
AWS LambdaでDuckDBとAWS Data Wrangler、Polarsの処理性能を比較してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
データ事業本部ビッグデータチームのkasamaです。
今回はLambda上で、DuckDBとAWS SDK for Pandas(AWS Data Wrangler)、Polarsをシンプルなcsv → parquetへ変換する処理を実行して、メモリ使用量、処理速度にどのような違いがあるか検証したいと思います。
前提
背景
以下のブログを読んでいて、DuckDBではデータパイプラインのパフォーマンスを8時間から8分に短縮した事例があると記載があったので、そんなに速くなるの?
AWS Data Wrangler、Polarsと比較してどれほど速いのか検証してみたいと思ったことがきっかけです。
以下ブログの性能評価も参考になりましたが、Lambda上で単純なcsv → parquet変換処理の場合でも同様なのかが気になりましたので、試してみたいと思います。
それぞれの違い
以下の表は、DuckDB、AWS SDK for Pandas (AWS Data Wrangler)、Polarsの主な違いを簡単にまとめたものです。
| 特性 | DuckDB | AWS SDK for Pandas (AWS Data Wrangler) | Polars |
|---|---|---|---|
| 実装言語 | C++ | Python (内部的にC) | Rust |
| アーキテクチャ | カラムナ型埋め込みデータベース | Pandasの拡張ライブラリ | カラムナ型DataFrame |
| 処理モデル | ベクトル化クエリ実行 | Pandasベース(主にシングルスレッド) | 並列処理、SIMD最適化 |
| 処理速度 | 非常に高速(SQLベース) | 中程度(Pandasに依存) | 非常に高速(Rustベース) |
| メモリ効率 | 高(アウトオブコア処理) | 中程度(Pandasに依存) | 高(Apache Arrow、最適化) |
| 主なユースケース | 分析クエリ、データパイプライン、ローカル開発 | AWS環境でのETL、データレイク構築 | 高性能データ分析、大規模データセット処理 |
- DuckDB:
- カラムナ型: データがカラム(列)単位で格納・処理されます。従来の行指向と異なり、特定の列だけを効率的に読み取れます。
- 埋め込みデータベース: アプリケーションのプロセス内で動作し、別サーバーを必要としなせず、SQLiteのように単一ファイルとして動作可能です。DuckDBの場合はインメモリなので、ファイルを作成せず、メモリ内だけで動作可能です。
- ベクトル化クエリ実行: 一度に多数の値(ベクトル)をバッチ処理することで、CPUのパイプラインと命令レベル並列性を最大化します。これにより関数呼び出しのオーバーヘッドが大幅に削減され、処理速度が向上します。
- OLAP特化設計: 分析クエリ(OLAP)に最適化されており、大量データのスキャン、集計、結合操作が高速です。特に集計クエリや複雑な分析において優れたパフォーマンスを発揮します。
- 並列処理: 複数のCPUコアを活用して処理を並列化し、大規模なデータセットでも高速な処理を実現します。
- AWS SDK for Pandas:
- AWS のデータと分析サービスと Pandas DataFrame 間のやり取りが簡単に行える Python ライブラリです。
- AWS環境でのデータ処理に特化。AWS各種サービスとの統合が最大の強みです。
- Polars:
- Rust: Polars は Rust で記述されており、Rustの所有権システムとメモリ管理モデルにより、C/C++レベルのパフォーマンスを実現しつつ、メモリ使用量を細かく制御した効率的なデータ処理が可能です。
- カラムナ型DataFrame: Apache Arrow形式をメモリモデルとして採用し、データをカラム単位で格納・処理します。これにより分析操作が高速化され、メモリ効率も向上します。
- 並列処理エンジン: 使用可能な CPU コア間でワークロードを並列処理にすることでマシンのパワーを活用します。
SIMD最適化: 単一命令で複数データを処理するSIMD命令を活用し、ベクトル化された処理を実現します。これにより速度向上が可能です。 - 高性能データ分析、大規模データセット処理処理に使われます。
検証結果
- 100MBファイル
| ライブラリ | 実行時間(秒) | メモリ使用量(MB) | 結果 |
|---|---|---|---|
| AWS Data Wrangler | 6.81 | 701 | 成功 |
| DuckDB | 2.43 | 734 | 成功 |
| Polars | 1.70 | 644 | 成功 |
- 1GBファイル
| ライブラリ | 実行時間(秒) | メモリ使用量(MB) | 結果 |
|---|---|---|---|
| AWS Data Wrangler | 65.00 | 4,126 | 成功 |
| DuckDB | 15.09 | 1,256 | 成功 |
| Polars | 16.01 | 3,015 | 成功 |
- 3GBファイル
| ライブラリ | 実行時間(秒) | メモリ使用量(MB) | 結果 |
|---|---|---|---|
| AWS Data Wrangler | - | - | 失敗 (OOM) |
| DuckDB | 61.41 | 1,680 | 成功 |
| Polars | 56.59 | 6,800 | 成功 |
- 6GBファイル
| ライブラリ | 実行時間(秒) | メモリ使用量(MB) | 結果 |
|---|---|---|---|
| AWS Data Wrangler | - | - | 未実施 |
| DuckDB | 180.59 | 1,725 | 成功 |
| Polars | 115.54 | 10,228 | 成功 |
- 10GBファイル
| ライブラリ | 実行時間(秒) | メモリ使用量(MB) | 結果 |
|---|---|---|---|
| AWS Data Wrangler | - | - | 未実施 |
| DuckDB | 192.06 | 1,708 | 成功 |
| Polars | - | - | 未実施 |
- 30GBファイル
| ライブラリ | 実行時間(秒) | メモリ使用量(MB) | 結果 |
|---|---|---|---|
| AWS Data Wrangler | - | - | 未実施 |
| DuckDB | 651.20 | 2,990 | 成功 |
| Polars | - | - | 未実施 |
※: OOMはOutOfMemory
-
処理速度比較
- 小規模ファイル (100MB): DuckDBとPolarsが同等で、AWS Data Wranglerより約4倍高速
- 中規模ファイル (1GB): DuckDBとPolarsが同等で、AWS Data Wranglerより約4倍高速
- 大規模ファイル (3GB-6GB): PolarsがDuckDBより高速
-
メモリ効率比較
- 小規模ファイル (100MB): Polarsが最も効率的、DuckDBが最も消費量が多い(差は小さい)
- 中規模ファイル (1GB): DuckDBが最も効率的、AWS Data Wranglerは3倍以上のメモリを使用
- 大規模ファイル (3GB-6GB): DuckDBが最も効率的
-
用途
- AWS Data Wrangler: 他ライブラリでは連携していないAWSサービスとの連携で使用。(ただし大規模ファイルには不向き)
- Polars: 処理速度重視する時に選択。(ただしPolarsのDataFrameの記法の学習コストはある)
- DuckDB: メモリ効率を重視する時に選択。Downloadせずメモリを消費しない分、他と比較してメモリ効率が良い。30GBファイルも処理可能でした。SQL記法で実装を簡単にできる。(ただし大規模処理になるとPolarsよりも速度面で劣る可能性もある)
今回の単純なCSV → Parquet処理においての比較ですので、もっと複雑な処理だった場合や、パフォーマンスの良い実装をした場合は結果が変わってくるかもしれないので、あくまで一例として参考にしていただければと思います。DuckDBは分析クエリ向けに最適化されているので、今回のように全てstringではなく数値データも含まれている場合だと、DuckDBの方が速いケースもあるかと思います。
実装
今回の実装コードについては、Github上に格納してあるのでご確認いただければと思います。
@ 53_duckdb_awswrangler_polars % tree
.
