
C++の音声エフェクト高速化 - オブジェクト指向プログラミングとSIMDをアセンブリで検証
はじめに
C++ で音声エフェクトを実装する際、拡張しやすさを優先して virtual を使った設計にすると、書き方次第で処理が想像以上に遅くなることがあります。本記事では、同じ処理を「サンプル単位」「ブロック単位 (自動ベクタ化あり) 」「ブロック単位 (手書き AVX2) 」の 3 系統で比較し、さらに 測定結果が想定と逆転した理由 を、MSVC の自動ベクタ化レポートとアセンブリ出力 (.cod) で確認します。音声処理の実装において、設計を保ったまま速くするために、どこを疑い、どう裏取りすべきか、そして、どの最適化が実際に効いているかを整理します。
背景
実務の音声処理では、複数のエフェクトをチェーンとして適用する場面が多く、要件としては次の両方が求められます。
- エフェクトの追加や差し替えが容易であること (保守性、拡張性)
- リアルタイム処理として十分に高速であること (レイテンシ、CPU 使用率)
このとき、オブジェクト指向プログラミング (以下、OOP) と SIMD 最適化は、相性が良い場合もあれば、実装の形によっては噛み合わない場合もあります。本記事は、その現象がどこで発生しているかを、測定ログと生成コードで切り分けることを目的にしています。
SIMD とは
SIMD は同じ演算を複数のデータにまとめて実行する仕組みで、float 配列のような連続データに対する乗算・min/max 等で効果が出やすい最適化です (過去の解説記事) 。C++ では、コンパイラがループを自動的に SIMD 化する場合と、AVX2 などの命令を開発者が明示的に記述する場合があります。
対象読者
- C++ で簡単な DSP (gain/clip など) を書いたことがある方
- サンプル単位処理とブロック処理の概念は理解しているが、最適化の裏取りには自信がない方
- 「手書き SIMD (AVX2) を書けば速いはず」と考えているが、実測で裏切られた経験がある方
参考
- FA, /Fa (Listing file)
- loop pragma (no_vector / ivdep など)
- Vectorizer and parallelizer messages (C5001/C5002 と理由コード)
- Avoiding AVX-SSE Transition Penalties (Intel資料)
OOP と SIMD が噛み合う条件
virtual が内側ループにあることの問題
SIMD が得意なのは、同じ計算を、連続した配列要素に対して繰り返す形です。一方で、サンプルごとに fx->processSample(x) のような virtual 呼び出しが入ると、ループ内部に間接呼び出しが入りやすく、コンパイラはループを単純な形として扱いにくくなります。
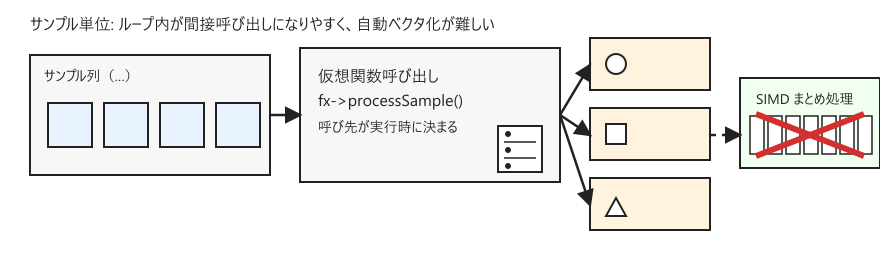
サンプル単位ではなく、たとえば 512 サンプル単位のブロックで処理すると、virtual はブロックごとになり、配列を走査する内側ループは素直な for になりやすくなります。この形は、コンパイラの自動ベクタ化が効く可能性が高く、OOP と SIMD の両立の出発点になります。

検証環境
- CPU: Intel(R) Core(TM) i7-11700F @ 2.50GHz
- コンパイラ: MSVC v143 (VS 2022 C++ x64/x86 ビルドツール)
- 言語モード: C++ 17
- ビルド構成: ReleaseAsm x64
コンパイル設定は、最適化を有効化しつつ、生成コードの裏取りができるように調整しました。
- 最適化:
/O2,/Ob2,/Oi,/Ot
- 命令セット:
/arch:AVX2 - 出力:
/FAcs(ソース相当情報+機械語付き listing)
ターゲットはサンプルコードの形なので、CPU の世代や細かいオプションによって絶対値は変わります。ここでは、あくまでパターン間の相対的な傾向を確認します。
実験条件
- サンプルレート: 48kHz
- ブロックサイズ: 512
- 総サンプル数: 10,240,000 (512 × 20,000)
- エフェクト数: 8 (gain と clip を交互に適用)
- 計測: 同一条件で複数回実行し、最速値を採用
- ノイズ低減: スレッド優先度の引き上げと CPU コア固定
また、後述の裏取りのため、MSVC の /FAcs により .cod を出力しています。
検証1: A/B/C を測ったところ想定外の結果が出た
下記の 3 パターンで検証を行い、実行速度を測定しました。
A: サンプルごとに virtual を呼ぶ
サンプル単位の processSample() を、サンプルごとに 8 回呼び出す構成です。OOP としては拡張しやすい一方で、内側ループに virtual が入り、コンパイラが SIMD 化しにくい形になります。
sample-virtual サンプルコード (抜粋)
struct ISampleFx {
virtual ~ISampleFx() = default;
virtual float processSample(float x) noexcept = 0;
};
static BenchResult bench_sample_virtual(
