![[アップデート] Amazon Bedrock の InvokeModel API でもメタデータタグ付けが可能になり、リクエスト単位の使用量追跡ができるようになりました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e3065182082062711612153bbdcf1d96/c04359de689df2f56eb066576ab63fb5/amazon-bedrock?w=3840&fm=webp)
[アップデート] Amazon Bedrock の InvokeModel API でもメタデータタグ付けが可能になり、リクエスト単位の使用量追跡ができるようになりました
いわさです。
Amazon Bedrock ではマルチテナント環境や複数チームでの利用時に、推論コストをテナント・チーム・アプリケーション単位で追跡したいケースがあります。
従来から AWS は以下のようなマルチテナントコスト追跡のガイダンスを公開していました。
- Manage multi-tenant Amazon Bedrock costs using application inference profiles
- Application inference profiles を使ったテナント別コスト配分
- Cost tracking multi-tenant model inference on Amazon Bedrock
— Converse API のrequestMetadataを使ったテナント別ログ分析 - Guidance for a Multi-Tenant, Generative AI Gateway with Cost and Usage Tracking on AWS
- マルチテナント AI ゲートウェイのリファレンスアーキテクチャ
Application inference profiles はテナントごとにプロファイルリソースを作成してタグを付ける方式で、Cost Explorer にネイティブに反映されるメリットがあります。
一方で、テナント数が数千〜数百万規模になるとプロファイルのライフサイクル管理やタグ数の制約が課題になるとのこと。
そこで2つ目のブログでは、Converse API の requestMetadata パラメータを使い、リクエスト単位でテナント情報を付与して Invocation Logs から分析するアプローチが紹介されていました。
ただし、この requestMetadata は Converse / ConverseStream API でのみ利用可能で、InvokeModel / InvokeModelWithResponseStream API では同等の機能がありませんでした。
そのため、Converse API はテキスト生成のチャット系ワークロードをカバーしますが、画像生成(Stable Diffusion、Titan Image Generator)や Embeddings(Titan Embeddings、Cohere Embed)など InvokeModel でしか呼べないワークロードではメタデータ付与ができない状態でした。
これが先日のアップデートで、InvokeModel および InvokeModelWithResponseStream API でも X-Amzn-Bedrock-Request-Metadata HTTP ヘッダーを使ってリクエスト単位のメタデータタグ付けが可能になりました。
これにより bedrock-runtime エンドポイントの全推論 API(InvokeModel / InvokeModelWithResponseStream / Converse / ConverseStream)で統一的にリクエスト単位のメタデータを付与できるようになっています。
これで例えば、マルチテナント SaaS で RAG パイプラインの Embeddings 呼び出しをテナント別に追跡したい、といったケースでもメタデータを使った管理ができるようになります。
今回こちらを確認してみたので紹介します。
リクエストにメタデータを付与してみる
では実際に InvokeModel API にメタデータを付与してみます。
AWS CLI v2 では --request-metadata オプションが追加されており、JSON 形式で任意の key-value ペアを渡すことが出来ます。
今回は試しに team, environment, experiment の3つのメタデータを付与して InvokeModel を呼び出してみました。
aws bedrock-runtime invoke-model \
--request-metadata '{"team":"hoge","environment":"dev","experiment":"fuga"}' \
--model-id jp.anthropic.claude-haiku-4-5-20251001-v1:0 \
--content-type application/json \
--accept application/json \
--body fileb://<(echo '{"anthropic_version":"bedrock-2023-05-31","max_tokens":50,"messages":[{"role":"user","content":"Say hello in one word."}]}') \
--region ap-northeast-1 \
/tmp/response.json
正常にレスポンスが返ってきました。
{
"model": "claude-haiku-4-5-20251001",
"id": "msg_bdrk_01KP9C7v9NcCYmNk21TB8wnM",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "Hello!"
}
],
"stop_reason": "end_turn",
"stop_sequence": null,
"usage": {
"input_tokens": 13,
"output_tokens": 5
}
}
事前にリソースを作成する必要はなく、呼び出しごとに異なるタグを付けられるのがポイントですね。
なお、公式ドキュメントによるとメタデータには以下の制限があるみたいです。
Maximum 16 metadata entries per request.
Keys: maximum 256 characters.
Values: maximum 256 characters.
