ドキュメントファイルの解析と変換に特化したオープンソースツール「docling」を試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
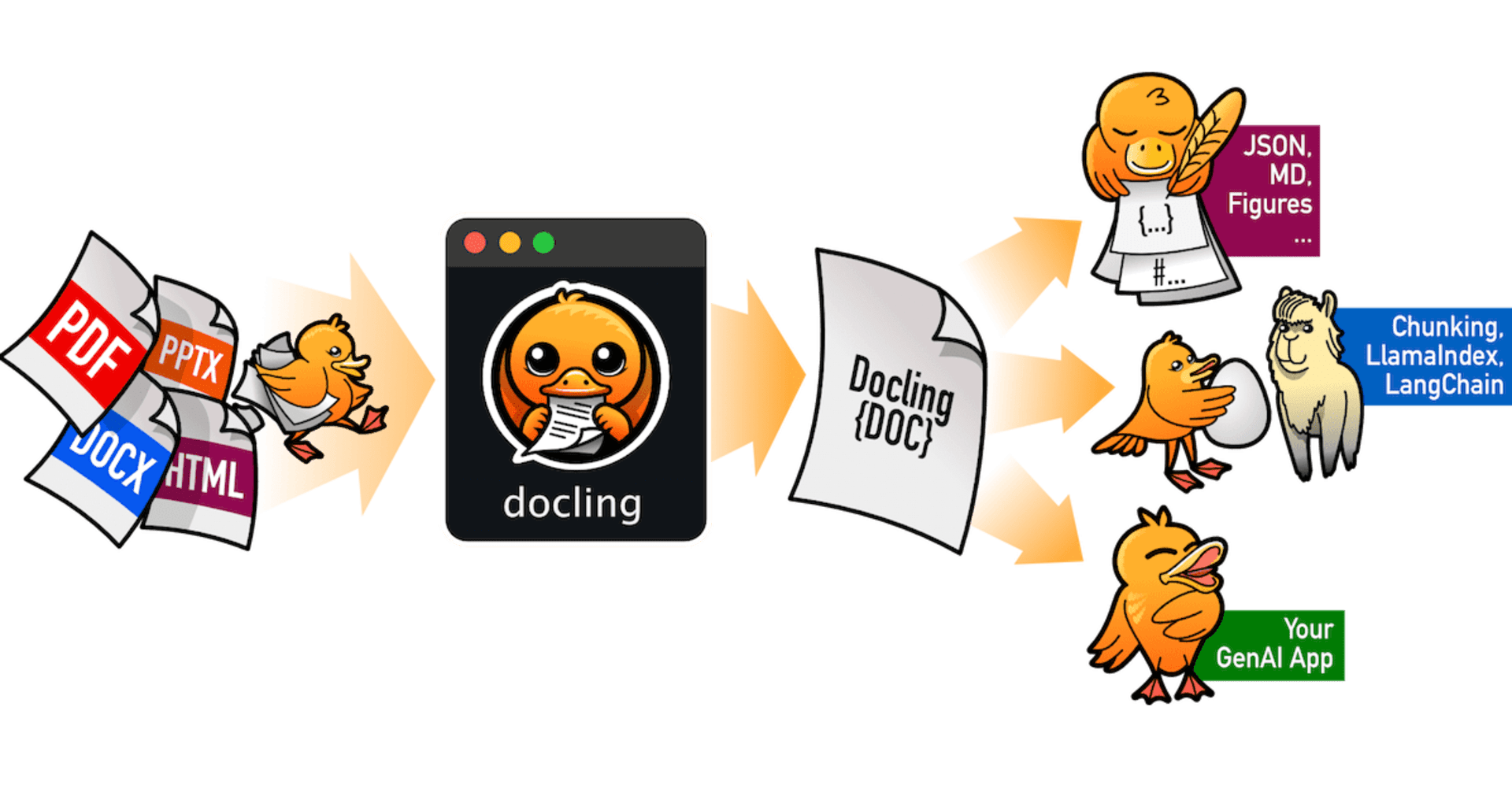
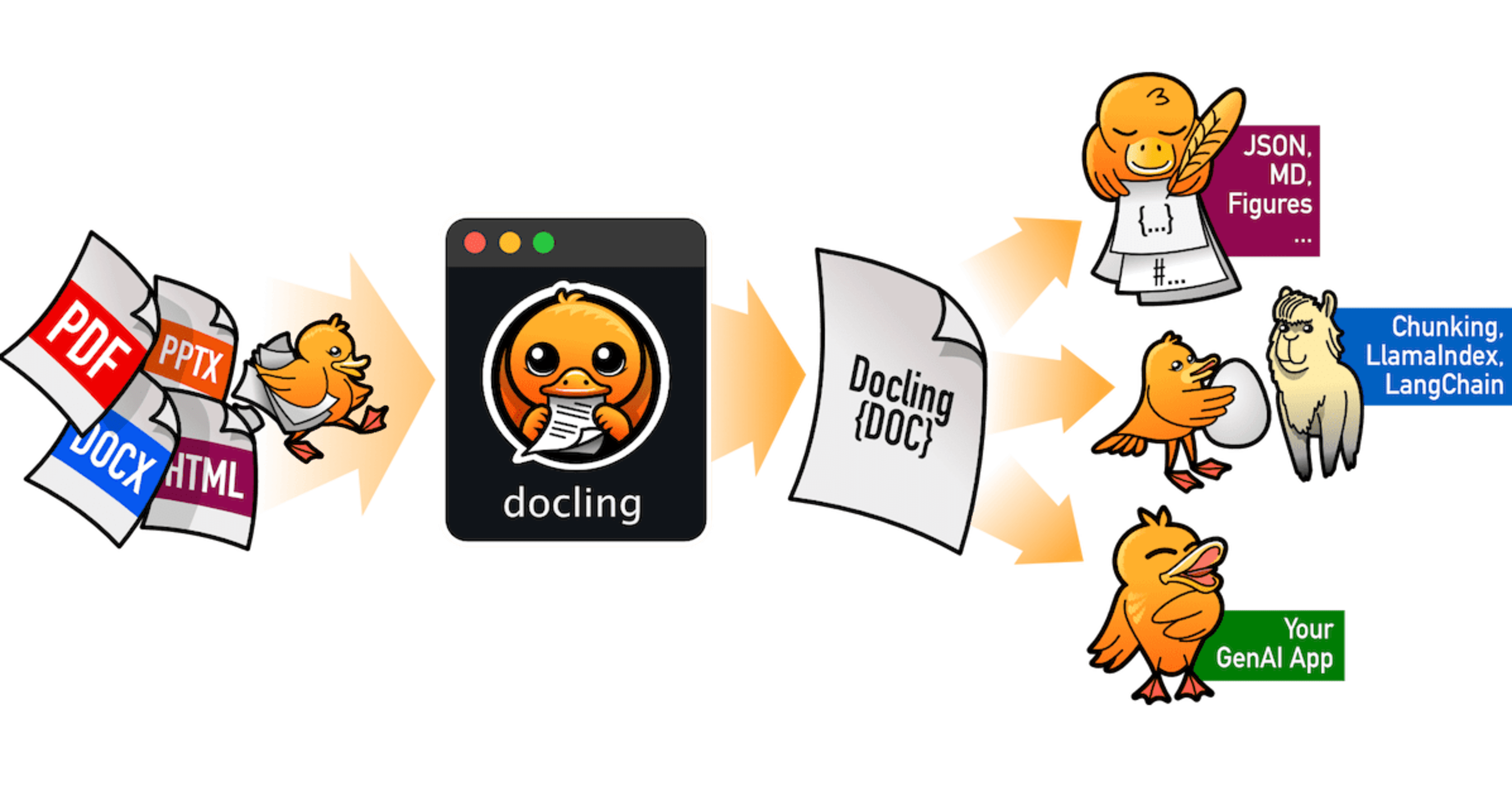
AWS事業本部コンサルティング部の石川です。最近、文書ファイルの解析と変換に特化した オープンソースツール「docling」 が注目を集めています。このツールは、最先端のAIモデルを活用して、ドキュメントの構造を理解し、様々な形式に変換することができます。今回、実際にdoclingを使用して日本語のドキュメントファイルからMarkdownファイルとJSONファイルへ変換を試してみます。
doclingとは
doclingは、ドキュメントの変換と解析に特化したオープンソースのPythonパッケージです。最先端の人工知能モデルを活用し、レイアウト解析にDocLayNetモデル、表構造認識にTableFormerモデルを使用しています。一般的なハードウェアで効率的に動作し、少ないリソースで高性能を発揮します。JSONやMarkdown形式への変換が可能で、拡張性も高く、新機能やモデルの追加が容易な設計となっています。
- 一般的なドキュメント形式(PDF、DOCX、PPTX、画像、HTML、AsciiDoc、Markdown)を読み取り、MarkdownおよびJSONにエクスポートします
- ページレイアウト、読み取り順序、表構造を含む高度な PDF ドキュメントの理解
- 統一された表現力豊かなDoclingDocument表現形式
- タイトル、著者、参考文献、言語などのメタデータ抽出
- 強力な RAG / QA アプリケーションのためのシームレスな LlamaIndexと LangChain の統合
- スキャンしたPDFのOCRサポート
- シンプルで便利なCLI
技術的には、doclingは線形のパイプラインを実装しており、各ドキュメントに対して順次処理を行います。まずPDFバックエンドでテキストトークンと座標を抽出し、ページのビットマップ画像をレンダリングします。次に、AIモデルを使用してレイアウトや表構造などの特徴を抽出します。最後に、結果を集約してポストプロセスを行い、メタデータの補強や言語検出、読み取り順序の推論を行います。処理は72 dpiの解像度で行われています。最終的に、構造化されたデータ型に変換され、JSONやMarkdownとして出力されます。
doclingのインストール