├── README.md
├── cdk
│ ├── bin
│ │ └── app.ts
│ ├── cdk.json
│ ├── jest.config.js
│ ├── layers
│ │ ├── duckdb
│ │ │ └── requirements.txt
│ │ └── polars
│ │ └── requirements.txt
│ ├── lib
│ │ └── lambda-stack.ts
│ ├── package-lock.json
│ ├── package.json
│ └── tsconfig.json
├── make_test_data
│ ├── create_db.sql
│ ├── create_test_csv.py
│ ├── large_sample.sql
│ ├── medium_sample.sql
│ ├── sample_1gb.sql
│ └── small_sample.sql
└── resources
└── lambda
├── aws_wrangler_test.py
├── duckdb_test.py
└── polars_test.py
10 directories, 19 files
app.ts
#!/usr/bin/env node
import * as cdk from "aws-cdk-lib";
import { LambdaStack } from "../lib/lambda-stack";
const app = new cdk.App();
new LambdaStack(app, `CmKasamaLambdaStack`, {
description: `CmKasamaLambdaStack`,
env: {
account: process.env.CDK_DEFAULT_ACCOUNT,
region: process.env.CDK_DEFAULT_REGION,
},
tags: {
Repository: `CmKasamaLambdaStack-test-tag`,
},
projectName: "cm-kasama",
envName: "dev",
});
app.tsではLambdaStackを呼び出しています。
duckdb
polars
fsspec
s3fs
layersではduckdbとpolarsで使用するライブラリを定義しています。
lambda-stack.ts
import { Construct } from "constructs";
import * as cdk from "aws-cdk-lib";
import * as lambda from "aws-cdk-lib/aws-lambda";
import * as iam from "aws-cdk-lib/aws-iam";
import * as path from "path";
import { PythonLayerVersion } from "@aws-cdk/aws-lambda-python-alpha";
export interface LambdaStackProps extends cdk.StackProps {
envName: string;
projectName: string;
}
export class LambdaStack extends cdk.Stack {
constructor(scope: Construct, id: string, props: LambdaStackProps) {
super(scope, id, props);
const lambdaRole = new iam.Role(this, "LambdaExecutionRole", {
assumedBy: new iam.ServicePrincipal("lambda.amazonaws.com"),
managedPolicies: [
iam.ManagedPolicy.fromAwsManagedPolicyName(
"service-role/AWSLambdaBasicExecutionRole",
),
iam.ManagedPolicy.fromAwsManagedPolicyName("AmazonS3FullAccess"),
],
});
const awswranglerLambdaName = `${props.projectName}-${props.envName}-awswrangler-handler`;
const duckdbLambdaName = `${props.projectName}-${props.envName}-duckdb-handler`;
const polarsLambdaName = `${props.projectName}-${props.envName}-polars-handler`;
const source_bucket = "<your_source_bucket>";
const filename = "medium_sample";
const source_key = `src/${filename}.csv`;
const destination_bucket = "<your_destination_bucket>";
const destination_key = `target/${filename}/${filename}.parquet`;
const duckdbLayer = new PythonLayerVersion(this, "DuckdbLayer", {
entry: path.join(__dirname, "../layers/duckdb"),
compatibleRuntimes: [lambda.Runtime.PYTHON_3_13],
compatibleArchitectures: [lambda.Architecture.ARM_64],
description: "Layer containing DuckDB",
layerVersionName: `${props.projectName}-${props.envName}-duckdb-layer`,
bundling: {
assetHashType: cdk.AssetHashType.SOURCE,
outputPathSuffix: "python",
},
});
const polarsLayer = new PythonLayerVersion(this, "PolarsLayer", {
entry: path.join(__dirname, "../layers/polars"),
compatibleRuntimes: [lambda.Runtime.PYTHON_3_13],
compatibleArchitectures: [lambda.Architecture.ARM_64],
description: "Layer containing Polars",
layerVersionName: `${props.projectName}-${props.envName}-polars-layer`,
bundling: {
assetHashType: cdk.AssetHashType.SOURCE,
outputPathSuffix: "python",
},
});
new lambda.Function(this, "AwswranglerLambda", {
functionName: awswranglerLambdaName,
runtime: lambda.Runtime.PYTHON_3_13,
code: lambda.Code.fromAsset("../resources/lambda"),
handler: "aws_wrangler_test.lambda_handler",
memorySize: 10240,
ephemeralStorageSize: cdk.Size.gibibytes(10),
timeout: cdk.Duration.seconds(900),
role: lambdaRole,
layers: [
lambda.LayerVersion.fromLayerVersionArn(
this,
"AwsSdkPandasLayer",
"arn:aws:lambda:ap-northeast-1:336392948345:layer:AWSSDKPandas-Python313-Arm64:1",
),
],
environment: {
source_bucket: source_bucket,
source_key: source_key,
destination_bucket: destination_bucket,
destination_key: destination_key,
},
architecture: lambda.Architecture.ARM_64,
});
new lambda.Function(this, "DuckdbLambda", {
functionName: duckdbLambdaName,
runtime: lambda.Runtime.PYTHON_3_13,
code: lambda.Code.fromAsset("../resources/lambda"),
handler: "duckdb_test.lambda_handler",
memorySize: 10240,
ephemeralStorageSize: cdk.Size.gibibytes(10),
timeout: cdk.Duration.seconds(900),
role: lambdaRole,
layers: [duckdbLayer],
environment: {
source_bucket: source_bucket,
source_key: source_key,
destination_bucket: destination_bucket,
destination_key: destination_key,
},
architecture: lambda.Architecture.ARM_64,
});
new lambda.Function(this, "polarsLambda", {
functionName: polarsLambdaName,
runtime: lambda.Runtime.PYTHON_3_13,
code: lambda.Code.fromAsset("../resources/lambda"),
handler: "polars_test.lambda_handler",
memorySize: 10240,
ephemeralStorageSize: cdk.Size.gibibytes(10),
timeout: cdk.Duration.seconds(900),
role: lambdaRole,
layers: [polarsLayer],
environment: {
source_bucket: source_bucket,
source_key: source_key,
destination_bucket: destination_bucket,
destination_key: destination_key,
},
architecture: lambda.Architecture.ARM_64,
});
}
}
lambda-stack.tsではLambda関数とlayerを定義しています。Lambdaの基本的な設定値は全て以下としています。それ以外は、それぞれのライブラリを使用するためのLayerを設定しています。
- Runtime: PYTHON_3_13
- Architecture: ARM_64
- memorySize: 10240
- ephemeralStorageSize: 10240
- timeout: 900
aws_wrangler_test.py
import os
import time
import json
import awswrangler as wr
def lambda_handler(event, context):
start_time = time.time()
# S3バケット情報を取得
source_bucket = os.environ.get("source_bucket")
source_key = os.environ.get("source_key")
destination_bucket = os.environ.get("destination_bucket")
destination_key = os.environ.get("destination_key")
source_path = f"s3://{source_bucket}/{source_key}"
destination_path = f"s3://{destination_bucket}/{destination_key}"
try:
# 処理開始をログ出力
print(f"処理開始: {source_key}")
# AWS Data Wranglerを使用してCSVを直接読み込み、Parquetとして保存
df = wr.s3.read_csv(source_path)
wr.s3.to_parquet(
df=df,
path=destination_path,
compression="snappy", # 圧縮方式を明示的に指定
)
execution_time = time.time() - start_time
print(f"処理完了: 実行時間 {execution_time:.2f}秒")
return {
"statusCode": 200,
"body": json.dumps(
{
"message": "CSV to Parquet conversion completed successfully with AWS Data Wrangler",
"execution_time": execution_time,
"source": source_path,
"destination": destination_path,
}
),
}
except Exception as e:
print(f"エラー発生: {str(e)}")
raise e
AWS SDK for PandasをテストするLambda関数の実装です。S3のCSVデータを読み込んでParquetに変換し、再度S3にUploadする処理です。
duckdb_test.py
import os
import time
import json
import duckdb
def lambda_handler(event, context):
start_time = time.time()
# S3バケット情報を取得
source_bucket = os.environ.get("source_bucket")
source_key = os.environ.get("source_key")
destination_bucket = os.environ.get("destination_bucket")
destination_key = os.environ.get("destination_key")
source_path = f"s3://{source_bucket}/{source_key}"
destination_path = f"s3://{destination_bucket}/{destination_key}"
try:
# 処理開始をログ出力
print(f"処理開始: {source_key}")
# DuckDBを使用してCSVをParquetに変換(S3から直接読み込み、S3に直接書き込み)
con = duckdb.connect(database=":memory:")
con.execute("SET home_directory='/tmp'") # Lambdaの一時ディレクトリに設定
# httpfs拡張をインストールしてロード
con.execute("INSTALL httpfs;")
con.execute("LOAD httpfs;")
# CSVをParquetに変換(圧縮指定あり)
con.execute(f"""
COPY (SELECT * FROM read_csv_auto('{source_path}', parallel=True))
TO '{destination_path}' (FORMAT PARQUET, COMPRESSION 'SNAPPY');
""")
con.close()
execution_time = time.time() - start_time
print(f"処理完了: 実行時間 {execution_time:.2f}秒")
return {
"statusCode": 200,
"body": json.dumps(
{
"message": "CSV to Parquet conversion completed successfully with DuckDB",
"execution_time": execution_time,
"source": source_path,
"destination": destination_path,
}
),
}
except Exception as e:
print(f"エラー発生: {str(e)}")
raise e
DuckDBをテストするLambda関数の実装です。COPYコマンドでParquetに変換し、S3にUploadする処理です。
polars_test.py
import os
import time
import json
import polars as pl
def lambda_handler(event, context):
start_time = time.time()
# 専用のサブディレクトリを作成し、適切な権限を設定
tmp_dir = "/tmp/polars_cache"
# 環境変数を設定
os.environ["POLARS_TEMP_DIR"] = tmp_dir
# S3バケット情報を取得
source_bucket = os.environ.get("source_bucket")
source_key = os.environ.get("source_key")
destination_bucket = os.environ.get("destination_bucket")
destination_key = os.environ.get("destination_key")
source_path = f"s3://{source_bucket}/{source_key}"
destination_path = f"s3://{destination_bucket}/{destination_key}"
try:
# 処理開始をログ出力
print(f"処理開始: {source_key}")
# S3から直接CSVをスキャン
df_lazy = pl.scan_csv(source_path, rechunk=True, low_memory=True)
# S3に直接Parquetとして保存
df_lazy.sink_parquet(destination_path, compression="snappy")
execution_time = time.time() - start_time
print(f"処理完了: 実行時間 {execution_time:.2f}秒")
return {
"statusCode": 200,
"body": json.dumps(
{
"message": "CSV to Parquet conversion completed successfully with Polars LazyFrame",
"execution_time": execution_time,
"source": source_path,
"destination": destination_path,
}
),
}
except Exception as e:
print(f"エラー発生: {str(e)}")
return {"statusCode": 500, "body": json.dumps({"error": str(e)})}
PolarsをテストするLambda関数の実装です。S3のCSVデータをscanしてParquetに変換し、S3にUploadする処理です。デフォルトのDataFrameだと3GBファイルよりOut of memoryが発生するため、LazyFrameを使用します。LazyFrameを使用すると、ストリーミングを使用してメモリよりも大きなデータセットを操作できます。
create_test_csv.py
import pandas as pd
import random
import os
import sys
def create_sample_csv(filename="sample_data.csv", rows=1000000):
"""
より一般的な文字列データを含むCSVファイルを作成する関数
Parameters:
filename (str): 作成するCSVファイルの名前
rows (int): 行数
"""
print(f"{rows}行のデータを生成中...")
