
AWS Cost Anomaly Detectionが得意なこと・苦手なこと
はじめに
お疲れ様です、データ事業本部の小高です。
複数のAWSアカウントを管理している中で、コスト監視のサービスを検討していたところ
AWSにはマネージドのコスト異常検知サービスとしてAWS Cost Anomaly Detectionに行き着きました。
こちらはMLベースで監視をしてくれて、無料のサービスになります。
これだけ聞くと導入しない理由がなさそうですが、実際に検証してみると「できること」と「できないこと」がわかりましたので、
本記事では、実際の検証結果をもとにCost Anomaly Detectionの得意分野と苦手分野をまとめてみました。
そもそもCost Anomaly Detectionとは
MLが過去のコストパターンを学習し、そこから逸脱したコスト変動を「異常」として検出するマネージドサービスです。新しいサービスの検知には最低10日間の履歴データが必要です。Cost Explorerに含まれており、追加料金なしで利用できます。検知は1日約3回、Cost Explorerのデータ更新後に実行されます。
検知の仕組み(2段階)
検知は2段階で動作します。
- 異常の検出: MLが過去パターンと比較して異常かどうかを判定する
- しきい値による通知判定: 異常の合計影響額(Total Impact)がしきい値を超えた場合に通知する
この2段階の仕組みは、検証結果のセクションで実例とあわせて詳しく説明します。