const float* in, float* out, size_t nSamples, int chainLen, int repeats)
{
auto chain = make_sample_chain(chainLen);
for (int r = 0; r < repeats; ++r) {
float sum = 0.0f;
for (size_t i = 0; i < nSamples; ++i) {
float y = in[i];
for (auto& fx : chain) {
y = fx->processSample(y); // ← サンプルごとに virtual
}
out[i] = y;
sum += y;
}
// timing / best-of-N は省略
}
}
B: ブロックごとに virtual、ブロック内部は普通の for
virtual は「ブロックごと」の呼び出しに押し出し、ブロック内部は配列走査の単純な for になります。
block-virtual scalar サンプルコード (抜粋)
struct IBlockFx {
virtual ~IBlockFx() = default;
virtual void processBlock(const float* in, float* out, int n) noexcept = 0;
};
struct GainBlockScalar : IBlockFx {
float g;
explicit GainBlockScalar(float gain) : g(gain) {}
void processBlock(const float* in, float* out, int n) noexcept override {
for (int i = 0; i < n; ++i) {
out[i] = in[i] * g; // ← 素直なループ (自動ベクタ化の余地)
}
}
};
static BenchResult bench_block_virtual(
const float* in, float* out, size_t nSamples, int blockSize, int chainLen, /*...*/)
{
auto chain = make_block_chain(chainLen, /*useAvx2=*/false);
std::vector<float> scratchA(blockSize), scratchB(blockSize);
const size_t nBlocks = nSamples / (size_t)blockSize;
for (size_t b = 0; b < nBlocks; ++b) {
const float* curIn = in + b * (size_t)blockSize;
float* curOut = scratchA.data();
for (int i = 0; i < (int)chain.size(); ++i) {
chain[i]->processBlock(curIn, curOut, blockSize); // ← ブロックごとに virtual
curIn = curOut;
curOut = (curOut == scratchA.data()) ? scratchB.data() : scratchA.data();
}
// out へ書き出し (checksum の加算は省略)
}
}
C: ブロック内部を AVX2 intrinsics で手書き
B と同じく virtual はブロック境界に置き、ブロック内部は intrinsics で 8 要素ずつ処理します。本実装では loadu/storeu を使用し、アライメント前提を置かない形にしています。
block-virtual AVX2 サンプルコード (抜粋)
struct GainBlockAVX2 : IBlockFx {
float g;
explicit GainBlockAVX2(float gain) : g(gain) {}
void processBlock(const float* in, float* out, int n) noexcept override {
const __m256 vg = _mm256_set1_ps(g);
int i = 0;
for (; i + 8 <= n; i += 8) {
__m256 x = _mm256_loadu_ps(in + i);
__m256 y = _mm256_mul_ps(x, vg);
_mm256_storeu_ps(out + i, y);
}
for (; i < n; ++i) out[i] = in[i] * g; // tail
}
};
struct ClipBlockAVX2 : IBlockFx {
float lo, hi;
ClipBlockAVX2(float l, float h) : lo(l), hi(h) {}
void processBlock(const float* in, float* out, int n) noexcept override {
const __m256 vlo = _mm256_set1_ps(lo);
const __m256 vhi = _mm256_set1_ps(hi);
