
Amazon Bedrock Knowledge BasesとAmazon S3 Vectorsを用いて、画像とメタデータによる部品検索を試してみた #AWSreInvent
この記事はクラスメソッド発 製造業 Advent Calendar 2025の8日目です。
製造業のユースケースを想定して、画像とメタデータを組み合わせた部品検索をAmazon Bedrock Knowledge BasesとAmazon S3 Vectorsを用いて試してみます。
先日、Amazon Bedrock Knowledge BasesでAmazon Nova Multimodal Embeddingsを使った画像埋め込みによるマルチモーダル検索がサポートされました。これまでは、Amazon Bedrock Data Automation(BDA)で画像やPDFなどをテキストに変換してから検索するアプローチが中心でしたが、今回のアップデートにより、画像そのものをベクトル化して検索で使えるようになりました。
一方で、Amazon S3 Vectorsは、S3上にベクトルインデックスを管理できるベクトルストアで、低コストかつマネージドで利用できます。元々プレビューとして利用可能でしたが、先日のアップデートによりGAになり、東京リージョンでも利用可能となりました。機能としては、キーワードでの部分一致検索とのハイブリッド検索はできないものの、ベクトル類似度検索とメタデータによるフィルタリングには対応しています。シンプルなRAG / ナレッジベース用途など小さく始める場合に向いています。
