
Cloud RunとCloud Pub/SubのPullサブスクリプションで非同期処理を試してみた
はじめに
こんにちは。
クラウド事業本部コンサルティング部の渡邉です。
Web API でユーザーのリクエストを受け付けると同時に、時間のかかるバックエンド処理(画像変換・メール送信・在庫更新など)を非同期で実行したいというケースは多くあります。同期的に処理すると API のレスポンスが遅くなり、バックエンドが詰まるとフロントエンドにも影響が波及します。
本記事では、Cloud Pub/Sub の Pull サブスクリプションと Cloud Run(Service / Worker Pool)を組み合わせた非同期処理アーキテクチャを実際に構築し、非同期化のメリットを検証します。
検証するアーキテクチャ
シナリオは EC サイトの注文処理です。以下の 2 つのコンポーネントで構成します。
| コンポーネント | Cloud Run リソース | 役割 |
|---|---|---|
| 注文受付 API (order-api) | Cloud Run Service | POST リクエストを受け取り Pub/Sub にパブリッシュ後、即座に 202 を返す |
| 注文処理ワーカー (order-worker) | Cloud Run Worker Pool | Pull サブスクリプションから StreamingPull でメッセージを取得して処理 |
API はパブリッシュが完了した時点でレスポンスを返します。注文処理にかかる時間は API のレスポンスタイムに影響しません。
実際に試してみる
前提条件
- Google Cloud プロジェクトが作成済みであること
gcloudCLI がインストール・認証済みであること- 以下の IAM ロールが付与されていること
- Cloud Run Admin(
roles/run.admin) - Pub/Sub Admin(
roles/pubsub.admin) - Service Account Creator(
roles/iam.serviceAccountCreator) - Service Account User(
roles/iam.serviceAccountUser)
- Cloud Run Admin(
- Cloud Run、Pub/Sub、Cloud Build、Artifact Registry API が有効化されていること
ステップ 0: 環境変数の設定
export PROJECT_ID=YOUR_PROJECT_ID
export REGION=asia-northeast1
export TOPIC_ID=order-events
