
AWS Backup を使って Amazon S3 のバックアップを構成した時にどういう動きをするのか概念などを整理した
いわさです。
AWS Backup を使うと Amazon S3 のバックアップを構成することが出来ます。
この時、Amazon S3 側のバックアップがどのように AWS Backup で保持されるのか、継続的バックアップがどういう仕組みで動作するのかなどをうまく言語化出来ないなと思ったので、基本的な概念とともにイメージを整理してみることにしました。
AWS Backup を使って Amazon S3 のバックアップを取得する
AWS Backup では Backup Plan を構成することで、どういうスケジュールでどのリソースのバックアップを取得するのかを構成することが出来ます。
そして Backup Vault と呼ばれる入れ物にバックアップデータを保存するイメージになります。
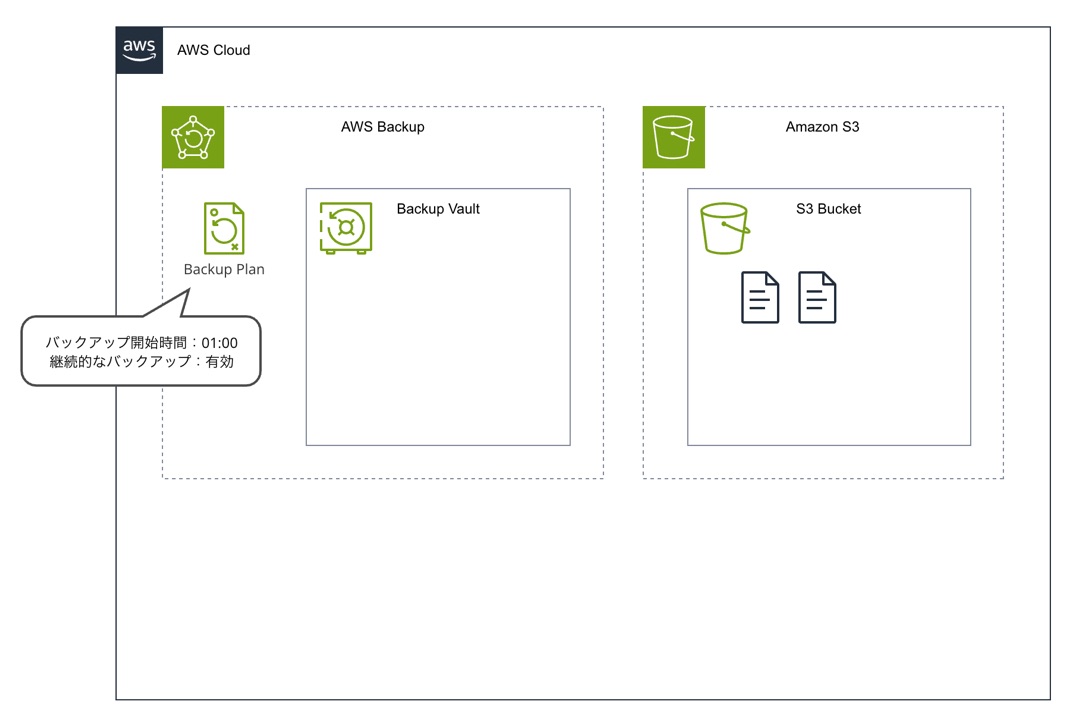
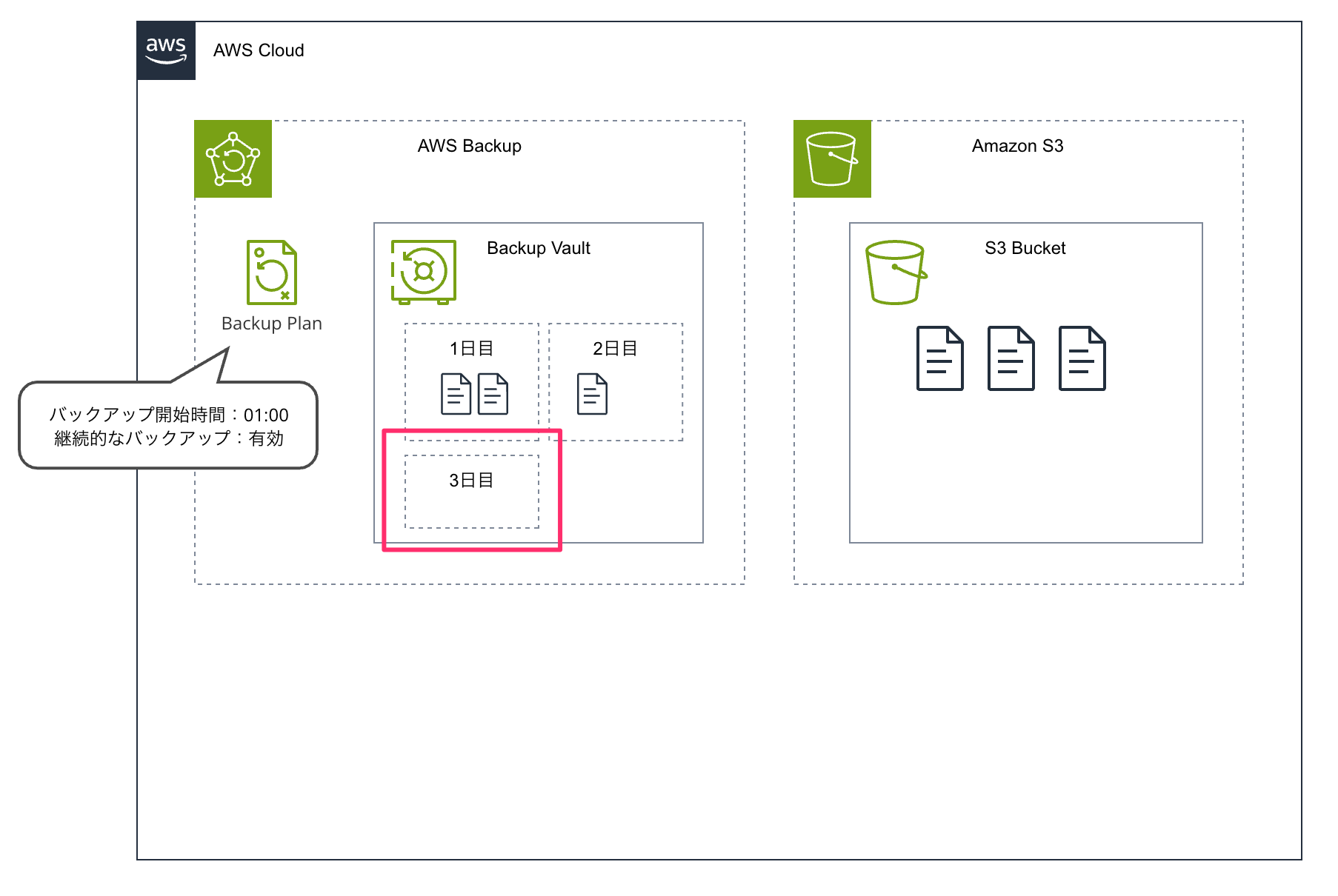
