
C++ inline 指定がパフォーマンスに与える影響を MSVC で検証する
はじめに
「inline を付ければ関数呼び出しが消えて速くなる。」C++ を学び始めると、一度はこのように理解する方が多いのではないでしょうか。しかし、実際にはそれほど単純ではありません。
本記事では MSVC を使い、inline キーワードの有無が実行速度にどう影響するかを実測で検証します。inline キーワードを付けるだけで速くなるのか、それとも他の要因が大きいのか。検証を通じて inline キーワードとインライン展開の関係を整理していきます。
inline 関数とは
C++ では関数の宣言に inline キーワードを付けることができます。
inline int add(int a, int b) { return a + b; }
この指定が持つ仕様上の意味は ODR (One Definition Rule) の緩和です。通常、同じ関数の定義はプログラム全体で 1 つだけ許されます。inline を付けると、同じ定義を複数の翻訳単位に置いてもリンクエラーにならなくなります。ヘッダファイルに関数定義を書くときに必要な仕組みです。
C++ の規格では inline はインライン展開のヒントとも記述されていますが、拘束力はなくコンパイラは無視できます。少なくとも仕様上保証されているのは ODR の緩和だけであり、速度向上を約束するものではありません。
インライン展開とは
インライン展開とは、コンパイラが関数呼び出しを本体のコードで置き換える最適化手法です。
// 呼び出し側のコード (概念的なイメージ)
result = add(x, y); → result = x + y; // call 命令が消える
呼び出しのオーバーヘッドがなくなるため、小さな関数では高速化につながります。さらに展開先では定数畳み込みやループ最適化など追加の最適化が効きやすくなる利点もあります。
inline キーワードを付けても、コンパイラがインライン展開するとは限りません。逆に、付けなくてもコンパイラが自動で展開することがあります。コンパイラは関数の大きさや呼び出し頻度からコストと効果を推定し、展開の可否を自動判断します。また、MSVC には __forceinline という拡張もあり、コンパイラに展開を強く要求することができます。それでも絶対に保証されるわけではありません。
検証環境
| 項目 | 値 |
|---|---|
| OS | Windows 11 |
| CPU | Intel Core i7-11700F |
| コンパイラ | MSVC v143 (Visual Studio 2022) |
| C++ 標準 | C++14 |
対象読者
- C++ の
inlineを聞いたことはあるが仕組みをよく知らない方 - コンパイラがどのように関数呼び出しを最適化するか興味がある方
参考
- inline specifier - cppreference.com
- __forceinline - Microsoft Learn
- /GL (Whole Program Optimization) - Microsoft Learn
検証方法
本記事では、コンパイラが実際にはどのようにふるまうのか、実測で確かめていきます。
- 検証 1:
inline指定の有無
同じ関数に対して修飾なし (plain) /inline/__forceinlineの 3 パターンを用意し、実行時間を比較します。inlineを付けることで本当に速くなるのかを直接確かめます。 - 検証 2: 関数の性質
極小関数 (add)・分岐付き関数 (clamp)・ループ付き関数 (heavy) の 3 種類を用意し、関数の大きさや構造がインライン展開の判断にどう影響するかを確認します。 - 検証 3: 呼び出し場所
関数の定義と呼び出しが同じ.cppファイルにある場合 (same-TU) と、別の.cppファイルにある場合 (cross-TU) で実行時間を比較します。 - 検証 4: コンパイル条件
Debug (最適化なし)・Release_NoLTO (最適化あり)・Release_LTO (最適化あり + リンク時最適化) の 3 構成で同じコードをビルドし、最適化オプションの影響を確認します。
検証用の関数
3 種類の関数を用意しました。それぞれ修飾なし (plain) / inline / __forceinline の 3 修飾で同一翻訳単位 (same-TU) に定義します。static を付けているのは、cross-TU 用の同名関数とリンク時に衝突しないようにするためです。
// --- add: 極小関数 (1 命令) ---
static int add_plain_same_tu(int a, int b) {
return a + b;
}
static inline int add_inlined_same_tu(int a, int b) {
return a + b;
}
static __forceinline int add_forced_same_tu(int a, int b) {
return a + b;
}
// --- clamp: 分岐付き関数 ---
