
Claude Code の /batch コマンドで同じ作業を6並列で回してみた
こんにちは!製造ビジネステクノロジー部の石井です。
Claude Code に /batch というコマンドがあるのをご存知でしょうか。
2026年2月28日の v2.1.63 でGAになった機能で、同じような作業を複数のワーカーに分解して並列実行してくれます。
実案件でも使ってみたんですが(その話は後半で)、今回はデモ用のプロジェクトを使ってシンプルに紹介してみます。
/batch コマンドとは
Claude Code の /batch は、1つのプロンプトを複数のワーカーに分解して並列実行してくれるコマンドです。
ざっくりした流れはこんな感じです。
/batchを実行すると、まず Plan モードに入ってコードベースを調査し、作業を独立したユニットに分解する- 分解計画がユーザーに提示されるので、内容を確認して 承認する
- 承認後、各ユニットごとにワーカー(子プロセス)が git worktree で独立した作業ディレクトリを作成し、並列で作業を進める
- メインプロセスは各ワーカーの進捗をトラッキングして、すべて終わったら完了状態になる
ポイントは git worktree を使っている点です。各ワーカーがそれぞれ独立した作業ディレクトリで動くので、並列で実行しても作業内容が互いに干渉することがありません。また、いきなり実行されるのではなく、計画を確認してから承認するステップがあるので安心感があります。
あるワーカーがファイルを編集している最中に、別のワーカーの変更に巻き込まれる...みたいな事故は起きません。
たとえば「6つのドメインそれぞれにテストを書いてPR作成して」と指示すると、6つのワーカーが同時に起動して、それぞれ独立したブランチ&PRとして成果物を生成してくれます。
直列で1個ずつやるより圧倒的に速いですね。
向いているのは「同じパターンの作業を、対象を変えて繰り返す」タイプのタスクです。
テスト生成、同じパターンのリファクタ、共通関数を作った後の各ファイルへの適用、多言語対応、ドキュメント作成など、対象が独立していて同じ手順で進められるものが特に相性がいいです。
デモ用プロジェクトの紹介
今回のデモで使うのは、Hono + TypeScript で作ったタスク管理APIです。
技術スタックはこんな感じ。
- ランタイム: Node.js
- フレームワーク: Hono
- 言語: TypeScript
- DB: PostgreSQL(Docker Compose で起動)
- テスト: Vitest
- パッケージマネージャ: pnpm
フォルダ構成
batch-test-gen-demo/
├── src/
│ ├── index.ts # エントリポイント(serve)
│ ├── app.ts # Honoアプリ定義
│ ├── db/
│ │ ├── client.ts # DB接続
│ │ └── schema.ts # スキーマ定義
│ ├── store/ # データアクセスロジック
│ │ ├── taskStore.ts
│ │ ├── projectStore.ts
│ │ ├── milestoneStore.ts
│ │ ├── userStore.ts
│ │ ├── tagStore.ts
│ │ └── commentStore.ts
│ ├── routes/
│ │ ├── tasks.ts
│ │ ├── projects.ts
