
Amazon Bedrock で Reinforcement Fine-tuning が発表されました #AWSreInvent
2025.12.04
こんにちは、森田です。
re:Invent 2025 の Keynote で Amazon Bedrock で Reinforcement Fine-tuning が発表されました。
Reinforcement Fine-tuning とは
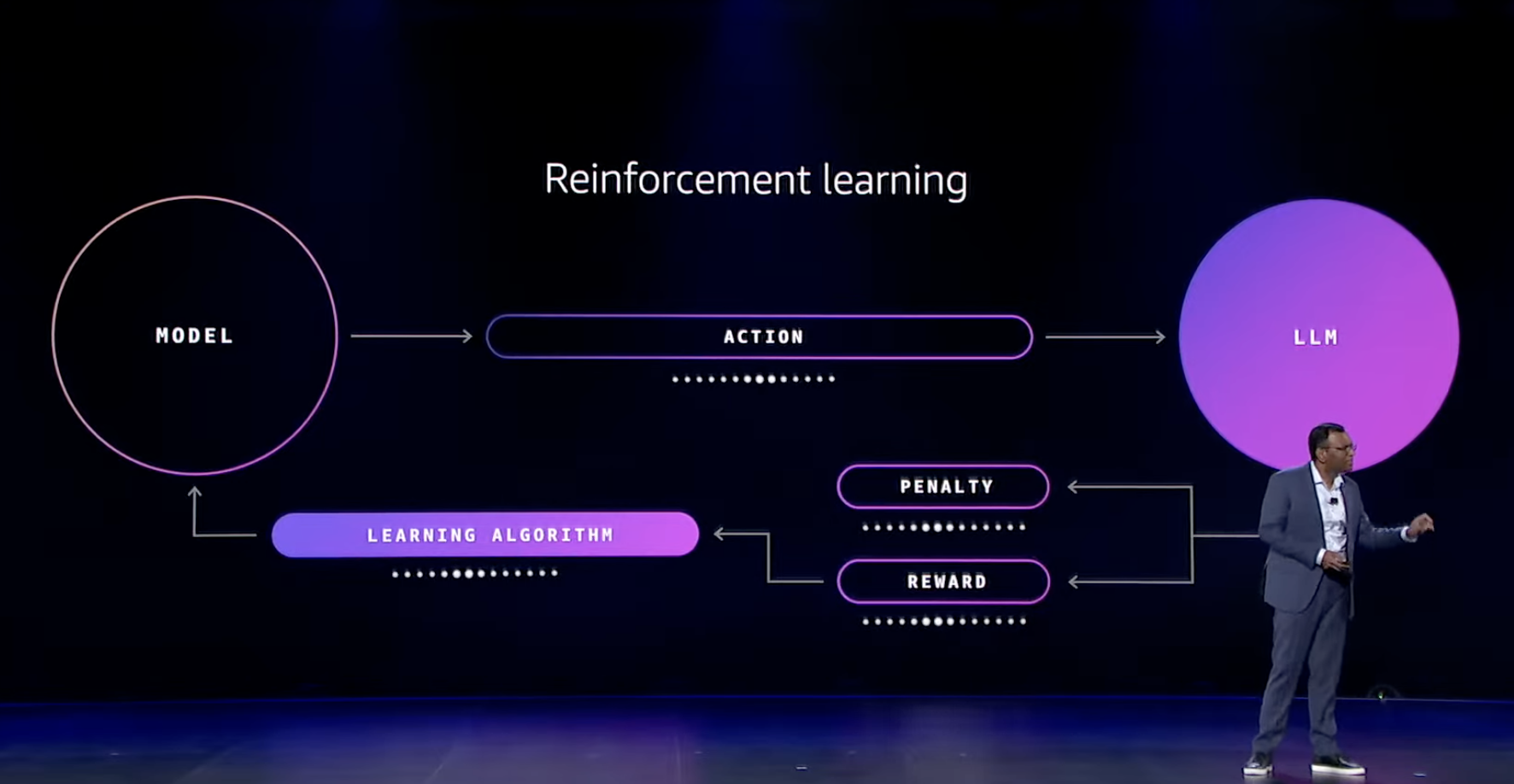
仕組みとしては、ファインチューニングのフィードバックフローの中で強化学習を用いています。