製造業の現場では、たとえば「このネジは何か?」「似たようなネジを探したい」といった、画像から部品を特定・類似検索したいケースがありそうです。このとき、画像だけに頼るのではなく、事前に測定した「ねじの呼び径(例: M6)」「長さ(例: 20mm)」「材質」「表面処理」といった情報をメタデータとして持たせておくと、より効率よく候補を絞り込めます。また、リクエストしているユーザーの部署や拠点といったメタデータで検索対象を制限すると、ユーザーごとに閲覧すべきデータに絞ることもできます。
そこで本記事では、こうしたユースケースを想定して、
- 部品の属性情報をメタデータとして登録し、
- 画像+メタデータを組み合わせて部品検索を行う
という流れを、Amazon Bedrock Knowledge BasesとAmazon S3 Vectorsを使って試してみます。
なお、Nova Multimodal Embeddingsは2025年12月8日時点ではus-east-1(バージニア北部)のみ利用可能なため、検証はus-east-1リージョンで行います。
やってみる
今回は画像データとして、家にあったネジを写真で撮り、それを用います。今回は機能の検証が目的なので、簡易的に2種類のネジを撮影し、そのうちの1つに対して写真を2枚撮り、長さが異なるネジとして登録します。
Pythonを用いてCSVからJSON形式のメタデータファイルを作成し、その後、マネジメントコンソールを中心に各リソースの作成や検証を行います。
メタデータの作成
まずは、エクセルなどでメタデータを作成し、CSVに出力します。今回利用するCSVは次のようなものです。
