MCP Serverとしてtool実行 with トークン
取得したアクセストークンをAuthorizationヘッダーに付与して、MCPでGatewayにツール実行リクエストを送信します。
6-7. Gateway側での認証とLambda関数実行
-
- 受信したトークンを検証: GatewayのInbound Auth(Cognito認証)が、受信したアクセストークンの正当性を検証
-
- Gateway経由でLambda関数を実行: 認証が成功したら、GatewayがLambda関数を呼び出し
8-9. Lambda関数の処理と結果返却
-
- Lambda関数を実行: Lambda関数内で
context.client_contextからツール名(get_order_toolなど)を判別して処理
- Lambda関数を実行: Lambda関数内で
-
- 結果を返却: 注文情報のJSONデータを返却
10. LLMが解釈した結果を返却
最後に、LLMが自然言語に変換してユーザーに分かりやすく返答します。例えば下記のように返事をする想定です。
注文ID 123の情報は以下の通りです:
- 注文ID: 123
- 状態: 処理中 (processing)
- 商品:
1. 商品A: 2点
2. 商品B: 1点
- 合計金額: 5,000円
RuntimeのOutbound Auth → GatewayのInbound Auth → Lambda実行という流れで、
Lambda関数をMCPツール化可能にします!
前提条件
必要な環境
- AWS CLI 2.28.8
- Python 3.12
- AWSアカウント(us-west-2リージョンを使用)
- 適切なIAM権限(AgentCore、Lambda、Cognito、IAMの操作権限)
- モデルの有効化
- 今回は
anthropic.claude-3-5-haiku-20241022-v1:0を使用します
- 今回は
必要なライブラリ
実装に必要なライブラリをrequirements.txtにまとめました。python-dotenvで.env管理、strands-agentsでエージェント実装、bedrock-agentcoreでRuntime/Gateway操作を行います。
boto3
botocore
strands-agents
bedrock-agentcore
bedrock-agentcore-starter-toolkit
python-dotenv
requests
仮想環境を作成して必要なパッケージをインストールします。
# 仮想環境の作成と有効化
python3 -m venv agentcore-env
source agentcore-env/bin/activate
# 依存関係のインストール
pip install -r requirements.txt
プロジェクト構成
今回作成するファイル構成は以下のとおりです。
.
├── requirements.txt # 依存関係
├── .env # 環境変数設定(自動生成)
├── .env.example # 環境変数のテンプレート
├── setup_cognito.py # Cognito設定スクリプト(.env自動更新)
├── create_iam_roles.py # IAMロール作成スクリプト(.env自動更新)
├── create_lambda.py # Lambda関数作成スクリプト(.env自動更新)
├── create_gateway.py # Gateway作成スクリプト(.env自動更新)
├── setup_outbound_auth.py # OutboundAuth設定スクリプト(必須)
├── runtime_agent.py # Runtime実装(AgentCore Identity使用)
├── deploy_runtime.py # Runtimeデプロイスクリプト
└── invoke_agentcore.py # 動作確認用スクリプト
環境変数の管理
今回は.envファイルで環境変数を一元管理します。各スクリプトが実行されるたびに.envファイルが自動更新されるので、手動での環境変数設定が不要になります。
# Cognito設定(setup_cognito.pyが自動更新)
COGNITO_DISCOVERY_URL=
M2M_CLIENT_ID=
M2M_CLIENT_SECRET=
COGNITO_POOL_ID=
RESOURCE_SERVER_ID=agentcore-gateway
# Gateway設定(create_gateway.pyが自動更新)
GATEWAY_URL=
GATEWAY_ID=
# IAMロール(create_iam_roles.pyが自動更新)
GATEWAY_ROLE_ARN=
RUNTIME_ROLE_ARN=
LAMBDA_ROLE_ARN=
# Lambda設定(create_lambda.pyが自動更新)
LAMBDA_ARN=
# AgentCore Identity設定(setup_outbound_auth.py実行後に手動追加)
IDENTITY_PROVIDER_NAME=agentcore-identity-for-gateway
GATEWAY_SCOPE=agentcore-gateway/read agentcore-gateway/write
サンプルのレポジトリ
実装を1通り行ったレポジトリは下記にあるので、必要に応じてご参照ください。
実装手順
1. Cognito User Poolの作成
まずはGatewayのInbound認証用にCognitoを設定します。M2M認証なので、Resource ServerとApp Clientの設定が必要です。
setup_cognito.pyでは、Cognito User Pool、Resource Server、User Pool Domain、App Clientを作成し、結果を.envファイルに自動保存します。
import boto3
import json
import os
from botocore.exceptions import ClientError
from dotenv import load_dotenv, set_key
REGION = "us-west-2"
USER_POOL_NAME = "agentcore-gateway-pool"
RESOURCE_SERVER_ID = "agentcore-gateway"
RESOURCE_SERVER_NAME = "AgentCore Gateway Resource Server"
CLIENT_NAME = "agentcore-m2m-client"
# Scopeの定義
SCOPES = [
{"ScopeName": "read", "ScopeDescription": "Read access to Gateway"},
{"ScopeName": "write", "ScopeDescription": "Write access to Gateway"}
]
def create_cognito_m2m_setup():
cognito = boto3.client("cognito-idp", region_name=REGION)
try:
# User Poolの作成
pool_response = cognito.create_user_pool(
PoolName=USER_POOL_NAME,
Policies={
'PasswordPolicy': {
'MinimumLength': 8,
'RequireUppercase': True,
'RequireLowercase': True,
'RequireNumbers': True,
'RequireSymbols': True
}
}
)
pool_id = pool_response['UserPool']['Id']
print(f"✅ User Pool作成完了: {pool_id}")
# Resource Serverの作成
resource_response = cognito.create_resource_server(
UserPoolId=pool_id,
Identifier=RESOURCE_SERVER_ID,
Name=RESOURCE_SERVER_NAME,
Scopes=SCOPES
)
print(f"✅ Resource Server作成完了: {RESOURCE_SERVER_ID}")
# User Pool Domain作成(OAuth2 token endpointに必須)
domain_name = f"agentcore-gateway-auth-{int(time.time())}"
try:
