
PythonとNode.jsでAmazon S3 Vectorsの基本操作を実行する
はじめに
AI チャットや FAQ ボットを作るとき、LLM に社内ドキュメントや製品仕様を参照させたい場面がよくあります。代表的な手法が RAG です。RAG は、質問に関連する文書を先に検索し、その文書を LLM にコンテキストとして与え回答させます。これにより、LLM 単体では答えにくい社内固有の情報や最新情報を扱いやすくなります。
RAG の検索には、文書を埋め込み (embedding) と呼ばれる数値ベクトルに変換し、意味的に近い文書を探すベクトル検索を使うことが多いです。
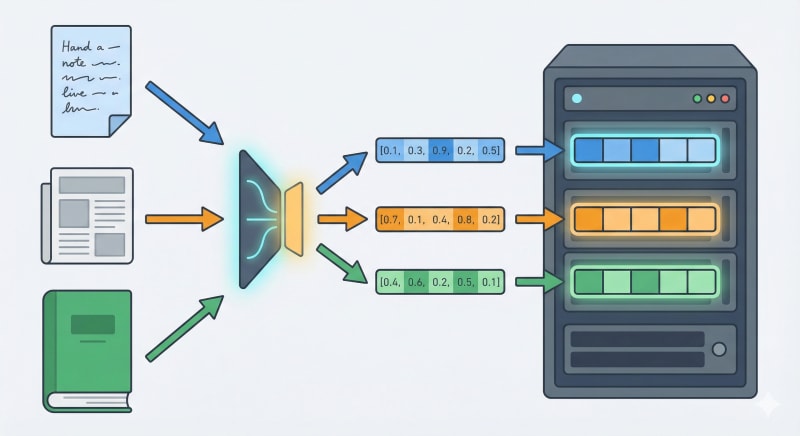
ベクトル検索を始めるには、ベクトルを保存する仕組みと検索用のインデックスが必要です。ベクトル専用 DB を別途用意すると、クラスタの用意、容量見積もり、スケール設計、監視などが必要になります。
Amazon S3 Vectors は、S3 にベクトルを保存でき、専用 API でベクトル検索ができます。アプリケーション側では、ベクトルバケットとベクトルインデックスを作り、ベクトルを追加して検索します。これにより、ベクトル検索のために別サービスのインフラを用意せずに、検証を始められます。
本記事では、Python と Node.js で Amazon S3 Vectors を操作してみます。機能ごとにスクリプトを分け、順に実行していきます。なお、本記事では embedding については扱いません。動作確認には固定のベクトル値を投入します。
対象読者
- AWS の認証情報を使って SDK を動かせる
- Python と Node.js のどちらか、または両方で検証したい
- Amazon S3 Vectors の API を把握したい
検証環境
- AWS CLI: 2.31.31
- Python: 3.12.3
- Node.js: 22.16.0
- リージョン: ap-northeast-1
参考
S3 Vectors の仕様
Amazon S3 Vectors は、ベクトルバケットの中にベクトルインデックスを作り、そのインデックスに対して PutVectors / GetVectors / ListVectors / QueryVectors を実行します。
float32 で保存され、取得時も float32 が返る
ベクトルの data は float32 として扱われます。SDK から高精度の数値型で渡した場合でも、S3 Vectors 側で float32 に変換され、GetVectors や QueryVectors では float32 の値が返ります。
metadata は filterable と non-filterable がある
metadata filtering は、ベクトルの近さで検索した結果に対して、metadata の値で絞り込みできる機能です。 たとえば year が 2021 以上のベクトルだけを対象にする、といった使い方ができます。既定では metadata は filter 条件に使えるため、filterable です。インデックス作成時に指定したキーだけは、あえて filter 条件に使えない non-filterable にできます。
non-filterable metadata は、ベクトルに付属情報として保存できます。GetVectors や QueryVectors の returnMetadata で取得できます。一方で、QueryVectors の filter 条件には使えません。
AWS マネジメントコンソールでの事前準備
ここでは、ベクトルバケットとベクトルインデックスをコンソールで作ります。
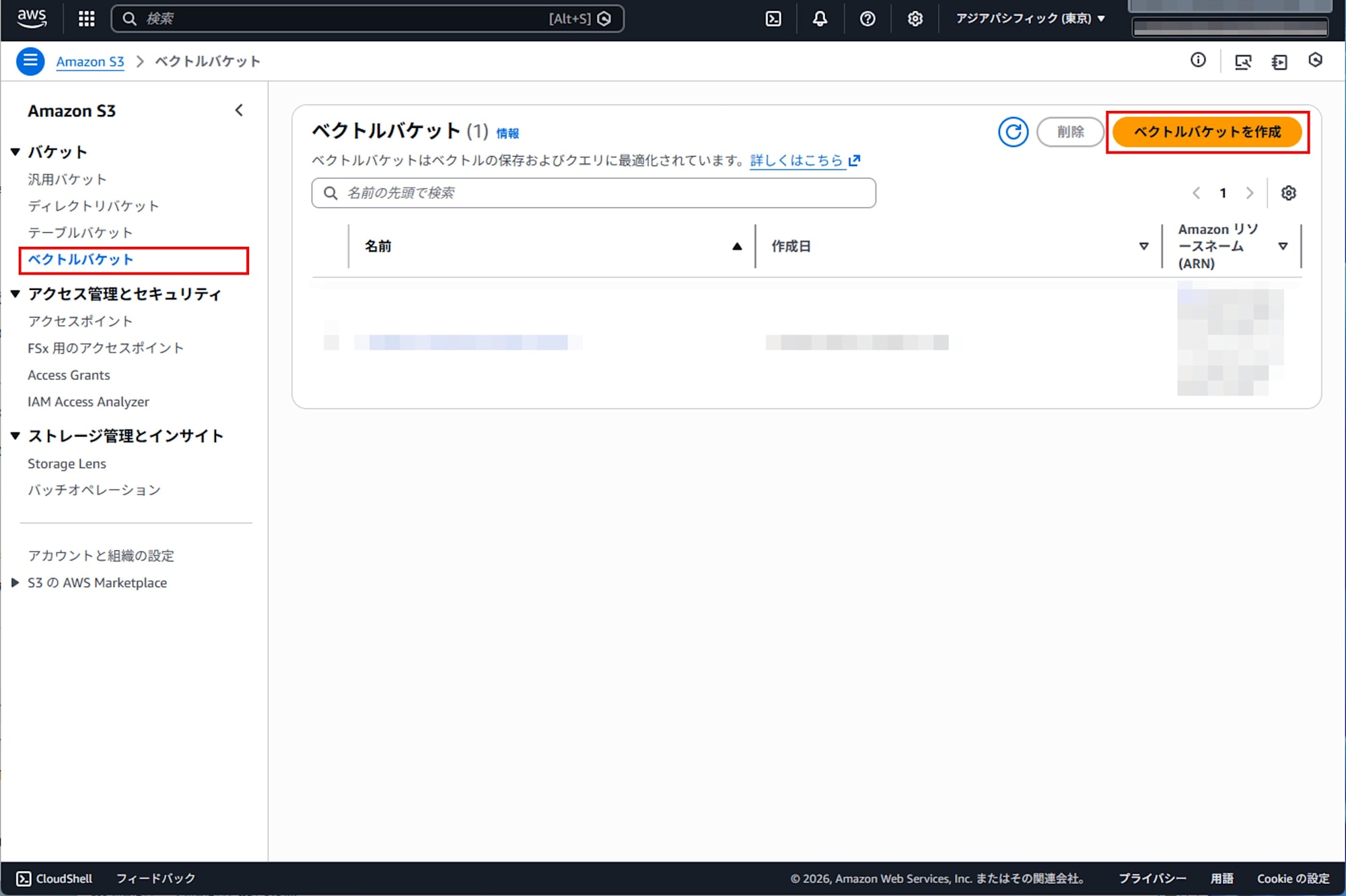
ベクトルバケットの作成
Amazon S3 コンソールを開き、S3 Vectors の画面からベクトルバケットを作成します。
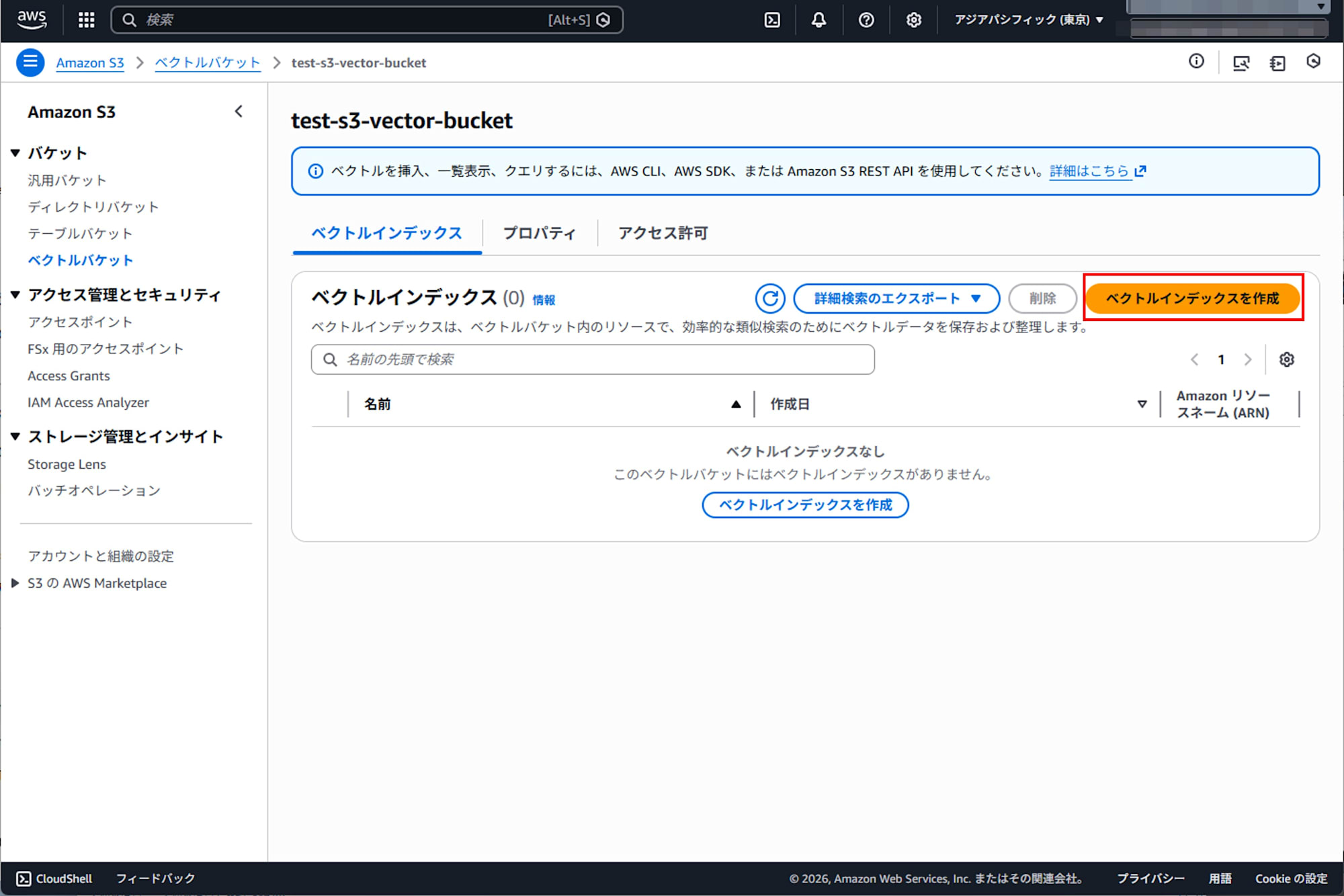
ベクトルインデックスの作成
作成したベクトルバケットの中に、ベクトルインデックスを作成します。
本記事では、次の 2 つのインデックスを作ります。
- movies (cosine)
- movies-euclidean (euclidean)
ディメンションと距離メトリックを決めます。今回はディメンションを 1024 として検証します。
また、non-filterable metadata として raw_text を指定します。
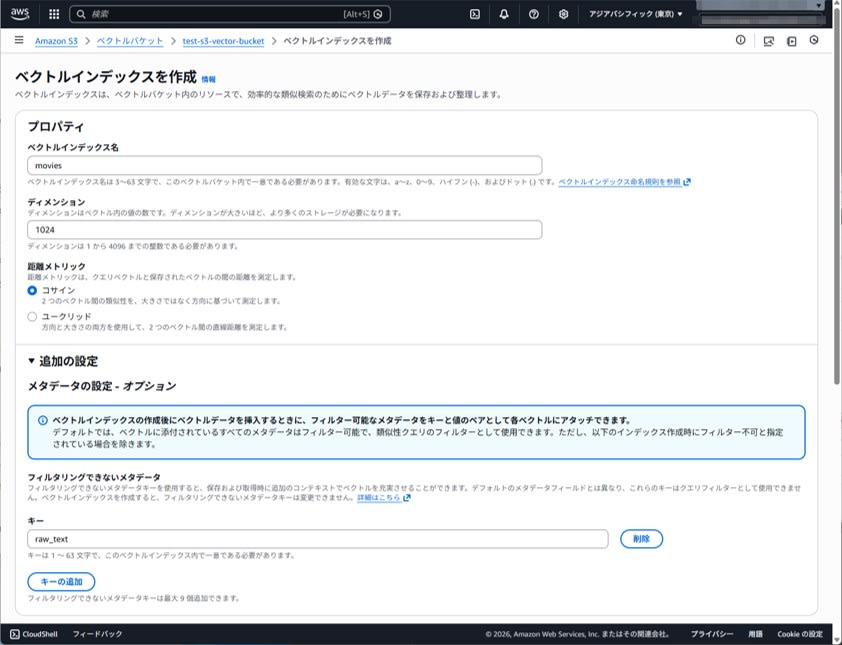
作成後、インデックス一覧に対象が表示されることを確認します。
環境変数
以降の例では、環境変数として次を使います。
| 変数名 | 値 |
|---|---|
| VECTOR_BUCKET_NAME | test-s3-vector-bucket |
| INDEX_NAME | movies |
| INDEX_NAME_EUC | movies-euclidean |
| DIMENSION | 1024 |
| AWS_REGION | ap-northeast-1 |
Python で操作する
依存関係のインストール
仮想環境を作り、boto3 を入れます。
python3 -m venv .venv