Allowed characters: a restricted set of alphanumeric and punctuation characters.
1リクエストあたり最大16エントリ、キー・値ともに最大256文字、使用可能な文字は英数字と一部の記号に制限されているとのこと。
ログからメタデータを確認・分析してみる
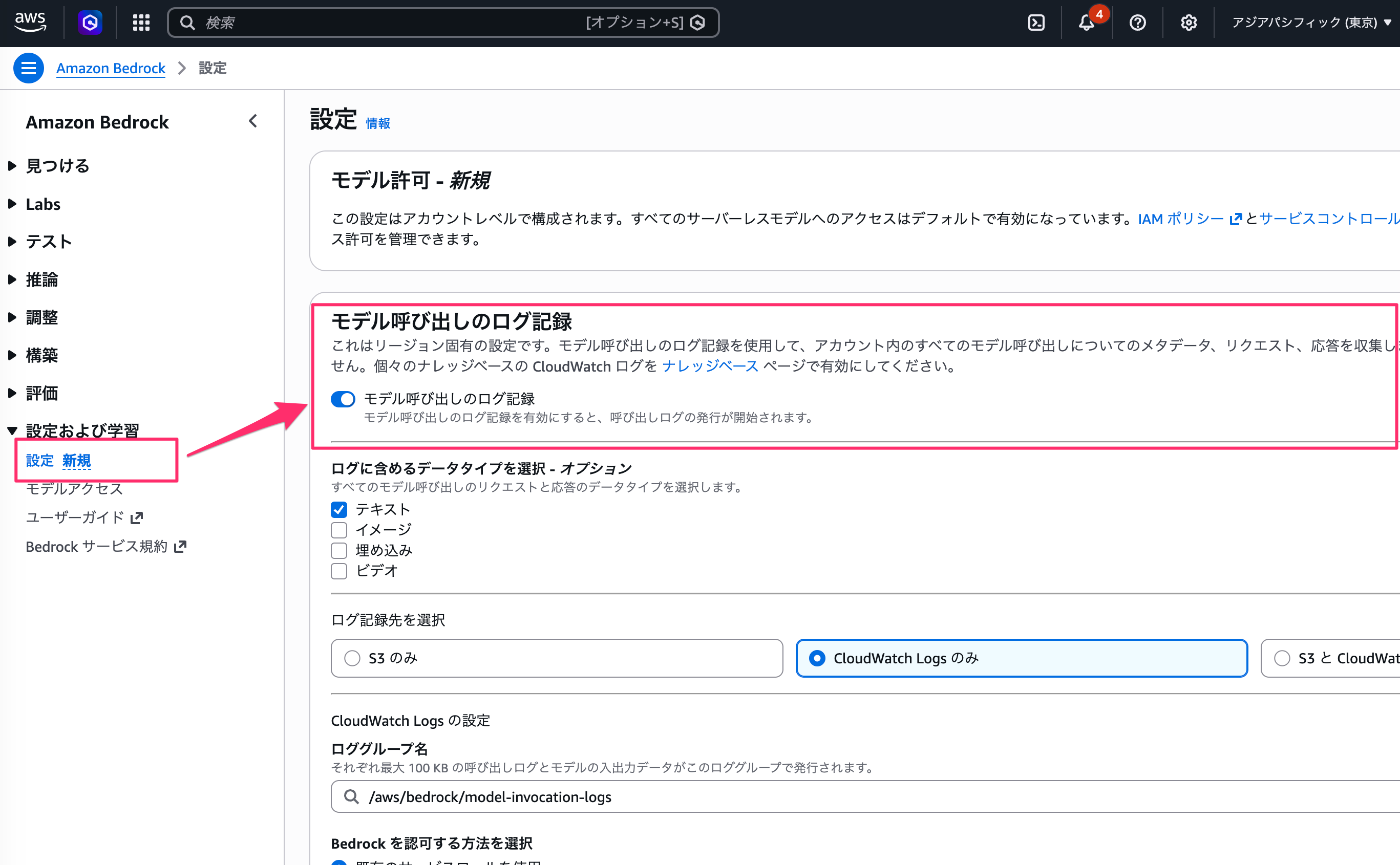
リクエストメタデータはモデル呼び出しのログに記録されます。
Converse API と同様で、事前に Bedrock のモデル呼び出しのログ記録を有効にしておく必要があります。
今回は CloudWatch Logs への配信を設定しました。
なお、公式ドキュメントによると、ログが有効でない場合もリクエスト自体は成功するが、メタデータは保持されないとのことです。
Request metadata values are recorded only when model invocation logging is enabled in the call's AWS Region. If logging is not configured, the request still succeeds but the metadata is not retained.
