
ELB ヘルスチェック失敗時、EC2 Auto Scaling は同じ AZ にインスタンスを再作成するのか検証してみた
はじめに
テクニカルサポートの 片方 です。
EC2 Auto Scaling を利用している環境では、インスタンスに異常が発生した場合に、EC2 Auto Scaling グループが異常なインスタンスを終了し、新しいインスタンスを起動して必要なキャパシティを維持します。
また、該当の EC2 Auto Scaling グループでは EC2 インスタンスのステータスチェックだけでなく、Elastic Load Balancing のヘルスチェック結果を利用してインスタンスの正常性を判断することもできます。これにより、アプリケーションが応答しなくなった場合や、ロードバランサーから到達できなくなった場合にも、EC2 Auto Scaling によるインスタンスの置き換えを行うことができます。
ここで気になったのが、ELB ヘルスチェックに失敗したインスタンスが置き換えられる場合、新しいインスタンスは同じアベイラビリティーゾーンに起動されるのか、それとも別のアベイラビリティーゾーンに起動されるのかという点です。
例えば、複数のアベイラビリティーゾーンを利用して EC2 Auto Scaling グループを構成している場合、片方の AZ にあるインスタンスが ELB ヘルスチェックに失敗したとします。このとき、感覚的には「異常が発生した AZ を避けて、正常な AZ に新しいインスタンスが起動されるのではないか」と考えたくなります。
