
AWS Lambda Managed Instances でデフォルトの CPU 使用率ベースのスケーリングの挙動を確認してみた
こんにちは、製造ビジネステクノロジー部の若槻です。
AWS Lambda Managed Instances (LMI) でのスケーリングの仕様を調べるために公式ドキュメントを当たってみました。
Managed Instances currently scales based on CPU resource utilization and multi-concurrency saturation.
上記によると、スケーリングは次の2つの要素に基づき行われるとのこと。
- CPU 使用率
- 同時実行数の飽和
As traffic flows into your application, execution environments consume resources. The Lambda Agent notifies the Scaler, which decides whether to scale new execution environments or Managed Instances.
さらに上記によると、スケーリング対象は次のいずれかであるとのこと。
- 新しい実行環境
- マネージドインスタンス
これらを見るに、スケーリングの挙動にはいくつかパターンがありそうですね。
ちなみに前回は PerExecutionEnvironmentMaxConcurrency の値を最小にした上で「同時実行数を飽和」させたところ、「新しい実行環境のスケールのみ」が行われる挙動となりました。
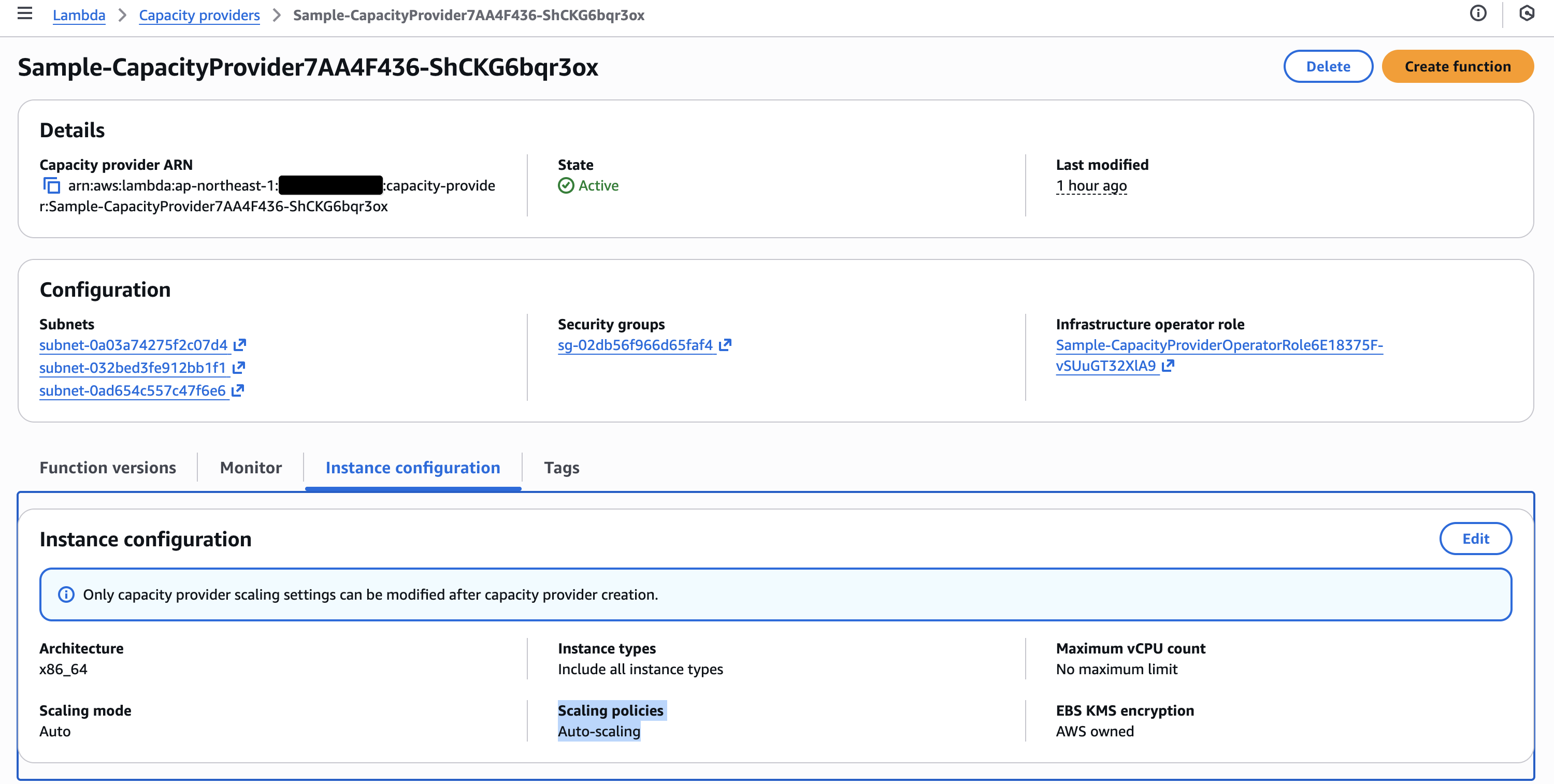
さらに、キャパシティプロバイダーのスケーリング設定は CPU 使用率やメモリ使用率に基づくスケーリングポリシーを定義可能です(CPU だけでは無いのか?)。デフォルトは「自動スケーリング (Auto)」となっており、サービス側でマネージドにスケーリングが行われます。
CapacityProviderScalingConfig
Configure how Lambda scales your instances:
- ScalingMode: Set to
Autofor automatic scaling orManualfor manual control. Default isAuto.- MaxVCpuCount: Maximum number of vCPUs for the capacity provider. Default is 400.
