
Amazon Bedrockで強化学習によるFine Tuning(RFT)
Introduction
ここにもあるように、re:Invent 2025 の KeynoteでAmazon BedrockのRFT(強化学習によるファインチューニング)が発表されました。
ファインチューニングにおいて強化学習を用いることで自律的に学習し、
従来よりも少ないデータセットでの精度向上が期待できるとのこと。
本記事では、Amazon Nova 2 Lite を強化学習ファインチューニング(RFT)で訓練し、
指定された文字数以内で回答するモデルを作成してみます。
Environment
- MacBook Pro (14-inch, M3, 2023)
- OS : MacOS 15.7.1
- Rust : 1.91.1
- cargo-lambda : 1.8.6
- aws-cli : 2.32.13 Python/3.13.9 Darwin/24.6.0 exe/arm64
AWSアカウントはセットアップ済みとします。
Bedrock RFT の制約(2025年12月時点)
AWS 公式ドキュメントより、現時点での RFT 対応モデルは以下の通りです。
| Provider | Model | Model ID | Region |
|---|---|---|---|
| Amazon | Nova 2 Lite | amazon.nova-2-lite-v1:0:256k | us-east-1 |
Nova 2 Liteのみ、かつus-east-1リージョンのみのサポート。
Example Lambda
今回はRFTの例として、指定した文字数以内で回答できるようにモデルをファインチューニングします。
LLMを使うときにプロンプトで「x文字以内で答えてください」と指示しても余計な説明を付けて制限を守らないことがあるので、それを解決します。
基本的にはここの流れで進めます。
全体のすすめかた
基本的にCDKとAWS CLIで進めていきます。
| ステップ | AWS CLI コマンド | 説明 |
|---|---|---|
| Lambda デプロイ | cdk deploy |
報酬関数 (Lambda)、S3、IAM Role を作成 |
| RFT ジョブ作成 | aws bedrock create-model-customization-job |
トレーニングジョブを開始 |
| ジョブ状態確認 | aws bedrock get-model-customization-job |
進捗とステータスを確認 |
| メトリクス取得 | aws s3 cp |
トレーニング結果を S3 から取得 |
| モデルテスト | aws bedrock-runtime converse |
カスタムモデルで推論テスト |
RFT の全体フローは以下の通りです:
┌─────────────────────────────────────────────────────────────────┐
│ 1. 報酬関数の実装 (Lambda) │
│ モデル出力を評価し、スコア (0.0〜1.0) を返す │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 2. トレーニングデータの準備 (JSONL) │
│ プロンプトのみ記載(正解は不要) │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 3. インフラのデプロイ (CDK) │
│ Lambda, S3, IAM Role を作成 │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 4. RFT ジョブの実行 (Bedrock API) │
│ Bedrock がモデル出力 → Lambda で評価 → 強化学習を繰り返す │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 5. カスタムモデルのデプロイと評価 │
│ Deploy for on-demand → Playground or API でテスト │
└─────────────────────────────────────────────────────────────────┘
従来の教師ありファインチューニング (SFT) では正解データが必要ですが、
RFT では報酬関数を定義します。
Bedrockがモデル出力を生成してLambdaが評価し、その結果をもとに強化学習が進みます。
報酬関数
報酬関数(Reward Function)とは、モデルの出力が「良い」か「悪い」か評価し、
スコア(0.0〜1.0)を返す関数です。
RFT ではこのスコアをフィードバックとして、モデルが「良いスコアが出る出力」を学習します。
これは、正解を定義しにくいタスクに有効となりますし、
大量のデータセットを用意する必要もなくなります。
Amazon Bedrock での報酬関数
Bedrock RFT では2 種類のアプローチを提供しています。
今回は文字数制限というルールで判定できるため、RLVRを使用します。
- RLVR : 客観的に正誤判定できるタスク(Lambdaで評価)
- RLAIF: モデレーションなど主観的評価が必要なタスク(Model as Judgeで評価)
今回実装する報酬関数は、以下のシンプルなルールを実装します。
| 出力 | 報酬スコア |
|---|---|
| 文字数制限以内 | 1.0 |
| 文字数制限超過 | 0.0 |
この報酬関数をLambda(Rust)として実装します。
トレーニングデータ
RFT のトレーニングデータは JSONL 形式で、プロンプトのみを記載します(正解は不要)。
{"messages": [{"role": "user", "content": "AIとは何か30文字以内で説明して"}]}
{"messages": [{"role": "user", "content": "クラウドコンピューティングを40文字以内で説明して"}]}
{"messages": [{"role": "user", "content": "機械学習とは何か25文字以内で答えて"}]}