│ │ ├── milestones.ts
│ │ ├── users.ts
│ │ ├── tags.ts
│ │ ├── comments.ts
│ │ └── stats.ts
│ ├── handlers/ # ← ドメインごとにサブディレクトリ
│ │ ├── tasks/ # 10ファイル
│ │ ├── projects/ # 6ファイル
│ │ ├── milestones/ # 5ファイル
│ │ ├── users/ # 6ファイル
│ │ ├── tags/ # 3ファイル
│ │ └── comments/ # 3ファイル
│ └── types/
│ ├── task.ts
│ ├── project.ts
│ ├── milestone.ts
│ ├── user.ts
│ ├── tag.ts
│ └── comment.ts
├── web/
│ ├── index.html
│ └── src/
│ ├── main.tsx
│ └── App.tsx # タスク管理画面
├── test/ # ← ここが空の状態からスタート
├── docker-compose.yml # PostgreSQL
├── package.json
├── tsconfig.json
└── vitest.config.ts
ドメイン構成
6つのドメインに分かれていて、合計33個のハンドラーがあります。
| ドメイン | ハンドラー数 | 内容 |
|---|---|---|
| tasks | 10 | CRUD + 統計 + 検索 + タグ操作 |
| projects | 6 | CRUD + プロジェクト内タスク取得 |
| milestones | 5 | CRUD(プロジェクトにネスト) |
| users | 6 | CRUD + ユーザーのタスク取得 |
| tags | 3 | 作成/一覧/削除 |
| comments | 3 | 作成/一覧/削除(タスクにネスト) |
データは PostgreSQL で管理していて、docker compose up -d で立ち上がります。
なお、事前に /init で CLAUDE.md を生成済みの状態からスタートしています。
/batch でテストを一括生成(基本編)
まずはシンプルに、テスト生成だけを /batch でやってみます。test/ ディレクトリが空の状態からスタートです。
実行前の状態
test/ ディレクトリには .gitkeep しかない、まっさらな状態です。
/batch に渡したプロンプト
/batch src/handlers/ 配下の6ドメイン(tasks, projects, milestones, users, tags, comments)
それぞれに対応するテストコードを test/handlers/<ドメイン名>/ 配下に生成してください。
テストは Vitest + Hono の app.request() を使い、
正常系・異常系の両方をカバーしてください。
各テストの前にDBのデータをリセットしてください。
各ドメインごとに独立したブランチとPRを作成してください。
今回はわかりやすいように「6ドメインそれぞれに対して」と分割単位まで明示していますが、ここまで指定しなくても /batch は Plan モードでコードベースを調査して適切な分割単位を自分で判断してくれます。