- ScalingPolicies: Define target tracking scaling policies for CPU and memory utilization
今回は、前回確認できなかった部分でもある、AWS Lambda Managed Instances でデフォルト「自動スケーリング (Auto)」時の CPU 使用率に基づくスケーリングの挙動を確認してみました。
やってみた
ハンドラーコード
Lambda 関数のハンドラーコードは以下の通りです。
export const handler = async (): Promise<void> => {
const start = Date.now();
// 約50秒間、CPUを使い続ける(イベントループをブロック)
while (Date.now() - start < 50_000) {
Math.sqrt(Math.random());
}
};
約50秒間 CPU を使い続ける、CPU ヘビーな負荷を発生させる処理を実装しています。
インフラ実装
インフラ実装には AWS CDK を使用しました。
VPC は予め作成したものを使用します。
VPC 定義コード
import * as ec2 from "aws-cdk-lib/aws-ec2";
import { Construct } from "constructs";
/**
* VPC 実装
*
* MEMO: VPC から各種 AWS サービスへのネットワーク経路確保のために NAT Gateway を配置する
*/
export class VpcConstruct extends Construct {
public readonly vpc: ec2.Vpc;
constructor(scope: Construct, id: string) {
super(scope, id);
this.vpc = new ec2.Vpc(this, "Default", {
subnetConfiguration: [
/**
* NAT Gateway を配置するためのパブリックサブネット
*/
{
name: "Public",
subnetType: ec2.SubnetType.PUBLIC,
},
/**
* Lambda 関数を配置するためのプライベートサブネット
*/
{
name: "PrivateWithEgress",
subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS,
},
],
});
}
}
CDK スタック全体のソースコードは以下となります。
import * as cdk from "aws-cdk-lib";
import * as ec2 from "aws-cdk-lib/aws-ec2";
import * as lambda from "aws-cdk-lib/aws-lambda";
import * as lambda_nodejs from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
import { VpcConstruct } from "./constructs/vpc";
export class SampleStack extends cdk.Stack {
constructor(scope: Construct, id: string, props: cdk.StackProps) {
super(scope, id, props);
/**
* VPC 作成
*/
const vpcConstruct = new VpcConstruct(this, "Vpc");
const vpc = vpcConstruct.vpc;
/**
* セキュリティグループ作成
*/