export SUBSCRIPTION_ID=order-sub
export PRODUCER_SA=order-api-sa
export CONSUMER_SA=order-worker-sa
ステップ 1: Pub/Sub トピック・Pull サブスクリプションの作成
# トピックを作成
gcloud pubsub topics create $TOPIC_ID --project=$PROJECT_ID
# Pull サブスクリプションを作成
gcloud pubsub subscriptions create $SUBSCRIPTION_ID \
--topic=$TOPIC_ID \
--project=$PROJECT_ID
# 確認
gcloud pubsub topics list --project=$PROJECT_ID
gcloud pubsub subscriptions list --project=$PROJECT_ID
Pub/Sub トピックとPull サブスクリプションの作成が確認できました。
# トピック
user@hostname:~$ gcloud pubsub topics list --project=$PROJECT_ID
---
name: projects/your-project-id/topics/order-events
# Pull サブスクリプション
user@hostname:~$ gcloud pubsub subscriptions list --project=$PROJECT_ID
---
ackDeadlineSeconds: 10
expirationPolicy:
ttl: 2678400s
messageRetentionDuration: 604800s
name: projects/your-project-id/subscriptions/order-sub
pushConfig: {}
state: ACTIVE
topic: projects/your-project-id/topics/order-events
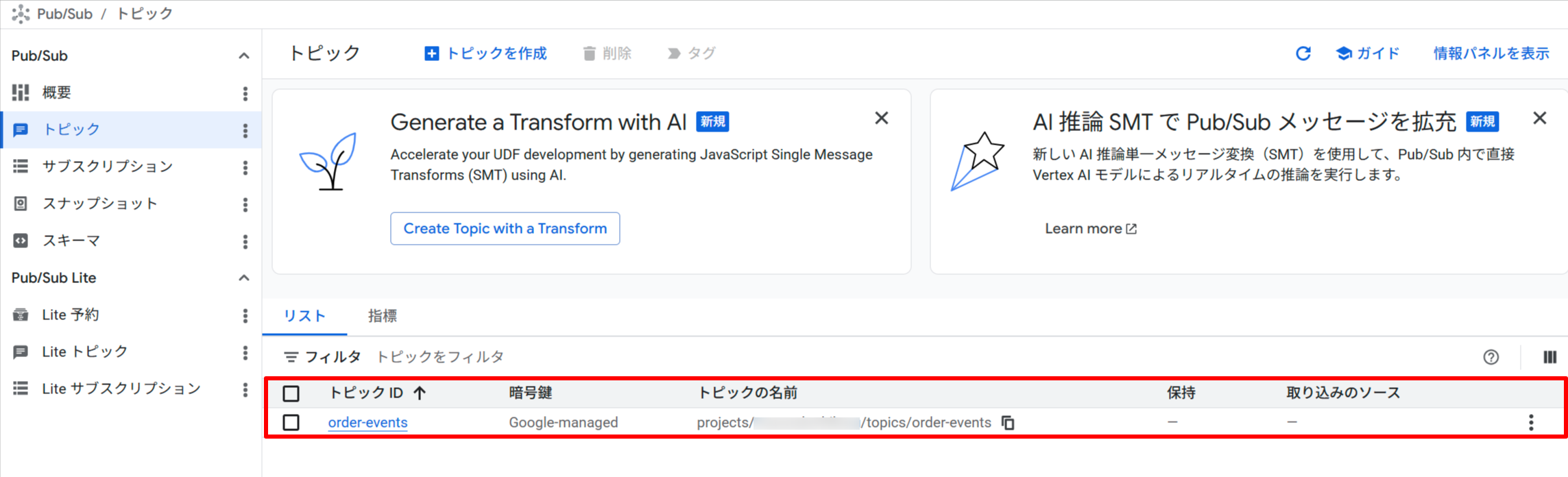
Pub/Sub トピック「order-events」の作成を確認
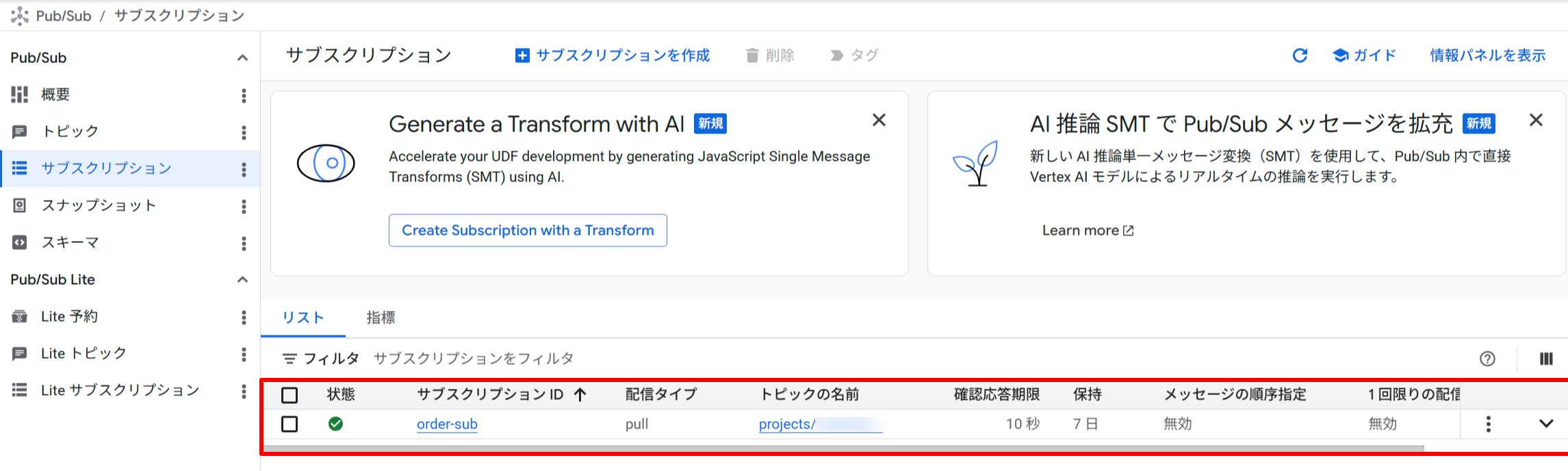
Pub/Sub サブスクリプション「order-sub」の作成を確認(ACTIVE 状態)
ステップ 2: サービスアカウントの作成と権限付与
プロデューサーとコンシューマーそれぞれ専用のサービスアカウントを作成し、最小権限を付与します。