source .venv/bin/activate
pip install boto3
env_check.py
このスクリプトは、環境変数の不足を早めに検知するために使います。
import os
import sys
REQUIRED = ["AWS_REGION", "VECTOR_BUCKET_NAME", "INDEX_NAME", "INDEX_NAME_EUC", "DIMENSION"]
missing = [k for k in REQUIRED if not os.getenv(k)]
if missing:
print("Missing env:", ", ".join(missing))
sys.exit(1)
print("OK")
実行結果
OK
put_vectors.py
ベクトルを追加します。ここでは doc1 を 1 件入れます。
import os
import boto3
region = os.environ["AWS_REGION"]
bucket = os.environ["VECTOR_BUCKET_NAME"]
index_name = os.environ["INDEX_NAME"]
dim = int(os.environ["DIMENSION"])
def vec(first: float) -> list[float]:
v = [0.0] * dim
v[0] = first
return v
client = boto3.client("s3vectors", region_name=region)
client.put_vectors(
vectorBucketName=bucket,
indexName=index_name,
vectors=[
{
"key": "doc1",
"data": {"float32": vec(0.1)},
"metadata": {"genre": "mystery", "year": 2020, "raw_text": "hello"},
}
],
)
print("put-vectors: done")
実行結果
put-vectors: done
get_vectors.py
追加したベクトルを取得します。returnData と returnMetadata を True にしないと、key だけが返ります。DIMENSION が 1024 の場合、data.float32 は 1024 要素になるため、今回の検証では先頭の一部だけを表示します。
import os
import boto3
region = os.environ["AWS_REGION"]
bucket = os.environ["VECTOR_BUCKET_NAME"]
index_name = os.environ["INDEX_NAME"]
dim = int(os.environ["DIMENSION"])
client = boto3.client("s3vectors", region_name=region)
res = client.get_vectors(
vectorBucketName=bucket,
indexName=index_name,
keys=["doc1"],
returnData=True,
returnMetadata=True,
)
v = res["vectors"][0]
data = v.get("data", {}).get("float32", [])
print(f"key: {v['key']}")
print(f"dimension: {len(data)} / expected: {dim}")
print(f"data[0:8]: {data[:8]}")
print(f"metadata: {v.get('metadata')}")
実行結果
key: doc1
dimension: 1024 / expected: 1024
data[0:8]: [0.10000000149011612, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
metadata: {'raw_text': 'hello', 'genre': 'mystery', 'year': 2020}
list_vectors.py
インデックス内のベクトル一覧を取得します。ここでは returnMetadata を True にして、付属情報も確認します。
import os
import boto3
import json
region = os.environ["AWS_REGION"]
bucket = os.environ["VECTOR_BUCKET_NAME"]
index_name = os.environ["INDEX_NAME"]
client = boto3.client("s3vectors", region_name=region)
res = client.list_vectors(
vectorBucketName=bucket,
indexName=index_name,
returnMetadata=True,
)
print(json.dumps(res, ensure_ascii=False, indent=2))
実行結果
{
"ResponseMetadata": {
(略)
},
"vectors": [
{