const securityGroup = new ec2.SecurityGroup(this, "SecurityGroup", {
vpc,
});
/**
* Capacity Provider 作成
*/
const capacityProvider = new lambda.CapacityProvider(
this,
"CapacityProvider",
{
subnets: vpc.selectSubnets({
subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS,
}).subnets,
securityGroups: [securityGroup],
}
);
/**
* LMI 用 Lambda 関数作成
*/
const lmiFunction = new lambda_nodejs.NodejsFunction(this, "LmiFunction", {
entry: "src/handler.ts",
runtime: lambda.Runtime.NODEJS_24_X, // LMI では Node.js 22.x 以上が必須
});
/**
* Capacity Provider に Lambda 関数を追加
*/
capacityProvider.addFunction(lmiFunction);
}
}
上記デプロイによりリソースを作成します。
scalingOptions が未設定のため、キャパシティプロバイダーのスケーリングモードはデフォルトの「自動スケーリング (Auto)」となります。
動作確認
今回は徐々にトラフィックを増加させるなどの器用なことはせず、シンプルに AWS CLI を使って並列で関数を 30 回呼び出すスパイク的な負荷投入を行いました。
負荷投入方法としては、次のコマンドを実行するだけです。
for i in {1..30}; do
aws lambda invoke \
--function-name ${FUNCTION_NAME} \
--invocation-type Event \
--region ap-northeast-1 \
output_$i.json
done
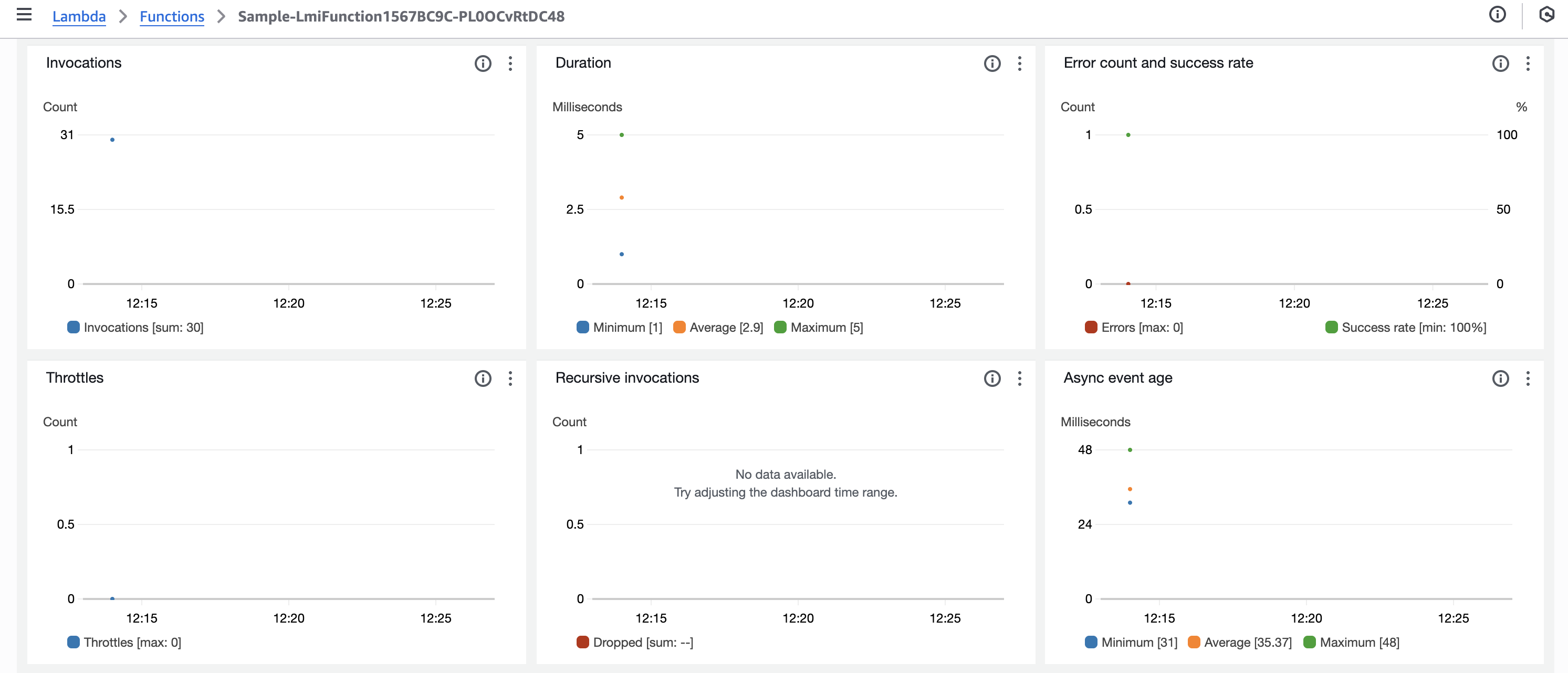
Lambda 関数のメトリクス
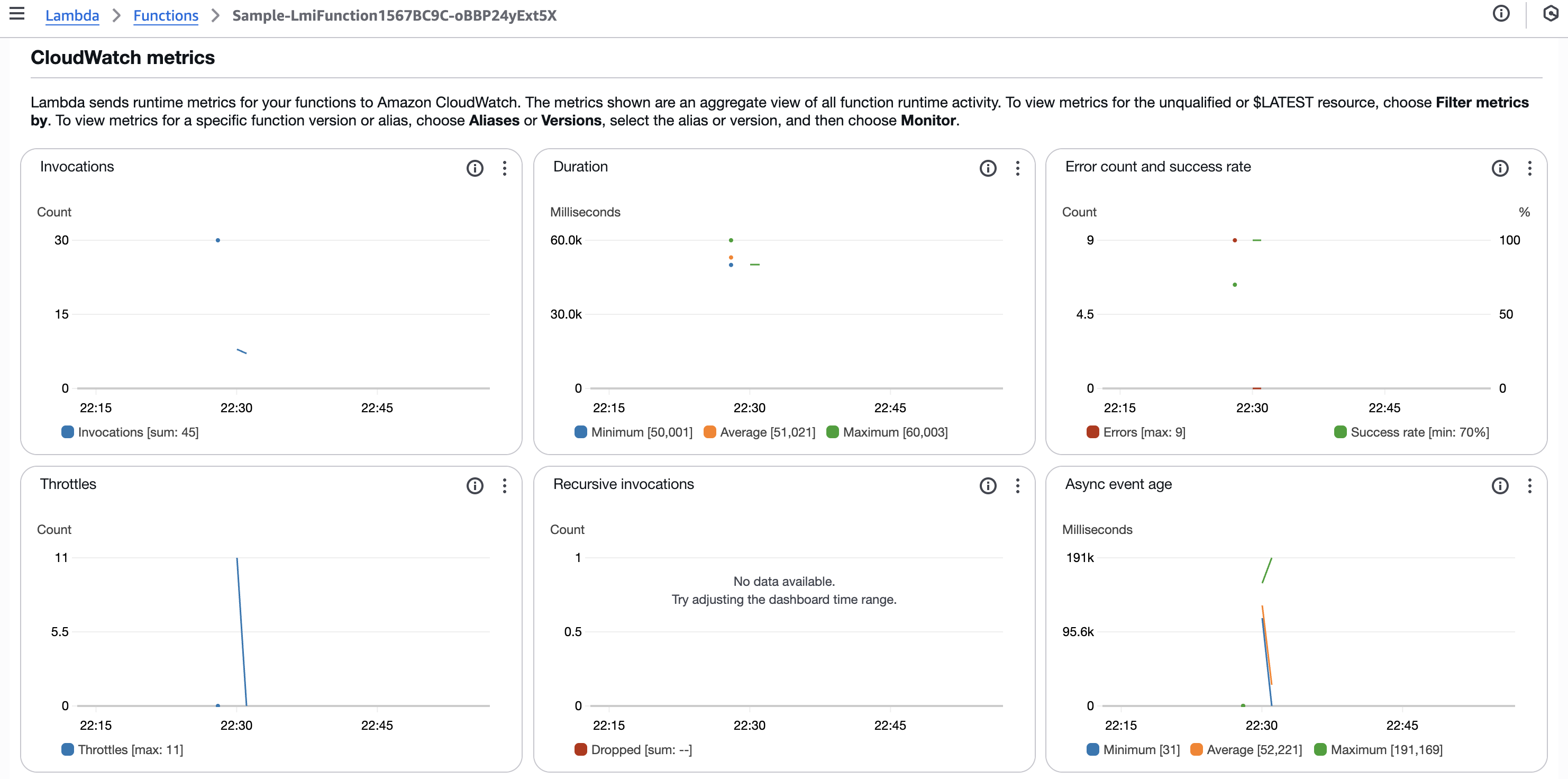
負荷投入後の Lambda 関数のメトリクスは以下のようになりました。
- Invocations
- Duration
- Error count and success rate
- Throttles
- Recursive invocations
- Async event age
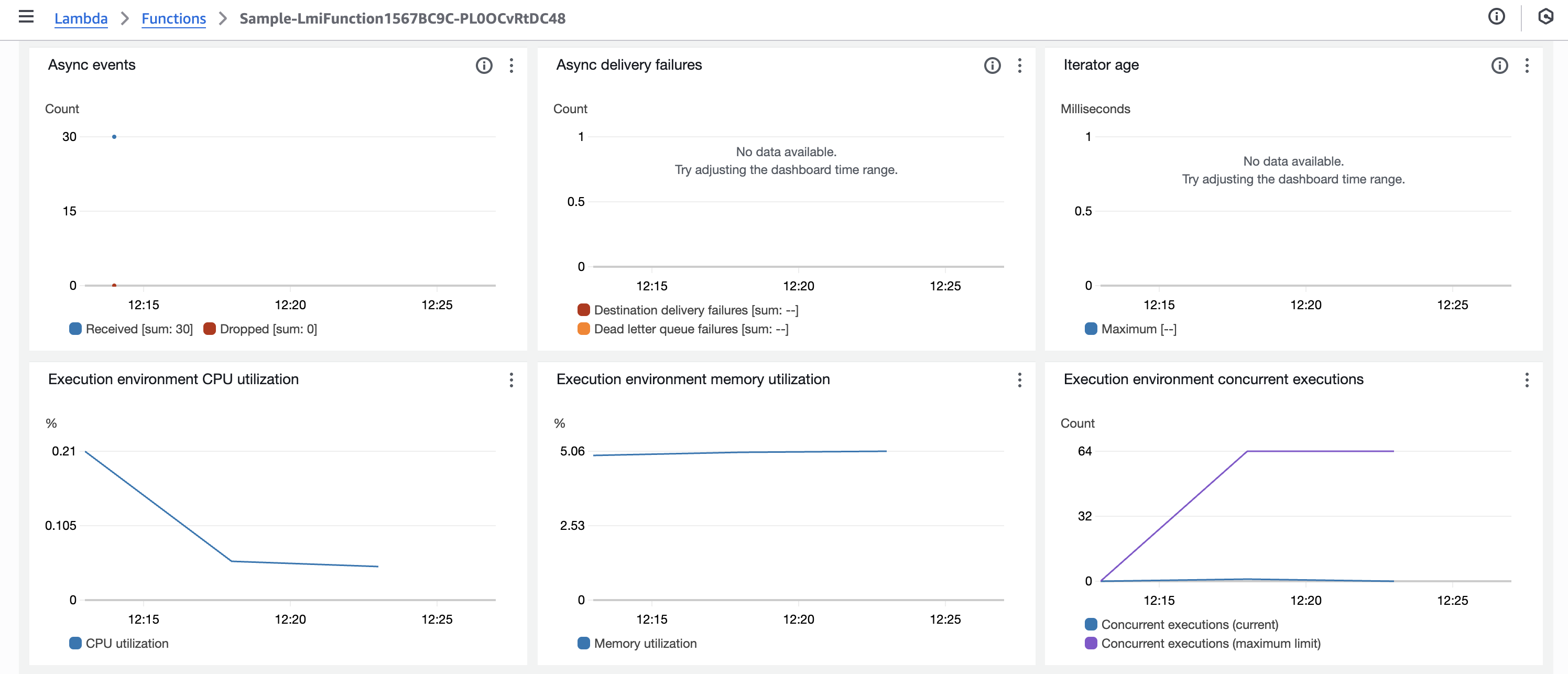
- Async events
- Async delivery failures
- Iterator age
- Execution environment CPU utilization
- Execution environment memory utilization
- Execution environment concurrent executions
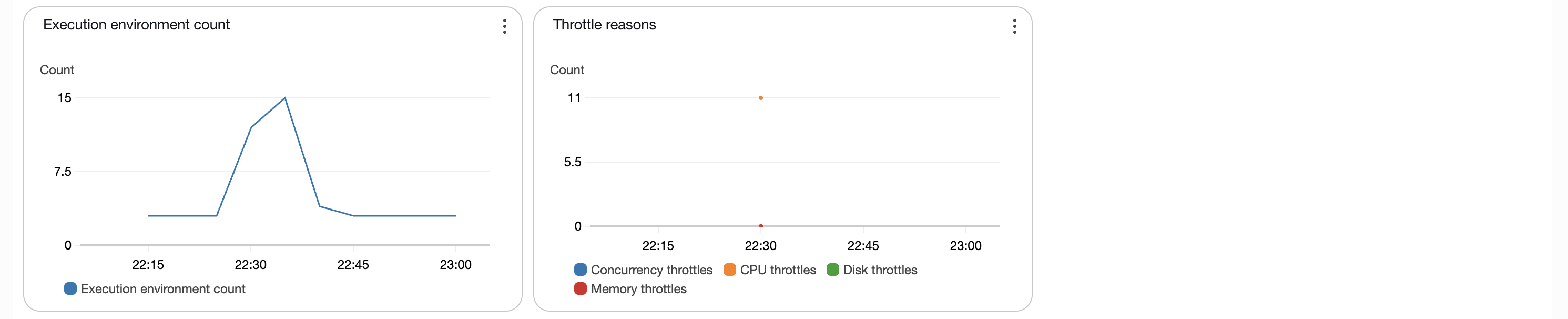
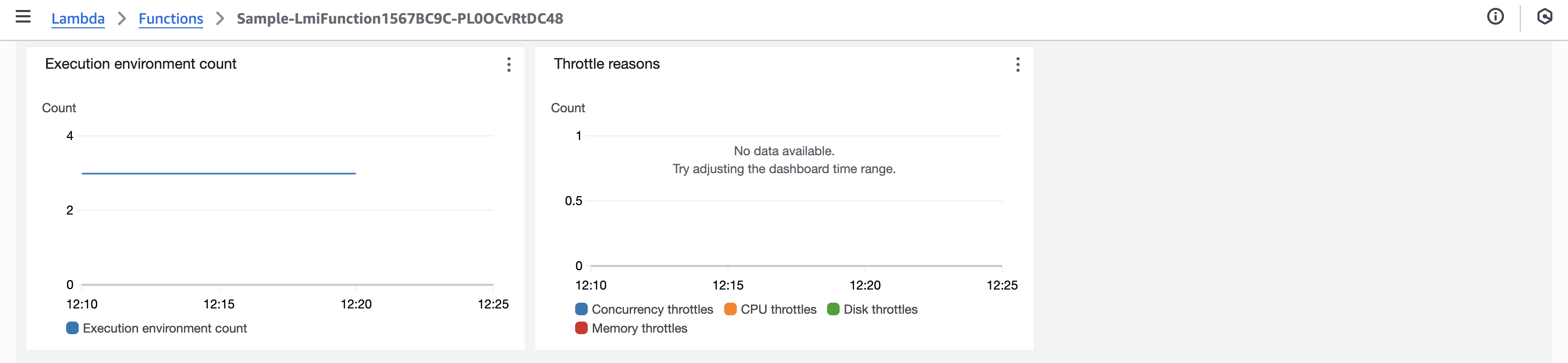
- Execution environment count
- Throttle reasons
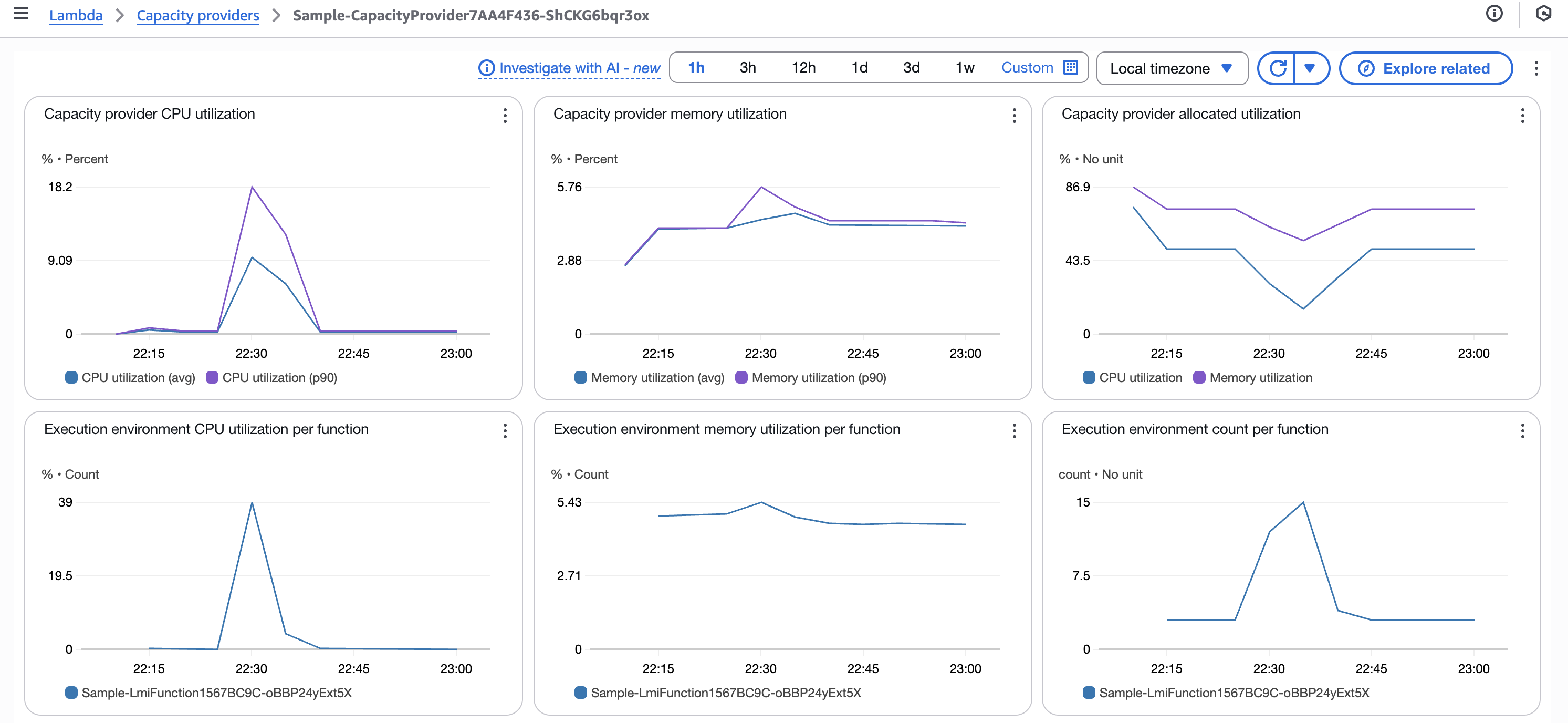
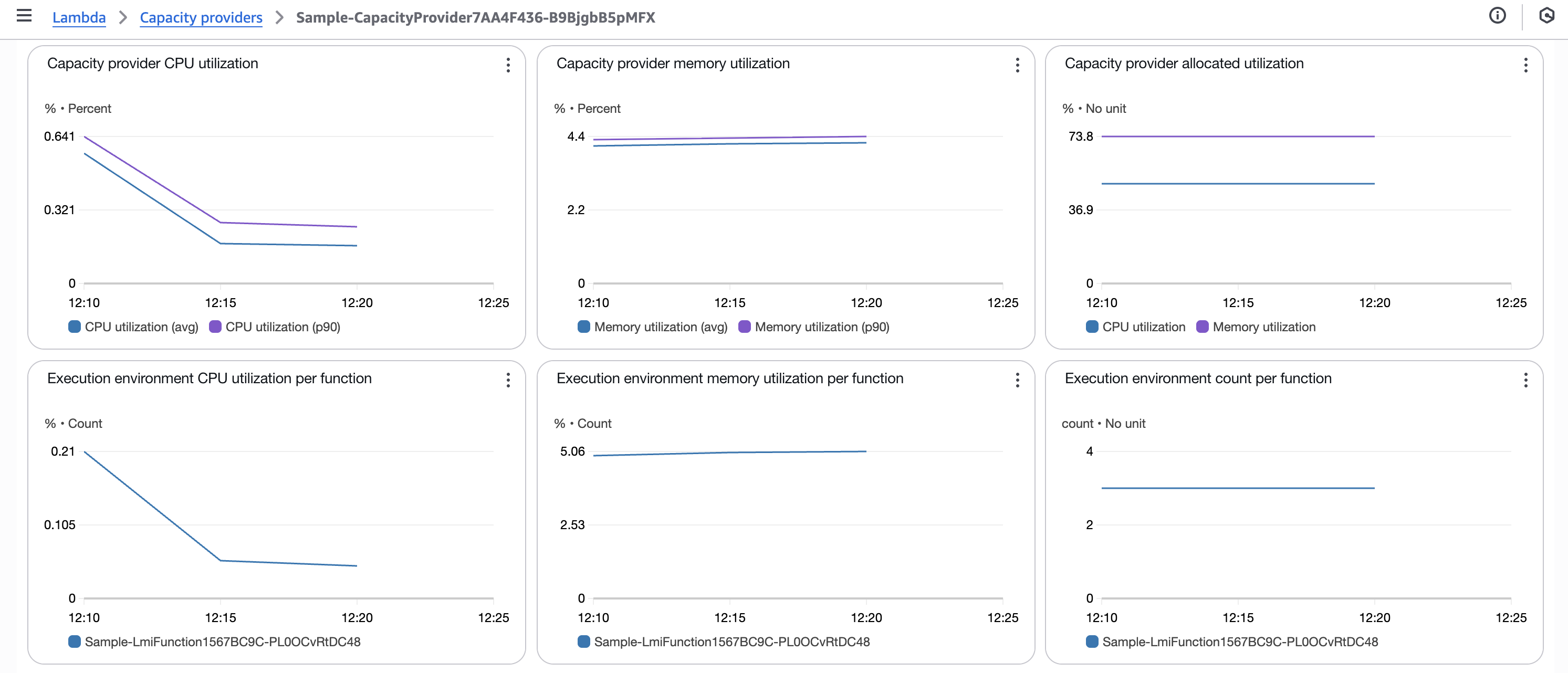
Capacity Provider のメトリクス
負荷投入後のキャパシティプロバイダーのメトリクスは以下のようになりました。
