
An introduction to various DR strategies in AWS
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Abstract
Disaster Recovery (DR) is one of the most important aspects when it comes to Cloud based infrastructure and even in cases of physical infrastructure. It enshrines the fact that in case the live and production environments shut down due to some disaster, then the infrastructure be scalable that the application be quickly served by a backup server with minimal downtime.
Introduction
Today, companies are looking for cloud services to have their backup infrastructure on it. The primary can be in a different or same cloud service provider or it can be physical data centres. When going for DR in AWS, there are various strategies which one need to know based on the cost and downtime requirements the company can afford. These are broadly classified into:
- Backup and Restore
- Pilot Light
- Warm Standby
- Multi Site active/active
Explanation of each
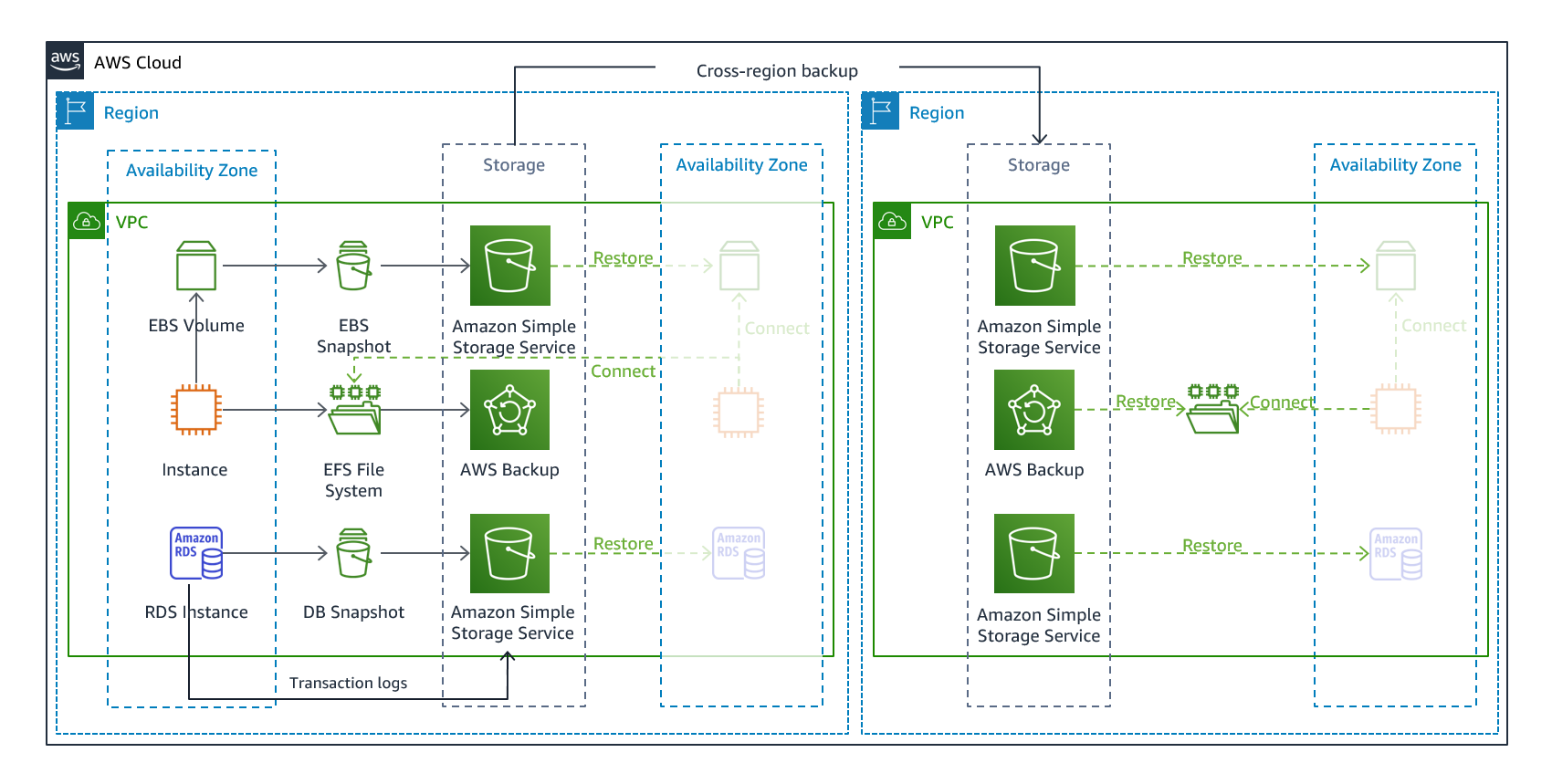
Backup and restore
In backup and restore, we do regular and scheduled backups of our application data and databases. This might includes the copy of the AMI images which our instances might be using, RDS Snapshots etc. When an outage occurs in the primary infrastructure, we manually spin up the EC2 and RDS DB i.e. creating a new infrastructure and then restoring the images and snapshots we created earlier.