# 会社名のサンプル
companies = [
"Acme Corp",
"Globex",
"Initech",
"Umbrella Corp",
"Stark Industries",
"Wayne Enterprises",
"Cyberdyne Systems",
"Soylent Corp",
"Massive Dynamic",
"Weyland-Yutani",
"Oscorp",
"Gekko & Co",
"Wonka Industries",
"Duff Brewing",
]
# 製品カテゴリ
categories = [
"Electronics",
"Clothing",
"Food",
"Home Goods",
"Office Supplies",
"Sporting Goods",
"Toys",
"Books",
"Health",
"Automotive",
]
# 国名
countries = [
"USA",
"Canada",
"UK",
"Germany",
"France",
"Japan",
"China",
"Australia",
"Brazil",
"India",
"Mexico",
"Spain",
"Italy",
"Russia",
]
# 都市名
cities = [
"New York",
"London",
"Tokyo",
"Paris",
"Berlin",
"Sydney",
"Toronto",
"Shanghai",
"Mumbai",
"Rio de Janeiro",
"Mexico City",
"Madrid",
"Rome",
"Moscow",
]
# メールドメイン
email_domains = [
"gmail.com",
"yahoo.com",
"hotmail.com",
"outlook.com",
"company.com",
"example.org",
"business.net",
"mail.co",
"webmail.info",
"protonmail.com",
]
# ランダムデータの生成
data = {
"customer_id": [f"CUST-{random.randint(10000, 99999)}" for _ in range(rows)],
"full_name": [