# プロデューサー用 SA(Pub/Sub へのパブリッシュ権限)
gcloud iam service-accounts create $PRODUCER_SA \
--display-name="Order API Service Account" \
--project=$PROJECT_ID
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PRODUCER_SA@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/pubsub.publisher"
# コンシューマー用 SA(サブスクリプションからの Pull 権限)
gcloud iam service-accounts create $CONSUMER_SA \
--display-name="Order Worker Service Account" \
--project=$PROJECT_ID
gcloud pubsub subscriptions add-iam-policy-binding $SUBSCRIPTION_ID \
--member="serviceAccount:$CONSUMER_SA@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/pubsub.subscriber" \
--project=$PROJECT_ID
プロデューサーとコンシューマーそれぞれ専用のサービスアカウントと、権限を付与が確認できました。
# プロデューサー用 SA(Pub/Sub へのパブリッシュ権限)
user@hostname:~$ gcloud projects get-iam-policy $PROJECT_ID \
--flatten="bindings[].members" \
--filter="bindings.members=serviceAccount:$PRODUCER_SA@$PROJECT_ID.iam.gserviceaccount.com" \
--format="table(bindings.role)"
ROLE
roles/pubsub.publisher
# コンシューマー用 SA(サブスクリプションからの Pull 権限)
user@hostname:~$ gcloud pubsub subscriptions get-iam-policy $SUBSCRIPTION_ID \
> --project=$PROJECT_ID
bindings:
- members:
- serviceAccount:order-worker-sa@your-project-id.iam.gserviceaccount.com
role: roles/pubsub.subscriber
etag: BwZSIhRXtDo=
version: 1
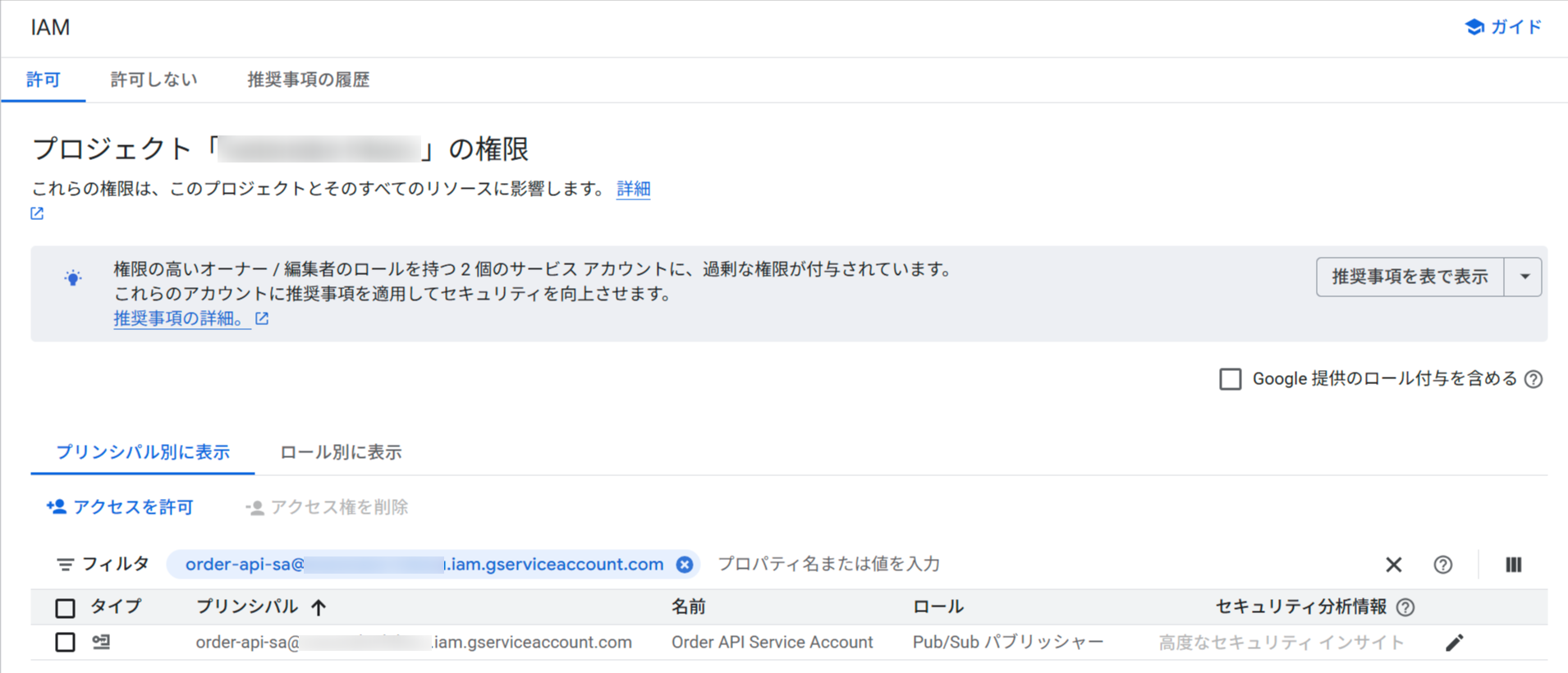
プロデューサー用 SA(order-api-sa)への Pub/Sub Publisher ロール付与を確認
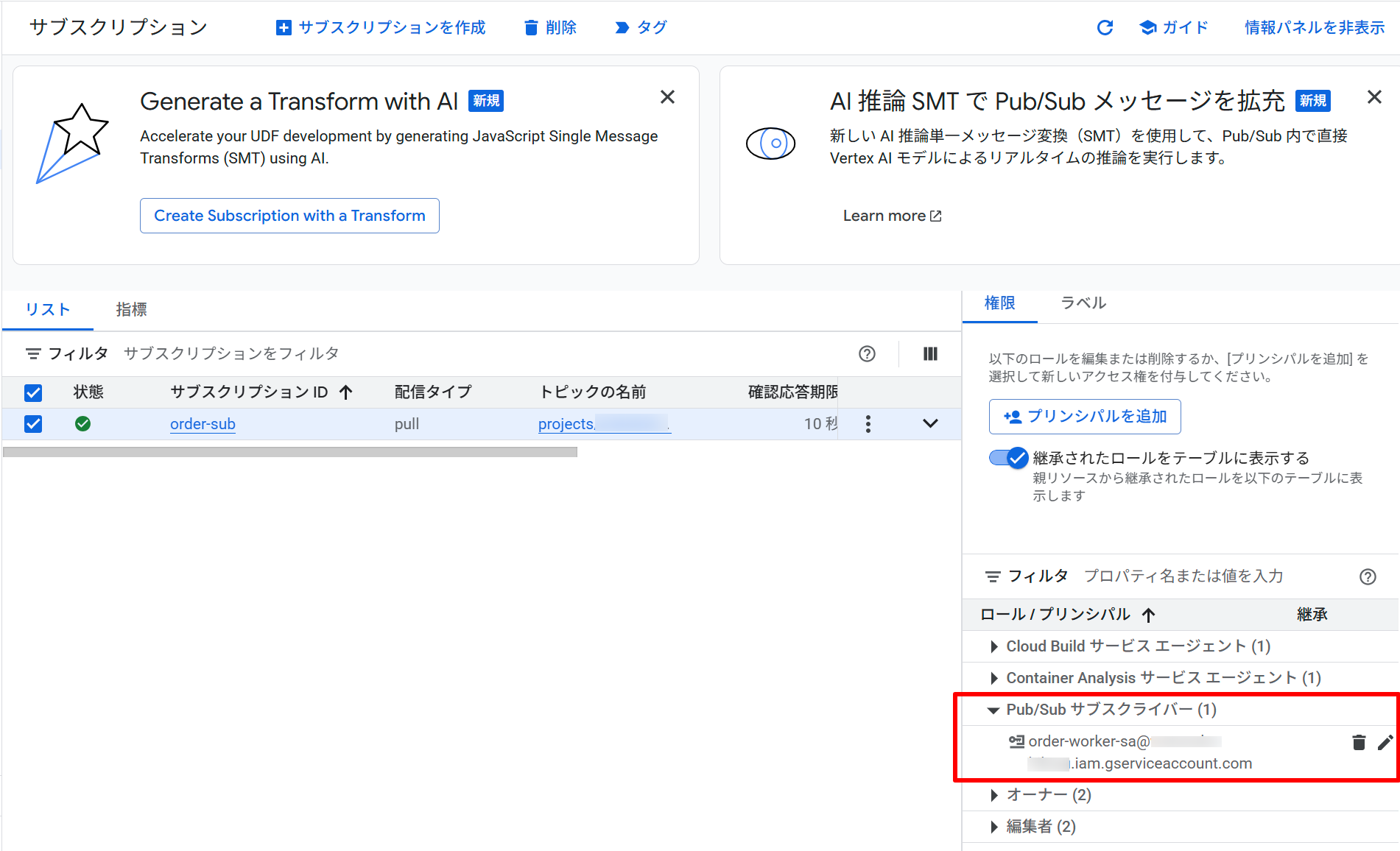
コンシューマー用 SA(order-worker-sa)へのサブスクリプション Subscriber ロール付与を確認
ステップ 3: コンシューマー(Cloud Run Worker Pool)のデプロイ
Worker Pool は HTTP エンドポイントを持たず、起動後すぐに Pub/Sub へ StreamingPull を開始します。
ディレクトリ構成
order-worker/
├── worker.py
└── Dockerfile
worker.py
import os
import time
from google.cloud import pubsub_v1
PROJECT_ID = os.environ.get("PROJECT_ID")
SUBSCRIPTION_ID = os.environ.get("SUBSCRIPTION_ID")
subscription_path = f"projects/{PROJECT_ID}/subscriptions/{SUBSCRIPTION_ID}"
print(f"Worker starting. Watching {subscription_path}...")
subscriber = pubsub_v1.SubscriberClient()
def callback(message):
try:
data = message.data.decode("utf-8")
print(f"Processing: {data}")
time.sleep(5) # 注文処理を模したスリープ
print(f"Done: {data}")
message.ack()
except Exception as e:
print(f"Error: {e}")
message.nack()
streaming_pull_future = subscriber.subscribe(subscription_path, callback=callback)
print(f"Listening for messages on {subscription_path}...")