image_file,part_number,thread_size,length_mm
m4-20.jpg,SCREW-TAP-M4-20,M4,20
m4-30.jpg,SCREW-TAP-M4-30,M4,30
m3-6.jpg,SCREW-PAN-M3-6-BK,M3,6
以下のPythonスクリプトを用いて、CSVからJSON形式のメタデータファイルを作成します。
import csv
import json
from pathlib import Path
DATA_DIR = Path("data")
CSV_PATH = DATA_DIR / "parts.csv"
def main():
with CSV_PATH.open(encoding="utf-8-sig") as f:
reader = csv.DictReader(f)
for row in reader:
print(row)
image_file = row["image_file"].strip()
meta = {
"metadataAttributes": {
"part_number": row["part_number"].strip(),
"thread_size": row["thread_size"].strip(),
"length_mm": int(row["length_mm"]),
}
}
# 画像ファイルと同じ場所に <filename>.metadata.json を作成
meta_path = DATA_DIR / f"{image_file}.metadata.json"
print(f"write {meta_path}")
with meta_path.open("w", encoding="utf-8") as out:
json.dump(meta, out, ensure_ascii=False, indent=2)
if __name__ == "__main__":
main()
画像ファイルとparts.csvをdata/に配置し、pythonスクリプトを実行します。
python3 main.py
実行後、data/に画像ファイルごとに画像ファイル名.metadata.jsonが作成されます。
1つ中身を見てみると、各属性ごとにCSVで指定した値が入っています。
{
"metadataAttributes": {
"part_number": "SCREW-PAN-M3-6-BK",
"thread_size": "M3",
"length_mm": 6
}
}
S3バケットの作成とデータのアップロード
まずは2つのS3バケットを作成します。
- データソース用のS3バケット
- マルチモーダルストレージ用のS3バケット: データソース用とは異なるバケットを利用することが推奨されます
- ナレッジベース作成時にマルチモーダルストレージ用S3 URIに、
s3://バケット名/パスプレフィックス/のように指定すると、エラーになったため、バケットを直接指定する必要があるようです。
- ナレッジベース作成時にマルチモーダルストレージ用S3 URIに、