Strength - Form a cost perspective, It is the cheapest strategy of all, but the downtime is huge, since you are manually creating the DR infrastructure. This could be inappropriate for mission critical applications.
Pilot Light
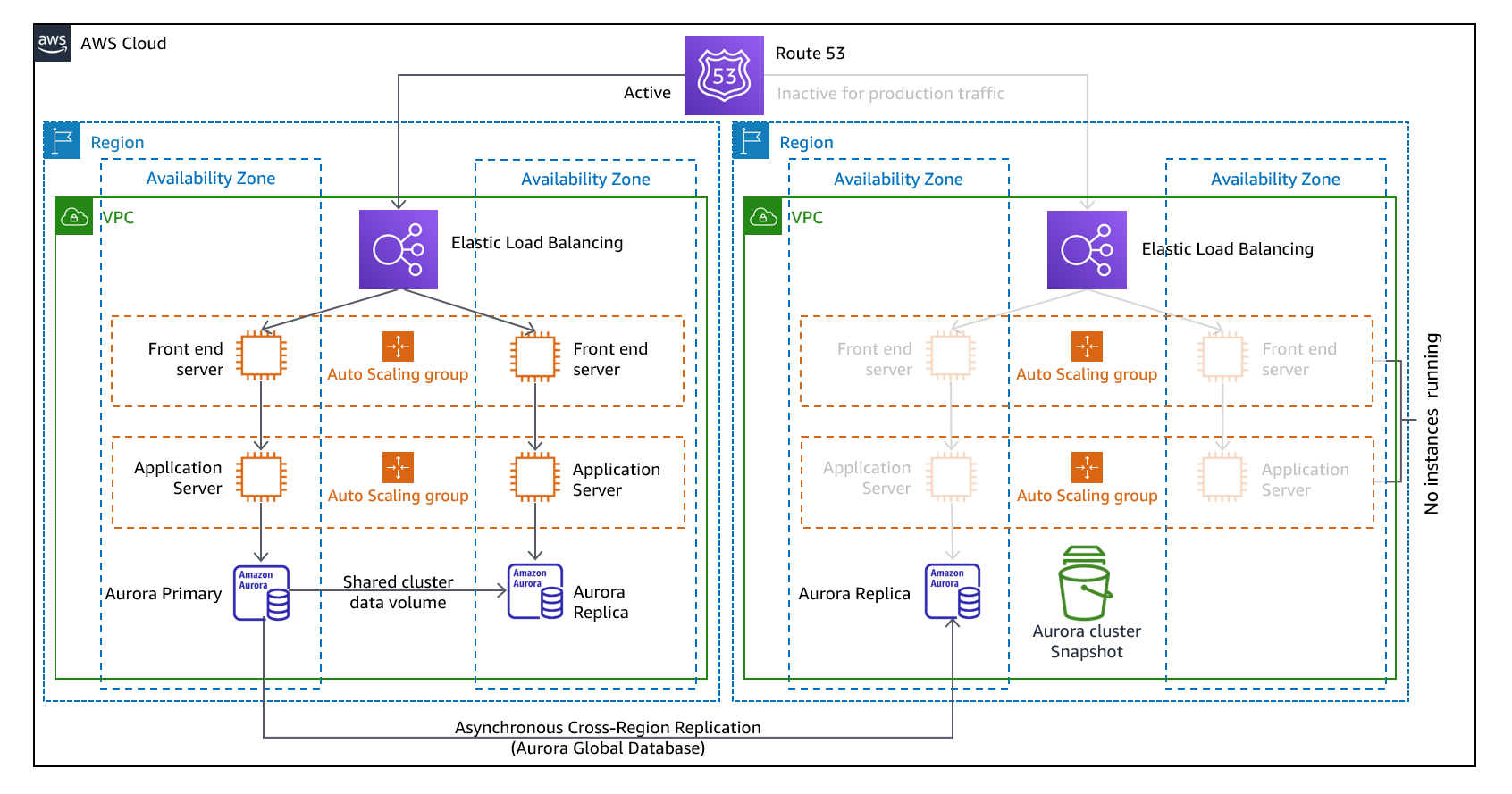
In pilot Light, some portion of primary infrastructure is already created in the backup cloud like databases and its backups are already configured. You can used read replicas in the DR region. Moreover, the EC2 instances are also already created but the application is not yet deployed on it. So this is different from the backup and restore option, in a way that the main infrastructure is always available. As soon as the disaster occurs, you deploy the application on EC2, promote the read replica as primary in case the switchover is made to the DR region.