with subscriber:
try:
streaming_pull_future.result()
except Exception as e:
print(f"Streaming pull failed: {e}")
worker.py の解説
① 環境変数からサブスクリプションパスを組み立てる
PROJECT_ID = os.environ.get("PROJECT_ID")
SUBSCRIPTION_ID = os.environ.get("SUBSCRIPTION_ID")
subscription_path = f"projects/{PROJECT_ID}/subscriptions/{SUBSCRIPTION_ID}"
Pub/Sub の各リソースは projects/{project}/subscriptions/{subscription} 形式のフルパスで識別されます。プロジェクト ID とサブスクリプション ID はデプロイ時に --set-env-vars で渡した環境変数から読み取ります。コードにハードコードしないことで、環境(dev/stg/prd)を変数で切り替えられます。
② SubscriberClient をモジュールレベルで生成する
subscriber = pubsub_v1.SubscriberClient()
SubscriberClient は gRPC コネクションを内部に持ちます。Worker Pool のプロセスは 1 つのインスタンスにつき 1 プロセスなので、モジュールレベルで一度だけ生成することでコネクションを使い回し、オーバーヘッドを抑えます。
③ コールバック関数 — メッセージ 1 件ごとに呼ばれる処理
def callback(message):
try:
data = message.data.decode("utf-8") # バイト列を文字列に変換
...
message.ack() # 正常完了 → Pub/Sub にメッセージ削除を通知
except Exception as e:
message.nack() # 処理失敗 → Pub/Sub に再配信を要求
message.data は bytes 型です。JSON など文字列ベースのデータを扱う場合は .decode("utf-8") で変換します。
| メソッド | 意味 | Pub/Sub の動作 |
|---|---|---|
message.ack() |
処理成功を通知 | メッセージをサブスクリプションから削除 |
message.nack() |
処理失敗を通知 | Ack 期限をリセットし、すぐに再配信 |
| (何もしない) | Ack 期限切れ | 期限(デフォルト 10 秒〜600 秒)後に自動再配信 |
callback の処理フローを図で整理すると以下のようになります。
④ StreamingPull の開始と無限待機
streaming_pull_future = subscriber.subscribe(subscription_path, callback=callback)
with subscriber:
streaming_pull_future.result() # ここでブロックし続ける
subscriber.subscribe() は バックグラウンドスレッドで Pub/Sub との gRPC 双方向ストリームを開き、メッセージが届くたびに callback を非同期で呼び出します。このメソッド自体はすぐに制御を返します。
streaming_pull_future.result() はメインスレッドをブロックし続けることで、プロセスが終了しないようにします。例外が発生した場合にここで検知できます。
with subscriber: ブロックはプロセス終了時に subscriber.close() を確実に呼び出し、gRPC コネクションをクリーンアップします。
メインスレッドとバックグラウンドスレッドの関係を図で示すと以下のようになります。
Dockerfile
FROM python:3.12-slim
RUN pip install google-cloud-pubsub
COPY worker.py .
CMD ["python", "-u", "worker.py"]
デプロイ
cd order-worker
gcloud run worker-pools deploy order-worker \
--source . \
--region $REGION \
--service-account="$CONSUMER_SA@$PROJECT_ID.iam.gserviceaccount.com" \
--instances=1 \
--set-env-vars PROJECT_ID=$PROJECT_ID,SUBSCRIPTION_ID=$SUBSCRIPTION_ID
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named
[cloud-run-source-deploy] in region [asia-northeast1] will be created.
Do you want to continue (Y/n)? Y
Building using Dockerfile and deploying container to Cloud Run worker pool [order-worker] in project [your-project-id] region [asia-northeast1]
✓ Deploying new worker pool... Building Container.
✓ Creating Container Repository...
✓ Uploading sources...
✓ Building Container... Logs are available at [ https://console.cloud.google.com/cloud-build/builds;region=asia-northeast1/YOUR_BUILD_ID?project=YOUR_PROJECT_NUMBER ].
. Creating Revision...
Done.
Worker pool [order-worker] revision [order-worker-00001-zz6] has been deployed.
Done.
