![[アップデート] Amazon Bedrock AgentCore Evaluations にコードベース Evaluatorが追加されたので試してみた](https://images.ctfassets.net/ct0aopd36mqt/7M0d5bjsd0K4Et30cVFvB6/5b2095750cc8bf73f04f63ed0d4b3546/AgentCore2.png?w=3840&fm=webp)
[アップデート] Amazon Bedrock AgentCore Evaluations にコードベース Evaluatorが追加されたので試してみた
はじめに
コンサルティング部の神野です。
Amazon Bedrock AgentCore Evaluations のコンソールを眺めていると、AWS Lambda を使うコードベース Evaluator が使えるようになっていました!
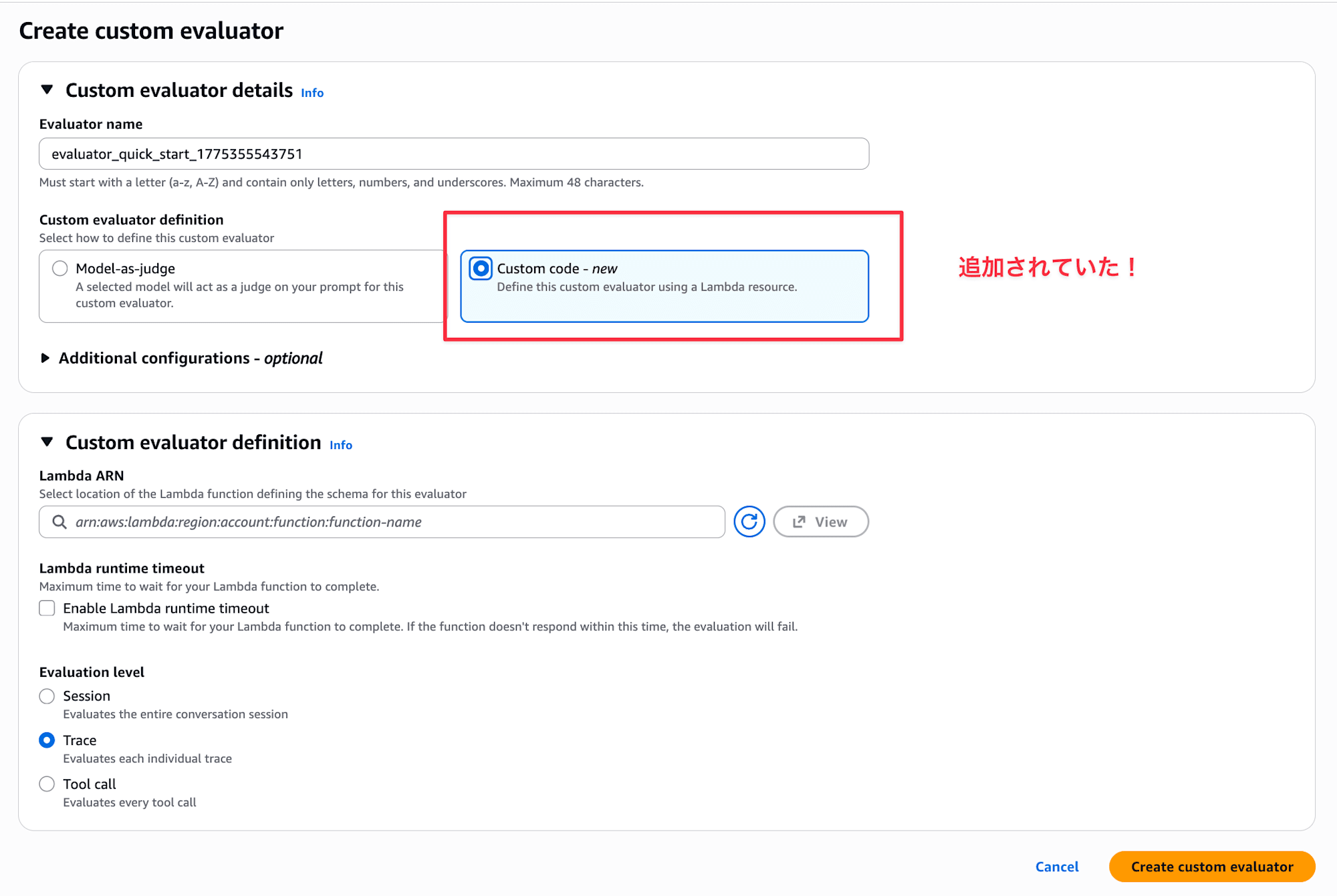
これまでカスタム Evaluator は LLM-as-a-Judge しか対応していなかったのですが、コードで評価ロジックを書けるようになりました。フォーマットチェックなど決定的な観点で評価したい時に使えるイメージですかね。
今回は、シンプルなエージェントを AgentCore Runtime にデプロイして、Lambda のコードベース Evaluator から応答文字数をチェックしてみました。
コードベース Evaluator はどういう時に使うのか
個人的にあまり活用イメージが湧かなかったのですが、公式ドキュメントに以下のような記載がありました。
Custom code-based evaluators let you use your own AWS Lambda function to programmatically evaluate agent performance, instead of using an LLM as a judge. This gives you full control over the evaluation logic — you can implement deterministic checks, call external APIs, run regex matching, compute custom metrics, or apply any business-specific rules.
