
Amazon S3 Vectorsでマルチモーダルな画像検索をやってみた
2024年7月に、AWSからAmazon S3 Vectorsが発表されました。これは、S3という実質的な無限にスケールするストレージサービス上で、ベクトル検索を構築できるサービスです。
ユースケースとして、大量の画像・動画ファイル群に対するセマンティック(類似)検索が挙げられています。
ドキュメントでは、大規模な動画や画像ファイル群に対してベクトル検索でセマンティック(類似)検索するユースケースが挙げられています。
本記事では、そのようなユースケースの小さなデモとして、画像データに対して Amazon Titan Multimodal Embeddings G1モデルを使ってマルチモーダル検索する方法を紹介します。
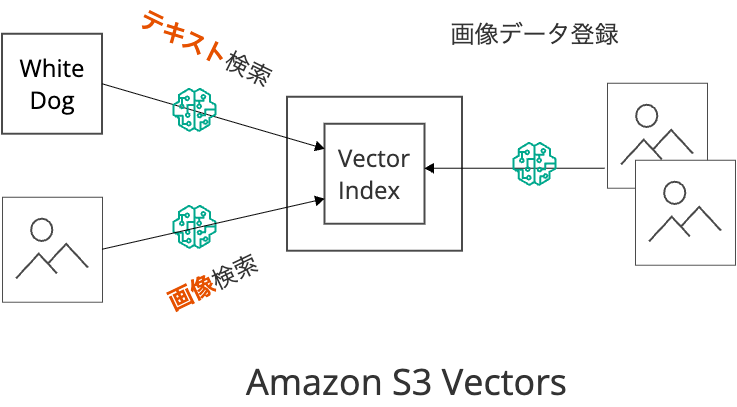
ベクトルデータベースとしてのAmazon S3 Vectors
ベクトル検索は、テキストや画像といったデータをN次元の数値表現(ベクトル)に変換し(埋め込み)、ベクトル同士の距離を計算することで類似度を測定し、似ているデータを検索できます。
ベクトル検索を行う上では、このベクトルの保存先が必要であり、保存先として OpenSearch や PostgreSQL(pgvector)などが活用されてきました。
今回発表されたAmazon S3 Vectors を利用すると、ベクトルデータベース サーバー を起動することなく、 サーバーレス にベクトル検索できます。
特に、大量のデータに対してベクトル検索するようなケースにおいて、ストレージなどのキャパシティから解放されるのは、大きなメリットではないかと思います。
Amazon S3 Vectorsの料金ページでも、計算例として100万オーダーのデータ数が例示されていることからも、大規模データを前提としているように伺えます。
マルチモーダル検索について
データをベクトル変換する埋込モデルによっては、テキストと画像というように複数種類(モード)に対応しているモデルもあります。
このようなモデルを使うと、検索画像に近い画像を検索するだけでなく(画像同士の検索)、検索語(テキスト)に近い画像を検索する(テキストで画像を検索する)ことも可能です。
このような検索をマルチモーダル検索といいます。
Amazon S3 Vectors を使った画像のマルチモーダル検索
今回は、AWSが提供するマルチモーダルな埋め込みモデル Amazon Titan Multimodal Embeddings G1 を利用し、Amazon S3 Vectors に保存した画像に対して、画像とテキストの2パターンで検索します。
東京を含む多くのリージョンでは利用できないため、今回は バージニア北部 (us-east-1)リージョン を利用しました。
Amazon S3 Vectorsを作成
Amazon S3の「Vector bucket」メニューからベクトルバケットを作成します。
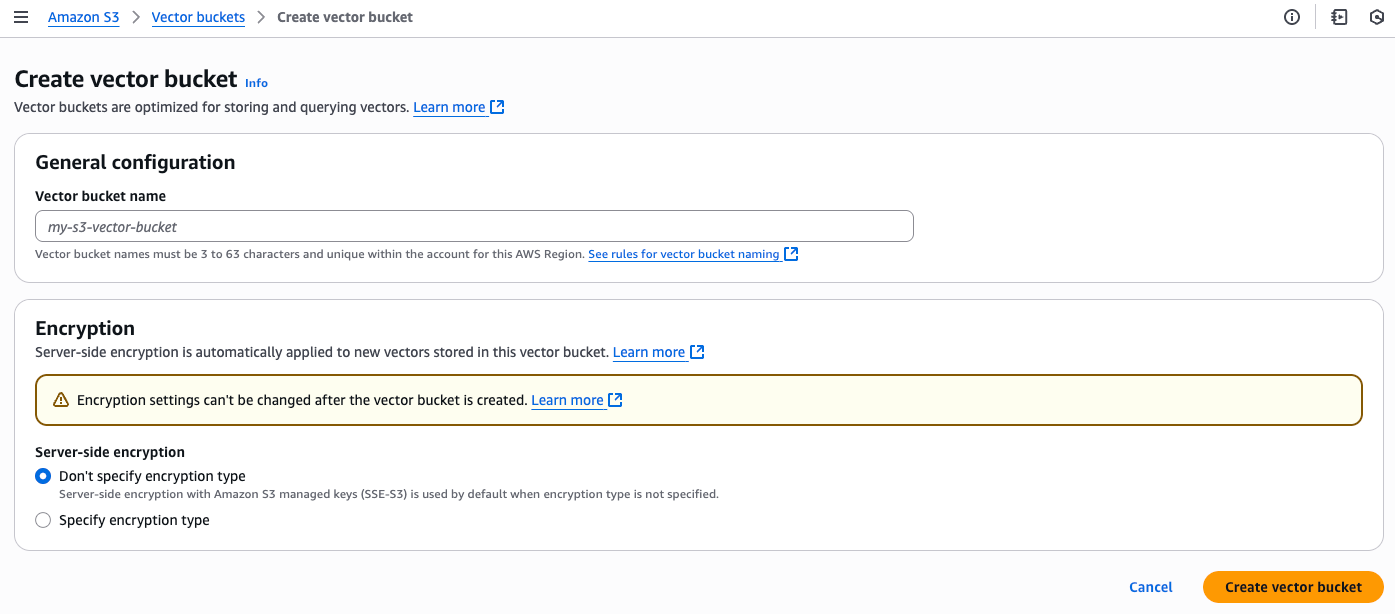
次に、このバケットの中に、ベクトル検索用のインデックス(ベクトルインデックス)を作成します。
埋め込みモデルの次元に合わせて、次元を設定します。
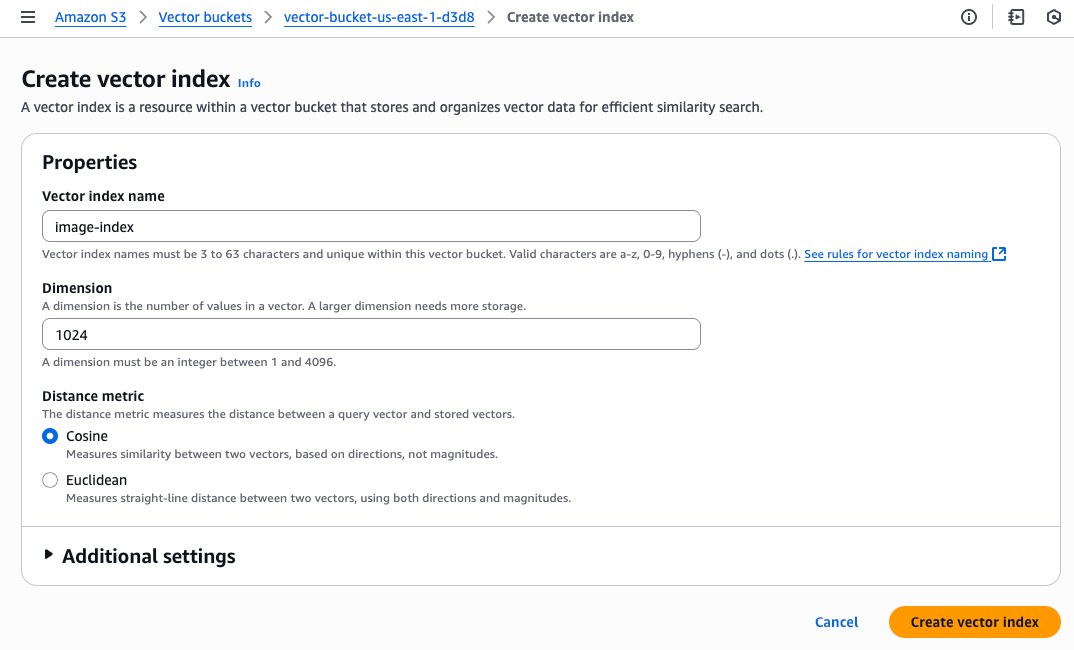