Bedrock は各プロンプトに対してモデルに回答を生成させ、Lambda 報酬関数で評価します。
Lambda実装
報酬関数の重要な部分を解説します。
Lambda が受け取る入力
トレーニング中、Bedrock は以下のような JSON を Lambda に送信します。
messages にはユーザーのプロンプトと、モデルが生成した assistant の回答が含まれます。
[
{
"id": 0,
"messages": [
{"role": "user", "content": "AIとは何か30文字以内で説明して"},
{"role": "assistant", "content": "人工知能の略で、機械が学習・推論する技術"}
]
},
{
"id": 1,
"messages": [
{"role": "user", "content": "機械学習を25文字以内で説明して"},
{"role": "assistant", "content": "データからパターンを学ぶ技術"}
]
}
]
Lambda はこの入力を受け取り、各サンプルの assistant 回答を評価してスコアを返します。
入出力の型定義(Rust)
上記の JSON に対応する型を定義します。
/// RFT から送られてくる入力
#[derive(Deserialize)]
struct RftSample {
id: u64, // サンプルID(整数)
messages: Vec<Message>, // 会話履歴
}
/// Lambda が返す報酬スコア
#[derive(Serialize)]
struct RewardResult {
id: u64, // 入力と同じID
aggregate_reward_score: f64, // 報酬スコア (0.0〜1.0)
}
最初はidをStringで定義していたのですが、
実際は整数で送られてきてエラーになっていたので数値に変更。
文字数制限の抽出
ユーザーメッセージから「30文字以内」などの制限値を正規表現で抽出します。
fn extract_char_limit(user_message: &str) -> Option<usize> {
let patterns = [
r"(\d+)\s*文字以内",
r"(\d+)\s*字以内",
];
for pattern in patterns {
if let Some(caps) = Regex::new(pattern).ok()?.captures(user_message) {
return caps.get(1)?.as_str().parse().ok();
}
}
None
}
報酬スコア計算
モデルの出力文字数と制限を比較し、スコアを返します。
limit以内なら1.0、それ以外は0というシンプルなロジック。
fn calculate_reward(response: &str, limit: usize) -> f64 {
let actual = response.trim().chars().count(); // Unicode文字数
if actual <= limit { 1.0 } else { 0.0 }
}
ヘルパー関数
ユーザーメッセージから文字数制限を抽出し、アシスタントの応答を取得します。
/// ユーザーメッセージから文字数制限を抽出(例: "30文字以内で" → Some(30))
fn extract_char_limit(user_message: &str) -> Option<usize> {
let re = Regex::new(r"(\d+)\s*文字以内").ok()?;
re.captures(user_message)?.get(1)?.as_str().parse().ok()
}
/// メッセージ配列からアシスタントの応答を取得
fn get_assistant_response(messages: &[Message]) -> Option<&str> {
messages.iter()
.filter(|m| m.role == "assistant")
.last()
.map(|m| m.content.as_str())
}
/// メッセージ配列からユーザーの最後のメッセージを取得
fn get_user_message(messages: &[Message]) -> Option<&str> {
messages.iter()
.filter(|m| m.role == "user")
.last()
.map(|m| m.content.as_str())
}
Lambda handler
Bedrock RFTは複数のサンプルを配列で送信するため、以下のように処理します。
async fn handler(event: LambdaEvent<serde_json::Value>) -> Result<serde_json::Value, Error> {
let samples: Vec<RftSample> = serde_json::from_value(event.payload)?;
let results: Vec<RewardResult> = samples
.into_iter()
.map(|sample| {
let user_msg = get_user_message(&sample.messages);
let limit = user_msg.and_then(extract_char_limit);
let response = get_assistant_response(&sample.messages);
let score = match (response, limit) {
(Some(res), Some(lim)) => calculate_reward(res, lim),
_ => 0.0, // 応答または制限がない場合は0点
};
RewardResult { id: sample.id, aggregate_reward_score: score }
})
.collect();
Ok(serde_json::to_value(results)?)
