
エンジニアのためのMCP勉強会#1『MCPを活用した検索システムの作り方』というテーマで登壇しました #catalks
最近注目を集めている MCP(Model Completion Protocol) について、AWSドキュメントの検索という親しみを持ちやすいサンプルが公開されていたので、AWSとドキュメント検索という個人的に親しみをもてるキーワードを切り口に、MCPで検索するのはどういうことなのか、触ってみる機会がありました。
その結果について、弊社イベントのClassmethod AI Talks #21 『エンジニアのためのMCP勉強会 #1』で『MCPを活用した検索システムの作り方』というテーマで発表しましたので、発表内容を簡単に共有します。
登壇資料
スライド
動画
AWS MCP Serversとは
AWS MCP Serversは、AWSのベストプラクティスをMCPサーバーとして提供するものです。2024年4月1日頃にGitHub上で公開され、同時に紹介ブログも公開されました。
このリポジトリには、2025/04/17 時点で以下の様々なサーバー実装が含まれていますが、今回は「AWS Documentation MCP Server」 を中心に解説します。
- Core MCP Server
- Amazon Bedrock Knowledge Base Retrieval MCP Server
- AWS CDK MCP Server
- Cost Analysis MCP Server
- Amazon Nova Canvas MCP Server
- AWS Documentation MCP Server ※ 今回の発表対象
- AWS Lambda MCP Server
- AWS Diagram MCP Server
- AWS Terraform MCP Server
インストール方法
MCPサーバーのセットアップ
MCPはクライアント・サーバー・アーキテクチャーで動作します。クライアントとサーバー間のトランスポートレイヤーには、以下の2方式があります
- プロセス間通信する「STDIO」
- ネットワーク越しに通信する「Server Sent Events(SSE)」
今回のMCPサーバーはSTDIO方式を利用するため、クライアント環境にサーバープログラムもセットアップする必要があります。サーバープログラムはPythonで実装されているため、 uv という環境構築プログラムをインストールし、その絶対パスを控えておきます。
$ curl -LsSf https://astral.sh/uv/install.sh | sh
$ which uvx
/Users/ユーザー名/.local/bin/uvx
クライアントの設定
MCPプロトコルのクライアントとして、今回は Claude Desktop を利用します。
Claude Desktopを起動後、Settings→Developer→Edit Configから、MCPサーバーの起動方法をJSONで記述します。
この際、command には、先ほど控えた uvx のパスを実環境に合わせて絶対パスで指定します。
{
"mcpServers": {
"awslabs.aws-documentation-mcp-server": {
"command": "/Users/ユーザー名/.local/bin/uvx",
"args": ["awslabs.aws-documentation-mcp-server@latest"],
"env": {
"FASTMCP_LOG_LEVEL": "ERROR"
},
"disabled": false,
"autoApprove": []
}
}
}
command と args から類推できるように、STDIO方式では、MCPクライアントがMCPサーバーをサブプロセスとして起動し、プロセス間通信を行います。
個人的には、この通信方式にびっくりしました。
実際の動作
Claude DesktopからAWSに関する質問を投げると、AIエージェントとして振る舞い、MCPを呼び出して最新のAWSドキュメントを元に回答を生成してくれます。

回答画面の青枠が MCPツール と呼ばれるもので、LLMがMCPの力を借りて処理したものです。
今回のケースでは、以下の2つのツールが呼び出されています:
search_documentationread_documentation
MCPツールの中身
MCPサーバーの実装を読み解くと、MCPツールが外部に対して以下の2種類のリクエストを投げていることがわかりました
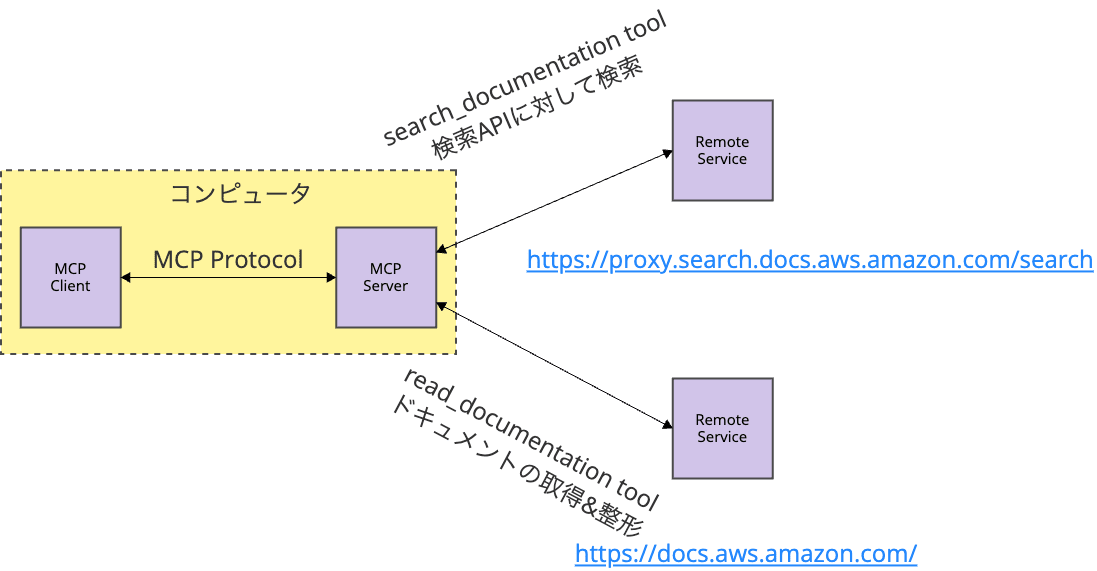
-
検索リクエスト:
search_documentationツールは、AWSが提供するドキュメント検索システムに問い合わせ、マッチしたドキュメントのURIなどを取得します。 -
コンテンツ取得リクエスト:
read_documentationツールは、URIを元に一般ユーザー向けのドキュメントサイトに実際にリクエストし、整形したテキストを取得します。
LLMはこの外部から取得したドキュメントを元に、質問の回答を生成しています。
MCPの General architecture 仕様で言うと、これはMCPサーバーからリモートサービスにWeb APIリクエストするアーキテクチャで実現されています。
