![[レポート] Amazon Nova 2 Omni: A new frontier in multimodal AI に参加してきました! #AIM3324 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート] Amazon Nova 2 Omni: A new frontier in multimodal AI に参加してきました! #AIM3324 #AWSreInvent
こんにちは!運用イノベーション部の大野です。
re:Invent 2025 の「Amazon Nova 2 Omni: A new frontier in multimodal AI」(AIM3324) に参加してきました。

セッション概要
セッションタイトル
[NEW LAUNCH] Amazon Nova 2 Omni: A new frontier in multimodal AI (AIM3324)
説明
Amazon Nova 2 Omniは、エンタープライズアプリケーション専用に設計された、最も先進的で統合されたマルチモーダル基盤モデルです。テキスト、画像、動画、音声の入力を処理すると同時に、テキストと画像の両方をネイティブに生成する、業界初の推論モデルでもあります。
クリエイティブなワークフロー、カスタマーエクスペリエンス、あるいは企業の生産性向上にご興味がある方ならどなたでも、このセッションを通じて、Nova 2 Omniの統合されたマルチモーダルアーキテクチャが、いかにして皆様の組織におけるイノベーションを推進できるかをご覧いただけます。
スピーカー
- Rohit Mittal - Product Manager, Amazon
- Ashwin Swaminathan - Director, Applied Science, Amazon
- 山本 覚 - CAIO & Executive Officer, Dentsu Digital Inc.
セッションカテゴリ
- Type: Breakout session
- Level: 300 – Advanced
- Features: Lecture-style
- Topic: Artificial Intelligence, Business Applications
- Area of Interest: Generative AI
- Industry: Advertising & Marketing, Media & Entertainment, Software & Internet
- Role: Developer / Engineer, IT Professional / Technical Manager
- Services: Amazon Bedrock, Amazon Nova

サマリ
本セッションでは、AWS re:Invent 2025で発表されたAmazon Nova 2モデルファミリーの中でも特に注目される「Nova 2 Omni」について、その技術的特徴、ベンチマーク性能、そして電通デジタルによる実際の活用事例が紹介されました。
主なポイント
- 統合マルチモーダル推論モデル:テキスト、画像、動画、音声を理解し、テキストと画像を生成できる、Amazon Bedrock上で唯一のモデル
- 卓越したベンチマーク性能:MMAUリーダーボードで第2位、画像編集でFluxを上回りGPT-4oと同等の性能
- 開発効率の劇的向上:電通デジタルでは7日間で7つのアプリケーションを開発
Amazon Novaファミリーの振り返り

セッション冒頭で、昨年のre:Invent 2024で発表されたAmazon Novaファミリーの振り返りがありました。
昨年発表されたモデル
理解モデル(Understanding Models)
- Nova Micro / Lite / Pro - テキスト、画像、動画を入力としてテキストを生成
- Nova Premier - 最大・最高性能の理解モデル(後から追加)
生成モデル(Generation Models)
- Nova Canvas - 画像生成モデル
- Nova Reel - 動画生成モデル
その他
- Nova Sonic - リアルタイム会話AI向けのspeech-to-speechモデル
- Nova Multimodal Embedding - 業界初のネイティブマルチモーダル埋め込みモデル(先月発表)
Amazon Nova 2ファミリーの発表