f"{random.choice(['John', 'Jane', 'Robert', 'Mary', 'David', 'Sarah', 'Michael', 'Lisa', 'James', 'Emily'])} {random.choice(['Smith', 'Johnson', 'Williams', 'Jones', 'Brown', 'Davis', 'Miller', 'Wilson', 'Moore', 'Taylor', 'Anderson', 'Thomas', 'Jackson', 'White'])}"
for _ in range(rows)
],
"email": [
f"user{random.randint(100, 999)}@{random.choice(email_domains)}"
for _ in range(rows)
],
"phone": [
f"+{random.randint(1, 9)}-{random.randint(100, 999)}-{random.randint(100, 999)}-{random.randint(1000, 9999)}"
for _ in range(rows)
],
"company": [random.choice(companies) for _ in range(rows)],
"purchase_amount": [
f"${random.randint(10, 1000)}.{random.randint(0, 99):02d}"
for _ in range(rows)
],
"category": [random.choice(categories) for _ in range(rows)],
"country": [random.choice(countries) for _ in range(rows)],
"city": [random.choice(cities) for _ in range(rows)],
"status": [
random.choice(["Completed", "Pending", "Cancelled", "Refunded", "Shipped"])
for _ in range(rows)
],
}
# DataFrameの作成
df = pd.DataFrame(data)
# CSVに保存
df.to_csv(filename, index=False)
# ファイルサイズの確認
file_size = os.path.getsize(filename) / (1024 * 1024) # MBに変換
print(f"ファイル '{filename}' の作成が完了しました。")