}
Build
ビルドしましょう。
これでデプロイ準備完了です。
$ cd lambda-reward
$ cargo lambda build --release --arm64
・・・
Deploy
では、さきほど cargo lambda build でビルドした Lambda とその他リソースをデプロイしましょう。
CDK実行
CDK が target/lambda/rft-char-limit-reward/bootstrap を Lambda にデプロイします。
※CDKのコードは本記事のAppendixを参照
$ CDK_DEFAULT_ACCOUNT=xxxxx CDK_DEFAULT_REGION=us-east-1 \
% pnpm exec cdk deploy
# 出力:
# RftJsonRewardStack.RewardFunctionArn = arn:aws:lambda:us-east-1:xxxxx:function:rft-char-limit-reward
# RftJsonRewardStack.TrainingDataBucketName = xxxxxxx
# RftJsonRewardStack.BedrockRftRoleArn = arn:aws:iam::xxxxxx:role/BedrockRftJsonDemoRole
CDK スタックでデプロイされるリソースは以下です。
- Lambda:
rft-char-limit-reward(Rust, ARM64) - S3:
xxxxxxxxx - IAM Role:
BedrockRftJsonDemoRole(Bedrock RFT 用) - トレーニングデータと検証データを自動アップロード(後述)
データ準備 — トレーニング・検証データ
トレーニングと検証に使うデータを準備します。
以下のようなjsonlデータを生成AIに作成させます。
トレーニングデータ: 110 サンプル (char-limit-training.jsonl)
検証データ: 15 サンプル (char-limit-validation.jsonl)
#サンプル例
{"messages": [{"role": "user", "content": "AIとは何か30文字以内で説明して"}]}
{"messages": [{"role": "user", "content": "クラウドコンピューティングを40文字以内で説明して"}]}
{"messages": [{"role": "user", "content": "機械学習とは何か25文字以内で答えて"}]}
{"messages": [{"role": "user", "content": "日本の首都を10文字以内で答えて"}]}
トレーニング開始 — RFT ジョブ作成
aws bedrock create-model-customization-job コマンドで RFT ジョブを作成します。
パラメータは以下。
| パラメータ | 説明 |
|---|---|
--job-name |
ジョブの識別名 |
--base-model-identifier |
ベースモデル(現時点では Nova 2 Lite のみ) |
--customization-type |
REINFORCEMENT_FINE_TUNING を指定 |
--custom-model-name |
作成されるカスタムモデルの名前 |
--role-arn |
Bedrock が使用する IAM ロール(S3, Lambda アクセス権限が必要) |
