![[登壇資料] 「生成AIシステムのセキュリティ対策 〜 ベストプラクティスと実践 〜」というタイトルでClassmethod ODYSSEY Onlineに登壇しました #cm_odyssey](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1721558714/user-gen-eyecatch/adawdzoguzbiel6wcf4m.png)
[登壇資料] 「生成AIシステムのセキュリティ対策 〜 ベストプラクティスと実践 〜」というタイトルでClassmethod ODYSSEY Onlineに登壇しました #cm_odyssey
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
みなさん、こんにちは!
福岡オフィスの青柳です。
弊社クラスメソッドでは、創立20周年を記念したイベントとして「Classmethod ODYSSEY」を1ヶ月間にわたって開催しています。
7/8 (月) に開催された「Classmethod Odyssey ONLINE 生成AI編」において登壇させて頂きました。
私が担当したセッションでは、 「生成AIシステムのセキュリティ対策 〜 ベストプラクティスと実践 〜」 というタイトルでお話ししました。
生成AIの利用が拡大する中で、プライバシー、機密情報、内部データの保護がより一層重要となっています。本セッションでは、生成AIシステムにおけるセキュリティリスクと、それらに対する具体的な対策方法を解説します。AWSインフラで行う対策、アプリケーションやプロンプトでの対策など、実務で役立つベストプラクティスを詳しくご紹介します。