Pythonパッケージのdoclingをインストールします。doclingのバージョンは、2.3.1、Pythonのバージョンは 3.10.11です。
% pip install docling
Collecting docling
Downloading docling-2.3.1-py3-none-any.whl.metadata (6.0 kB)
Requirement already satisfied: beautifulsoup4<5.0.0,>=4.12.3 in ./.pyenv/versions/3.10.11/lib/python3.10/site-packages (from docling) (4.12.3)
Collecting certifi>=2024.7.4 (from docling)
Downloading certifi-2024.8.30-py3-none-any.whl.metadata (2.2 kB)
Collecting deepsearch-glm<0.27.0,>=0.26.1 (from docling)
Downloading deepsearch_glm-0.26.1-cp310-cp310-macosx_14_0_arm64.whl.metadata (10
:
:
:
Successfully installed Shapely-2.0.6 XlsxWriter-3.2.0 certifi-2024.8.30 deepsearch-glm-0.26.1 docling-2.3.1 docling-core-2.3.1 docling-ibm-models-2.0.3 docling-parse-2.0.2 docutils-0.21.2 easyocr-1.7.2 filetype-1.2.0 imageio-2.36.0 jsonlines-3.1.0 jsonref-1.1.0 lazy-loader-0.4 lxml-4.9.4 marko-2.1.2 mean_average_precision-2021.4.26.0 ninja-1.11.1.1 opencv-python-headless-4.10.0.84 pillow-10.4.0 pyarrow-16.1.0 pyclipper-1.3.0.post6 pydantic-settings-2.6.1 pypdfium2-4.30.0 python-bidi-0.6.3 python-docx-1.1.2 python-pptx-1.0.2 requests-2.32.3 rtree-1.3.0 scikit-image-0.24.0 scipy-1.14.1 shellingham-1.5.4 sympy-1.13.1 tabulate-0.9.0 tifffile-2024.9.20 torch-2.5.1 torchvision-0.20.1 typer-0.12.5