| モデル | 主な用途 | 特徴 |
|---|---|---|
| Nova 2 Lite | 日常的なワークロード向けの高速・低コスト推論 | 初のハイブリッド推論モデル。開発者が推論の有効/無効とレベルを制御可能 |
| Nova 2 Pro | 高度な推論・複雑なエージェントタスク | コーディング、複雑なエージェント、マルチエージェントシナリオ向け(プレビュー) |
| Nova 2 Omni | 統合マルチモーダル理解・生成 | 音声を含むあらゆるモダリティを理解し、テキストと画像を生成(プレビュー) |
| Nova 2 Sonic | 音声会話AI | 初代より性能向上、対応言語増加、より自然な会話 |
共通仕様
- コンテキストウィンドウ: 最大100万入力トークン
- テキスト対応言語: 200以上
- 音声入力対応言語: 10言語(Pro、Omniのみ)
Nova 2 Omniの技術的特徴
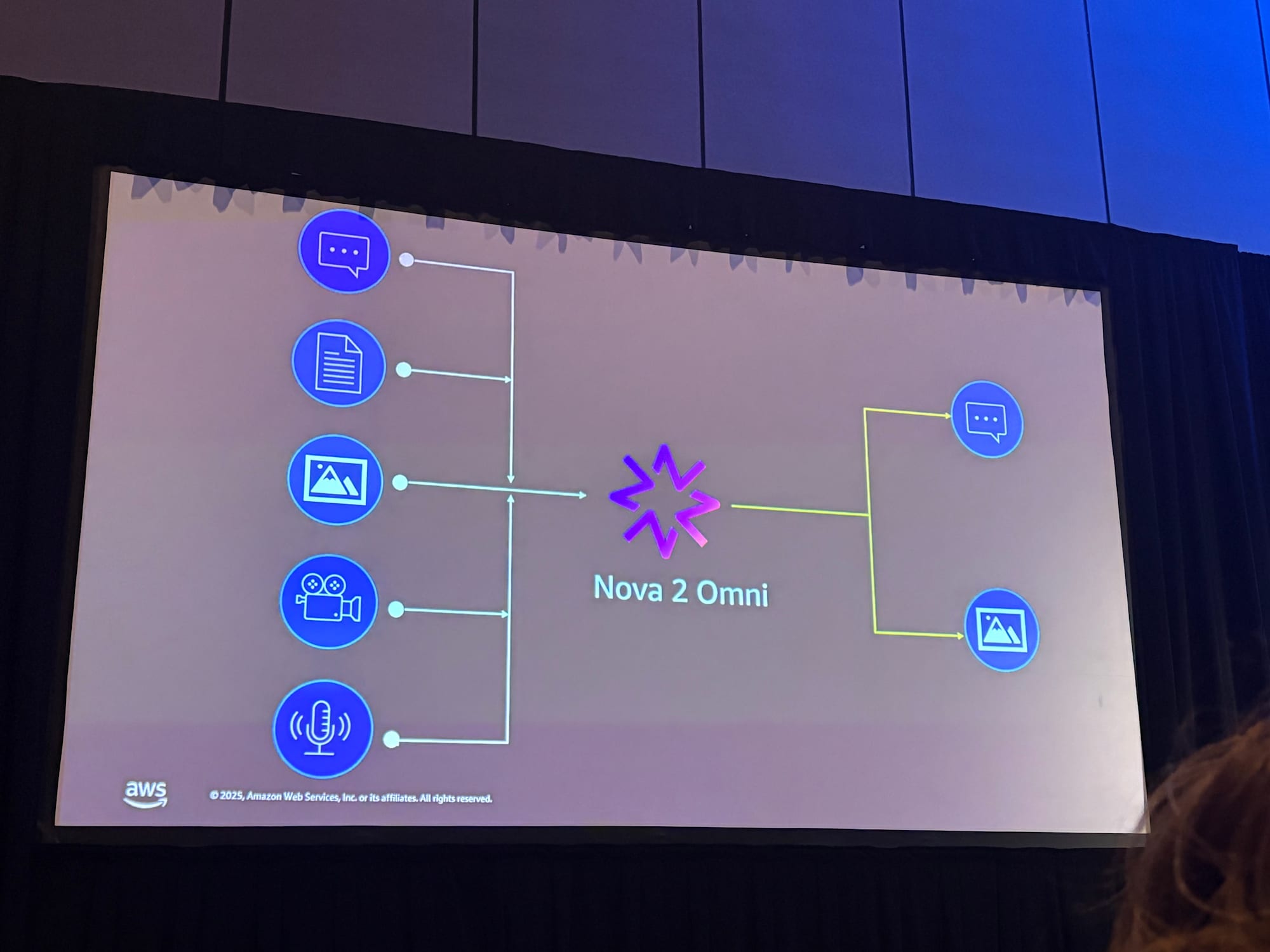