--training-data-config |
トレーニングデータの S3 URI |
--validation-data-config |
検証データの S3 URI |
--output-data-config |
出力先の S3 URI(メトリクス等が保存される) |
--customization-config |
RFT 固有の設定(下記参照) |
customization-config
RFT設定は以下。
| 設定 | 説明 |
|---|---|
lambdaGrader.lambdaArn |
報酬関数として使用する Lambda の ARN |
epochCount |
トレーニングのエポック数 |
trainingSamplePerPrompt |
1プロンプトあたりの生成回答数 |
実際の実行コマンドは以下。
$ aws bedrock create-model-customization-job \
--job-name "rft-char-limit" \
--base-model-identifier "amazon.nova-2-lite-v1:0:256k" \
--customization-type "REINFORCEMENT_FINE_TUNING" \
--custom-model-name "nova-2-lite-char-limit-v1" \
--role-arn "arn:aws:iam::xxxxxx:role/BedrockRftJsonDemoRole" \
--training-data-config '{
"s3Uri": "s3://<created bucket>/training-data/char-limit-training.jsonl"
}' \
--validation-data-config '{
"validators": [{
"s3Uri": "s3://<created bucket>/training-data/char-limit-validation.jsonl"
}]
}' \
--output-data-config '{
"s3Uri": "s3://<created bucket>/output/"
}' \
--customization-config '{
"rftConfig": {
"graderConfig": {
"lambdaGrader": {
"lambdaArn": "arn:aws:lambda:us-east-1:xxxxx:function:rft-char-limit-reward"
}
},
"hyperParameters": {
"epochCount": 10,
"trainingSamplePerPrompt": 8
}
}
}' \
--region us-east-1
Job ARNが返却されれば成功です。
私の場合、30分前後でトレーニングが完了しました。
なお、RFTジョブ実行中にLambdaでエラーが発生した場合は
CloudWatchログで確認できます。
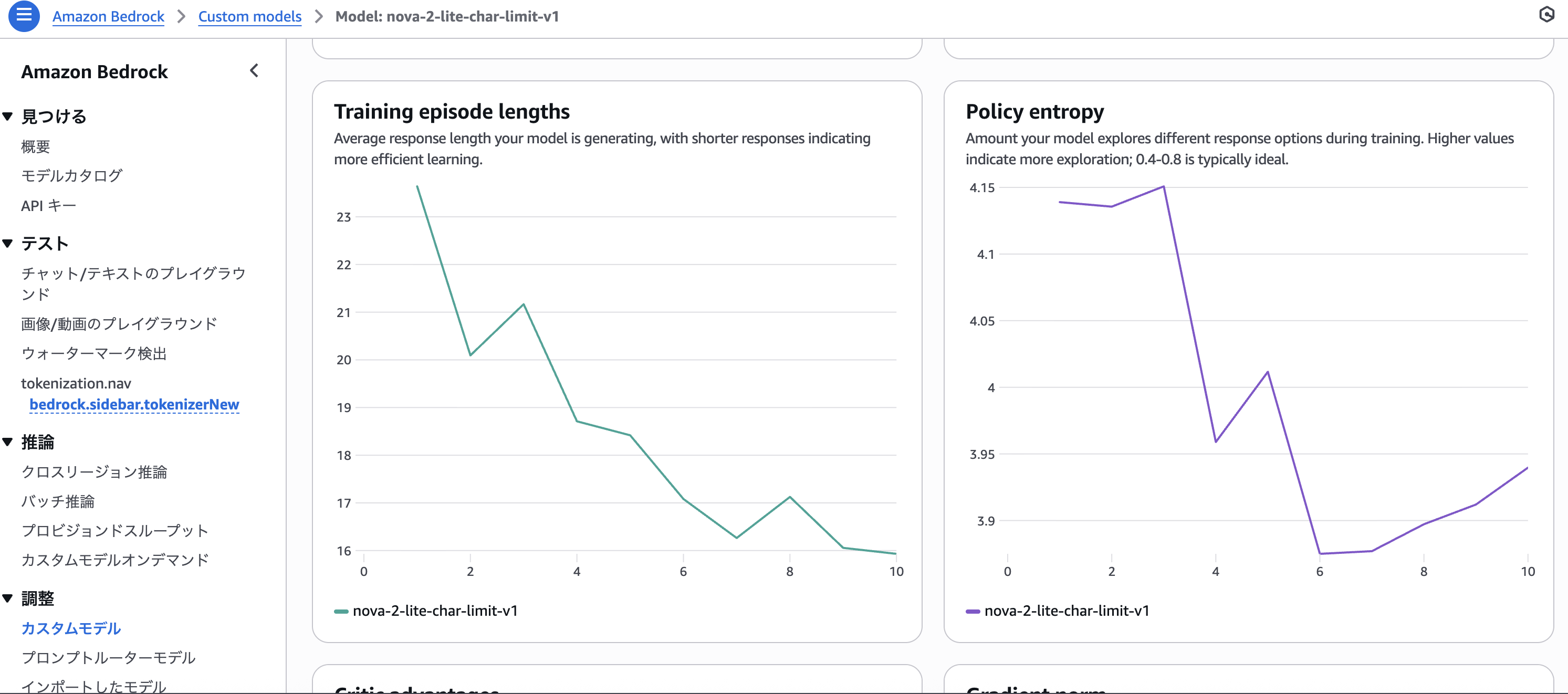
トレーニングメトリクス確認
トレーニングメトリクスを確認しましょう。
作成したバケットのoutput以下にCSVができています。
実際のメトリクスは以下のようになってました。
トレーニング結果(10エポック):
| Epoch | train_reward_mean | 変化 |
|---|---|---|
| 0 | 0.307 | ベースライン |
| 1 | 0.419 | +0.11 |
| 2 | 0.542 | +0.12 |
