
Amazon ECRはタグの付け替え時にプッシュ日時を更新しないためライフサイクルの対象に注意しよう
初めに
先日Docker Registry HTTP API V2を利用してイメージタグをリモート上から取得する方法を紹介させていただきました。
今回の最終的な目的としてはこれを発展し「マイナー以降の指定を持つイメージ」を指定したイメージを数世代+「メジャーバージョンのみのタグ(該当メジャーの最新バージョン)を持つイメージ」をECR上に持たせることを目的としていました。
タグを取得する方法さえわかればそこまで手間ではない...と思ったのですがライフサイクルポリシーを利用したバージョン管理、実行基盤となるGithub Actionsの仕様等々の噛み合いで手間取ったので備忘録として残しておきます。
最終的なECR上の状態
本記事執筆時点でOracle Container Registry(以降OCR)で管理されているJDKの最新2世代は「21.0.6」および「21.0.7(=21)」となります。
これを複製するように処理を組み込み(後述)、ECR上の実態としては最終的には以下のように2イメージ、新しい方にメジャーバージョンのみのタグがつくようになります。
またメジャーバージョンタグは常に最新マイナーに付け直したいためミュータブルにしています。

また、自前で古いイメージの失効処理を組み込むのは管理が煩雑になるためライフサイクルポリシーを利用してマイナー以降の指定があるタグを最新数世代のみ保持するように設定しています。

ライフサイクルの対象はプッシュ日時の古い順に
https://docs.aws.amazon.com/ja_jp/AmazonECR/latest/userguide/LifecyclePolicies.html
期限切れは常に pushed_at_time の順に並べられ、より古いイメージが新しいものよりも先に期限切れとなります。
Amazon ECRのライフサイクルでの世代管理は「プッシュされた日時」に基づき、古い順に削除されます。
そのため通常最新世代のみを定期的にPushするのであれば特に問題ないのですが、冪等性確保・更新頻度の関係で複数イメージを同時期にプッシュする場合その順序が重要になってきます。
タグの更新ではプッシュ日時は更新されない
同一ダイジェストのイメージがすでにECR上に存在する状態で別のタグをつけてdocker pushをする場合、イメージに対してタグの付け替え・付与は発生しますがプッシュ日時(imagePushedAt)は更新されない形となるようです(実際の動作を確認する限り)。
そのため、プログラム等で処理する場合対象のタグを1配列に昇順でソートすると、文字列の形式上マイナー指定のないものが先頭に来るため単純に処理すると以下のようになってしまう形となります。
| プッシュ順序 | タグ | イメージID | 実際プッシュ日時 | ECR上でのプッシュ日時扱い |
|---|---|---|---|---|
| 1 | 21 | sha256:AAAAA | 2025-06-05 00:00:00 | 2025-06-05T00:00:00 |
| 2 | 21.0.6 | sha256:BBBBB | 2025-06-05 00:10:00 | 2025-06-05T00:10:00 |
| 3 | 21.0.7 | sha256:AAAAA | 2025-06-05 00:20:00 | 2025-06-05T00:00:00 |