統合モデルの優位性
Nova 2 Omniの設計思想について次のような説明がありました。
「将来のモデルは完全にマルチモーダルになると考えています。それは人間のインタラクションと同じです—話し言葉、視覚、そして書き言葉。このモデルは、Amazon Bedrock上で初めて音声を含むあらゆるモダリティを理解しながら、同じモデル内で高品質な画像も生成できます。」
主な強み
- instruction following(指示追従)、tool calling(ツール呼び出し) に優れる
- ドキュメント理解、画像理解、動画理解、音声理解で最先端の性能
- クロスモーダル推論(cross-modal reasoning)という新機能
- 複数の専門モデルを組み合わせるより高品質な出力
- 複雑なパイプライン構築が不要で、開発・保守コスト削減と市場投入時間短縮を実現
ベンチマーク性能
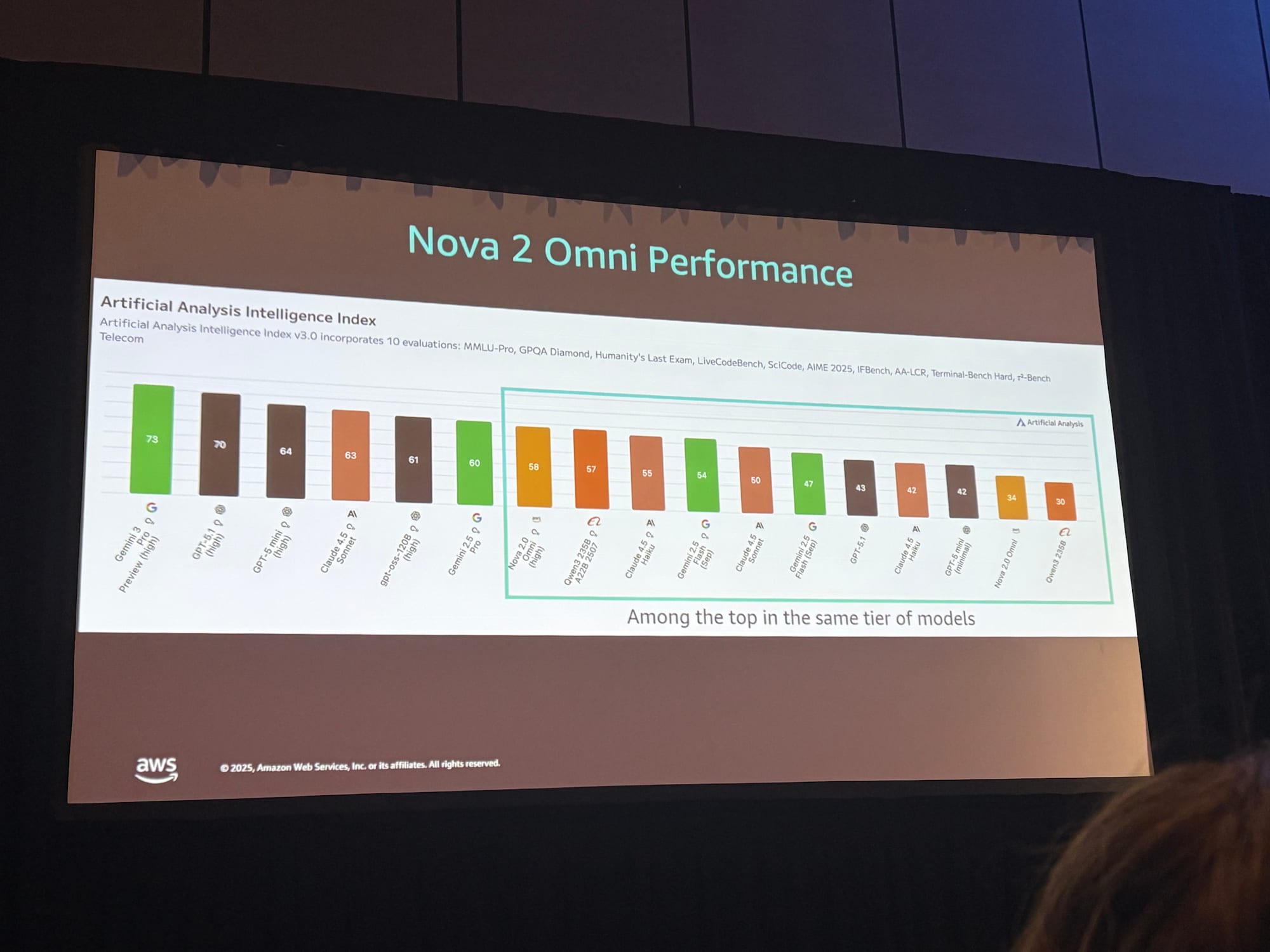
Artificial Analysisに基づくベンチマーク結果が紹介されました。
- Gemini 2.5 Flash、GPT-4o miniと同等クラスで非常に競争力のある位置にランクイン
- knowledge reasoning、instruction following、tool callingで高いスコア
主要なユースケース
ドキュメント理解

