
AWS で NVIDIA Blackwell Ultra B300 搭載の P6-B300 インスタンスが利用できるようになりました
はじめに
2025 年 11 月、NVIDIA Blackwell Ultra B300 GPU を搭載した Amazon EC2 P6-B300 インスタンスの一般提供が開始されました。この GPU は大規模言語モデル(LLM)のトレーニングと推論に最適化されています。
最近の GPU インスタンスは Capacity Blocks for ML での予約のみ対応が多く、簡単に起動して試せません。本記事では試してみたができなかったので P6-B300 インスタンスのスペック、費用感、利用方法について紹介します。
主要なスペック
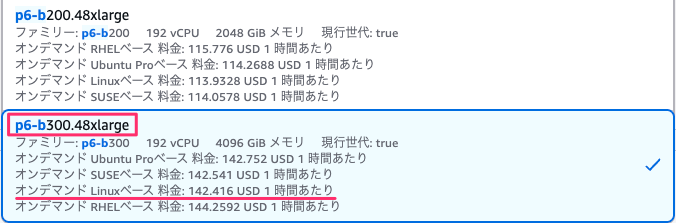
p6-b300.48xlarge のスペックを紹介します。インスタンスサイズは 48xlarge のみです。提供リージョンは現時点でオレゴンのみとなっています。
| 項目 | 仕様 |
|---|---|
| プロセッサ | Intel Xeon Emerald Rapids |
| vCPU | 192 |
| CPU コア数 | 96 |
| システムメモリ | 4 TB(4096 GiB) |
| GPU | NVIDIA Blackwell Ultra B300 GPU x 8 |
| GPU メモリ | 2.1 TB(2148 GiB、268 GiB x 8) |
| ネットワーク | 6.4 Tbps EFA、300 Gbps 専用 ENA スループット |
| ローカルストレージ | ローカル NVMe SSD(インスタンスストア)3.84TB x 8 |
GPU メモリの大きさに加え、ネットワーク帯域幅も非常に大きいです。トレーニング時のノード間通信を前提とした高帯域設計と考えられます。
費用感
オンデマンド価格
Linux のオンデマンド価格は $142.416/時間です。
オンデマンド利用については AWS のアカウントマネージャーへお問い合わせくださいと記載がありました。クラスメソッドメンバーズのお客様は、弊社の営業担当または AWS ご担当者様へご確認ください。
Capacity Blocks for ML
Capacity Blocks for ML は、一定期間の一部の GPU インスタンスを事前予約できるサービスです。
ML モデルのトレーニングやファインチューニング、実験やプロトタイプ開発など、GPU を数日から数週間の期間利用する場合に最適です。必要な期間、確実に GPU 容量を確保できてかつ割引も受けられます。
昨今、GPU 需要ですとリージョンによってはオンデマンド起動がままならい状況です。高価な GPU を使いたいなら、予約して事前にキャパシティを確保しないといけない状況と言った方が正しいです。