See logs with:
gcloud beta run worker-pools logs tail order-worker
Or visit https://console.cloud.google.com/run/worker-pools/details/asia-northeast1/order-worker

Cloud Run Worker Pool「order-worker」のデプロイ完了を確認
ステップ 4: プロデューサー(Cloud Run Service)のデプロイ
API は受け取った注文データを Pub/Sub にパブリッシュし、即座に 202 Accepted を返します。
ディレクトリ構成:
order-api/
├── main.py
└── requirements.txt
main.py
import os
from flask import Flask, request, jsonify
from google.cloud import pubsub_v1
app = Flask(__name__)
publisher = pubsub_v1.PublisherClient()
project_id = os.environ.get("PROJECT_ID")
topic_id = os.environ.get("TOPIC_ID")
topic_path = publisher.topic_path(project_id, topic_id)
@app.route("/orders", methods=["POST"])
def create_order():
data = request.get_data()
if not data:
return jsonify({"error": "request body is required"}), 400
future = publisher.publish(topic_path, data)
message_id = future.result()
return jsonify({"status": "queued", "message_id": message_id}), 202
if __name__ == "__main__":
app.run(host="0.0.0.0", port=int(os.environ.get("PORT", 8080)))
main.py の解説
① PublisherClient とトピックパスをモジュールレベルで初期化する
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_id)
PublisherClient は内部に gRPC コネクションプールを持ちます。Cloud Run はリクエストをさばく間コンテナを再利用するため、リクエストハンドラの外でインスタンス化しておけば、コネクション確立のコストを毎リクエストで払わずに済みます。
topic_path() は "projects/{project}/topics/{topic}" 形式のフルパスを生成するヘルパーメソッドです。
② リクエストボディをバイト列のまま取り出す
data = request.get_data()
request.get_data() はリクエストボディを bytes で返します。Pub/Sub のメッセージペイロード(data フィールド)は bytes を要求するため、JSON のパース・再シリアライズを挟まずにそのまま渡せます。これにより、API はペイロードの形式に依存しない薄いゲートウェイとして機能します。
create_order() 全体の処理フローは以下のとおりです。
③ パブリッシュと future.result() の役割
future = publisher.publish(topic_path, data)
message_id = future.result()
publisher.publish() は非同期で Pub/Sub にメッセージを送信し、Future オブジェクトを即座に返します。future.result() を呼ぶことで Pub/Sub サーバーがメッセージを受信・保存するまで待機し、採番された message_id を受け取ります。
API・Pub/Sub SDK・Pub/Sub サービス間のやり取りをシーケンスで示すと以下のようになります。
④ 202 Accepted を返す理由
return jsonify({"status": "queued", "message_id": message_id}), 202
HTTP 202 Accepted は「リクエストは受け付けたが、処理はまだ完了していない」を意味するステータスコードです。200 OK ではなく 202 を返すことで、クライアントに対して注文の最終処理は非同期で行われることを明示します。message_id を返すと、クライアントが後続の処理状況確認 API(ポーリング等)を実装する際の識別子として使えます。
⑤ ポート設定
app.run(host="0.0.0.0", port=int(os.environ.get("PORT", 8080)))
Cloud Run はコンテナの待ち受けポートを環境変数 PORT で渡します。os.environ.get("PORT", 8080) でローカル実行時のデフォルト(8080)を保ちつつ、Cloud Run 上では自動設定されたポートを使います。host="0.0.0.0" はコンテナ外からの接続を受け付けるために必須です。
requirements.txt
Flask==3.0.3
gunicorn==23.0.0
google-cloud-pubsub==2.28.0
デプロイ
cd order-api
gcloud run deploy order-api \
--source . \
--region $REGION \
--service-account="$PRODUCER_SA@$PROJECT_ID.iam.gserviceaccount.com" \
--set-env-vars PROJECT_ID=$PROJECT_ID,TOPIC_ID=$TOPIC_ID \
--allow-unauthenticated
デプロイ完了時に表示された URL を環境変数に保存します。
Building using Buildpacks and deploying container to Cloud Run service [order-api] in project [your-project-id] region [asia-northeast1]
✓ Building and deploying new service... Done.
✓ Validating configuration...
✓ Uploading sources...
✓ Building Container... Logs are available at [ https://console.cloud.google.com/cloud-build/builds;region=asia-northeast1/YOUR_BUILD_ID?project=YOUR_PROJECT_NUMBER ].
✓ Creating Revision...
✓ Routing traffic...
✓ Setting IAM Policy...
Done.
Service [order-api] revision [order-api-00001-4sl] has been deployed and is serving 100 percent of traffic.