登壇資料
セッション内容の概要
大きく以下の2つの内容についてお話ししました。
- 生成AIシステムを構築/利用する際の、基本的なセキュリティ対策の考え方
- 暗号化
- ネットワーク
- ID管理/アクセス制御
- 生成AI観点からのセキュリティリスクと対策
生成AIシステムを構築/利用する際の、基本的なセキュリティ対策の考え方
生成AIを利用する際、次のようなセキュリティ面の懸念があります。
- 情報漏洩・盗聴
- ユーザーが入力したテキスト (質問内容に含まれている個人情報)
- 生成AIが出力したテキスト (回答内容に含まれている機密情報)
- RAGで使用する社内ドキュメント
- 不正アクセス
- 情報漏洩
- なりすまし
- 脆弱性を突いた攻撃
- サービス停止
- 不正利用
これらのセキュリティ懸念に対処するための代表的な対策手段として、今回のセッションでは以下を挙げて説明しました。
(これだけがセキュリティ対策の全てという訳ではありません)
- 「暗号化」によるセキュリティ対策
- 「ネットワーク観点」のセキュリティ対策
- 「ID管理」と「アクセス制御」によるセキュリティ対策
「暗号化」によるセキュリティ対策
暗号化を行う対象は、大きく以下の2つあります。
- データ転送中の暗号化
- データ保管時の暗号化
まず「データ転送中の暗号化」についてです。