P6-B300 での Capacity Blocks 利用状況
キャパシティの予約ができませんでした。
1 世代前の p6-b200.48xlarge のリリース時にも同じエラーを確認しています。

現在、p6-b200.48xlarge では確認できているため、サービスクォータの問題ではありません。当時は p6 のサービスクォータ項目自体が存在しませんでした。後日確認した際に追加されていたため、上限を緩和しました。しかし、キャパシティの予約は依然としてできませんでした。
この問題は時間が経過することで解決したため、リリース直後は利用できないのではないかと疑っています。お急ぎの方は AWS サポートへお問い合わせください。
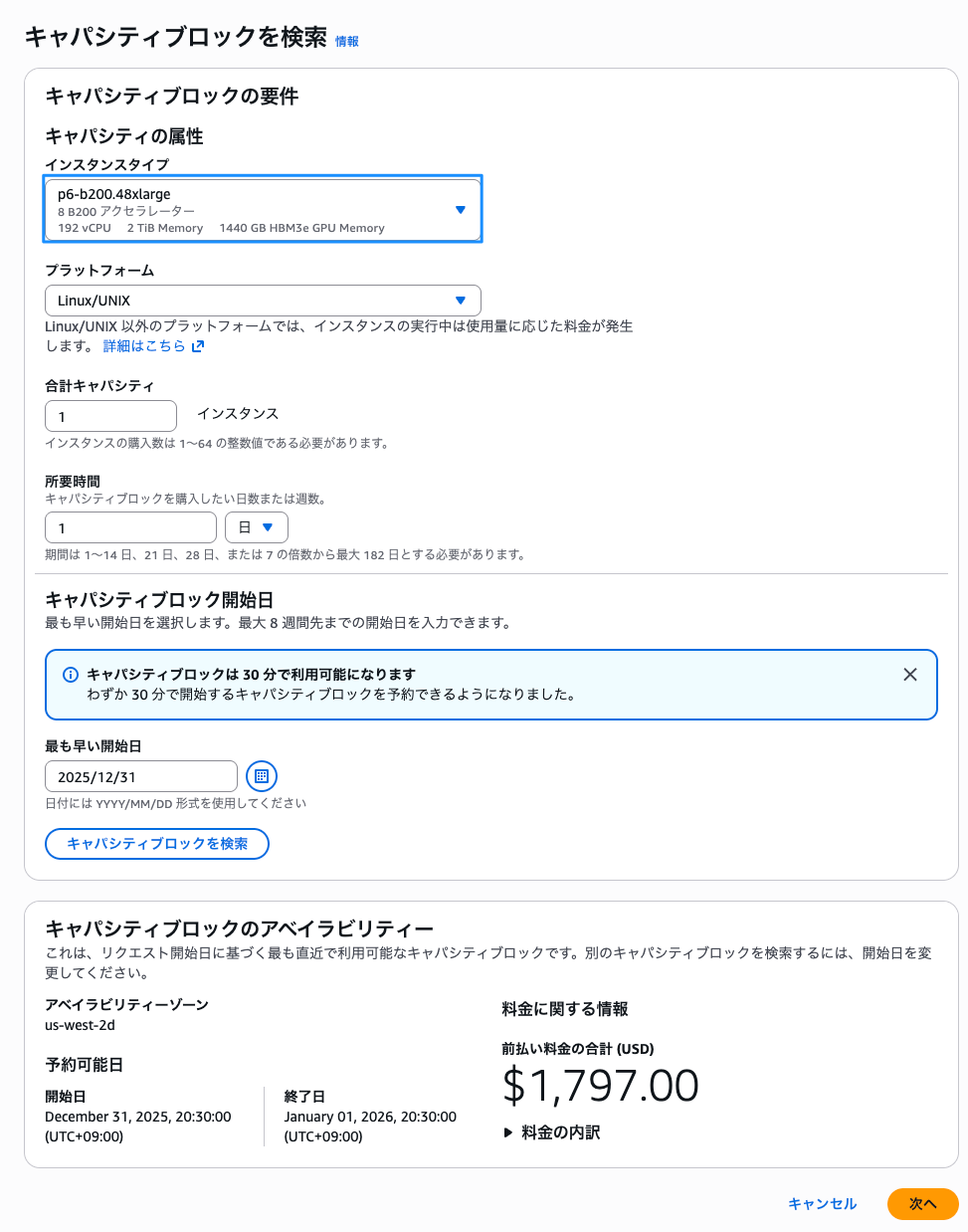
そのため、今回も Capacity Blocks for ML の割引額は確認できませんでした。
1世代前のインスタンスタイプとスペック比較
1 世代前の p6-b200.48xlarge と比較します。
| 項目 | p6-b200.48xlarge | p6-b300.48xlarge | 倍率 |
|---|---|---|---|
| GPU メモリサイズ | 1.4 TB | 2.1 TB | 1.5 倍 |
| ネットワーク帯域幅 | 3.2 Tbps | 6.4 Tbps | 2 倍 |
| システムメモリ | 2 TB | 4 TB | 2 倍 |
| オンデマンド価格 | $113.933/時間 | $142.416/時間 | 1.25 倍 |
GPU の合計メモリサイズが 1.5 倍になり、最新世代の GPU を 1.25 倍の価格で利用できます。これは費用対効果が高いと言えるでしょう。
まとめ
P6-B300 インスタンスの登場により、AWS で最新の NVIDIA Blackwell Ultra GB300 GPU を利用できるようになりました。
ポイントは以下の通りです。
- 大規模言語モデルのトレーニングと推論に最適化
- P6-B200 比で 1.5 倍の GPU メモリサイズ
- 2 倍のネットワーク帯域幅(6.4 Tbps)
今後は他リージョンへの展開に期待しましょう。1 リージョンだけの展開ですと GPU 争奪戦になりますからね。
おわりに
2025 年 11 月 3 日、AWS は OpenAI との 380 億ドル規模の戦略的提携を発表しました。その記事には GB200 と GB300 を数十万チップ規模で提供すると書かれていました。
この発表を読んで、近々 AWS でも GB300 インスタンスが提供されるのではないかと期待しています。今後は GB300 NVL72 の P6e-GB300 UltraServer(仮)の一般提供されることを期待したいと思います。