参考: Prerequisites for multimodal knowledge bases - Amazon Bedrock
マネジメントコンソールからS3バケットを開き、2つのS3バケットをそれぞれデフォルト設定で作成します。その際、リージョンがus-east-1になっていることを確認してください。
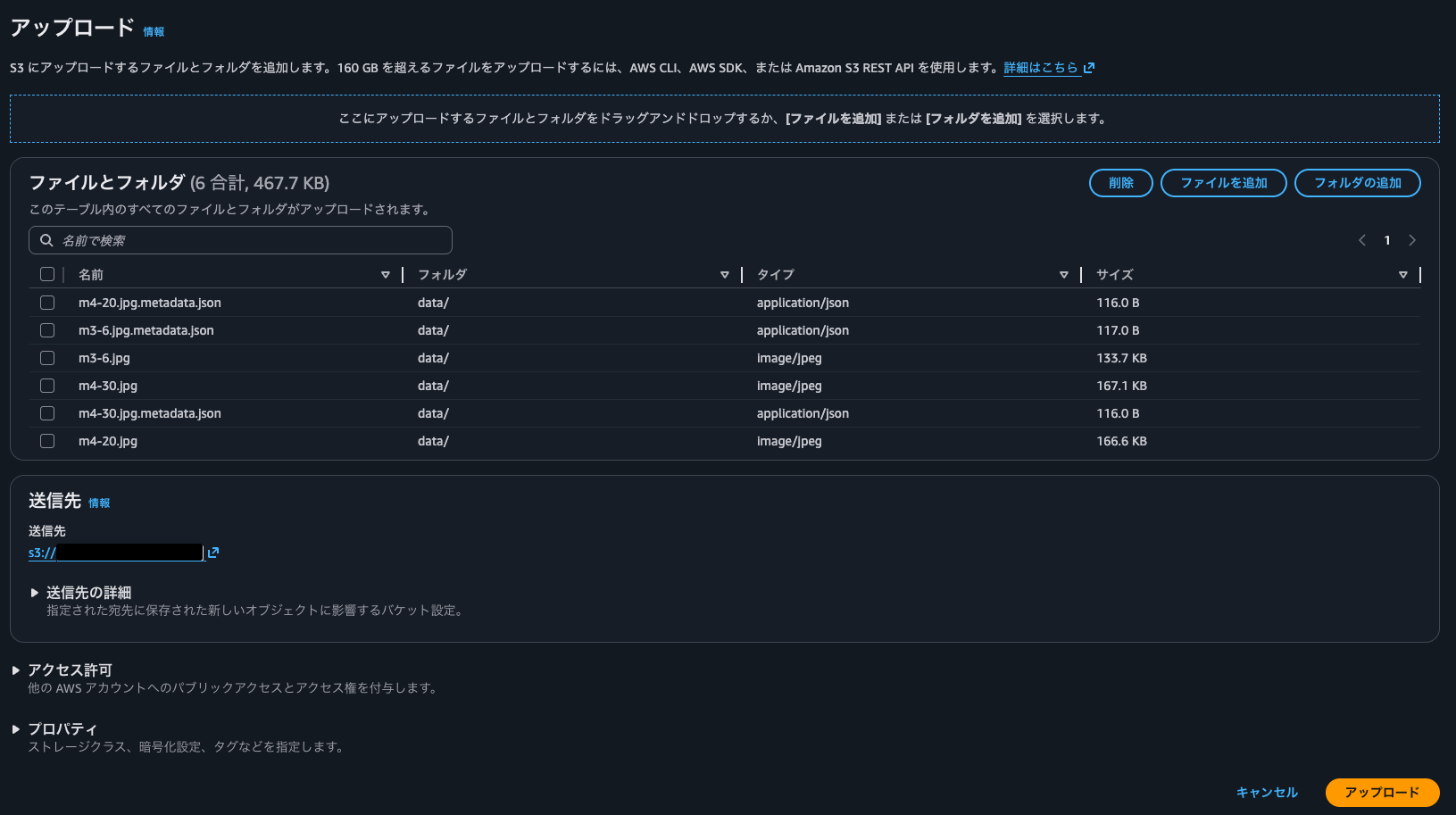
データソース用のS3バケットにdata/内のファイルをアップロードします。
S3バケットを選択して、オブジェクト一覧ページを開き、そこからアップロード画面に移動します。フォルダの追加をクリックし、data/を選択しアップロードします。
一覧にアップロード対象のファイルが表示されるので、不要なparts.csvは選択して削除します。
右下のアップロードボタンからアップロードします。
ナレッジベースの作成
次にナレッジベースを作成します。Bedrockのナレッジベースの画面を開き、作成ボタンから"ベクトルストアを含むナレッジベース"を選択します。
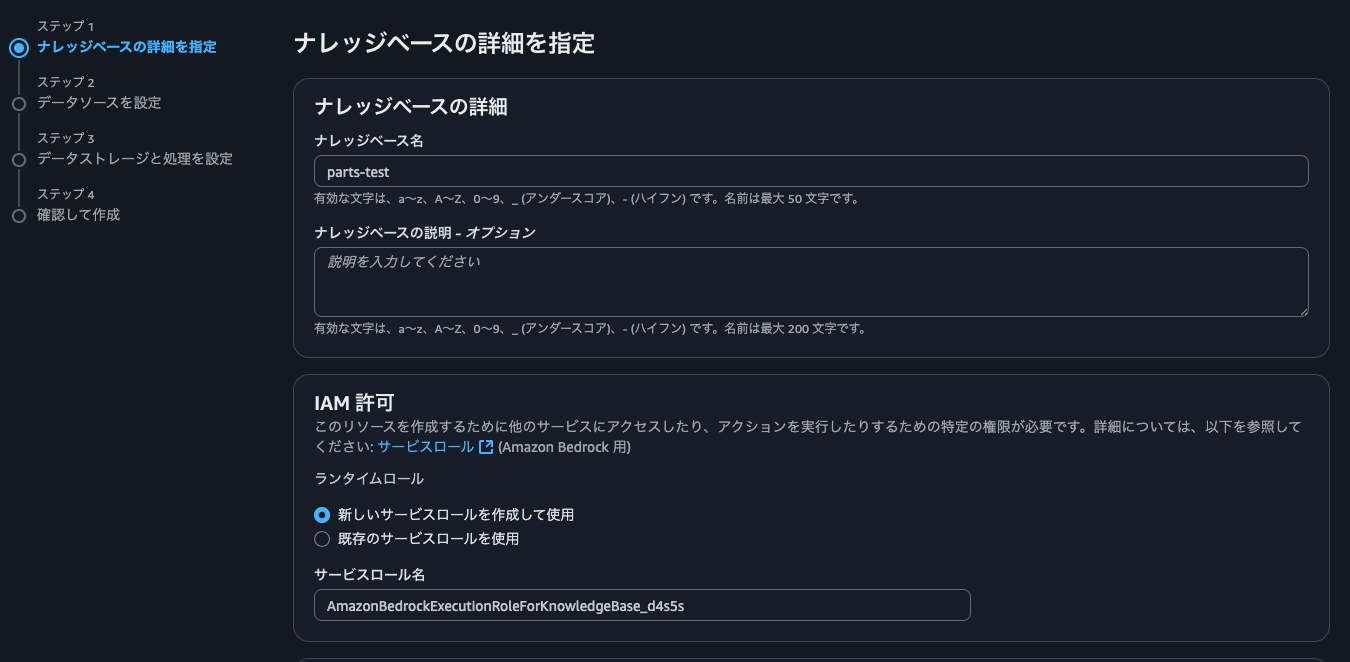
ナレッジベース名を入力し、Bedrockのサービスロールを作成して使用を選択します。
データソースにはデフォルトのS3を選択し、次に進みます。
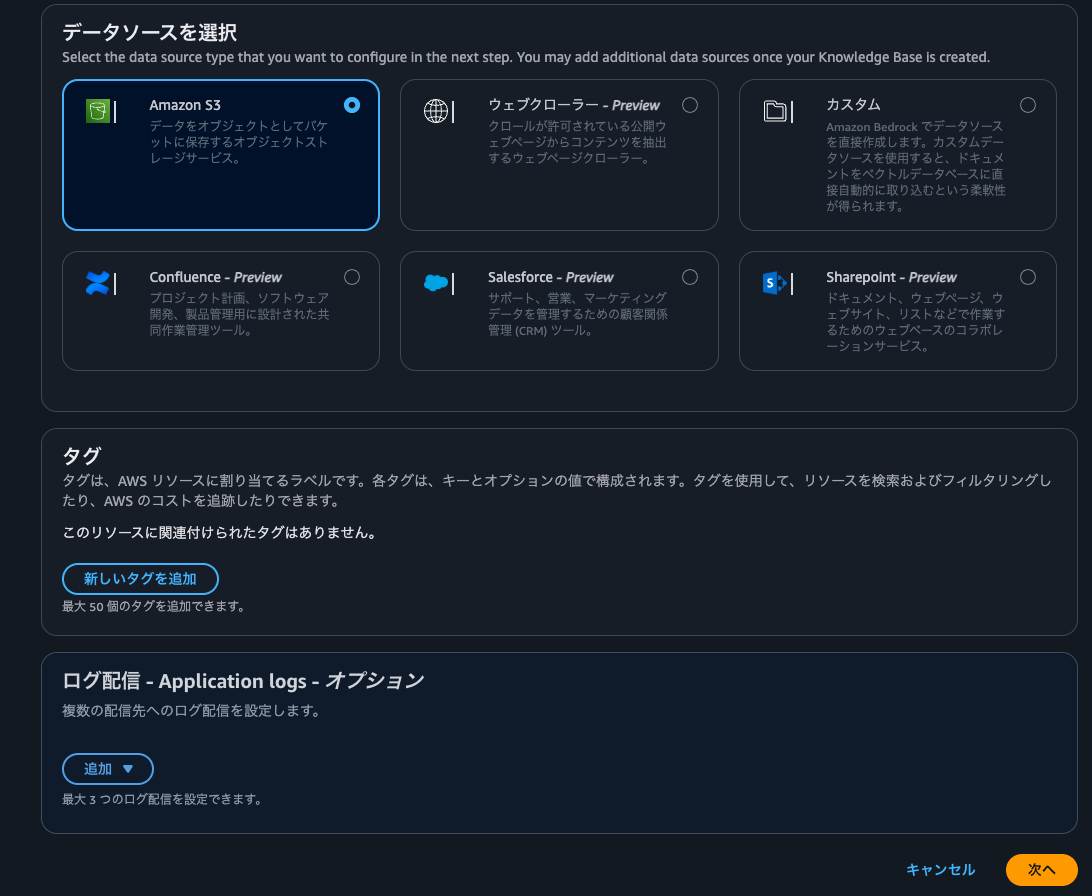
データソース名を入力し、S3のURIには先程データをアップロードした場所のURIを入力します。
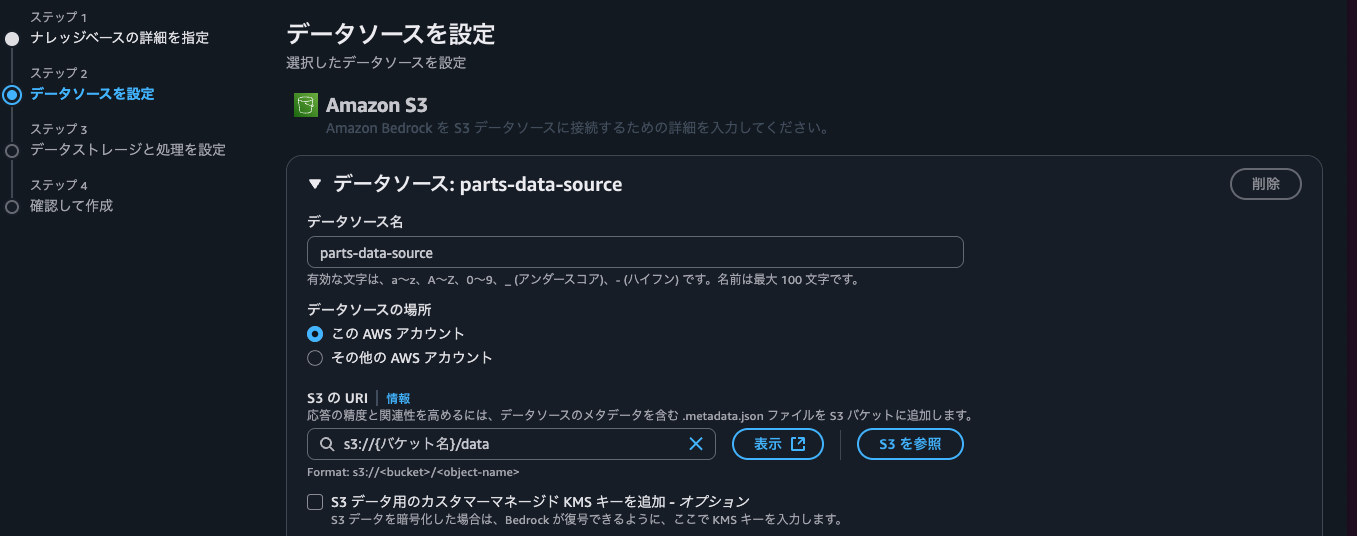