print(f"行数: {rows}、列数: {len(df.columns)}")
print(f"ファイルサイズ: {file_size:.2f} MB")
return filename
if __name__ == "__main__":
if len(sys.argv) < 3:
print("使用方法: python create_sample_data.py <ファイル名> <行数>")
sys.exit(1)
filename = sys.argv[1]
rows = int(sys.argv[2])
create_sample_csv(filename, rows)
今回の検証用のsampleデータを作成する実装です。このコードをlocalで実行し、テストデータをS3にuploadして検証しています。
テストデータ準備
今回使用するテストデータの準備を行います。テストデータはファイルサイズごとに作るのでそれぞれのコマンドを実行し、S3 Bucketに格納します。S3 Bucketは手動で作成したものを使用しています。
pandasを使用するのでinstallします。
pip install pandas
それぞれのファイルサイズとなるようにコマンドを実行し、S3へUploadします。
cd make_test_data
# 100MBのファイル
python create_test_csv.py small_sample.csv 922000
aws s3 mv small_sample.csv s3://<YOUR_S3_BUCKET>/src/ --profile <YOUR_AWS_PROFILE>
# 1GBのファイル
python test.py 1gb_sample.csv 9443000
aws s3 mv 1gb_sample.csv s3://<YOUR_S3_BUCKET>/src/ --profile <YOUR_AWS_PROFILE>
# 3GBのファイル
python create_test_csv.py medium_sample.csv 28300000
aws s3 mv medium_sample.csv s3://<YOUR_S3_BUCKET>/src/ --profile <YOUR_AWS_PROFILE>
# 6GBのファイル
python create_test_csv.py large_sample.csv 56600000
