![[2026 年版] ALB ヘルスチェックの基本設定・トラブルシューティング総まとめ](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-f650a3011b384cc3781610c17755bc71/c37c67c9bc40b72e6dce1a49f4153283/elastic-load-balancing?w=3840&fm=webp)
[2026 年版] ALB ヘルスチェックの基本設定・トラブルシューティング総まとめ
クラスメソッドオペレーションズの Shimizu です。
弊社サポートデスクには ALB(Application Load Balancer)のヘルスチェック設定について、日々多くのご質問をいただきます。
基本設定やトラブルシューティングなど、状況によって確認するべきドキュメント資料が多岐にわたり、どこから確認すればよいか分からない、という方も多いのではないでしょうか。
この記事では、ALB ヘルスチェックの基本的な仕組みから、構築時・運用時それぞれのトラブルシューティング、確認すべきログまでをまとめて整理します。
できる限り分かりやすい内容を目指していますので、ALB のヘルスチェックでお困りの方はぜひご覧ください。
- 1. ALB ヘルスチェックの仕組み
- 2. ヘルスチェック失敗時に確認するログ
- 3. ヘルスチェック失敗時のトラブルシューティング
1. ALB ヘルスチェックの仕組み
ALB はユーザーから受信するリクエストとは別に、ターゲット(EC2、ECS)に対してヘルスチェックのリクエストを常に送信します。(下記図参照)
これに対して正常に応答しているターゲットは healthy となり、ユーザーリクエストが転送されます。一方で応答に異常があるターゲットは unhealthy と見なされ、ユーザーリクエストが転送されなくなります。
(※ ただし例外的に「ターゲットがすべて異常な場合はフェイルオープンでそのままリクエストが転送される」という仕様があります。)
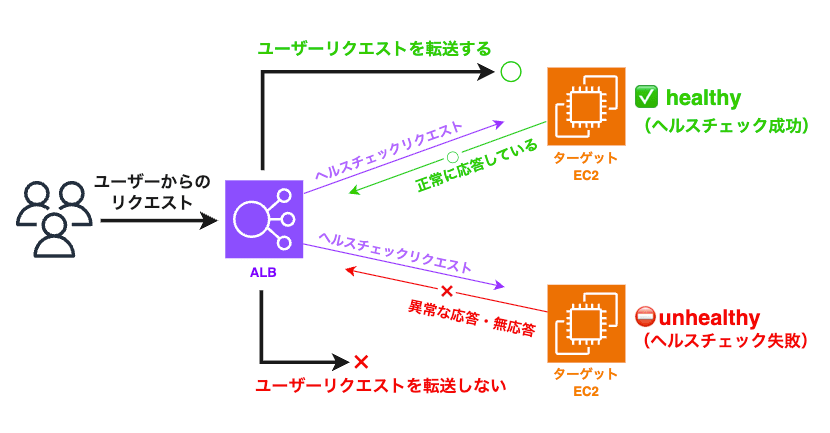
「ターゲット側がどのような状態なら正常、または異常であるか」は、ターゲットグループのヘルスチェック設定により定義されます。
ヘルスチェック設定
ヘルスチェックでユーザーが設定できる項目は以下になります。
| パラメータ | 説明 | デフォルト値 |
|---|---|---|
| プロトコル / ポート | ヘルスチェックリクエストの送信先 | HTTP / 80 |
| パス | リクエスト先の URL パス | / |
| 正常のしきい値(Healthy threshold) | healthy に戻るために必要な連続成功回数 |
5 回 |
| 非正常のしきい値(Unhealthy threshold) | unhealthy と判定するまでの連続失敗回数 |
2 回 |
| タイムアウト | 1 回のヘルスチェックで応答を待つ最大秒数 | 5 秒 |
| 間隔(Interval) | ヘルスチェックの送信間隔 | 30 秒 |
| 成功コード(Matcher) | 正常と見なすステータスコード | 200 |
以下は一般的な設定の例です。
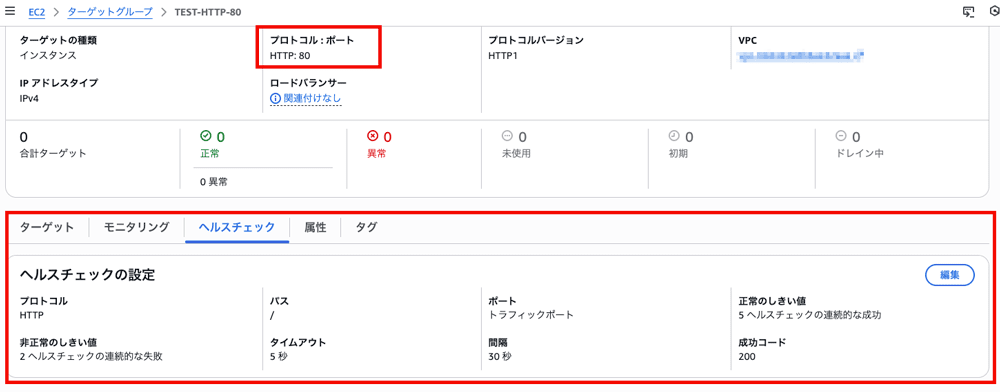
この場合は、「ターゲット上のパス /(ドキュメントルート)に対して HTTP:80 でヘルスチェックリクエストを 30 秒間隔で送信し、ターゲットが常にステータスコード 200 を返し続ける」ことが「正常」の定義になります。
この条件を満たさない場合は「異常」と見なされます。具体的には以下のような状況です。
- 成功コードで定義した 200 以外のステータスコード(302、404、502 など)がターゲット側から返される
- タイムアウトの 5 秒以内にターゲットが応答しない
- ALB とターゲットの間の通信で HTTP:80 の通信が遮断されている
これらの応答異常が非正常のしきい値(デフォルトは 2 回)に達すると unhealthy 状態となり、そのターゲットへリクエストが転送されなくなります。
ただし状態が変化し、正常応答が正常のしきい値(デフォルトは 5 回)に達すれば healthy 状態に戻り、再度リクエストが転送されるようになります。
参考資料:
2. ヘルスチェック失敗時に確認するログ
ヘルスチェック失敗時のトラブルシューティングに役立つ主なログは、以下のとおりです。
- ALB ヘルスチェックログ
- バックエンド Web サーバー(Apache、Nginx など)のアクセスログ