コードで決定的に判定できるならコードベース、できないなら LLM-as-a-Judge、という棲み分けなのかなと感じました。
- 決定的なチェック(応答が JSON として valid か、必須フィールドがあるか)
- 正規表現マッチ(特定のフォーマットに従っているか)
- 外部 API 呼び出し(DB やナレッジベースと照合して正解チェック)
- カスタムメトリクス(トークン消費量やレイテンシの閾値チェック)
- ビジネス固有のルール(業界特有のコンプライアンスチェックなど)
公式ドキュメントのサンプルコードでも、エージェントの応答が valid な JSON かどうかを検証する例が紹介されていました。逆に、回答の自然さや正確性など人間の主観的な判断が必要な評価は LLM-as-a-Judge を今まで通り使用する形になるかと思います。
バチっと決まったユースケースが見つかったらブログで紹介したいですね・・・!
前提
今回の環境は以下です。
- AWS CLI 1.44.71
- Python 3.13.11
- uv 0.9.26
- strands-agents 1.34.1
- bedrock-agentcore 1.6.0
- bedrock-agentcore-starter-toolkit 0.3.4
- リージョン:
us-east-1 - CloudWatch Transaction Search を有効化済み
実装
プロジェクトのセットアップ
まずは uv でプロジェクトを作成して、必要なパッケージを追加していきます。
uv init custom-eval-lambda
cd custom-eval-lambda
uv add strands-agents bedrock-agentcore bedrock-agentcore-starter-toolkit
| パッケージ | 用途 |
|---|---|
strands-agents |
エージェントの実装に使用します |
bedrock-agentcore |
AgentCore Runtime へのデプロイに使用します |
bedrock-agentcore-starter-toolkit |
agentcore CLI(デプロイ・評価の実行)に使用します |
これでプロジェクトの準備はOKです!