domain_response = cognito.create_user_pool_domain(
Domain=domain_name,
UserPoolId=pool_id
)
print(f"✅ User Pool Domain作成完了: {domain_name}")
except ClientError as e:
if e.response['Error']['Code'] == 'InvalidParameterException' and 'already exists' in str(e):
# ドメイン名重複時は別の名前で再試行
domain_name = f"agentcore-gateway-auth-{int(time.time())}-retry"
domain_response = cognito.create_user_pool_domain(
Domain=domain_name,
UserPoolId=pool_id
)
print(f"✅ User Pool Domain作成完了(リトライ): {domain_name}")
else:
raise
# App Client作成(M2M用)
client_response = cognito.create_user_pool_client(
UserPoolId=pool_id,
ClientName=CLIENT_NAME,
GenerateSecret=True, # M2M認証には必須
AllowedOAuthFlows=['client_credentials'], # M2M認証フロー
AllowedOAuthScopes=[
f"{RESOURCE_SERVER_ID}/read",
f"{RESOURCE_SERVER_ID}/write"
],
AllowedOAuthFlowsUserPoolClient=True
)
client_id = client_response['UserPoolClient']['ClientId']
client_secret = client_response['UserPoolClient']['ClientSecret']
# Discovery URLの生成
discovery_url = f"https://cognito-idp.{REGION}.amazonaws.com/{pool_id}/.well-known/openid-configuration"
print("\n🎉 Cognito M2M設定完了!")
print(f"Pool ID: {pool_id}")
print(f"Client ID: {client_id}")
print(f"Client Secret: {client_secret}")
print(f"Discovery URL: {discovery_url}")
# .envファイルに設定を自動保存
env_file = ".env"
# .env.exampleからコピー(初回のみ)
if not os.path.exists(env_file) and os.path.exists(".env.example"):
with open(".env.example", "r") as src, open(env_file, "w") as dst:
dst.write(src.read())
# 環境変数を更新
set_key(env_file, "COGNITO_POOL_ID", pool_id)
set_key(env_file, "M2M_CLIENT_ID", client_id)
set_key(env_file, "M2M_CLIENT_SECRET", client_secret)
set_key(env_file, "COGNITO_DISCOVERY_URL", discovery_url)
set_key(env_file, "RESOURCE_SERVER_ID", RESOURCE_SERVER_ID)
print(f"\n✅ 設定を.envファイルに保存しました!")
return {
"pool_id": pool_id,
"client_id": client_id,
"client_secret": client_secret,
"discovery_url": discovery_url
}
except ClientError as e:
print(f"❌ エラーが発生しました: {e}")
raise
if __name__ == "__main__":
cognito_config = create_cognito_m2m_setup()
User Pool Domainも忘れずに作成しましょうね!最初作成を忘れていて下記エラーになりました。
エラー内容:An error occurred (ValidationException) when calling the GetResourceOauth2Token operation: Error parsing ClientCredentials response
CognitoでOAuth 2.0のclient_credentialsフロー(M2M認証)を使用するにはUser Pool Domainが必須です。
- User Pool Domainを作成することで初めて
/oauth2/tokenエンドポイントが有効になる - このエンドポイントがないと、M2M認証でアクセストークンを取得できない
- AgentCore Identityは内部でこのエンドポイントを呼び出すため、Domainがないとエラーになる
2. IAMロールの作成
GatewayとRuntimeそれぞれに必要なIAMロールを作成します。今回はPythonスクリプトで自動化し、作成したロールARNを.envファイルに自動保存します。
create_iam_roles.pyでは、アカウントIDを自動取得し、Gateway/Runtime用の詳細な権限を設定して、結果を.envファイルに保存します。
"""
IAMロール作成スクリプト
Gateway用とRuntime用のIAMロールを作成し、.envファイルに自動保存します。
"""
import boto3
import json
import os
import time
from botocore.exceptions import ClientError
from dotenv import load_dotenv, set_key
# AWSクライアント
iam = boto3.client('iam')
sts = boto3.client('sts')
def get_account_id():
"""AWSアカウントIDを取得"""
return sts.get_caller_identity()["Account"]
def create_trust_policy(account_id):
"""信頼ポリシーを生成(Gateway/Runtime共通)"""
return {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AssumeRolePolicy",
"Effect": "Allow",
"Principal": {
"Service": "bedrock-agentcore.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": account_id
},
"ArnLike": {
"aws:SourceArn": f"arn:aws:bedrock-agentcore:us-west-2:{account_id}:*"
}
}
}
]
}
Runtime用の詳細なポリシー
Runtime用には、ECRアクセス、CloudWatch Logs、X-Ray、メトリクス、Bedrockモデル呼び出し、AgentCore Identity認証関連、Secrets Managerの権限を付与します。AgentCore Identity関連の権限は、OutboundAuth機能でM2M認証トークンを取得する際に必要になります。
コード全文
def create_runtime_policy(account_id):
"""Runtime用の詳細な実行ポリシーを生成"""
return {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ECRImageAccess",
"Effect": "Allow",
"Action": [
"ecr:BatchGetImage",
"ecr:GetDownloadUrlForLayer"
],
"Resource": [
f"arn:aws:ecr:us-west-2:{account_id}:repository/*"
]
},