aws s3 mv large_sample.csv s3://<YOUR_S3_BUCKET>/src/ --profile <YOUR_AWS_PROFILE>
デプロイ
それではCDKでのデプロイ作業を実施します。
package.jsonがあるディレクトリで依存関係をインストールします。
npm install
次にcdk.jsonがあるディレクトリで、CDKで定義されたリソースのコードをAWS CloudFormationテンプレートに合成(変換)するプロセスを実行します。
npx cdk synth --profile <YOUR_AWS_PROFILE>
同じくcdk.jsonがあるディレクトリでデプロイコマンドを実行します。--allはCDKアプリケーションに含まれる全てのスタックをデプロイするためのオプション、--require-approval neverはセキュリティ的に敏感な変更やIAMリソースの変更を含むデプロイメント時の承認を求めるダイアログ表示を完全にスキップします。neverは、どんな変更でも事前確認なしにデプロイすることを意味します。今回は検証用なので指定していますが、慎重にデプロイする場合は必要のないオプションになるかもしれません。
npx cdk deploy --all --require-approval never --profile <YOUR_AWS_PROFILE>
検証
前提として、Lambdaのコールドスタートで実行時間にブレがあることを避けるために、同じLambdaを2回実行して、2回目の処理で計測したいと思います。計測する観点は実行時間とメモリ使用量です。
100MBファイル
まずは100MBファイルで実行してみたいと思います。
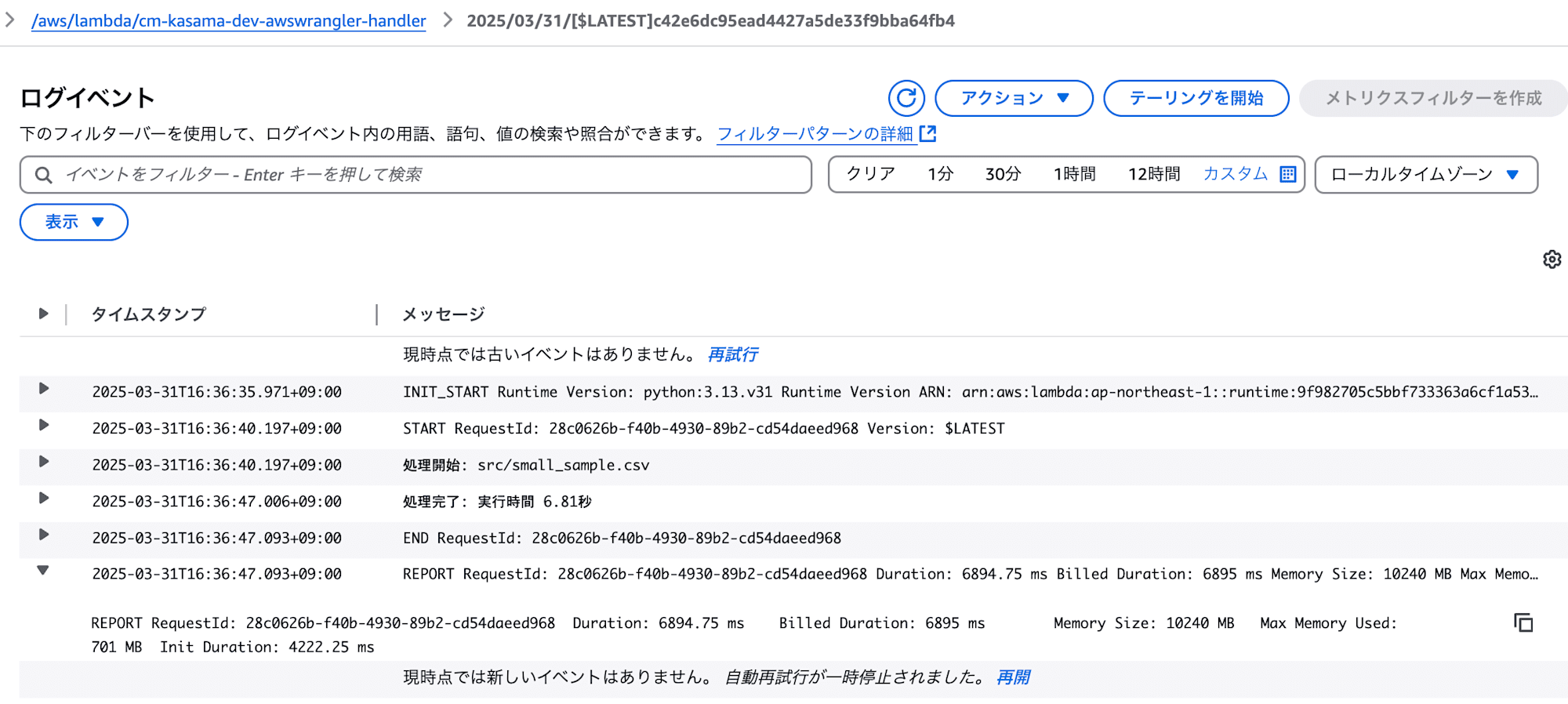
- AWS SDK for Pandas (AWS Data Wrangler)
処理は正常に終了しました。
実行時間: 6.81秒
メモリ使用量: 701 MB
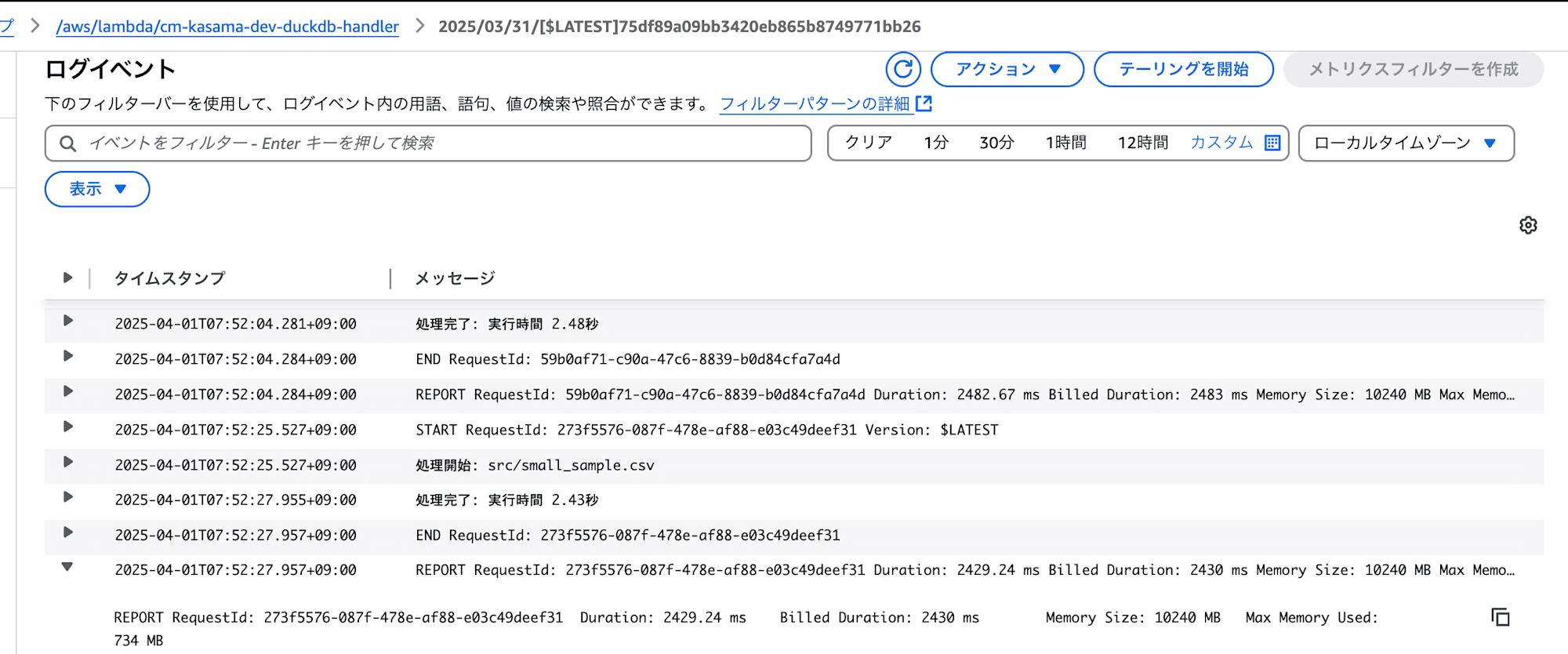
- DuckDB
処理は正常に終了しました。
実行時間: 2.43秒
メモリ使用量: 734 MB
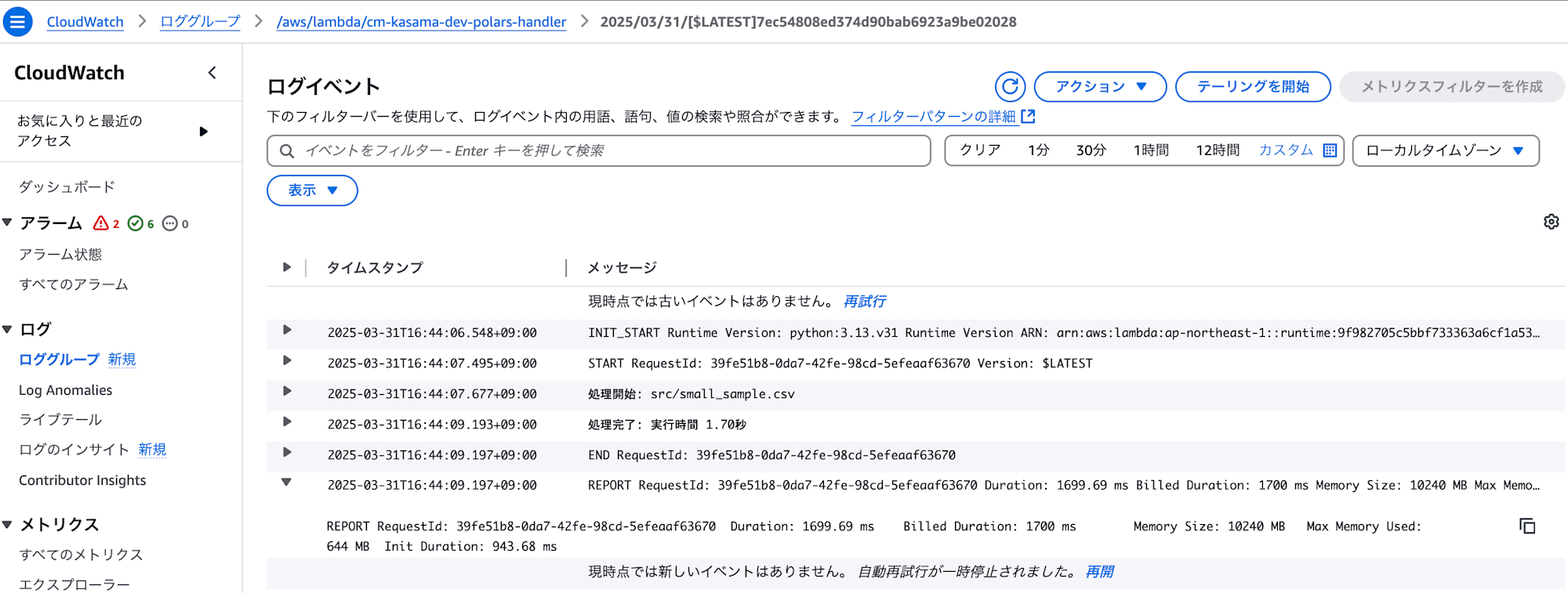
- Polars
処理は正常に終了しました。
実行時間: 1.70秒
メモリ使用量: 644 MB
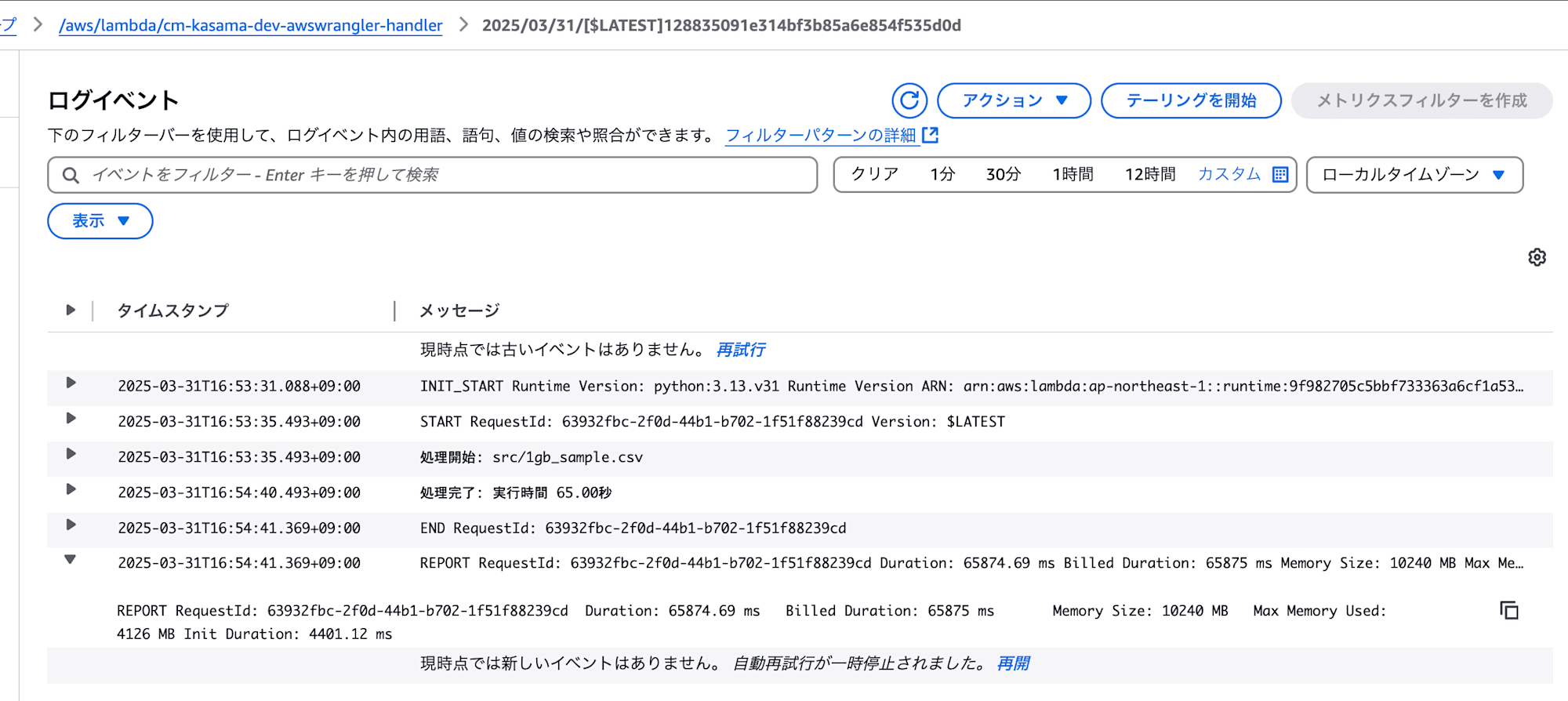
1GBファイル