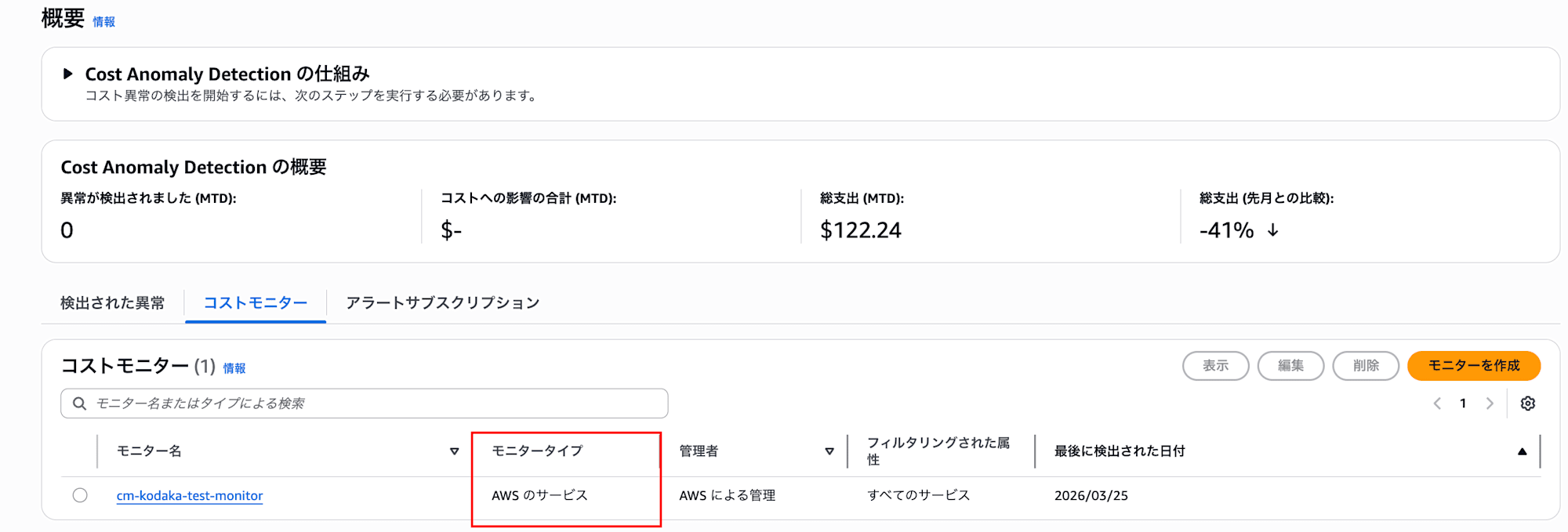
モニタータイプ
監視対象の粒度に応じて4種類のモニタータイプが用意されています。
| モニタータイプ | 監視対象 | 備考 |
|---|---|---|
| AWSサービスモニター | 全AWSサービスを個別に追跡 | アカウントに1つだけ作成可能 |
| 連結アカウントモニター | 個別またはグループ指定のアカウント | Organizations環境向け |
| コスト配分タグモニター | タグのキー/値ペアで追跡 | タグ運用が整っている場合に有効 |
| コストカテゴリモニター | カスタム分類で追跡 | コストカテゴリの事前定義が必要 |
今回の検証ではAWSサービスモニターを使用しました。
アラートサブスクリプション
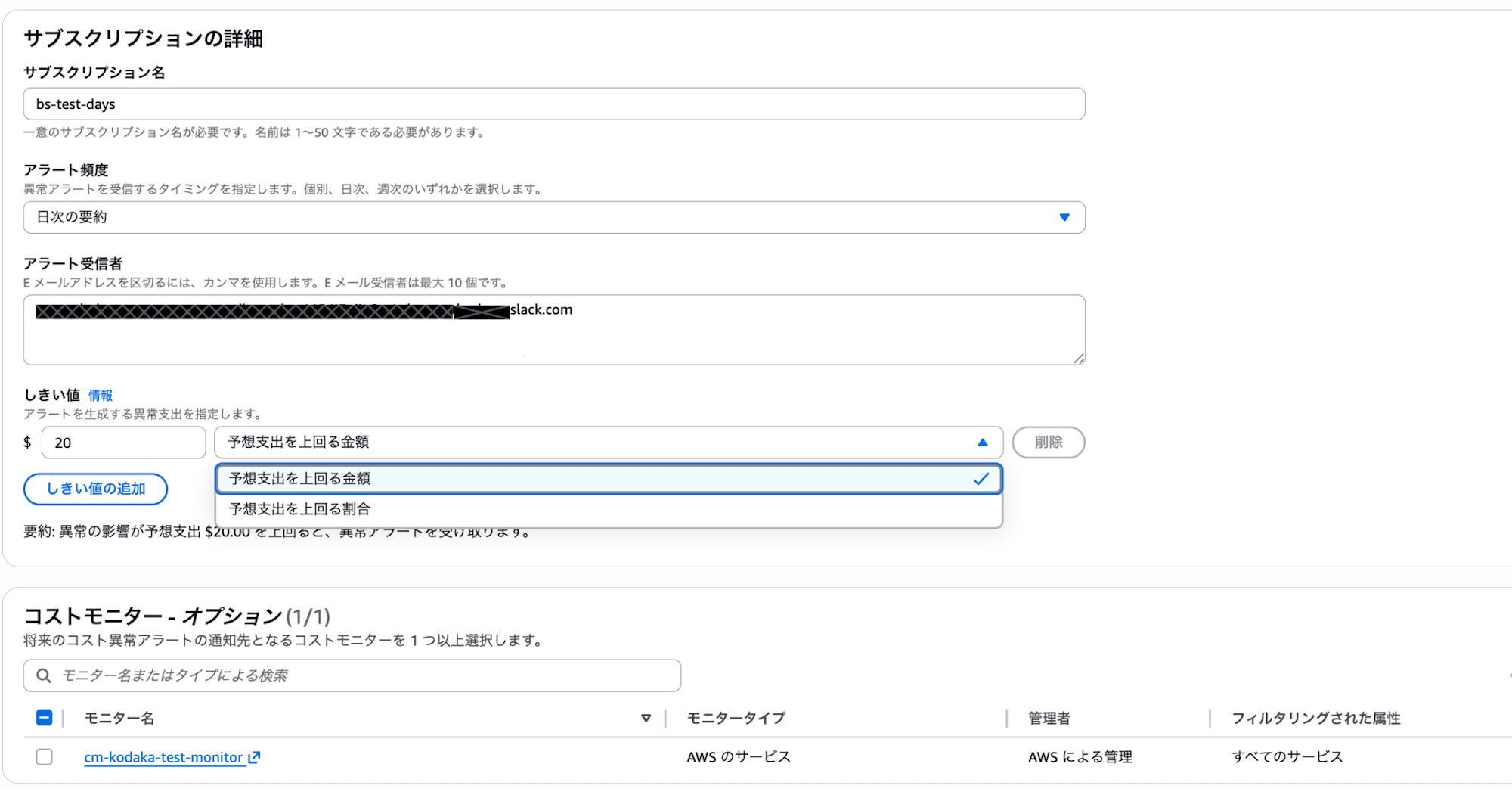
アラートサブスクリプションでは、以下を設定します。
- しきい値: 金額(例: $20以上)、割合(例: 80%超過)、またはその両方のAND/OR条件
- 通知頻度: 個別アラート / 日次要約 / 週次要約 の3択。個別アラートはSNSトピックが必須(メール不可)
- 通知先: メール(最大10アドレス)、SNSトピック、またはその両方。
検証してみた
検証設定
| 項目 | 設定内容 |
|---|---|
| モニタータイプ | AWSサービスモニター |
| サブスクリプション名 | bs-test-days |
| しきい値 | $20(予想支出を上回る金額) |