{
"Sid": "ECRTokenAccess",
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken"
],
"Resource": "*"
},
{
"Sid": "LogsDescribeLogGroups",
"Effect": "Allow",
"Action": [
"logs:DescribeLogGroups"
],
"Resource": "*"
},
{
"Sid": "LogsGroupLevel",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:DescribeLogStreams"
],
"Resource": [
f"arn:aws:logs:us-west-2:{account_id}:log-group:/aws/bedrock-agentcore/runtimes/*"
]
},
{
"Sid": "LogsStreamLevel",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
f"arn:aws:logs:us-west-2:{account_id}:log-group:/aws/bedrock-agentcore/runtimes/*:log-stream:*"
]
},
{
"Sid": "XRayAccess",
"Effect": "Allow",
"Action": [
"xray:PutTraceSegments",
"xray:PutTelemetryRecords",
"xray:GetSamplingRules",
"xray:GetSamplingTargets"
],
"Resource": ["*"]
},
{
"Sid": "CloudWatchMetrics",
"Effect": "Allow",
"Resource": "*",
"Action": "cloudwatch:PutMetricData",
"Condition": {
"StringEquals": {
"cloudwatch:namespace": "bedrock-agentcore"
}
}
},
{
"Sid": "BedrockModelInvocation",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": [
"arn:aws:bedrock:*::foundation-model/*",
f"arn:aws:bedrock:us-west-2:{account_id}:*"
]
},
{
"Sid": "AgentCoreIdentityAccess",
"Effect": "Allow",
"Action": [
"bedrock-agentcore:GetResourceOauth2Token",
"bedrock-agentcore:GetWorkloadAccessToken",
"bedrock-agentcore:GetWorkloadAccessTokenForUserId"
],
"Resource": ["*"]
},
{
"Sid": "SecretsManagerAccess",
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": ["*"]
}
]
}
Gateway用のポリシー
Gateway用には、Lambda実行権限、CloudWatch Logsの権限を付与します。
コード全文
def create_gateway_policy(account_id):
"""Gateway用の実行ポリシーを生成"""
return {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LambdaInvocation",
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction"
],
"Resource": f"arn:aws:lambda:us-west-2:{account_id}:function:*"
},
{
"Sid": "LogsAccess",
"Effect": "Allow",
"Action": [
"logs:DescribeLogStreams",
"logs:CreateLogGroup",
"logs:DescribeLogGroups",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
f"arn:aws:logs:us-west-2:{account_id}:log-group:/aws/bedrock-agentcore/gateway/*"
]
},
{
"Sid": "XRayAccess",
"Effect": "Allow",
"Action": [
"xray:PutTraceSegments",
"xray:PutTelemetryRecords"
],
"Resource": ["*"]
}
]
}
Lambda用のポリシー
Lambda関数用のIAMロールも同時に作成されます。Lambda用には基本的なCloudWatch Logs権限を付与します。
コード全文
def create_lambda_policy(account_id):
"""Lambda関数用の実行ポリシーを生成"""
return {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LogsAccess",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
f"arn:aws:logs:us-west-2:{account_id}:log-group:/aws/lambda/agentcore-order-tools:*"
]
},
{
"Sid": "XRayAccess",
"Effect": "Allow",
"Action": [
"xray:PutTraceSegments",
"xray:PutTelemetryRecords"
],
"Resource": ["*"]
}
]
}
実行すると、3つのIAMロール(Gateway、Runtime、Lambda)が作成され、ARNが.envファイルに自動保存されます。
# IAMロールを作成(.envファイルを自動更新)
python create_iam_roles.py
実行結果の例:
🚀 IAMロール作成スクリプトを開始します...
アカウントID: 123456789012
📦 Gateway用IAMロールを作成中...
✅ IAMロール作成成功: AgentCoreGatewayRole-1234567890
ポリシーをアタッチしました
📦 Runtime用IAMロールを作成中...
✅ IAMロール作成成功: AgentCoreRuntimeRole-1234567890
ポリシーをアタッチしました
📦 Lambda関数用IAMロールを作成中...
✅ IAMロール作成成功: AgentCoreLambdaRole-1234567890
ポリシーをアタッチしました
🎉 IAMロール作成完了!
Gateway Role ARN: arn:aws:iam::123456789012:role/AgentCoreGatewayRole-1234567890
Runtime Role ARN: arn:aws:iam::123456789012:role/AgentCoreRuntimeRole-1234567890
Lambda Role ARN: arn:aws:iam::123456789012:role/AgentCoreLambdaRole-1234567890
✅ .envファイルに保存しました
3. Lambda関数の作成
次に、MCPツール化するLambda関数を作成します。
ツール名を判別する際にGateway経由で呼び出される際のcontext.client_contextを活用するのがポイントです!
最初、Lambda関数でどうやってツール名を判別すればいいのか分からず困りました。
調べてみると、Gateway経由で呼び出されるLambda関数では、context.client_context.custom['bedrockAgentCoreToolName']からツール名が取得できることがわかりました。
さらに、実際のツール名には Gateway Target のプレフィックス(例:order-lambda-target___get_order_tool)が付くため、___で分割して実際のツール名を抽出する処理が必要でした。
この実装はAWS公式のサンプルコードが大変参考になりました!