"key": "doc1",
"metadata": {
"year": 2020,
"genre": "mystery",
"raw_text": "hello"
}
}
]
}
query_vectors.py
filter なしで類似検索します。DIMENSION と同じ長さの query vector を渡す必要があります。
import os
import boto3
import json
region = os.environ["AWS_REGION"]
bucket = os.environ["VECTOR_BUCKET_NAME"]
index_name = os.environ["INDEX_NAME"]
dim = int(os.environ["DIMENSION"])
def vec(first: float) -> list[float]:
v = [0.0] * dim
v[0] = first
return v
client = boto3.client("s3vectors", region_name=region)
res = client.query_vectors(
vectorBucketName=bucket,
indexName=index_name,
topK=5,
queryVector={"float32": vec(0.19)},
returnDistance=True,
returnMetadata=True,
)
print(json.dumps(res, ensure_ascii=False, indent=2))
ここでの vec(0.19) は、補助関数 vec(first) が作る DIMENSION 次元のベクトルです。具体的には、先頭の 1 要素だけが 0.19 で、残りはすべて 0.0 になります。同様に vec(0.1) も先頭要素だけが 0.1 で、残りがすべて 0.0 のベクトルです。この 2 つはスカラー倍の関係にあり、向きが同じベクトルとして扱えます。
コサイン類似度 (cosine similarity) は次の式で定義されます。
実行結果
{
"ResponseMetadata": {
(略)
},
"vectors": [
{
"distance": 0.0,
"key": "doc1",
"metadata": {
"genre": "mystery",
"raw_text": "hello",
"year": 2020
}
}
],
"distanceMetric": "cosine"
}
実際に distance が 0.0 と計算されていることが実行結果から分かります。
query_vectors_filter.py
metadata filter を使って絞り込みます。ここでは year が 2021 以上のものだけを対象にします。filter の構文は metadata filtering のページに例があります。
まず、doc1 を更新します。PutVectors は同じ key に対して再投入できるため、更新として扱えます。
import os
import boto3
region = os.environ["AWS_REGION"]
bucket = os.environ["VECTOR_BUCKET_NAME"]
index_name = os.environ["INDEX_NAME"]
dim = int(os.environ["DIMENSION"])
def vec(first: float) -> list[float]:
v = [0.0] * dim
v[0] = first
return v
client = boto3.client("s3vectors", region_name=region)
client.put_vectors(
vectorBucketName=bucket,
indexName=index_name,
vectors=[
{
"key": "doc1",
"data": {"float32": vec(0.2)},
"metadata": {"genre": "mystery", "year": 2021, "raw_text": "hello2"},
}
],
)
print("put-vectors: updated")
続いて、filter 付きで query します。
import os
import boto3
import json
region = os.environ["AWS_REGION"]
bucket = os.environ["VECTOR_BUCKET_NAME"]
index_name = os.environ["INDEX_NAME"]
dim = int(os.environ["DIMENSION"])
def vec(first: float) -> list[float]:
v = [0.0] * dim
v[0] = first
return v
client = boto3.client("s3vectors", region_name=region)
res = client.query_vectors(
vectorBucketName=bucket,
indexName=index_name,
topK=5,
queryVector={"float32": vec(0.19)},
returnDistance=True,