ALB で取得できるログには他にも「アクセスログ」や「接続ログ」がありますが、ヘルスチェック状況が記録されるのは「ヘルスチェックログ」のみです。
ヘルスチェックログは比較的最近(2025 年末)に実装されたため、有効化されていない方が多い印象ですが、トラブルシューティングに大変役立つため、有効化をおすすめします。
以下に、それぞれのログの詳細を説明します。
ALB ヘルスチェックログ
ALB から送信されたヘルスチェックの成否や、ターゲット側から返却されたステータスコードを最も明確に確認できるログです。
## 成功の例
http 2026-03-01T01:40:45.498155Z 0.001397553 172.31.1.138:80 test-alb-tg PASS 200 -
http 2026-03-01T01:41:15.528794Z 0.001409683 172.31.1.138:80 test-alb-tg PASS 200 -
## 失敗の例
http 2026-03-01T01:45:15.739468Z 0.001020884 172.31.1.138:80 test-alb-tg FAIL 502 TargetError
http 2026-03-01T01:45:45.767513Z 0.003360746 172.31.1.138:80 test-alb-tg FAIL 502 TargetError
ログの各フィールドは以下のとおりです。
| フィールド | 説明 | 上記例の値 |
|---|---|---|
| type | ヘルスチェックのプロトコル | http |
| timestamp | ヘルスチェック実行時刻(UTC) | 2026-03-01T01:40:45.498155Z |
| latency | ヘルスチェックの応答時間(秒) | 0.001397553 |
| target:port | ターゲットの IP アドレスとポート | 172.31.1.138:80 |
| target_group | ターゲットグループ名 | test-alb-tg |
| status | ヘルスチェック結果(PASS / FAIL) | PASS または FAIL |
| status_code | ターゲットから返されたステータスコード | 200 または 502 |
| reason | 失敗時の理由コード(成功時は -) |
- または TargetError |
失敗時の reason code から、原因の方向性を判断できます。
| reason code | 意味 | 主な原因 |
|---|---|---|
TimedOut |
ターゲットへの接続がタイムアウトした | セキュリティグループ、NACL、ターゲット停止 |
ConnectionReset |
ターゲットが接続をリセットした | アプリケーションのクラッシュ、プロセス再起動 |
ResponseCodeMismatch |
返されたステータスコードが成功コードと一致しない | アプリケーションエラー(4xx、5xx など) |
ResponseStringMismatch |
レスポンスボディが期待する文字列と一致しない | gRPC ヘルスチェック使用時 |
TargetError |
ターゲット側でエラーが発生した | アプリケーション内部エラー |
InternalError |
ALB 内部エラー | AWS 側の一時的な問題 |
詳細は以下のドキュメントをご覧ください。
参考資料:
バックエンド Web サーバーのアクセスログ
バックエンド Web サーバー側(apache、nginx 等)のアクセスログで、ヘルスチェックに応答した状況を確認できます。
以下の例のように、User-Agent が ELB-HealthChecker/2.0 になっているログが、ヘルスチェックに応答した記録です。
172.31.2.188 - - [01/Mar/2026:01:00:03 +0000] "GET / HTTP/1.1" 200 98 "-" "ELB-HealthChecker/2.0" "-"
172.31.2.188 - - [01/Mar/2026:01:30:03 +0000] "GET / HTTP/1.1" 200 98 "-" "ELB-HealthChecker/2.0" "-"
172.31.2.188 - - [01/Mar/2026:02:00:03 +0000] "GET / HTTP/1.1" 200 98 "-" "ELB-HealthChecker/2.0" "-"