| 3 | 0.580 | +0.04 |
| 4 | 0.603 | +0.02 |
| 5 | 0.695 | +0.09 |
| 6 | 0.736 | +0.04 |
| 7 | 0.728 | -0.01 |
| 8 | 0.752 | +0.02 |
| 9 | 0.748 | -0.00 |
検証結果:
結果は以下でした。
- トレーニング開始時: 31% (0.307)
- トレーニング終了時: 75% (0.748)
- 検証データ: 93% (0.933)
モデルは文字数制限を守ることについて学習できている様子。
AWSコンソールでメトリクスを見ることもできます。
カスタムモデル生成
トレーニングが完了してカスタムモデルができたので試してみましょう。
カスタムモデルを Playground でテストするには、オンデマンド推論用にデプロイする必要があります。
AWSコンソールからデプロイするのは以下。
- Amazon Bedrock → Custom modelsに移動
- 作成したカスタムモデルを選択
- 「Set up inference」 をクリック
- 「Deploy for on-demand」 を選択
- デプロイ名を入力して作成
AWS CLIでもカスタムモデルのデプロイが可能です。
# カスタムモデルの ARN を取得
% aws bedrock list-custom-models --region us-east-1
# オンデマンド推論用にデプロイ
% aws bedrock create-custom-model-deployment \
--model-deployment-name "rft-char-limit-deployment" \
--model-id "<取得したカスタムモデルのARN>" \
--region us-east-1
参考: Deploy a custom model for on-demand inference
Playground でのテスト
デプロイ完了後、「Test in playground」 ボタンからテストできます。
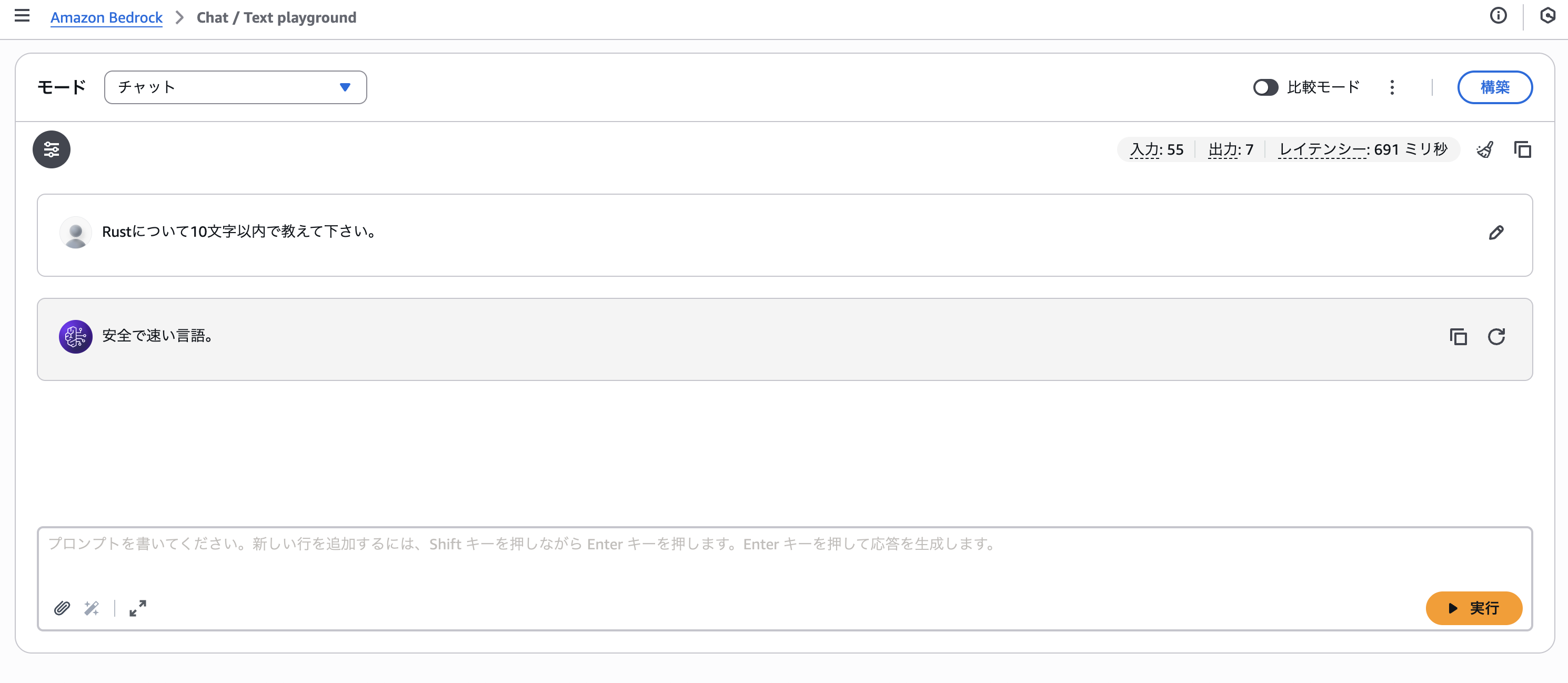
今回はAWS CLIを使用して、以下のように2つのモデルをテストしました。
# ベースモデル
aws bedrock-runtime converse \
--model-id "us.amazon.nova-2-lite-v1:0" \
--messages '[{"role":"user","content":[{"text":"機械学習を20文字以内で説明して"}]}]' \
--inference-config '{"temperature":0,"maxTokens":100}' \
--region us-east-1
# カスタムモデル
aws bedrock-runtime converse \
--model-id "arn:aws:bedrock:us-east-1:ACCOUNT_ID:custom-model-deployment/DEPLOYMENT_ID" \
--messages '[{"role":"user","content":[{"text":"機械学習を20文字以内で説明して"}]}]' \
--inference-config '{"temperature":0,"maxTokens":100}' \
--region us-east-1
比較結果(n=10、15〜35文字制限、temperature=0):
| プロンプト | 制限 | カスタム | ベース |