しかし、ELB ヘルスチェックの失敗は、必ずしも AZ 自体の障害を意味するわけではありません。アプリケーションの停止、Security Group や Network ACL の設定、ヘルスチェックパスの不備など、さまざまな要因で発生する可能性があります。
そこで本記事では、EC2 Auto Scaling グループで起動される EC2 インスタンスのセキュリティグループを利用して意図的に ELB ヘルスチェックを失敗させ、EC2 Auto Scaling が置き換えインスタンスをどの AZ に起動するのかを検証してみます。
先に結論から
今回の検証では、ELB ヘルスチェックに失敗したインスタンスの置き換えとして、同じ AZ に新しい EC2 インスタンスが起動される挙動を確認しました。
これは、セキュリティグループによって ELB ヘルスチェックを意図的に失敗させているだけであり、対象 AZ での EC2 インスタンスの起動自体は失敗していないためです。
検証環境
今回の検証では、(ELB) Application Load Balancer と EC2 Auto Scaling を利用した Web サーバー構成を用意しました。
EC2 Auto Scaling グループは複数のアベイラビリティーゾーンを利用できるように構成し、検証開始時点では ap-northeast-1a に 1 台の EC2 インスタンスが起動している状態です。
| 項目 | 内容 |
|---|---|
| リージョン | 東京リージョン ap-northeast-1 |
| 利用 AZ | ap-northeast-1a、ap-northeast-1c |
| ロードバランサー | Application Load Balancer |
| EC2 Auto Scaling グループ | 1 つ |
| アベイラビリティーゾーン分散戦略 | バランシング(ベストエフォート) |
| 希望するキャパシティ | 1 |
| 最小キャパシティ | 1 |
| 最大キャパシティ | 1 |
| ヘルスチェック | ELB ヘルスチェック |
| ヘルスチェックプロトコル | HTTP |
| ヘルスチェックポート | 80 |
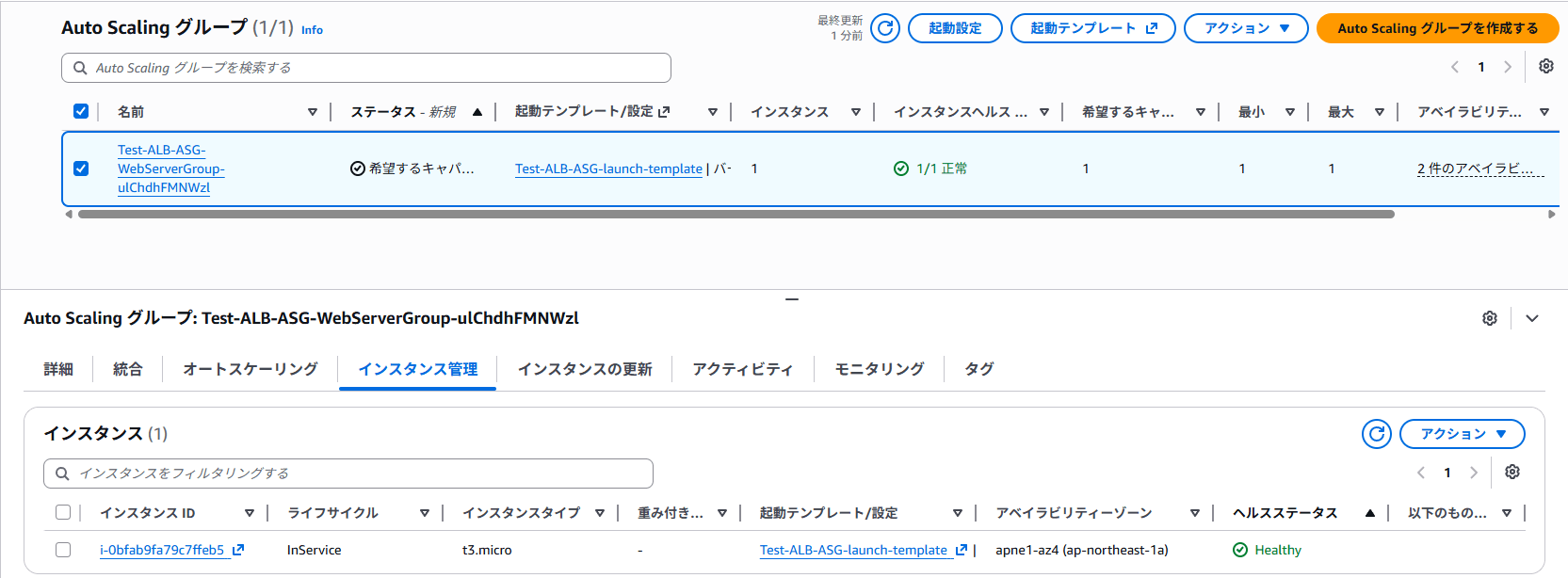

検証開始時点では、Auto Scaling グループ上のインスタンスは Healthy であり、EC2 コンソール上でもステータスチェックは正常です。
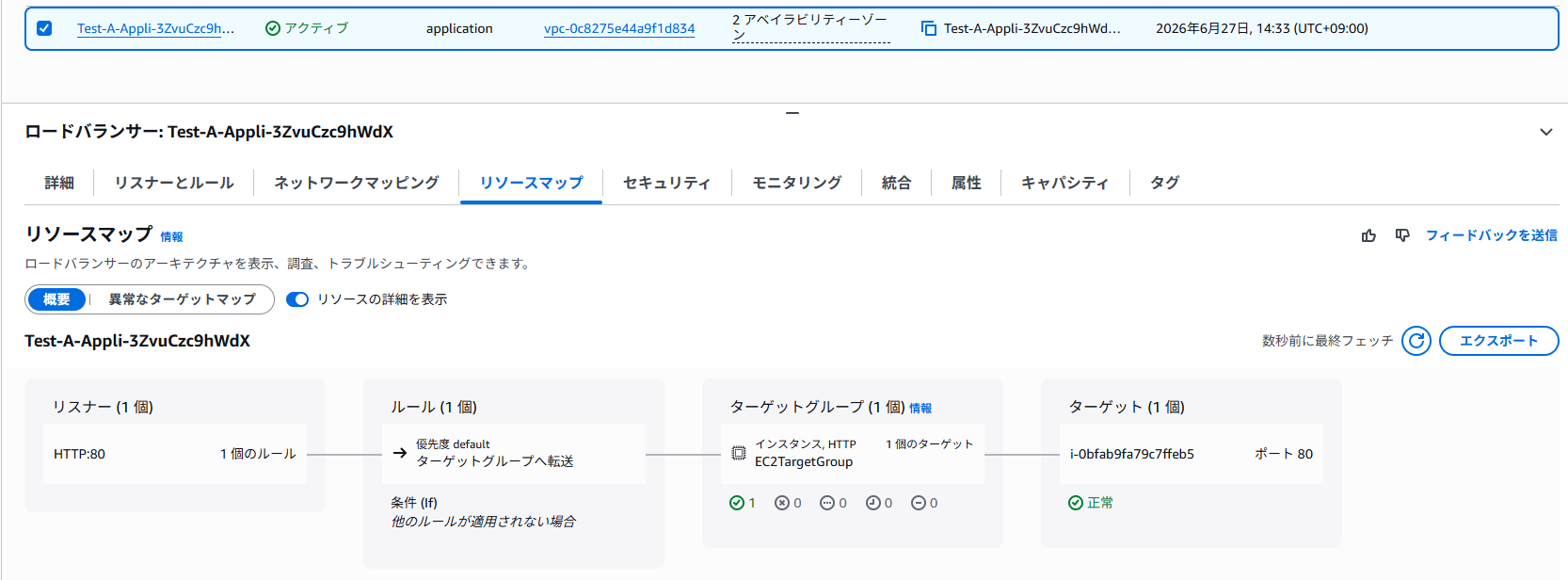
ELB ヘルスチェックに失敗するように意図的に設定