int i = 0;
for (; i + 8 <= n; i += 8) {
__m256 x = _mm256_loadu_ps(in + i);
x = _mm256_max_ps(x, vlo);
x = _mm256_min_ps(x, vhi);
_mm256_storeu_ps(out + i, x);
}
for (; i < n; ++i) { /* scalar tail */ }
}
};
結果は以下の通りです。
A) sample-virtual 83.016 ms 123.35 MSamples/s
B) block-virtual scalar 6.675 ms 1534.15 MSamples/s
C) block-virtual AVX2 8.327 ms 1229.79 MSamples/s
A → B は大幅に改善しており、virtual の置き場所を変える効果は明確に出ています (約 12.4 倍) 。一方、B → C は逆転し、手書き AVX2 が、B (ソース上は scalar) に負けています。この時点で、論点は「手書き SIMD が遅いかどうか」ではなく、「B が本当に scalar だったのか」 に移ります。
コンパイラレポートの調査
ビルドログでは、B 側 (GainBlockScalar / ClipBlockScalar) のループが loop vectorized (C5001) と判定されていました。これは B は実質的に SIMD 化されている 可能性を示唆します。一方、AVX2 実装側で一部 not vectorized (C5002) が混在しており、手書き SIMD を書いたからといって、コンパイラ最適化と常に噛み合うわけではないことも示唆されます。
ただし、レポートはあくまでヒントであり、結論にはできません。ここから先は .cod を観察し、実際に生成されている命令を確認します。
アセンブリの調査
GainBlockScalar は YMM 幅での乗算になっている
アセンブリの GainBlockScalar::processBlock を確認すると、係数をレジスタへ展開し、8 要素 (YMM) ずつ乗算している箇所が確認できます。以下は該当箇所の抜粋です。
; GainBlockScalar::processBlock (抜粋)
vbroadcastss ymm2, DWORD PTR [rcx+8]
...
vmulps ymm0, ymm2, YMMWORD PTR [rdi+rdx]
vmovups YMMWORD PTR [r8+rdx], ymm0
vmulps と YMMWORD PTR が現れているため、このループは少なくとも一部で 256-bit (float×8) 幅の SIMD として生成されています。つまり、ソースは scalar でも、生成コードは scalar ではありません。
ClipBlockScalar も YMM 幅での min/max になっている
同様に ClipBlockScalar::processBlock でも vmaxps / vminps が確認できます。
; ClipBlockScalar::processBlock (抜粋)
vmaxps ymm0, ymm3, YMMWORD PTR [r11+rax-32]
vminps ymm0, ymm4, ymm0
vmovups YMMWORD PTR [r11+rax-32], ymm0
ここまでで、検証1 における「B が C より速い」ことの原因について、「B が scalar 実装である」という前提が崩れている可能性が高い と推測できます。
検証2: no_vec で比較を成立させる
B’: 自動ベクタ化を意図的に無効化する
検証2 では、B の processBlock 内ループに #pragma loop(no_vector) を付け、コンパイラの自動ベクタ化を抑止します。これにより、B と C の比較が「scalar と手書き SIMD」の比較として成立しやすくなります。
block-virtual scalar(no_vec) サンプルコード (抜粋)
struct GainBlockScalarNoVec : IBlockFx {
float g;
explicit GainBlockScalarNoVec(float gain) : g(gain) {}
void processBlock(const float* in, float* out, int n) noexcept override {
#pragma loop(no_vector)
for (int i = 0; i < n; ++i) {
out[i] = in[i] * g;
}
}
};
struct ClipBlockScalarNoVec : IBlockFx {
float lo, hi;
ClipBlockScalarNoVec(float l, float h) : lo(l), hi(h) {}
void processBlock(const float* in, float* out, int n) noexcept override {
#pragma loop(no_vector)
for (int i = 0; i < n; ++i) {
float x = in[i];