search_documentation ツール(検索)の実態
search_documentation はAWSの管理する official なドキュメント検索システムに検索しているだけです。
MCPサーバーを経由しなくても、cURLなどから直接問い合わせることも可能です。
$ curl -X POST https://proxy.search.docs.aws.amazon.com/search \
-H "Content-Type: application/json" \
-d '{
"textQuery": {
"input": "S3 bucket naming rules"
},
"contextAttributes": [
{
"key": "domain",
"value": "docs.aws.amazon.com"
}
],
"acceptSuggestionBody": "RawText",
"locales": ["en_us"]
}'
{
"queryId": "40dd0cc1-4e0f-42af-9385-a1878fe3cbb5",
"suggestions": [
{
"textExcerptSuggestion": {
"link": "https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-tables-buckets-naming.html",
"title": "Amazon S3 table bucket, table, and namespace naming rules - Amazon Simple Storage Service",
"suggestionBody": "For general purpose bucket naming rules, see General purpose bucket naming rules. For directory bucket naming rules, see Directory bucket naming rules.",
"summary": "Use the table bucket naming rules to create table buckets and name tables and namespaces in Amazon S3 Tables.",
"context": [
{
"key": "aws-docs-search-product",
"value": "Amazon Simple Storage Service"
},
{
"key": "domain",
"value": "docs.aws.amazon.com"
},
{
"key": "document-type",
"value": "documentation"
},
{
"key": "publisher",
"value": "aws"
},
{
"key": "aws-docs-search-guide",
"value": "User Guide"
},
{
"key": "programming-language",
"value": "javascript"
}
],
"sourceUpdatedAt": 1741901134584,
"isCitable": true
}
},
{
"textExcerptSuggestion": {
"link": "https://docs.aws.amazon.com/AmazonS3/latest/userguide/directory-bucket-naming-rules.html",
"title": "Directory bucket naming rules - Amazon Simple Storage Service",
"suggestionBody": "When you create a directory bucket in Amazon S3, the following bucket naming rules apply. For general purpose bucket naming rules, see General purpose bucket naming rules.",
"summary": "Use the directory bucket naming rules when you create a directory bucket in Amazon S3.",
"context": [
{
"key": "domain",
"value": "docs.aws.amazon.com"
},
{
"key": "programming-language",
"value": "javascript"
},
{
"key": "document-type",
"value": "documentation"
},
{
"key": "publisher",
"value": "aws"
},
{
"key": "aws-docs-search-guide",
"value": "User Guide"
},
{
"key": "aws-docs-search-product",
"value": "Amazon Simple Storage Service"
}
],
"sourceUpdatedAt": 1743438752030,
"isCitable": true
}
},
...