import json
def lambda_handler(event, context):
"""
AgentCore Gateway経由で呼び出されるLambda関数
context.client_contextからツール名を判別して処理を分岐
"""
# Gateway経由の場合、context.client_contextが設定される
tool_name = None
try:
if hasattr(context, 'client_context') and context.client_context:
# client_contextから直接ツール名を取得
tool_name = context.client_context.custom['bedrockAgentCoreToolName']
print(f"Original tool name from Gateway: {tool_name}")
# Gateway Target プレフィックスを除去
delimiter = "___"
if delimiter in tool_name:
tool_name = tool_name[tool_name.index(delimiter) + len(delimiter):]
print(f"Processed tool name: {tool_name}")
print(f"Client context structure: {str(context.client_context)}")
else:
print("No client_context available - direct Lambda invocation")
except (AttributeError, KeyError, TypeError) as e:
print(f"Error accessing client_context: {e}")
tool_name = None
# ツール名に基づいて処理を分岐
if tool_name == 'get_order_tool':
order_id = event.get('orderId', 'unknown')
# 実際のビジネスロジックをここに実装
result = {
"orderId": order_id,
"status": "processing",
"items": [
{"name": "商品A", "quantity": 2},
{"name": "商品B", "quantity": 1}
],
"total": 5000
}
return {
"statusCode": 200,
"body": json.dumps(result)
}
elif tool_name == 'update_order_tool':
order_id = event.get('orderId', 'unknown')
# 実際の更新処理をここに実装
result = {
"orderId": order_id,
"status": "updated",
"message": f"Order {order_id} has been updated successfully"
}
return {
"statusCode": 200,
"body": json.dumps(result)
}
else:
# ツール名が不明な場合
return {
"statusCode": 400,
"body": json.dumps({
"error": f"Unknown tool: {tool_name}"
})
}
Lambda関数もPythonスクリプトで自動化します。.envファイルからLambdaロールARNを読み込み、作成したLambda関数のARNを.envファイルに保存します。
create_lambda.pyでは、Lambda関数のコード生成、ZIPパッケージ化、デプロイ、.env更新を自動で行います。
コード全文
"""
Lambda関数作成スクリプト
注文管理Lambda関数を作成し、.envファイルに自動保存します。
"""
import boto3
import zipfile
import os
from botocore.exceptions import ClientError
from dotenv import load_dotenv, set_key
# AWSクライアント
lambda_client = boto3.client('lambda', region_name='us-west-2')
LAMBDA_FUNCTION_NAME = "agentcore-order-tools"
LAMBDA_RUNTIME = "python3.12"
LAMBDA_HANDLER = "lambda_function.lambda_handler"
def create_lambda_function(role_arn):
"""Lambda関数を作成"""
try:
# デプロイメントパッケージを読み込み
with open("lambda_function_code.zip", "rb") as f:
zip_content = f.read()
# Lambda関数を作成
response = lambda_client.create_function(
FunctionName=LAMBDA_FUNCTION_NAME,
Runtime=LAMBDA_RUNTIME,
Role=role_arn,
Handler=LAMBDA_HANDLER,
Code={'ZipFile': zip_content},
Description='Order management tools for AgentCore Gateway'
)
function_arn = response['FunctionArn']
print(f"✅ Lambda関数作成成功: {LAMBDA_FUNCTION_NAME}")
return function_arn
except ClientError as e:
if e.response['Error']['Code'] == 'ResourceConflictException':
print(f"ℹ️ Lambda関数は既に存在します")
response = lambda_client.get_function(FunctionName=LAMBDA_FUNCTION_NAME)
return response['Configuration']['FunctionArn']
実行すると、Lambda関数が作成され、ARNが.envファイルに自動保存されます。
# Lambda関数を作成(.envファイルを自動更新)
python create_lambda.py
実行結果の例:
🚀 Lambda関数作成スクリプトを開始します...
✅ Lambda関数のコードを作成しました
✅ デプロイメントパッケージを作成しました: lambda_function_code.zip
✅ Lambda関数作成成功: agentcore-order-tools
🎉 Lambda関数作成完了!
Function ARN: arn:aws:lambda:us-west-2:123456789012:function:agentcore-order-tools
✅ .envファイルに保存しました
🧹 作業ファイルを削除しました
4. AgentCore Identity OutboundAuth設定
AgentCore IdentityのOutboundAuth機能を使ってM2M認証を行うため、Credential Providerの設定が必要です。この設定により、RuntimeからGatewayへのM2M認証が自動化されます。
setup_outbound_auth.pyでは、.envファイルから既存のGateway設定を自動読み取りし、Credential Providerを作成して、結果を.envファイルに自動保存します。
"""
AgentCore Identity OutboundAuth自動セットアップスクリプト
Gateway用のCredential Providerを自動作成します。
"""
import boto3
import requests
import json
import os
from typing import Dict, Any, Optional
from botocore.exceptions import ClientError
class OutboundAuthSetup:
def __init__(self, region: str = "us-west-2"):
self.region = region
self.cognito_client = boto3.client("cognito-idp", region_name=region)
self.gateway_client = boto3.client("bedrock-agentcore-control", region_name=region)
self.identity_client = boto3.client("bedrock-agentcore-control", region_name=region)
def get_gateway_info(self, gateway_name: str) -> Dict[str, Any]:
"""
既存のGatewayから必要な情報を取得
"""
try:
# Gatewayを検索
response = self.gateway_client.list_gateways()
gateway_info = None
for gateway in response.get("gateways", []):
if gateway.get("name") == gateway_name:
gateway_info = gateway
break
if not gateway_info:
raise Exception(f"Gateway '{gateway_name}' not found")
# 詳細情報を取得
gateway_detail = self.gateway_client.get_gateway(
gatewayIdentifier=gateway_info["gatewayId"]
)
print(f"✅ Gateway情報取得成功: {gateway_name}")
print(f" Gateway ID: {gateway_detail['gatewayId']}")
print(f" Gateway URL: {gateway_detail['gatewayUrl']}")
return gateway_detail
except ClientError as e:
print(f"❌ Gateway情報取得エラー: {e}")
raise
def get_cognito_discovery_url(self, gateway_detail: Dict[str, Any]) -> str:
"""
GatewayのCognito設定からDiscovery URLを取得
"""
try:
auth_config = gateway_detail.get("authorizerConfiguration", {})
custom_jwt = auth_config.get("customJWTAuthorizer", {})
discovery_url = custom_jwt.get("discoveryUrl")
if not discovery_url:
raise Exception("Gateway authorizerConfiguration にdiscoveryUrlが見つかりません")
print(f"✅ Discovery URL取得成功: {discovery_url}")
return discovery_url
except Exception as e:
print(f"❌ Discovery URL取得エラー: {e}")
raise
def get_cognito_client_info(self, discovery_url: str) -> Dict[str, str]:
"""
Discovery URLからUser Pool IDを抽出し、クライアント情報を取得
"""
try:
# Discovery URLからUser Pool IDを抽出
# 例: https://cognito-idp.us-west-2.amazonaws.com/us-west-2_XXXXXXX/.well-known/openid-configuration
import re
match = re.search(r'/([^/]+)/.well-known', discovery_url)
if not match:
raise Exception("Discovery URLからUser Pool IDを抽出できません")
user_pool_id = match.group(1)
print(f"✅ User Pool ID抽出成功: {user_pool_id}")
# User Pool Clientsを取得
clients_response = self.cognito_client.list_user_pool_clients(
UserPoolId=user_pool_id
)
if not clients_response.get("UserPoolClients"):
raise Exception("User Pool Clientが見つかりません")
# 最初のクライアント(通常M2M用)を使用
client_info = clients_response["UserPoolClients"][0]
client_id = client_info["ClientId"]
# クライアント詳細を取得
client_detail = self.cognito_client.describe_user_pool_client(
UserPoolId=user_pool_id,
ClientId=client_id
)
client_secret = client_detail["UserPoolClient"].get("ClientSecret")
print(f"✅ Cognito Client情報取得成功:")
print(f" Client ID: {client_id}")
print(f" Client Secret: {'*' * 8}...{client_secret[-4:] if client_secret else 'なし'}")
return {
"client_id": client_id,
"client_secret": client_secret,
"user_pool_id": user_pool_id,
"discovery_url": discovery_url
}
except ClientError as e:
print(f"❌ Cognito Client情報取得エラー: {e}")
raise
def create_oauth2_credential_provider(self,
provider_name: str,
cognito_info: Dict[str, str]) -> Dict[str, Any]:
"""
OAuth2 Credential Providerを作成
"""
try:
create_request = {
"name": provider_name,
"description": f"Gateway M2M認証用Credential Provider - {provider_name}",
"configurationOverrides": {
"clientId": cognito_info["client_id"],
"clientSecret": cognito_info["client_secret"],
"discoveryUrl": cognito_info["discovery_url"],
"grantType": "client_credentials"
}
}
print(f"🔐 OAuth2 Credential Provider作成中: {provider_name}")
response = self.identity_client.create_oauth2_credential_provider(**create_request)
print(f"✅ OAuth2 Credential Provider作成成功!")
print(f" Provider Name: {response['name']}")
print(f" Provider ID: {response.get('credentialProviderId', 'N/A')}")
return response
except ClientError as e:
if e.response['Error']['Code'] == 'ConflictException':
print(f"⚠️ Credential Provider '{provider_name}' は既に存在します")
# 既存のプロバイダ情報を取得
try:
list_response = self.identity_client.list_oauth2_credential_providers()
for provider in list_response.get("oauth2CredentialProviders", []):
if provider["name"] == provider_name:
print(f"✅ 既存のCredential Provider使用: {provider_name}")
return provider
except Exception as list_error:
print(f"❌ 既存プロバイダ情報取得エラー: {list_error}")
raise
else:
print(f"❌ OAuth2 Credential Provider作成エラー: {e}")
raise
実行方法:
# OutboundAuth設定(必須ステップ)- .envファイルから自動読み取り
python setup_outbound_auth.py
実行するとIDENTITY_PROVIDER_NAMEとGATEWAY_SCOPEも自動で.envファイルに保存されます!
実行結果の例:
🚀 OutboundAuth自動設定開始
.envファイルから設定を読み込み中...
Gateway ID: 1234567890abcdef
Provider Name: agentcore-identity-for-gateway
Region: us-west-2
--------------------------------------------------
✅ Gateway情報取得成功: order-management-gateway
Gateway URL: https://gateway-1234567890abcdef.mcp.us-west-2.amazonaws.com
✅ Discovery URL取得成功: https://cognito-idp.us-west-2.amazonaws.com/us-west-2_XXXXXXX/.well-known/openid-configuration
✅ User Pool ID抽出成功: us-west-2_XXXXXXX
✅ Cognito Client情報取得成功:
Client ID: 1234567890abcdef
Client Secret: ********...xyz123
🔐 OAuth2 Credential Provider作成中: agentcore-identity-for-gateway
✅ OAuth2 Credential Provider作成成功!
Provider Name: agentcore-identity-for-gateway
Provider ID: resource-provider-oauth-client
--------------------------------------------------
🎉 OutboundAuth設定完了!
✅ 以下の環境変数を.envファイルに自動保存しました:
IDENTITY_PROVIDER_NAME=agentcore-identity-for-gateway
GATEWAY_SCOPE=agentcore-gateway/read agentcore-gateway/write
5. AgentCore Gatewayの作成
Gatewayを作成します!Cognito認証を設定し、Lambda関数をMCPツールとしてGatewayと紐付けして登録します。
IAMロールで呼び出しを行うため、認証情報プロバイダーに"credentialProviderType": "GATEWAY_IAM_ROLE"と記載したり、ツール自体の定義を書いて、ターゲットをLambda関数のARNを指定することで紐付けが可能になります。
create_gateway.pyでは、.envファイルから設定を読み込み、Gateway作成後に結果を.envファイルに自動保存します。
import boto3
import json
import os
from bedrock_agentcore_starter_toolkit.operations.gateway.client import GatewayClient
from dotenv import load_dotenv, set_key
def create_gateway_with_lambda(cognito_config, gateway_role_arn, lambda_arn):
"""
Cognito認証付きGatewayを作成し、Lambda関数をMCPツール化
"""
# Gateway clientの初期化
gateway_client = GatewayClient(region_name="us-west-2")
# 1. Gatewayの作成(Cognito認証設定)
gateway_name = "order-management-gateway"
print(f"🚀 Gateway '{gateway_name}' を作成中...")
try:
authorizer_config = {
"customJWTAuthorizer": {
"discoveryUrl": cognito_config["discovery_url"],
"allowedClients": [cognito_config["client_id"]]
}
}
gateway_response = gateway_client.create_mcp_gateway(
name=gateway_name,
role_arn=gateway_role_arn,
authorizer_config=authorizer_config,
enable_semantic_search=True # セマンティック検索も有効化!