| 通知頻度 | 日次要約 |
| 通知先 | Slackチャンネルのメールアドレスを登録 |
何が起きたか
検証期間中に、VPCエンドポイント(東京リージョン)で約$4〜5/日の異常コストが発生しました。この事例を通じて、先ほど触れた2段階の検知の仕組みがどう動くかを見ていきます。
第1段階: 異常の検出
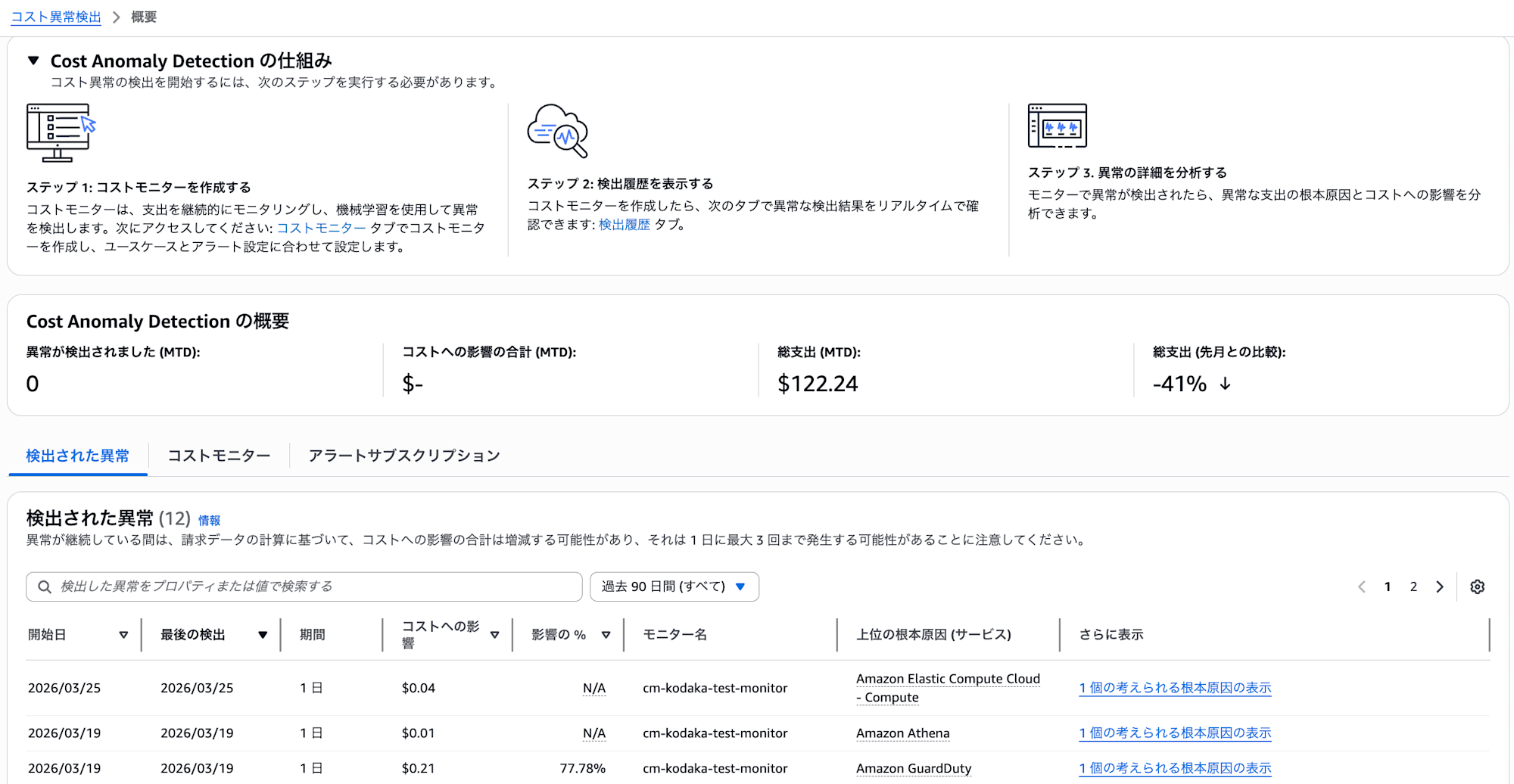
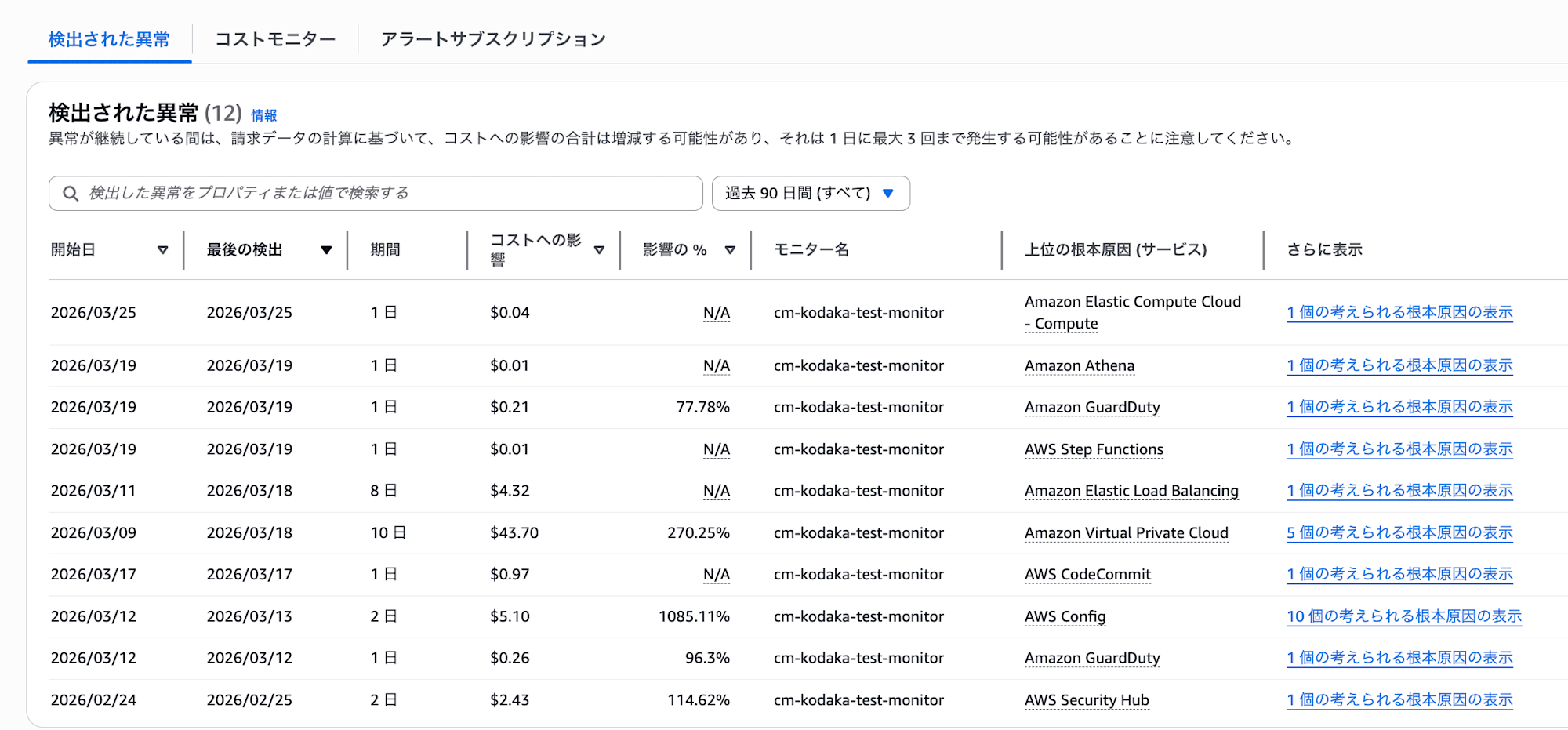
まず、MLがVPCエンドポイントのコスト変動を「異常」と判定しました。コンソールの「検出された異常」画面を見ると、VPCエンドポイント以外にも$0.01や$0.04といった小額の異常も検出されていることが分かります。
ただし、この段階ではまだ通知は来ません。検出されただけです。
第2段階: しきい値による通知判定
検出された異常の合計影響額がアラートサブスクリプションのしきい値(今回は$20)を超えて、初めて通知が送られます。逆に、異常として検出されていてもしきい値未満であれば通知は来ず、コンソールの「検出された異常」でのみ確認できます。
また、MLが異常と判定しなければ、しきい値をいくら低く設定しても通知対象にはなりません。
時系列で整理します。
| 日付 | 出来事 |
|---|---|
| 3/9 | 異常コスト発生開始(約$4〜5/日) |
| 3/9〜15 | 第1段階でMLは異常を検出済み。ただし合計影響額がしきい値$20未満のため第2段階で通知されず |