static int clamp_plain_same_tu(int value, int lo, int hi) {
if (value < lo) return lo;
if (value > hi) return hi;
return value;
}
static inline int clamp_inlined_same_tu(int value, int lo, int hi) {
if (value < lo) return lo;
if (value > hi) return hi;
return value;
}
static __forceinline int clamp_forced_same_tu(int value, int lo, int hi) {
if (value < lo) return lo;
if (value > hi) return hi;
return value;
}
// --- heavy: ループ付き関数 ---
static int heavy_plain_same_tu(int n) {
int sum = 0;
for (int i = 1; i <= n; ++i) { sum += i * i; }
return sum;
}
static inline int heavy_inlined_same_tu(int n) {
int sum = 0;
for (int i = 1; i <= n; ++i) { sum += i * i; }
return sum;
}
static __forceinline int heavy_forced_same_tu(int n) {
int sum = 0;
for (int i = 1; i <= n; ++i) { sum += i * i; }
return sum;
}
別翻訳単位 (cross-TU) 用には修飾なしの関数を別ファイルに定義します。
// cross_tu_functions.h
#pragma once
int add_plain_cross_tu(int a, int b);
int clamp_plain_cross_tu(int value, int lo, int hi);
int heavy_plain_cross_tu(int n);
// cross_tu_functions.cpp
#include "cross_tu_functions.h"
int add_plain_cross_tu(int a, int b) {
return a + b;
}
int clamp_plain_cross_tu(int value, int lo, int hi) {
if (value < lo) return lo;
if (value > hi) return hi;
return value;
}
int heavy_plain_cross_tu(int n) {
int sum = 0;
for (int i = 1; i <= n; ++i) { sum += i * i; }
return sum;
}
計測方法
計測にはマクロ RUN_BENCH を使用しました。関数ポインタ経由の呼び出しを避けるため、呼び出し式をマクロ引数として直接展開しました。ウォームアップ 100 万回の後、add と clamp は 1 億回、heavy は 1,000 万回呼び出して経過時間を記録しました。volatile 変数への加算で Dead Code Elimination を防いでいます。なお本記事の計測値は 1 回の試行結果であり、volatile による最適化抑制の影響も含まれます。傾向の把握を目的としているため、数 ms 程度の差は誤差として扱っています。
bench.h (計測マクロとユーティリティ)
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include <chrono>
#include <cstdio>
#include <string>
#include <vector>
struct BenchResult {
std::string config;
std::string function;
std::string inline_type;
std::string call_type;
int iterations;
double time_ms;
};
// RUN_BENCH: direct call macro (avoids function pointer to preserve inlining)
// - Warmup: 1,000,000 iterations
// - Measurement: `iters` iterations
// - volatile sink prevents dead-code elimination
#define RUN_BENCH(results, cfg, func, itype, ctype, iters, call_expr) \
do { \
volatile int sink = 0; \
for (int i = 0; i < 1000000; ++i) { \
sink += (call_expr); \
} \