「テスト書いて」くらいのざっくりした指示でも、ドメイン構成を見て分解計画を立ててくれるので、まずは試してみて計画の粒度が合わなければプロンプトで調整する、くらいの感覚でOKです。
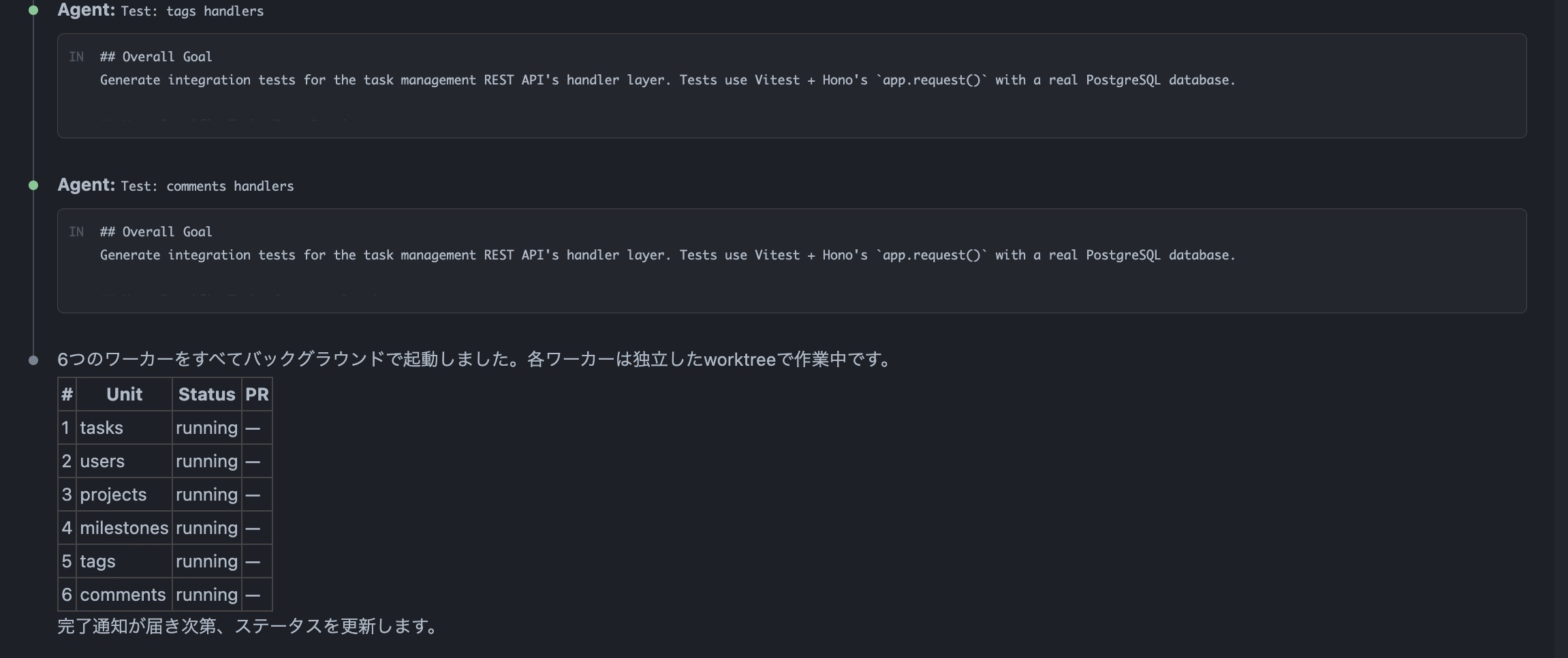
これを実行すると、Claude Code がプロンプトを分析して6つのワーカーに分解してくれます。
生成対象
test/handlers/tasks/— 10ファイル分のテストtest/handlers/projects/— 6ファイル分のテストtest/handlers/milestones/— 5ファイル分のテストtest/handlers/users/— 6ファイル分のテストtest/handlers/tags/— 3ファイル分のテストtest/handlers/comments/— 3ファイル分のテスト
6つのワーカーがドメインごとに並列で起動して、それぞれが独立したPRとしてテストコードを生成してくれます。
完了したものからステータスが更新されていきます。
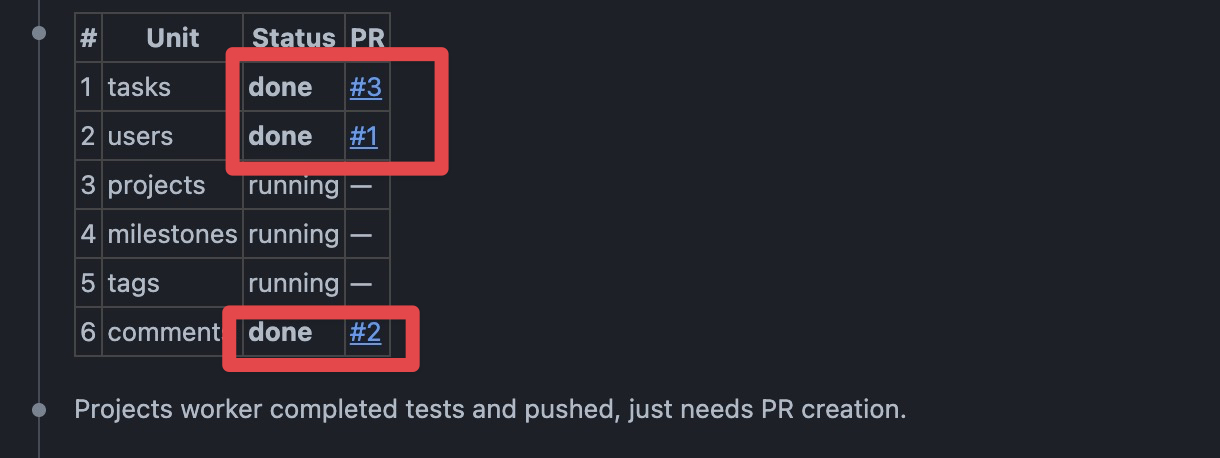
すべて完了するとこんな感じになります。
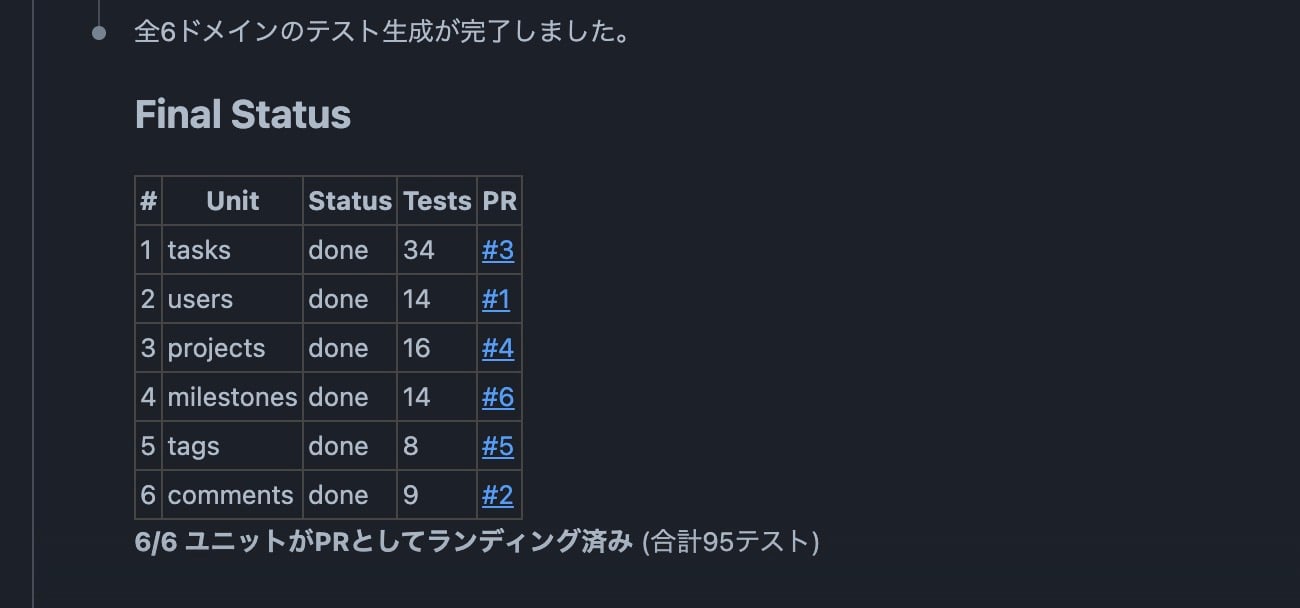
結果
各ハンドラーの正常系・異常系がしっかりカバーされたテストが生成されました。
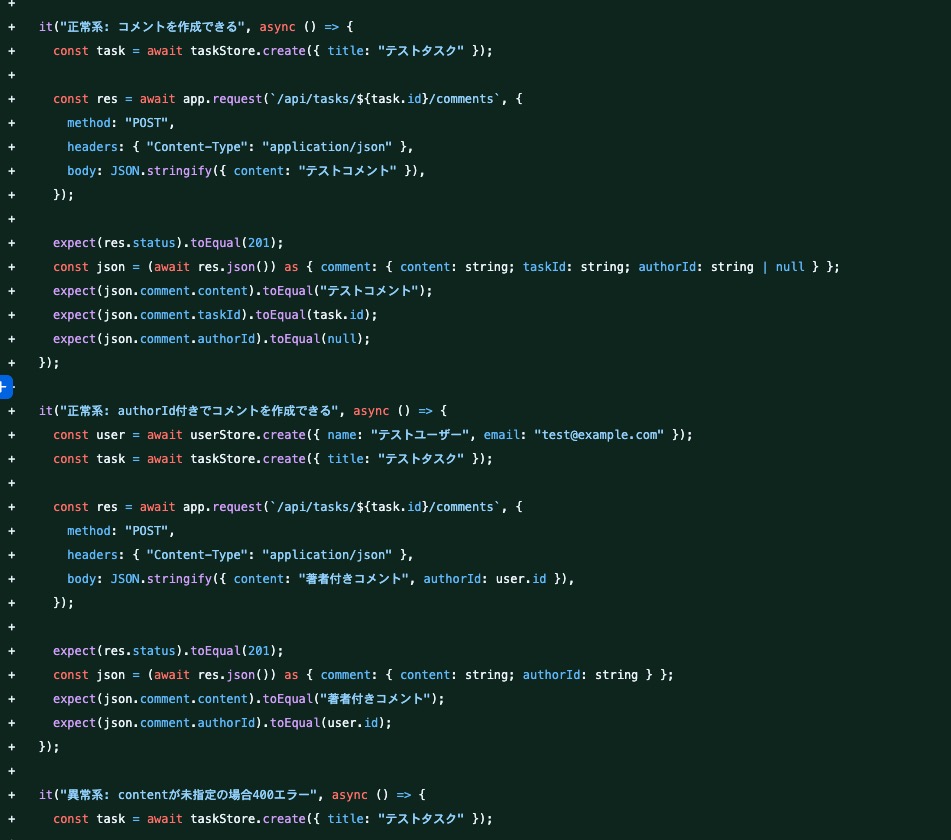
生成されたテストを一部覗いてみるとそれっぽいテストをちゃんと実装してくれてました。
トラブルシューティング:Bash 権限エラーで停止する
/batch を実行したとき、ワーカーが途中で止まって Permission to use Bash has been denied というエラーが出ることがあります。
これはサブエージェントが親セッションの Bash 権限設定を継承しないという既知の問題です(Issue #18950)。/batch に限らず、skills や Plan エージェントなど Task ツール経由のサブエージェント全般で発生します。親セッションで Bash(*) を allow していても、各ワーカーはその設定を読み込まないため、Bash コマンドを実行しようとしたタイミングで止まってしまいます。2026年3月時点で Issue はオープン状態・未修正です。
回避策は2段階で試すといいです。
まず:settings.local.json に allow を書く
.claude/settings.local.json は git に含まれない個人用の設定ファイルです。ここに Bash(*) を書いておくと、チームの設定には影響せず自分の環境だけで有効になります。
これで解消する場合があります。
{
"permissions": {
"allow": [
"Bash(*)"
]
}
}
ワーカーが何のコマンドを実行するか事前に把握しきれないので、コマンドを個別に列挙するより Bash(*) で一括許可して settings.local.json でスコープを個人に留めるのが現実的です。deny で危険な操作だけ明示的に塞いでおくと、より安心して使えます。
{
"permissions": {
"allow": ["Bash(*)"],
"deny": [
"Bash(git config *)",
"Bash(git push --force *)",
"Bash(chmod *)",
"Bash(rm -rf /*)",