ログ有効化後にメタデータ付きリクエストを実行すると、CloudWatch Logs にログが記録されます。
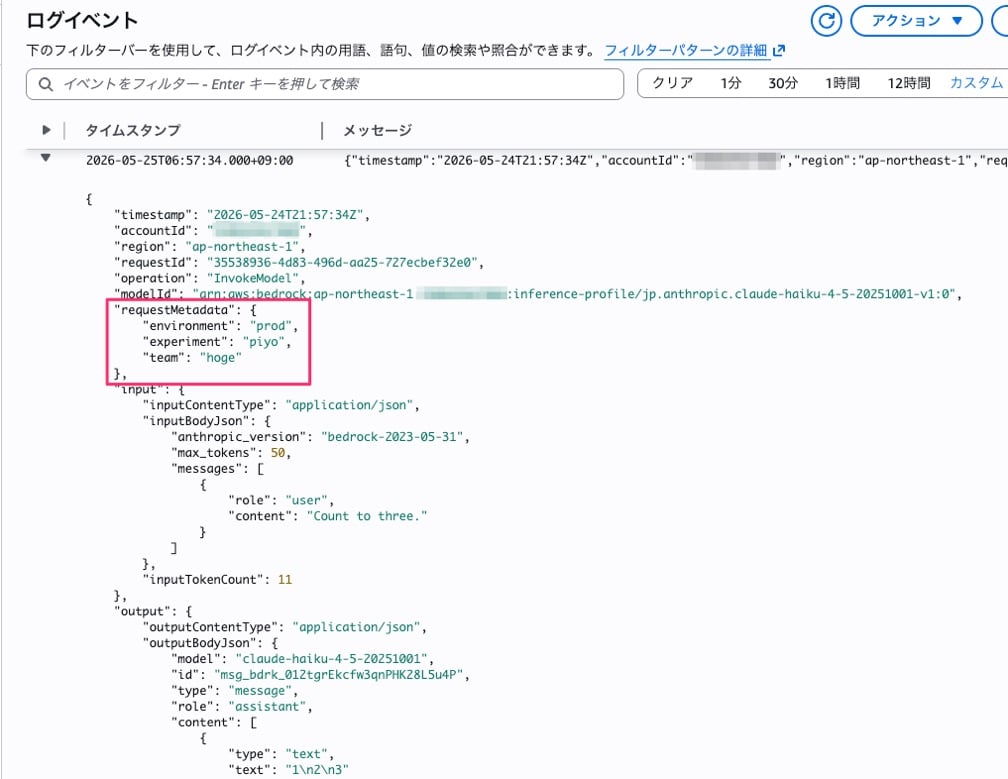
ログエントリの JSON を確認すると、requestMetadata フィールドとしてリクエスト時に付与したメタデータがそのまま記録されていることがわかります。
{
"timestamp": "2026-05-24T21:57:14Z",
"accountId": "123456789012",
"region": "ap-northeast-1",
"requestId": "96afa848-e921-4e2d-b232-3dfd84c2e0d5",
"operation": "InvokeModel",
"modelId": "arn:aws:bedrock:ap-northeast-1:123456789012:inference-profile/jp.anthropic.claude-haiku-4-5-20251001-v1:0",
"requestMetadata": {
"environment": "dev",
"experiment": "fuga",
"team": "hoge"
},
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 50,
"messages": [{"role": "user", "content": "Say hello in one word."}]
},
"inputTokenCount": 13
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": {
"model": "claude-haiku-4-5-20251001",
"content": [{"type": "text", "text": "Hello!"}],
"usage": {"input_tokens": 13, "output_tokens": 5}
},
"outputTokenCount": 5
},
"identity": {"arn": "arn:aws:iam::123456789012:user/hoge"},
"schemaType": "ModelInvocationLog",
"schemaVersion": "1.0"
}