典型的な「RAGを備えた生成AIチャットアプリ」として、以下のようなシステム構成を考えます。
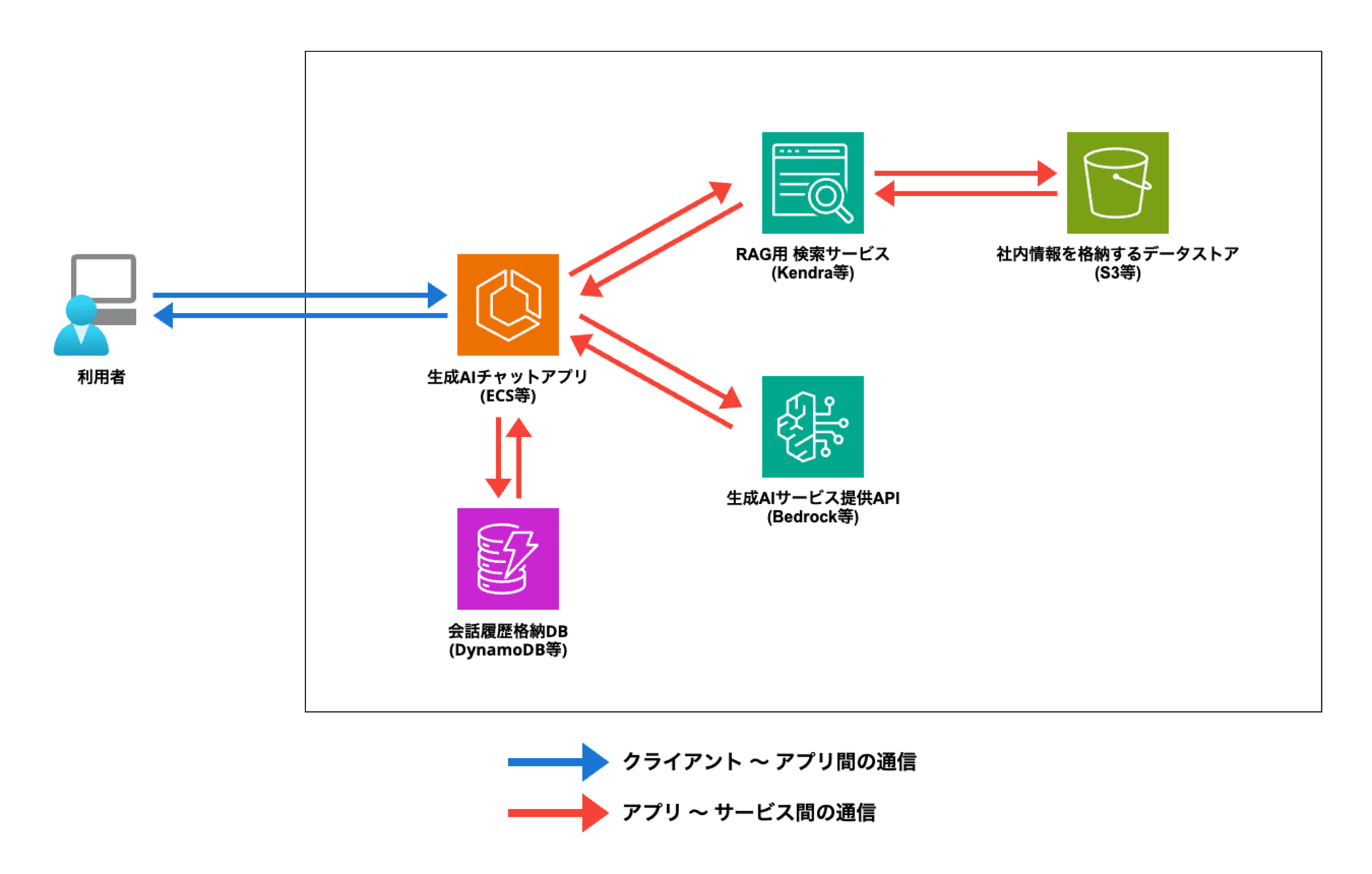
データ転送中の暗号化は、「クライアント 〜 アプリ間の通信」と「アプリ 〜 サービス間の通信」に大きく分けて考えることができます。
クライアント 〜 アプリ間の通信の暗号化は、Webアプリ/Webサービスであれば「HTTPS」で行うのが基本です。
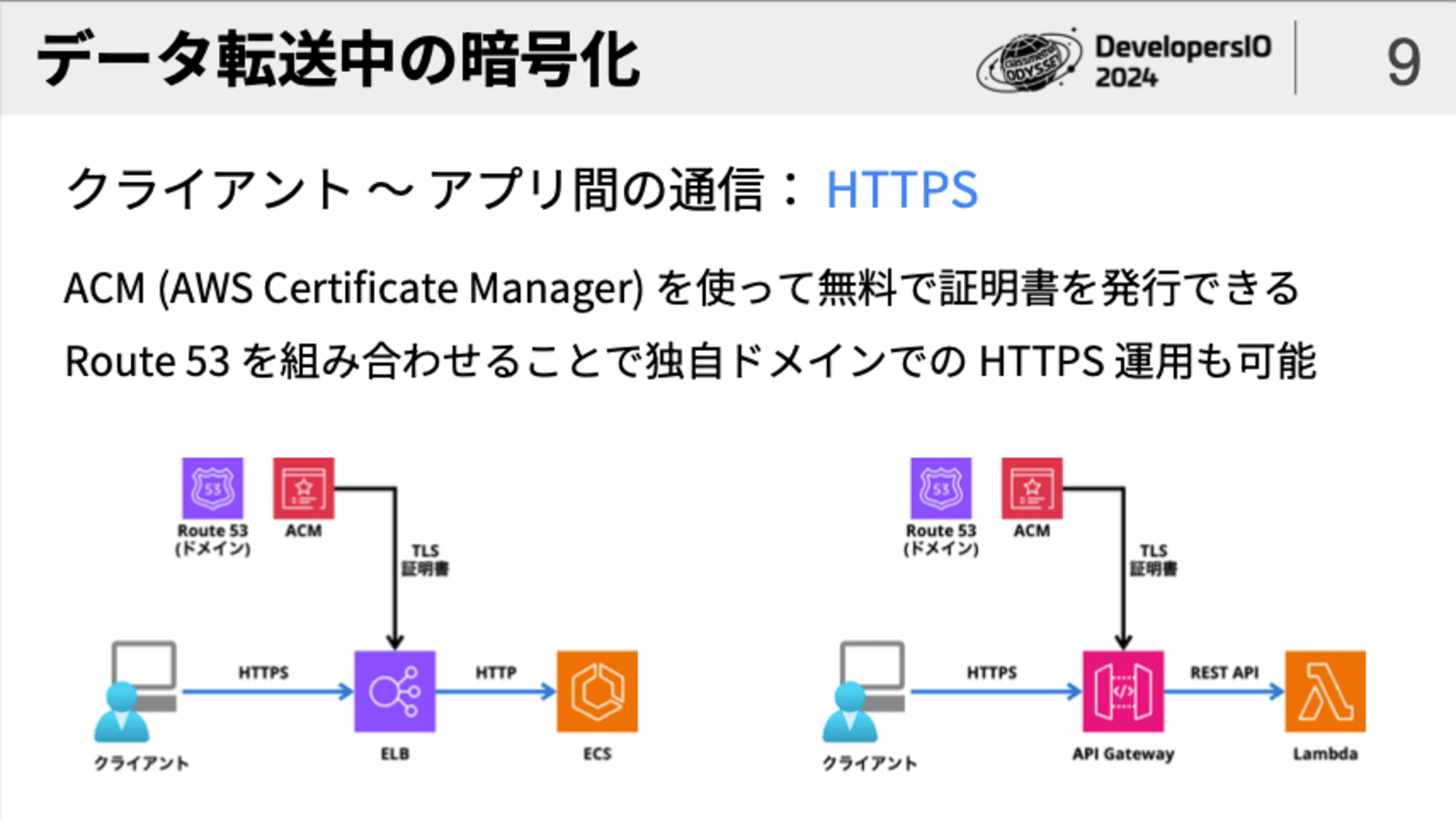
一方、アプリ 〜 サービス間の通信の暗号化は、TLSを適用します。
この時、「サービスによってTLSがデフォルトで使われるもの・オプションであるものがある」「使われるTLSのバージョンが古い場合がある」という点に気をつけます。

次に、「データ保管時の暗号化」についてです。
生成AIにおける「データ保管時の暗号化」のポイントは、「LLMはステートレスなAPIである」という点です。
ステートレスであるということは、データを保存しないということであるため、LLMはデータ保管時の暗号化について「対象外」ということになります。
では、生成AIアプリにおいてはデータ保管時の暗号化を一切考えなくてよいかというと、そんなことはありません。
下図のように「会話履歴を保存するDB」や「RAGのベクトルデータベース、データソース」といった箇所にはデータが保存されますので、暗号化の検討の対象となります。
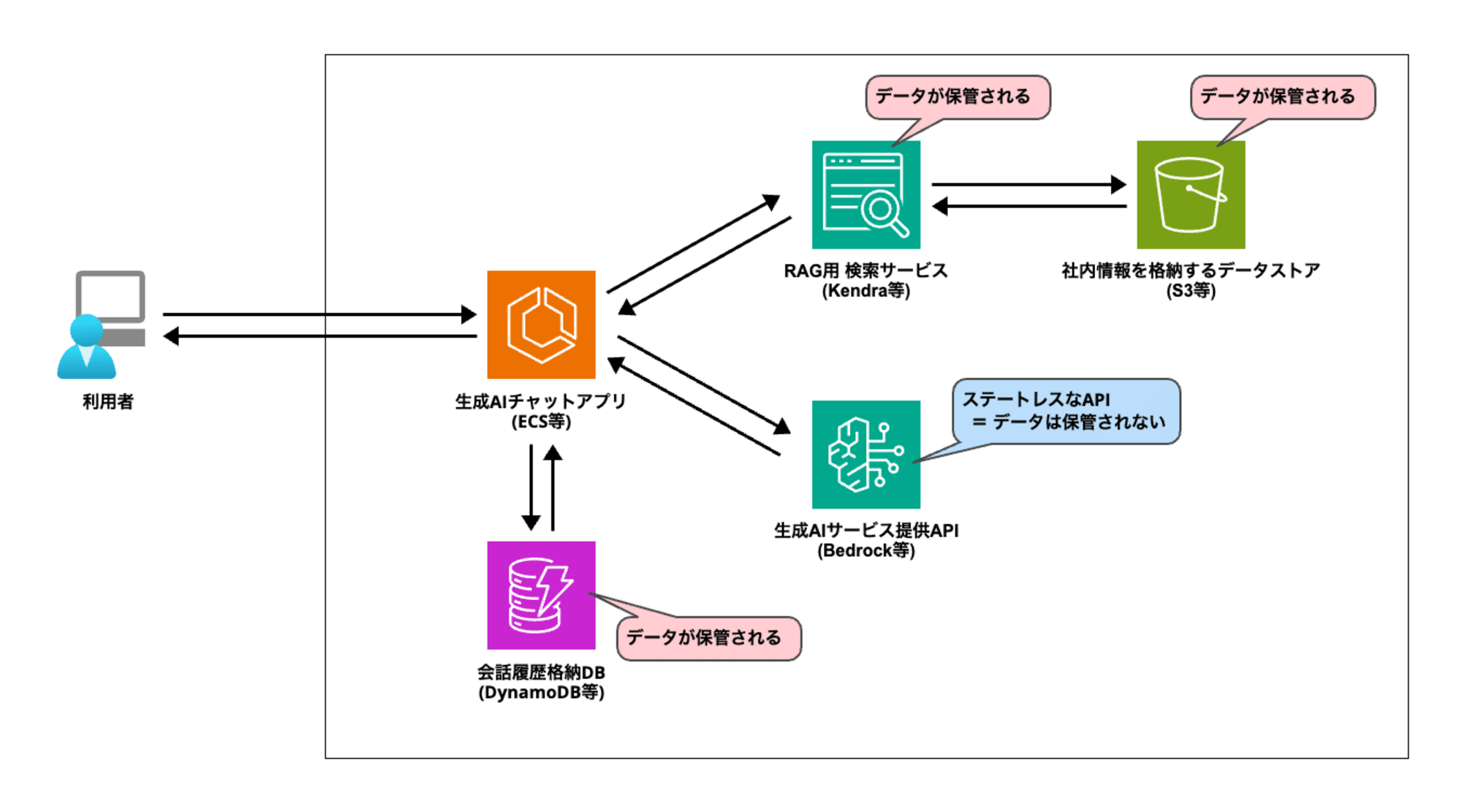