エージェントを用意する
次に評価対象のエージェントを用意します。
from bedrock_agentcore import BedrockAgentCoreApp
from strands import Agent
app = BedrockAgentCoreApp()
agent = Agent()
@app.entrypoint
def invoke(payload):
prompt = payload.get("prompt", "AWSのS3とEBSの違いを教えてください")
result = agent(prompt)
return {"message": result.message}
if __name__ == "__main__":
app.run()
入力の prompt を Strands の Agent に渡して、応答を返すだけのシンプルな構成です。
実装が完了したらデプロイを実施します。今回はコンテナでデプロイとします。
いくつか質問されますが基本デフォルトの設定とします。
# デプロイの設定
uv run agentcore configure \
-e my_agent.py \
-r us-east-1 \
-dt container \
--disable-memory
# 基本そのままEnter
# デプロイ
uv run agentcore deploy
評価対象セッションを作成する
デプロイ後に何回か呼び出して、評価対象のセッションを作っておきます。短い回答になりそうな質問と、長い回答になりそうな質問を投げてみます。
uv run agentcore invoke '{"prompt": "AWSのS3とEBSの違いを一言で教えてください"}'
Response:
{"message": {"role": "assistant", "content": [{"text":
"**S3はファイル保存用のオブジェクトストレージ、EBSはEC2インスタンス用のディスクストレージ**です。"}]}}
uv run agentcore invoke '{"prompt": "AWSのS3、EBS、EFSの違いをユースケース・料金体系・パフォーマンス特性の観点から詳しく比較して教えてください"}'
Response:
{"message": {"role": "assistant", "content": [{"text": "# AWS S3・EBS・EFS の詳細比較\n\n## 1. ユースケース\n\n### S3 (Simple
Storage Service)\n- **Webサイトの静的コンテンツ配信**(画像、CSS、JS)\n- **データバックアップ・アーカイブ**\n-
**データレイクの構築**\n- **アプリケーションログの保存**\n- **機械学習用データセットの保存**\n-
**災害復旧用データ保管**\n\n### EBS (Elastic Block Store)\n- **EC2インスタンスのルートボリューム**\n-
**データベースストレージ**(MySQL、PostgreSQL等)\n- **ファイルシステム**\n- **高IOPSが必要なアプリケーション**\n-
**スナップショット機能を使ったバックアップ**\n\n### EFS (Elastic File System)\n-
**複数のEC2インスタンス間でのファイル共有**\n- **コンテナアプリケーションの共有ストレージ**\n-
**WebサーバーやCMSの共有コンテンツ**\n- **ビッグデータ分析での並列処���**\n- **開発環境での共有作業領域**\n\n## 2.
料金体系\n\n### S3\n```\n- ストレージ料金: 使用容量に応じた従量課金\n - Standard: ~$0.023/GB/月\n - IA (Infrequent Access):
~$0.0125/GB/月\n - Glacier: ~$0.004/GB/月\n- リクエスト料金: API呼び出し回数\n- データ転送料金: 外部への転送時\n```\n\n###
EBS\n```\n- ボリューム料金: プロビジョニング容量での課金\n - gp3: ~$0.08/GB/月\n - io2: ~$0.125/GB/月 + IOPS料金\n-
スナップショット料金: ~$0.05/GB/月(差分のみ)\n- 使わなくてもプロビジョニング分は課金\n```\n\n### EFS\n```\n- ストレージ料金:
使用容量に応じた従量課金\n - Standard: ~$0.30/GB/月\n - IA: ~$0.025/GB/月\n- プロビジョンドスループット: 追加料金\n-
最も高価だが使った分だけ課金\n```\n\n## 3. パフォーマンス特性\n\n### S3\n| 項目 | 特性 |\n|------|------|\n| **スループット**
| 3,500 PUT/POST/DELETE、5,500 GET/秒 |\n| **レイテンシ** | 100-200ms(初回リクエスト) |\n| **耐久性** |
99.999999999%(イレブンナイン) |\n| **可用性** | 99.9%(Standard) |\n| **制限** | オブジェクトサイズ最大5TB |\n\n### EBS\n|
項目 | gp3 | io2 |\n|------|-----|-----|\n| **IOPS** | 3,000-16,000 | 100-64,000 |\n| **スループット** | 125-1,000 MB/s |
1,000 MB/s |\n| **レイテンシ** | 単一桁ms | サブms |\n| **耐久性** | 99.999% | 99.999% |\n| **可用性** | 99.999% | 99.999%
|\n\n### EFS\n| 項目 | 汎用モード | 最大I/Oモード |\n|------|-----------|---------------|\n| **スループット** |
7,000ファイル操作/秒 | >7,000ファイル操作/秒 |\n| **レイテンシ** | 単一桁ms | 若干高い |\n| **同時接続** |
数千のEC2インスタンス | 数千のEC2インスタンス |\n| **スケール** | ペタバイト級まで自動拡張 | ペタバイト級まで自動拡張 |\n\n##