|---|---|---|---|
| 機械学習を | 20文字 | o 17文字 | o 20文字 |
| インターネットを | 25文字 | o 19文字 | x 27文字 |
| データベースを | 20文字 | o 11文字 | x 25文字 |
| プログラミングを | 30文字 | o 21文字 | o 28文字 |
| ブロックチェーンを | 25文字 | o 13文字 | o 16文字 |
| AIとは何か | 15文字 | o 12文字 | o 15文字 |
| クラウドコンピューティングを | 35文字 | o 27文字 | x 41文字 |
| APIとは何か | 20文字 | x 26文字 | x 31文字 |
| セキュリティを | 25文字 | o 24文字 | x 35文字 |
| IoTを | 15文字 | o 11文字 | x 26文字 |
強化学習したモデルのほうが良い結果がでています。
少ないテストデータでも一応、効果が確認できました。
Summary
本記事では、Amazon Bedrock の強化学習ファインチューニング (RFT) を使って、
カスタムモデルを作成して文字数制限を守らせる方法を試してみました。
Lambdaで報酬関数を定義してテストデータに対して実行させることでモデルを改善させ、
実際にモデルの性能が改善されることが確認できたかと思います。
RFTでは構造化出力やガイドラインの遵守などの評価指標を定義できるタスクが向いているので、
いろいろ利用できそうですね。
References
- AWS Blog: Improve model accuracy with reinforcement fine-tuning in Amazon Bedrock
- Amazon Bedrock User Guide: Reinforcement fine-tuning
- Amazon Bedrock User Guide: Setting up reward functions
- Amazon Bedrock User Guide: Create a reinforcement fine-tuning job
- Amazon Bedrock で Reinforcement Fine-tuning が発表されました #AWSreInvent | DevelopersIO
- 「Reinforcement Fine-tuning 基礎〜実践まで」 というテーマで登壇しました #AWSreInvent #cmregrowth | DevelopersIO
Appendix
CDKコード
RFT に必要なリソース(Lambda、S3、IAM Role)をデプロイする CDK スタック。
import * as cdk from "aws-cdk-lib";
import * as lambda from "aws-cdk-lib/aws-lambda";
import * as iam from "aws-cdk-lib/aws-iam";
import * as s3 from "aws-cdk-lib/aws-s3";
import * as s3deploy from "aws-cdk-lib/aws-s3-deployment";
import { Construct } from "constructs";
import * as path from "path";
export class RftRewardStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// S3 バケット(トレーニングデータ用)