Amazon S3 をターゲットにした場合、対象リソースに指定したバケットのすべてのオブジェクトのフルバックアップを初回に取得します。
前提条件として、Amazon S3 バケットのバージョニング機能を有効にする必要があります。全部取得して Vault に突っ込むならいらないのでは?という気もちょっとするのですが要るんですよね。
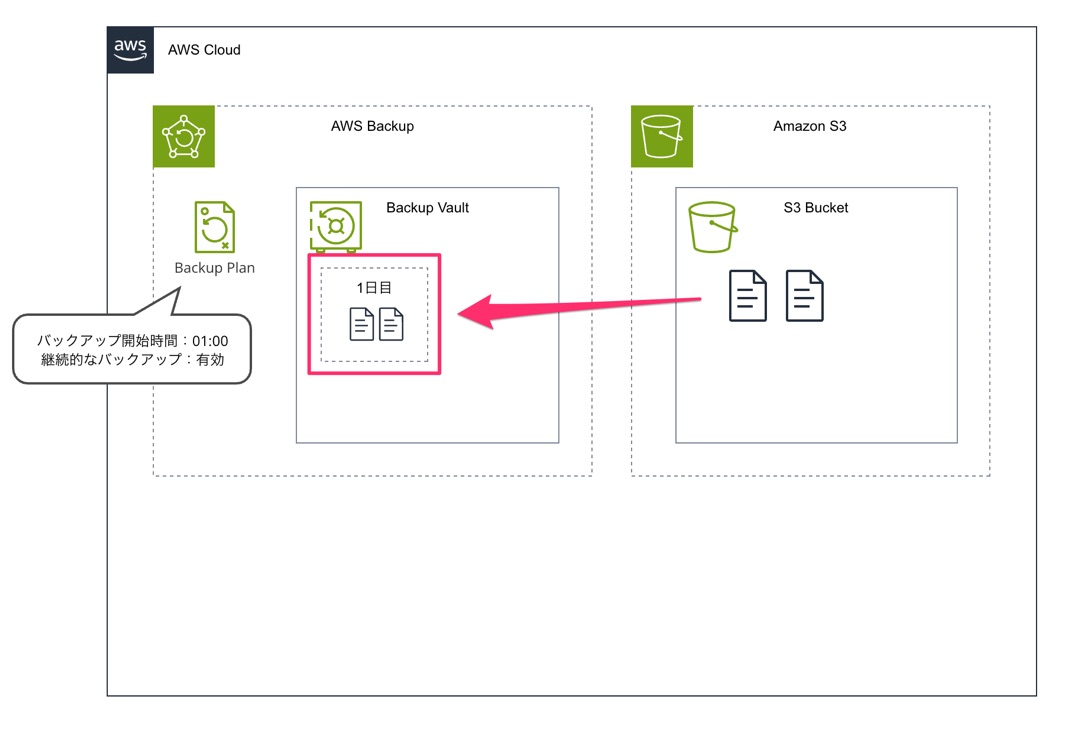
そしてバックアップが取得される際は最新のオブジェクトだけでなく古いバージョンのオブジェクトも取得されます。

2回目以降のバックアップでは Amazon S3 の場合は増分バックアップとして取得される仕様となっています。
バックアップ対象のサービスによって異なっているのでここは注意してください。例えば DocumentDB や DynamoDB は増分バックアップをサポートしていません。
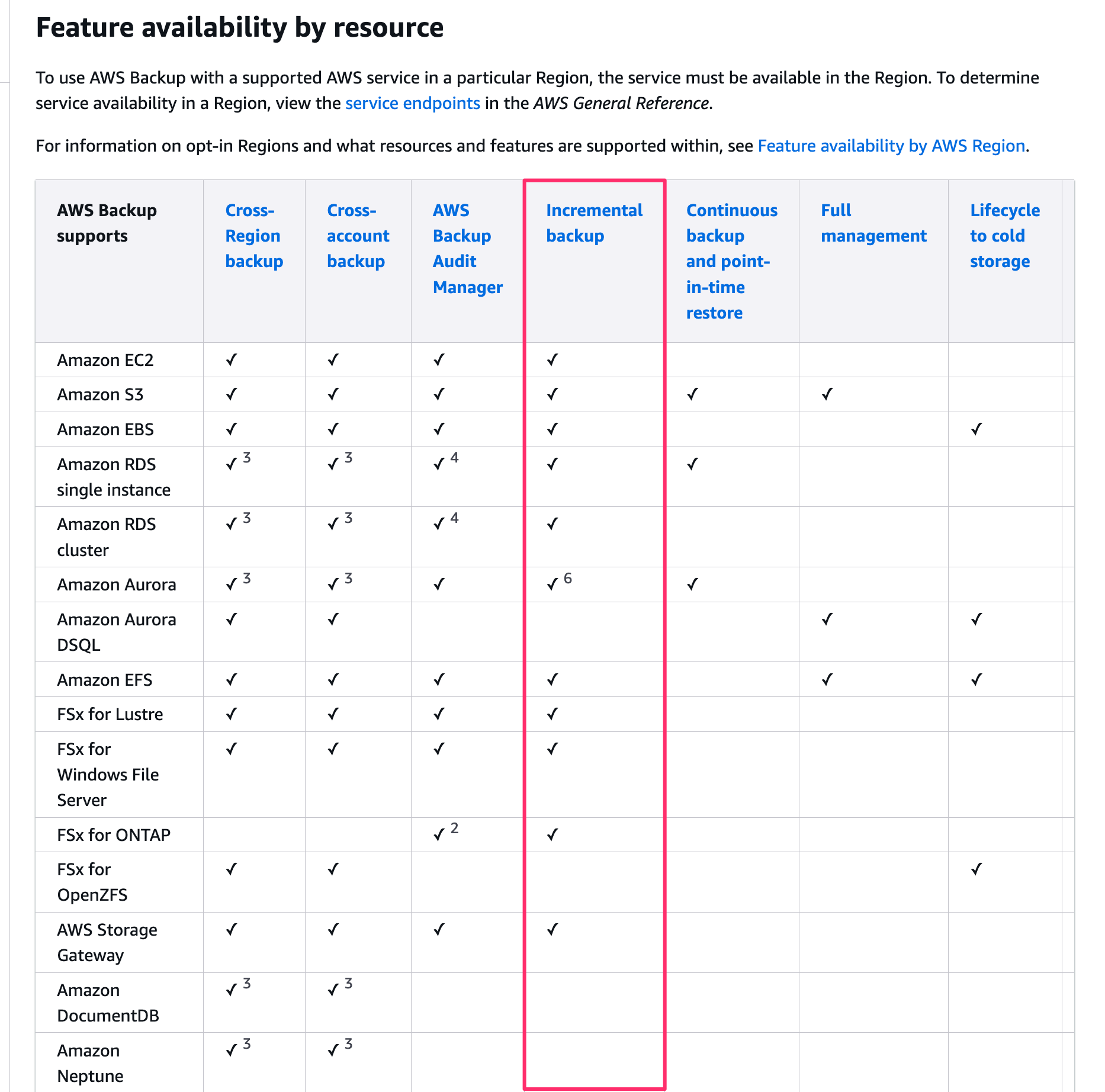
AWS Backup feature availability - AWS Backup より
そして以下の公式ドキュメント上でも初回はフルバックアップで、それ以降はオブジェクトレベルでの増分バックアップであると記載されていますね。