## ヘルスチェックに応答していない時:特にエラーは記録されず、タイムスタンプの間隔が開く
172.31.2.188 - - [01/Mar/2026:05:23:16 +0000] "GET / HTTP/1.1" 200 98 "-" "ELB-HealthChecker/2.0" "-"
ただしこれはあくまでも「サーバー側がヘルスチェックに応答した記録」であり、「ALB がヘルスチェックを送信した記録」ではないことに注意しましょう。
もしサーバーがヘルスチェックに応答しなかった場合、明確なエラーは記録されず、上記例のようにタイムスタンプの間隔が開いた状態になります。
一見すると分かりにくいため「なぜ正常応答しているのにヘルスチェックに失敗するのか」とお問い合わせをいただくことがありますが、調べてみると多くの場合は上記例のように、応答ログが途切れていたり間隔が不規則になっている箇所があります。
そのため、Web サーバー側のアクセスログ(応答側)はあくまでも補助的なものとして、詳細調査を行うには前述の ALB ヘルスチェックログ(送信側)も併せて確認することをおすすめします。
参考資料:
3. ヘルスチェック失敗時のトラブルシューティング
ヘルスチェックが失敗する状況は、大きく分けて以下の 2 パターンがあります。
- ALB の構築時にヘルスチェックが成功しない(設定の問題)
- ALB の運用中に時々ヘルスチェックが失敗する(一時的な問題)
以下に、それぞれのパターンでの確認ポイントを紹介します。
ALB の構築時にヘルスチェックが成功しない
この場合は基本設定に問題がある可能性が高いため、AWS コンソール上から原因を特定できる場合があります。
ターゲットグループ画面の「ヘルスステータスの詳細」に表示されたメッセージを確認してみましょう。
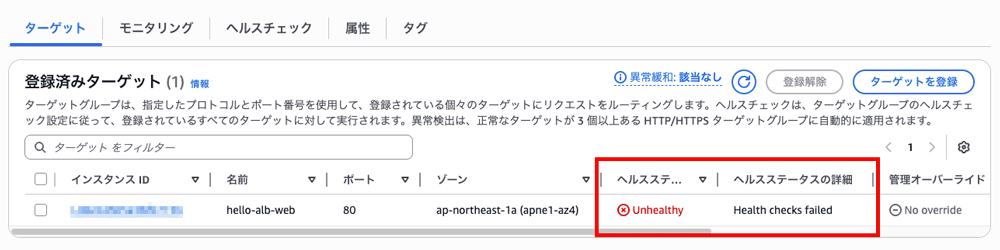
例えば、この欄に Request timed out と表示されている場合は、ALB からターゲットにヘルスチェックリクエストが届いていない可能性が高いです。
一方で、Health checks failed with these codes:[XXX] と表示されている場合は、ターゲットにヘルスチェックは届いているものの、サーバー内部から [XXX] のステータスコードが返されていることを示します。
メッセージから AWS 側、サーバー内部のどちらが原因か当たりを付けて、以下の点を確認してみましょう。
▪️AWS 設定の確認ポイント
- ALB からターゲットへの通信が、セキュリティグループで許可されているか
- ALB とターゲット EC2 の VPC やサブネットが異なっていたり、NACL などで制限されていないか
- ALB とターゲットが別 VPC にある構成(ターゲットタイプ:IP)では、VPC 間の相互接続が確保されているか
▪️バックエンドサーバー側の確認ポイント
- バックエンドサーバー内部で Apache、Nginx などが起動しているか
- ヘルスチェックに設定したポート(80、8080 など)をターゲット側で listen する設定になっているか
- ヘルスチェック先パスに、
index.htmlなどの応答可能なページが存在しているか - ヘルスチェック先パスから、成功コード(200)以外のステータスコードが返されていないか
- 例:リダイレクト設定により 301/302 が返されている、認証が必要なパスで 401/403 が返されている、など
表示されるメッセージの意味と対処方法は、以下の記事を参考にしてください。
- Health checks for Application Load Balancer target groups - Elastic Load Balancing
- ALB ヘルスチェックが "Health checks failed with these codes:[XXX]" で失敗する原因と対処法 | DevelopersIO
- ALB ヘルスチェックが "Request timed out" で失敗する原因と対処法 | DevelopersIO
- ALB ヘルスチェックが "Target is in an Availability Zone that is not enabled for the load balancer" で失敗する原因と対処法 | DevelopersIO
バックエンドサーバーに直接アクセスして原因を切り分けたい場合は、下記記事を参考にしてください。
ALB の運用中に時々ヘルスチェックが失敗する