今回は、Amazon Titan Multimodal Embeddings G1モデルのデフォルトの 1024次元 としました。
また、ベクトルの距離として、コサイン距離、または、ユークリッド距離を選べます。
今回は 「コサイン距離」 を選択しました。後述のように、コサイン 類似度 ではなくてコサイン 距離 のため、 0(似ている)から1(似ていない)の値を取ります。
画像の登録
まず、検索対象となる画像データをAmazon S3 Vectorsに登録します。
以下の流れで処理します。
- bedrock:InvokeModel API : 埋め込みモデルを利用して画像をベクトル化
- s3vectors:PutVectors API : ベクトルをVector Indexに登録
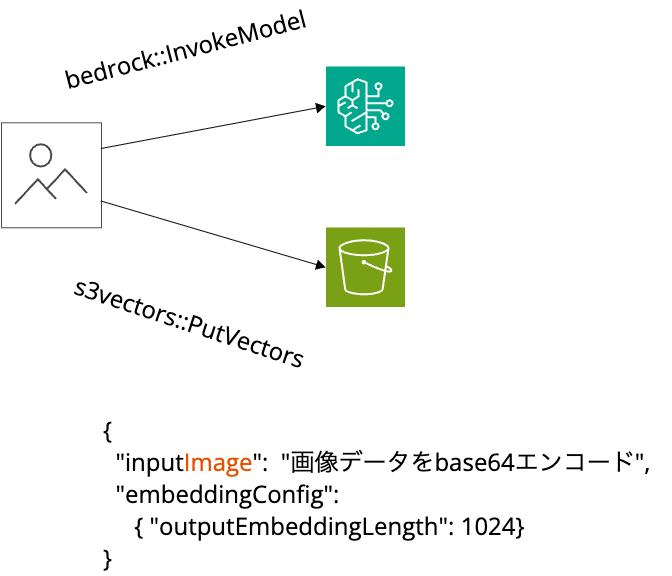
img ディレクトリ以下にあるこれら画像をPython SDKで登録するのが以下のコードです。
Titan 埋め込みモデルには画像を渡すため、画像データを base64 エンコーディングして、inputImage 引数で渡します
import base64
import glob
import json
import boto3
REGION = "us-east-1"
MODEL_ID = "amazon.titan-embed-image-v1"
DIMENSION = 1024
VECTOR_BUCKET_NAME = "your-bucket-name"
VECTOR_INDEX_NAME = "image-index"
bedrock = boto3.client("bedrock-runtime", region_name=REGION)
s3vectors = boto3.client("s3vectors", region_name=REGION)
file_paths = glob.glob("img/*")
vectors = []
for path in file_paths:
print(path)
image_bytes = open(path, "rb").read()
response = bedrock.invoke_model(
modelId=MODEL_ID,
body=json.dumps(
{
"inputImage": base64.b64encode(image_bytes).decode("utf-8"),
"embeddingConfig": {"outputEmbeddingLength": DIMENSION},
}
),
)
response_body = json.loads(response["body"].read())
vectors.append(
{
"key": path,
"data": {"float32": response_body["embedding"]},
"metadata": {"source_path": path},
}
)
res = s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET_NAME, indexName=VECTOR_INDEX_NAME, vectors=vectors