AWSの場合、データ保管時の暗号化には基本的に「KMS」が用いられます。
(S3の「SSE-S3」のようにKMSの名前が出ていなくても内部的にはKMSが使われることがあります)
KMSを用いて暗号化の設定を行う際、「キーの種類でどれを選べばよいか」という点で迷われる方も多いかもしれません。

勘違いされることも多いですが、KMSのキーの種類による暗号化強度の違いはありません。
キーの種類を選ぶポイントとしては、「キーの保存場所・管理責任はどこか」「キーの高度な管理を行う必要があるか」という点になります。
これらは、企業のセキュリティポリシーやコンプライアンスの観点から決定することになるかと思います。
キーを顧客自身が所有して高度な管理を行えるオプションを選択した場合、KMSの利用費は高くなり、また、運用管理に要するコストも大きくなることについて留意する必要があります。
「ネットワーク観点」のセキュリティ対策
ネットワーク観点のセキュリティ対策を考えるにあたり、まず、AWSにおける「ネットワーク領域の分類」を知っておく必要があります。
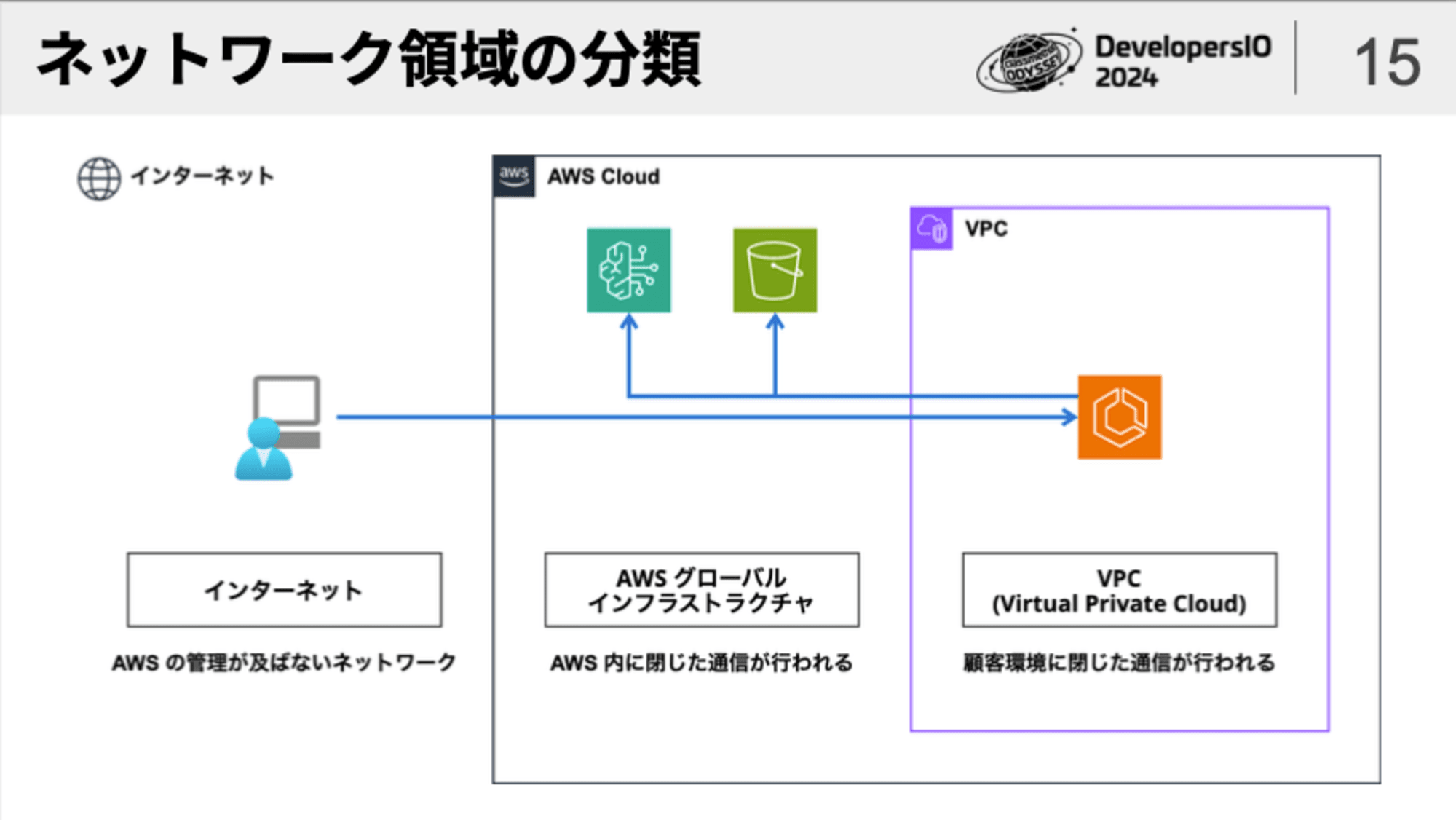
EC2やECSなどのAWSサービスは、AWSアカウント内に作成した顧客専用ネットワーク環境である「VPC」の内部で通信が行われます。
この点については、皆さん良く理解されているのではないかと思います。
では、S3やDynamoDB、あるいはBedrockなど、いわゆる「マネージドサービス」と呼ばれるAWSサービスは、どこで通信が行われるのでしょう?