"Bash(gh repo delete *)",
"Bash(pnpm add -g *)"
]
}
}
使っているツールやプロジェクトの構成に合わせて調整してください。
deny は allow より優先評価されるので、Bash(*) で全開放していても deny にマッチするコマンドは必ずブロックされます(公式ドキュメント)。
それでも止まる場合:権限確認ステップ自体をスキップする
これが最も確実な回避策です。
CLI で使っている場合は、--dangerously-skip-permissions フラグをつけて起動します。
claude --dangerously-skip-permissions
VSCode 等のエディタ拡張経由で使っている場合は、VS Code の settings.json に以下を追加します。
{
"claudeCode.allowDangerouslySkipPermissions": true
}
このオプションは権限確認を完全にスキップするので、作業内容が明確に定義されているときだけ使うのが原則です。
テスト生成やドキュメント作成のように「何をするか読める」タスクなら比較的安全ですが、トラブルシューティングのように作業範囲が曖昧なケースでは Claude が何をするか予測しづらいため、使用は推奨しません。使う場合は Docker などのサンドボックス環境が安全です。
ローカルで直接使う場合は以下の点に注意してください。
- 本番環境や機密情報を含むリポジトリでの使用は避ける
- フィーチャーブランチで作業する・実行前に
git stashで退避する
スキルファイルを使った応用編
基本編では「テスト生成だけ」でしたが、応用編では /batch にもう少し複雑なワークフローをやらせてみます。
具体的には「ブランチ命名 → テスト実装 → テストパターンのレビュー → コミット → PR作成」まで一気通貫で、各工程のルールをスキルファイルで縛れるかの検証です。
rules / skills を用意する
応用編では、ルールファイルとスキルファイルの両方を使います。ワーカーがちゃんと読んだかどうかが一目でわかるように、事前に Claude と相談してちょっと変わったルールも仕込んであります。
各ファイルの詳細はこちらのPRを見てもらうとして、ここでは要点だけ紹介します。
rules(自動適用)
| ファイル | 適用範囲 | 要点 |
|---|---|---|
pr-title-prefix.md |
全体 | PRタイトルの先頭に「rules/skills使用ver. 」をつける |
test-conventions.md |
test/**/*.ts |
テストデータのタスク名は寿司ネタ、開始/終了時にログ出力 |
test-tasks-special.md |
test/handlers/tasks/** |
tasks ドメインのテストデータのタスク名は戦国武将にする |
rules は paths フロントマターで適用フォルダを指定できます。test-tasks-special.md は tasks ドメインだけに効くようにしてあります。
skills(プロンプトから明示的に参照)
| スキル | 要点 |
|---|---|
commit-convention |
コミットメッセージに季語を入れる |
review-test-pattern |
境界値テストで「森鷗外」(サロゲートペア)を使う + レビューチェックリストをコメントで残す |