これは定期バックアップでも、後述の継続的バックアップの場合でも同じです。
For both backup types, the first backup is a full backup, while subsequent backups are incremental at object-level.
なので次のようなイメージになります。
次の定期バックアップでは増分のみ保存され、もし変更点がなければ復元ポイントは作成されるのですが、サイズがゼロになります。
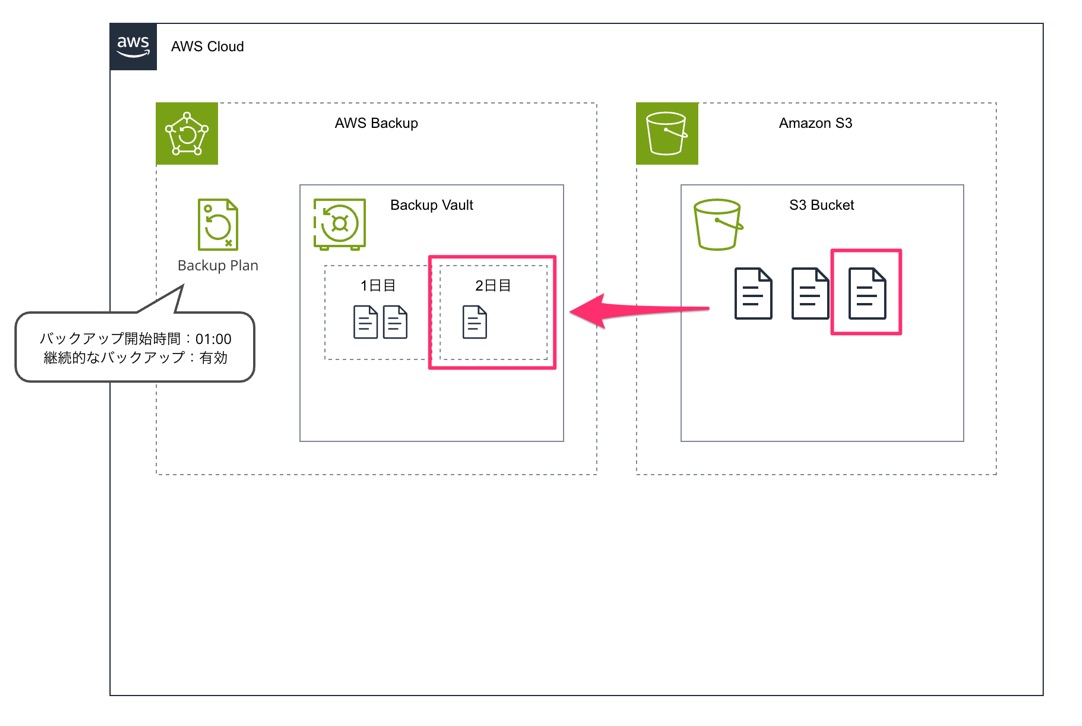
なお、この Amazon S3 を AWS Backup でバックアップする際にいくつか注意事項があります。
小さすぎるオブジェクトが大量にある場合だとコスト高になる可能性がある
128KB未満の S3 オブジェクトの場合、バックアップは 128KB 単位の料金になるという制限事項があります。
For S3 objects smaller than 128 KB, the backups would be priced as a 128-KB backup. I