)
今回は犬と猫の画像を10枚用意し、登録しました。
- スコティッシュフォールド
- イエローラブラドール・レトリーバー
- ゴールデンレトリーバー
- 黒柴
- 白柴
- 赤柴
- シベリアンハスキー
- (赤)秋田犬
- (白)秋田犬
- ポメラニアン
類似画像を検索
ベクトル検索を利用し、入力した画像と似ている画像を検索してみましょう。
プログラムとしては、先程とほぼ同様であり、ベクトル登録するAPI(s3vectors::PutVectors)の代わりにベクトル検索するAPI(s3vectors::QueryVectors)を呼び出し、上位3件(topK=3)を返しています。類似度(近さ)を把握するために、 returnDistance=True としています。
この distance(コサイン 距離 ) は0から1の値を取り、0に近づくほど似ていて、1に近づくほど似ていないことを意味します。 コサイン 類似度 のように -1(似ていない) から 1(似ている) の値を取るわけではないことに注意しましょう。
import base64
import json
import sys
import boto3
REGION = "us-east-1"
MODEL_ID = "amazon.titan-embed-image-v1"
DIMENSION = 1024
VECTOR_BUCKET_NAME = "your-bucket-name"
VECTOR_INDEX_NAME = "image-index"
bedrock = boto3.client("bedrock-runtime", region_name=REGION)
s3vectors = boto3.client("s3vectors", region_name=REGION)
img_path = sys.argv[1]
image_bytes = open(img_path, "rb").read()
response = bedrock.invoke_model(
modelId=MODEL_ID,
body=json.dumps(
{
"inputImage": base64.b64encode(image_bytes).decode("utf-8"),
"embeddingConfig": {"outputEmbeddingLength": DIMENSION},
}
),
)
response_body = json.loads(response["body"].read())
embedding = response_body["embedding"]
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=VECTOR_INDEX_NAME,
queryVector={"float32": embedding},
topK=3,
returnDistance=True,
returnMetadata=True,
)
print(json.dumps(response["vectors"], indent=2))
まずは一番自明なケースとして、登録済みの秋田犬の画像で検索すると、登録済みの画像が類似度(distance) がほぼ0、つまり、ほぼ完全一致の画像としてかえってきました。