顧客から最も多く寄せられるユースケースがドキュメント理解です。
主な機能
- 前世代と比較して大幅に高い精度
- OCR文字認識とキー情報抽出の改善
- 組み込みツールによる検証機能
- 構造化出力(JSON/XML形式)
- 矛盾の検出


音声理解

Nova 2 ProとNova 2 Omniは、Amazon Bedrockで初めて音声理解をサポートするモデルです。
主な機能
- 音声の文字起こし(Speech Transcription)
- 最大3人の話者分離(Multi-speaker Diarization)
- 音声内容の要約と質問応答
- ツール呼び出し
ベンチマーク性能
- MMAU(Massive Multitask Audio Understanding)リーダーボードで総合第2位
セッションでは、Andy JassyのQ3決算発表の音声スニペットを使ったデモが行われ、文字起こし精度、キーポイント抽出、要約機能が実演されました。
画像・動画理解

画像・動画理解のユースケースが3つのカテゴリに分けて説明されました。
1. 知覚とオブジェクト検出(Perception and Object Detection)
- シーン内のオブジェクトに対するバウンディングボックスの生成
- 非常にタイトで正確なバウンディングボックスを生成
2. 質問応答(Q&A)
- シーンで何が起きているかを理解して回答
- 例:リレー競技の画像で、3チーム(イギリス、スイス、ベルギー)を識別し、バトンの位置、誰がバトンを渡したか、誰が1位かを特定
3. 時間的理解(Temporal Understanding)
- 動画内の特定イベントがいつ発生したかを把握
- 例:「ボートの上に立っている男性」を探すプロンプトに対し、10〜14秒のタイムスタンプを特定し、歩いているがボート上にいない部分は正しく除外



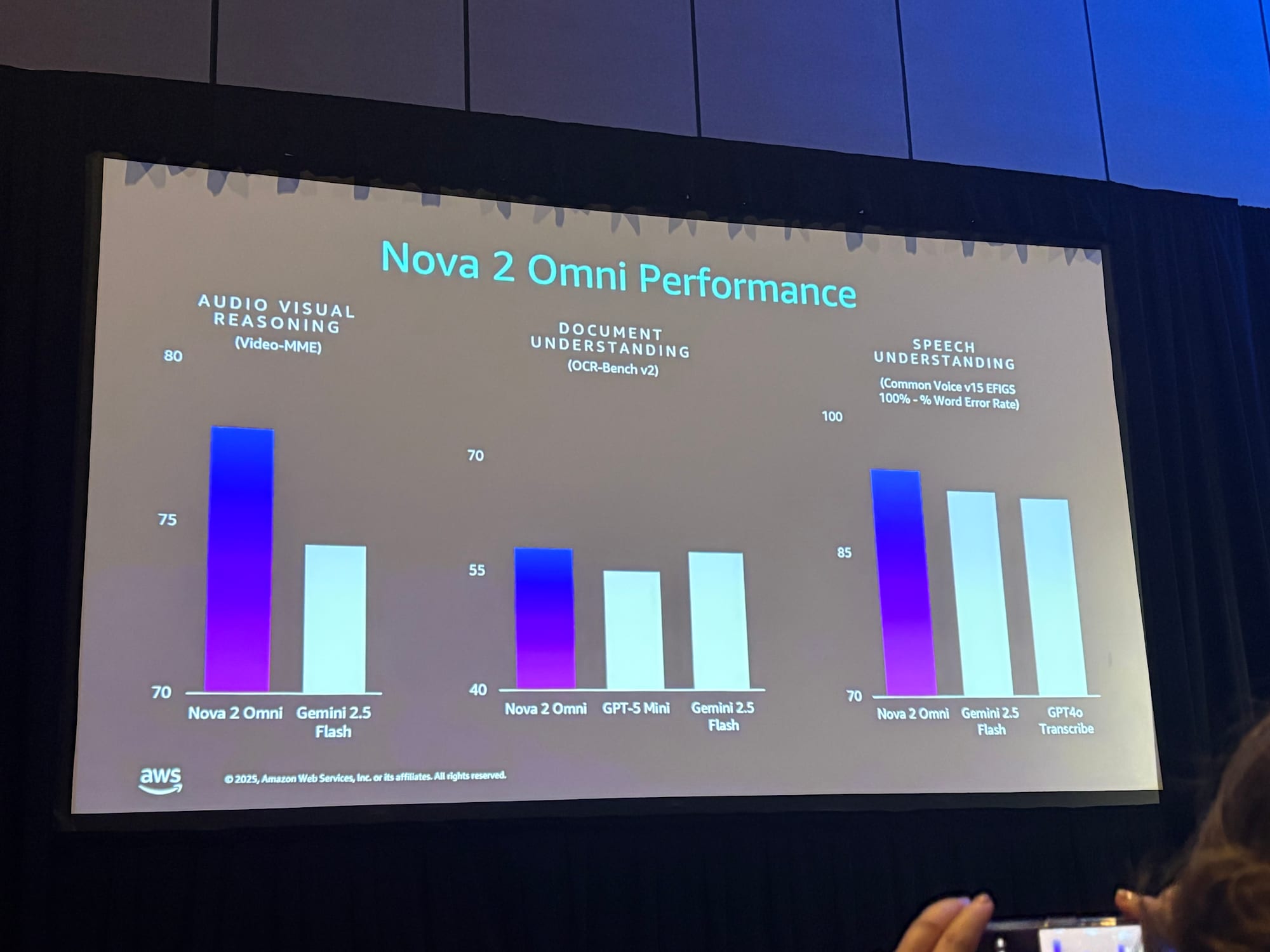
ベンチマーク性能
- Video-MMEベンチマーク(動画+音声のクロスモーダル理解)で同カテゴリのモデルを大幅に上回る
- OCR Benchで最先端を超える性能
- CMUと共同開発したMavericksベンチマーク(実際の顧客ユースケースに基づく)でトップクラス
画像生成・編集