「普段はヘルスチェックに成功している」という状況であるため、AWS の設定には基本的に問題なく、主にターゲット側の一時的な要因(アプリケーションの処理遅延など)が原因で発生します。
多くの場合「一時的にヘルスチェックに失敗していたが、今は回復している」という状況のため、当時の原因を調査するには「ヘルスチェックに失敗した当時のログを保持しているか」が重要になります。
▪️ALB ヘルスチェックログを有効化している場合
ALB ヘルスチェックログを有効化していれば、ヘルスチェックに失敗していた当時のターゲットの IP アドレス、失敗時刻、理由(reason code)を確認できます。これが最も明確な方法です。
http 2026-03-01T01:45:15.739468Z 0.001020884 172.31.1.138:80 test-alb-tg FAIL 502 TargetError
上記例では IP アドレス 172.31.1.138 を持つターゲット EC2 インスタンスが 502 エラーを返したため、ヘルスチェックに失敗したことを示しています。
▪️ALB ヘルスチェックログが無効の場合
ヘルスチェックログを有効化していなかった場合は、以下のような方法でヘルスチェックに失敗していたターゲットを推測します。
いずれも間接的な確認方法になるため、ALB のヘルスチェックログを取得していた場合と比較し、多くの調査が必要になります。
- CloudWatch でターゲットグループの
UnhealthyHostCountメトリクスを、ディメンションTargetGroup+AvailabilityZoneで確認する。unhealthyがカウントされている AZ から、対象ターゲットを推測する。 - 各 Web サーバーのアクセスログを調べて
ELB-HealthChecker/2.0への応答が途切れていた箇所や、応答ステータスコードが異常になっていた箇所がないか確認する(前項を参照) - ALB アクセスログで
UnhealthyHostContが発生していた時刻付近を抽出して、バックエンド側から 5xx 等のステータスコードが返されていたり、応答遅延が発生しているログを確認する。
https 2026-06-29T03:15:12.345678Z app/prod-alb/50dc6c495c0c9188 203.0.113.10:54321 10.0.2.25:8080 0.001 -1 -1 504 - 798 561 "GET https://example.com:443/api/slow HTTP/1.1" "curl/8.5.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2 arn:aws:elasticloadbalancing:ap-northeast-1:123456789012:targetgroup/prod-tg/73e2d6bc24d8a067 "Root=1-6860f0e0-abcdef0123456789abcdef01" "example.com" "arn:aws:acm:ap-northeast-1:123456789012:certificate/12345678-1234-1234-1234-123456789012" 1 2026-06-29T03:14:12.344000Z "forward" "-" "-" "10.0.2.25:8080" "-" "-" "-" TID_1234abcd5678ef90 "-" "-" "-"
上記例では IP アドレス 10.0.2.25 を持つターゲット EC2 インスタンスが、ALB のアイドルタイムアウトまでに応答しなかったため ALB が 504 を返している = ターゲットが応答していなかった、と判断できます。
上記いずれかの方法で UnhealthyHostCount の原因となった対象ターゲットを特定できたら、以下の観点で原因を調査します。
▪️AWS サービス側の調査
unhealthy になっていた時間帯のターゲット EC2 インスタンスのメトリクスで、以下のような異常がないか確認します。
| 確認するメトリクス | 確認する内容 |
|---|---|
StatusCheckFailed |
EC2 のステータスチェックが失敗していないか(基盤障害の可能性) |
CPUUtilization |
CPU 使用率が高騰していないか |
NetworkIn / NetworkOut |
ネットワークトラフィックに異常がないか |
▪️サーバー内部の調査