※ https://commons.wikimedia.org/wiki/File:Akita_inu.jpeg
$ uv run python query-by-img.py img/dog-akita.jpg
[
{
"key": "img/dog-akita.jpg",
"metadata": {
"source_path": "img/dog-akita.jpg"
},
"distance": 0.0003943443298339844
},
{
"key": "img/dog-shiba.jpg",
"metadata": {
"source_path": "img/dog-shiba.jpg"
},
"distance": 0.3504660725593567
},
{
"key": "img/dog_blackshiba.jpg",
"metadata": {
"source_path": "img/dog_blackshiba.jpg"
},
"distance": 0.3736330270767212
}
]
次に、登録済みとは異なる赤柴(マル)の画像で検索してみましょう

※ https://commons.wikimedia.org/wiki/File:Shibainu_Maru.jpg
$ uv run python query-by-img.py img-all/dog-shibamaru.jpg
[
{
"key": "img/dog-shiba.jpg",
"metadata": {
"source_path": "img/dog-shiba.jpg"
},
"distance": 0.2881940007209778
},
{
"key": "img/dog-akita.jpg",
"metadata": {
"source_path": "img/dog-akita.jpg"
},
"distance": 0.3340585231781006
},
{
"key": "img/dog_blackshiba.jpg",
"metadata": {
"source_path": "img/dog_blackshiba.jpg"
},
"distance": 0.4215009808540344
}
]
柴犬や大きさはともかく見た目の似ている秋田犬がマッチしました。
1位:赤柴