オブジェクト特性を判断して対象バケットを AWS Backup でのバックアップ対象にすべきか検討し、プランに割り当てるリソースを調整したほうが良いでしょう。
Intelligent-Tiering を使っていると「Frequent Access」に戻される
S3 Intelligent-Tiering は一定期間アクセスのないオブジェクトをコストの安い階層に移動してくれる機能です。
どうやら AWS Backup によってアクセスされることで、アクセスされたとみなされて標準の「Frequent Access」に移動されてしまうようです。
Backups of an object in the storage class S3 Intelligent-Tiering (INT) access those objects. This access triggers S3 Intelligent-Tiering to automatically move those objects to Frequent Access.
特にこれを気をつけるべきは初回のフルバックアップの時だと思います。
すでに Infrequent Access や Archive Instant Access に移動されているオブジェクトが存在する場合は標準階層に戻されてしまう可能性がありますので認識しておきましょう。
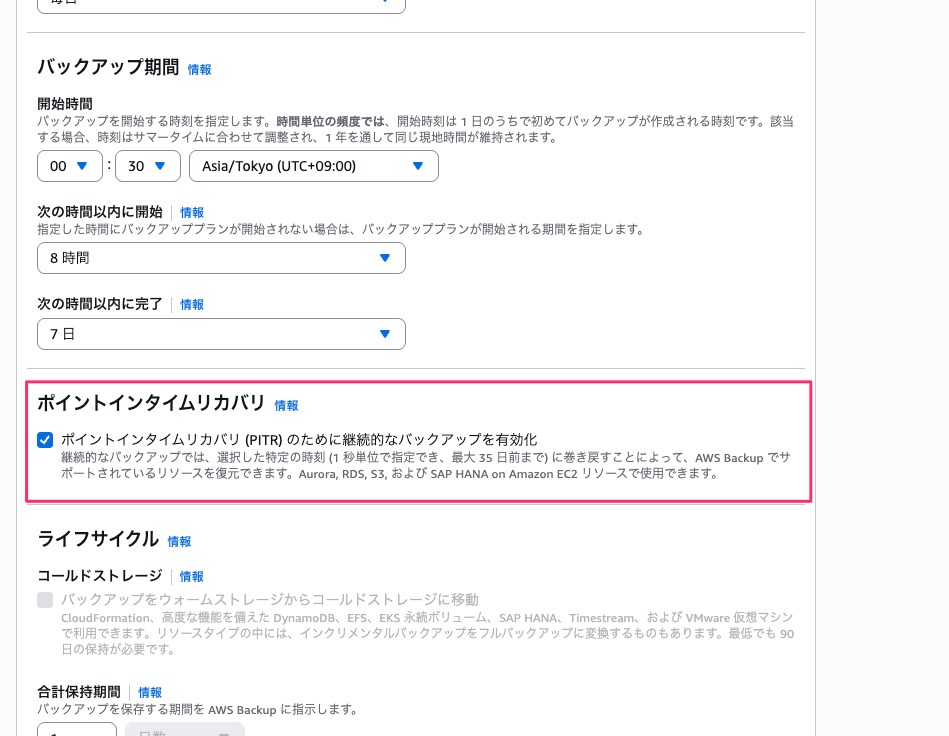
継続的バックアップを有効化する
バックアッププランのルールを作成する際に継続的バックアップを有効化することが出来ます。
これを有効化することでポイントインタイムリカバリ(PITR)機能を使うことが出来ます。
例えばバックアップ頻度が「毎日」だった場合は通常だと毎日特定の時間に取得された復元ポイントが最新となります。最長で24時間前になるわけです。
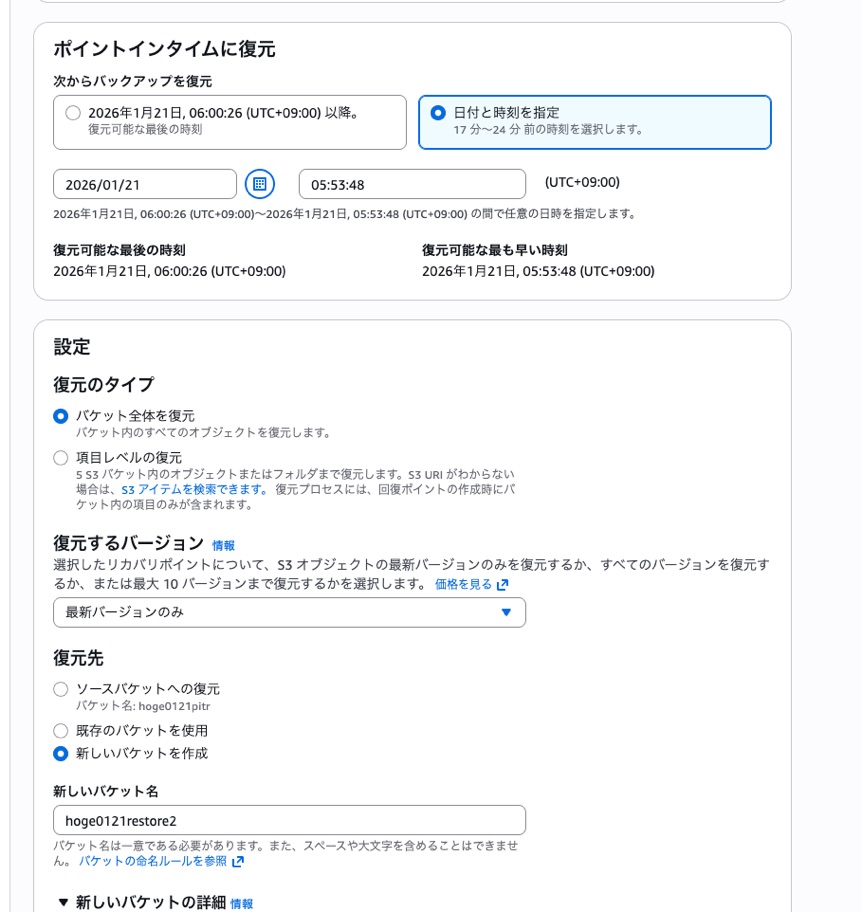
しかし、PITR が使える場合、上記の頻度だったとしても20分前などの状態に復元することが出来ます。
上記ルールで継続的バックアップを有効化するとcontinuousというプレフィックスがついた復元ポイントが次のように作成されます。
バックアップタイプは「連続」です。