)
# gateway_responseは辞書なので、キーでアクセス
gateway_id = gateway_response['gateway_id'] if 'gateway_id' in gateway_response else gateway_response['gatewayId']
gateway_url = gateway_response['mcp_url'] if 'mcp_url' in gateway_response else gateway_response['mcpUrl']
except Exception as e:
if "already exists" in str(e) or "ConflictException" in str(e):
print(f"ℹ️ Gateway '{gateway_name}' は既に存在します。既存のGatewayを取得中...")
# 既存のGatewayを取得
gateways = gateway_client.list_gateways()
existing_gateway = None
# 名前で検索
for gateway in gateways:
if gateway.get('name') == gateway_name:
existing_gateway = gateway
break
if existing_gateway:
gateway_id = existing_gateway['gateway_id'] if 'gateway_id' in existing_gateway else existing_gateway['gatewayId']
gateway_url = existing_gateway['mcp_url'] if 'mcp_url' in existing_gateway else existing_gateway['mcpUrl']
else:
print("❌ 既存のGatewayが見つかりませんでした")
raise e
else:
raise e
print(f"✅ Gateway作成完了!")
print(f" Gateway ID: {gateway_id}")
print(f" MCP URL: {gateway_url}")
# 2. Lambda関数をターゲットとして登録
print("\n🔧 Lambda関数をMCPツールとして登録中...")
# ツールスキーマの定義
tool_schemas = [
{
"name": "get_order_tool",
"description": "注文情報を取得します",
"inputSchema": {
"type": "object",
"properties": {
"orderId": {
"type": "string",
"description": "注文ID"
}
},
"required": ["orderId"]
}
},
{
"name": "update_order_tool",
"description": "注文情報を更新します",
"inputSchema": {
"type": "object",
"properties": {
"orderId": {
"type": "string",
"description": "注文ID"
}
},
"required": ["orderId"]
}
}
]
# ターゲット設定
target_config = {
"mcp": {
"lambda": {
"lambdaArn": lambda_arn,
"toolSchema": {
"inlinePayload": tool_schemas
}
}
}
}
# 認証情報プロバイダー(Lambda呼び出しにはGatewayのIAMロールを使用)
credential_config = [
{
"credentialProviderType": "GATEWAY_IAM_ROLE"
}
]
bedrock_client = boto3.client('bedrock-agentcore-control', region_name='us-west-2')
target_response = bedrock_client.create_gateway_target(
gatewayIdentifier=gateway_id,
name="order-lambda-target",
description="注文管理Lambda関数",
targetConfiguration=target_config,
credentialProviderConfigurations=credential_config
)
print(f"✅ Lambda MCPツール登録完了!")
print(f" Target ID: {target_response['targetId']}")
# .envファイルに結果を保存
set_key(".env", "GATEWAY_ID", gateway_id)
set_key(".env", "GATEWAY_URL", gateway_url)
print(f"\n✅ Gateway情報を.envファイルに保存しました!")
return {
"gateway_id": gateway_id,
"gateway_url": gateway_url,
"target_id": target_response['targetId']
}
if __name__ == "__main__":
# .envファイルから設定を読み込み
load_dotenv()
# Cognito設定を.envから取得
cognito_config = {
"discovery_url": os.environ.get("COGNITO_DISCOVERY_URL"),
"client_id": os.environ.get("M2M_CLIENT_ID"),
"client_secret": os.environ.get("M2M_CLIENT_SECRET")
}
# IAMロールとLambda ARNも.envから取得
gateway_role_arn = os.environ.get("GATEWAY_ROLE_ARN")
lambda_arn = os.environ.get("LAMBDA_ARN")
# 必須項目のチェック
if not all([cognito_config["discovery_url"], cognito_config["client_id"],
cognito_config["client_secret"], gateway_role_arn, lambda_arn]):
print("❌ .envファイルに必要な設定が不足しています")
print(" 以下の項目を確認してください:")
print(" - COGNITO_DISCOVERY_URL, M2M_CLIENT_ID, M2M_CLIENT_SECRET")
print(" - GATEWAY_ROLE_ARN, LAMBDA_ARN")
exit(1)
gateway_info = create_gateway_with_lambda(cognito_config, gateway_role_arn, lambda_arn)
6. AgentCore Runtimeの実装
Runtime エージェントの実装
次に、AgentCore Identityを使ってGatewayを呼び出すエージェントを実装します。
runtime_agent.pyでは、AgentCore Identityの@requires_access_tokenデコレーターを使用してM2M認証を自動化します。これにより、手動でのトークン取得処理が不要になります。便利ですね。
処理自体はシンプルで注文の照会や更新を担当するエージェントとします。
エージェントで使用するLLMはanthropic.claude-3-5-haiku-20241022-v1:0としていますが、お好みで変更ください。
import os
from strands import Agent
from strands.models import BedrockModel
from strands.tools.mcp import MCPClient
from mcp.client.streamable_http import streamablehttp_client
from bedrock_agentcore.runtime import BedrockAgentCoreApp
from bedrock_agentcore.identity.auth import requires_access_token
from typing import Dict, Any
# エージェントアプリケーションの初期化
app = BedrockAgentCoreApp()
@app.entrypoint
async def order_management_agent(payload: Dict[str, Any]):
"""
注文管理エージェント(AgentCore Identity使用)