% docling --version
Docling version: 2.3.1
Docling Core version: 2.3.1
Docling IBM Models version: 2.0.3
Docling Parse version: 2.0.2
% python --version
Python 3.10.11
doclingコマンドによるPDFの変換
doclingコマンドのオプション
% docling
Usage: docling [OPTIONS] source
╭─ Arguments ──────────────────────────────────────────────────────────────────╮
│ * input_sources source PDF files to convert. Can be local file / │
│ directory paths or URL. │
│ [default: None] │
│ [required] │
╰──────────────────────────────────────────────────────────────────────────────╯
╭─ Options ────────────────────────────────────────────────────────────────────╮
│ --from [docx|pptx|html|i Specify input │
│ mage|pdf|asciidoc formats to │
│ |md] convert from. │
│ Defaults to all │
│ formats. │
│ [default: None] │
│ --to [md|json|text|doc Specify output │
│ tags] formats. Defaults │
│ to Markdown. │
│ [default: None] │
│ --ocr --no-ocr If enabled, the │
│ bitmap content │
│ will be processed │
│ using OCR. │
│ [default: ocr] │
│ --ocr-engine [easyocr|tesserac The OCR engine to │
│ t_cli|tesseract] use. │
│ [default: │
│ easyocr] │
│ --abort-on-error --no-abort-on-e… If enabled, the │