| 3/16 | 合計影響額$28.99でしきい値$20を超過。最初の通知 |
| 3/16 | VPCエンドポイントを削除 |
| 3/16〜20 | 削除後も毎日アラートが発生。3/19時点で合計影響額$43.70 |
| 3/21〜 | MLが再学習し、通知停止 |
しきい値と通知タイミング
今回、約$4〜5/日の異常に対してしきい値を$20に設定していたため、合計影響額が$20を超える3/16まで通知が来ませんでした。結果として異常開始から7日後の通知です。しきい値を下げれば通知は早くなりますが、その分ノイズも増えるため、バランスの調整が必要です。
なお、この間もコンソール上の「検出された異常」には記録されていたので、コンソールを確認すれば気づくことはできます。
Slackへの通知内容
Slackに届いた通知には以下の情報が含まれていました。
- Anomaly Detected For: 異常が検出されたサービス名(Amazon Virtual Private Cloud)
- Date: 開始日、最終検出日、期間
- Cost Impact: 1日あたりの最大影響額(Max Daily Impact)と合計影響額(Total Impact)
- Root Cause(s): 根本原因の候補(サービス、アカウント、リージョン、UsageType、影響額)
- Monitor Details: モニター名とタイプ
- Next Steps: 根本原因の詳細へのリンク
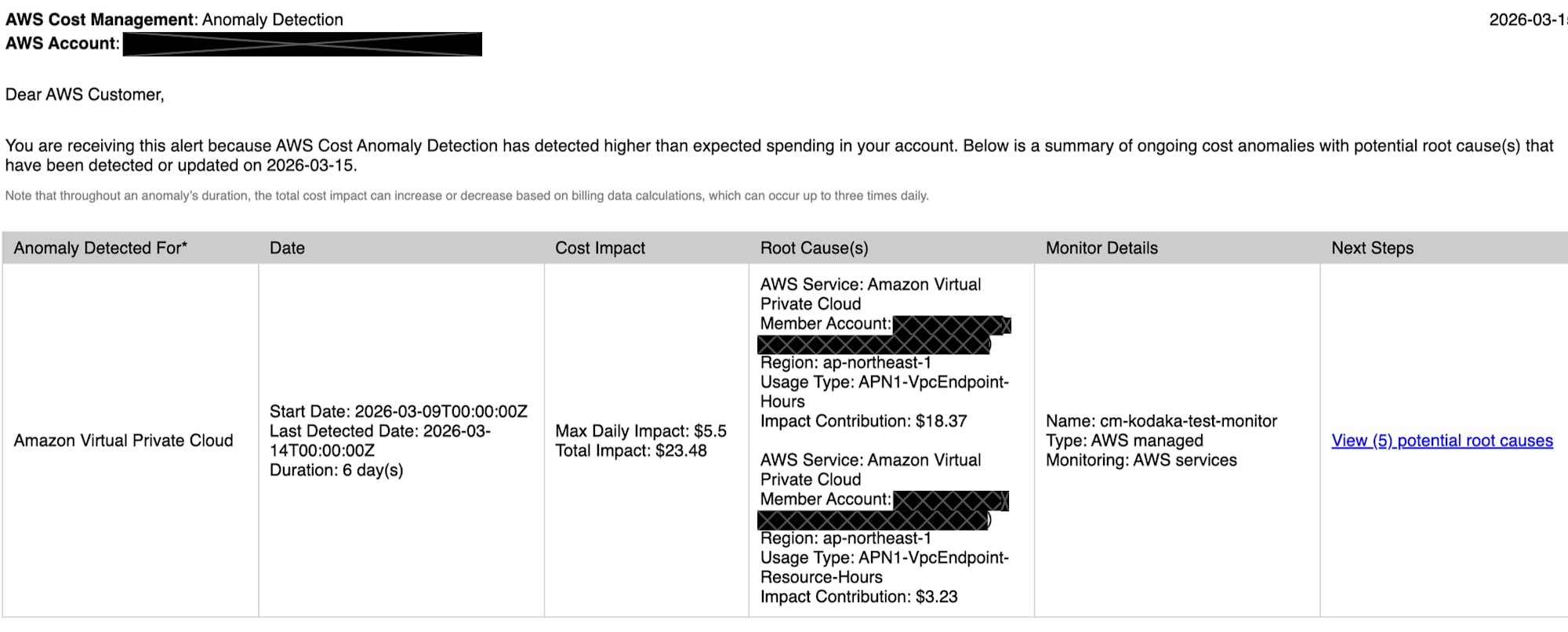