4. 選択指針\n\n**S3を選ぶべき場合:**\n- 静的コンテンツやバ��クアップデータ\n- コスト重視で頻繁なアクセスが不要\n-
インターネット経由でのアクセスが必要\n\n**EBSを選ぶべき場合:**\n- 単一インスタンスで高性能が必要\n- データベースやOS用途\n-
低レイテンシが重要\n\n**EFSを選ぶべき場合:**\n- 複数インスタンス間でのファイル共有が必要\n- 容量の予測が困難\n-
POSIX準拠のファイルシステムが必要"}]}}
Lambda で評価ロジックを書く
次に、コードベース Evaluator の本体になる Lambda 関数を用意します。
まず Lambda に渡されるリクエストを確認してみます(span は 1 件に絞っています)。
{
"schemaVersion": "1.0",
"evaluationLevel": "TRACE",
"evaluationInput": {
"sessionSpans": [
{
"name": "invoke_agent Strands Agents",
"kind": "INTERNAL",
"trace_id": "69d1d6635a99baa94f465b8b607e2d0f",
"span_id": "6e6a73c41262e9d9",
"session_id": "fa6759fb-6782-464e-941d-8bc1b80b5b12",
"attributes": {
"gen_ai.usage.input_tokens": 24,
"gen_ai.usage.output_tokens": 732,
"gen_ai.request.model": "us.anthropic.claude-sonnet-4-20250514-v1:0",
"gen_ai.operation.name": "invoke_agent",
"gen_ai.system": "strands-agents",
"session.id": "fa6759fb-6782-464e-941d-8bc1b80b5b12"
},
"span_events": [
{
"body": {
"output": {
"messages": [
{
"content": {
"message": "AWSのS3とEBSの主な違いについて説明します。...",
"finish_reason": "end_turn"
},
"role": "assistant"
}
]
},
"input": {
"messages": [
{
"content": {
"content": "[{\"text\": \"AWSのS3とEBSの違いを教えてください\"}]"
},
"role": "user"
}
]
}
}
}
],
"traceId": "69d1d6635a99baa94f465b8b607e2d0f"
}
]
},
"evaluationTarget": {
"traceIds": [
"69d1d6635a99baa94f465b8b607e2d0f"
]
}
}
今回は応答テキストが span_events[].body.output.messages の中に入っているのを確認できたので、ここから assistant ロールのメッセージを取り出して文字長を評価してみます。
import json
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
logger.info(json.dumps(event, ensure_ascii=False))
spans = event.get("evaluationInput", {}).get("sessionSpans", [])
trace_ids = set((event.get("evaluationTarget") or {}).get("traceIds", []))
response = extract_response(spans, trace_ids)
if not response:
return {
"label": "Fail",
"value": 0.0,
"explanation": "評価対象 trace から応答を取得できませんでした。"
}
if len(response) < 100:
return {
"label": "TooShort",
"value": 0.4,
"explanation": "応答が短すぎます。100文字以上を目安にしたいです。"
}
if len(response) > 3000:
return {
"label": "TooLong",
"value": 0.7,
"explanation": "応答が長すぎます。3000文字以内に収めたいです。"
}
return {
"label": "Pass",
"value": 1.0,
"explanation": "応答長は想定範囲でした。"
}
def extract_response(spans, trace_ids):
for span in spans:
trace_id = span.get("traceId") or span.get("trace_id")
if trace_ids and trace_id not in trace_ids:
continue
for span_event in span.get("span_events", []):
messages = span_event.get("body", {}).get("output", {}).get("messages", [])
for msg in reversed(messages):
if msg.get("role") != "assistant":
continue
content = msg.get("content", {})
if isinstance(content, str):
return content.strip()
if isinstance(content, dict):
return content.get("message", "").strip()
return ""
extract_response では span_events[].body.output.messages から assistant のメッセージを探しています。content はフレームワークによって文字列か辞書か変わるので、両方に対応しています。