auto start = std::chrono::high_resolution_clock::now(); \
sink = 0; \
for (int i = 0; i < (iters); ++i) { \
sink += (call_expr); \
} \
auto end = std::chrono::high_resolution_clock::now(); \
double ms = std::chrono::duration<double, std::milli>( \
end - start).count(); \
BenchResult r; \
r.config = (cfg); \
r.function = (func); \
r.inline_type = (itype); \
r.call_type = (ctype); \
r.iterations = (iters); \
r.time_ms = ms; \
(results).push_back(r); \
} while (0)
inline void write_csv(const std::vector<BenchResult>& results,
const std::string& filename) {
FILE* fp = fopen(filename.c_str(), "w");
if (!fp) return;
fprintf(fp, "config,function,inline_type,call_type,iterations,time_ms\n");
for (const auto& r : results) {
fprintf(fp, "%s,%s,%s,%s,%d,%.3f\n",
r.config.c_str(), r.function.c_str(),
r.inline_type.c_str(), r.call_type.c_str(),
r.iterations, r.time_ms);
}
fclose(fp);
}
inline void print_results(const std::vector<BenchResult>& results) {
printf("%-14s %-24s %-14s %-10s %12s %10s\n",
"config", "function", "inline_type", "call_type",
"iterations", "time_ms");
printf("----------------------------------------------------"
"-------------------------------------------\n");
for (const auto& r : results) {
printf("%-14s %-24s %-14s %-10s %12d %10.3f\n",
r.config.c_str(), r.function.c_str(),
r.inline_type.c_str(), r.call_type.c_str(),
r.iterations, r.time_ms);
}
}
main() 関数 (計測の実行部分)
int main() {
std::vector<BenchResult> results;
const char* cfg = BENCH_CONFIG;
const int ADD_ITERS = 100000000; // 1 億回
const int CLAMP_ITERS = 100000000; // 1 億回
const int HEAVY_ITERS = 10000000; // 1,000 万回
// --- same-TU: add ---
RUN_BENCH(results, cfg, "add_plain", "plain", "same_tu", ADD_ITERS,
add_plain_same_tu(i, i + 1));
RUN_BENCH(results, cfg, "add_inline", "inline", "same_tu", ADD_ITERS,
add_inlined_same_tu(i, i + 1));
RUN_BENCH(results, cfg, "add_forced", "__forceinline", "same_tu", ADD_ITERS,
add_forced_same_tu(i, i + 1));
// --- same-TU: clamp ---
RUN_BENCH(results, cfg, "clamp_plain", "plain", "same_tu", CLAMP_ITERS,
clamp_plain_same_tu(i, 0, 1000));
RUN_BENCH(results, cfg, "clamp_inline", "inline", "same_tu", CLAMP_ITERS,
clamp_inlined_same_tu(i, 0, 1000));
RUN_BENCH(results, cfg, "clamp_forced", "__forceinline", "same_tu", CLAMP_ITERS,
clamp_forced_same_tu(i, 0, 1000));