│ bitmap content │
│ will be processed │
│ using OCR. │
│ [default: │
│ no-abort-on-erro… │
│ --output PATH Output directory │
│ where results are │
│ saved. │
│ [default: .] │
│ --version Show version │
│ information. │
│ --help Show this message │
│ and exit. │
╰──────────────────────────────────────────────────────────────────────────────╯
doclingコマンドの実行例
変換元のファイルと変換したいドキュメントのフォーマットを--toオプションで指定します。出力ファイルは、拡張子を.mdに変更して出力されます。また、変換元のファイルのドキュメントフォーマットは、拡張子ではなくファイルの中身から自動認識をされるようです。
% docling --to md openai-whisper-large-v3-turbo-faster-whisper.pdf
INFO:docling.document_converter:Going to convert document batch...
Fetching 9 files: 100%|███████████████████████| 9/9 [00:00<00:00, 138273.76it/s]
INFO:docling.pipeline.base_pipeline:Processing document openai-whisper-large-v3-turbo-faster-whisper.pdf
INFO:docling.document_converter:Finished converting document openai-whisper-large-v3-turbo-faster-whisper.pdf in 10.52 sec.
INFO:docling.cli.main:writing Markdown output to openai-whisper-large-v3-turbo-faster-whisper.md
INFO:docling.cli.main:Processed 1 docs, of which 0 failed
INFO:docling.cli.main:All documents were converted in 10.52 seconds.