Strength - It has a lower downtime than the backup and restore strategy, but it’s more costlier than that.
Warm Standby
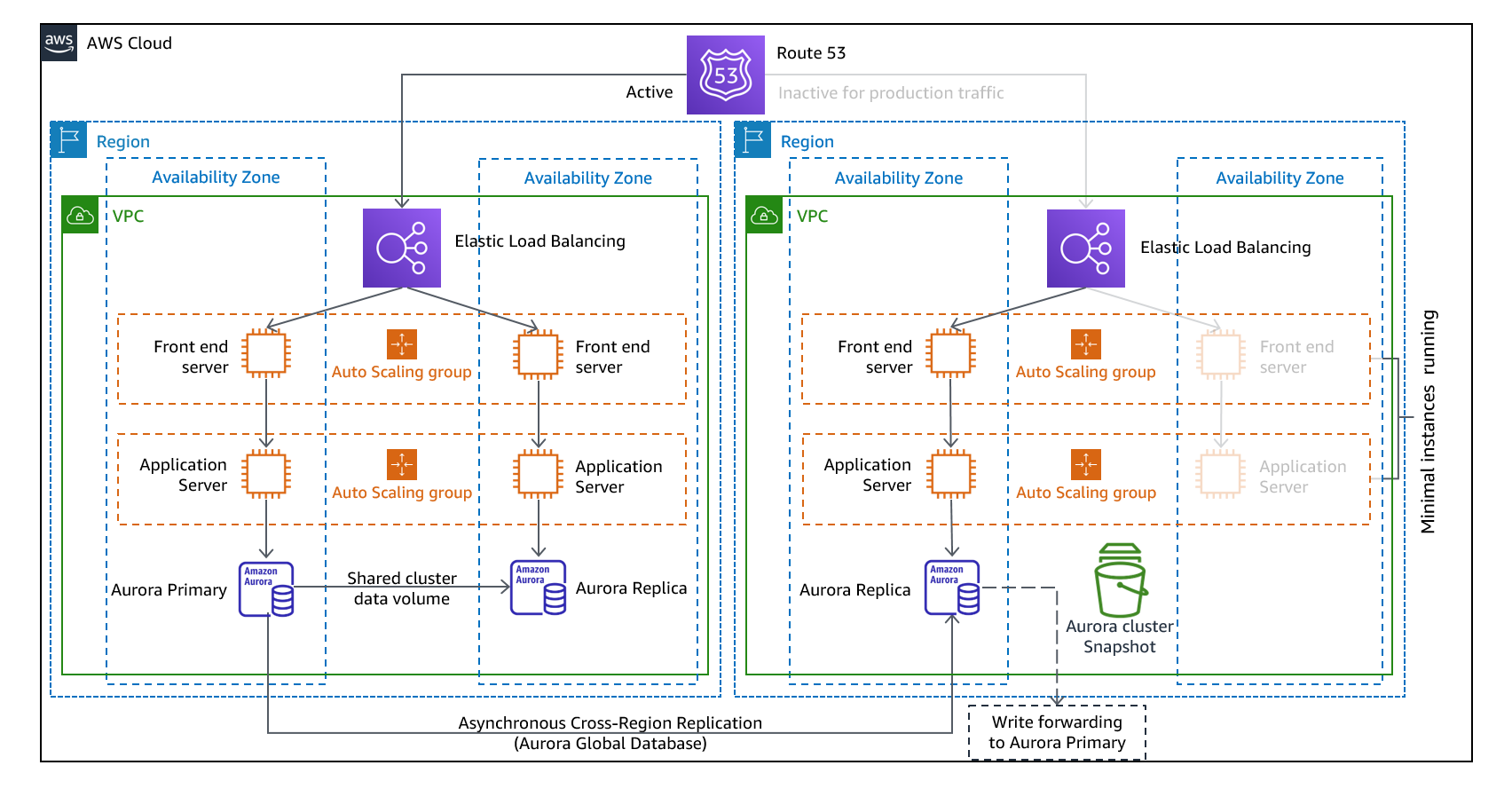
In this approach, the backup region (DR cloud) has a running infrastructure although at a smaller scale than the primary infrastructure. You replicate data to the DR cloud, synchronize the Database between your primary infrastructure and the DR cloud. When any failover occurs, the infra in DR cloud scales up to meet the traffic demand (for e.g., via Autoscaling).
Strength - This approach is costlier than the previous two approaches but has lower downtime than them.