// --- same-TU: heavy ---
RUN_BENCH(results, cfg, "heavy_plain", "plain", "same_tu", HEAVY_ITERS,
heavy_plain_same_tu(i % 50 + 1));
RUN_BENCH(results, cfg, "heavy_inline", "inline", "same_tu", HEAVY_ITERS,
heavy_inlined_same_tu(i % 50 + 1));
RUN_BENCH(results, cfg, "heavy_forced", "__forceinline", "same_tu", HEAVY_ITERS,
heavy_forced_same_tu(i % 50 + 1));
// --- cross-TU ---
RUN_BENCH(results, cfg, "add_plain", "plain", "cross_tu", ADD_ITERS,
add_plain_cross_tu(i, i + 1));
RUN_BENCH(results, cfg, "clamp_plain", "plain", "cross_tu", CLAMP_ITERS,
clamp_plain_cross_tu(i, 0, 1000));
RUN_BENCH(results, cfg, "heavy_plain", "plain", "cross_tu", HEAVY_ITERS,
heavy_plain_cross_tu(i % 50 + 1));
// --- Output ---
print_results(results);
std::string csv_name = std::string("results_") + cfg + ".csv";
write_csv(results, csv_name);
printf("\nResults written to %s\n", csv_name.c_str());
return 0;
}
ビルド構成
3 種類のビルド構成を使用しました。BENCH_CONFIG マクロでビルド構成名を埋め込み、CSV ファイル名に反映しました。
| 構成名 (記事中の表記) | VS 構成名 | 最適化 | LTO |
|---|---|---|---|
| Debug | Debug | なし (/Od) |
なし |
| Release_NoLTO | ReleaseNoLTO | あり (/O2 /Oi) |
なし |
| Release_LTO | Release | あり (/O2 /Oi) |
あり (/GL + /LTCG) |
ビルドコマンド:
msbuild test-inline-code-performance.sln /p:Configuration=Debug /p:Platform=x64
msbuild test-inline-code-performance.sln /p:Configuration=ReleaseNoLTO /p:Platform=x64
msbuild test-inline-code-performance.sln /p:Configuration=Release /p:Platform=x64
アセンブリリスト出力には /FA オプションを使用しました。
検証結果
検証 1: inline 指定の有無
同一翻訳単位・Release_NoLTO での結果を示します。
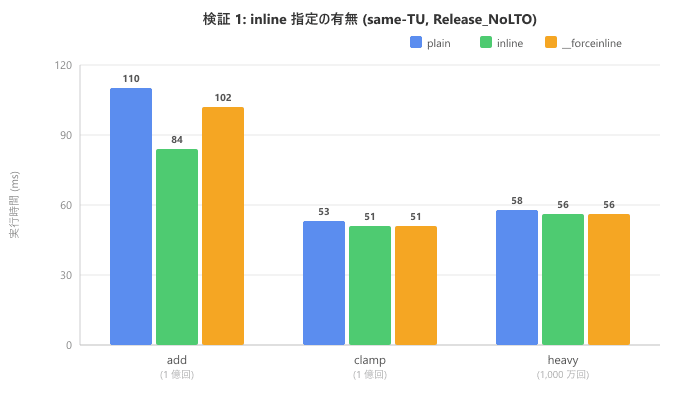
| 関数 | plain (ms) | inline (ms) |
__forceinline (ms) |
|---|---|---|---|
| add (1 億回) | 110 | 84 | 102 |
| clamp (1 億回) | 53 | 51 | 51 |
| heavy (1,000 万回) | 58 | 56 | 56 |
clamp と heavy は 3 修飾でほぼ同じ実行時間です。add は数値にばらつきがありますが、アセンブリを確認すると 3 修飾すべてでインライン展開されていました。この差はインライン展開の有無ではなく、コード配置の違いによる揺らぎと考えられます。少なくとも今回の MSVC 環境では、inline の有無はコンパイラの最適化判断に影響を与えていませんでした。
検証 2: 関数の性質
同じデータを関数の軸で整理します。plain 修飾・same-TU・Release_NoLTO のアセンブリを確認しました。
| 関数 | 性質 | plain でのインライン展開 |
|---|---|---|
| add | 極小 (1 命令) | 展開された |
| clamp | 分岐付き | 展開された |
| heavy | ループ付き | 展開されなかった |
極小関数の add はコンパイラが自動で展開しました。分岐付きの clamp も同様です。一方、ループを含む heavy はコスト超過と判断され、__forceinline を付けない限り展開されませんでした。検証 1 の表で heavy の実行時間が 3 修飾ともほぼ同じなのは、ループ本体の計算コストが支配的で、呼び出しオーバーヘッドの有無が結果に表れにくいためです。今回の検証では、inline キーワードの有無よりも関数の性質のほうが展開の可否に大きく影響していました。