この場合、21.0.7が後にプッシュ処理されてはいますが、ECR上でのプッシュ日時としては更新されず21.0.6より古くなってしまいます。
つまり21.0.8がリリースされるなど後続のバージョンが追加されてしまうと、ライフサイクルの処理では21.0.6ではなく21.0.7が削除されます。
ケースにより対応方針は変わるかと思いますが、今回の場合は先にマイナー・パッチバージョン付きのイメージを全て処理させた後にメジャーバージョンタグを付与する形で回避しました。
一応念の為describe-imagesをしてみるとわかりますが同じダイジェストに複数のタグがついている場合は、API上も同一イメージ扱いであくまでそれに対して複数のタグがついている扱いであることが確認できます。
{
"imageDetails": [
{
"registryId": "xxxxxx",
"repositoryName": "oracle-jdk",
"imageDigest": "sha256:xxxxxx",
"imageTags": [
"21.0.7",
"21"
],
"imageSizeInBytes": 320148354,
"imagePushedAt": "2025-06-05T16:31:23.953000+09:00",
"imageManifestMediaType": "application/vnd.docker.distribution.manifest.v2+json",
"artifactMediaType": "application/vnd.docker.container.image.v1+json",
"lastRecordedPullTime": "2025-06-05T16:31:30.238000+09:00"
}
]
Github Actionsのrunに書いた処理の一部抜粋になりますが大体こんな感じになります。
複数メジャーバージョンを持っても処理できるようにループさせてますが、またがない場合はもうちょっとシンプルになります。
run: >
result="[]";
versions=$(echo ${{ env.JDK_MAJOR_VERSION}} | jq -r '.[]');
for version in $versions; do
## バージョン比較は文字列で行うと問題のあるケースがあるのでsort_by()で数値に変換した上で比較
res=$(echo '${{ steps.get-full-jdk-tags.outputs.full-tags }}' | jq --arg version "$version" '
[.Tags[] | select(test("^" + $version + "\\.[0-9]+\\.[0-9]+$"))]
| sort_by(split(".") | map(if test("^[0-9]+$") then tonumber else 0 end))
## uniqueは処理上ソート処理が挟まるので実行タイミングに注意
| unique | [ .[-'"${{ env.VERSION_LENGTH }}"':], $version ] | flatten'
);
echo "$version => $res";
result=$(echo "$result $res" | jq -s 'add');
done;
echo tags=$result >> $GITHUB_OUTPUT;
tags=["21.0.6","21.0.7","21","24.0.1","24"]のような形が出力期待値となります。