Multi-site active/active
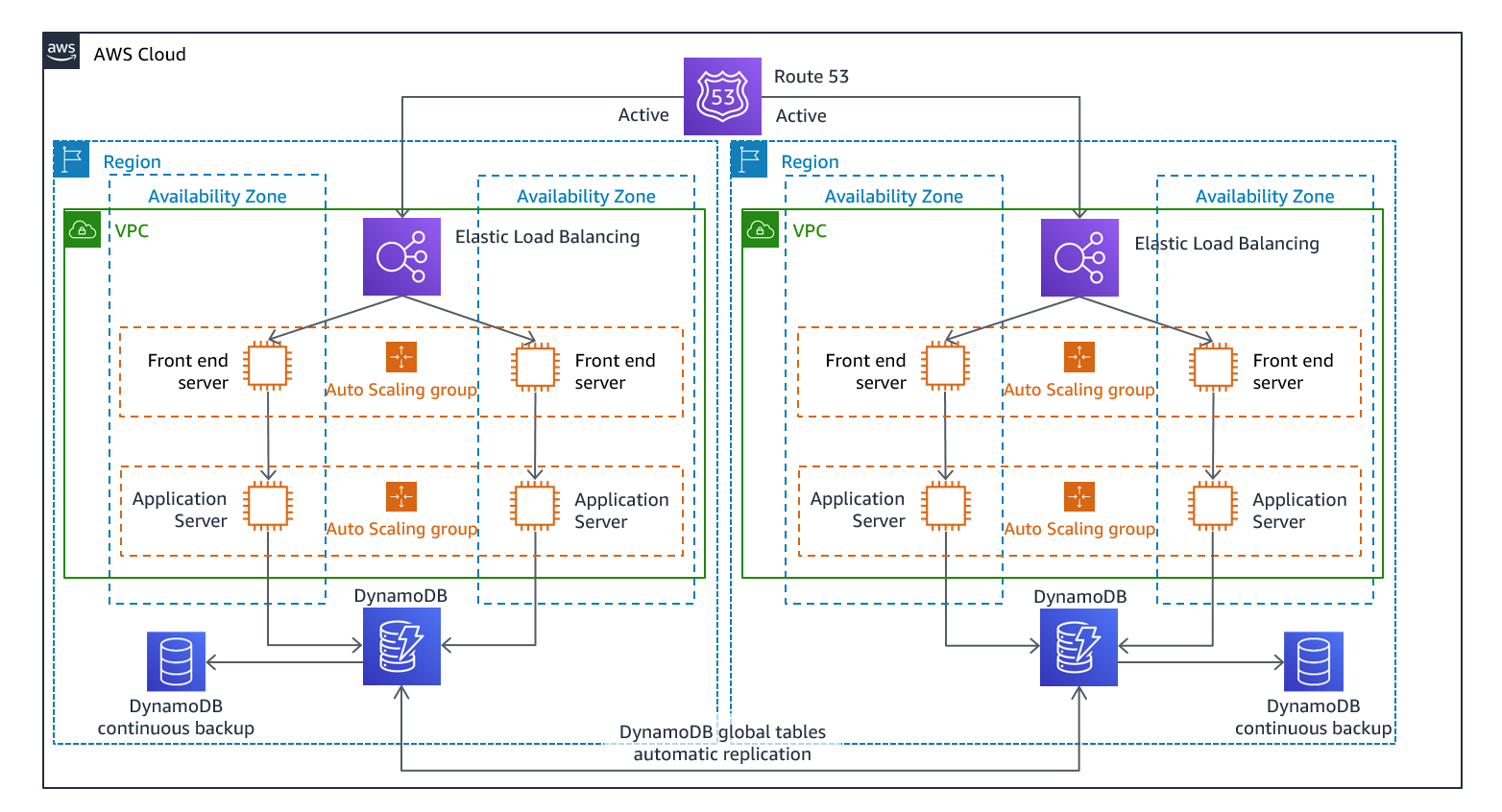
In this the DR cloud is a complete mirror image of the production infrastructure, and it is also up and running, As soon as disaster occurs in the primary, DNS health check configures itself to switch to the DR cloud infrastructure.
Strength - This approach has least downtime but is the costliest of all, since we are maintaining a complete running infrastructure as backup . This strategy especially suitable for mission critical use cases, where downtime is something which cannot be traded off.
Some information on Route 53
For the strategies, Pilot Light, Warm Standby and Multi-site active/active, we use the Route 53 service of AWS. Since in all the three categories, we have some or the other infrastructure already provisioned in the DR cloud. So when a disaster occurs in the primary, for a failover to the DR region, Route 53 is needed, Route 53 has a health check feature.
So for eg- we have a CNAME as www.example.com, but that points out to two aliases, one of the primary region and other of the DR region. So when a disaster occurs in the primary, the health check sees that the Alias is not functional, so it automatically failovers to the DR cloud alias. This is also called Failover Routing Policy of Route 53.