returnMetadata=True,
filter={"$and": [{"genre": {"$eq": "mystery"}}, {"year": {"$gte": 2021}}]},
)
print(json.dumps(res, ensure_ascii=False, indent=2))
実行結果
put-vectors: updated
{
"ResponseMetadata": {
(略)
},
"vectors": [
{
"distance": 0.0,
"key": "doc1",
"metadata": {
"raw_text": "hello2",
"year": 2021,
"genre": "mystery"
}
}
],
"distanceMetric": "cosine"
}
query_vectors_non_filterable.py
non-filterable metadata を filter に入れると失敗します。今回は raw_text を non-filterable にしたので、次の query は ValidationException になります。
import os
import boto3
region = os.environ["AWS_REGION"]
bucket = os.environ["VECTOR_BUCKET_NAME"]
index_name = os.environ["INDEX_NAME"]
dim = int(os.environ["DIMENSION"])
def vec(first: float) -> list[float]:
v = [0.0] * dim
v[0] = first
return v
client = boto3.client("s3vectors", region_name=region)
client.query_vectors(
vectorBucketName=bucket,
indexName=index_name,
topK=5,
queryVector={"float32": vec(0.19)},
filter={"raw_text": {"$eq": "hello"}},
)
実行結果
Traceback (most recent call last):
File "query_vectors_non_filterable.py", line 15, in <module>
client.query_vectors(
File ".venv/lib/python3.12/site-packages/botocore/client.py", line 602, in _api_call
return self._make_api_call(operation_name, kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ".venv/lib/python3.12/site-packages/botocore/context.py", line 123, in wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File ".venv/lib/python3.12/site-packages/botocore/client.py", line 1078, in _make_api_call
raise error_class(parsed_response, operation_name)
botocore.errorfactory.ValidationException: An error occurred (ValidationException) when calling the QueryVectors operation: Invalid use of non-filterable metadata in filter
delete_vectors.py
ベクトルを削除します。
import os
import boto3
region = os.environ["AWS_REGION"]
bucket = os.environ["VECTOR_BUCKET_NAME"]
index_name = os.environ["INDEX_NAME"]
client = boto3.client("s3vectors", region_name=region)
client.delete_vectors(
vectorBucketName=bucket,
indexName=index_name,
keys=["doc1"],
)
print("delete-vectors: done")
実行結果
delete-vectors: done
削除後に list_vectors.py を実行し、空になったことを確認します。
実行結果
{
"ResponseMetadata": {
(略)
},
"vectors": []
}
check_euclidean.py
movies-euclidean に vec(0.1) を投入し、vec(0.19) で検索して distance を確認します。
euclidean は直線距離を使う距離メトリックです。ユークリッド距離は一般に次の式で定義されます。