Nova 2 Omniの画像生成・編集機能について説明がありました。
優れた理解バックボーンを持っているため、それを活用してより高品質な画像生成とより高品質な編集タスクを実現できます。
最適化ポイント
- ビジュアルテキストレンダリングを大幅に改善
- テキストLLMによるバッキングで、画像内の長文テキストも高品質にレンダリング
ベンチマーク性能(ブラインドA/Bテスト)
- Nova Canvas比で大幅改善(ステップファンクション的な向上)
- Fluxモデルを上回る
- GPT-4o、Geminiと同等

複雑な生成の例
「パリの街で、歩行者が全員カメラを見ている画像」というプロンプトに対し、ほとんどのモデルが失敗する中、Nova 2 Omniは約90%の人がカメラを見ているシーンを生成。
画像編集機能

Nova 2 Omniは、テキストプロンプトのみで9種類の編集操作をサポートします。
| 操作 | 説明 | 例 |
|---|---|---|
| Add | オブジェクト追加 | 木製ベンチをシーンのスタイルに合わせて追加 |
| Add Text | テキスト追加 | ドア番号を追加 |
| Color Change | 色変更 | 自転車を赤に変更、フロスティングの色を変更 |
| Alter Scene | シーン変更 | 雪景色から砂浜の背景へ |
| Replace | 置換 | 髪型を変えずに帽子だけ変更 |
| Remove | 削除 | シロクマを削除、携帯電話を削除しながらセーターの色も変更(複合プロンプト) |
| Style/Motion | スタイル/動き変更 | 表情やスタイルの変更 |