pr-template |
it の説明文を関西弁で書く |
スキルファイルをブランチにまとめる
まず、スキルファイルを追加するブランチを作成してPRを出します。
git checkout -b chore/add-test-rules-and-skills
# .claude/rules/ と .claude/skills/ 配下にファイルを追加
git add .claude/rules/ .claude/skills/
git commit -m "chore: テスト生成用のルールとスキルファイルを追加"
git push -u origin chore/add-test-rules-and-skills
gh pr create --title "テスト生成用のルールとスキルファイルを追加"
このブランチをベースにして /batch を実行します。こうすることで、各ワーカーがスキルファイルを確実に参照できる状態になります。
/batch 実行
/batch src/handlers/ 配下の6ドメイン(tasks, projects, milestones, users, tags, comments)
それぞれに対して以下のワークフローを実行してください。
PRのベースブランチは chore/add-test-rules-and-skills にしてください。
作業ブランチ名は末尾に -v2 をつけてください。
1. 対応するテストコードを test/handlers/ 配下に生成する
- Vitest + Hono の app.request() を使用
- 正常系・異常系の両方をカバー
- 各テストの前にDBのデータをリセットする
2. /review-test-pattern でテストパターンをレビューし、不足しているケースがあれば追加する
3. /commit-convention でコミットする
4. pushしてGitHub ActionsのCIが通ることを確認する(gh run watch で監視)
5. /pr-template でPRを作成する
基本編よりやることが増えていますが、各ステップのルールをスキルファイルで定義しているので、6ドメイン分のワーカーが同じ規約に従って動いてくれる...はず。
ちなみに、テスト確認をローカルの pnpm test ではなく GitHub Actions の CI にしているのには理由があります。
/batch のワーカーは git worktree で独立した作業ディレクトリを持つのでファイルの競合は起きないんですが、テスト実行時のDB接続は共有されてしまいます。
複数ワーカーが同時に pnpm test を走らせると、同じ PostgreSQL に対してデータのリセットやInsertが並列で走ることになり、テストが干渉して失敗するケースが出てきます。
そこで、pushしてリモートのCIで確認する方式にしています。GitHub Actions ではワーカーごとに独立した PostgreSQL コンテナが立ち上がるので、並列実行しても干渉しません。gh run watch で実行中のワークフローを監視できるので、ワーカーはpush後にCIの結果を待って、パスしたら次のステップに進む流れになります。
検証
/batch を実行すると、まず Plan モードでコードベースを調査して分解計画を提示してくれます。
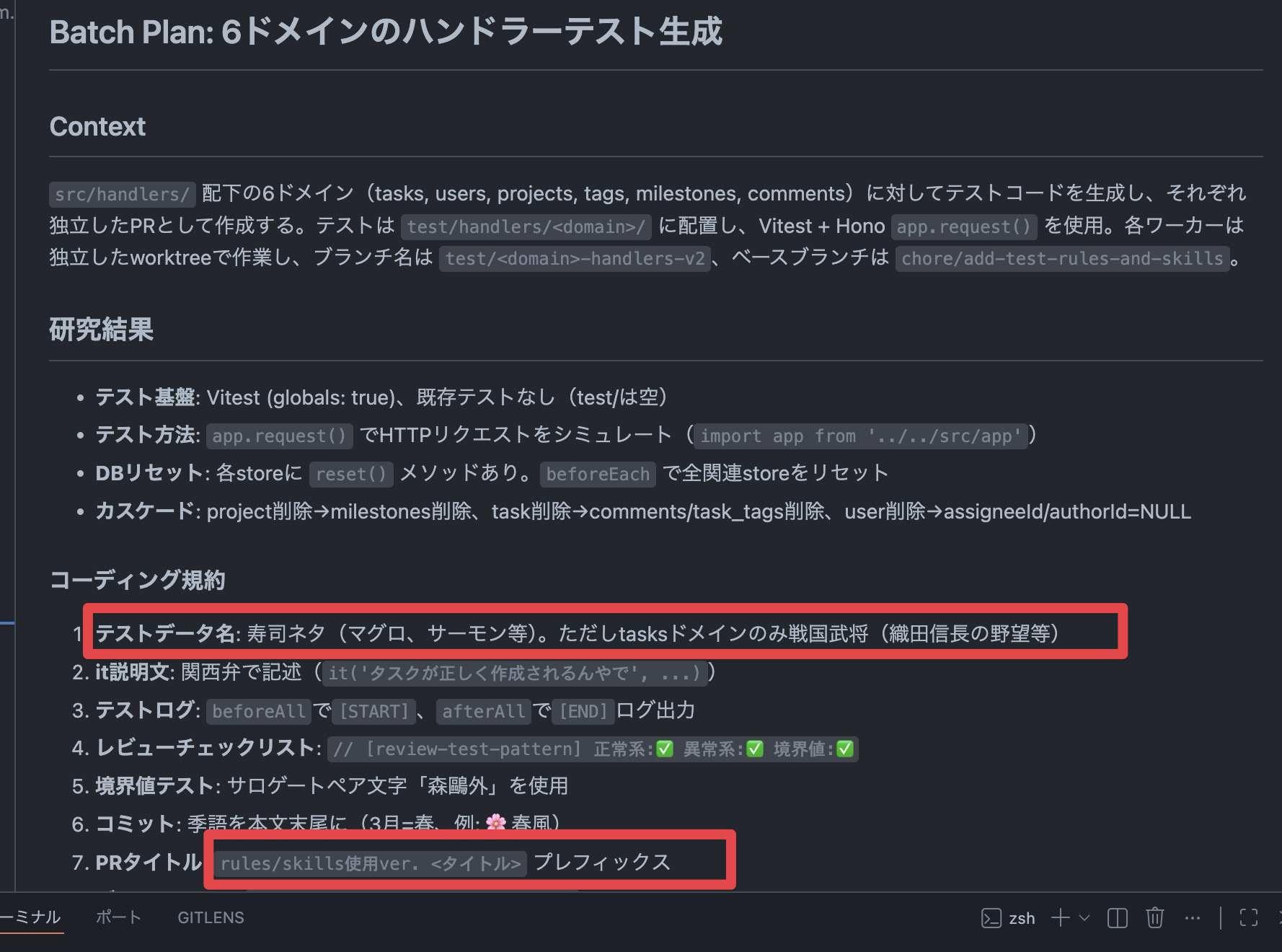