一方で、S3 Vectors が QueryVectors の応答で返す distance は computed distance や measure of similarity と説明されており、数学的なユークリッド距離と一致するとは限りません。そこでこのスクリプトでは、ユークリッド距離 (L2) と二乗距離 (L2 squared) の両方を計算し、返ってきた distance がどちらに近いかを確認します。
なお、今回の vec(first) は先頭の 1 要素だけが非 0 なので、DIMENSION が 1024 でも差分があるのは 1 要素だけです。そのため、理論上の L2 は |0.19 - 0.1| になります。
import os
import time
import boto3
region = os.environ["AWS_REGION"]
bucket = os.environ["VECTOR_BUCKET_NAME"]
index_name = os.environ["INDEX_NAME_EUC"]
dim = int(os.environ["DIMENSION"])
KEY = "doc-euc-1"
def vec(first: float) -> list[float]:
v = [0.0] * dim
v[0] = first
return v
client = boto3.client("s3vectors", region_name=region)
inserted = False
try:
client.put_vectors(
vectorBucketName=bucket,
indexName=index_name,
vectors=[
{
"key": KEY,
"data": {"float32": vec(0.1)},
"metadata": {"note": "euclidean quick check"},
}
],
)
inserted = True
# 1. 反映待ち: GetVectors で存在確認 (最大 10 回)
for _ in range(10):
g = client.get_vectors(
vectorBucketName=bucket,
indexName=index_name,
keys=[KEY],
)
if g.get("vectors"):
break
time.sleep(0.3)
# 2. 反映待ち: QueryVectors で検索 (最大 10 回)
res = None
for _ in range(10):
res = client.query_vectors(
vectorBucketName=bucket,
indexName=index_name,
topK=1,
queryVector={"float32": vec(0.19)},
returnDistance=True,
)
if res.get("vectors"):
break
time.sleep(0.3)
if not res or not res.get("vectors"):
# 空のままでも落とさず、状況が分かる出力にする
print("distanceMetric:", (res or {}).get("distanceMetric"))
print("vectors: []")
print("note: QueryVectors returned no results. Try again, or check indexName and data presence.")
raise SystemExit(1)
returned = res["vectors"][0]["distance"]
delta = 0.19 - 0.1
expected_l2 = abs(delta)
expected_l2_squared = delta * delta
print("distanceMetric:", res.get("distanceMetric"))
print("distance:", returned)
print("expected_l2:", expected_l2)
print("expected_l2_squared:", expected_l2_squared)
finally:
if inserted:
client.delete_vectors(
vectorBucketName=bucket,
indexName=index_name,
keys=[KEY],
)
実行結果 (例)
distanceMetric: euclidean
distance: 0.007821191102266312
expected_l2: 0.09
expected_l2_squared: 0.0081
実測では、S3 Vectors が返す distance は L2 よりも L2 squared に近い値になりました。S3 Vectors の distance は数学的な距離と完全に一致すると決め打ちせず、順位付けのための指標として扱うほうが安全です。値の比較が必要な場合は、同じ distanceMetric と同じスケールのデータ同士で相対比較するとよいでしょう。
Node.js で操作する
依存関係のインストール
AWS SDK for JavaScript の S3 Vectors クライアントを使います。
npm init -y
npm install @aws-sdk/client-s3vectors