],
"facets": {
"aws-docs-search-guide": [
"User Guide",
"API Reference",
"Developer Guide",
"Defining S3 bucket and path names for data lake layers on the AWS Cloud",
"Guide",
"Implementation Guide",
"Administration Guide",
"Amazon GuardDuty User Guide",
"Amazon QuickSight",
"Controls Reference Guide"
],
"aws-docs-search-product": [
"Amazon Simple Storage Service",
"AWS CloudFormation",
"AWS Prescriptive Guidance",
"AWS Config",
"AWS SDK For Ruby V3",
"AWS Cloud Development Kit (AWS CDK)",
"Amazon S3 on Outposts",
"AWS CLI",
"AWS SimSpace Weaver",
"Amazon Bedrock"
]
}
}
read_documentation ツール(コンテンツ取得)の実態
コンテンツ取得は、Pythonの一般的なスクレイピング手法が使われています。
httpxで公開ドキュメントからコンテンツを直接取得します。
@mcp.tool()
async def search_documentation(...) -> List[SearchResult]:
…
request_body = {
'textQuery': {
'input': search_phrase,
},
'contextAttributes': [{'key': 'domain', 'value': 'docs.aws.amazon.com'}],
'acceptSuggestionBody': 'RawText',
'locales': ['en_us'],
}
async with httpx.AsyncClient() as client:
try:
response = await client.post(
SEARCH_API_URL,
json=request_body,
headers={'Content-Type': 'application/json', 'User-Agent': DEFAULT_USER_AGENT},
timeout=30,