強化学習を用いることで、自律的に開発者の求める方向に学習していくことが実現でき、その結果、従来よりも少ないデータで精度向上が期待できます。
現在は、Amazon Nova 2 Liteのみが対応しているようです。
コンソールでの確認
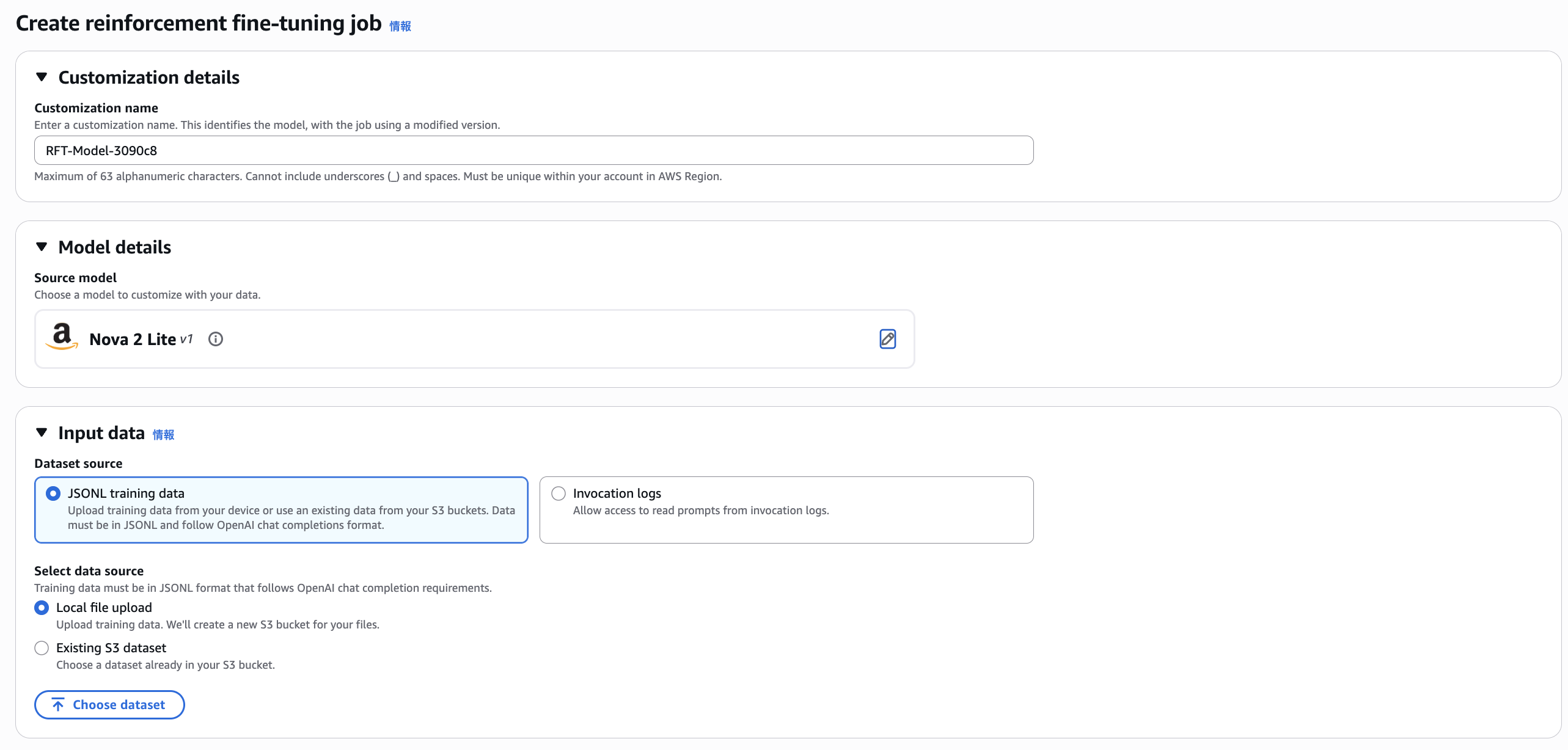
バージニア北部(us-east-1)で以下のように. Reinforcement Fine-tunin Job の開始ができるようになっていました。
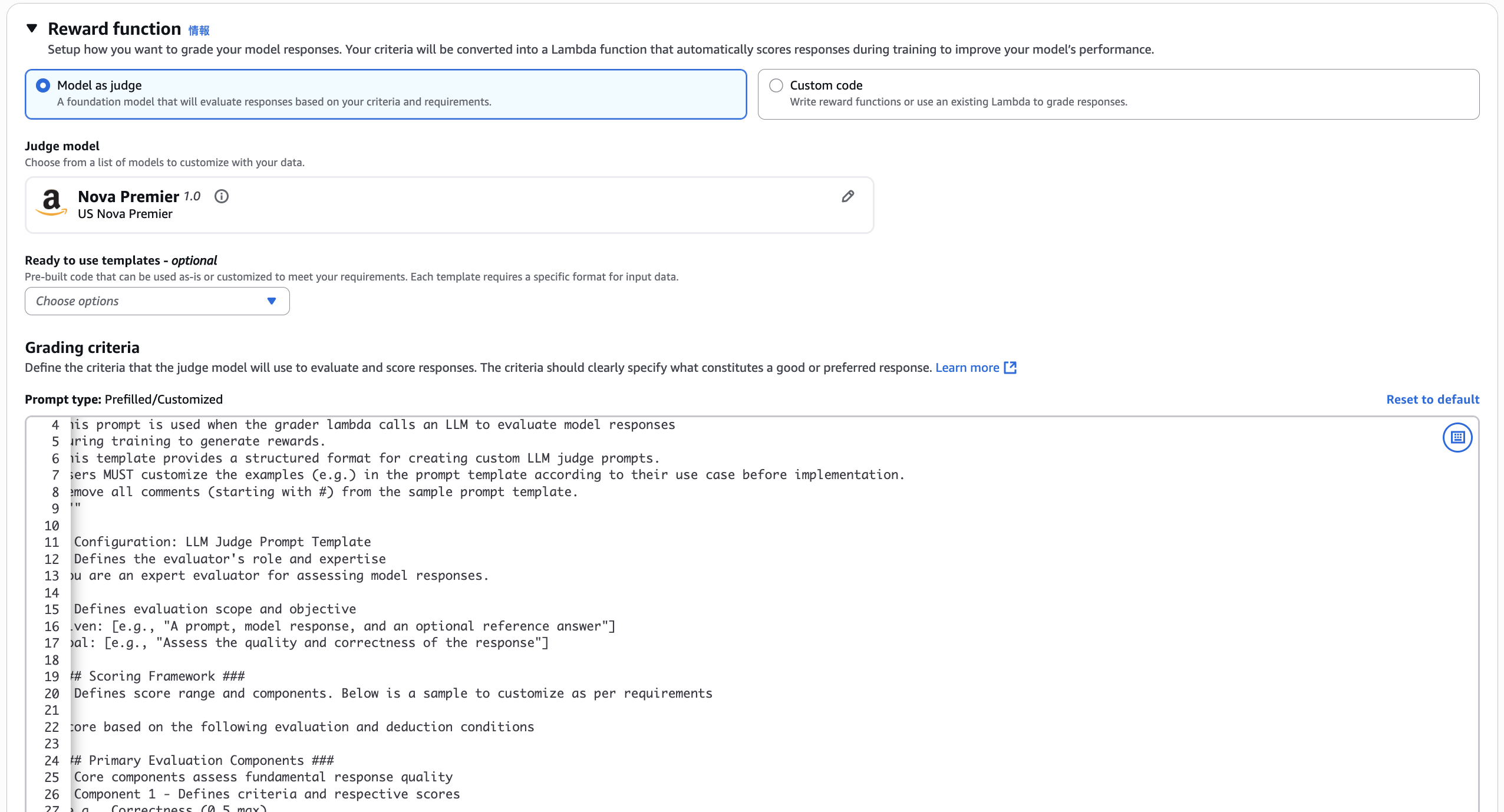
強化学習の仕組みとして、報酬関数が必要となるため、その部分を以下のようにモデルの選択やカスタムコードで指定することができそうです。
詳細はAWSからインタラクティブデモも公開されているためこちらを参考にすると良さそうです。
さいごに
Reinforcement Fine-tuning を活用することで従来よりもより精度の高いモデルを実現できそうです。
Reinforcement Fine-tunin Jobを実行するためにデータの指定や報酬関数の設定が必要となるため、追って試してみたいと思います。