検証 3: 呼び出し場所
Release_NoLTO で同一翻訳単位と別翻訳単位を比較します。cross-TU は plain 修飾のみ測定しました。
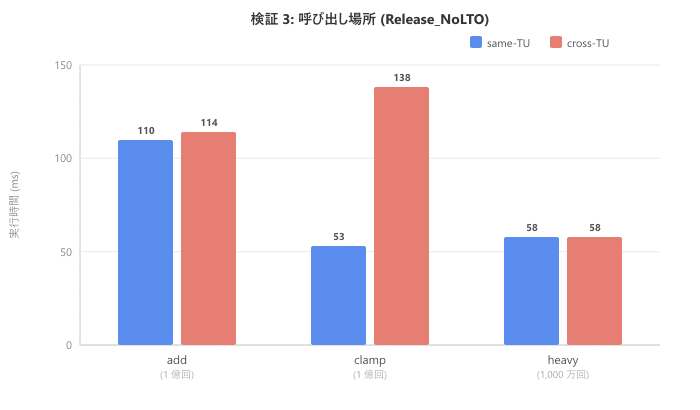
| 関数 | same-TU (ms) | cross-TU (ms) |
|---|---|---|
| add (1 億回) | 110 | 114 |
| clamp (1 億回) | 53 | 138 |
| heavy (1,000 万回) | 58 | 58 |
clamp に注目してください。same-TU では 53ms だったのが、cross-TU では 138ms と約 2.6 倍に増加しました。翻訳単位をまたぐとコンパイラは関数定義を参照できず、インライン展開が行われません。その結果、呼び出しオーバーヘッドがそのまま残るだけでなく、定数畳み込みなど展開先で行われるはずの追加最適化の機会も失われます。add は関数本体が極小のため呼び出しオーバーヘッド自体が小さく、差が出にくくなっています。heavy はそもそも展開されないため差がありません。
検証 4: コンパイル条件
cross-TU で 3 つのビルド構成を比較します。
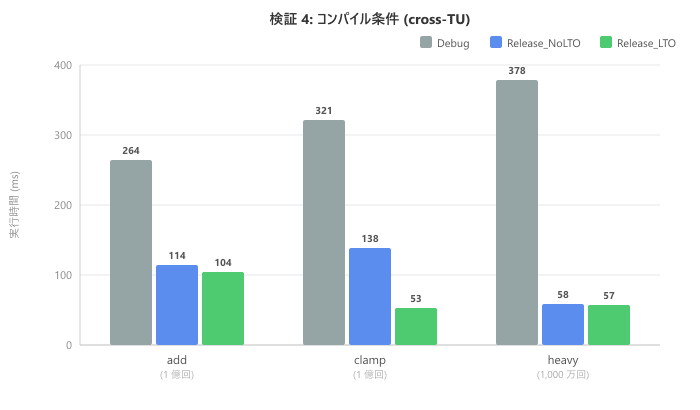
| 関数 | Debug (ms) | Release_NoLTO (ms) | Release_LTO (ms) |
|---|---|---|---|
| add (1 億回) | 264 | 114 | 104 |
| clamp (1 億回) | 321 | 138 | 53 |
| heavy (1,000 万回) | 378 | 58 | 57 |
Debug は最適化が無効なため全体的に遅くなっています。Release_NoLTO では heavy が大幅に改善されますが、clamp の cross-TU は 138ms のまま残っています。Release_LTO に注目すると、clamp が 53ms に改善されています。LTO (リンク時最適化) により翻訳単位の壁を越えたインライン展開が可能になったためです。検証 3 で確認した cross-TU の性能低下は LTO で解消できます。
アセンブリの確認
数値だけでなく、生成されたアセンブリからもインライン展開の有無を確認しました。
Release_NoLTO: add (same-TU) → 展開あり
$LL16@main:
mov ecx, DWORD PTR sink$1[rsp]
inc ecx
add ecx, edx ; 加算が直接埋め込まれている
mov DWORD PTR sink$1[rsp], ecx
add edx, 2
cmp edx, 2000000
jl SHORT $LL16@main
call 命令はありません。add ecx, edx として関数本体がループ内に直接展開されています。なお cmp edx, 2000000 はウォームアップループ (100 万回) の比較命令で、コンパイラのループ変換により値が変わっています。インライン展開の確認には影響しません。
Release_NoLTO: add (cross-TU) → 展開なし
$LL88@main:
lea ebx, DWORD PTR [rax+1]
mov edx, ebx
mov ecx, eax
call ?add_plain_cross_tu@@YAHHH@Z ; 関数呼び出しが残る
...
jl SHORT $LL88@main
翻訳単位が異なるため call 命令が残り、毎回関数呼び出しが発生します。Debug ビルドでは同一翻訳単位であっても call 命令が出力されます。最適化が無効であるためです。Release_LTO の cross-TU では add と clamp の call 命令が消え、same-TU と同等のコードが生成されることも確認しました。
検証で分かったこと
今回の MSVC 環境での検証を通じて、以下のことが確認できました。
inlineキーワードの有無だけでは、インライン展開の結果は変わらない- インライン展開されるかどうかは、関数の大きさや構造に大きく依存している
- 翻訳単位をまたぐとインライン展開の機会が失われる
- LTO を有効にすると翻訳単位の壁を越えた展開が可能
ただし、inline に実用的な意味がないわけではありません。inline を付けることでヘッダファイルに関数定義を置けるようになり、呼び出し側の翻訳単位からコンパイラが関数本体を参照できるようになります。これは検証 3 で確認した通り、インライン展開の機会を生むうえで重要です。
まとめ
inline を付けるだけで速くなるわけではありません。インライン展開はコンパイラが関数の性質やコストを見て自動で判断しており、キーワードの有無よりも関数の設計・翻訳単位の構成・LTO の活用が速度に影響します。パフォーマンスが気になる場面では、まずプロファイラで計測するところから始めるのがよいでしょう。