スキルやルールの内容がちゃんと計画に反映されているのがわかります。
この内容で問題なければ承認して、実行に進みます。
無事作業が完了しました。
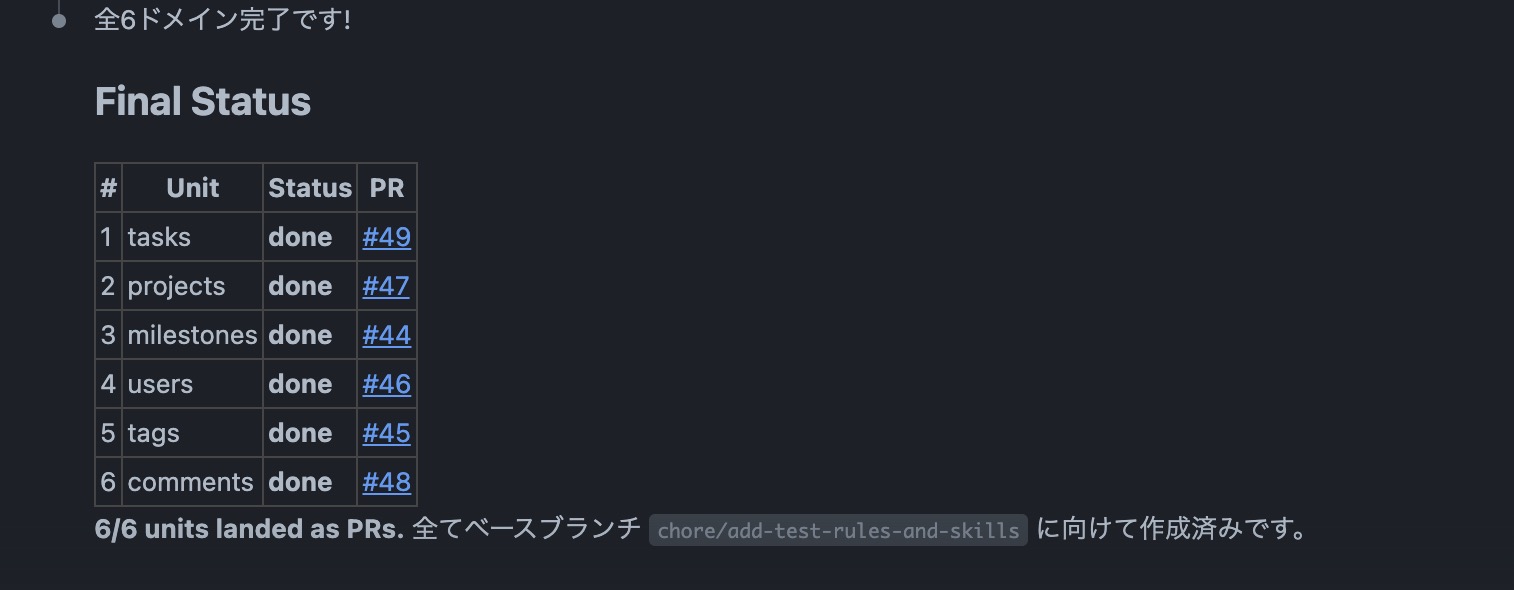
検証結果
各ドメインで生成されたPRの詳細はこちらから確認できます。
6ドメインすべてでPRが作成され、CIも全件パスしていました。
各ルール・スキルがちゃんと反映されているか、1つずつ確認していきます。
PRタイトルプレフィックス(rule: pr-title-prefix.md)
全PRに「rules/skills使用ver. 」がついています。
| PR | タイトル |
|---|---|
| #49 | rules/skills使用ver. tasksドメインのハンドラーテストを追加 |
| #48 | rules/skills使用ver. commentsドメインのハンドラーテストを追加 |
| #47 | rules/skills使用ver. projectsドメインのハンドラーテストを追加 |
| #46 | rules/skills使用ver. usersドメインのハンドラーテストを追加 |
| #45 | rules/skills使用ver. tagsドメインのハンドラーテストを追加 |
| #44 | rules/skills使用ver. マイルストーンハンドラーのテストを追加 |
✅ 全6PR反映済み
テストデータの命名(rule: test-conventions.md / test-tasks-special.md)
test-conventions.md で「テストデータのタスク名は寿司ネタ」、test-tasks-special.md で「tasksドメインだけは戦国武将にする」と指定していました。
- tasks以外の5ドメイン: マグロ、サーモン、エビ、イカ、タマゴ、ウニなどの寿司ネタが使われています。users ドメインでは「マグロ太郎」「サーモン花子」のようにユーザー名に寿司ネタを組み込むアレンジも入ってました
- tasksドメイン: 織田信長の野望、豊臣秀吉の天下統一、徳川家康の忍耐、武田信玄、上杉謙信、伊達政宗と、しっかり戦国武将になっています。寿司ネタの混入もなし
paths フロントマターによるドメイン限定ルールがちゃんと効いていますね。
✅ 全6PR反映済み
開始/終了時のログ出力(rule: test-conventions.md)
全PRの describe ブロックに beforeAll / afterAll で [START] / [END] のログ出力が入っていました。
✅ 全6PR反映済み
it の説明文を関西弁に(skill: pr-template)
全PRの it() が関西弁で書かれています。
it("タスクが正しく作成されるんやで", ...)
it("titleが空やったら400返すっちゅうねん", ...)
it("存在しないプロジェクトやったら404返すねん", ...)
it("他のユーザーのタスクは含まれへんで", ...)
「〜やで」「〜ねん」「〜っちゅうねん」「〜へんで」など、バリエーションも豊富でした。
✅ 全6PR反映済み
境界値テストで「森鷗外」(skill: review-test-pattern)
全PRのテストファイルに、サロゲートペア文字「森鷗外」を使った境界値テストが含まれていました。tasks ドメインでは「森鷗外の野望」「森鷗外の策略」「森鷗外の進軍」のように戦国武将テーマに合わせた使い方になっていて、ちゃんとドメイン固有ルールとの整合性もとれています。