"""
print("📋 エージェント起動")
print(f"受信したペイロード: {payload}")
# AgentCore Identityを使用してGatewayにアクセス
gateway_url = os.environ.get("GATEWAY_URL")
provider_name = os.environ.get("IDENTITY_PROVIDER_NAME", "agentcore-identity-for-gateway")
gateway_scope = os.environ.get("GATEWAY_SCOPE") # 例: "agentcore-gateway/read agentcore-gateway/write"
@requires_access_token(
provider_name="resource-provider-oauth-client-zckzu",
scopes=gateway_scope.split() if gateway_scope else [],
auth_flow="M2M",
force_authentication=False,
)
async def process_with_gateway(*, access_token: str) -> str:
"""
Gatewayへのアクセストークンを取得し、MCPクライアントで処理
"""
print(f"✅ アクセストークン取得成功")
# MCPクライアントの作成(AgentCore Identity認証トークン付き)
def create_streamable_http_transport():
return streamablehttp_client(
gateway_url,
headers={"Authorization": f"Bearer {access_token}"}
)
client = MCPClient(create_streamable_http_transport)
print(f"✅ MCP Client初期化完了(AgentCore Identity認証)")
try:
with client:
# ツールリストを取得
tools = client.list_tools_sync()
print(f"🛠️ 利用可能なツール: {[tool.tool_name for tool in tools]}")
# Bedrockモデルとエージェントの初期化
model = BedrockModel(
model_id="anthropic.claude-3-5-haiku-20241022-v1:0",
params={"max_tokens": 4096, "temperature": 0.7},
region="us-west-2"
)
agent = Agent(
model=model,
tools=tools,
system_prompt="あなたは注文管理システムのアシスタントです。注文の照会や更新を手伝います。"
)
print("✅ エージェント初期化完了!")
# ユーザー入力を処理
user_input = payload.get("prompt", "注文IDの123の情報を教えて")
print(f"💬 ユーザー入力: {user_input}")
# エージェントで処理(内部でGatewayのツールを呼び出す)
response = agent(user_input)
result = response.message['content'][0]['text']
print(f"🤖 エージェント応答: {result}")
return result
except Exception as e:
print(f"❌ エージェント処理エラー: {e}")
return f"エラーが発生しました: {str(e)}"
try:
# AgentCore Identityを使用してアクセストークンを取得し、処理を実行
return await process_with_gateway()
except Exception as e:
print(f"❌ 認証エラー: {e}")
return f"認証に失敗しました: {str(e)}"
if __name__ == "__main__":
app.run()
Runtimeのデプロイ
最後に、RuntimeをデプロイするスクリプトPython版です。
deploy_runtime.pyでは、認証なしのRuntimeをデプロイし、.envファイルから読み込んだ設定を環境変数として渡します。
コード全量
from bedrock_agentcore_starter_toolkit import Runtime
import os
from dotenv import load_dotenv, set_key
def deploy_runtime():
"""
認証なしのRuntimeをデプロイ(M2M認証はGateway呼び出し時に実行)
"""
# .envファイルを読み込み
load_dotenv()
print("🚀 AgentCore Runtimeのデプロイを開始...")
# .envファイルから環境変数を取得
env_vars = {
# Gateway接続情報
"GATEWAY_URL": os.environ.get("GATEWAY_URL"),
# Cognito M2M認証情報
"COGNITO_DISCOVERY_URL": os.environ.get("COGNITO_DISCOVERY_URL"),
"M2M_CLIENT_ID": os.environ.get("M2M_CLIENT_ID"),
"M2M_CLIENT_SECRET": os.environ.get("M2M_CLIENT_SECRET"),
"RESOURCE_SERVER_ID": os.environ.get("RESOURCE_SERVER_ID", "agentcore-gateway")
}
# Runtimeの設定(認証なし)
runtime = Runtime()
response = runtime.configure(
entrypoint="runtime_agent.py",
execution_role=os.environ.get("RUNTIME_ROLE_ARN"),
auto_create_ecr=True,
requirements_file="requirements.txt",
region="us-west-2",
agent_name="order_management_runtime",
# 認証設定なし!(Inbound Authなし)
)
print("✅ Runtime設定完了!デプロイ中...")
# デプロイ実行
launch_result = runtime.launch(env_vars=env_vars)
print(f"✅ Runtimeデプロイ完了!")
print(f" Agent ARN: {launch_result.agent_arn}")
print(f" 注意: このRuntimeは認証なしで動作します(開発環境用)")
# Runtime ARNを.envファイルに保存
set_key(".env", "RUNTIME_ARN", launch_result.agent_arn)
print(f"✅ Runtime ARNを.envファイルに保存しました!")
return launch_result
if __name__ == "__main__":
deploy_runtime()
動作確認
実行手順のまとめ
全体の流れを整理すると以下のようになります。
# 初期設定
cp .env.example .env
# Cognito設定(.envファイルを自動更新)
python setup_cognito.py
# → .envファイルにCognito設定が自動保存される
# IAMロール作成(.envファイルを自動更新)
python create_iam_roles.py
# → Gateway用とRuntime用のロールARNが.envファイルに自動保存される
# Lambda関数作成(.envファイルを自動更新)
python create_lambda.py
# → Lambda関数が作成され、ARNが.envファイルに自動保存される
# Gateway作成(.envファイルを自動更新)
python create_gateway.py
# → .envファイルにGateway URLが自動保存される
# OutboundAuth設定(必須ステップ)
python setup_outbound_auth.py
# → .envから自動読み取り、AgentCore IdentityのCredential Provider作成、結果を.envに自動保存
# Runtimeデプロイ(.envファイルから設定を読み込み、Runtime ARNも.envに自動保存)
python deploy_runtime.py
すべての設定は.envファイルで管理して、自動化しています!