if (x < lo) x = lo;
if (x > hi) x = hi;
out[i] = x;
}
}
};
こうすることで、アセンブリでも、該当箇所に pragma のコメントが残ることが確認できました。
; 128 : #pragma loop(no_vector)
; 129 : for (int i = 0; i < n; ++i) {
実行結果は以下のようになりました。
A) sample-virtual 83.016 ms 123.35 MSamples/s
B) block-virtual scalar 6.675 ms 1534.15 MSamples/s
B') block-virtual scalar(no_vec) 27.504 ms 372.31 MSamples/s
C) block-virtual AVX2 8.327 ms 1229.79 MSamples/s
B → B’ で大きく低速化しているため、B が自動ベクタ化の恩恵を受けていたことが強く示唆されます。また、C が B’ を上回っており、「scalar に対する手書き SIMD の優位性」 という比較がここでは成立しています。
アセンブリ調査による裏取り: B’ はスカラ演算になっている
#pragma loop(no_vector) を付けた B’ について、.cod を確認すると、GainBlockScalarNoVec::processBlock のループ本体が 1 要素ずつ処理するスカラ命令として生成されていることが分かります。以下は抜粋です。
; GainBlockScalarNoVec::processBlock (抜粋)
; 128 : #pragma loop(no_vector)
vmovss xmm0, DWORD PTR [rdi+rdx]
vmulss xmm0, xmm0, DWORD PTR [rcx+8]
vmovss DWORD PTR [r8+rdx], xmm0
ここで出てくる vmulss は XMM レジスタを用いた **スカラ乗算(1 要素)**であり、YMM 幅(8 要素)で計算する vmulps とは性質が異なります。つまり、B’ は「見た目だけでなく、生成コードとしてもスカラ」に落ちていると言えます。
同様に ClipBlockScalarNoVec::processBlock でも、vmaxss / vminss といった スカラ命令が確認できます。
; ClipBlockScalarNoVec::processBlock (抜粋)
; 137 : #pragma loop(no_vector)
vmovss xmm0, DWORD PTR [r11+rax-4]
vmaxss xmm1, xmm0, DWORD PTR [rcx+8]
vminss xmm2, xmm1, DWORD PTR [rcx+12]
vmovss DWORD PTR [rax-20], xmm2
以上より、検証1 で B が高速だった主因は、ソースが scalar であっても 実際には自動ベクタ化により SIMD 命令(YMM 幅)が生成されていた点にあります。検証1 の B と C の比較は「scalar vs 手書き AVX2」ではなく、実態としては 「自動ベクタ化された実装 vs 手書き AVX2 実装」 の比較になっていたことが分かりました。
この条件では、手書き AVX2 側が 末尾処理(tail)や loadu/storeu によるアライメント最適化の制約 でループ形状が複雑になりやすく、結果として自動ベクタ化された側のほうがアンローリングやスケジューリングまで含めて良いコードになり、差が 25% 程度まで広がることがあります。従って、C が B に劣後した結果だけをもって「手書き SIMD が無意味」と結論づけるのは適切ではありません。比較実験では、実装ではなく生成コードも根拠に「何と何を比較しているか」を確定させたうえで、評価する必要があります。
考察
最適化の出発点は「SIMD を書くこと」ではなく「SIMD が効く形に整えること」
A → B が示す通り、virtual をブロック境界へ押し出し、内側ループを単純な配列走査にするだけで、性能は十倍単位で変わり得ます。実務でまず効くのは、手書き命令よりも、処理構造の整理です。
scalar 実装は実測上 scalar とは限らない
B と B’ の結果が示す通り、最適化ビルドではコンパイラが自動ベクタ化します。比較実験では「生成コードが何になっているか」を前提に置かないと、結論が逆転します。本稿では、コンパイラレポートを手がかりにしつつ、アセンブリ出力で裏取りすることで、比較対象の実体を確定させました。
まとめ
本記事では、OOP と SIMD を両立させる際に起こりがちな「測定の逆転」を、測定結果・コンパイラレポート・アセンブリ出力を根拠に切り分けました。結論として、B (block-virtual scalar) が速かったのは、ソースが scalar でも生成コードが SIMD 化されていたためであり、B’ で自動ベクタ化を止めると、C (手書き AVX2) が優位になることが確認できました。実務では、まず「ブロック化とループの単純化」でコンパイラ最適化が最大限効く形を作り、そのうえで必要な場合にのみ手書き SIMD を検討する、という順序が安全です。