Service URL: https://order-api-YOUR_PROJECT_NUMBER.asia-northeast1.run.app

Cloud Run Service「order-api」のデプロイ完了を確認
ステップ 5: 動作確認
注文を送信します。API は 5 秒の処理時間がかかる注文処理を待たずに即応答します。-w オプションでレスポンスタイムを計測します。
# 注文リクエストの送信(レスポンスタイム計測付き)
curl -X POST $SERVICE_URL/orders \
-H "Content-Type: application/json" \
-d '{"order_id":"ORD-001","item":"book","qty":2}' \
-w "\ntime_total: %{time_total}s\n"
curl -X POST $SERVICE_URL/orders \
-H "Content-Type: application/json" \
-d '{"order_id":"ORD-002","item":"pen","qty":5}' \
-w "\ntime_total: %{time_total}s\n"
{"message_id":"19114283623792820","status":"queued"}
time_total: 0.208955s
{"message_id":"19114287379961629","status":"queued"}
time_total: 0.141060s
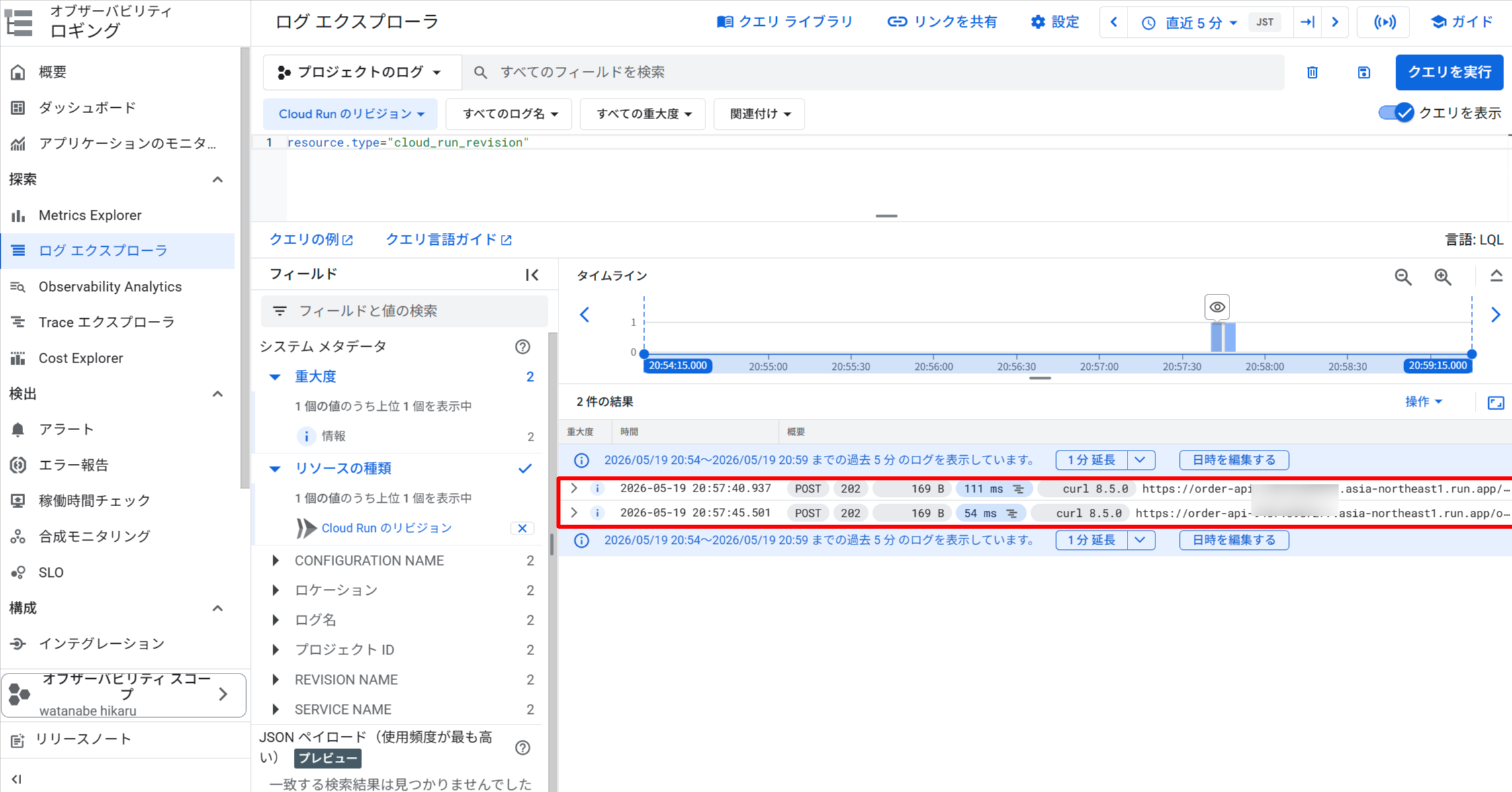
Cloud Run Service(order-api)のログ: 20:57 頃に 2 件の POST /orders リクエストが記録されている
Cloud Run Service のログに 2 件の POST リクエストが約 20:57:40頃 に記録されています。この時点で API はすでに 202 を返しており、注文処理の完了を待っていません。
Worker Pool のログでメッセージが処理されていることを確認します。