- Capacity provider CPU utilization
- Capacity provider memory utilization
- Capacity provider allocated utilization
- Execution environment CPU utilization per function
- Execution environment memory utilization per function
- Execution environment count per function
- Capacity provider instance counts

スケーリングの挙動まとめ
前述のメトリクスから、今回のスケーリングの挙動をまとめると以下のようになります。
- Lambda 設定
- 関数
- Maximum concurrency per execution environment: デフォルト値 (
64) - Execution environment memory (GiB) per vCPU: デフォルト値 (
2)
- Maximum concurrency per execution environment: デフォルト値 (
- キャパシティプロバイダー
- スケーリングポリシー: デフォルト値 (Auto)
- 関数
- 初期状態
- マネージドインスタンス: m7a.xlarge ×
3台 - 実行環境:
3環境
- マネージドインスタンス: m7a.xlarge ×
- 負荷投入
- 投入時刻: 22:30
- 投入内容: 関数を並列で
30回呼び出し
- 負荷投入後のリソース使用率の変化
- CPU 使用率:
0から39%まで上昇 - メモリ使用率:
5%前後で安定
- CPU 使用率:
- スケーリングの挙動
- マネージドインスタンス: m7a.xlarge ×
3台 + m7i.xlarge ×2台 にスケールアウト- 2つのインスタンスタイプの混在状態となったが、時間単価やスペックはほぼ同等
- 実行環境:
15環境までスケールアウト
- マネージドインスタンス: m7a.xlarge ×
- スロットル
- CPU 使用率の上昇に伴い、
11件のスロットルが発生
- CPU 使用率の上昇に伴い、
ここで、起動された2つのインスタンスタイプの仕様は以下の通りです。
| インスタンス名 | オンデマンド時間単価 | vCPU | メモリ |
|---|---|---|---|
| m7a.xlarge | USD 0.29946 | 4 | 16 GiB |
| m7i.xlarge | USD 0.2604 | 4 | 16 GiB |
(比較)CPU ヘビーでない負荷時はスロットルは発生せず
比較として、ハンドラーコードを以下のように CPU ヘビーでない処理に変更した場合のメトリクスも確認しました。
export const handler = async (): Promise<void> => {
console.log("Hello, world!");
};
その場合は、同じ負荷リクエスト(並列で関数を 30 回呼び出す)を掛けた場合でも、スロットルやエラーは発生せず、スケーリングも発生しませんでした。
メトリクス

考察
CPU 使用率の上昇に伴いマネージドインスタンスのスケールアウトが発生し、それに伴い実行環境のスケールアウトも発生しています。今回は CPU ヘビーな負荷を投入したため、CPU 使用率の上昇がスケーリングのトリガーとなったと考えられます。
また CPU 使用率が 40% 未満に留まっているにも関わらずスロットルが発生したのは、実行環境ごとに割り当てられる vCPU 数が限られており、新しい実行環境のスケールアウトが追いつかなかったためと推測されます。
おわりに