const bucket = new s3.Bucket(this, "TrainingDataBucket", {
bucketName: `rft-demo-${this.account}-${this.region}`,
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
// トレーニングデータを S3 にデプロイ
new s3deploy.BucketDeployment(this, "DeployTrainingData", {
sources: [s3deploy.Source.asset(path.join(__dirname, "../../training-data"))],
destinationBucket: bucket,
destinationKeyPrefix: "training-data",
});
// Lambda 報酬関数(Rust)
const rewardFunction = new lambda.Function(this, "RewardFunction", {
functionName: "rft-char-limit-reward",
runtime: lambda.Runtime.PROVIDED_AL2023,
architecture: lambda.Architecture.ARM_64,
handler: "bootstrap",
code: lambda.Code.fromAsset(
path.join(__dirname, "../../lambda-reward/target/lambda/rft-char-limit-reward")
),
timeout: cdk.Duration.minutes(1),
memorySize: 256,
});
// Bedrock からの Lambda 呼び出し許可
rewardFunction.addPermission("BedrockInvoke", {
principal: new iam.ServicePrincipal("bedrock.amazonaws.com"),
action: "lambda:InvokeFunction",
});
// Bedrock RFT ジョブ用 IAM Role
const bedrockRole = new iam.Role(this, "BedrockRftRole", {
roleName: "BedrockRftRole",
assumedBy: new iam.ServicePrincipal("bedrock.amazonaws.com"),
});
bucket.grantRead(bedrockRole); // トレーニングデータ読み取り
bucket.grantWrite(bedrockRole, "output/*"); // 出力書き込み
rewardFunction.grantInvoke(bedrockRole); // Lambda 呼び出し
// 出力
new cdk.CfnOutput(this, "LambdaArn", { value: rewardFunction.functionArn });
new cdk.CfnOutput(this, "BucketName", { value: bucket.bucketName });
new cdk.CfnOutput(this, "RoleArn", { value: bedrockRole.roleArn });
}
}