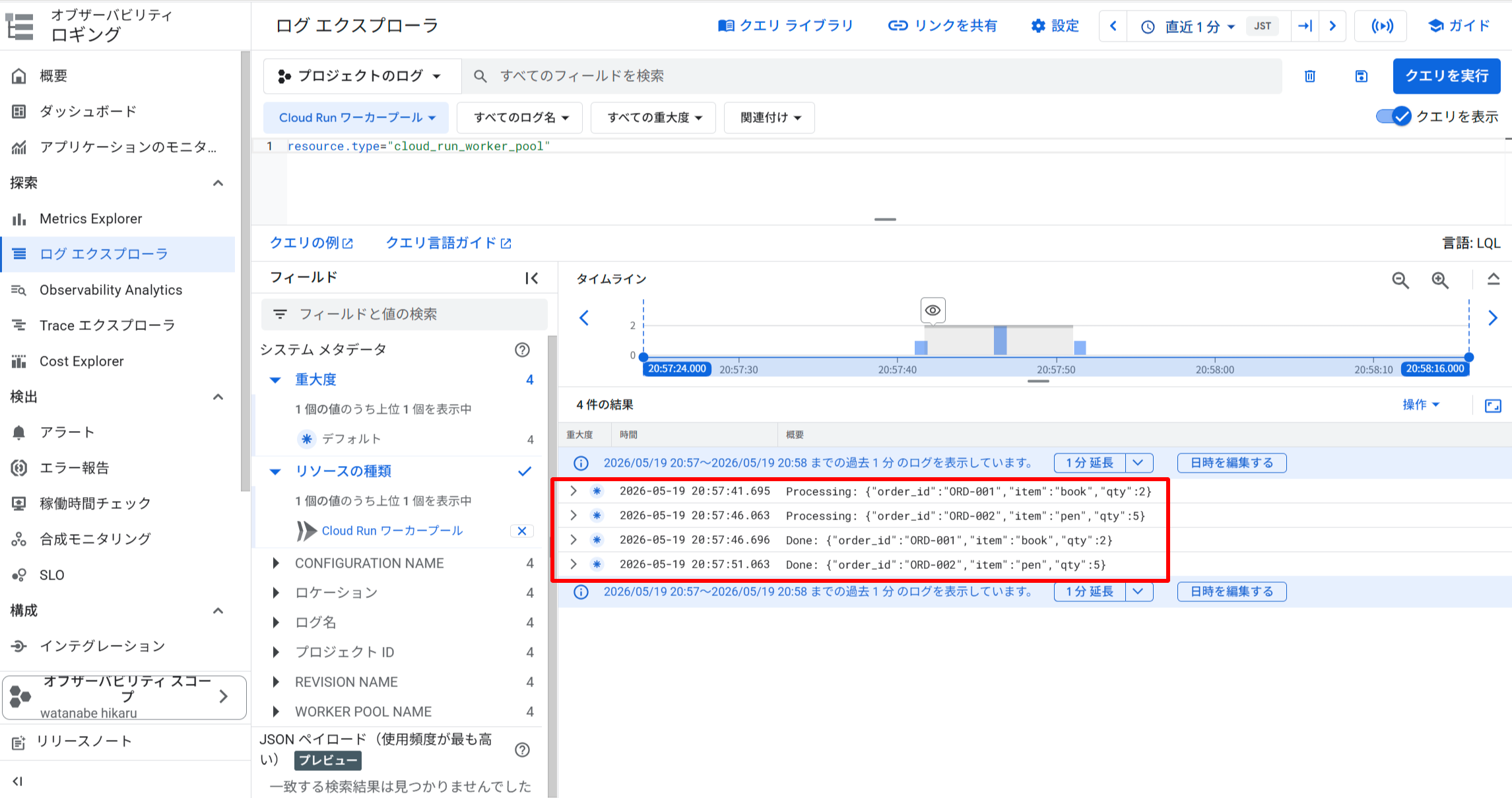
Cloud Run Worker Pool(order-worker)のログ: Processing → Done のペアが 2 件、各処理に約 5 秒かかっていることが確認できる
Worker Pool のログには 4 件のエントリが記録されています。Processing: と Done: のタイムスタンプ差がそれぞれ約 5 秒で、time.sleep(5) による処理時間と一致します。また API がレスポンスを返した 20:57:41頃 より約5秒後の 20:57:46頃 にログが出力されており、API の応答と Worker の処理が完全に切り離された非同期処理が成立していることが確認できます。
API は 202 Accepted を即座に返し、バックグラウンドで Worker が注文処理を継続していることがわかります。
まとめ
今回は Cloud Pub/Sub の Pull サブスクリプションと Cloud Run(Service + Worker Pool)を組み合わせた非同期処理アーキテクチャをご紹介しました。注文受付 API は Pub/Sub へのパブリッシュが完了した時点で即座に 202 を返し、以降の注文処理は Worker Pool が StreamingPull で非同期に担うことで、API のレスポンスタイムとバックエンド処理の重さを完全に切り離せることを確認できました。Pull サブスクリプション+Worker Pool の構成はコンシューマー側でメッセージ取得ペースを完全にコントロールできるため、重い処理を持つワーカーでも過負荷になりにくくフロー制御が自然に効く点も実感できました。また message.ack() を処理完了後に呼ぶルールを守るだけで障害時の自動リトライが成立するため、アプリケーションコードにリトライロジックを書く必要がなくコードをシンプルに保てます。
一方で、デフォルトの at-least-once 配信により同じメッセージが複数回届く場合があるため冪等な実装が前提になる点は押さえておきましょう。
この記事が誰かの助けになれば幸いです。
以上、クラウド事業本部コンサルティング部の渡邉でした!