通知の粒度としてはUsageTypeまでです。「どのVPCエンドポイントが原因か」というリソースIDレベルの情報は含まれていません。
リソース削除後も通知が続いた
VPCエンドポイントは3/16に削除しましたが、3/20まで毎日アラートが発生し続けました。3/21以降にようやく通知が止まっています。MLがコスト変動のパターンを再学習し、異常と判定しなくなったためです。
これはMLベースの検知ならではの挙動です。対処が完了しても即座には通知が止まりません。また裏を返すと、削除せずに放置していた場合はMLが「正常」と学習して通知が止まってしまうということでもあります。
得意なこと
1. 想定外のコスト急増を自動で拾える
ルールを事前に定義しなくても、MLが「いつもと違う」変動を検知します。新しいサービスの利用開始時も自動で追跡対象になるため、「監視対象に入れ忘れた」という漏れがありません。
2. 無料で、運用保守が不要
Cost Explorerの機能として提供されているため追加料金はゼロ。マネージドサービスなのでコードの保守やランタイムの更新も不要です。一度設定すれば基本的に放置できます。
3. Organizations全体を一括で監視できる
管理アカウントからモニターを設定すれば、アカウントが増えても自動追跡されます。アカウント追加のたびに監視設定を追加する必要がありません。
4. 季節性やトレンドを考慮してくれる
MLが週次・月次の季節性や自然な成長傾向を学習するため、毎月末にコストが上がるようなパターンを誤検知しにくくなっています。