次は1GBファイルで実行してみたいと思います。
- AWS SDK for Pandas (AWS Data Wrangler)
処理は正常に終了しました。
実行時間: 65.00秒
メモリ使用量: 4126 MB
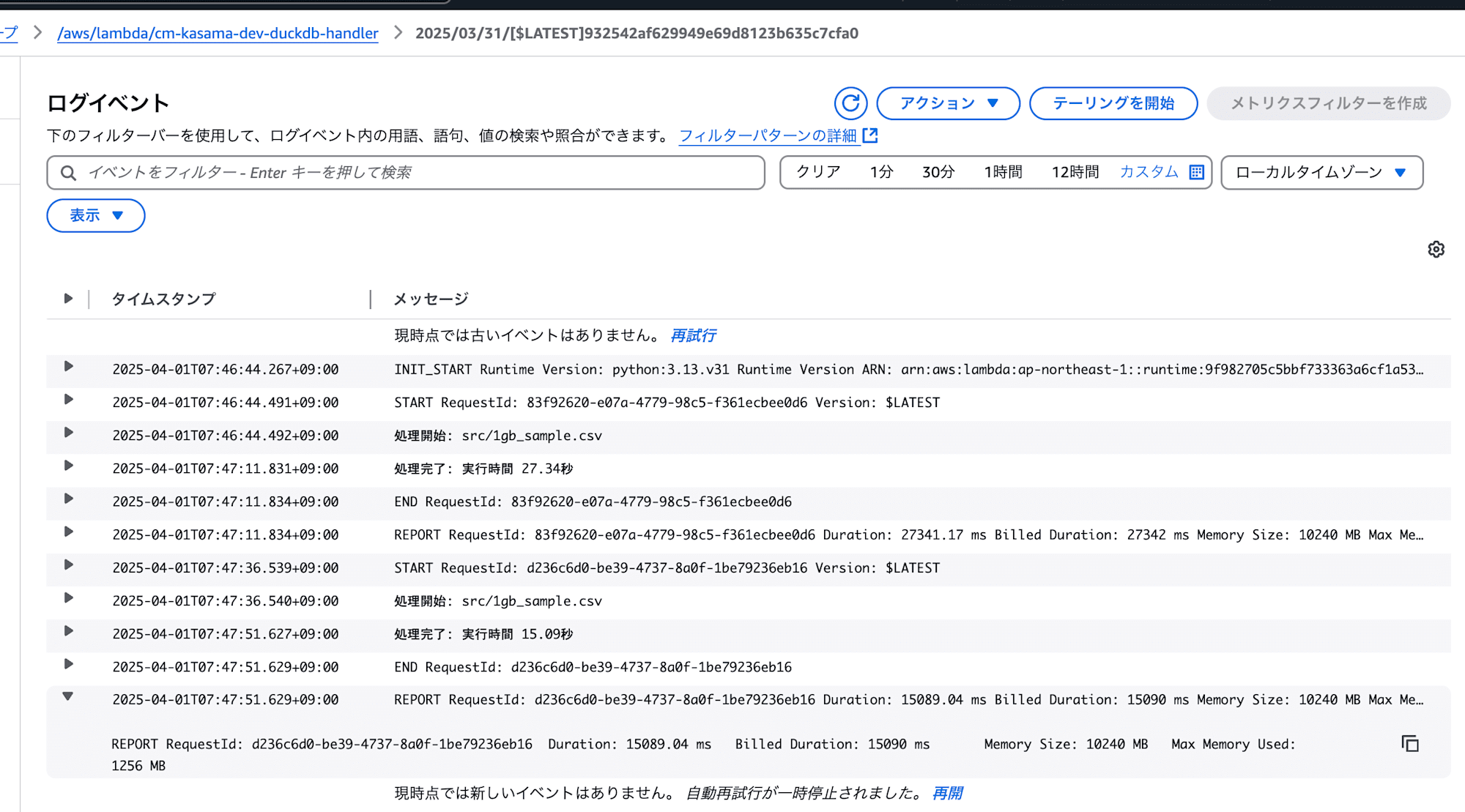
- DuckDB
処理は正常に終了しました。
実行時間: 15.09秒
メモリ使用量: 1256 MB
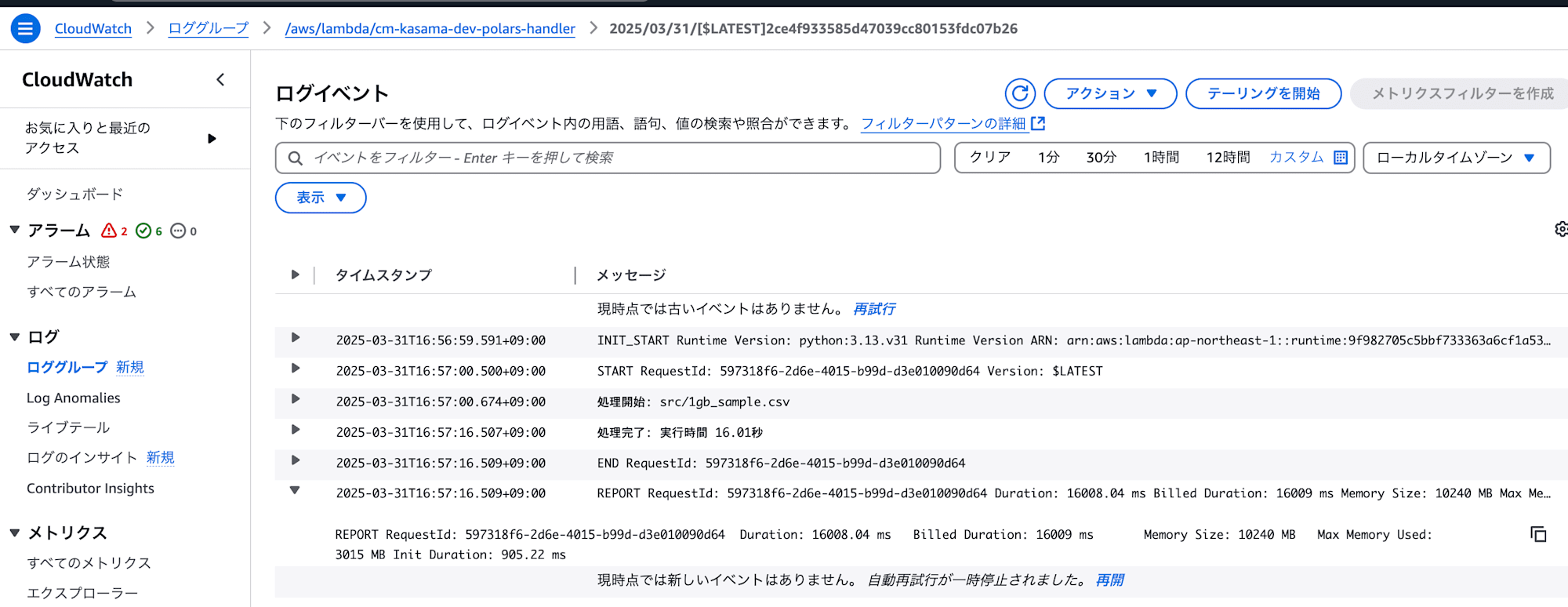
- Polars
処理は正常に終了しました。
実行時間: 16.01秒
メモリ使用量: 3015 MB
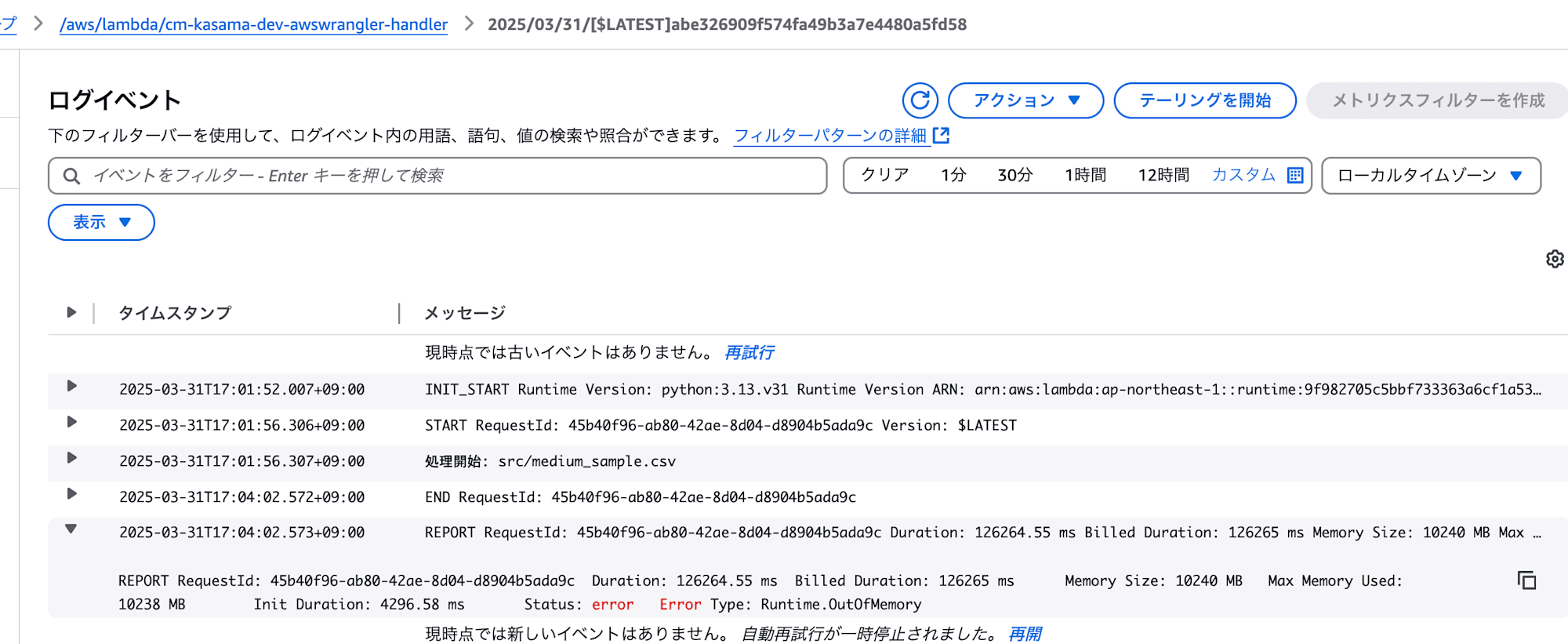
3GBファイル
次は3GBファイルで実行してみたいと思います。
- AWS SDK for Pandas (AWS Data Wrangler)
処理はOutOfMemoryで失敗しました。
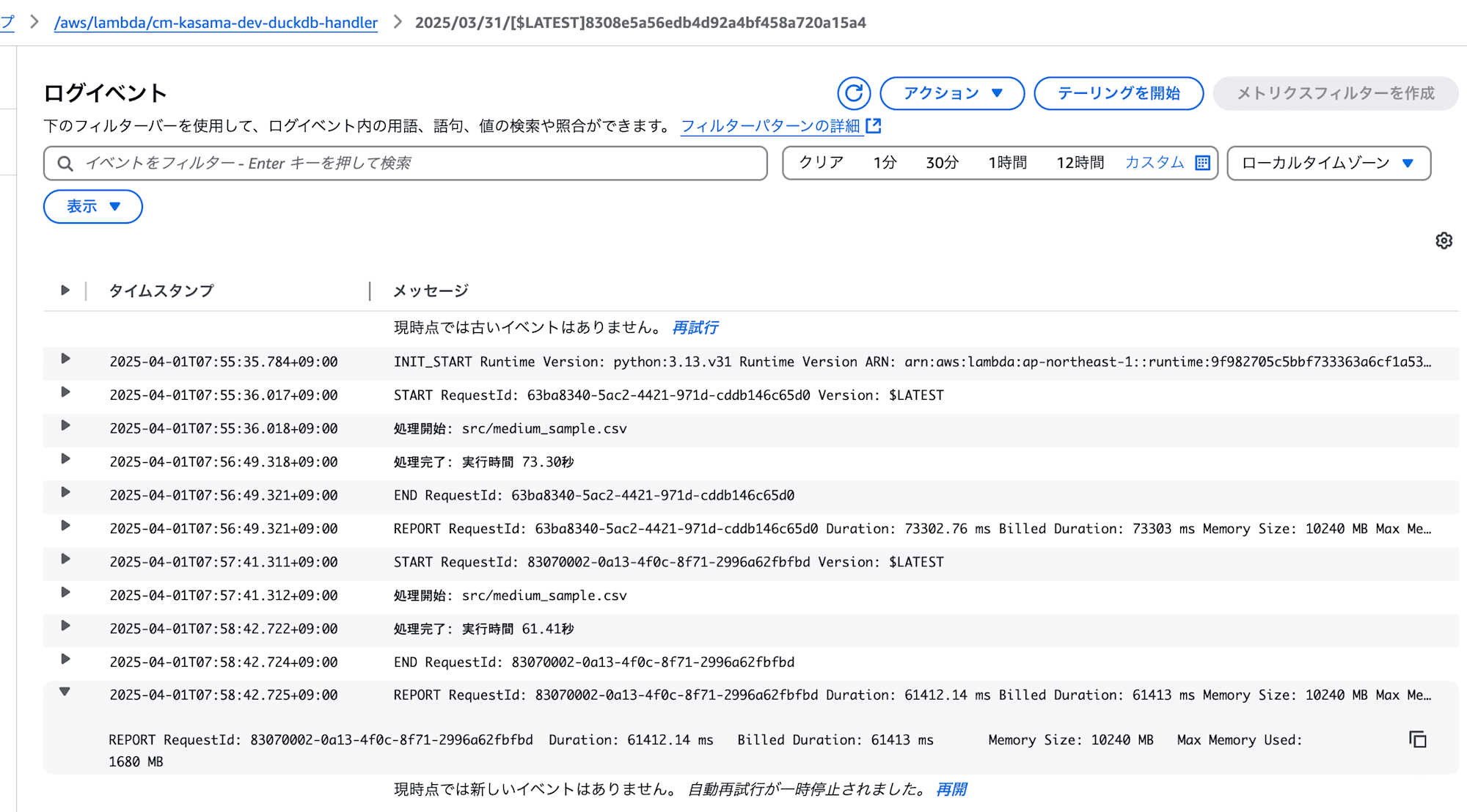
- DuckDB
処理は正常に終了しました。
実行時間: 61.41秒
メモリ使用量: 1680 MB
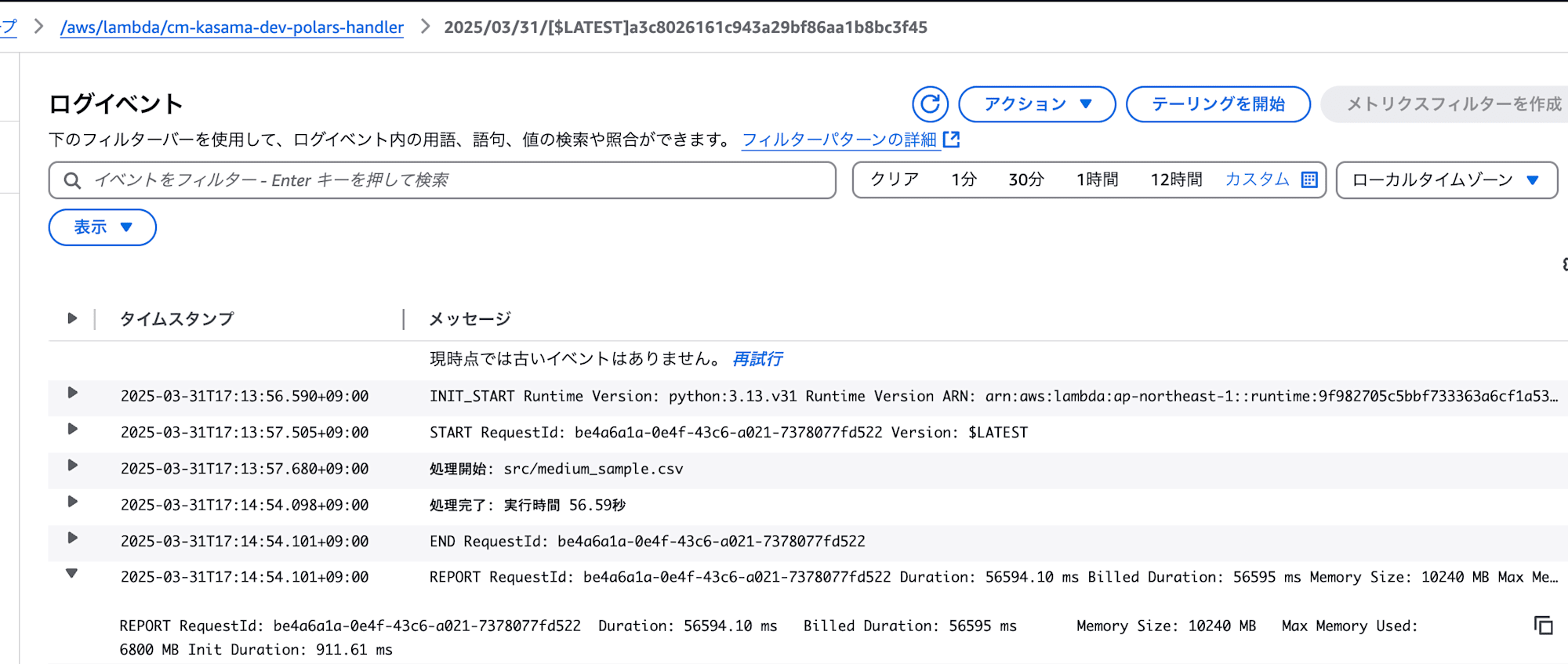
- Polars
処理は正常に終了しました。
実行時間: 56.59秒
メモリ使用量: 6800 MB
6GBファイル
最後に6GBファイルで実行してみたいと思います。
AWS SDK for Pandas (AWS Data Wrangler)は3GBで失敗したので、スキップします。
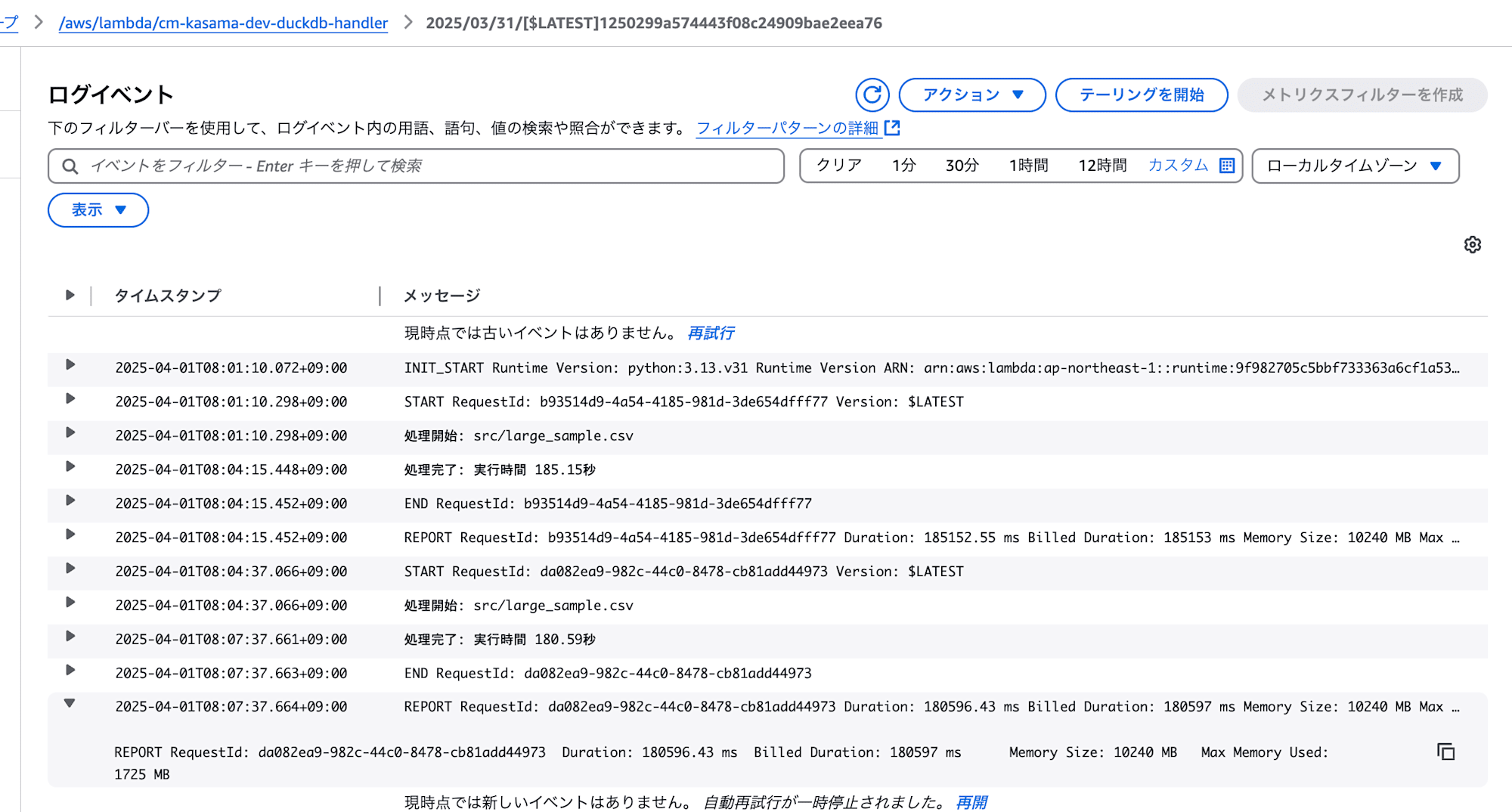
- DuckDB
処理は正常に終了しました。
実行時間: 180.59秒
メモリ使用量: 1725 MB
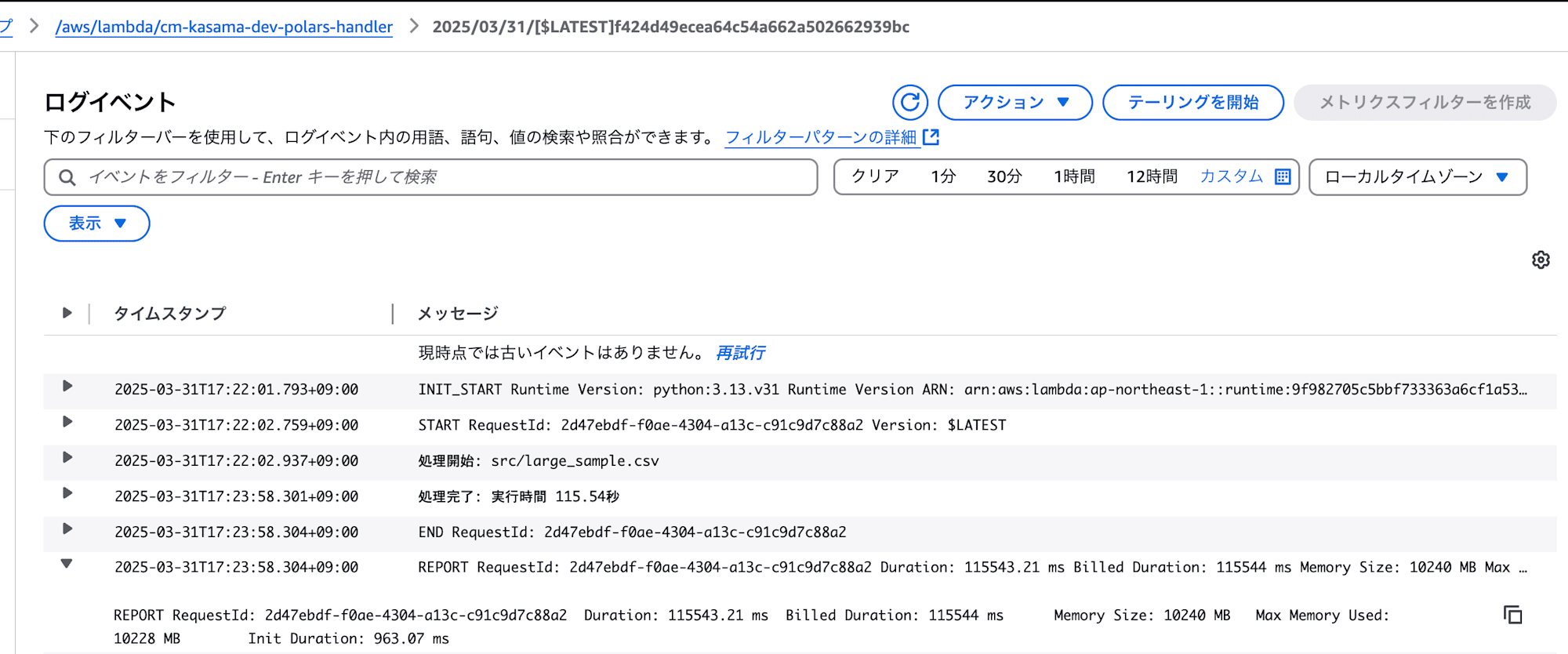
- Polars
処理は正常に終了しました。
実行時間: 115.54秒
メモリ使用量: 10228 MB
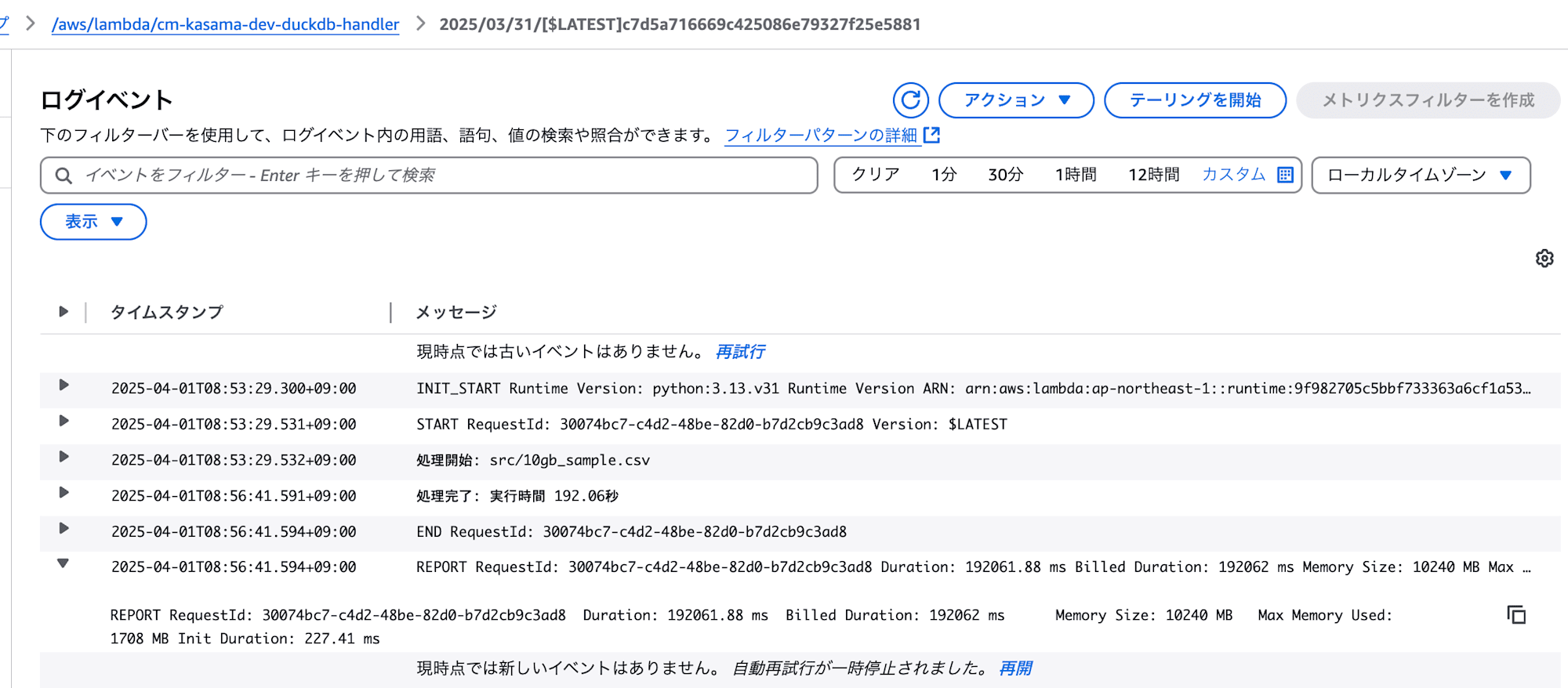
10GBファイル
- DuckDB
処理は正常に終了しました。
実行時間: 192.06秒
メモリ使用量: 1708 MB
30GBファイル
どこまでいけるのか試してみたく30GBファイルで実行しました。
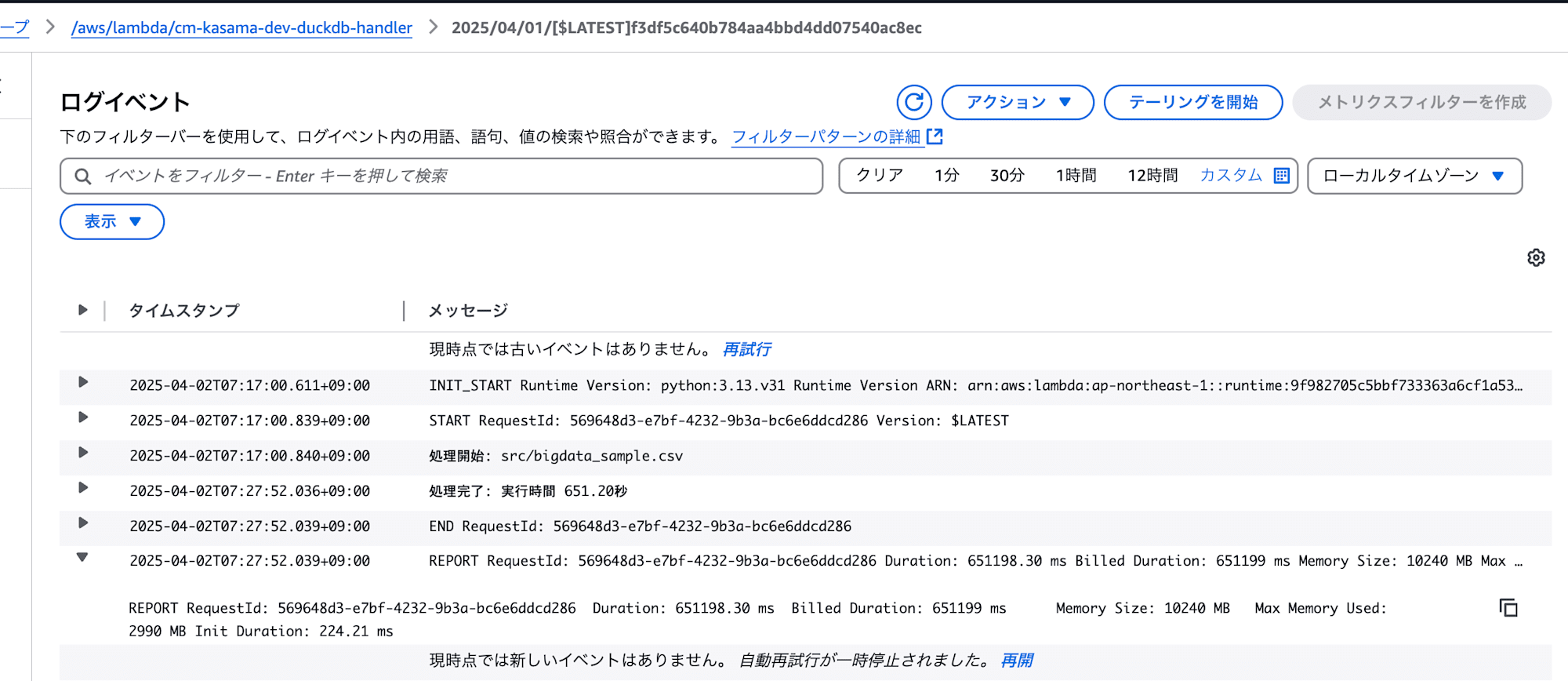
- DuckDB