チャンキング(分割)などは不要なので、解析戦略にはデフォルトパーサー、チャンキング戦略にはチャンキングなしを選びます。
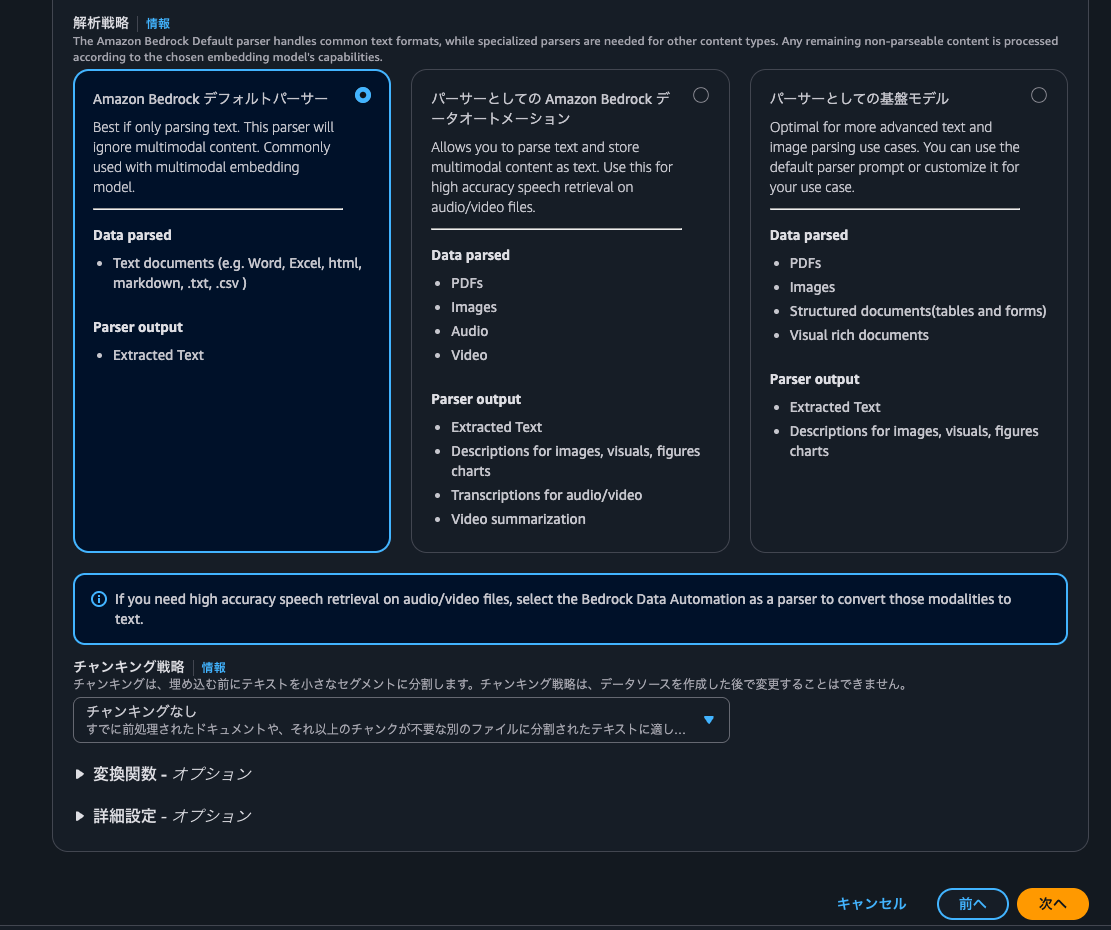
埋め込みモデルにはAmazon Nova Multimodal Embeddingsを選択し、ベクトルデータベースはクイック作成とS3 Vectorsを選択します。
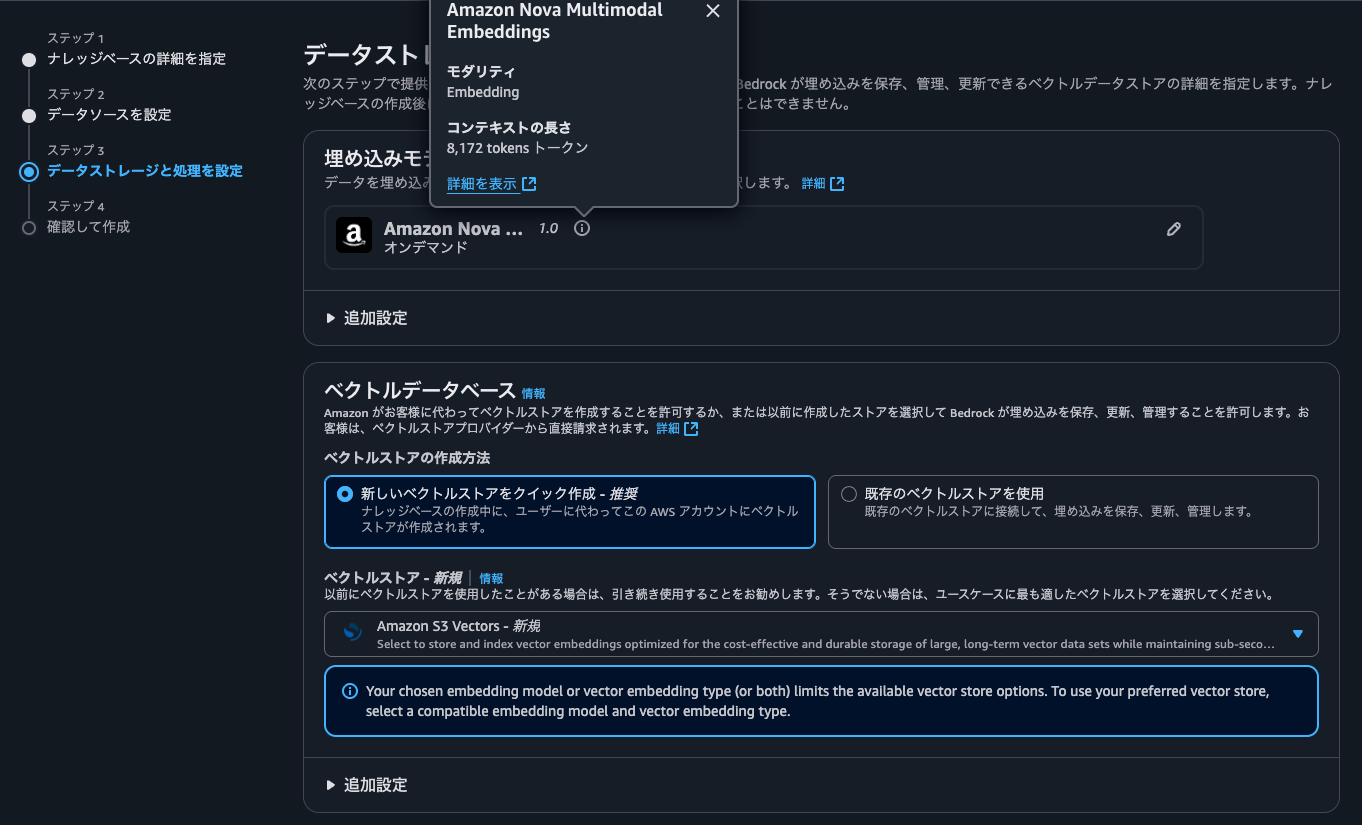
マルチモーダルストレージの保存先に、先程作成したS3バケットを指定して次に進みます。
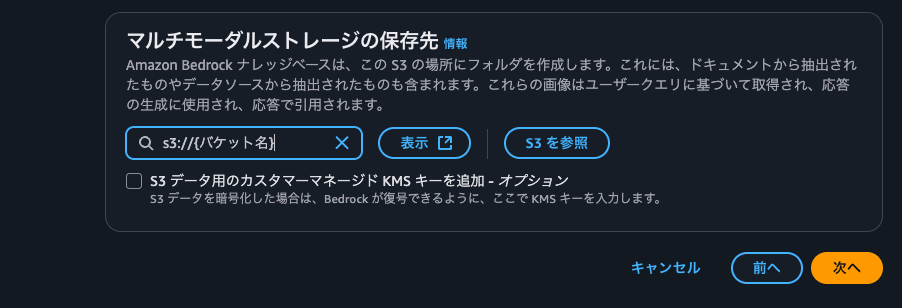
最後に確認画面で設定内容を確認し、問題なければ右下から作成します。
数十秒から数分で作成が完了します。
作成後、ナレッジベースの画面に自動的に遷移されるので、データソース一覧のところから"同期"します。
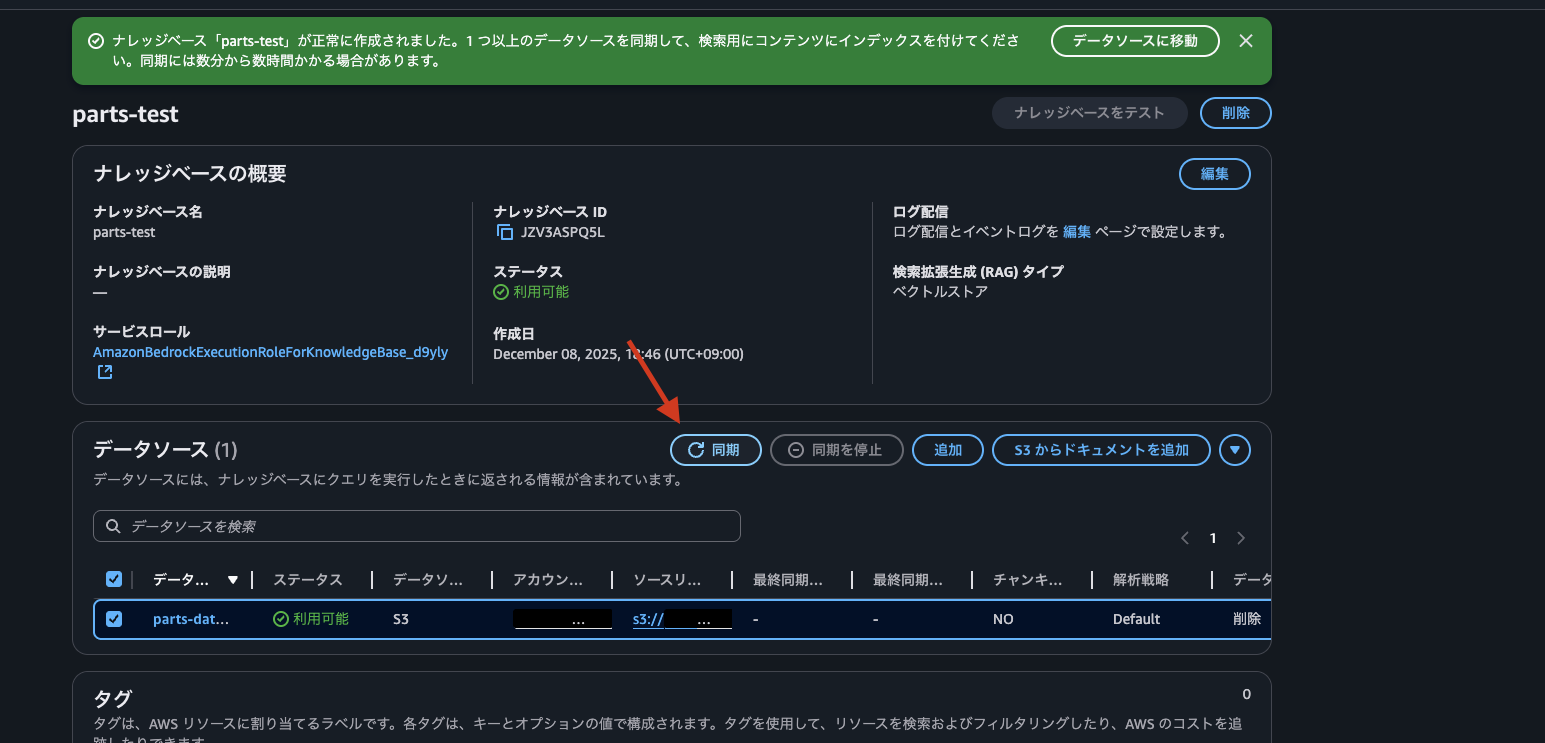
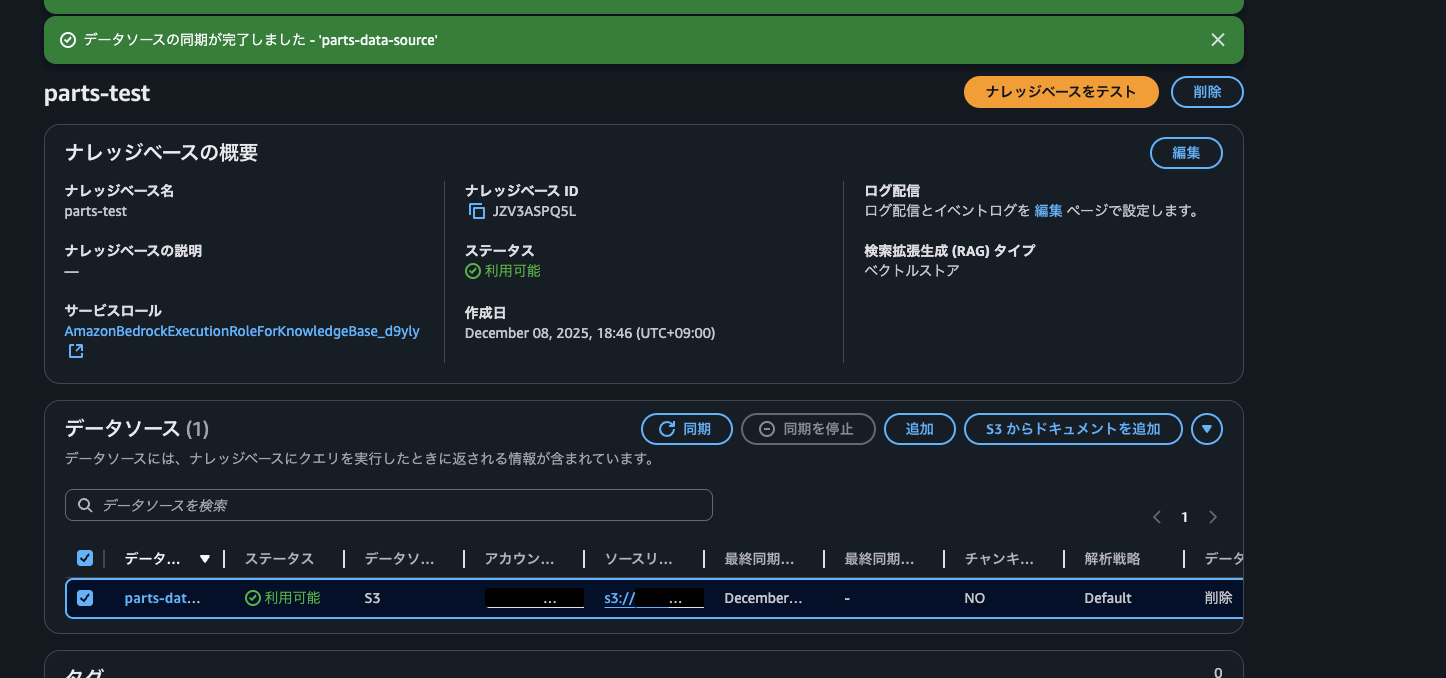
しばらくして、同期が完了すると、同期が完了した旨の表示とデータソースのステータスが利用可能になります。
画像検索の検証
ナレッジベースページの右側の"ナレッジベースをテスト"からナレッジベースの動作を確認することができるため、試してみます。