苦手なこと
1. 小額のじわじわ増加は検知しにくい
MLは過去のパターンとの乖離で異常を判定するため、少しずつコストが増えていくケースではそもそも「異常」として検出されない可能性があります。検出されなければしきい値の設定に関係なく通知は来ません。
2. 定点観測ができない
「今月いくら使っているか」「サービス別の内訳はどうか」といった日常的なコスト把握には使えません。Cost Anomaly Detectionはあくまで異常検知サービスであり、「異常がなければ何も通知しない」が基本動作です。
日次・月次のコスト状況を定期的に把握したい場合は、別の仕組みが必要です。
ちょうどこのブログを書いている時にメンバーからピッタリの記事を共有してもらいました。
今回は特に言及はしませんが、参考になるかもしれません。
3. 不要リソースの垂れ流しに気づけない
継続的に発生しているコストはMLが「正常」と学習します。
例えば、使っていないQuickSightユーザーやEBSボリュームが月々課金され続けていても、それが安定したコストであれば検知対象になりません。今回の検証でもVPCエンドポイントを放置し続けていたら、いずれMLが正常と判断して通知が止まっていたはずです。
4. リソース単位のしきい値設定ができない
しきい値はアラートサブスクリプション単位でしか設定できません。「このサービスは$5、あのサービスは$50」といった粒度の制御は不可能です。金額と割合のAND/OR条件は設定できますが、あくまでサブスクリプション全体に対する設定です。