※ https://commons.wikimedia.org/wiki/File:Shiba_inu_taiki.jpg
2位:秋田犬
※ https://commons.wikimedia.org/wiki/File:Akita_inu.jpeg
3位:黒柴

※ https://commons.wikimedia.org/wiki/File:Taro_Go_Kazumisou.JPG
白のマンチカンで検索してみます。

※ https://commons.wikimedia.org/wiki/File:Longhairedmunchkin.jpg
$ uv run python query-by-img.py img-all/cat-munchikan.jpg
[
{
"key": "img/dog-whitepomeranian.jpg",
"metadata": {
"source_path": "img/dog-whitepomeranian.jpg"
},
"distance": 0.3948613405227661
},
{
"key": "img/dog_whiteshiba.jpg",
"metadata": {
"source_path": "img/dog_whiteshiba.jpg"
},
"distance": 0.46674448251724243
},
{
"key": "img/dog-whiteakita.jpg",
"metadata": {
"source_path": "img/dog-whiteakita.jpg"
},
"distance": 0.49415719509124756
}
]
猫つながりで、唯一登録していた猫のスコティッシュフォールドではなく、白系の犬がマッチしました。基盤モデルは犬・猫の違いよりも見た目の類似度を優先した模様です。
1位:ポメラニアン

※ https://commons.wikimedia.org/wiki/File:Pipin_Pomeranian.jpg
2位:白柴

※ https://commons.wikimedia.org/wiki/File:Siro-shiba.JPG
3位:白秋田

※ https://en.wikipedia.org/wiki/File:آکیتای_سفید.jpg
テキストで検索
マルチモーダル検索の検証として、テキストで画像検索してみます。
埋め込み作成時が画像の時とことなります。 "inputImage": "画像データをbase64エンコード" ではなく "inputText": query というようにクエリーを inputText 引数で渡します。
# Populate a vector index with embeddings from Amazon Titan Text Embeddings V2.
import base64
import json
import sys
import boto3
REGION = "us-east-1"
MODEL_ID = "amazon.titan-embed-image-v1"
DIMENSION = 1024
VECTOR_BUCKET_NAME = "your-bucket-name"
VECTOR_INDEX_NAME = "image-index"
bedrock = boto3.client("bedrock-runtime", region_name=REGION)
s3vectors = boto3.client("s3vectors", region_name=REGION)
query = sys.argv[1]
response = bedrock.invoke_model(
modelId=MODEL_ID,
body=json.dumps(
{
"inputText": query,
"embeddingConfig": {"outputEmbeddingLength": DIMENSION},
}
),
)
response_body = json.loads(response["body"].read())
embedding = response_body["embedding"]
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=VECTOR_INDEX_NAME,
queryVector={"float32": embedding},
topK=3,
returnDistance=True,
returnMetadata=True,
)
print(json.dumps(response["vectors"], indent=2))
注意点として、 "Amazon Titan Multimodal Embeddings G1" の 対応言語は英語のみ のため、英語で問い合わせます。
「ポメラニアン」 で検索すると、ポメラニアンがトップでマッチしました。
$ uv run python query-by-text.py pomeranian
[
{
"key": "img/dog-whitepomeranian.jpg",
"metadata": {
"source_path": "img/dog-whitepomeranian.jpg"
},
"distance": 0.5091206431388855
},
{
"key": "img/dog_whiteshiba.jpg",
"metadata": {
"source_path": "img/dog_whiteshiba.jpg"
},
"distance": 0.6251574754714966
},
{
"key": "img/dog-goldenretriever.jpg",
"metadata": {
"source_path": "img/dog-goldenretriever.jpg"
},
"distance": 0.6375358700752258
}
]
1位:ポメラニアン
※ https://commons.wikimedia.org/wiki/File:Pipin_Pomeranian.jpg
2位:白柴
※ https://commons.wikimedia.org/wiki/File:Siro-shiba.JPG
3位: ゴールデンレトリーバー