CloudWatch メトリクスで明確な異常が見つからない場合は、ターゲット内部のログを確認します。ヘルスチェックに失敗していた時刻付近で、サーバー内部に何か異常なログが出ていないかを確認します。
これは EC2 内部の OS やアプリケーションに大きく依存するため、本記事では一例の紹介にとどまりますが、一般的に以下のようなログが調査対象になります。
| 確認するログ | 主な確認内容 |
|---|---|
| Web サーバーアクセスログ | ELB-HealthChecker/2.0 の応答が途切れていないか、ステータスコード、応答時間 |
| Web サーバーエラーログ | 5xx、リバースプロキシ先への接続失敗、タイムアウト、プロセス数上限 |
| アプリケーションログ | ヘルスチェックパス処理時の例外、DB 接続エラー、外部 API 待ち |
| システムログ | OOM Killer、サービス再起動、カーネルエラー、ディスク枯渇 |
| systemd journal | nginx、httpd、アプリケーションサービスの再起動・クラッシュ |
OS 側の問題としては、OOM Killer によるプロセス終了、ディスク枯渇、カーネルレベルのエラーなどが原因になることがあります。
Amazon Linux 2 などでは /var/log/messages、Ubuntu では /var/log/syslog、Amazon Linux 2023 では journalctl を中心に確認します。
Mar 01 01:45:11 ip-172-31-1-138 kernel: Out of memory: Killed process 2345 (java) total-vm:2048000kB, anon-rss:1536000kB, file-rss:0kB, shmem-rss:0kB
Mar 01 01:45:11 ip-172-31-1-138 systemd[1]: myapp.service: Main process exited, code=killed, status=9/KILL
上記例では、メモリ不足によりアプリケーションプロセスが強制終了され、ヘルスチェックに失敗した可能性があります。
Mar 01 01:45:20 ip-172-31-1-138 myapp[2345]: write /var/log/myapp/app.log: no space left on device
Mar 01 01:45:21 ip-172-31-1-138 nginx[1234]: 2026/03/01 01:45:21 [crit] 1234#1234: *100 open() "/var/lib/nginx/tmp/proxy/1/00/0000000001" failed (28: No space left on device)
上記例では、ディスク枯渇によりアプリケーションや Web サーバーが正常に動作できず、ヘルスチェックが失敗している可能性があります。
参考資料:
さいごに
いかがでしたでしょうか。
ALB のヘルスチェック失敗は調査するべき範囲が広いですが、仕様を理解していれば大体の原因箇所に当たりを付けられる場合が多いので、本記事が仕様を理解するための一助になれば幸いです。
特にトラブルシューティングにおいては、当時のログを取得していたかどうかにより調査に要する時間が大きく異なります。
ALB アクセスログしか取得していない、というパターンが多く見られますが、ALB ヘルスチェックログも大いに役立つため、ぜひ有効化をお勧めします。
また、ALB と EC2 Auto Scaling を組み合わせた場合や NLB(Network Load Balancer)のヘルスチェック失敗については異なる考慮が必要になり、本記事では書ききれませんでしたが、また機会があれば記事にしたいと思います。
本記事が、ALB ヘルスチェック失敗時の原因切り分けやログ設計の参考になれば幸いです。
クラスメソッドオペレーションズ株式会社について
クラスメソッドグループのオペレーション企業です。
運用・保守開発・サポート・情シス・バックオフィスの専門チームが、IT・AIをフル活用した「しくみ」を通じて、お客様の業務代行から課題解決や高付加価値サービスまでを提供するエキスパート集団です。
当社は様々な職種でメンバーを募集しています。
「オペレーション・エクセレンス」と「らしく働く、らしく生きる」を共に実現するカルチャー・しくみ・働き方にご興味がある方は、クラスメソッドオペレーションズ株式会社 コーポレートサイト をぜひご覧ください。
※2026年1月 アノテーション㈱から社名変更しました