次に Lambda の実行ロールを作成してデプロイします。
まずはIAMロールを作成して、AWSLambdaBasicExecutionRoleをアタッチします。
aws iam create-role \
--role-name agentcore-custom-evaluator-role \
--assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'
aws iam attach-role-policy \
--role-name agentcore-custom-evaluator-role \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
ロールを作成したら、対象ファイルをzip化してアップロードします。
FUNCTION_NAME=agentcore-custom-evaluator
ROLE_ARN=$(aws iam get-role \
--role-name agentcore-custom-evaluator-role \
--query 'Role.Arn' \
--output text)
zip function.zip lambda_function.py
aws lambda create-function \
--function-name "$FUNCTION_NAME" \
--runtime python3.12 \
--role "$ROLE_ARN" \
--handler lambda_function.lambda_handler \
--zip-file fileb://function.zip \
--timeout 60 \
--region us-east-1
LAMBDA_ARN=$(aws lambda get-function \
--function-name "$FUNCTION_NAME" \
--query 'Configuration.FunctionArn' \
--output text)
これで準備完了です!次にコードベースで評価を行うEvaluator を登録してみます。
コードベース Evaluator を登録する
Evaluator の設定はシンプルです。レベル(今回はTRACE)とLambda ARN とタイムアウトだけ指定すれば OK です。
| 設定項目 | 設定値 | 説明 |
|---|---|---|
lambdaArn |
"$LAMBDA_ARN" |
評価ロジックとして呼び出す関数です |
lambdaTimeoutInSeconds |
120 |
Lambda 呼び出しのタイムアウト秒数です |
EVALUATOR_ID=$(aws bedrock-agentcore-control create-evaluator \
--evaluator-name response_quality_checker \
--level TRACE \
--description "Lambda-based response quality evaluator" \
--evaluator-config "{\"codeBased\":{\"lambdaConfig\":{\"lambdaArn\":\"${LAMBDA_ARN}\",\"lambdaTimeoutInSeconds\":120}}}" \
--region us-east-1 \
--query 'evaluatorId' \
--output text)
またEVALUATOR_IDを変数として控えておきます。後ほどテストでこのIDを使用するためです。
動作確認
評価を実行する
Evaluator が作成できたら、Starter Toolkit の evalコマンドで実行します。直前にデプロイしたエージェントのセッションが自動で評価対象になります。
uv run agentcore eval run \
--evaluator "$EVALUATOR_ID"
✓ Successful Evaluations
Evaluator: response_quality_checker
Score: 1.00
Label: Pass
Explanation: 応答長は想定範囲でした。
Evaluated:
- Session: fa6759fb-6782-464e-941d-8bc1b80b5b12
- Trace: 69dba023661f60fe07171f6d55e71564
Evaluator: response_quality_checker
Score: 0.40
Label: TooShort
Explanation: 応答が短すぎます。100文字以上を目安にしたいです。
Evaluated:
- Session: fa6759fb-6782-464e-941d-8bc1b80b5b12
- Trace: 69dba01224d6de5d14f6424a00d8cf7d
無事テストできました!!詳しく比較する質問の方は Pass(1.00)、一言で聞いた方は TooShort(0.40)になっていますね。質問の仕方によって応答長が変わるので、ちゃんと Evaluator が効いているのが確認できました!
なお、オンライン評価でも使えるか試してみたのですが、コンソールでオンライン評価を設定する際にはコードベース Evaluator は選択肢に表れず、CLI から作成を試みても Code-based evaluator(s) cannot be used in online evaluation. Code-based evaluators support on-demand evaluation only. というエラーになりました。現時点ではオンデマンド評価のみの対応のようです。
おわりに
今回は応答の文字長チェックというシンプルな例でしたが、Lambda で自由にロジックを書けるので、評価の幅は広がりそうですね。試してみてどう言ったユースケースで使ったら良いんだろう・・・と模索中ではありますが、活用できるシーンで使っていければと思います!その際はブログで紹介します!
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございましたー!