※ https://commons.wikimedia.org/wiki/File:Golden_Retriever_10weeks.jpg
「猫(cat)」 で検索 すると、スコティッシュフォールドが最上位でマッチしました。
$ uv run python query-by-text.py cat
[
{
"key": "img/cat-scottishfold.jpg",
"metadata": {
"source_path": "img/cat-scottishfold.jpg"
},
"distance": 0.6171168088912964
},
{
"key": "img/dog-goldenretriever.jpg",
"metadata": {
"source_path": "img/dog-goldenretriever.jpg"
},
"distance": 0.6812556385993958
},
{
"key": "img/dog-whitepomeranian.jpg",
"metadata": {
"source_path": "img/dog-whitepomeranian.jpg"
},
"distance": 0.6864098310470581
}
]
1位:スコティッシュフォールド

※ https://commons.wikimedia.org/wiki/File:Adult_Scottish_Fold.jpg
2位:ゴールデンレトリーバー
※ https://commons.wikimedia.org/wiki/File:Golden_Retriever_10weeks.jpg
3位:ポメラニアン
※ https://commons.wikimedia.org/wiki/File:Pipin_Pomeranian.jpg
最後に、 「白い犬(white dog)」 で10件まで検索しました。
$ uv run python query-by-text.py 'white dog'
[
{
"key": "img/dog-whitepomeranian.jpg",
"metadata": {
"source_path": "img/dog-whitepomeranian.jpg"
},
"distance": 0.5569024085998535
},
{
"key": "img/dog_whiteshiba.jpg",
"metadata": {
"source_path": "img/dog_whiteshiba.jpg"
},
"distance": 0.5684007406234741
},
{
"key": "img/dog-goldenretriever.jpg",
"metadata": {
"source_path": "img/dog-goldenretriever.jpg"
},
"distance": 0.5840048789978027
},
...
{
"key": "img/dog_blackshiba.jpg",
"metadata": {
"source_path": "img/dog_blackshiba.jpg"
},
"distance": 0.6677646636962891
},
{
"key": "img/cat-scottishfold.jpg",
"metadata": {
"source_path": "img/cat-scottishfold.jpg"
},
"distance": 0.7216280102729797
}
]
白系の犬が上位に並び、9位は黒柴、最下位は猫(スコティッシュフォールド)と直感に近い結果が得られました。
1位
※ https://commons.wikimedia.org/wiki/File:Pipin_Pomeranian.jpg
2位
※ https://commons.wikimedia.org/wiki/File:Siro-shiba.JPG
3位
※ https://commons.wikimedia.org/wiki/File:Golden_Retriever_10weeks.jpg
9位

※ https://commons.wikimedia.org/wiki/File:Taro_Go_Kazumisou.JPG
10位
※ https://commons.wikimedia.org/wiki/File:Adult_Scottish_Fold.jpg
まとめ
Amazon S3 Vectorsを利用した画像のマルチモーダル検索システムを実装してみました。
OpenSearchのようなベクトルデータベースを利用する場合よりも安価に大規模に活用でき、サブセカンドな検索応答に対応するスグレモノです。
ただし、Amazon S3 Vectorsは銀の弾丸ではありません。
検索に限定しても、スケールするためにはベクトルインデックスを分割したり、クエリコストを下げるためにメタデータを活用したりと、設計で考慮すべき点はたくさんあります。
データベースを意識しないサーバーレスなサービスに仕上がっていますが、裏ではしっかりとデータベースが動いています。
料金ページやドキュメントの "Metadata filtering" や "S3 Vectors best practices" などを読み込んで、どのように検索しているのか(インデックスを活用しているのか)、しっかり理解する必要がありそうです。
参考
- [プレビュー] S3ベースの低コストなベクトルストレージ「Amazon S3 Vectors」が発表されました (Bedrock Knowledge Basesのベクトルストアとしても使える!) | DevelopersIO
- Introducing Amazon S3 Vectors: First cloud storage with native vector support at scale (preview) | AWS News Blog
- Working with S3 Vectors and vector buckets - Amazon Simple Storage Service