AWS Lambda Managed Instances でデフォルトの CPU 使用率ベースのスケーリングの挙動を確認してみました。スケーリングポリシーがデフォルトの「自動スケーリング (Auto)」の場合、CPU 使用率が 40% 近くとなればスケーリングが発生する可能性があることがわかりました。
また急激な負荷増加時には当然のことながらスケーリングが追いつかずスロットルが発生する挙動となりますが、そもそも Lambda Managed Instances は下記の通りデフォルトでは5分でトラフィックが2倍になるような、緩やかなスケーリングを想定しているようです。
Consider Lambda Managed Instances for the following use cases:
- High volume-predictable workloads - Best suited for steady-state workloads without unexpected traffic spikes. Lambda Managed Instances scale to handle traffic doubling within five minutes by default.
CPU ヘビーなワークロードに対してスパイク的な負荷が予想される場合にはスケーリングポリシーのカスタマイズや、以前に書いた下記記事のようにメモリおよび vCPU 割り当てを増やすなどの対策が必要ですが、実行環境のスケーリングにタイムラグがあることを考えるとそれにも限界はありそうです。
やはり Lambda Managed Instances は、定常リクエストが見込まれるワークロードに向いていると言えそうです。Amazon SQS や Amazon Kinesis Data Streams などのイベントソースと組み合わせて、トラフィックを平準化するなどの工夫が求められそうですね。
以上