よく言われるのは「VPCに所属していないマネージドサービスは、インターネット経由で通信が行われる」ということです。
かなり昔においてはこの認識は間違っていなかったのですが、現在のAWSではこの認識は間違っています。
AWSのマネージドサービスは「AWSグローバルインフラストラクチャ」というAWS内に閉じたネットワーク環境の内部で通信が行われます。
サービス間の通信はプライベートIPではなくグローバルIPが使われますので、そのことで「インターネットを経由している」と誤解される場合があるのかもしれません。
「AWSグローバルインフラストラクチャ」のネットワーク通信に関しては、佐々木拓郎氏のブログ記事が分かりやすいので参考にしてください。
このことを押さえた上で、よく議論される「ネットワーク閉域化」の必要性について考えてみましょう。
標準的なネットワーク構成でも、以下のようにセキュリティは担保されています。
- クライアント 〜 アプリ間の通信:
- インターネットを経由しますが、HTTPSで暗号化されています
- アプリ 〜 サービス間の通信:
- AWS内に閉じた通信 (AWSグローバルインフラストラクチャまたはVPC) であり、かつ、TLSによる暗号化も行われます
その上で、閉域化を検討すべき場面としては、以下のようなものが挙げられます。
- 企業やシステムにおけるセキュリティポリシーで『閉域化が必須』と定められている
- コスト (利用費や運用コスト) が増加したとしても、標準的な構成よりも強固なセキュリティが必要
そのような場面では、下図のように「VPNまたはDirect Connect」および「VPC Endpoint」を用いて、ネットワークの完全な閉域化を行うことが可能です。
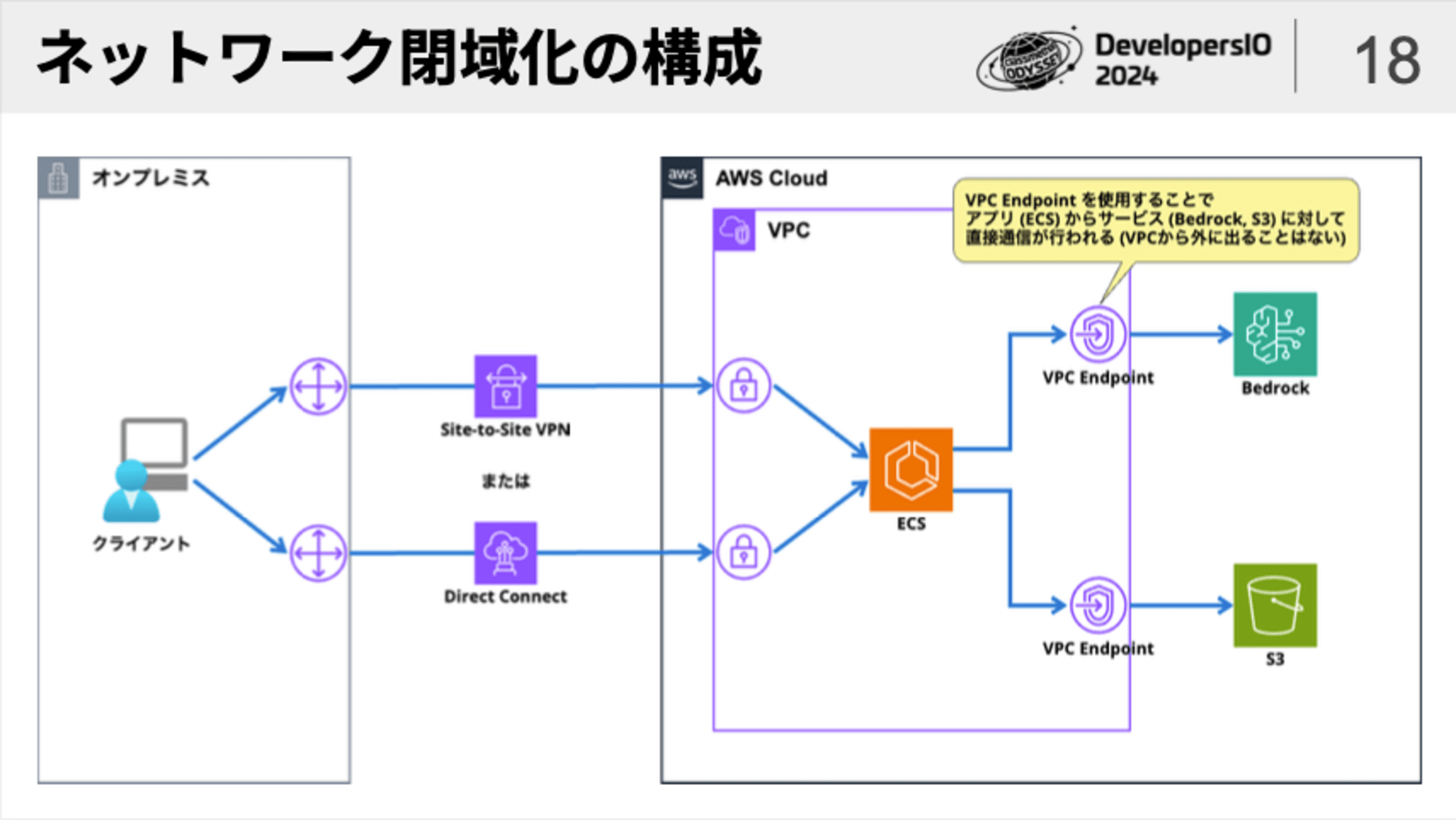
「ID管理」と「アクセス制御」によるセキュリティ対策
ID管理/アクセス制御によるセキュリティ対策は、「クライアント 〜 アプリ間」と「アプリ 〜 サービス間」に分けて考える必要があります。
「クライアント 〜 アプリ間」のアクセス制御は、自前でユーザー認証の仕組みを実装することもできますが、運用面やセキュリティ面を考えると既存の認証基盤を利用するのが現実的です。