5. 原因特定はUsageTypeまで
根本原因分析で提供される情報はサービス・リージョン・利用タイプ(UsageType)の粒度です。「どのリソース(リソースID)が原因か」までは特定できません。今回の検証でも「VPCエンドポイントが原因」までは分かりましたが、どのエンドポイントかはコンソールで自分で調べる必要がありました。
結局どう使うべきか
Cost Anomaly Detectionの本質は「想定外のコスト急増に対するセーフティネット」です。定点観測や不要リソースの棚卸しまで包括的に行うサービスでありません。
以下のような使い方がオススメです。
独自のコスト監視がないチーム・アカウントのガードレール。 まだ何も監視していないなら、まずこれを入れるだけで最低限の異常検知が手に入ります。無料で設定も数分なので、導入のハードルはほぼありません。
既存の監視との併用でセーフティネットとして使う。 既にルールベースや独自の監視手段を持っている場合でも、ルールに定義されていない想定外の異常をカバーする役割として追加できます。無料なので併用のコストもゼロです。
まとめ
AWS Cost Anomaly Detectionは、MLベースで無料のコスト異常検知サービスです。想定外の急増を自動で拾えるセーフティネットとしては有効です。無料で運用負荷もないため、導入のハードルは低いです。
ただし、これだけでコスト管理が完結するものではありません。他のサービスと組み合わせることで、異常検知・予算管理・定点観測をカバーできるようになります。