テスト画面が開いたら、まずは画像をフィルタ無しで画像を検索してみます。応答生成には対応していないため、取得応答生成で取得のみを選択します。次に右下のチャット欄でクリップアイコンから画像を添付します。この時、画像の拡張子がjpgには対応していないようで、jpegに変更してアップロードする必要があります。(ちなみに、ナレッジベースのデータソースにはjpgが含まれていても動作していました。テスト画面の入力としてjpgに対応していないようです。)
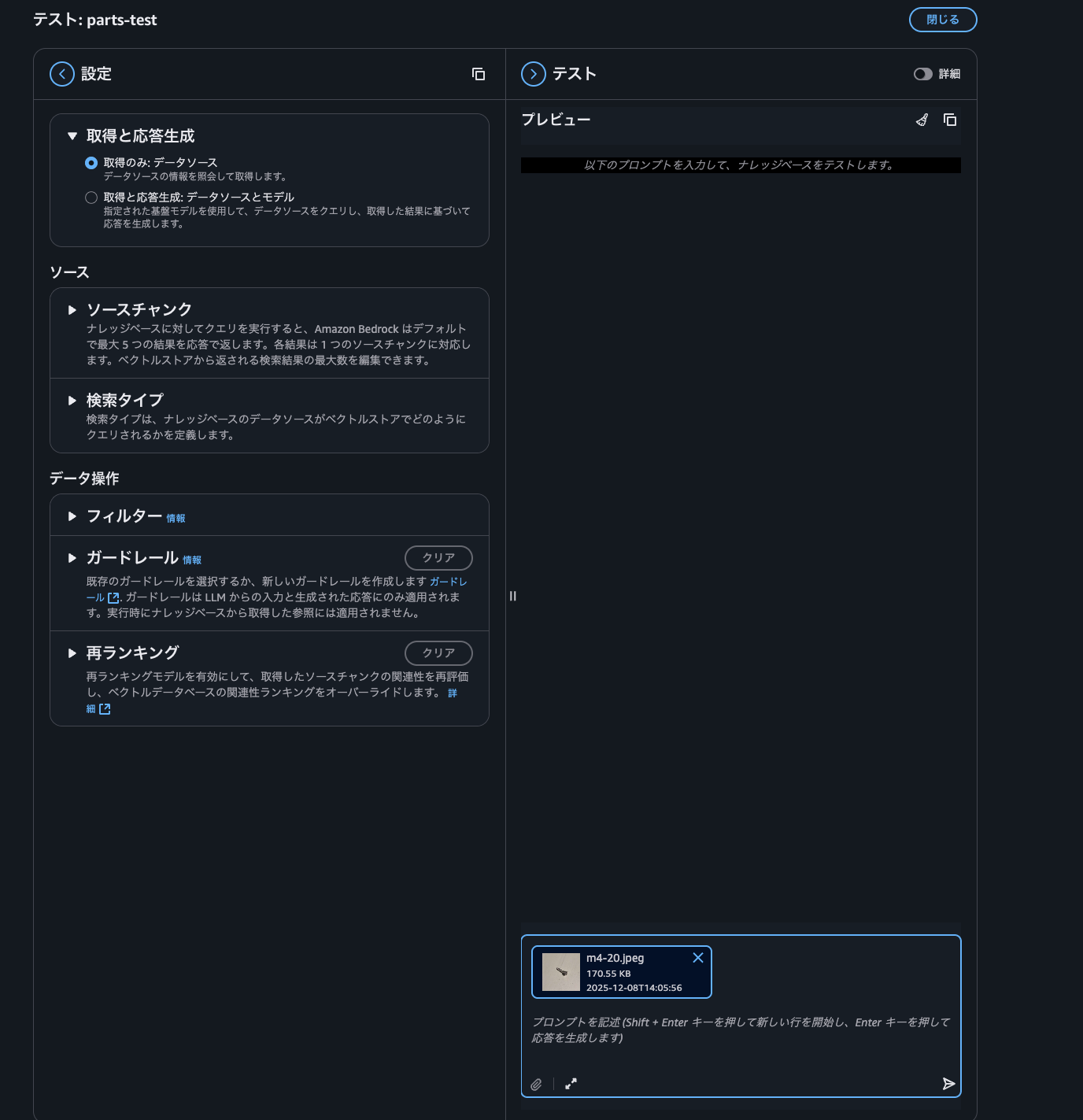
右下の送信アイコンのボタンを押すと、検索結果が表示されます。詳細ボタンを押すとスコアも表示されます。
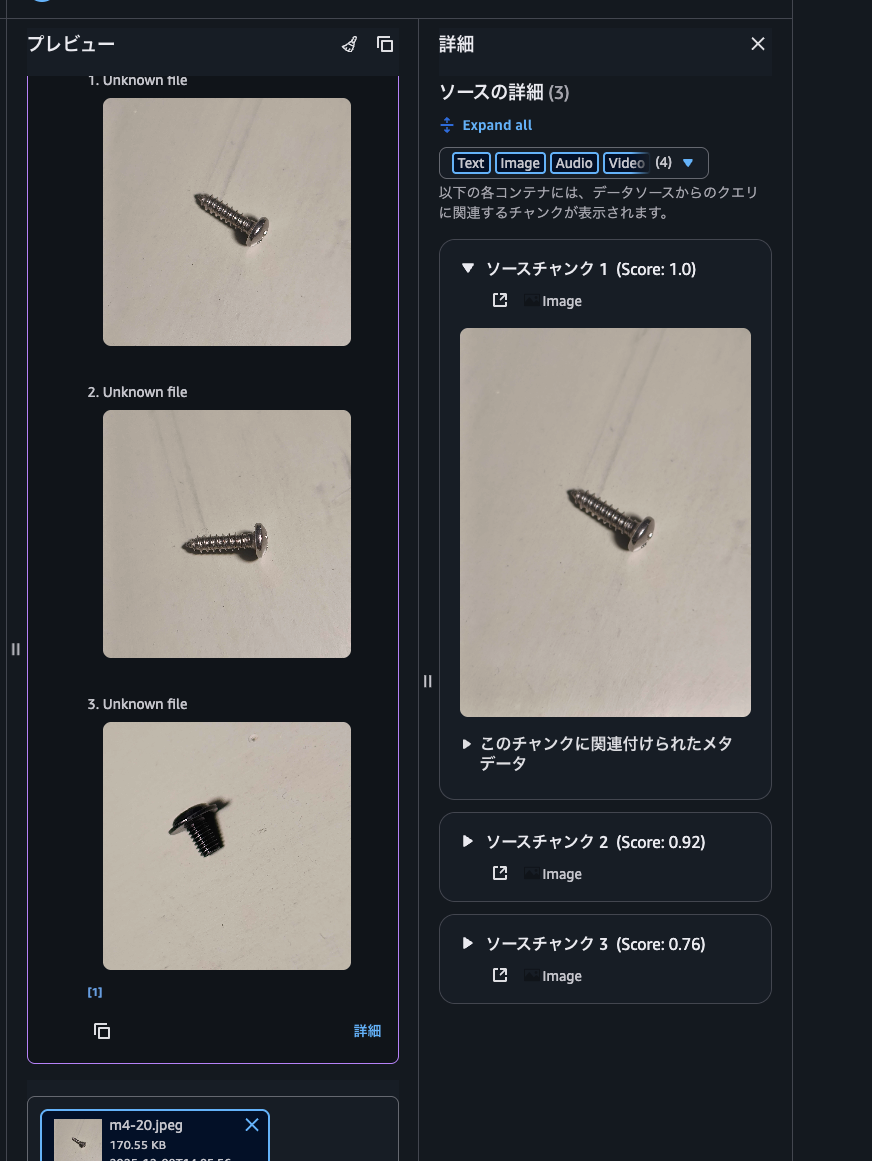
では、次にメタデータで絞り込んでみます。
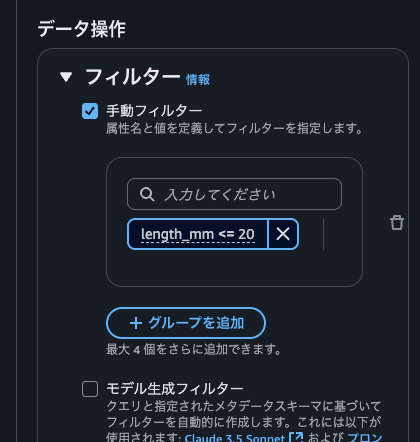
左側のフィルターから手動フィルターを有効にし、length_mm <= 20 を入力して指定します。その後、再度検索を実行します。
検索結果として、メタデータのlength_mmが20以下のものに制限して表示されました。
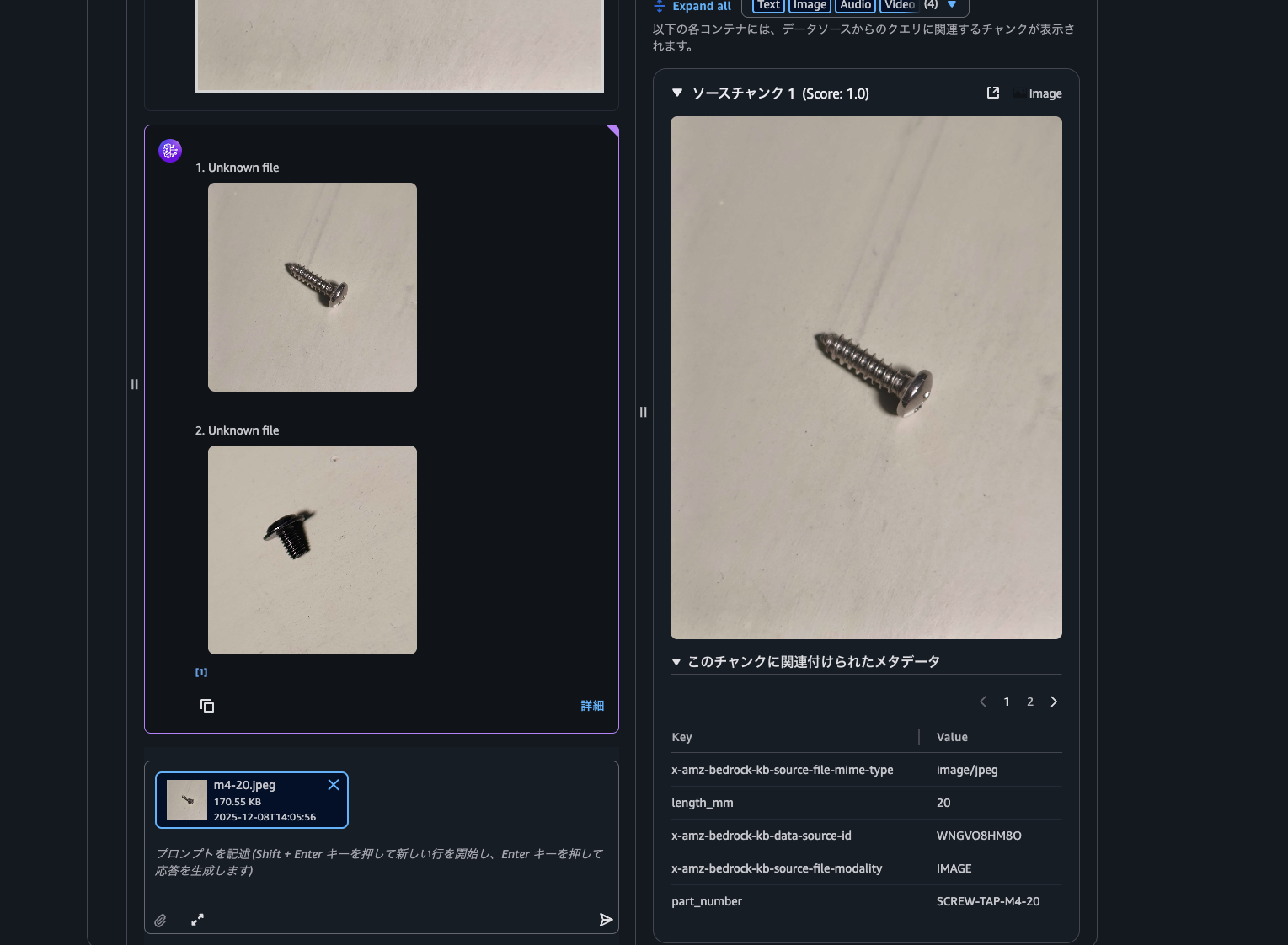
<=の演算子以外にも一致=や配列に含まれるかどうか:などの演算子も利用できるようです。詳細は以下のドキュメントを参照してください。
- Configure and customize queries and response generation - Amazon Bedrock
- Manual metadata filtering内に絞込に関する説明があります
さいごに
今回はBedrock Knowledge BasesとS3 Vectorsを使って、簡単に画像とメタデータからの部品検索を試すことができました。今回試した内容以外でも、Bedrock Knowledge Basesでは音声や動画などもベクトル化して検索したり、音声やPDF、動画、画像などをテキストに変換し、検索できます。製造業に限らずですが、さまざまなユースケースで活用できそうです。費用も安く始めることができるため、まずは小さな検証から色々試してみてください!
参考
- [アップデート] Amazon Bedrock Knowledge Bases のマルチモーダル検索が一般提供開始されました #AWSreInvent
- Build a knowledge base for multimodal content - Amazon Bedrock
- Amazon S3 Vectors now generally available with increased scale and performance | AWS News Blog
- Multimodal retrieval for Bedrock Knowledge Bases now generally available - AWS
- Knowledge Bases for Amazon Bedrock がメタデータフィルタリングをサポートし検索精度向上 | Amazon Web Services ブログ
- Troubleshooting multimodal knowledge bases - Amazon Bedrock