✅ 全6PR反映済み
レビューチェックリスト(skill: review-test-pattern)
全テストファイルの先頭に // [review-test-pattern] 正常系:✅ 異常系:✅ 境界値:✅ のチェックリストコメントが付与されていました。
✅ 全6PR反映済み
コミットメッセージに季語(skill: commit-convention)
全PRのコミットメッセージ末尾に季語が入っています。
| PR | 季語 |
|---|---|
| #49 (tasks) | 🌸 花曇 |
| #48 (comments) | 🌸 春霞 |
| #47 (projects) | 🌸 沈丁花 |
| #46 (users) | 🌸 春霞 |
| #45 (tags) | 🌸 春霞 |
| #44 (milestones) | 🌸 桜餅 |
全部春の季語で統一されていますね。ワーカーごとに異なる季語を選んでいるのもいい感じです。
✅ 全6PR反映済み
CI
全6PRでGitHub Actionsのチェックがパスしています。プロンプトで「CIが通ることを確認する」と指定していた通り、ワーカーが gh run watch でCIの完了を待ってからPR作成に進んでくれたようです。
✅ 全6PR パス
総合結果
| チェック項目 | 結果 |
|---|---|
| PRタイトルプレフィックス(rule) | ✅ 6/6 |
| テストデータ寿司ネタ(rule) | ✅ 5/5(tasks以外) |
| テストデータ戦国武将(rule) | ✅ 1/1(tasksのみ) |
| 開始/終了ログ(rule) | ✅ 6/6 |
it 関西弁(skill) |
✅ 6/6 |
| 森鷗外 境界値(skill) | ✅ 6/6 |
| レビューチェックリスト(skill) | ✅ 6/6 |
| コミット季語(skill) | ✅ 6/6 |
| CI パス | ✅ 6/6 |
rules も skills も全項目が反映されていました。paths によるドメイン限定ルール(tasks だけ戦国武将にする)もちゃんと効いていて、他ドメインへの漏れもなしです。
ちょっと変わったルールを仕込んでも、ワーカーはきっちり読んで従ってくれるのがわかりますね。
実案件で使ってみた話
やったこと
デモではテスト生成にフォーカスしましたが、実案件ではもっと大きなワークフローを /batch に任せてみました。
具体的には 「API仕様書更新 → API修正 → テストコード修正 → レビュー → PR作成」 という一連の流れを、8つのAPIエンドポイントに対して8並列で実行しています。
やっていることは応用編の延長で、スキルファイルで各工程のルールを定義して、/batch のプロンプトにワークフロー全体を記述する形です。テスト生成だけじゃなく、実装そのものも並列で回せるのは結構インパクトがありました。
ちなみに8ワーカーが同時に走ると、PCのファンがものすごい勢いで回ってすごい音がなってました。
実際にやってみて
以下の流れで進めてみました。
- Claude と作業手順を相談してプロンプトを作る
- 「ちゃんとしたプロンプトができた」と思って
/batchで一気に実行 - 実装計画(Plan)を深く確認せずにそのままGO
- 実際の作業内容が意図とちょっとズレてる
- → 全ワーカーが同じズレた方向で進んでしまい、全部やり直し