- 社内ユーザーの認証:
- SAMLベースの認証基盤を使う (Avtive Directory (ADFS)、Entra ID、Google Workspace、など)
- 社外ユーザーの認証:
- OpenID Connectベースの認証基盤を使う (Apple、Facebook、X、GitHub、など)
これらの認証基盤と連係してユーザー認証とアクセス認可を行う仕組みをアプリケーションに実装する際は、「IAM Identity Center」や「Cognito」あるいはサードパーティ製ツールを利用することが多いです。
一方、「アプリ 〜 サービス間」のアクセス制御は、「IAM」を使うことが基本です。
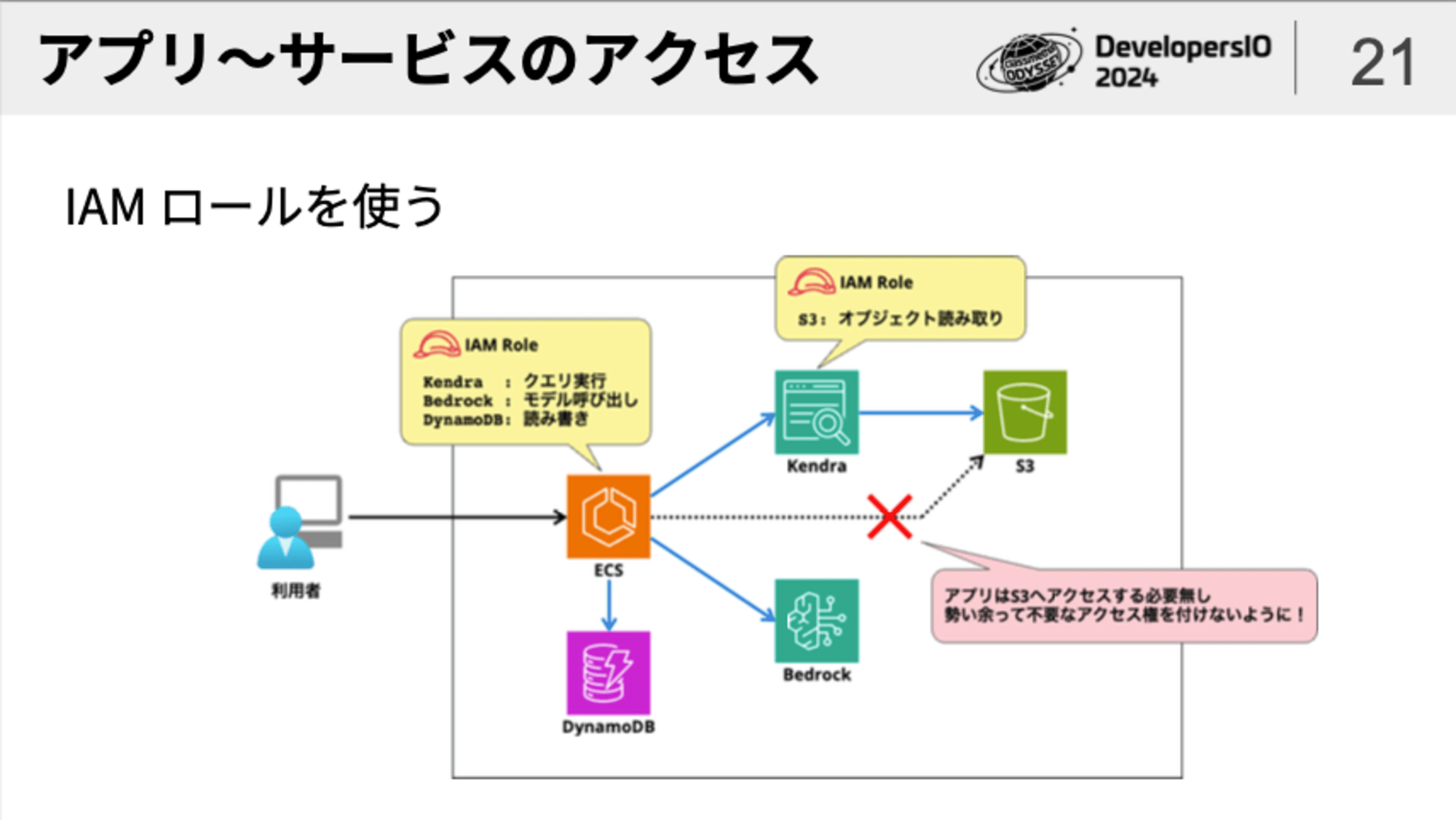
普段からAWSを使いこなしている方であれば、EC2やECSにおいて「IAMユーザーのアクセスキー」を使ってアクセス権限を得るのはバッドプラクティスであり、「IAMロール」を使うのがベストプラクティスであるということをご存知かと思います。
また、上図では「Kendra」から「S3」へアクセスする必要がありますが、この時にKendraに対してアクセス権限を設定する際にも「IAMロール」が使われます。(このような使われ方をする時には「サービスロール」とも呼ばれます)
IAMを使ってアクセス制御を行う際に重要なポイントは「最小権限の原則」に従うという点です。
「後からアクセス要件が発生するかもしれないから」「なんか面倒臭いから」という理由で、必要のないアクセス権限を付与することは避けましょう。
また、アクセス権限の種類だけでなく、アクセス対象についても、可能な限り必要な範囲に限定すべきです。
生成AI観点からのセキュリティリスクと対策
ここまでは、どちらかと言うと生成AIに特化しない全般的なセキュリティ対策の話をしました。
ここからは、生成AIに特化したセキュリティ対策の話になります。