% ll openai-whisper-large-v3-turbo-faster-whisper.md
-rw-r--r--@ 1 ishikawa.satoru staff 24245 11 4 17:57 openai-whisper-large-v3-turbo-faster-whisper.md
なお、初回の実行時は設定やモデルなどダウンロードするため、5分ほど待たされました。プログレスがあまり進まないのですが、初回の実行は気長にお待ち下さい。
config.json: 100%|██████| 41.0/41.0 [00:00<00:00, 91.3kB/s]
(…)artifacts/tableformer/fat/tm_config.json: 100%|██████| 7.09k/7.09k [00:00<00:00, 3.72MB/s]
.gitignore: 100%|██████| 5.18k/5.18k [00:00<00:00, 12.6MB/s]
README.md: 100%|██████| 3.49k/3.49k [00:00<00:00, 26.6MB/s]
.gitattributes: 100%|██████| 1.71k/1.71k [00:00<00:00, 11.8MB/s]
(…)del_artifacts/tableformer/tm_config.json: 100%|██████| 7.09k/7.09k [00:00<00:00, 16.3MB/s]
otslp_all_fast.check: 100%|██████| 146M/146M [00:14<00:00, 10.0MB/s]
model.pt: 100%|██████| 202M/202M [00:21<00:00, 9.56MB/s]
otslp_all_standard_094_clean.check: 100%|██████| 213M/213M [00:21<00:00, 9.78MB/s]
Fetching 9 files: 100%|██████| 9/9 [00:22<00:00, 2.49s/it]
Downloading detection model, please wait. This may take several minutes depending upon your network connection.██████| 202M/202M [00:21<00:00, 10.3MB/s]
Progress: |██████| 100.0% CompleteDownloading recognition model, please wait. This may take several minutes depending upon your network connection.
Progress: |██████| 100.0% CompleteTraceback (most recent call last):
プログラムからdoclingを実行する方法
他のシステムとの連携や自動化など考慮し、プログラムからdoclingを実行する方法も解説します。
ドキュメントファイルを変換するプログラム
このプログラムは変換したいファイルパスを指定してプログラムを実行すると、MarkdownファイルとJSONファイルを出力するプログラムです。
DocumentConverterのインスタンス(converter)を作成し、converterインスタンスを用いてドキュメントファイルを変換します。変換結果(result)からMarkdownやJSONに変換し、ファイル出力します。
from docling.document_converter import DocumentConverter
import json
import sys
import os
# 引数がない場合のエラーチェック
if len(sys.argv) < 2:
print("エラー: 変換元ファイルが指定されていません。")
sys.exit(1)
# ドキュメントのファイルのパスを指定
file_path = sys.argv[1]
file_name = os.path.basename(file_path)
file_name_without_extension = os.path.splitext(file_name)[0]
# DocumentConverterのインスタンスを作成
converter = DocumentConverter()
# ドキュメントファイルを変換
result = converter.convert(file_path)
# Markdownに変換
markdown_output = result.document.export_to_markdown()
# JSONに変換(dict形式で取得してからJSONに変換)
json_output = json.dumps(result.document.export_to_dict(), ensure_ascii=False, indent=2)
# Markdownをファイルに保存
markdown_file_name = "output_" + file_name_without_extension + ".md"
with open(markdown_file_name, "w", encoding="utf-8") as md_file:
md_file.write(markdown_output)
# JSONをファイルに保存
json_file_name = "output-" + file_name_without_extension + ".json"