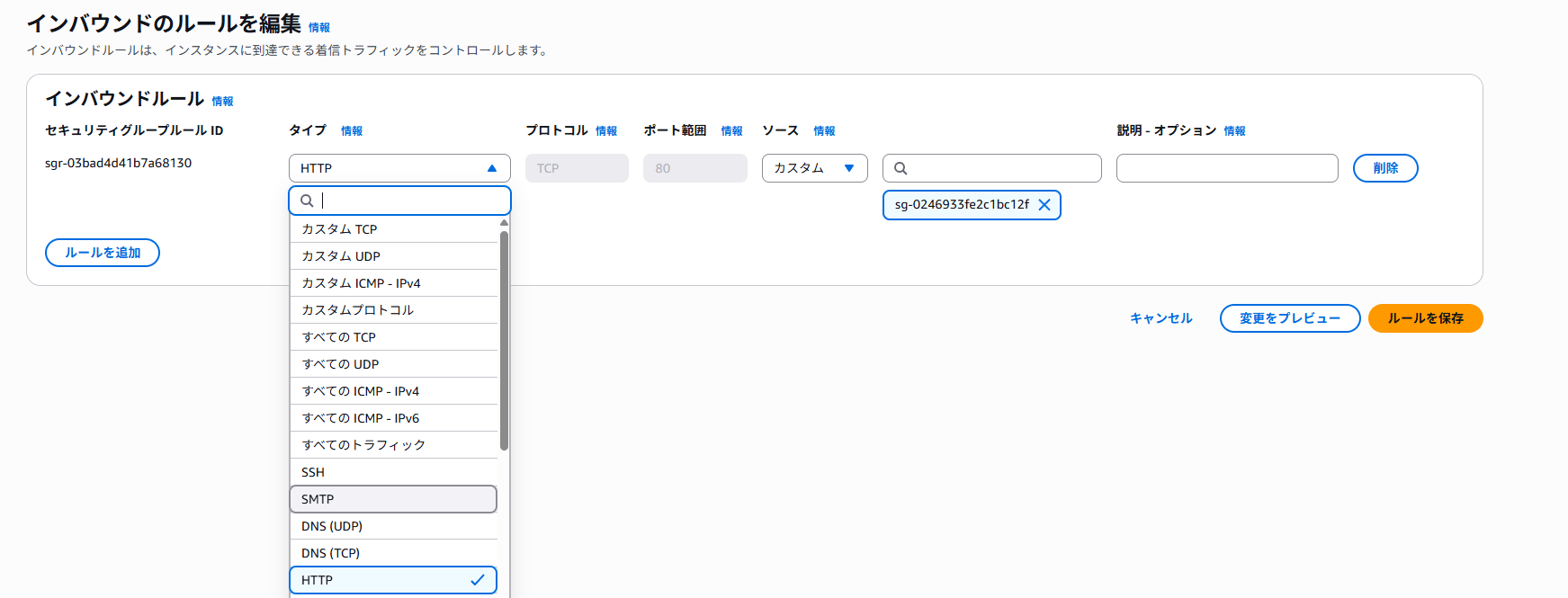
今回の検証では、EC2 インスタンスに関連付けられている Security Group のインバウンドルールを変更し、ALB からの HTTP ヘルスチェックが到達しない状態を作ります。
これにより、ELB ヘルスチェックに失敗した場合に、EC2 Auto Scaling がどの AZ に置き換えインスタンスを起動するのかを確認します。
例)
HTTP ⇒ SMTP
準備ができたので確認します。
確認してみた
検証時の EC2 インスタンス (i-0bfab9fa79c7ffeb5) は ap-northeast-1a の AZ で起動しています。
それでは、ELB ヘルスチェックに失敗するまで暫く待ちます。
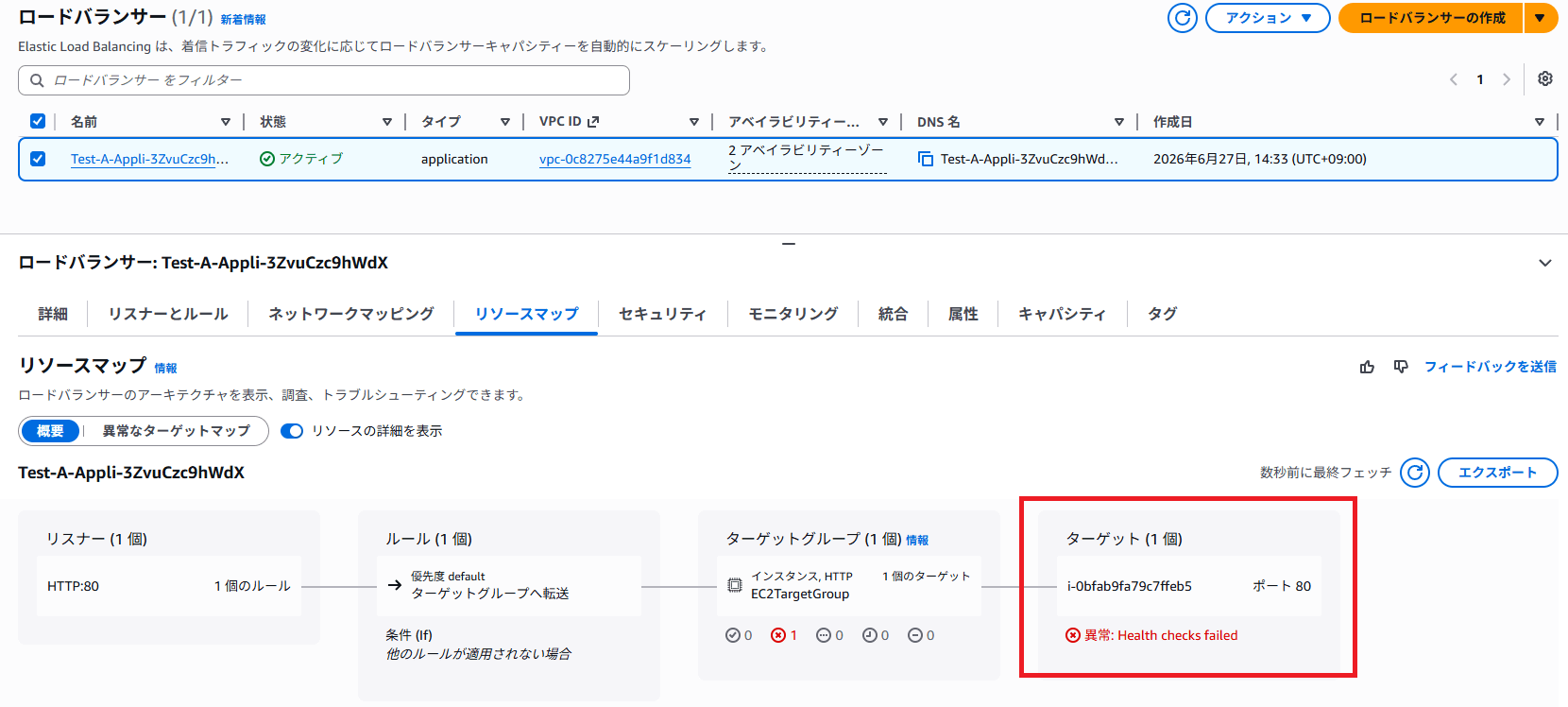
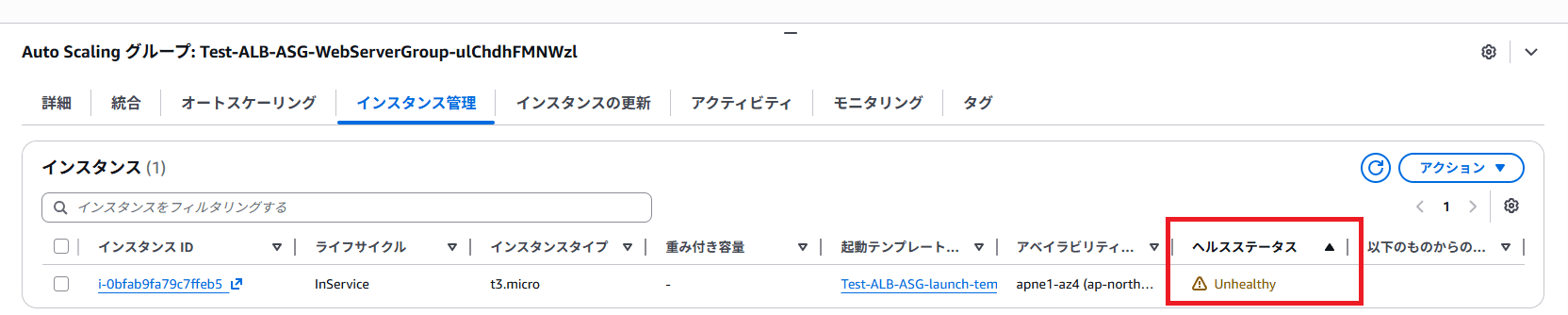
新しく起動される EC2 インスタンスはどの AZ で起動されるか確認します。
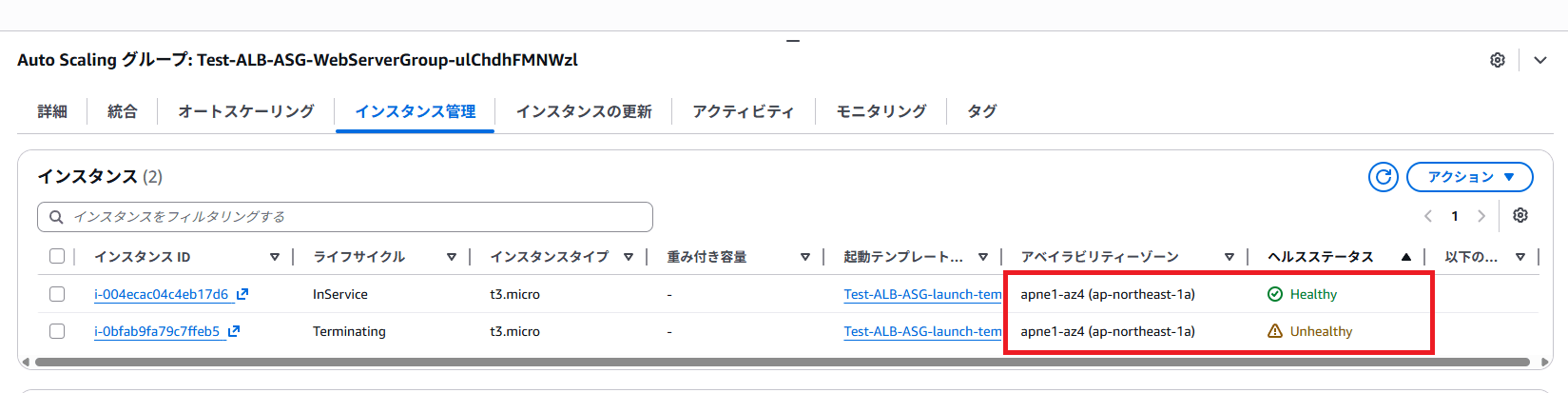

引き続き同じ ap-northeast-1a の AZ で起動しました。
補足
EC2 インスタンスの置換を行う必要がある場合、EC2 Auto Scaling は同じ AZ で置換先の EC2 インスタンスの起動を優先的に試みる動作となっています。