/batch はワークフロー全体を一気に回すので、気づいたときにはもうPRまでできあがっちゃってます。
「あれ、なんか思ってたのと違う...」ってPRを開いて気づいたときにはもう手遅れ。8つ全部やり直しです。
1個ズレるだけならまだしも、並列で走っているからこそ全部ズレたときの被害が大きい。。
次からこうするようにした
これを踏まえて、以下の流れでやるようにしました。
- まず 1つだけ 通常のセッションで作業を試す
- 生成結果を確認して「これでいいな」という状態を作る
- その作業内容を Claude に手順化してもらう(= 実績ベースのプロンプトになる)
- 手順化されたプロンプト + 適用範囲を
/batchに渡して並列実行 - 実装計画(Plan)をちゃんと確認してからGO(本来当たり前なんですが・・・)
並列で走るからこそ、1つズレると全部ズレる。最初の1つを手動で成功させてから横展開する形式にして実装計画を改めてちゃんと確認するようにしました。
完了条件と確認ポイントは明確にしておく
これは /batch に限った話ではないんですが、各手順で確認してほしいことや完了条件を曖昧にしないのは大事です。
たとえば「テストを書いてコミットして」だけだと、テストが通るか確認せずにコミットまで進んでしまう可能性があります。
「CIが通ることを確認してからPRを作成する」まで書いておくことで、同じ品質基準で動いてくれるようになります。
今回の応用編のプロンプトでも、ステップ4に「GitHub ActionsのCIが通ることを確認する」を明示的に入れているのはそのためです。
通常のセッションなら「あ、ここはこうして」って途中で軌道修正できるので、多少曖昧でもなんとかなります。でも /batch だとワーカーは一度走り出したら止められないし、それが並列で何個も同時に走っている。1つの曖昧さが全ワーカーに波及するので、複雑なタスクになるほど想定外が起きたときの被害がでかくなります。
完了条件やチェックポイントをルールやスキルファイルに定義しておくのも有効です。プロジェクトに合わせて育てていくと、普段の開発でも効いてきます。
まとめ
Claude Code の /batch コマンドを使って、同じ作業を並列で回す方法を紹介しました。
実案件でも使ってみて感じたのは、複雑なワークフローを /batch に任せると、想定通りにいかなかったときの被害がでかいということです。並列で走っている分、1つズレると全部ズレる。
手戻りのコストが直列の何倍にもなります。
逆に言うと、/batch が一番力を発揮するのは単純作業を一気に横展開したいときです。
「同じパターンの作業を、対象を変えて繰り返す」——テスト生成、定型的なリファクタ、ドキュメント作成など、1つ成功パターンを作ってから横に広げる使い方がめちゃくちゃ刺さります。
自分の失敗談が参考になれば幸いです。
おまけ
2026年3月26日(木)に、クラスメソッド名古屋オフィス(伏見駅徒歩5分)で 「なごやクラメソゆる勉強会」 を開催します!
第1回のテーマは「最近やってみたこと」のLT大会です。
途中退出OK、LTを聞くだけでもOK。LT後には交流タイムもあるので、LTで気になったことを登壇者に聞いてみたり、「最近これ気になってるんですけど...」みたいな雑談をしたり、なんでも気軽に話せます。
今後も定期的にイベントを開催していく予定で、こちらで随時更新していく予定です!ご興味ある方はぜひ!