requestMetadata に team, environment, experiment がそのまま記録されていることが確認できます。
また input.inputTokenCount と output.outputTokenCount も記録されているので、これを使ってトークン使用量の集計が可能です。
CloudWatch Logs Insights を使えば、メタデータのフィールドでフィルタリングや集計ができます。
検証として、team=hoge で2回、team=piyo で1回リクエストを送った状態で集計クエリを実行してみました。
stats count(*) as requestCount,
sum(input.inputTokenCount) as totalInputTokens,
sum(output.outputTokenCount) as totalOutputTokens
by requestMetadata.team
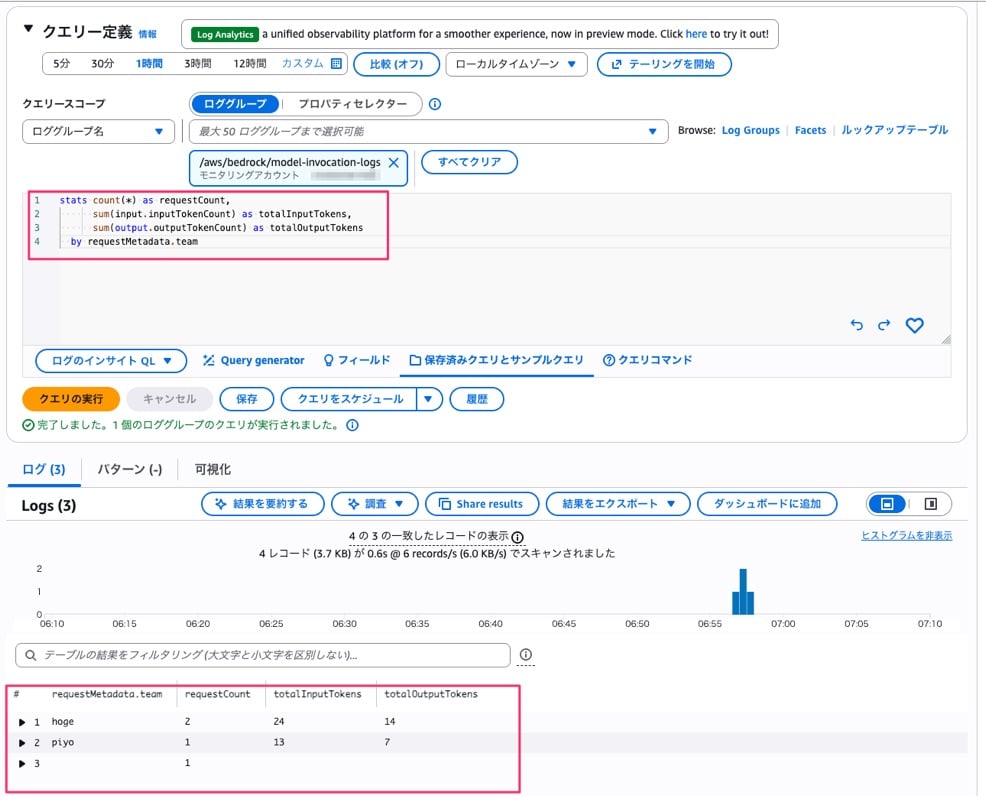
チームごとのリクエスト数とトークン使用量が集計できていることがわかります。
ここにトークン単価を掛ければテナント別のコスト算出が可能ですね。
なお、リクエストメタデータは Cost Explorer や CUR には反映されません。
テナント数が少なく Cost Explorer でサクッと見たい場合は Application inference profiles を使い、テナント数が多い場合やリクエスト単位の柔軟な追跡が必要な場合はリクエストメタデータ + ログ分析、という棲み分けになりそうです。
さいごに
本日は Amazon Bedrock の InvokeModel / InvokeModelWithResponseStream API でリクエスト単位のメタデータタグ付けが可能になったので確認してみました。
Converse API では以前から使えていた requestMetadata が InvokeModel 系にも拡張された形で、bedrock-runtime エンドポイント全体で統一的にリクエスト単位の追跡ができるようになっています。
AWS CLI v2 でも --request-metadata オプションとして対応済みで、手軽に試せます。
事前にプロファイルやプロジェクトを作る必要がなく、呼び出しごとに自由にタグを付けられるのは良いですね。