EC2 Auto Scailing ではアベイラビリティゾーン戦略により、EC2 インスタンスが起動する AZ の選択方法を設定可能ですが、デフォルト設定である「バランスの取れたベストエフォート」では、対象 AZ での起動に失敗した場合に、別の AZ での起動を試みる動作となります。
一方で、今回のように ELB ヘルスチェックを利用した仮想的な障害検証の場合、EC2 インスタンスの起動自体には失敗していません。
そのため、優先的に同じ AZ が選択され、インスタンスの起動が施行されています。
もし、AZ 障害の際に他の AZ で起動したい場合には、必要なキャパシティを 2 以上とし AZ 分散する方法、ゾーンシフトを有効化する方法が考えられます。
ゾーンシフトを有効化することで AZ 障害が AWS 側によって検知されると、EC2 Auto Scaling は対象の AZ をEC2 インスタンスの起動先の選択肢から除外いたします。
そのため、もし仮に大規模な AWS 側の AZ 障害が発生した場合には、対象 AZ 以外の AZ 内にあるサブネットが選択され、インスタンスが起動可能であることが想定されます。
また、そもそも本検証のように希望容量を 1 として単体で利用することはお勧めしていません。
特別な理由がない限りそのリージョンで使⽤可能なすべての AZ が含まれるようにすることをお勧めします。
Auto Scaling グループが複数のアベイラビリティーゾーンにまたがるようにすることを強くお勧めします。
まとめ
本ブログが誰かの参考になれば幸いです。
参考資料
- Auto Scaling グループのヘルスチェックについて - Amazon EC2 Auto Scaling
- Auto Scaling グループのアベイラビリティーゾーンの分散 - Amazon EC2 Auto Scaling
- Auto Scaling グループのゾーンシフト - Amazon EC2 Auto Scaling
- 混合インスタンスグループを作成するための設定の概要 - Amazon EC2 Auto Scaling
クラスメソッドオペレーションズ株式会社について
クラスメソッドグループのオペレーション企業です。
運用・保守開発・サポート・情シス・バックオフィスの専門チームが、IT・AIをフル活用した「しくみ」を通じて、お客様の業務代行から課題解決や高付加価値サービスまでを提供するエキスパート集団です。
当社は様々な職種でメンバーを募集しています。
「オペレーション・エクセレンス」と「らしく働く、らしく生きる」を共に実現するカルチャー・しくみ・働き方にご興味がある方は、クラスメソッドオペレーションズ株式会社 コーポレートサイト をぜひご覧ください。※2026年1月 アノテーション㈱から社名変更しました