セキュリティに関する様々な情報を発信する非営利組織である「OWASP」より、生成AIアプリケーションを作成・利用する際のセキュリティリスクと対策について整理した 「OWASP Top 10 for Large Language Model Applications」 が公開されています。
日本のOWASP組織によって日本語に翻訳されたものはこちらです:
以下の10項目が挙げられています。
- 01: Prompt Injection (プロンプトインジェクション)
- 02: Insecure Output Handling (安全が確認されていない出力ハンドリング)
- 03: Training Data Poisoning (訓練データの汚染)
- 04: Model Denial of Service (モデルのDoS)
- 05: Supply Chain Vulnerabilities (サプライチェーンの脆弱性)
- 06: Sensitive Information Disclosure (機微情報の漏えい)
- 07: Insecure Plugin Design (安全が確認されていないプラグイン設計)
- 08: Excessive Agency (過剰な代理行為)
- 09: Overreliance (過度の信頼)
- 10: Model Theft (モデルの盗難)
今回のセッションでは、これらの中からいくつかの項目をピックアップして解説をしました。
プロンプトインジェクション
「プロンプトインジェクション」とは、悪意を持った者がLLMを意図的に誤動作させる指示を与えて、好ましくない内容を生成AIに出力させる攻撃のことを指します。
- 犯罪行為に使うことができる情報を回答させる (「爆弾の作り方を教えろ」)
- 個人情報や機密情報を聞き出そうとする
各社のLLMでプロンプトインジェクションへの対策は行われているものの、それでも、特定の指示の与え方をすることで対処策をすり抜けて攻撃が行われることはあり得ます。
プロンプトインジェクションを用いた攻撃手法には、以下のようなパターンがあります。
- 攻撃者がLLMに対して直接プロンプトインジェクションを試みる
- 攻撃者が他者を使って間接的にプロンプトインジェクションを発動させる
後者は、どうやって間接的な攻撃を行うのでしょう?