復元時には次のようにポイントインタイムに復元という操作ができるようになります。なるほど。
この機能、どのような仕組みで動いているのでしょうか。
また、この機能を有効化したときのバックアップ料金はどのようになるのでしょう。
ドキュメントに記述されていまして、継続的バックアップは EventBridge を使って Amazon S3 と AWS Backup で連携されます。
継続的バックアップを使うことで、S3 バケットに発生した変更を検知して変更された部分だけ追加で保存されます。これがトランザクションログのような使われ方をされ、ポイントインタイムリストアを行う際には通常の復元に加えて特定時点までの変更を反映することで復元しています。
次のようなイメージです。
料金で考える場合は、Backup Vault に変更があった部分だけ追加で保存されるのでその料金が発生します。なお、継続的バックアップは最大で35日までなので、コールドストレージへの移行はサポートされていません。
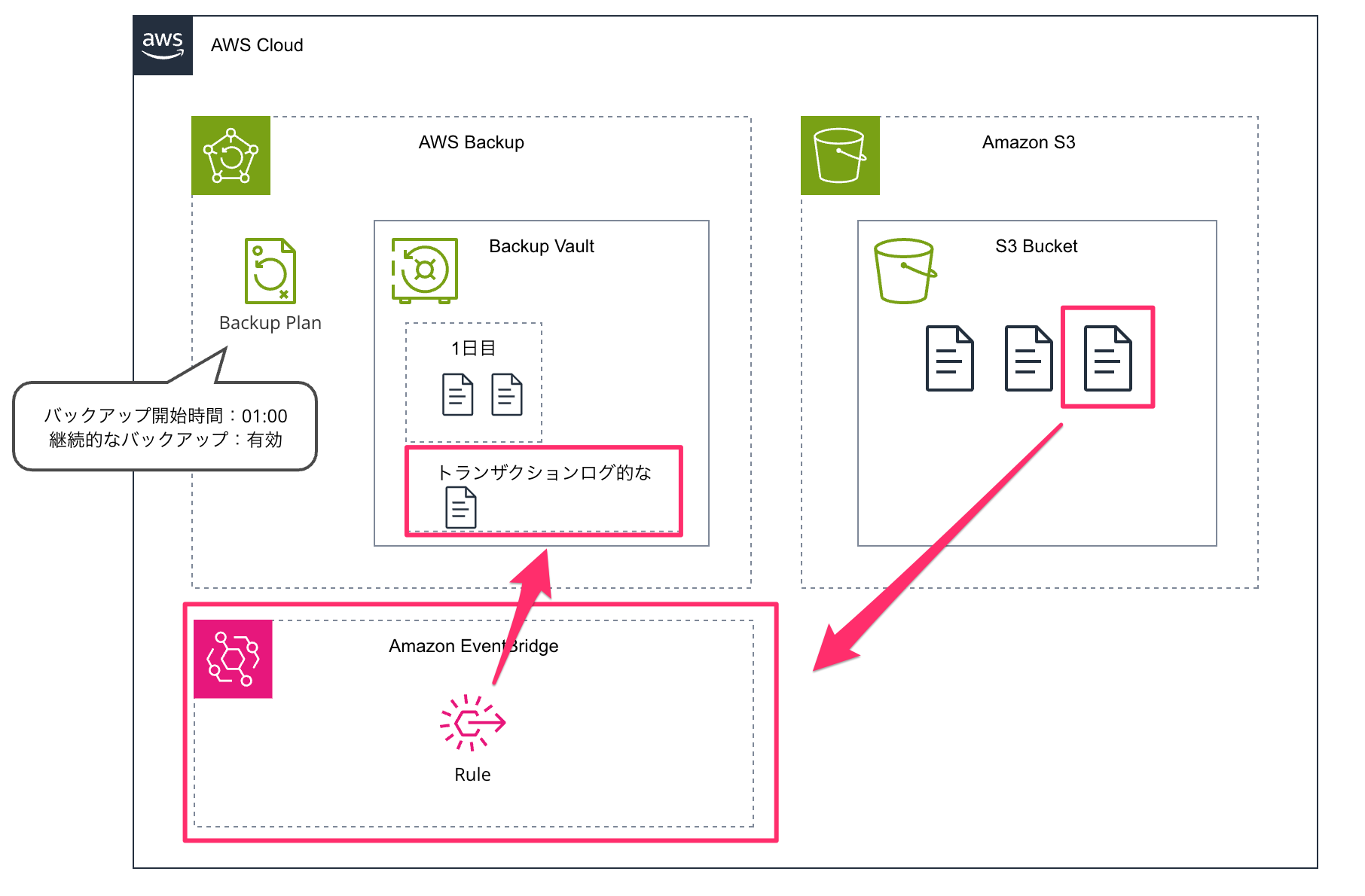
実際に確認してみると、継続的バックアップを有効化することで自動で EventBridge ルールが作成され、対象 S3 バケットの EventBridge へのイベント通知もオンになっていました。このあたりを手動で触ると継続的バックアップが動かなくなるので注意しましょうね。


なお上記ドキュメントに補足されていますが、RDS の場合は PITR で最短 5 分前まで戻すことが出来るのですが、S3 の場合は 15 分前が最短になります。
Amazon RDS activity allows restores up until the most recent 5 minutes of activity; Amazon S3 allows restores up until the most recent 15 minutes of activity.
さいごに
本日は AWS Backup を使って Amazon S3 のバックアップを構成した時にどういう動きをするのか概念などを整理してみました。
Backup Vault の料金がどのような感じで使われるのか、継続的バックアップがどういう仕組で連携されて Vault 上どのように考えるのが良いのかが整理できた気がします。そんな気がする。