env_check.js
Python と同様に、環境変数の不足を早めに検知します。Node.js 編では cosine のインデックスだけを使い、 euclidean は省略します。
const required = ["AWS_REGION", "VECTOR_BUCKET_NAME", "INDEX_NAME", "DIMENSION"];
const missing = required.filter((k) => !process.env[k]);
if (missing.length) {
console.error(`Missing env: ${missing.join(", ")}`);
process.exit(1);
}
console.log("OK");
実行結果
OK
put_vectors.js
ベクトルを追加します。ここでは doc1 を 1 件入れます。
const { S3VectorsClient, PutVectorsCommand } = require("@aws-sdk/client-s3vectors");
const region = process.env.AWS_REGION;
const vectorBucketName = process.env.VECTOR_BUCKET_NAME;
const indexName = process.env.INDEX_NAME;
const dim = Number(process.env.DIMENSION);
const vec = (first) => {
const v = Array(dim).fill(0);
v[0] = first;
return v;
};
(async () => {
const client = new S3VectorsClient({ region });
await client.send(
new PutVectorsCommand({
vectorBucketName,
indexName,
vectors: [
{
key: "doc1",
data: { float32: vec(0.1) },
metadata: { genre: "mystery", year: 2020, raw_text: "hello" },
},
],
})
);
console.log("put-vectors: done");
})().catch((e) => {
console.error(e?.name, e?.message);
process.exit(1);
});
実行結果
put-vectors: done
get_vectors.js
追加したベクトルを取得します。returnData と returnMetadata を true にしないと、key だけが返ります。DIMENSION が大きい場合に備え、先頭の一部だけを表示します。
const { S3VectorsClient, GetVectorsCommand } = require("@aws-sdk/client-s3vectors");
const region = process.env.AWS_REGION;
const vectorBucketName = process.env.VECTOR_BUCKET_NAME;
const indexName = process.env.INDEX_NAME;
const dim = Number(process.env.DIMENSION);
(async () => {
const client = new S3VectorsClient({ region });
const res = await client.send(
new GetVectorsCommand({
vectorBucketName,
indexName,
keys: ["doc1"],
returnData: true,
returnMetadata: true,
})
);
const v = res.vectors?.[0];
const data = v?.data?.float32 ?? [];
console.log(`key: ${v?.key}`);
console.log(`dimension: ${data.length} / expected: ${dim}`);
console.log(`data[0:8]: ${JSON.stringify(data.slice(0, 8))}`);
console.log(`metadata: ${JSON.stringify(v?.metadata)}`);
})().catch((e) => {
console.error(e?.name, e?.message);
process.exit(1);
});
実行結果
key: doc1
dimension: 1024 / expected: 1024
data[0:8]: [0.10000000149011612,0,0,0,0,0,0,0]
metadata: {"year":2020,"raw_text":"hello","genre":"mystery"}
list_vectors.js
インデックス内のベクトル一覧を取得します。ここでは returnMetadata を true にして、付属情報も確認します。