例えば、攻撃者が「一見普通の内容に見えるが実はプロンプトインジェクションを仕込んだ内容」を含むファイルやWebページをターゲットユーザーの目につく場所にわざと設置しておきます。
ユーザーがこのファイルやWebサイトの内容を「要約」したり「翻訳」したいと考えて生成AIチャットにコピペして指示を与えると、プロンプトインジェクションが発動して攻撃が成立してしまう訳です。
プロンプトインジェクションへの対策としては、次のような方法があります。
- システムプロンプトに「個人情報を出力しない」「有害な情報を出力しない」などの指示を与えておく
- システムプロンプトを無視するようなプロンプトインジェクション攻撃も存在するため、効果が無い場合がある点に注意
- LLMへの入力、LLMからの出力をチェックする仕組みを講じる
- サードパーティ製ツールを使ったり、「Guardrails for Amazon Bedrock」を使います
- 古いバージョン/古いリリースのLLMだと対策が行われていない場合があるため、できるだけ新しいバージョン/新しいリリースのLLMを利用する
生成AIの出力の精査が不十分なことによるリスク
LLMの出力を精査せずに利用したために引き起こされる問題として、以下のようなものがあります。
- LLMが出力したサンプルコードをシェルで実行した結果、ファイルの誤削除など重篤な問題が発生してしまう
- LLMが出力したHTMLやJavaScriptをブラウザが解釈した結果、クロスサイトスクリプティング (XSS) が引き起こされてしまう
このような問題への対策としては、次のような方法があります。
- LLMが出力したコードは、必ず人の手でチェックやレビューを行う
- LLMの出力に対して検証やサニタイズを行う
- LLMの出力をそのまま表示せず、エンコードあるいはエスケープを行う
プロンプトで「出力結果に対して検証やエンコードを行ってください」と指示を与えることもできますが、LLMは完全ではないために抜け漏れが発生する場合もあります。
これらの処理は、LLMの出力結果に対して後処理で行うのが確実だと思います。
プラグイン・エージェントを利用する際のリスク
生成AIにおける最近のトレンドの一つとして、LLMを単体で使うのではなく「プラグイン」や「エージェント」を組み合わせて高度な利用を行うということがあります。
- 「プラグイン」
- 生成AIに「コマンドの実行」「APIの呼び出し」「アプリとの連係」などの機能を与えることによって、生成AIの出力結果を人間が解釈して作業を行う代わりに、生成AIが行えるようにするもの
- 「エージェント」
- 与えられた指示を遂行するために必要なタスクを生成AIが自ら考え、必要に応じてAPIの呼び出しやアプリとの連係を行うことで自律的に作業を行えるようにするもの
いずれも、生成AIに対して「単に文章や画像を生成してもらう」以上の権限を与えることになります。
このような「プラグイン」や「エージェント」の利用においては、以下のようなリスクが考えられます。
- 意図しない不正なパラメーターを受け付けてしまう
- 悪意のあるコードの実行
- SQLインジェクション
- 攻撃者が用意したコンテンツの注入やWebサイトへの誘導
- 意図しない操作の実行や、意図しないデータのアクセスが行われてしまう
- 社内の重要なファイルやデータの削除
- 個人情報や機密情報へアクセス
- システムファイルの削除や改竄
対策としては以下のようなものが挙げられます。
- パラメーターの検証やサニタイズを行う
- パラメーターのエスケープあるいはエンコードを行う
攻撃者は、プラグインやエージェントが呼び出すAPIのパラメーターチェックの不備を突いて攻撃を仕掛けてきます。
そのための対策方法は、一般的なWebアプリやプログラムと同様の考え方で行うことができます。
また、以下のような対策も有効です。
- プラグインやエージェントに対して、必要最小限のアクセス権限とアクセス範囲を与える
- 例: データの参照のみが必要なエージェントに対しては、書き込み権限を与えない
- 例: 処理のために必要なデータ (DBやフォルダ) のみアクセス許可を与える
- 人間によるチェックや承認を行う
- 間違えることが許されない、あるいは、重要な処理を行うタイミングで「チェック」「承認」を行う
- 生成AIが提案する処理内容を提示して、人間が最終判断を行う
生成AIを過信して、不必要に強い権限を与えたり、提示してきた内容を無条件で受け入れることは、リスクに繋がります。
もちろん、過剰に生成AIを警戒してガチガチに縛ってしまうと、生成AIを活用する意義が無くなってしまいます。
効果的なポイントとタイミングで対策を行うことが求められます。
Guardrails for Amazon Bedrock
LLMの入力/出力 をチェックする手段として挙げた「Guardrails for Amazon Bedrock」は、サードパーティ製ツールに比べて、Bedrockサービスと統合されておりシームレスなセキュリティ対策が行えることが利点です。
現時点 (2024年7月) では日本語をサポートしていないため本番運用に適用することは難しいですが、いずれ日本語をサポートするようになれば強力なセキュリティ対策手段の一つになるでしょう。
Guardrails for Amazon Bedrockの詳細については、以下のブログを参照してください。
おわりに
生成AIシステムを構築/利用する際のセキュリティ対策について、以下の2つの観点から解説してきました。
- 生成AIに依存しない基本的な考え方
- 生成AIならではの観点からの考え方
前者は、一般的なWebアプリやクラウド利用におけるセキュリティ対策の考え方がベースとなっており、セキュリティの基本をしっかりと押さえておくことが大事です。
後者については、生成AIならではのセキュリティリスクや攻撃手法について理解した上で、必要な対策を行うことが必要になってきます。
とは言え、考え方はこれまでのシステム構築・アプリケーション開発におけるセキュリティ対策に通じるところも多々あるのではないかと思います。
セキュリティ対策をしっかり行いつつ、生成AIによる便利さ・可能性を安全に享受できるよう、活用して頂ければと思います。