Image Editベンチマークでの評価結果
- Fluxモデルを上回る
- GPT-4、Geminiと同等
電通デジタルによる活用事例
電通デジタルのCAIO(Chief AI Officer)である山本覚氏より、Amazon Nova(特にNova Omni)を活用した「Mugen AI」ソリューションの事例が紹介されました。
1. 広告クリエイティブ制作(Visionary Ad)
AIを活用したクリエイティブ生成とパフォーマンス予測のソリューションです。
従来の課題
動画のパフォーマンス予測は、動画をキーフレームとテキストに分離する必要があり、精度が落ちていました。
Nova Omniによる解決
Nova Omniは真のマルチモーダルAIであり、人間と同じように動画そのものを理解できます。その結果、高精度な予測が可能になりました。
デモ: ANA(全日本空輸)の事例
- 動画をアップロードしてキャンペーンを選択
- モデルがパフォーマンスを予測
- 予測値と実際の配信値の相関係数は0.88を達成
ストーリーボード生成
- テキストからストーリーボードと動画を生成
- 自然言語での画像編集が容易
- 日本語文字を非常に正確かつ美しく生成できることに驚き
動画編集
- 既存の動画素材を再利用
- Nova Omniが生素材を分析しメタデータを生成
- クリエイティブディレクターとしてバイラル戦略を策定
- 効率的に最終動画編集を作成
2. 計画・運用(Mugen AI Agent Canvas)
非エンジニアでもエージェントを構築できるソリューションです。
Nova OmniとNova Actの連携デモ
- 人間がAmazon Ads UIを操作する様子を動画で記録
- この動画をNova Omniに入力
- Nova Omniがワークフローを理解
- Nova Act(ブラウザ操作AI)用のプロンプトを自動生成
- Nova Actがブラウザを操作し、人の手を介さずにプロセスを完全自動化
マルチエージェント協調
Bedrock Agentsを活用し、「Shining Sparkling Water」という製品に対して
- ペルソナへのインタビュー
- キーメッセージの要約
- カスタマージャーニーの準備
- デジタルビジュアルの計画
複数のエージェントが協調して作業を実行。
3. 次世代エクスペリエンス
Miji Chat(クライアント向けチャットボット)
Nova Omniを活用してより豊かな体験を提供。
- ゴルフの例:ユーザーが英語で話し、その後日本語で入力。AIは言語切り替えを処理し、ゴルフスイング動画を分析してアドバイスを提供
店舗内体験
- 店舗内での顧客視点の動画を分析
- 行動に基づいてペルソナ(例:「スタイルを意識したオフィスワーカー」)を抽出
- このペルソナを使ってECデジタルストアでの行動を予測

開発効率の劇的改善

セッションの最後の最後に以下の内容で締め括られました。
ショッキングなニュースがあります。このプレゼンテーションについて知らされたのは先週の火曜日—準備期間はわずか7日間でした。しかし、私たちは7つのアプリケーションを紹介しました。1日1アプリケーションです。この急速な開発は、1人の開発者だけで行われました。AWS AIのおかげで、開発の心配から解放され、人々の心を動かすことと新しい価値の創造に集中できます。
まとめ
Amazon Nova 2 Omniは、マルチモーダルAIの新時代を切り拓く新たなモデルです。
主要なポイント
- 業界初の統合モデル: Amazon Bedrock上で初めて、音声を含むあらゆるモダリティを理解し、テキストと画像を生成できるモデル
- 卓越したベンチマーク性能: MMAU第2位、画像生成でGPT-4o同等、OCRで最先端超え
- 開発効率の劇的向上: 複数モデルのパイプライン構築不要で、電通デジタルでは7日間で7アプリケーションを開発
- クロスモーダル推論: 動画+音声など複数モダリティを統合した推論が可能
感想
今回のre:Inventで発表されたNova2ファミリーの顔役(?)モデル「Omni」についてのお披露目セッションでした!
入力としてテキスト、画像、動画に対応しているモデルは既に存在していましたが、更に音声入力+画像出力まで対応できるという点で、かなり利便性の高いモデルだなという感想です。
モデルを切り替えることなく様々なタスクを任せられるのはとても良いですね。
他社モデルと比較してのスコアも表示されていましたが、この辺りは実際に使用してみないと評価し難いところですよね...
GAされれば、個人的に興味のある物体検出で色々試してみようと思います。
AIの1利用者としても選択肢の幅が広がるのは嬉しいので、今後も進化に期待します!
以上、大野でした!
参考リンク
- Introducing Amazon Nova 2 Omni in Preview - AWS
- Amazon introduces new frontier Nova models - About Amazon
- Amazon Nova foundation models - AWS
- Top announcements of AWS re:Invent 2025 - AWS Blog
- AWS re:Invent 2025: Amazon announces Nova 2 - About Amazon
- Introducing Amazon Nova 2 Sonic - AWS Blog
- 電通デジタル - AI AdsにAmazon Nova Reelを導入