const { S3VectorsClient, ListVectorsCommand } = require("@aws-sdk/client-s3vectors");
const region = process.env.AWS_REGION;
const vectorBucketName = process.env.VECTOR_BUCKET_NAME;
const indexName = process.env.INDEX_NAME;
(async () => {
const client = new S3VectorsClient({ region });
const res = await client.send(
new ListVectorsCommand({
vectorBucketName,
indexName,
returnMetadata: true,
})
);
console.log(JSON.stringify(res, null, 2));
})().catch((e) => {
console.error(e?.name, e?.message);
process.exit(1);
});
実行結果
{
"vectors": [
{
"key": "doc1",
"metadata": {
"raw_text": "hello",
"genre": "mystery",
"year": 2020
}
}
],
"$metadata": {
(略)
}
}
query_vectors.js
filter なしで類似検索します。DIMENSION と同じ長さの query vector を渡す必要があります。
const { S3VectorsClient, QueryVectorsCommand } = require("@aws-sdk/client-s3vectors");
const region = process.env.AWS_REGION;
const vectorBucketName = process.env.VECTOR_BUCKET_NAME;
const indexName = process.env.INDEX_NAME;
const dim = Number(process.env.DIMENSION);
const vec = (first) => {
const v = Array(dim).fill(0);
v[0] = first;
return v;
};
(async () => {
const client = new S3VectorsClient({ region });
const res = await client.send(
new QueryVectorsCommand({
vectorBucketName,
indexName,
topK: 5,
queryVector: { float32: vec(0.19) },
returnDistance: true,
returnMetadata: true,
})
);
console.log(JSON.stringify(res, null, 2));
})().catch((e) => {
console.error(e?.name, e?.message);
process.exit(1);
});
実行結果
{
"vectors": [
{
"distance": 0,
"key": "doc1",
"metadata": {
"year": 2020,
"genre": "mystery",
"raw_text": "hello"
}
}
],
"distanceMetric": "cosine",
"$metadata": {
(略)
}
}
query_vectors_non_filterable.js
raw_text を non-filterable metadata にしている場合、filter に含めると失敗します。
const { S3VectorsClient, QueryVectorsCommand } = require("@aws-sdk/client-s3vectors");
const region = process.env.AWS_REGION;
const vectorBucketName = process.env.VECTOR_BUCKET_NAME;
const indexName = process.env.INDEX_NAME;
const dim = Number(process.env.DIMENSION);
const vec = (first) => {
const v = Array(dim).fill(0);
v[0] = first;
return v;
};
(async () => {
const client = new S3VectorsClient({ region });
try {
await client.send(
new QueryVectorsCommand({
vectorBucketName,
indexName,
topK: 5,
queryVector: { float32: vec(0.19) },
filter: { raw_text: { $eq: "hello" } },
})
);
} catch (e) {
console.error("expected error:", e?.name, e?.message);
}