)
取得したHTMLファイルを beautifulsoup とmarkdownify で整形しています。
def extract_content_from_html(html: str) -> str:
…
try:
# First use BeautifulSoup to clean up the HTML
from bs4 import BeautifulSoup
# Parse HTML with BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
…
# Use markdownify on the cleaned HTML content
content = markdownify.markdownify(
str(main_content),
…
)
…
return content
AWSのドキュメント検索サーバーが公開されていることも驚きですが(ツールの説明によると "Search AWS documentation using the official AWS Documentation Search API." とあります)、一般公開されているドキュメントを素直にスクレイピングしている点も興味深いです。
このようなわかりやすいリファレンス実装のおかげで、MCP検索サーバーの仕組みを理解しやすくなっています。
他の検索MCPサーバーの実装
AWS MCP Server documentationの仕組みがわかったところで、他の検索系MCPサーバーの実装も気になったのでのぞいてみました。
Amazon Bedrock Knowledge Bases
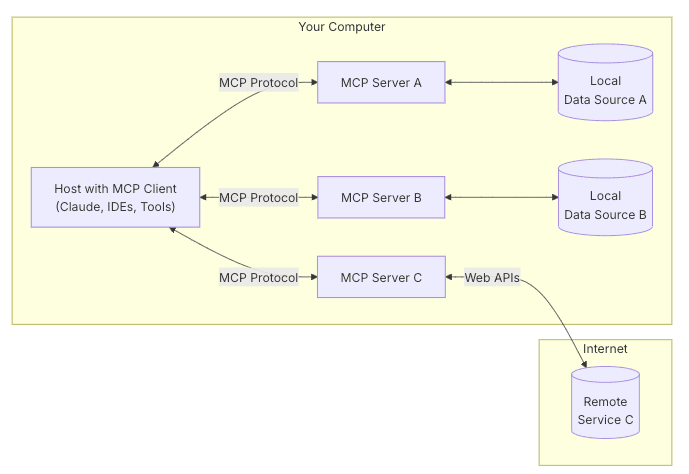
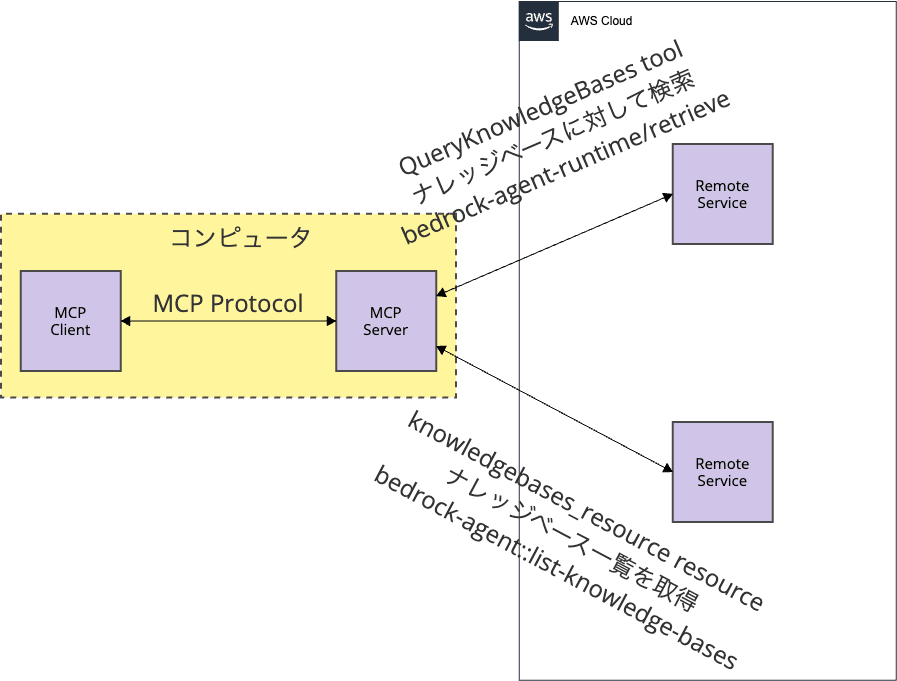
AWS Documentation MCP Serverと同じリポジトリに含まれる Amazon Bedrock Knowledge Base Retrieval MCP Server の場合、MCPリソースで、どのナレッジベースを参照するかという前処理が追加されていますが、MCPツールからAPIでナレッジベースに検索するという基本構造は同じです。
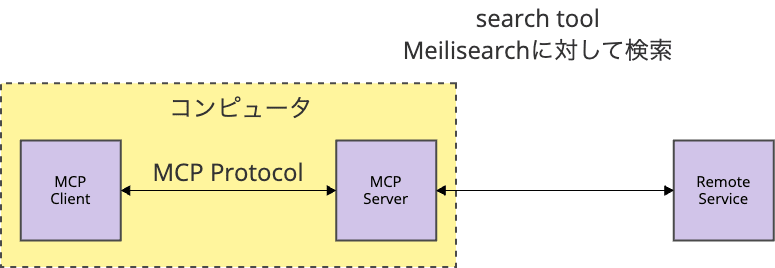
Meilisearch
OSS検索エンジンのMeilisearchのMCPサーバー を確認したところ、Meilisearchの検索サーバーを別途立て、MCPサーバーはそこに検索する仕組みになっていました。
MCPで検索システムを作るとは?