処理は正常に終了しました。
実行時間: 651.20秒 (10分 51.20秒)
メモリ使用量: 2990 MB
このデータサイズになると実行時間がLambdaの最大15分に引っかかる気になりますが、メモリは大丈夫ですね。
なぜLambdaで30GBファイルでもDuckDBなら処理できたのか
DuckDBが10GBのLambdaメモリ制限を超える30GBファイルを処理できる主な理由は、以下の特性が影響しているからだと考えています。
- ストリーミング実行エンジン
- 部分的なデータ処理: DuckDBは、データをチャンク単位で処理するストリーミング実行エンジンです。データソース(CSVやParquetファイルなど)を完全にメモリに読み込まず、一度に小さなチャンクだけを処理します。
- 自動マルチスレッド処理: 複数のデータストリームを並列に処理し、効率を高めます。
- 例えば、30GBのCSVファイルから集計を計算する場合、DuckDBはファイル全体をメモリに読み込むことなく、小さな部分ごとに読み込んで処理します。
- 中間結果のディスクスピリング
- 適応的なディスクスピリング: より複雑なクエリでは、中間結果がメモリ制限を超える可能性があります。DuckDBはメモリ使用量が制限を超えると、中間結果を一時的にディスクに書き出すことで、メモリ内に可能な限り多くのデータを保持します。これにより、利用可能なメモリよりも大きな中間結果を必要とする複雑なクエリでも処理が可能になります。
- カラムナーベクトル化クエリ実行
- ベクトル化処理: 一度に多くの値を「ベクトル」として処理します。
- カラム指向ストレージ: DuckDBの実行エンジンは特にOLAP向けに最適化されています。必要なカラムだけを読み込み、不要なデータの転送を避けます。
- 効率的なクエリ最適化: フィルタや射影のプッシュダウンなどの最適化を自動的に適用します。
- インメモリ処理と組み込み設計
- インプロセス実行: DuckDBはインメモリ処理を活用した組み込み型データベースとして設計されています。アプリケーションと同じメモリ空間内で動作し、プロセス間通信のオーバーヘッドがありません
これらの特性が組み合わさることで、DuckDBはLambdaの10GBメモリ制限内でも30GBの大規模ファイルを効率的に処理できます。
最後に
個人的には、DuckDBがこんなに簡単に実装できてメモリ性能が良いことに驚きました。Polarsも処理速度が速いことを知れてとても学びになりました。