動作テスト
動作確認には、Python版のテストスクリプトを使用します。invoke_agentcore.pyでは、.envファイルからRuntimeARNを自動読み取りし、boto3を使って実際のRuntimeを呼び出し、エラーハンドリングやストリーミングレスポンスも適切に処理します。
Runtime呼び出し時に「Workload access token has not been set」エラーが発生して何が起きているのか分からず困惑しました。
調べてみると、runtimeUserIdパラメータの設定が必要だったことが判明し、これはAgentCore Identityでユーザーコンテキストを管理するために必要な設定でした。Inbound AuthでRuntimeにも同一CognitoでJWT認証を使っていれば自動で設定されるのですが、今回は認証なしRuntimeのためパラメータ指定が必要だったみたいです。
今回はRuntimeのInbound AuthにCognitoを設定しなかったので、同一Cognitoを設定するケースも試してみたいですね!
この問題については下記Qiitaで詳しく解説されており、大変参考になりました!
公式ドキュメントにも一部記載があるので、気になる方はご参照ください。
コード全量
"""
Bedrock AgentCore Runtime を呼び出すサンプルスクリプト
"""
import boto3
import json
import os
from dotenv import load_dotenv
def invoke_agent_runtime(prompt, runtime_arn=None, qualifier="DEFAULT", region="us-west-2"):
"""
Bedrock AgentCore Runtime を呼び出す
Args:
prompt: エージェントに送信するプロンプト
runtime_arn: エージェントランタイムのARN(.envから自動読み取り)
qualifier: エンドポイント名(デフォルトは "DEFAULT")
region: AWSリージョン(デフォルトは "us-west-2")
Returns:
エージェントからのレスポンス
"""
# .envファイルからランタイムARNを取得
if runtime_arn is None:
load_dotenv()
runtime_arn = os.environ.get("RUNTIME_ARN")
if not runtime_arn:
raise ValueError("RUNTIME_ARN が.envファイルに設定されていません。deploy_runtime.pyを実行してください。")
# Bedrock AgentCore クライアントを初期化
client = boto3.client('bedrock-agentcore', region_name=region)
# ペイロードを準備(JSON形式でエンコード)
payload = json.dumps({
"prompt": prompt
}).encode('utf-8')
try:
# エージェントランタイムを呼び出し
response = client.invoke_agent_runtime(
agentRuntimeArn=runtime_arn,
qualifier=qualifier,
payload=payload,
contentType='application/json',
accept='application/json',
runtimeUserId="test-user-123"
)
# レスポンスを処理
if response.get('contentType') == 'text/event-stream':
# ストリーミングレスポンスの処理
content = []
for line in response['response'].iter_lines(chunk_size=10):
if line:
line = line.decode('utf-8')
if line.startswith('data: '):
line = line[6:]
print(f"ストリーミング: {line}")
content.append(line)
return '\n'.join(content)
elif response.get('contentType') == 'application/json':
# JSON レスポンスの処理
content = []
for chunk in response.get('response', []):
content.append(chunk.decode('utf-8'))
return json.loads(''.join(content))
else:
# その他のレスポンス形式
return response
except Exception as e:
print(f"エラーが発生しました: {type(e).__name__}: {str(e)}")
# エラーの詳細情報を表示
if hasattr(e, 'response'):
error_code = e.response.get('Error', {}).get('Code', 'Unknown')
error_message = e.response.get('Error', {}).get('Message', 'No message')
print(f"エラーコード: {error_code}")
print(f"エラーメッセージ: {error_message}")
return None
def main():
"""メイン関数"""
# 使用例
print("=== Bedrock AgentCore Runtime 呼び出しサンプル ===\n")
# 1. 基本的な呼び出し
print("1. 基本的な呼び出し:")
response = invoke_agent_runtime("注文ID 123の情報を教えてください エラーが起きた場合はエラーについても丁寧に教えてください。エラーメッセージの原文も添えてね。")
if response:
print(f"レスポンス: {response}\n")
if __name__ == "__main__":
main()
実行方法
# 動作確認スクリプトを実行
python invoke_agentcore.py
成功すると以下のような応答が返ってきます。
注文ID 123の情報は以下の通りです:
- 注文ID: 123
- 状態: 処理中 (processing)
- 商品:
1. 商品A: 2点
2. 商品B: 1点
- 合計金額: 5,000円
回答を見るに問題なくLambda関数をMCPサーバー化してToolとして利用できました!
レスポンスは下記が返ってくるので、LLMがJSONを理解して回答してくれましたね!!
{
"orderId": order_id,
"status": "processing",
"items": [
{"name": "商品A", "quantity": 2},
{"name": "商品B", "quantity": 1}
],
"total": 5000
}
今回のようにLambda関数をMCP Serverにするのは面白いですね。固定文言を今回は返却しましたが、Lambda関数でS3の情報やDynamoDBを参照してLLMに情報として渡すことも可能です!
権限などは要検討ですが、Lambda関数自体は特殊な加工は不要だったので簡単にMCPツール化できて面白いですね。
おわりに
今回はAmazon Bedrock AgentCore RuntimeからGatewayを呼び出し、Lambda関数をMCPツール化する方法を実装してみました!
Lambda関数をMCPツール化にする面白い機能ですよね。
今後はOpenAPI仕様のAPIをMCPツール化したり、ツール呼び出し時に便利な機能であるSemantic Search Toolについても検証していきたいと思います!
本記事が少しでも参考になりましたら幸いです!最後までご覧いただきありがとうございましたー!!