他の検索系MCPサーバーも同じような仕組みで実現されていました。
つまるところ、MCPを活用して検索システムを作るとは、リモートサービスとして検索システムを別途用意し、MCPツールでその検索システムに対して検索することと言えそうです。
MCPサーバーはライトウェイトなつなぎこみ
公開されている検索系MCPサーバーは、どこも検索エンジンを持っているところが、検索システムとつなぎこむ軽量なMCPサーバーを公開しているものばかりでした。
MCPの公式ドキュメントでも、MCPサーバーはライトウェイトなプログラムと明記されています。
MCP Servers: Lightweight programs that each expose specific capabilities through the standardized Model Context Protocol
MCPサーバーが重厚な実装になっていたら、何か間違えているかもしれません。
検索システムの重要性
逆に言えば、検索システムがない場合、MCP単体では検索は難しく、検索システムを構築するところから着手する必要があります。
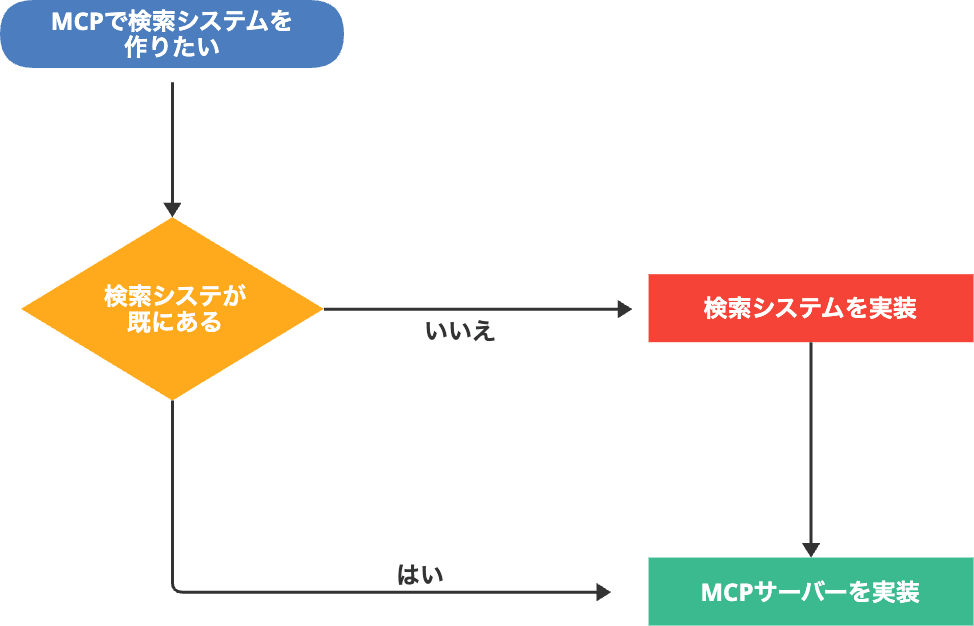
検索システムを作るには、以下のような多くの課題に取り組む必要があります:
- 検索エンジンの選択
- 全文検索かベクトル検索かの選択
- インデクシング方法の検討
- 検索対象ドキュメントの整備
- ドキュメントとインデックスの同期方法
- 検索性能の評価と改善
- などなど
検索システムにつなぎこむMCPサーバープログラムはライトウェイトですが、検索システムの開発や運用はヘビーウェイトです。
MCPはインターフェースでしかなく、LLMが生成する回答の質を改善するには、このヘビーウェイトな検索システムに向き合う必要があります。
検索システムに携わる人のためのおすすめ書籍
このヘビーウェイトな検索システムに携わることになった人向けに、おすすめの書籍を最後に2冊紹介します。
1. 「自然言語処理の教科書」
一冊目は、一橋大学の小町守先生による「自然言語処理の教科書」です。

MCP検索に限らず、社内の情報をAIで活用するといった広い意味の自然言語処理プロジェクトに携わることになった様々なロール向けに書かれています。特に、第1章の「自然言語処理システムのデザイン」と第5章の「言語資源の作り方」がおすすめです。
2. 「検索システム」
二冊目は、そのものズバリ「検索システム」です。

副題の通り、開発ロール向けの、実務者のための検索システム全般に対する具体的な開発改善ガイドブックです。
検索システムを俯瞰する上では、まずは第7章の「よい検索とは」と第8章の「検索システムプロジェクトの始め方」の2章に目を通すことをおすすめします。
まとめ
MCPを活用した検索システムを作るにはどうすればよいか、最後にまとめます
- リモートサービスとしてMCP外に検索システムを用意
- MCPツールで検索システムに検索
- 検索システムが無い場合、まずは検索システムを作る
- MCPサーバーはライトウェイト
- 検索システムはヘビーウェイト
- LLMの回答の質に直結する検索システムに向き合うこと
以上です。