with open(json_file_name, "w", encoding="utf-8") as json_file:
json_file.write(json_output)
print("変換が完了しました。")
print("Markdown出力: " + markdown_file_name)
print("JSON出力: " + json_file_name)
変換するプログラムの実行例
実行結果は、以下のようになります。
% python playground_docling.py openai-whisper-large-v3-turbo-faster-whisper.pdf
Fetching 9 files: 100%|█████████████████████████████████████| 9/9 [00:00<00:00, 81180.08it/s]
変換が完了しました。
Markdown出力: output_openai-whisper-large-v3-turbo-faster-whisper.md
JSON出力: output-openai-whisper-large-v3-turbo-faster-whisper.json
処理時間: 10.77502秒
% ll output*
-rw-r--r--@ 1 ishikawa.satoru staff 151036 11 4 19:01 output-openai-whisper-large-v3-turbo-faster-whisper.json
-rw-r--r--@ 1 ishikawa.satoru staff 24245 11 4 19:01 output_openai-whisper-large-v3-turbo-faster-whisper.md
検証では、上記のプログラムを用いてドキュメントファイルの変換の結果を確認します。
補足: Doclingが出力するJSONファイル
ドキュメントファイル(PDF、PowerPoint、WORD、MarkDown等)はヒューマンリーダブルなフォーマットであるのに対して、JSONファイルはマシンリーダブルなフォーマットです。
Doclingが出力するJSONファイルは、文書管理システム、検索エンジン、データ分析プラットフォーム、そしてAIを活用したアプリケーション連携など、幅広い用途で活用できる強力なツールとなります。
データの構造化と標準化
Doclingは、PDFやDOCXなどの文書を解析し、その内容を構造化されたJSONフォーマットで出力します。機械可読性の向上させて、文書の内容を自動的に処理・分析することが可能になります。また、異なる形式の文書でも、同じJSONスキーマで表現されることで、一貫した方法でデータを扱えるようになります。
文書理解と情報抽出
Doclingは最先端のAIモデルを使用して、文書の構造や内容を深く理解し、ページレイアウトや読み取り順序などの構造化情報としてを保存します。また、タイトル、著者、参考文献、言語などのメタデータを抽出します。
柔軟なデータ利用
JSONフォーマットでデータを出力することで、異なるシステム間でのデータ交換が容易になり、RAG/QAアプリケーションやLlamaIndexやLangChainなどのフレームワークと簡単に統合でき、強力な検索や質問応答システムの構築が可能になります。
様々な日本語ドキュメントを試してみる
英語のドキュメントはともかく、実際に日本語のドキュメントではどうか気になるところです。そこで、様々なフォーマットの日本語ドキュメントに対して動作を確認してみます。
PDF ファイルの変換例
内閣府の「AI戦略の課題と対応」 というPowerPointのファイルをPDFに変換したファイルで検証します。
AI事業者ガイドライン(第1.0版)
変換の実行
変換は、16ページのPDF ファイルは、約19秒かかりました。
% python playground_docling.py shiryo1-1.pdf
Fetching 9 files: 100%|█████████████████████████████████████| 9/9 [00:00<00:00, 74455.10it/s]
変換が完了しました。
Markdown出力: output_shiryo1-1.md
JSON出力: output-shiryo1-1.json
処理時間: 19.18724秒
変換前のファイル(AI戦略の課題と対応の2ページ目)
ドキュメントファイルは、以下のとおりです。
変換後のMarkdownファイル
Markdownファイルは、以下のとおりです。2ページ目に着目しますと、PDFファイル内の文字列は概ね文字情報として取得できました。イメージファイルは、<!-- image -->と出力されています。

Microsoft PowerPoint ファイルの変換例
**デジタル庁の「AI時代の官民データの整備・連携に向けた アクションプラン」**というPowerPointのファイルで検証します。
変換の実行
変換は、14ページのPowerPoint ファイル(.pptx)は、約0.1秒とかなり早く終わりました。
% python playground_docling.py 20231220_meeting_digital-system-reform_outline_04.pptx
変換が完了しました。
Markdown出力: output_20231220_meeting_digital-system-reform_outline_04.md