})().catch((e) => {
console.error(e?.name, e?.message);
process.exit(1);
});
実行結果
expected error: ValidationException Invalid use of non-filterable metadata in filter
delete_vectors.js
後片付けとして、追加したベクトルを削除します。
const { S3VectorsClient, DeleteVectorsCommand } = require("@aws-sdk/client-s3vectors");
const region = process.env.AWS_REGION;
const vectorBucketName = process.env.VECTOR_BUCKET_NAME;
const indexName = process.env.INDEX_NAME;
(async () => {
const client = new S3VectorsClient({ region });
await client.send(
new DeleteVectorsCommand({
vectorBucketName,
indexName,
keys: ["doc1"],
})
);
console.log("delete-vectors: done");
})().catch((e) => {
console.error(e?.name, e?.message);
process.exit(1);
});
実行結果
delete-vectors: done
考察
コンソールと SDK の役割分担
現時点では、コンソールはベクトルバケットとベクトルインデックスの作成までは扱えます。一方で、ベクトルの挿入、一覧表示、クエリは AWS SDK / AWS CLI / REST API の利用が前提です。今後コンソールの機能が拡充される可能性はありますが、運用を考えると SDK ベースの手順を先に固める価値は十分にあると思います。 たとえば、ベクトルの投入や更新はバッチ処理や CI と相性がよく、ログと一緒に再現手順を残せます。UI で完結する手順よりも、検証と本番移行の差分を小さくできます。
distanceMetric と distance の扱い
distanceMetric は、類似度の計算方法です。cosine は角度にもとづく指標で類似度を評価し、euclidean は直線距離にもとづく指標で類似度を評価します。
本記事の検証では、cosine の例では distance が 0.0 になりました。一方で euclidean の例では、数学的なユークリッド距離 (L2) を想定した値と一致しませんでした。このため、実装では distance の絶対値を距離そのものとして扱いすぎないほうが安全です。
たとえば L2 と L2 squared は単調増加の関係にあるため、同じデータ同士で順位付けをする限り、上位に来る結果は基本的に変わりません。重要なのは、同じ distanceMetric の結果を相対比較して上位を取り出すことです。
ただし distance にしきい値を設けて合否判定したい場合は注意が必要です。その場合は、実データで分布を見てから基準値を決めるほうが安全でしょう。
あえて S3 Vectors を選ぶ場面
S3 Vectors は、次のような場面で選びやすいと感じました。
- 既に S3 をデータレイクとして使っており、ベクトル検索だけのために別サービスの運用対象を増やしたくない場合
- まずは小さく検証したく、インフラの設計やクラスタ運用に時間を割きたくない場合
- ベクトル検索部分だけを部品として使い、前処理や後処理はアプリケーション側で自由に設計したい場合
一方で、RAG を短い手順で立ち上げたいだけなら、Amazon Bedrock Knowledge Bases のように、取り込み、分割、埋め込み、検索までをまとめて扱える仕組みが向きます。S3 Vectors は Knowledge Bases のベクトルストアとしても使えるため、最初は Knowledge Bases で試し、後から要件に応じて取り回しを変える選択肢も取りやすいです。
高度な検索機能やハイブリッド検索などを重視する場合は、Amazon OpenSearch Service や DocumentDB のように、検索に強いサービスを前提に設計したほうが合うことがあります。DynamoDB はトランザクション寄りのデータ配置に向きますが、ベクトル検索を中心に据える場合は OpenSearch と組み合わせる構成例も多く、要件次第で選び分けが必要です。
まとめ
Amazon S3 Vectors で、ベクトルバケットとベクトルインデックスを作成し、PutVectors / GetVectors / ListVectors / QueryVectors でベクトルデータを操作する方法を紹介しました。現時点のコンソールではリソース作成とインデックス一覧の確認ができる一方、ベクトルの挿入や検索は AWS SDK / AWS CLI から実行する形です。本記事では Python と Node.js それぞれでベクトル挿入や検索などを実行し、実行結果から実際の挙動を確認しました。RAG の検証や実装を進める際の参考になれば幸いです。