当初はmatrixで並列処理させて後続ジョブでマージさせようと考えていましたが、現時点では並行して走ったジョブのうち最後の値でoutputsが上書きされてしまう仕様があるようで、この辺りか見合いや取り回しが悪かったため1ステップで結合までまとめてやっています。
Github Actionsのmatrixは実行順序と配列順序はイコールではない
Github Actionsではmatrixを使うことで配列の値をベースにジョブを並行実行することができます。
また、利用する処理で呼び出すAPI処理のレート制限の関係で実行数を落としたい場合max-parallelを利用することで同時実行数に制限をかけることが可能です。
そのため直列処理をしたいがシェルの処理を書き込みたくない...という場合max-parallel=1とすることでジョブ単位で直列にforEachのような形で処理することが可能です。
ただし、配列のどの要素が処理されるかはユーザ側で決定されるものではなくGithub側で決定されるようです。
先のようにメジャーバージョンを指定するものを後に配列にしているものの
実際の実行順としてはメジャーバージョンのみ指定が先に来ています。
ただ何度実行してもこの順番で実行されるため昇順?か何か一定の条件でソートされてそうです。
次ジョブのmatrixに渡す値は以下の通りになっていますが

実際に実行すると以下のように21が表記的に先に来ており、実際にこの表記通り上から順に実行されました。
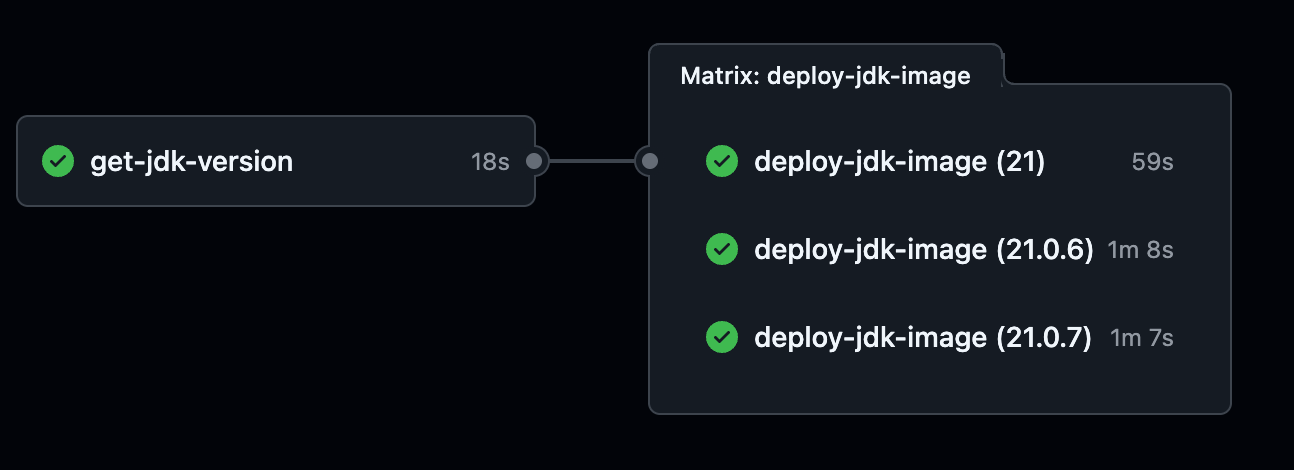
これに対するアプローチとしては以下2つが思いつきましたが今回は後者を採用しました。
- GIthub側の意図する処理順になる範囲、もしくは純不動の範囲で配列を分割
- ジョブ全体でループかけたい場合はシンプル
- 値が動的な場合予期せぬ順序になる可能性あり
- 地道に特定のステップでループ処理させる(今回はこちら)
- シェル上の処理になりユーザ側でコントロールできるので細かなコントロールが可能
- ステップ内でループを回すのでジョブ全体をループさせたい場合は困難
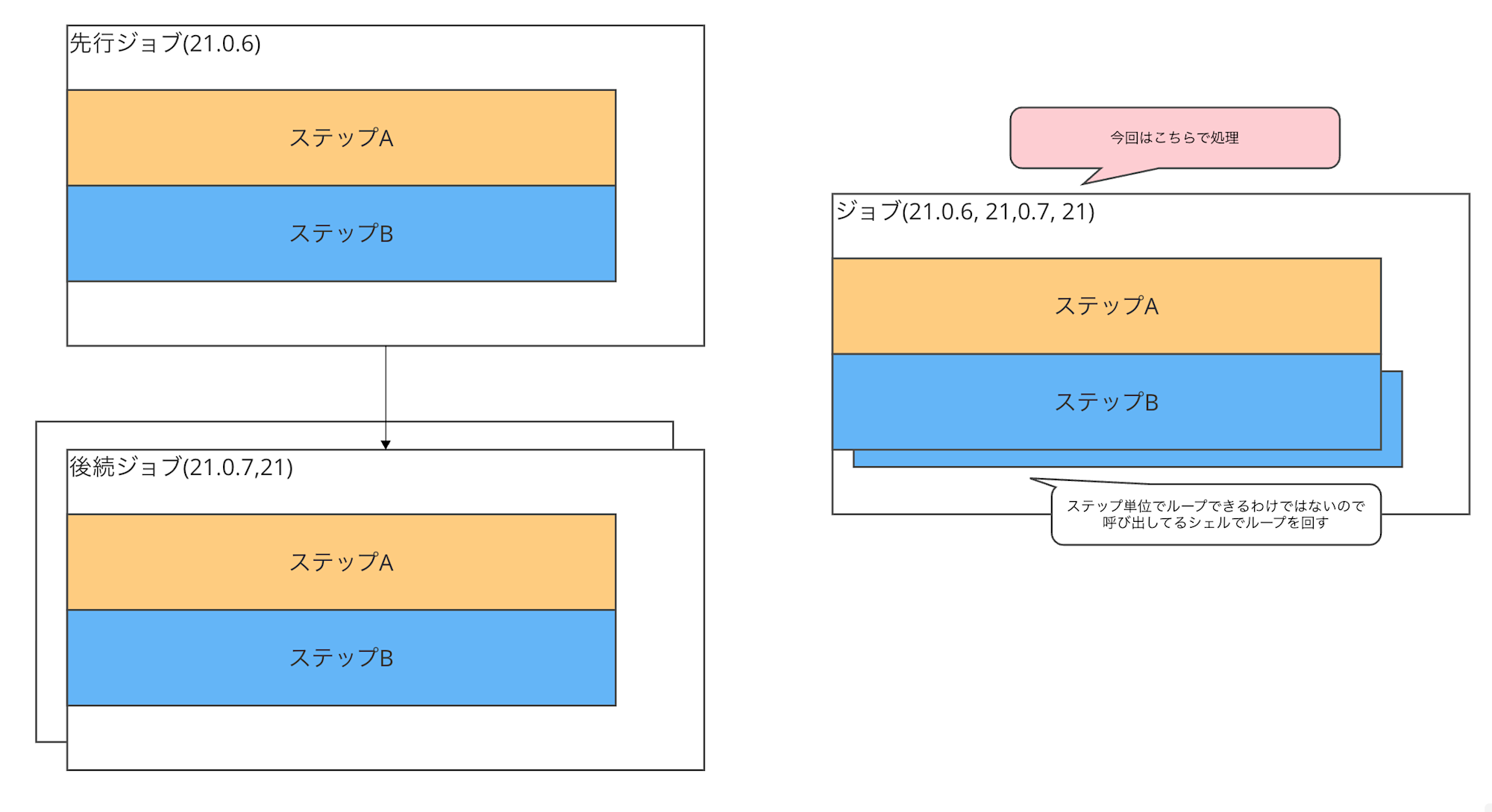
ジョブ定義自体を動的に定義することはできませんが静的に可能な範囲でうまく配列を分割すれば全体の処理時間を圧縮できますので、うまく並行実行できるところ、順序保証が必要な場所等々を考慮し適宜分解していきましょう。
終わりに
複数イメージをプッシュする場合、特に同一ダイジェストが含まれタグ更新が行われる場合のライフサイクルで少しハマりそうな部分があったので備忘録として残してみました。
イメージが同一であればタグの付け替えのみになるので冷静に考えてみればそれはそうかの一方、タグの変更を許さないようにイミュータブルな運用にしてると意外とみることがなく抜けがちな部分ではないでしょうか。
(AWSの推奨としても起動バージョンを明確にするためにイミュータブル推奨)
そのため気をつけるのケースというのはある程度限定されてはくるものの、アプリケーションではなくその基盤のイメージの管理となると、環境によっては特定のバージョンを使いたいという要望はありつつ最新のものを採用したいという場合にはミュータブルにした上でメジャーバージョンタグを最新に追従させるということはあるかと思います。
そういった場合は今回のように順序を意識する必要が出てきますので注意しましょう。