JSON出力: output-20231220_meeting_digital-system-reform_outline_04.json
処理時間: 0.11165秒
変換前のファイル(AI時代の官民データの整備・連携に向けた アクションプランの2ページ目)
ドキュメントファイルは、以下のとおりです。フォーマットや色調からいわゆる某コンサル会社フォーマットです。

変換後のMarkdownファイル
Markdownファイルは、以下のとおりです。2ページ目に着目しますと、PowerPointファイル内の文字列は概ね文字情報として取得できました。イメージファイルは、<!-- image -->と出力されています。ブロックごとのドキュメントの構造は取得できましたが、ブロックの前後関係はうまく取得できないようです。PowerPointというよりは、階層的にドキュメントを作成していないため構造が取れていないということも考えられます。

Microsoft Word ファイルの変換例
総務省の個人情報保護に関する「保有個人情報開示請求書」というWORDファイルで検証します。
変換の実行
変換は、4ページのWORDファイル(.docx)は、約0.03秒とかなり早く終わりました。ページ数が少ないこともあります。
% python playground_docling.py 000619588.docx
変換が完了しました。
Markdown出力: output_000619588.md
JSON出力: output-000619588.json
処理時間: 0.03036秒
変換前のファイル(保有個人情報開示請求書)
ドキュメントファイルは、以下のとおりです。1〜2ページはいかにもWORDというフォーマットです。

変換後のMarkdownファイル
Markdownファイルは、以下のとおりです。WORDファイル内の文字列は概ね文字情報として取得できました。ドキュメントの構造はうまく取得できない点もありますが、順序が正しく人が読んでも理解できる内容と言えるでしょう。本来は、画像なども埋め込み検証したかったのですが、検証の公平性を担保するため、あえてを公文書を選んでいるため変更を加えることができませんでした。

論文のPDFファイルの変換例
論文はとても重要な情報源ですが、段組みや段組みを無視して図表が入ったり、読み取る難易度が高いフォーマットでもあります。
国立情報学研究所の「大規模な日本語モデル構築・共有のためのプラットフォームの形成」 という 相澤彰子さんが書かれたのPDFファイルの論文を検証します。
変換の実行
変換は、5ページのPDFファイルは、約8秒で終わりました。
% python playground_docling.py jh231006-final.pdf
Fetching 9 files: 100%|█████████████████████████████████████| 9/9 [00:00<00:00, 89877.94it/s]
変換が完了しました。
Markdown出力: output_jh231006-final.md
JSON出力: output-jh231006-final.json
処理時間: 8.33283秒
変換前のファイル(大規模な日本語モデル構築・共有のためのプラットフォームの形成)
ドキュメントファイルは、以下のとおりです。ページをまたいだときに文章が右下から次のページの右上になるのかが確認のポイントです。

変換後のMarkdownファイル
Markdownファイルは、以下のとおりです。論文のPDFファイル内の文字列は概ね文字情報として取得できました。しかし、ドキュメントの構造はうまく取得できず、ページをまたいだときに文章が右下から次のページの右上につながっていませんでした。
また、一部文字化けではありませんが、「BERT をベ-スにしたエンコ- ダ-系のモデル」のように長音符がハイフンに書き換えられたり、右上の「*
今回、別の英語の論文で検証した際、ページをまたいだときに文章が右下から次のページの右上につながっていたので、日本語でもうまくつながることを期待していましたが残念です。また、数式のΣなどは、Texとも異なるエンコードされた状態で出力されたことを確認しています。

最後に
文書ファイルの解析と変換に特化したオープンソースツール「docling」について詳しく紹介しました。doclingは最先端のAIモデルを活用し、PDFの構造を理解して様々な形式に変換する能力を持っています。実際に日本語のPDF、PowerPoint、Word文書、そして論文PDFを用いて変換を試みた結果、文字情報の抽出においては概ね期待通りの結果が得られました。一方、複雑なレイアウトを持つPowerPointや論文PDFの変換では、文書構造の再現に課題が残ることも明らかになりました。特に、ページをまたぐ文章の連続性や、数式、画像の扱いについては改善の余地があることがわかりました。
PDFを変換は、他に比べて時間がかかりました。また、実行時に下記のメッセージが出力されたことから、単なるフォーマット変換ではなく、ページのレンダリングやモデルを用いた推論しているからでしょう。
Fetching 9 files: 100%|█████████████████████████████████████| 9/9 [00:00<00:00, 74455.10it/s]
日本語においては、課題が残るdoclingですが、文書管理システムや検索エンジン、データ分析プラットフォーム、AIアプリケーションなど、幅広い用途での活用が期待できるツールです。今後の更なる開発と改善により、日本語文書の処理精度が向上し、より多くのシーンで活用されることが期待されます。
参考文献